
안녕하세요.
이번에 리뷰해볼 논문은 long video understanding에서 1시간 가량의 롱이 아닌 최대 50시간 정도의 베리롱!! VU를 다룬 논문입니다.
그럼 리뷰 시작하겠습니다.
Intro
이 논문에서는 “very long video understanding”을 다룹니다. 일주일 동안의 50시간 분량을 very long으로 정의합니다. 그렇다면 이 베리 롱!! video understanding이 왜 필요할까요? 스마트안경 같은 웨어러블이 등장하면 AI가 사용자의 시야나 행동을 항상 켜진상태로 관찰할 수 있어야 하는데, 그렇게 되면 질문도 ‘지금 내 눈앞에 장면이 뭐야?’ 수준이 아닌 며칠~일주일 전의 경험을 뚝뚝 끊긴 비디오의 조각 조각들로 해석하는게 아니라 시간축에 따라 경험을 회상하고 해석해 대답할 수 있어야 하기 때문입니다.
기존 롱 비디오 understanding의 문제는 크게 Context window 한계와 ‘이 영상에서 물을 몇번 마셨나요?’ 같이 시간을 누적해서 행동을 추적 해야하는 very long stream에서 compositional multi-hop reasoning 부족한 문제가 있습니다. 또한 기존의 agentic접근이 많은 문제들을 해결하고 있지만 3가지 방향에서 아직은 부족하다고 설명합니다. 먼저 엔티티와 그들간의 관계를 일관되게 추론하는게(쉽게 말하자면 A라는 사람을 며칠간 지속적으로 추적해서 그사람의 행동이나 관계변화를 묶어서 이해하는 것) 어렵다고 합니다.
두번째로는 행동이나 습관은 한번만 찾아내는게 아니라 여러날(or여러순간)을 찾아야 하는데 이것이 쉽지 않다는 fine-grained temporal localization문제가 있습니다.
마지막으로는 모달리티간의 연결이 필요하다는 문제입니다. 각 모달에서 추출된 엔티티 정보가 따로놀면 정확한 추론이 어렵기 때문에 cross-modal linkage가 필요하다고 합니다!
저자들은 EGAgent를 제안합니다. long video에서 entity scene graph를 추출한 후 이것을 활용하는데 중심을 둔 에이전틱 접근으로 그래프의 nodes는 사람,장소,객체를 의미하고 edges는 노드 간의 관계(ex. uses, interacts with, mentions, talks to)를 의미합니다.
즉, planning agent에 entity scene graph에 대한 구조화된 검색 및 추론 tool과 하이브리드 시각&오디오 검색기능을 제공함으로 세밀하고 크로스모달하며 시간적으로 일관된 추론이 가능하게 합니다.
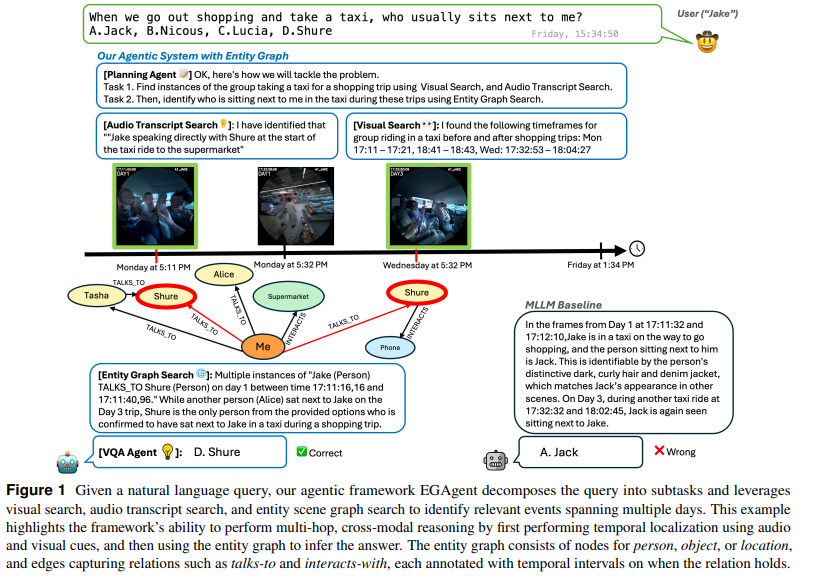
EGAgent의 planning agent가 이 entity graph를 검색하고 추론 할 수있도록 하는데 이때 visual search tool (SQL + semantic search hybrid)과 audio transcript search tool을 사용하도록 합니다. EGAgent의 흐름을 한마디로 설명하자면 비디오에서 엔티티-관계 그래프를 만들고 플래닝 에이전트가 그래프 검색,비주얼 검색, 오디오 캡션 검색을 조합해서 여러 날에 걸쳐진 정보를 모아 multi-hop reasoning을 진행합니다.
저자들의 contributions은 다음과 같습니다.
- entity graph representation으로 very long한 시간에서 구조화된 cross modal inference를 가능하게 한다.
- entity graph와 시각/오디오 검색 도구를 함께 쿼리로 넣어주는 agentic framework를 통해 EgoLifeQA에서 이전 SOTA 대비 높은 성능을 달성한다
Method
task setup
입력과 출력은 다음과 같이 구성되어 있습니다.
먼저 입력은 1FPS로 샘플링된 비디오 V, 전사된 음성과 시작,종료시간 AT이고 이를 입력으로 받아 test time에 자연어 쿼리를 함께 입력받아 텍스트형태의 최종 정답 A를 출력해야 합니다. (H:(V,AT,Q)→A)
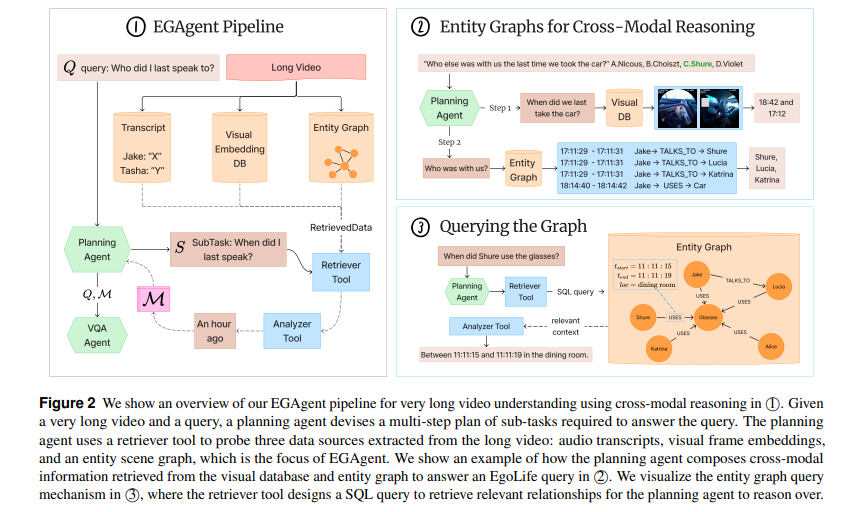
저자들이 제안하는 시스템은 크게 2단계로 진행됩니다. 먼저 Representation 단계로 entity-centric scene graph를 구축하고, 다음으로 Reasoning 단계 EGAgent라는 agentic framework를 사용하여 입력된 질문 쿼리를 sub-task로 분해해서 entity graph검색, visual검색, audio검색을 진행합니다
Entity Graph Representations
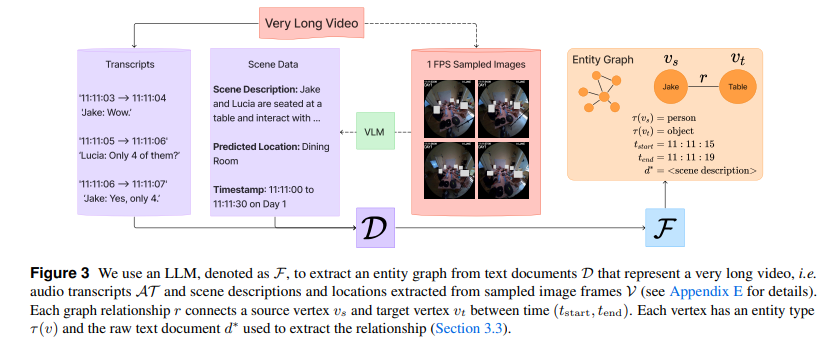
먼저 Entity Graph Representations단계입니다. 엔티티 그래프(G=(V,E))는 노드V와 엣지E로 구성되어있습니다. fig3처럼 텍스트 문서집합 D(오디오전사, 장면설명, timestep을 포함함)로부터 엔티티 그래프 G=(V, E)를 구성합니다. 이때 이 시간정보를 통해 해당 관계의 존재 여부나 순서, 지속시간 같은 것들을 추적할수 있게 되고 이 덕분에 긴 시간 범위에서 반복되는 사건이나 상호작용들을 추론할수 있게 됩니다.
엔티티 그래프 표현이라고 적혀있지만 사실상 시간관계가 달린 DB스키마를 정의하는 섹션으로 각 관계에는 모두 시간구간 (tstart, tend)가 붙여져 있습니다.
- 노드타입τ(v)은 3로 제한되어 있습니다 → person, object, location
관계타입R은 4개로 제한되어 있습니다 → talks-to, interacts-with, mentions, uses - 순서대로 살펴보자면
- 먼저 각 문서d에서 LLM이 엔티티,관계 세트를 뽑습니다.
- 이후 문서 전체 D에 대해 그 결과를 합칩니다.
- 관계 타입을 정해줌으로 구조를 단순화 합니다.
- 최종 e = ( v_s, τ(v_s), v_t, τ(v_t), r, t_start, t_end, d*)은 SQLite3 데이터베이스로 저장됩니다.
즉 처음에는 각 엣지 e를 e = (v_s, v_t, r) 형태로 초기화 되고 이후 각 엣지e에 대해 소스문서d로부터 확인한 시간 정보(t_start, t_end) 주석처리 해줍니다.
e = ( v_s, τ(v_s), v_t, τ(v_t), r, t_start, t_end, d*) (d*는 엣지가 추출된 근거텍스)
이 과정을 통해 비디오를 시간관계가 달린 관계 DB(entity graph + timestamps)로 바꾸어줍니다
Agentic Framework EGAgent

다음으로는 EGAgent 프레임워크를 살펴보겠습니다. 위의 EGAgent 알고리즘 흐름을 간단히 말하자면 쿼리를 Subtask로 나누고 각 서브테스크의 (Si, Ti, qi)에 대해 Ti(qi)로 검색 수행하고 → Analyzer가 결과 분석하고 → 분석 결과를 Working Memory M에 추가하는 과정을 반복한 후 → 최종으로 VQA Agent가 원래 질문 Q와 누적된 Working Memory M을 입력으로 받으 최종 답변 A를 생성합니다
이때 EGAgent는 6개의 구성요소로 이루어져 있고 이 각 구성요소들은 각Subtask마다 반복되는데 데이터의 특정 모달리티나 추론 단계에 대응됩니다
- Planning Agent, Retriever Tool 3개(Visual Search, Audio Transcript Search, Entity Graph Search), Analyzer Tool, VQA Agent
[Planning Agent]
복잡한 사용자의 질의Q를 subtask(S_i)로 분해하고 해당 subtask에 적절한 tool(T_i)을 선택하는 단계로 전체 추론을 지휘하는 오케스트레이터입니다. 이때 질문Q을 먼저 나누고 그 다음에 tool을 고르는게 아니라 한 번에 (S_i, T_i, q_i)를 같이 생성합니다. (q_i: tool에 넣을 쿼리인자) 툴 선택시에는 subtask 질문의 정보 유형에 따라 도구를 선택합니다. (관계 추적은 그래프, 발화 내용은 Audio, 시각정보 확인은 visual) 이후 이 검색결과는 Analyzer Tool로 전달되고 그 분석 결과가 작업메모리 M에 업데이트 됩니다. 이후 마지막으로 VQA Agent가 작업메모리와 원래 쿼리를 사용해 최종 답을 도출합니다
[Visual Search Tool (Toolvis)]
비디오를 1FPS로 샘플링하고 각 프레임을 비전 인코더로 임베딩해 벡터 DB에 저장합니다(타임스탬프,위치 같은 속성도 같이 저장함) 즉, 1FPS 프레임을 벡터DB로 검색하는 툴로 추론시 플래너는 텍스트 서브 쿼리 qi(텍스트 임베딩 ϕT(q))와 선택적 필터 f(“kitchen”, “morning”)를 주고 코사인 유사도로 k-NN 프레임을 뽑아 반환합니다
[Audio Transcript Search Tool (Toolaud)]
오디오를 전사한 자막 기반 검색으로, LLM기반으로 관련된 시간 범위 전체 transcripts를 LLM에 넣어서 검색하거나 BM25기반으로 어휘를 검색합니다.
[Entity Graph Search Tool (Tooleg)]
엔티티그래프 Representations단계에서 만든 엔티티-관계 SQLite DB에서 SQL로 검색합니다 자세히 살펴보자면 inference단계에서 4가지 필드(Planning Agent가 time filter, keyword text search, entity source&target nodes (vs, vt), relationship type r)에 대해 SQL 쿼리 q를 만듭니다. 이때 데이터의 불완전성이나 노이즈를 방지하기 위해 strict-to-relaxed 쿼리 전략을 선택하는데, 위의 모든 필드에 대해 exact match쿼리를 수행하고 결과가 없으면 점점 relaxed로 시간 범위를 넓히거나 부분 텍스트 매치를 허용하거나 관계타입 필터를 완화나는 방향으로 제약을 점진적으로 완화합니다.
[Analyzer Tool]
Analyzer는 위의 3가지 툴에서 검색으로 가져온 것들중에 진짜 관련있는 것만 남기고 중복은 제거하면서 가벼운 추론을 수행하는 정리 단계의 툴입니다.
[VQA Agent]
Q와 M(Working Memory, 누적 subtask결과 메모리)의 증거에 조건화 해 최종답변이 될 A를 생성하는 멀티모달 LLM으로 very long 비디오에 대해 상세하면서도 시간적으로 일관된 추론이 가능해집니다
Experiments
저자들은 very long video understanding에 초점을 맞춘 두 벤치마크(EgoLifeQA, Video-MME (Long))에서 평가를 진행했습니다.
Analysis on EgoLifeQA Benchmark
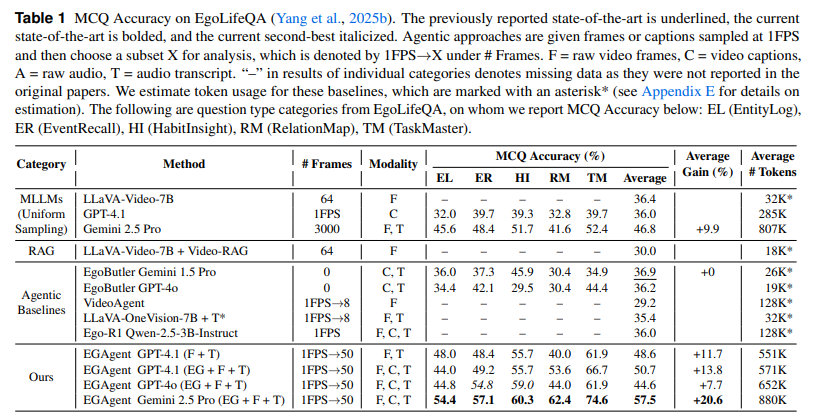
Table1) EgoLifeQA 벤치마크에 대한 방법론에 대한 비교로 3개의 카테고리로 나누어 실험을 진행했습니다. 프레임은 각 context window크기에 맞춰서 진행했으며 MCQ accuracy(EL (EntityLog), ER (EventRecall), HI (HabitInsight), RM (RelationMap), TM (TaskMaster))로 평가합니다.
표에서 확인할수 있다 싶이 Gemini2.5를 사용하는 방법에서 가장 높은 성능을 확인할수 있습니다. 하지만 entity graph reasoning를 사용하는 방법들(ours)은 백본에 상관없이 대체로 이미 높은 성능을 보임으로 이 entity graph reasoning 작업이 유의미함을 확인할수 있습니다.
Analysis on Video-MME Benchmark
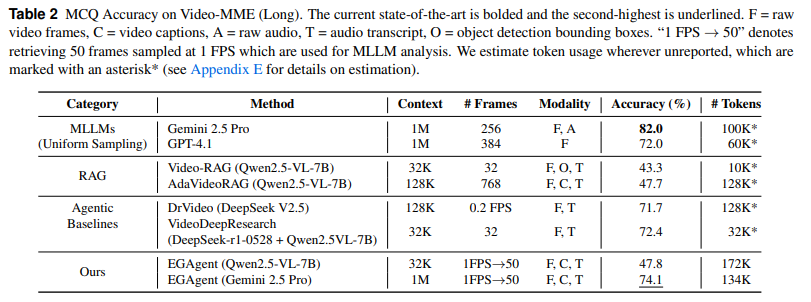
Tabel2) Video-MME의 롱 비디오에 대한 분석 또한 위와 마찬가지로 3개의 카테고리로 나누어 평가를 진행했습니다. ours가 가장 높은 어큐러시를 달성하지는 못했지만 최신 에이전트 방식과 비교해서 높은 성능을 보이며 특히 적은 프레임을 처리하면서도 비교할만한 성능을 보인다는 것을 확인할 수 있습니다
감사합니다.
리뷰 잘 읽었습니다. 궁금한 점이 있어 댓글 남겨두겠스니다!
Planner가 (S_i, T_i, q_i)를 한 번에 생성한다고 했는데, tool 선택 오류가 누적될 때 이를 되돌리는 메커니즘이 있는지 궁금합니다. 예를들어 graph에서 관계를 먼저 찾았어야 하는데 visual search로 가버리면, 이후 단계에서 아까 선택이 틀렸다는 걸 감지하고 재탐색하는 루프가 있을까요?
안녕하세요 찬미님, 좋은 리뷰 감사합니다.
Long video를 위해 entity에 해당하는 요소를 정의해서 그래프로 DB 를 구축해 해결하는 방법으로 이해했습니다. 그러나 QA의 대상은 비디오의 메인 정보가 아닌 다양한 부가정보가 될 수 있다고 생각합니다.
이러한 관점에서 저자들의 실험한 데이터셋이 일반적인 성능을 보이는데 적절한지 궁금합니다.
감사합니다
안녕하세요 찬미님 좋은 리뷰 감사합니다.
엔티티 그래프를 구성할 때 사용하는 오디오 전사와 장면 설명은 데이터셋에 이미 포함된 어노테이션인가요, 아니면 LLM 같은 모델을 활용해 생성한 것인가요? 또한 이에 대한 Ablation 결과가 있는지도 궁금합니다.
감사합니다.
Entity Graph Search에서 데이터 불완전성을 극복하기 위해 ‘Strict-to-relaxed’ 쿼리 전략을 사용한다고 하셨는데,
제약을 점진적으로 완화하여 검색 범위를 넓히면 관련성이 떨어지는 노이즈 데이터까지도 Working Memory에 들어오게 됩니다. VQA Agent가 최종 답변을 생성할 때, 이 누적된 노이즈로 인해 Multi-hop reasoning 과정에서hallucination이 증폭될 위험은 어떻게 다루는지 궁금합니다!