안녕하세요 최인하입니다. 이번에 리뷰할 논문은 Affordance를 이용하여 Dextreous hand의 How to grasp 부터 where to grasp까지 해결한 파이프라인을 제시하는 논문입니다. 물체를 용도에 맞게 사용하는 것 까지는 가지 않고 grasp만 진행한 논문이지만 접근 방식이 참신했고, 최적화 기법을 사용해서 specific hardware를 요구하지 않는다는 점이 인상 깊었습니다. 하지만 feedback loop의 부재로인한 실패와 너무 단순한 object만 사용하여 실험을 진행했다는 점이 제가 생각하기에는 단점이자 한계인 것 같습니다. 그럼 바로 리뷰해보겠습니다.

논문은 5-fingers gripper가 높은 자유도와 기구학적 문제로 인해서 모델이 표현하기에도 어렵다고 하며, 최근 접근 방식들은 방대한 데이터의 양과 hardware specific한 데이터셋에 의존하기 때문에 hardware에 대한 일반화도 어렵다고 합니다. 따라서 논문에서는 data-efficient한 framework를 제시합니다. 요약해서 설명하자면 raw human demonstrations video에서 나온 object의 key frame과 object를 grasp한 keyframe을 가지고 나온 손가락 별 contact heatmap을 gt로 하여 internet scale text-to-image diffusion model이 이를 예측하도록 합니다. 그 후 Grounding Dino와 SAM2를 가지고 masking된 object에 FoundationStereo를 통해 생성된 dense depth map과 결합하여 partial 3D point cloud를 얻게 됩니다. diffusion model이 예측한 likelihood map이 object 3D point cloud 위에 fuse되고 approaching vector가 정의되어 최적화 기법으로 grasp를 수행하게 됩니다.
논문에서 제시하는 framework로 얻을 수 있는 장점은 다음과 같습니다.
- “How to grasp”와 “where to grasp”를 동시에 정의했습니다. 기존의 방식들은 이 두 문제를 독립적으로 다루는 경우가 많았다고 합니다. 로봇이 object를 잡는 것을 넘어서 tools를 잡고 어떠한 task를 수행하기 위해서는 두가지가 두 문제를 동시에 정의해야겠죠.
- Finger-Specific한 Affordance를 제공합니다. 기존의 affordance 연구들은 ROI를 제공하는 수준이었다고 합니다. 하지만 5지 그리퍼의 dexterous manipulation 에 필요한 손가락 단위의 instructions는 주어지지 않아서 정보가 불충분했다고 하네요.
- Human teleoperation을 요구하지 않으므로 데이터 수집의 부담을 줄였습니다. raw human demonstration video만 필요하므로 힘들게 data를 모으는 과정을 생략했다고 보면 될 것 같습니다.
- Hardware의 일반화를 달성하였습니다. 최적화 기법을 이용하여 Approach, closure, hold 하므로 특정한 하드웨어에 fit하지 않는 것 같습니다. (근데 task를 수행하기 위해서는 learning이 들어가야 되지 않나.. learning이 들어가면 다시 hardware specific해질 것 같다고 생각합니다.)
Method
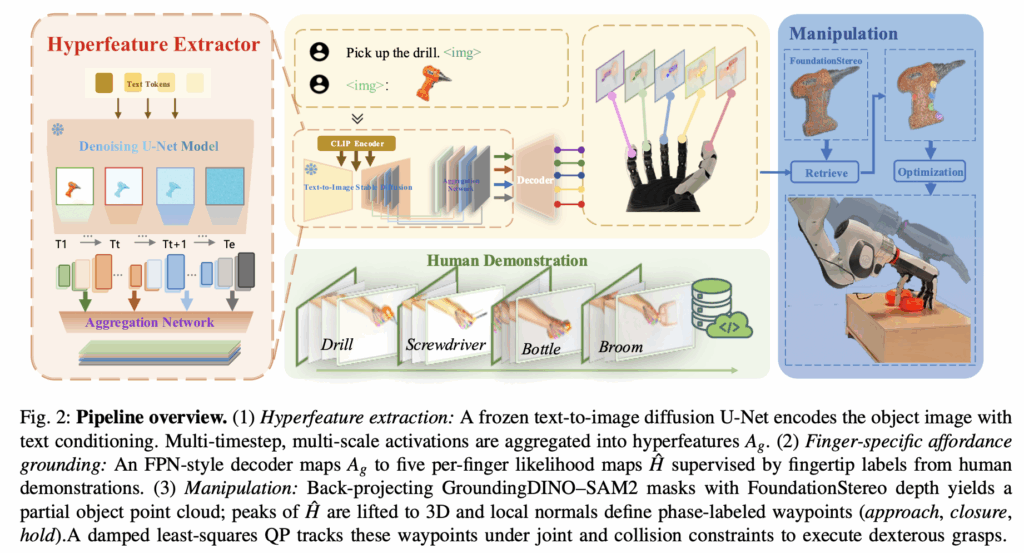
이제 논문의 방법론에 대해서 설명해보겠습니다. 사실 위에서 요약한게 전부이지만 조금 뜯어서 보겠습니다. 제 생각이긴 하지만 이 논문의 핵심은 grasp가 아니라 Diffusion model이 affordance를 이해하는 모습인 것 같습니다.
Data Collection
Human demonstration videos를 사용합니다. object만 있는 keyframe과 사람 손이 object를 grasp한 이미지가 pair로 training에 사용된다고 합니다. RTMPose로 2D hand keypoints를 얻는다고 하네요. 그렇게 얻은 fingertip keypoints를 이용해서 5 x h x w의 Gaussian channel을 얻는다고 합니다. 각각의 채널 당 손가락 하나의 fingertip 부분의 heatmap이 생긴다고 이해했습니다. 이를 tensor H라 하고 모델은 H를 MSE를 사용하여 regression을 수행합니다.
Feature synthesis and hyperfeature aggregation
논문에서는 기존의 backbone인 CNN과 ViT구조가 외형 정보만 사용하므로 object-part semnatics, inter-finger relations에 대한 정보를 효과적으로 표현하지 못한다고 언급하며 이를 해결하기 위해서 text-to-image diffusion model을 finger specific contact affordance를 예측하는데 사용한다고 합니다. 구조적으로는 U-Net 백본을 사용하며 cross-attention으로 text-embedding 을 주입한다고 하네요.
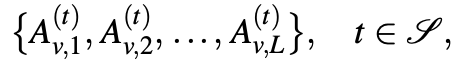
이 때 신기했던 점은 논문에서 multi-scale feature map을 뽑아서 feature aggregation을 진행한다는 점이었습니다. U-Net에서도 얕은 layer와 깊은 layer가 표현하는 level이 달라 합쳐주는구나 생각했습니다. 이 때 t는 디노이징 과정에서 모든 timesteps T를 고려해서 feature map을 뽑는 것은 시간적 cost가 많이 소비되기 때문에 일정 T를 고른다고 하네요. 이렇게 뽑은 timestep t feature map들을 다음과 같은 식으로 aggregation을 진행합니다.
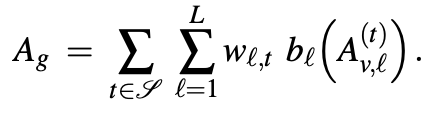
여기서 b는 d차원의 1 x 1 conv layer와 global average pooling으로 이루어져있고, w는 학습되는 가중치로 softmax를 취합니다.
Finger-specific Affordance Heatmap prediction
논문에서는 FPN-decoder 구조를 사용하여 high-level semantic discrimination을 유지하면서 spatial detail를 복원한다고 합니다.
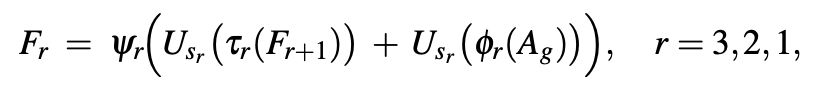
식은 위와 같은데요. 파이 기호는 1 x 1 conv layer로 각 단계의 채널 수는 256, 128, 64라고 합니다. U는 bilinear upsampling이며 목표 해상도는 (h, w) -> (2h, 2w) -> (H, W)라고 합니다. 프사이 기호는 3 x 3 conv layer입니다. 그리고 초기 F4 = 0으로 두고 계산한다고 하네요.
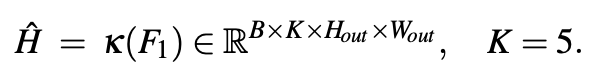
이제 마지막으로 3 x 3 conv layer를 통해서 최종 손가락별 heatmap이 생성이 됩니다. 그 후 MSE를 진행하게 됩니다!
Finger-specific Affordance Matching for Grasp Planning

이제 손가락별 affordance를 얻었으니까 object를 grasp해야겠죠. 논문에서는 grasp planning을 의도적으로 learning을 사용하지 않았다고 합니다. 위에서 언급한 것 처럼 hardware specific하지 않기 위해서겠죠. 따라서 최적화 방식이 사용되었습니다. 3D point cloud 와 affordance heatmap이 fuse되는 방식은 특별한게 없고 위에서 설명한 방식 그대로이기 때문에 생략하겠습니다.
최적화 planning으로는 QP(Quadratic Programming)가 사용되었습니다. 제약조건을 지키면서 해를 찾는 최적화 방식입니다. 결국 fingertip이 목표 지점에 도달하기 위해서 IK를 푸는 과정입니다. 우선 object에 Approaching Vector를 정의하는데요. 다음과 같이 정의합니다.
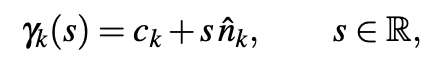
c는 fingertip contact location, n은 c의 surface normal vector입니다. 이 때 단순히 s가 0보다 크면 접근 중으로 0에 근접하면 closure, 0보다 작으면 hold로 취급합니다.
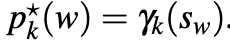
각 단계에서 목표는 위와 같이 Pstar로 정의됩니다.
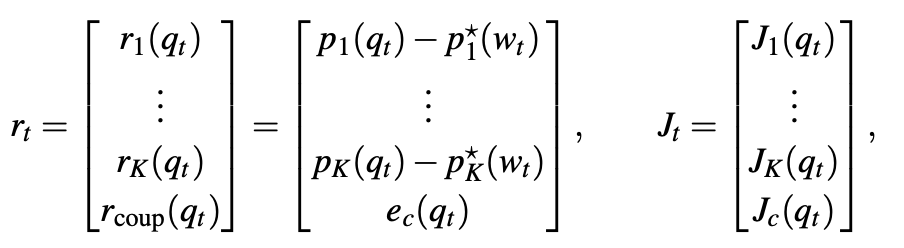
논문에서는 q를 arm – hand joint 값으로 두고 FK와 FK의 Jacobian을 구합니다. 그리고 위치에서의 목표값을 위와 같이 Pstar로 정의했기 때문에 우리는 현재 p값과 pstar값의 잔차를 최적화 하면 됩니다.
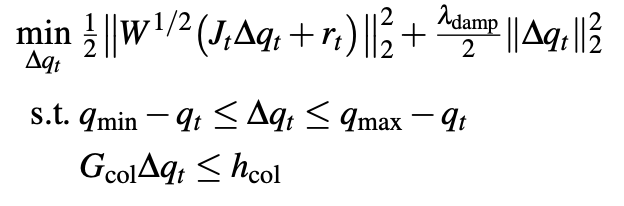
최적화 방식은 위와 같은데 밑의 제약 조건을 가지고 위의 식을 최적화 하는 방식입니다. 첫번째 제약은 joint값의 한계, 두번째는 self-collision과 같은 충돌 회피 제약입니다. 논문에서는 매 step step마다 FK를 다시 계산하여 동작 연속성과 singular point를 예방한다고 하네요.
Experiment
실험에 사용한 구성은 위와 같습니다. 논문에서는 다음 3가지를 중점적으로 검증하기 위해서 실험을 수행했다고 합니다.
- Text-to-image diffusion model의 vision-language priors를 사용하는 것이 기존의 discriminative backbones을 사용하는 것보다 성능 향상을 제공하는지
- Unseen 물체와 part 단서가 부족한 object에도 정확한지.
- hardware specific 문제가 해결되었는지
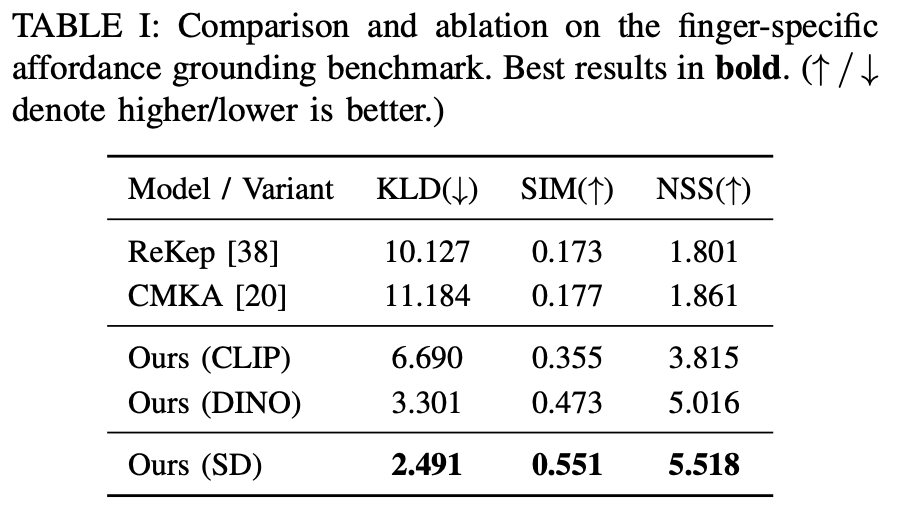
논문에서는 VLM을 사용하여 직접적으로 손가락별 affordance를 예측한 prior 연구가 없어서 유사한 ReKep과 CMKA를 baseline으로 두고 실험을 진행하였다고 합니다. 결과적으로 좋은 성능을 보였습니다. 그리고 diffusion model을 사용하지 않고 CLIP과 DINO를 사용하여 실험을 진행하였을 때 성능이 떨어진 것을 보아 text-to-image diffusion model을 사용하는 것이 affordance를 예측하고 이해하는데 도움이 된다는 것을 보여줬습니다.
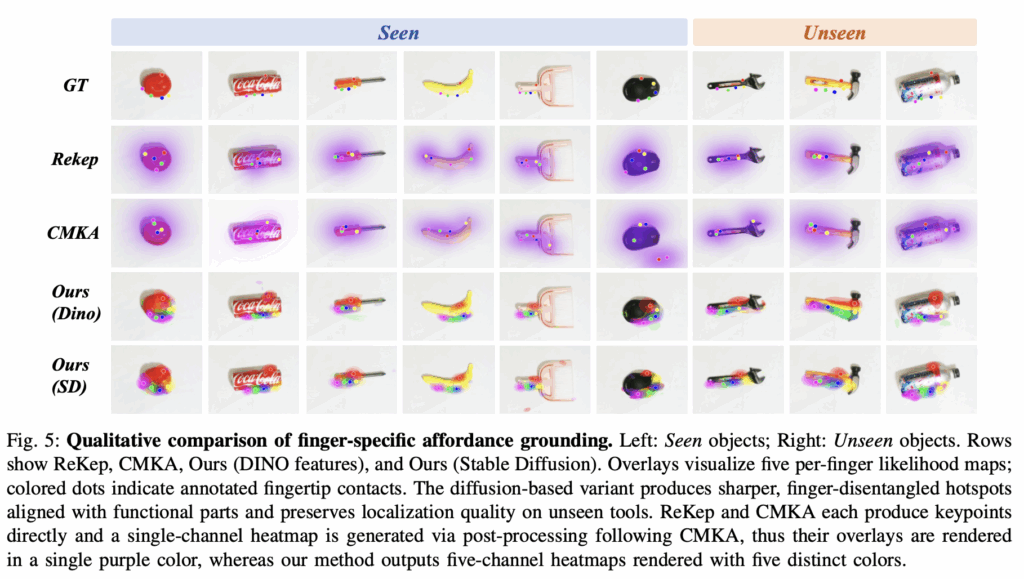
이미지의 특징만으로만 학습한 Rekep은 의미있는 semantic한 접촉 위치를 찾는데 부족했으며, CMKA의 segmentation 기반 계층 구조는 object가 뚜렷한 part-aligned regions를 가지고 있지 않을 때 성능이 저하 된다고 합니다. 그리고 Fig.5에서 볼 수 있듯이 Dino를 사용할경우 unseen object에서 시각적으로 두드러지는 머리 부분에 activation 한다고 합니다. 제가 CLIP 논문을 읽어보지는 않았지만 CLIP도 VLM인 것 같은데 왜 성능이 안좋고 unseen 실험에서는 왜 CLIP이 빠졌는지 잘 모르겠습니다.
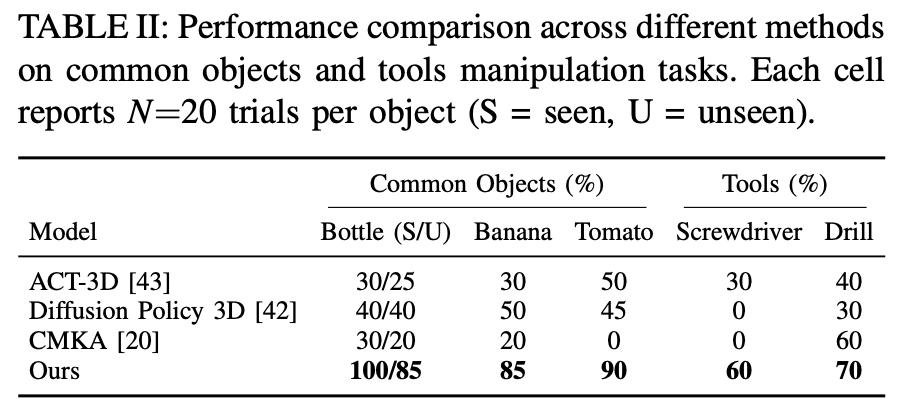
기존의 imitation learning 방법론들과도 비교를 진행했는데요. 논문에서는 이러한 방법론들은 궤적을 단순히 재현하므로 object의 형태가 변하거나 unseen에 취약하다고 합니다. 특히 논문에서는 최적화 방식에 사용된 제약조건 덕분에 높이가 낮은 object를 grasp할 때도 table과 충돌하지 않는다고 하네요.
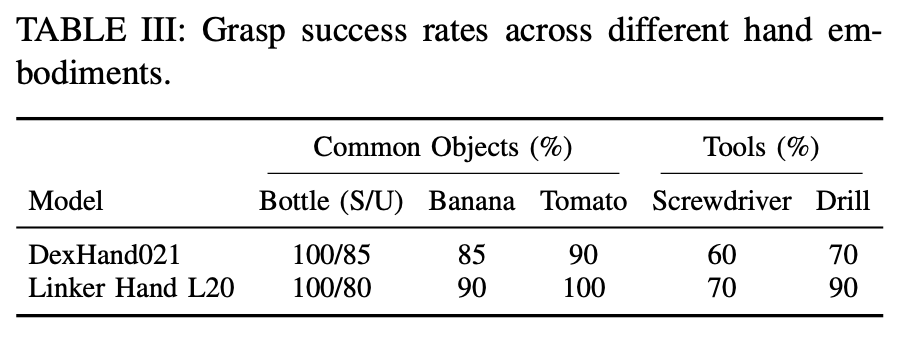
마지막으로 최적화 방식으로 인하여 hardware가 바뀌고 자유도가 바뀌었을 때에도 성공률이 거의 변화가 없는 모습을 보여주면서 hardware specific 문제를 해결했다고 합니다.
VLM을 활용하여 affordance를 이해하고, 학습 기반 정책이 아닌 최적화 기반 방식으로 grasp를 수행한 연구입니다. 단순 grasp 문제에서는 learning 대신 optimization 기반 접근 또한 효과적인 대안이 될 수 있음을 보여주는 것 같습니다. 다만 보다 복잡한 task에 대해서도 이러한 optimization 방식이 동일하게 적용 가능할지는 생각해봐야 될 것 같습니다. 감사합니다.
안녕하세요 인하님 리뷰 감사합니다.
이 논문은 grasp affordance를 다루긴 하는데 tool use 처럼 진짜 affordance가 유효한 “용도에 맞는 조작”까지 가려면 시간적/행동적 정보가 더 필요할 것 같은 생각이 드는데요,, 실제로 시퀀스한 행동이 가능하도록 이런 형태의 모델을 downstream manipulation policy 앞단의 모듈처럼 붙이는 연구들도 있나요?
안녕하세요 영규님! 질문 감사합니다.
저도 읽으면서 같은 생각이 들었던 것 같습니다. 사람들이 5-fingers gripper를 사용하려는 목적은 dexterity한 task를 수행할 수 있기 때문이라고 생각합니다. 그런점에서 이 논문은 최적화 기법으로 grasp만 진행하므로 어찌보면 hand는 장식인 느낌이 강한 것 같습니다 허허
2026년 논문이기도 하고 위와 같은 방식이 downstream manipulation policy 앞단에 사용되는 연구는 찾아보고 있다면 리뷰하도록 하겠습니다!! 뭔가 inference time이 매우 오래걸릴 것 같은 생각이 드네요!