안녕하세요. 오늘은 LLM의 생성 능력과 임베딩 능력을 하나의 모델로 통합하려는 GRIT(Generative Representational Instruction Tuning) 논문을 리뷰하고자 합니다. 최근 MLLM 기반 생성 모델을 검색에도 함께 활용하려는 연구가 늘어나면서, 두 기능을 동시에 수행할 수 있는 구조에 대한 관심이 높아지고 있습니다. 이에 관련 연구를 정리하는 과정에서 이 논문을 다루게 되었습니다.
그럼 바로 리뷰 시작하겠습니다.
1. Introduction
하나의 모델이 다양한 작업을 폭넓게 수행하도록 만드는 것은 인공지능 연구에서 오랜 시간 핵심 과제로 여겨져 왔습니다.최근에는 대규모 언어 모델(LLM)이 이러한 목표를 실현할 수 있는 아키텍처로 활용되고 있습니다. 실제로 많은 연구들은 “모든 텍스트 기반 문제는 결국 생성 문제로 환원될 수 있다”고 주장해왔고, 이에 따라 하나의 생성형 LLM으로 대부분의 작업을 처리하려는 흐름이 이어지고 있습니다. 하지만 정말 모든 텍스트 기반 작업을 생성으로만 해결하기에는 한계가 존재합니다.
clustering이나 retrieval처럼 임베딩을 사용하는 작업은 이러한 관점에서 거의 본격적으로 다뤄지지 않았습니다. 오늘날 검색 엔진, 추천 시스템, 챗봇 등 수많은 실제 응용 시스템은 텍스트 임베딩에 기반하고 있습니다. 즉, 생성 모델이 아무리 강력해도, 임베딩 성능이 좋지 않다면 실제 시스템에서의 활용에는 제약이 생깁니다.
이론적으로는 생성 모델이 숫자 시퀀스를 출력해 임베딩 벡터를 만들 수도 있습니다. 그러나 임베딩은 고차원이며 높은 정밀도를 요구하기 때문에, 이를 생성 방식으로 직접 출력하는 것은 사실상 비현실적입니다. 그래서 보통은 모델의 hidden state를 그대로 임베딩으로 사용합니다. 이미 숫자 텐서이기 때문에 훨씬 자연스럽고 효율적이기 때문입니다. 하지만 문제는 여기서 발생합니다.
현재의 생성형 모델들은 hidden state를 그대로 임베딩으로 사용하면 성능이 좋지 않습니다. 예를 들어 T5는 생성 작업에는 강하지만, 임베딩으로 활용하려면 별도의 파인튜닝이 필요합니다. 그리고 그렇게 되면 원래의 생성 능력을 잃어버리는 문제가 생깁니다. 즉, 생성과 표현 학습(embedding)은 사실상 서로 다른 훈련 패러다임으로 분리되어 발전해왔습니다.
이러한 단절을 해결하기 위해 저자들은 GRIT(Generative Representational Instruction Tuning)를 제안합니다. 핵심 아이디어는 생성과 임베딩을 하나의 모델 안에서 동시에 잘하도록 만드는 것입니다. 이를 위해 GRIT은 기존에 분리되어 있던 두 학습 패러다임을 통합합니다.
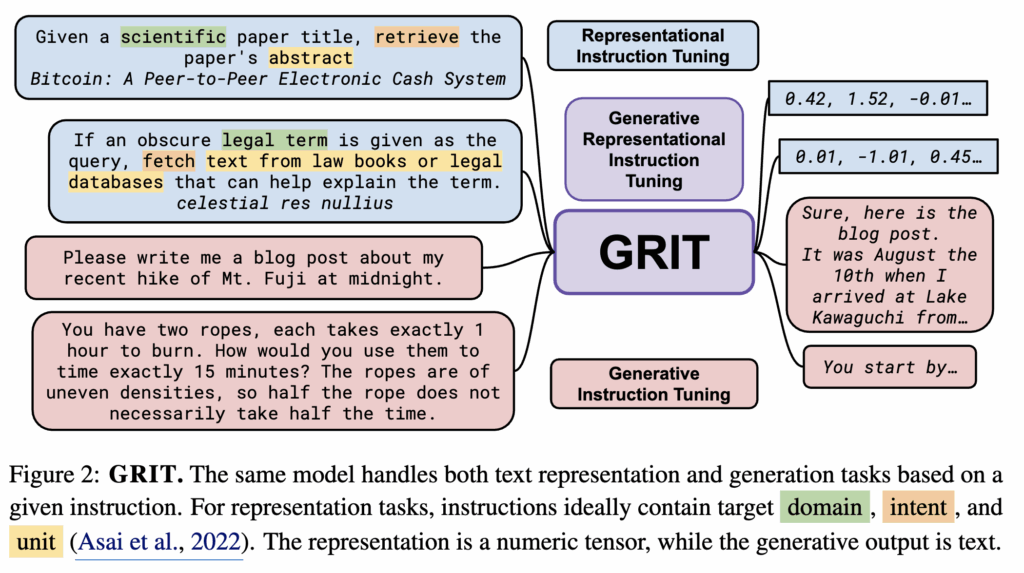
- Generative instruction tuning : 주어진 instruction에 대해 답을 생성하도록 학습
- Representational instruction tuning : 주어진 instruction에 따라 입력을 특정 방식으로 표현(임베딩)하도록 학습
중요한 점은, 모델이 instruction과 서로 다른 loss를 통해 두 작업을 구분하도록 설계했다는 것입니다. 즉, 하나의 모델이지만 내부적으로는 “생성 스트림”과 “표현 스트림”을 구분해 처리할 수 있도록 만든 구조라고 볼 수 있습니다.
저자들은 이 통합이 세 가지 장점을 가진다고 주장합니다.
1. Performance
저자들은 먼저 성능 측면에서의 이점을 강조합니다. GRIT은 단순히 두 기능을 합친 모델이 아니라, 생성 전용 모델과 임베딩 전용 모델 각각의 성능을 유지하면서도 일부 과제에서는 오히려 더 나은 결과를 보인다고 주장합니다. 구체적으로 7B 규모의 모델만으로도 Massive Text Embedding Benchmark에서 높은 성능을 달성하며, 동시에 대형 생성 모델들과 비슷한 생성 능력을 보여줍니다.
또한 MoE(Mixture-of-Experts) 구조를 적용한 모델에서는 추론 시 실제로 활성화되는 파라미터 수를 줄이면서도 성능을 더욱 개선합니다. 이에 sliding window attention을 사용해 입력 길이에 대한 제약 없이 생성과 임베딩을 모두 처리할 수 있다는 점도 함께 언급합니다.
2. Efficiency
두 번째로는 효율성 측면입니다. 현실적인 시스템 환경에서는 생성 모델과 임베딩 모델을 동시에 사용하는 경우가 많습니다. 대표적인 예가 Retrieval-Augmented Generation(RAG)입니다. 이 구조에서는 사용자의 질의와 검색된 문맥을 임베딩 모델과 생성 모델에 각각 통과시켜야 하기 때문에, 전체적으로 네 번의 forward pass가 발생합니다.
하지만 GRIT에서는 생성과 임베딩이 동일한 모델 안에서 이루어지기 때문에 계산을 공유할 수 있습니다. 중간 표현을 캐싱함으로써 중복 연산을 줄일 수 있고, 그 결과 전체 추론 비용을 크게 절감할 수 있습니다. 저자들은 특히 긴 문서 환경에서 60% 이상의 속도 개선이 가능하다고 설명합니다.
3. Simplicity
마지막으로는 시스템 단순성입니다. 현재 상용 API 서비스들은 보통 생성 endpoint와 임베딩 endpoint를 분리해 제공합니다. 이는 모델 자체뿐 아니라, 로드 밸런싱, 메모리 관리, 저장 공간, 서빙 파이프라인 등 인프라 전반을 이중으로 운영해야 한다는 의미입니다.
GRIT은 이 둘을 하나의 모델로 통합함으로써 이러한 구조적 복잡성을 줄일 수 있다고 주장합니다. 단일 모델로 두 가지 요구를 모두 처리할 수 있다면, 시스템 설계와 운영 측면에서 훨씬 간결한 아키텍처를 구성할 수 있기 때문입니다.
정리하면, GRIT은 생성과 표현 구조를 분리하지 않고 통합하려는 아키텍쳐라고 볼 수 있습니다. 구체적인 학습 방식과 손실 설계는 방법론 파트에서 더 자세히 살펴보겠습니다.
2. Methodology
이 절에서는 GRIT이 생성 학습과 표현 학습을 하나의 모델 안에서 어떻게 동시에 다루는지 설명합니다. 핵심은 두 가지 목적 함수 representational objective와 generative objective를 하나의 LLM 위에서 함께 학습시키는 구조입니다.
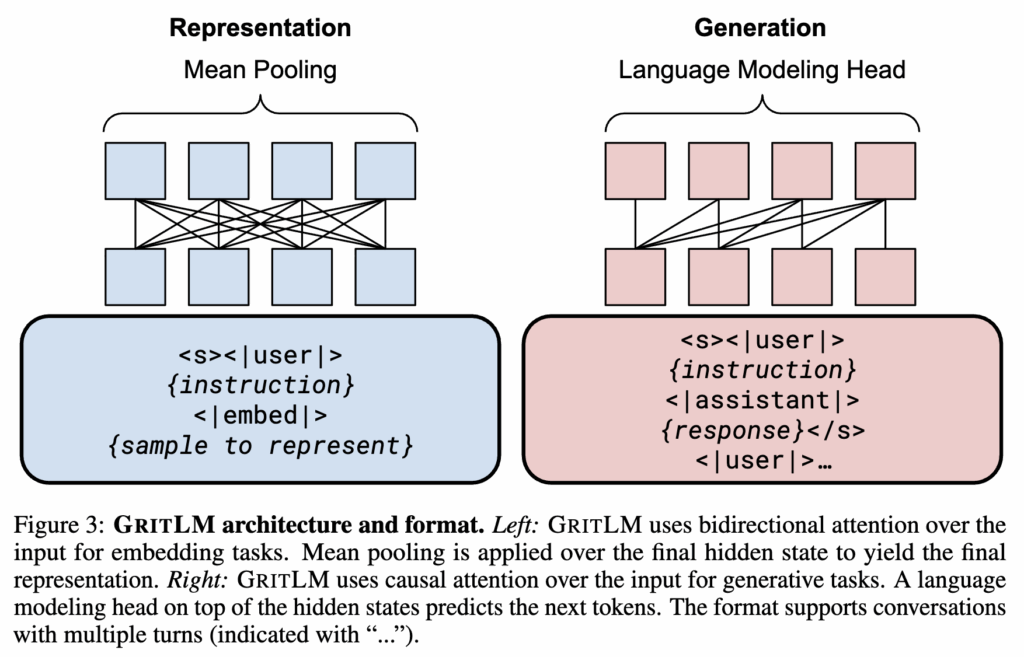
GRIT은 기존에 분리되어 진행되어 온 두 instruction tuning(Representational instruction tuning, Generative instruction tuning) 방식을 하나로 통합합니다.
Representational Objective
먼저 임베딩 학습입니다.
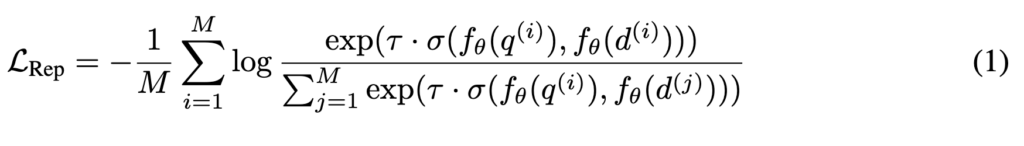
기존 텍스트 임베딩 연구를 그대로 따르며, contrastive learning 기반의 objective를 사용합니다. 수식 (1)은 전형적인 in-batch negative를 사용하는 InfoNCE 구조입니다.
입력은 query q와 document d 쌍이며, 동일한 배치 안에서 positive와 negative를 구성합니다. 모델 fθ는 GRIT LM 이고, temperature τ를 둔 cosine similarity 기반 점수를 사용합니다.
여기서 중요한 설계가 하나 있습니다. GRIT은 bidirectional attention과 mean pooling을 사용해 시퀀스 전체의 hidden state를 평균내어 하나의 embedding을 만듭니다. 이는 일반적인 decoder-only LLM이 causal attention 구조를 사용하는 것과는 다른 구조를 사용하고 있습니다. 왜냐하면 임베딩은 문장 전체의 의미를 요약해야 하기 때문에, 앞뒤 문맥을 모두 볼 수 있는 bidirectional attention이 더 적합하기 때문입니다.
또한 pooling 시 instruction 토큰은 평균에서 제외합니다. 대신 self-attention 구조상 이 토큰들은 여전히 표현 형성에 영향을 주기 때문에 직접 평균에는 포함하지 않고 간접적으로 representation에 반영됩니다.
Generative Objective
다음은 생성 학습입니다.
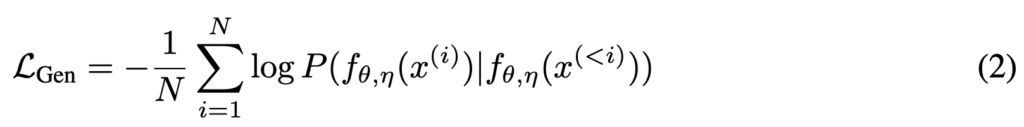
이 부분은 전형적인 language modeling objective입니다. 모델은 다음 토큰을 예측하도록 학습되며, loss는 생성된 response 토큰에 대해서만 계산됩니다.
여기서 생성 loss를 구하는 방법에는 여러가지가 있습니다. 같은 language modeling objective를 사용하더라도, 이를 배치 단위에서 어떻게 평균내느냐에 따라 모델의 생성 성향이 달라질 수 있기 때문입니다.
먼저 sample-level aggregation은 배치 내 각 샘플에 동일한 가중치를 부여하는 방식입니다. 즉, 한 문장이 5토큰이든 100토큰이든 하나의 샘플로서 동일한 비중을 갖습니다. 이 방식은 instruction tuning에서 흔히 사용되는데, 분류 태스크에서는 비교적 안정적인 성능을 보인다고 합니다. 다만 이러한 방식은 상대적으로 짧은 응답을 선호하는 방향으로 모델을 유도할 수 있다는 점이 단점으로 작용합니다.
반면 token-level aggregation은 각 토큰에 동일한 가중치를 부여합니다. 따라서 토큰 수가 많은 샘플이 더 큰 영향을 미치게 되고, 자연스럽게 모델이 더 긴 응답을 생성하는 방향으로 학습될 가능성이 있습니다. 특히 AlpacaEval과 같이 사람이나 모델 기반 평가를 사용하는 벤치마크는 긴 답변을 선호하는 경향이 있다고 하여 loss 구현 방식 자체가 평가 결과에까지 영향을 줄 수 있다고 합니다.
이 두가지 loss구현 방식에는 각 장단점이 있기에 최종적으로는 두 방식을 섞는 전략을 사용합니다. 예를 들어 배치를 일부 subset으로 나누어 token-level loss를 적용한 뒤, 그 subset 단위로 동일 가중치를 주는 식입니다.
Unified Objective
최종 loss는 다음과 같이 두 objective의 가중합입니다.

3. Experiments
이제 실험 부분을 살펴보겠습니다. 저자들은 사전학습된 Mistral 7B와 Mixtral 8×7B를 베이스 모델로 사용합니다. 학습 데이터는 크게 두가지를 사용합니다. 임베딩 학습에는 E5를 기반으로 하되, 여기에 과학 논문 데이터인 S2ORC를 추가해 확장한 버전(E5S)을 사용합니다. 생성 학습에는 Tülu 2 데이터를 사용합니다.
평가에서는 임베딩 성능은 MTEB의 56개의 데이터셋, 생성 성능은 Tülu 2 논문의 평가 프로토콜을 따르되, HumanEval 대신 HumanEvalSynthesize 변형을 사용합니다.
Main Results
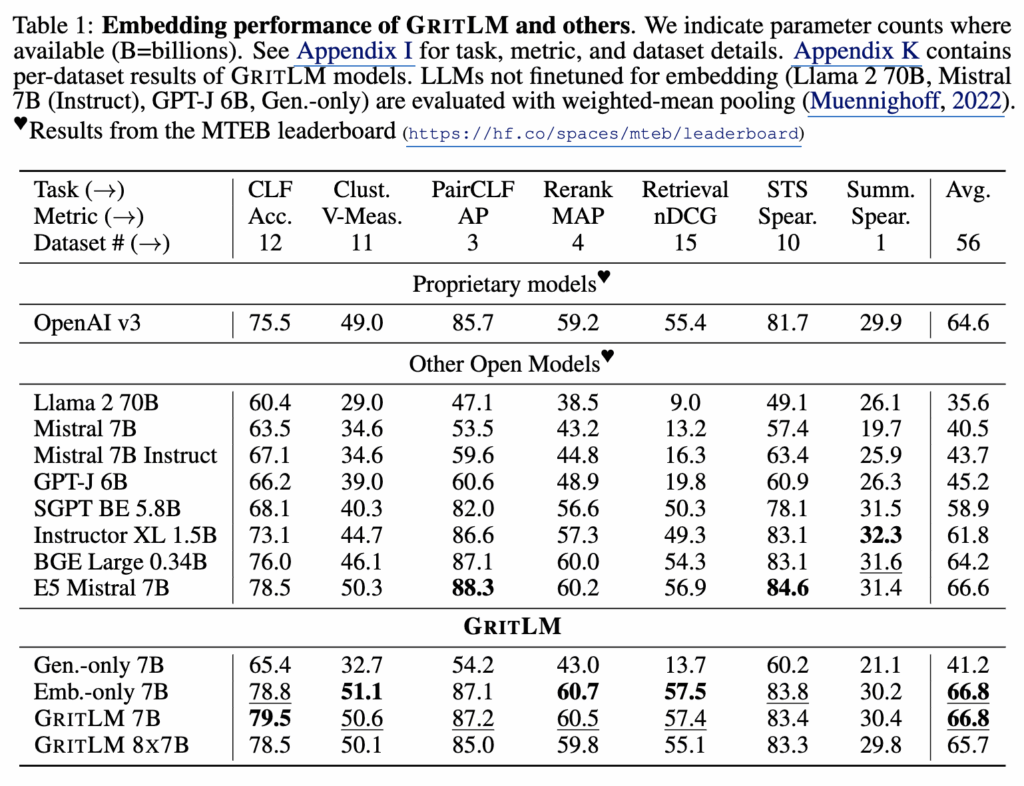
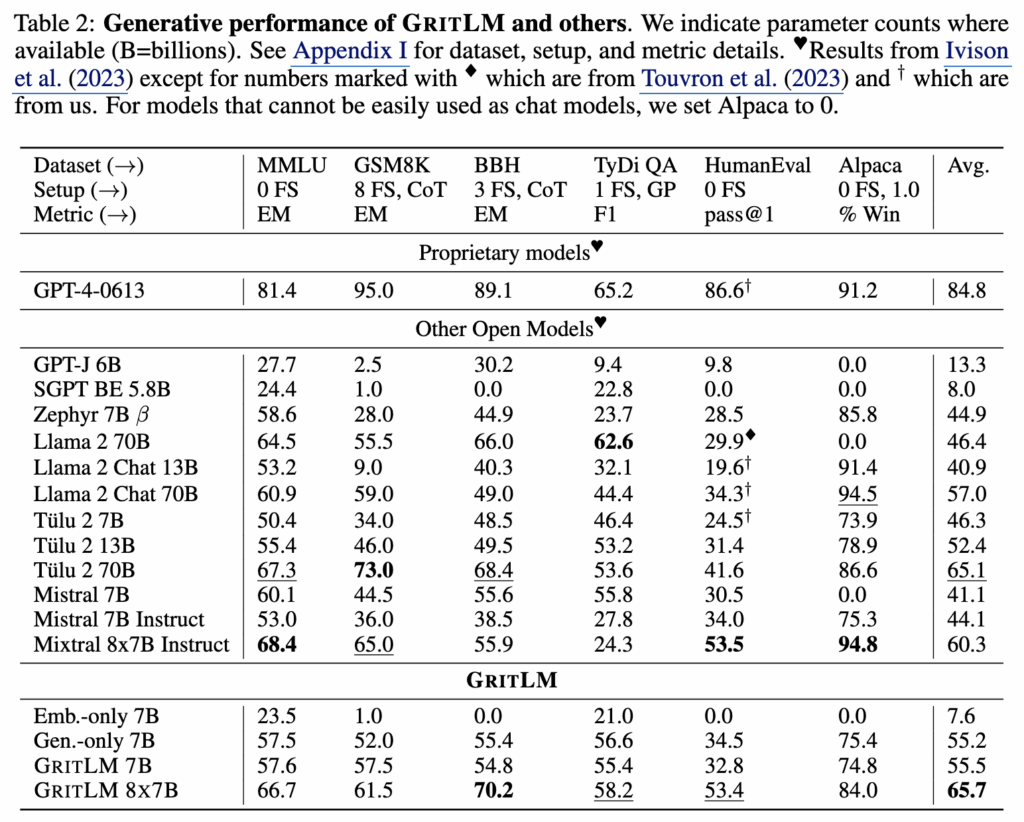
Table 1과 Table 2에서 GRIT LM 7B, GRIT LM 8×7B, 그리고 embedding-only 및 generative-only 변형 모델을 함께 비교합니다. 결과를 보면 GRIT LM 7B는 Massive Text Embedding Benchmark(MTEB)에서 여러 기존 오픈 모델 보다 좋은 성능을 보입니다. 다만 저자들은 Llama3, NV-Embed 등 성능이 더 좋은 모델들도 존재한다는 점도 인정을 하면서 GRIT이 모든 모델 중 최고라는 것은 아니고, 임베딩과 생성을 동시에 수행하는 모델 중에서는 강력한 성능을 보인다는 점을 강조합니다.
Table 1에 따르면 Llama 70B를 임베딩 용도로 사용할 경우 MTEB 점수는 35.6에 불과합니다. 반면 GRIT LM은 이 점수를 거의 두 배 가까이 끌어올립니다. 동시에 Table 2의 생성 성능에서는 Llama 70B보다 20% 이상 높은 결과를 보입니다. 여기서 저자들은 대형 생성 모델을 단순히 임베딩에 재활용하는 방식으로는 충분하지 않으며, 두 목적을 함께 최적화해야 한다고 강조합니다.
또한 embedding-only와 generative-only 변형 모델의 결과도 중요한 근거로 제시됩니다. embedding-only 모델에 LM head를 다시 붙여 생성 평가를 수행하면 MMLU에서 25.0 수준, 즉 랜덤 베이스라인에 가까운 성능이 나옵니다. 반대로 generative-only 모델의 임베딩 성능은 Table 1에서 41.2점에 머뭅니다. 이는 두 objective를 분리해 학습하면 상호 전환이 거의 이루어지지 않음을 보여줍니다. 결국 GRIT의 공동 최적화(joint optimization)가 두 성능을 동시에 확보하는 데 핵심이라는 주장입니다.
4. Reranking with GRIT
검색 기반 과제에서는 보통 두 단계를 거칩니다. 먼저 임베딩 기반으로 빠르게 후보 문서를 추리고, 그 다음 상위 k개의 문서를 더 정교한 방식으로 다시 정렬(reranking)하는 구조입니다. 전자는 속도를, 후자는 정확도를 담당한다고 보시면 됩니다.
기존 방식에서는 이 두 단계를 서로 다른 모델로 처리하는 경우가 일반적이었습니다. 첫 단계는 Bi-Encoder 구조를 사용해 쿼리와 문서를 각각 한 번씩만 통과시키기 때문에 연산량이 선형적으로 증가합니다. 반면 reranking 단계는 Cross-Encoder 방식으로, 쿼리와 각 문서를 함께 모델에 넣어 점수를 계산합니다. 이 경우 쿼리–문서 쌍마다 forward를 수행해야 하므로 계산량이 크게 증가합니다. 특히 문서 수가 많아질수록 비용이 급격히 늘어나기 때문에, 이 방식은 보통 상위 k개 문서에만 적용됩니다.
LLM을 활용한 reranking도 기본 원리는 같습니다. 각 문서를 쿼리와 함께 입력하고, 로그 확률을 이용해 점수를 계산하는 방식입니다. 최근 연구들은 여기에 instruction을 활용해 LLM이 직접 순위를 생성하도록 하는 접근도 제안하고 있습니다. 하지만 기존 연구들이 임베딩 모델과 reranking 모델을 분리해 사용했다면, GRIT은 하나의 모델로 두 단계를 모두 수행할 수 있습니다. 즉, 같은 모델이 먼저 임베딩 기반으로 top-k 문서를 뽑고, 이어서 생성 능력을 활용해 해당 문서들을 다시 정렬합니다.
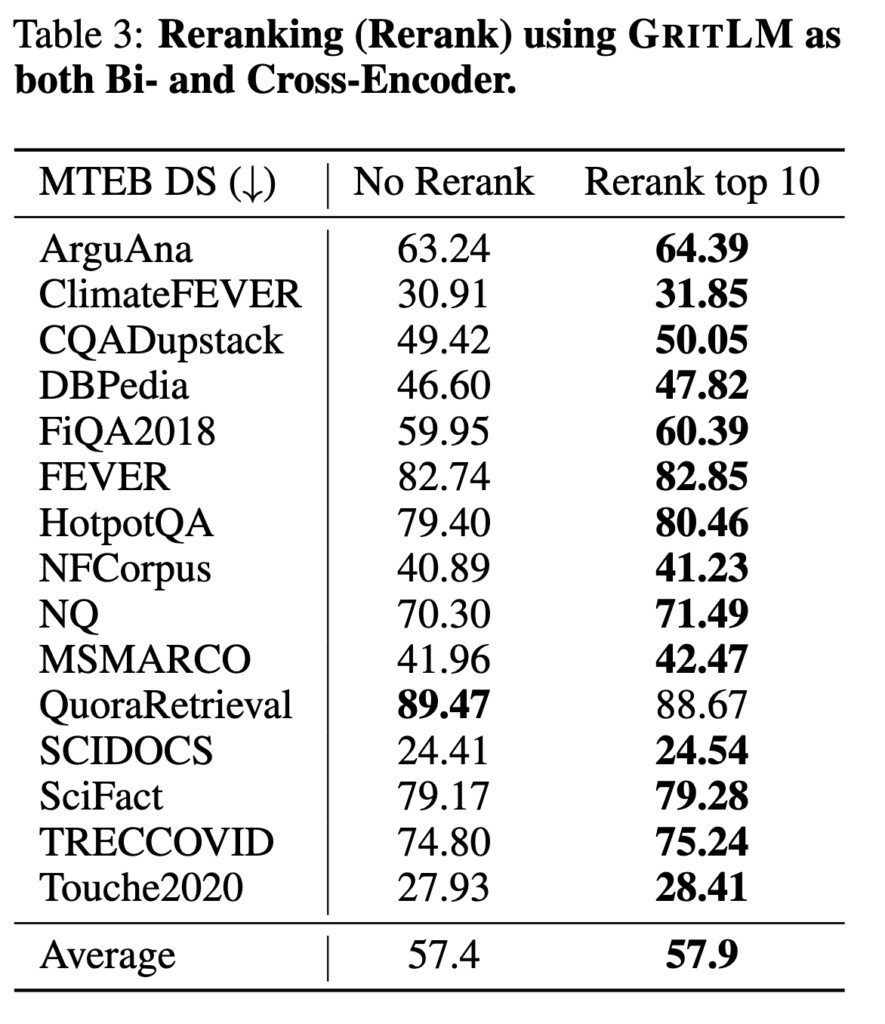
Table 3에서는 GRIT LM 7B가 자신의 임베딩 단계에서 선택한 상위 10개 문서를 다시 reranking했을 때의 성능을 보여줍니다. 결과를 보면 대부분의 retrieval 데이터셋에서 reranking을 적용했을 때 임베딩 단독 사용 대비 성능이 향상됩니다. 즉, 생성 능력을 후처리 단계에 활용하는 것이 실제로 유의미한 개선으로 이어진다는 점을 보여줍니다.
5. RAG WITH GRIT
GRIT은 임베딩과 생성을 하나의 모델로 통합했기 때문에, Retrieval-Augmented Generation(RAG) 구조 역시 단순화할 수 있습니다. 핵심 아이디어는 같은 모델을 사용하여 중복 연산을 줄이는 것입니다. 이를 위해 저자들은 caching 전략을 제안합니다.
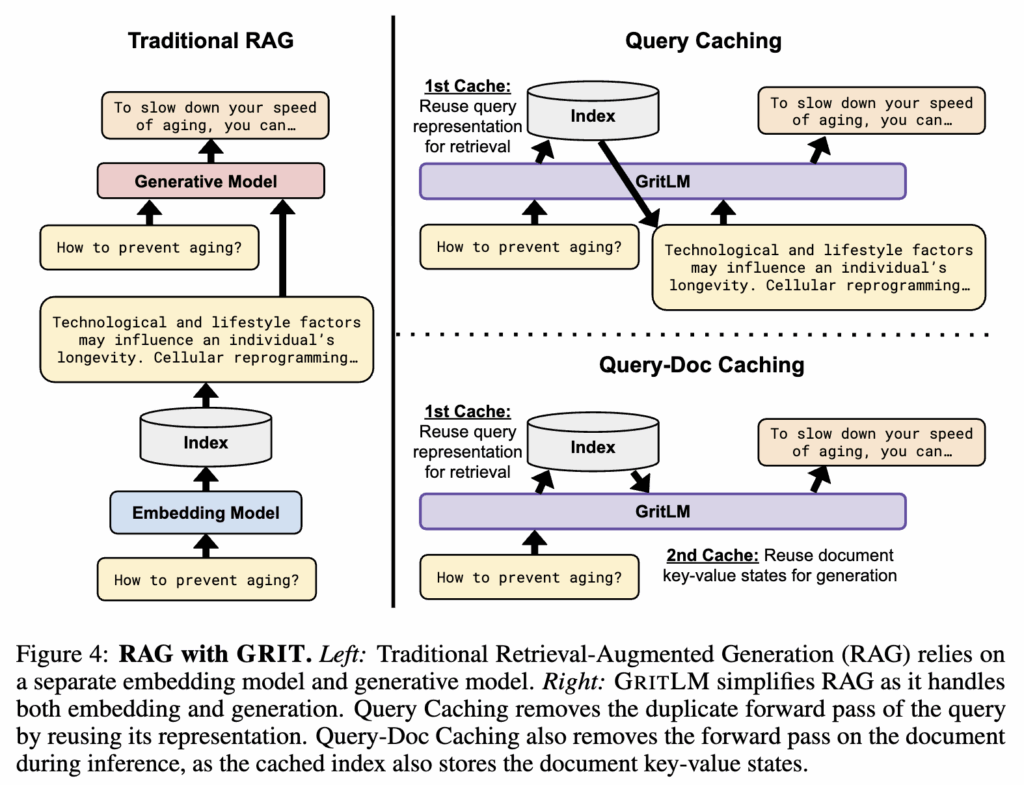
먼저 Query Caching입니다. 기존 RAG에서는 쿼리를 임베딩 모델에 한 번 통과시키고, 이후 생성 모델에 다시 한 번 통과시킵니다. 즉, 동일한 쿼리에 대해 두 번 forward를 수행합니다. 하지만 GRIT은 임베딩과 생성이 동일한 모델이기 때문에, 임베딩 단계에서 계산된 key-value states를 저장해두고 이를 생성 단계에서 재사용할 수 있습니다. 이 경우 쿼리에 대한 forward 한 번을 절약하게 됩니다.
다음은 Doc Caching입니다. 여기서는 쿼리가 아니라 문서를 캐싱합니다. 인덱스를 구축할 때 각 문서의 임베딩뿐 아니라 key-value states도 함께 저장해둡니다. 추론 시에는 임베딩 유사도로 문서를 찾되, 텍스트를 다시 통과시키는 대신 저장된 key-value states를 불러와 바로 생성 단계에 입력합니다. 이렇게 하면 in-context 문서마다 필요한 forward pass를 줄일 수 있습니다. 다만 저장 비용이 크게 증가합니다. 문서 텍스트는 더 이상 필요 없지만, 대신 크기가 큰 key-value states를 저장해야 하기 때문입니다. 예를 들어 268만 개 문서를 7B 모델 기준으로 저장하면 약 30TB의 key-value states가 필요합니다. 정리하면 Doc Caching은 추론 시 연산 비용을 크게 줄일 수 있는 대신, 대규모 key-value states를 저장해야 한다는 점에서 저장 비용과의 trade-off를 갖는 방식이라고 정리할 수 있습니다.
실험은 Natural Questions 데이터셋을 사용해 진행되며, 268만 개 문서 인덱스를 기반으로 평가합니다.
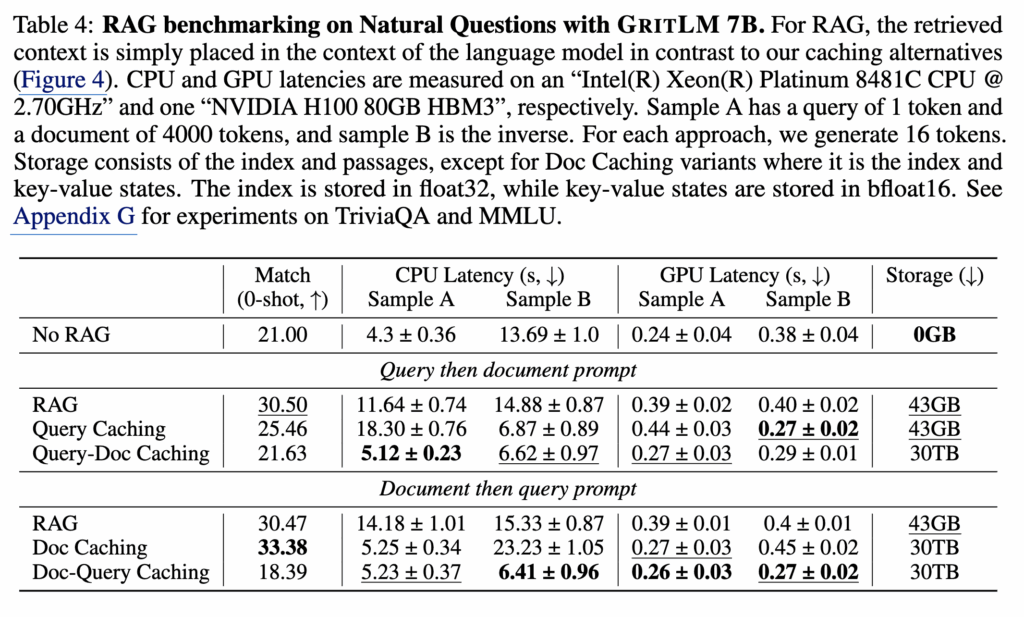
결과를 보면 전통적인 RAG가 No RAG baseline보다 확실히 성능이 높습니다. 이는 인덱스가 실제로 유의미하다는 점을 보여줍니다. 이론적으로 Query Caching과 Doc Caching은 RAG와 동일한 성능을 낼 수 있어야 하지만, 실제로는 차이가 발생합니다. 그 이유로 저자들은 두 가지를 제시합니다. 첫째는 attention 구조의 불일치입니다. 임베딩 단계에서는 bidirectional attention을 사용하지만, 생성 단계는 causal attention을 사용합니다. 둘째는 입력 포맷 차이입니다. 임베딩 포맷으로 구성된 쿼리를 생성 단계에서 그대로 사용하는 것이 성능 저하를 유발할 수 있습니다. 이 두 요인 때문에 Query Caching은 RAG 대비 성능이 다소 하락합니다. 다만 No RAG보다는 여전히 낫기 때문에, 속도와 성능 사이의 trade-off 문제로 볼 수 있습니다.
반면 Doc Caching은 오히려 약간의 성능 향상을 보입니다. 저자들은 문서는 완전한 이해보다는 훑어보는 수준으로도 충분할 수 있기 때문에, key-value state가 약간 왜곡되어도 큰 문제가 없었을 가능성을 제시합니다. Query-Doc과 Doc-Query Caching은 실험에서 거의 No RAG 수준에 머무르며, attention mismatch가 더 심해진 결과로 해석됩니다.
속도 측면에서는 caching이 특히 긴 시퀀스에서 큰 이점을 보입니다. 4000토큰 기준으로 Query Caching은 CPU에서 54%, GPU에서 33% 빠르며, Doc Caching은 각각 63%, 31% 빠릅니다.
정리하면 GRIT은 RAG 구조에서 중복 연산을 줄일 수 있는 구조적 장점을 가지며, 특히 긴 입력에서 속도 이득을 가져갈 수 있습니다. 다만 attention 구조 불일치와 포맷 차이로 인해 완전한 성능 보존은 어려우며, 이를 해결하려면 추가적인 RAG 파인튜닝이 필요할 수 있다는 점입니다.
의철님 안녕하세요. 좋은 리뷰 감사합니다.
뭔가 회사에서 하던 프로젝트를 성능 찍어서 논문으로 제출한 느낌인거같네요
제가 리뷰 중간에 놓친것인진 모르겠는데, 제안하는 joint loss로 학습하는 데이터셋 규모는 어느정도인건가요?
그리고 representation contrastive learning 할 때 한 문서의 길이는 어느정도인지나 내용끼리 어느정도 차이가 있는건지 궁금합니다. (완전 다른 주제의 문서라 다 뭉뚱그려 contrastive learning 해도 괜찮은 수준인지)
안녕하세요 현우님 좋은 질문 감사합니다.
논문 설정 기준으로 보면, joint loss로 학습할 때 generative 데이터는 약 32만, embedding 데이터는 대략 190만 샘플 정도를 사용합니다.
또한 Representation contrastive learning에서의 입력 길이는 query가 256 tokens, document는 학습 시 최대 2048 tokens까지 사용하며, 실제 평가에서는 주로 512 tokens 이하가 사용됩니다.
그리고 마지막으로 내용 차이에 대해서는 논문에서 사용한 E5 기반 데이터는 다양한 태스크를 포함하고 있고 이 데이터셋에는 hard negative를 포함하고 있습니다. 그래서 차이는 다양한 수준으로 존재한다고 볼 수 있겠습니다.
감사합니다.