지난 리뷰에서와 동일하게 이번에도 Universal Multimodal Retrieval 페이퍼를 리뷰해보겠습니다.
- Venue: CVPR 2025
- Authors: Yikun Liu, Pingan Chen, Jiayin Cai, Xiaolong Jiang, Yao Hu, Jiangchao Yao, Yanfeng Wang, Weidi Xie
- Affiliation: Shanghai Jiao Tong University, Xiaohongshu Inc.
- Title: LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
- Code: GitHub
1. Introduction
최근 멀티모달 정보 검색은 CLIP 같은 VLP 의 성공을 바탕으로 빠르게 발전했지만, 동시에 retrieval 태스크 자체가 훨씬 복잡해졌습니다. 예전처럼 텍스트↔이미지 한 가지 형태만 잘 맞추는 수준을 넘어서, composed image retrieval (ex. 이 이미지를 이렇게 바꾼 결과를 찾아라), long-text-to-image retrieval (긴 문서로 이미지 찾기), image/question-to-multimodal document retrieval (이미지+질문으로 문서 검색)처럼 입출력 모달리티가 뒤섞인 태스크들이 늘어나게 되었죠
문제는 이런 복잡도가 커질수록 기존 접근이 태스크별 fine-tuning으로 흘러가기 쉽다는 점이었습니다. 각 태스크에 맞춰 모델을 따로 튜닝하는 방식이 많아지면서, 여러 태스크를 한 번에 커버하는 범용 멀티모달 임베딩을 만들기는 여전히 어렵다고 여겨졌습니다.
또한 저자들은 dual-encoder(VLP)의 구조적 한계도 함께 언급했는데요. dual-encoder는 이미지와 텍스트를 각각 인코딩해 정렬하는 데 강점이 있지만, 이미지-텍스트가 interleaved로 섞이거나 텍스트 자체가 복잡해지는 상황에서는 불리해질 수 있다고 보았습니다. 결국 다양한 query 형태를 통합 처리할 수 있는 더 범용적인 검색기가 필요하다는 문제의식으로 이어지게 되었죠
이런 배경에서 본 논문은 VLP 중심 흐름에서 벗어나, Large Multimodal Model(LMM)을 retrieval로 재활용하는 방법을 제안했습니다. LMM이 이미 갖고 있는 강한 언어 이해와 멀티모달 추론 능력을 retrieval과 reranking에 붙이면, 복잡한 멀티모달 retrieval 태스크들을 같은 틀로 통합할 수 있지 않나 에서 출발한 것입니다. 특히 학습에서 보지 못한 unseen retrieval task로도 추가 학습 없이 확장될 가능성을 강조했습니다.
따라서 저자는 LMM을 기반으로 한 Universal Retriever(LamRA-Ret) 와 Universal Reranker(LamRA-Rank) 를 함께 제시했습니다. 전체 파이프라인은 임베딩 기반 1차 retrieval로 후보를 찾고(top-K), reranker가 이를 다시 정렬하는 구조를 따릅니다. 이때 query와 candidate가 이미지/텍스트/혼합 포맷이어도 동일한 정의로 처리한다는 점이 핵심입니다
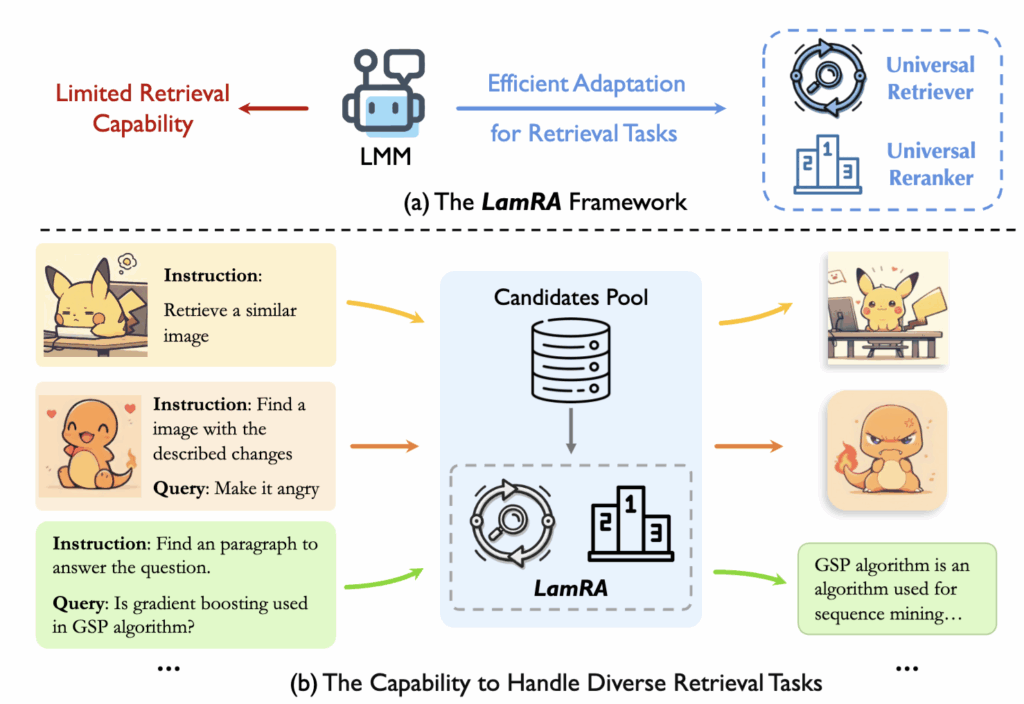
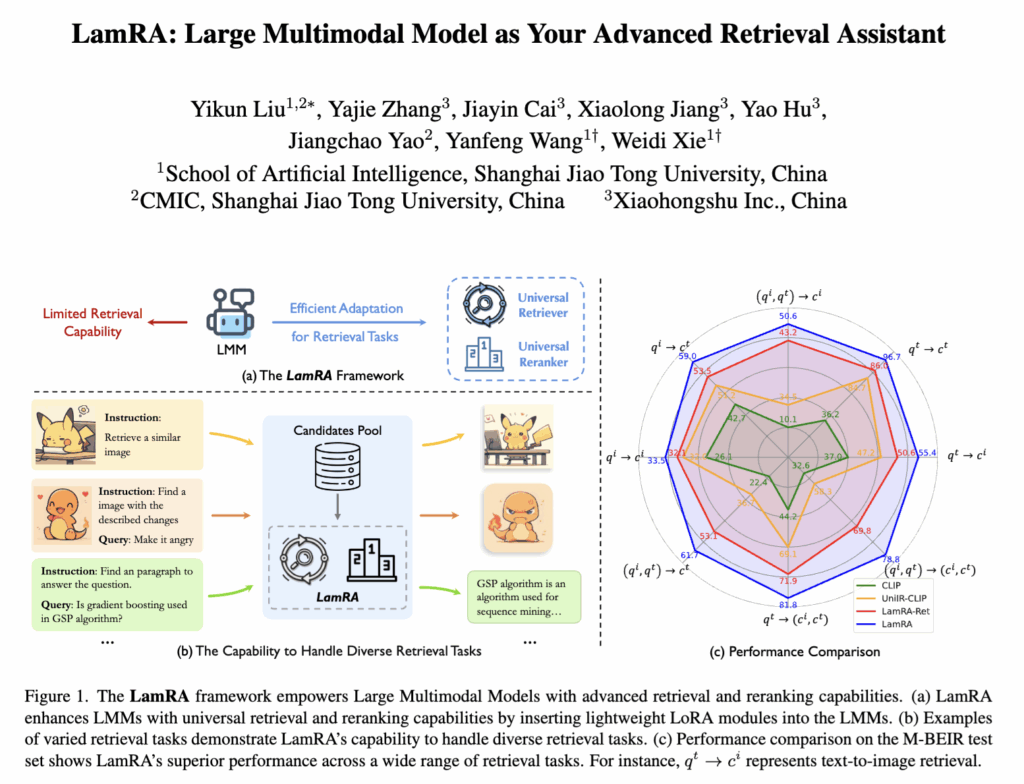
상단 Figure 1에서 제안하는 LamRA의 큰 그림을 확인할 수 있는데요. 다양한 retrieval 요청을 태스크별 모델로 쪼개지 않고, 하나의 LMM 기반 프레임워크로 처리하는 retrieval assistant를 만드는 것이었습니다. 이제 컨셉적으로 이해하셨을 것 같으니, 본격적인 방법론 설명으로 들어가보겠습니다.
2. Method
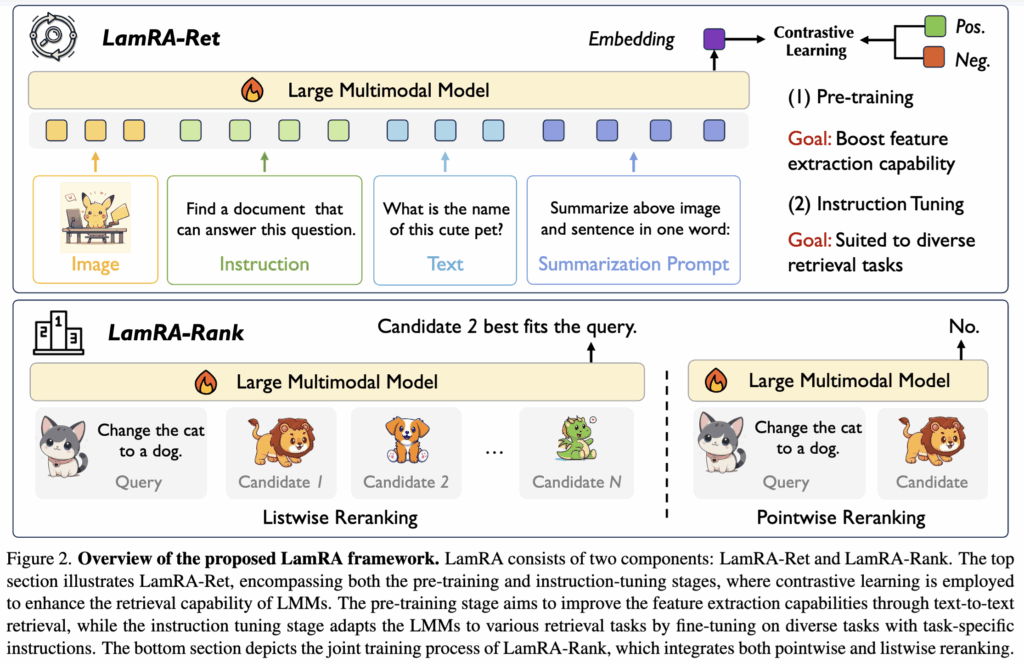
본격적인 방법론 설명에 앞서, LamRA의 전체 흐름은 Figure 2 먼저 살펴보겠습니다. LamRA는 (1) 임베딩 기반으로 빠르게 후보를 뽑는 LamRA-Ret과, (2) 상위 후보를 더 정교하게 재정렬하는 LamRA-Rank 두 단계로 구성됩니다. 위쪽은 retrieval을 위한 2-stage 학습(Pre-training → Instruction tuning), 아래쪽은 reranking을 위한 pointwise+listwise joint training 입니다.
2.1 Problem Formulation: Universal retrieval → reranking
query q는 이미지/텍스트/혹은 interleaved image-text가 될 수 있고, 후보 집합 \Omega=\{c_1,\dots,c_N\}의 각 candidate도 동일하게 다양한 포맷을 가질 수 있습니다. 그리고 LMM으로 query와 candidate의 임베딩을 각각 뽑은 뒤 cosine similarity로 1차 랭킹을 만들고, 여기서 얻은 top-K를 reranker로 다시 정렬하는 구조 입니다.
이를 통해, 태스크가 무엇이든 간에 결국은 (임베딩 기반 retrieval) → (reranking) 이라는 동일한 파이프라인으로 묶이게 됩니다.
2.2 Architecture & Feature Extraction
여기서 핵심은 생성형 LMM에서 retrieval용 embedding을 어떻게 뽑을 것인가 입니다. 기존 dual-encoder는 애초에 retrieval을 위해 학습된 모델이라 입력을 넣으면 바로 embedding이 나오지만, LMM은 기본적으로 다음 단어를 예측하는 생성 모델이라 retrieval에 바로 쓸 “임베딩 헤드”가 따로 존재하지 않습니다. 그래서 LMM을 retriever로 쓰려면, 어떤 지점의 hidden state를 embedding으로 정의할지부터 새로 정해야 했습니다.
저자들은 이를 위해 Explicit One-word Limitation(EOL)이라는 프롬프트를 사용했습니다. 입력에 따라 프롬프트는 아래와 같이 작성하였다고 합니다,
이미지<image> Summarize above image in one word <emb>
텍스트<text> Summarize above sentence in one word <emb>
혼합 입력<image_1> <text_1> ... <image_i> <text_j> Summarize above image and sentence in one word <emb>
이때 “한 단어로 요약”을 강제하면, 모델이 입력 내용을 하나의 압축된 의미로 모으는 방향으로 representation을 만들게 되고, retrieval에 쓸 수 있는 비교적 일관된 embedding 정의를 만들 수 있다고 본 것이죠 (실제로 자주 쓰이는 방법이기도 합니다) 마지막으로 embedding으로는, <emb> 토큰 바로 직전의 마지막 hidden state를 사용했습니다.
2.3 Training for Retrieval
LamRA-Ret은 retrieval 능력을 단계적으로 키우는 2-stage 학습을 사용했습니다.
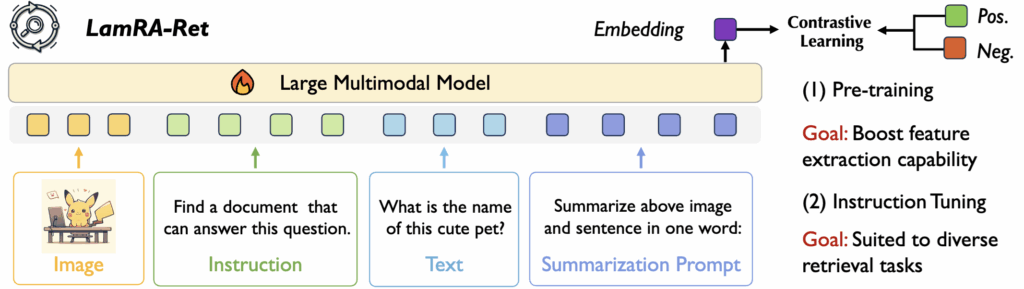
Stage-I: Adapting LMMs for Retrieval Tasks.
먼저 Stage-I 에서는 LMM이 원래 next-token prediction 같은 생성 목적에 최적화되어 있어서 retrieval 성능이 낮을 수 있습니다. 따라서 상단 그림 오른쪽에 써있는 것처럼, feature 추출 능력을 향상시키기위해 text-to-text retrieval 형태로 먼저 학습시켰습니다. 이를 위해, NLI (Natural Langauge Inference) 텍스트 쌍 데이터로 LoRA를 학습하여 retrieval에 적합한 표현을 만들었습니다.
Stage-II: Instruction Tuning for Universal Retrieval.
Stage-II에서는 M-BEIR(8 tasks, 10 datasets)로 multimodal instruction tuning을 수행했습니다. 이때 태스크별로 “retrieve a similar image” 같은 task-specific instruction을 붙여, 다양한 retrieval 형태를 하나의 LMM에 넣어 학습시키는 방식이었습니다.
이 때 학습 objective는 두 stage 모두 contrastive learning(InfoNCE)를 사용했다고 합니다.
2.4 Training for Reranking
LamRA-Rank는 “top 후보들 사이에서 미세한 차이를 가려내는 능력”을 목표로 했고, 이를 위해 먼저 LamRA-Ret을 retriever로 사용해 top-100 후보를 뽑아 hard negative로 활용했다고 합니다.
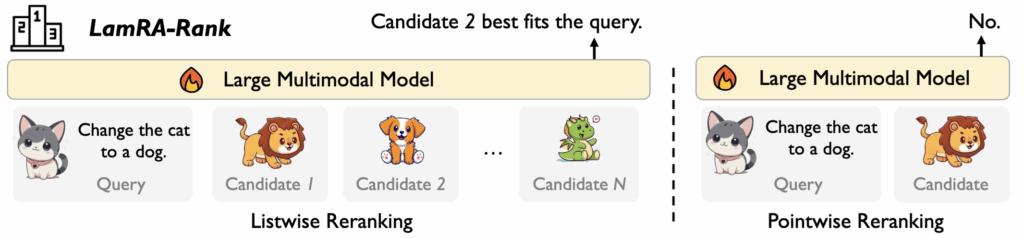
그리고 학습은 pointwise와 listwise를 같이 진행하였습니다.
Pointwise
query에 대해 정답 c_{pos}와 top-100에서 뽑은 negative c_{neg}를 구성하고, 모델이 정답에는 “YES”, negative에는 “NO”를 출력하도록 학습했. 점수는 “YES”가 나올 확률로 해석했고, loss는 cross-entropy를 사용하였습니다
Listwise
negative를 2~5개 뽑아 섞고, 정답을 임의 위치에 끼워 넣은 뒤, 모델이 정답의 위치 번호를 직접 출력하도록 학습했습니다. 역시 cross-entropy로 학습했고, 최종 loss는 pointwise+listwise의 가중합으로 정의햤다고 합니다.
결과적으로 LamRA-Rank는 “후보 하나씩 판단하는 방식(pointwise)”과 “후보 묶음에서 상대 순서를 고르는 방식(listwise)”를 모두 학습한 구조로 정리할 수 있을 것 같네요
2.5 Inference Pipeline
추론 단계에서는 LamRA-Ret으로 모든 후보의 cosine similarity 점수 S_{ret}를 계산해 top-K를 만든 뒤, LamRA-Rank로 reranking 점수 S_{rank}를 얻었습니다. pointwise를 쓰면 top-K 각각을 따로 넣어서 K번 inference를 하고, listwise를 쓰면 top-K를 한 번에 넣어 가장 적합한 후보의 번호를 출력하는 방식이라고 하네요,.
마지막으로 두 점수를 가중합 S=\alpha S_{ret} + (1-\alpha)S_{rank} 으로 합쳐 최종 순위를 만듭니다 여기서 \alpha는 하이퍼파라미터고, LamRA-Ret과 LamRA-Rank를 합친 전체가 바로 LamRA가 되죠
3. Experiments
3.1 Experimental Setup
3.1.1 Dataset & Evaluation
앞서 설명한대로, 학습 시 LamRA-Ret의 Stage-I에는 NLI 데이터셋을 사용했고, Stage-II instruction tuning에는 M-BEIR을 사용했습니다. M-BEIR은 8개의 retrieval task와 10개 데이터셋으로 구성되어 있고, 학습 샘플 규모는 1.1M이라고 합니다. 평가 지표로는 retrieval 태스크에서는 Recall@K, Image-Text Matching(ITM)은 Accuracy를 사용했습니다.
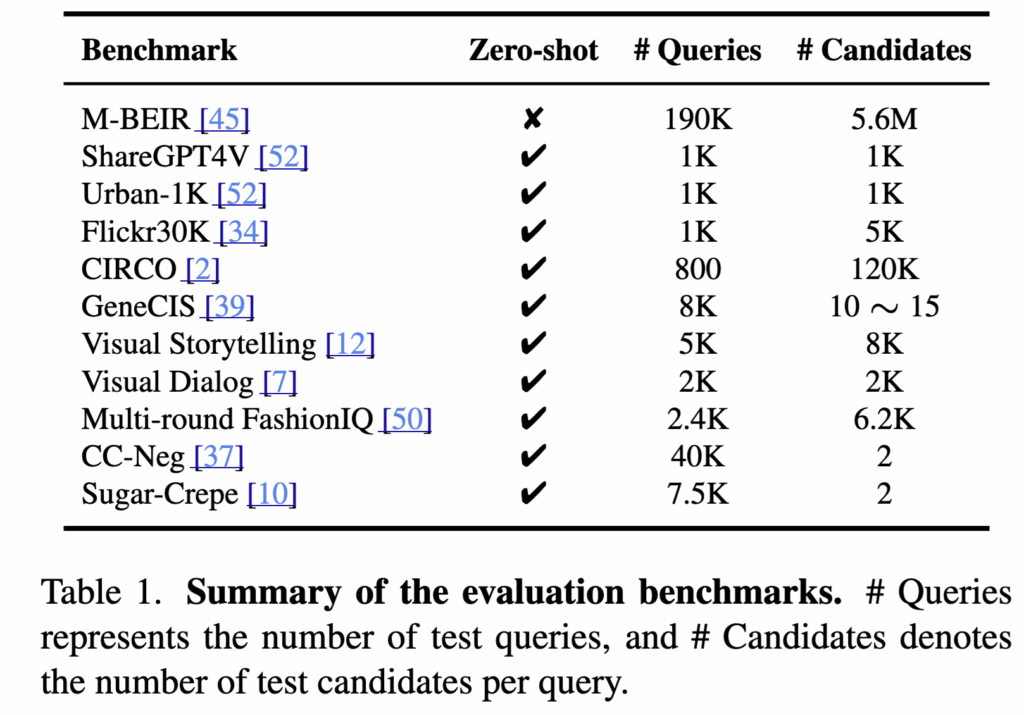
상단 Table 1에서 평가 벤치마크(쿼리 수/후보 수)가 정리되어 있고, M-BEIR 외에도 ShareGPT4V, Urban-1K, CIRCO, Visual Dialog 등 총 10개 unseen dataset에 대해 제로샷 평가를 추가로 수행하였습니다.
3.1.2 Experiment settings & Baseline
실험은 크게 세 가지로 진행되었습니다.
- 일부 태스크를 학습에서 제외(held-out)하고, 제외된 태스크에서 성능을 보는 unseen task generalization 평가
- M-BEIR의 8개 태스크 전체로 학습하고 M-BEIR test set에서 성능을 보는 세팅(“다양한 태스크를 커버하나?”)
- 학습에 없던 unseen dataset 10개로 제로샷 일반화 평가
구현은 기본적으로 Qwen2-VL-7B를 사용했고, vision side는 고정한 채 LLM 쪽만 LoRA로 fine-tuning했다고 했습니다. 또한 M-BEIR 평가에서는 top-50 reranking(기본 pointwise), unseen dataset에서는 top-10 reranking을 적용합니다.
3.2 Main Results on M-BEIR
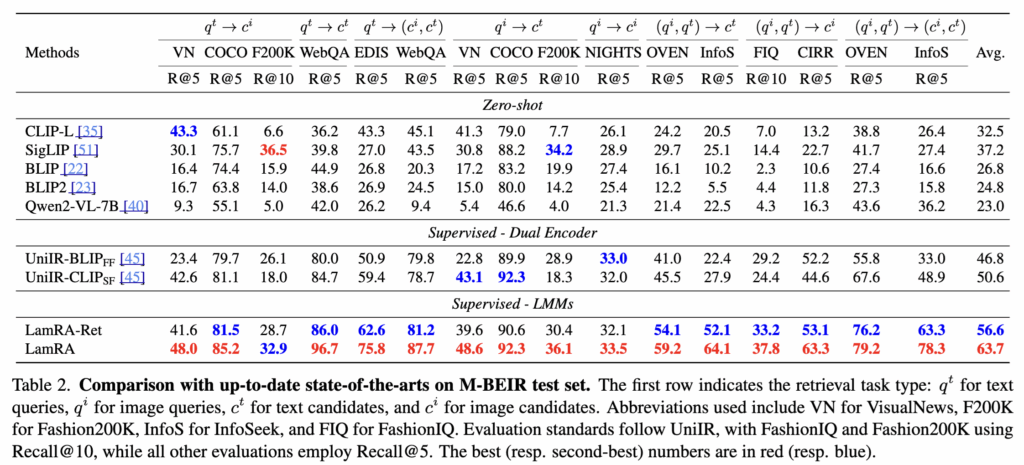
Table 2가 이 논문의 메인 결과라고 봐도 될 것 같습니다. 여기서는 입력/출력 포맷이 서로 다른 16개 M-BEIR retrieval task를 한 번에 묶어서 비교했고, LamRA-Ret과 LamRA(=reranking 포함)가 전반적으로 강한 성능을 보였습니다.
특히, 복잡한 태스크에서 dual-encoder 대비 격차가 커졌는데, 예를 들어 InfoSeek의 text-image-to-text retrieval에서 LamRA-Ret이 UniIR-CLIP보다 Recall@5가 크게 높았고, CIRR composed image retrieval에서도 유의미한 개선을 보였습니다.
reranking이 평균 성능을 확실히 끌어올린 것도 확인할 수 있습니다. LamRA는 LamRA-Ret 대비 평균 +7.1 point 향상되었고, 기본 Qwen2-VL-7B를 그냥 retrieval에 쓰면 평균 23.0인데 LamRA로 63.7까지 올라가기도 했다며 프레임워크 효과를 강조하였습니다.
3.3 Unseen Dataset Generalization
아래 Table 4에서는 학습에 포함되지 않은 10개 데이터셋에 대해 제로샷 성능입니다. 전체적으로 LamRA-Ret이 강했고, LamRA(=reranking 포함)는 여기서도 추가 개선을 가져왔습니다
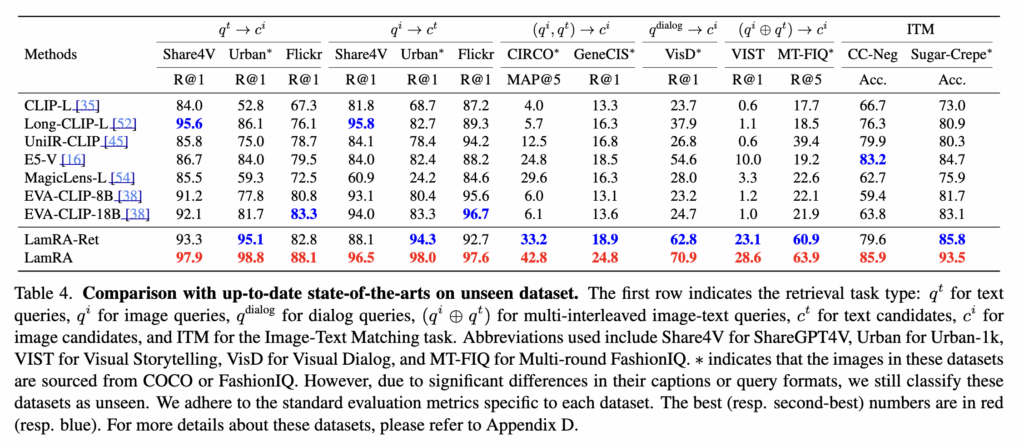
논문이 특히 강조하는 지점은 dual-encoder가 약해지는 상황에서 더 잘 나온다 는 부분이었습니다. 예를 들어 Urban-1K의 image-to-long-text retrieval처럼 긴 텍스트 이해가 필요한 세팅에서 성능 향상이 컸다고 설명했습니다.
3.4 Unseen Task Generalization
아래 Table 3에서는 더 다양한 태스크에 대한 평가인데요. image-to-image, text-image-to-text, text-image-to-text-image 같은 일부 태스크를 학습에서 아예 빼고(held-out), 나머지 태스크로만 학습한 뒤 제외했던 태스크에서 성능을 본 것입니다.
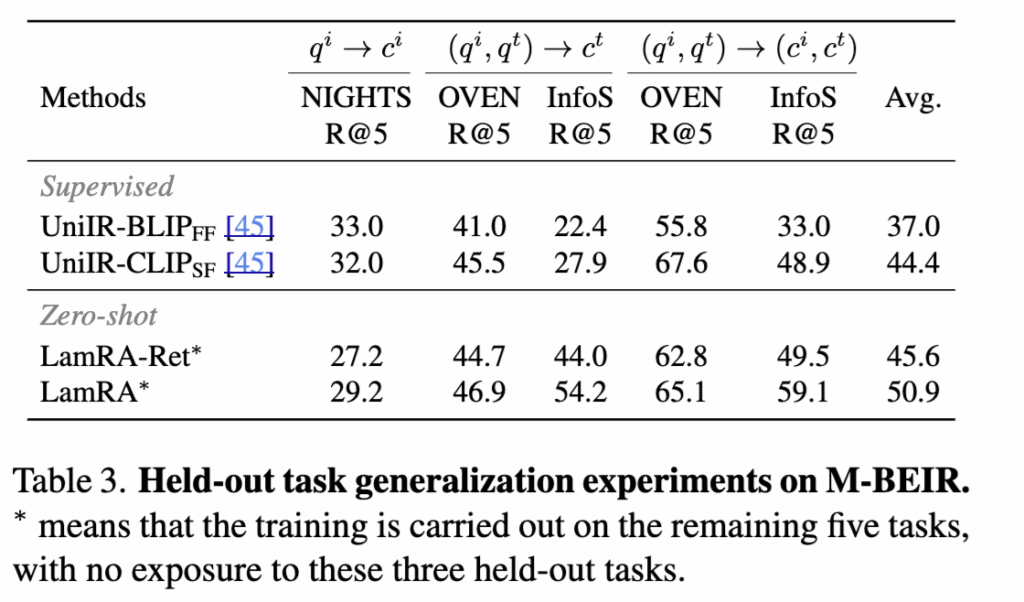
결과적으로 LamRA(특히 reranking 포함)가 held-out 태스크에서도 경쟁력 있는 성능을 보였고, 복잡한 태스크에서는 supervised baseline보다도 강한 케이스를 강조했습니다(ex. InfoSeek의 text-image-to-text retrieval에서 큰 폭으로 앞선다). 이 부분을 근거로 추가 학습 없이 unseen retrieval task로 extrapolate할 수 있었다고 하네요
3.5 Ablation Study
(1) Two-stage training 필요성

Table 5는 2-stage 학습의 효과 입니다. 아무것도 안 하면 평균 23.0이고, pre-training만/inst-tuning만 했을 때의 수치가 각각 올라가며, 둘 다 했을 때 평균 56.6으로 가장 높았습니다. 결국 pre-training과 instruction tuning이 “각각 의미 있게 기여한다”는 결론을 내릴 수 있겠네요
(2) 모델 크기 키우

Qwen2-VL-2B에서 7B로 커지면 M-BEIR 평균 성능이 올라가는 scaling trend도 함께 제시했습니다.
(3) Pointwise vs Listwise reranking
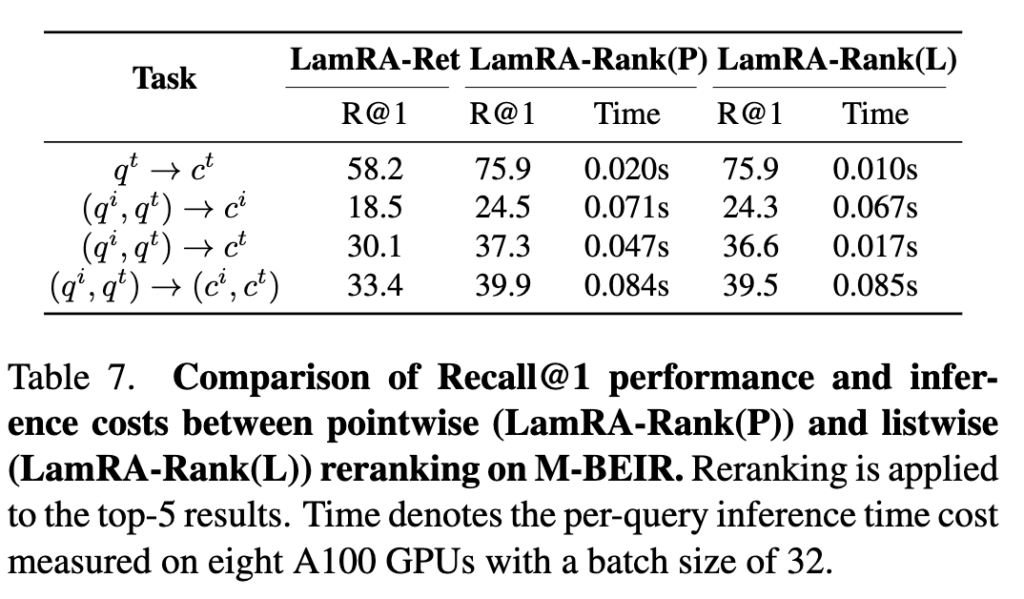
두 방식 모두 R@1을 크게 올려주지만, pointwise는 후보 수만큼 여러 번 inference를 해야 해서 비용이 커지고, listwise는 한 번에 처리할 수 있어 빠르지만 컨텍스트 길이 제한 때문에 후보 수에 제약이 생긴다 합니다. 즉 “성능 vs 비용/제약”의 트레이드오프로 선택할 수 있다는 결론이죠
(4) Video retrieval 확장 가능성?
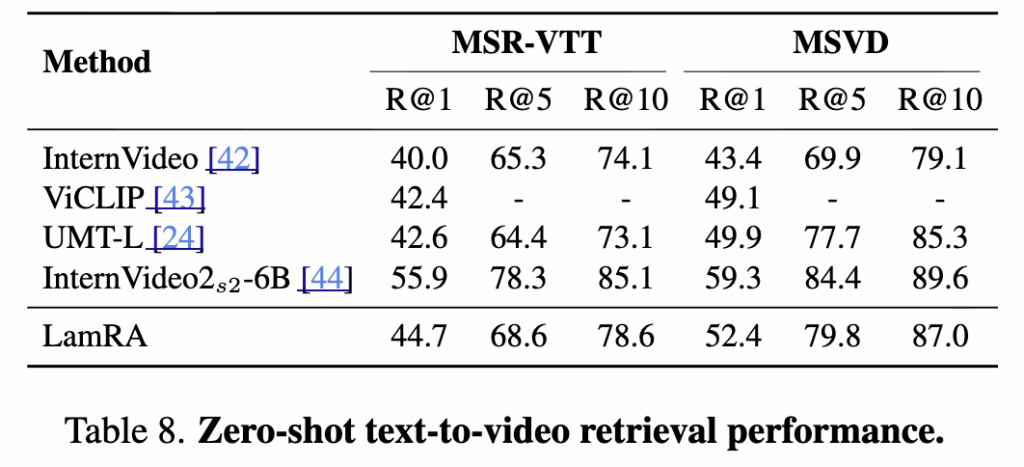
흥미롭게도 비디오 데이터로 따로 fine-tuning하지 않았는데도, MSR-VTT/MSVD에서 text-to-video retrieval 제로샷 성능을 보여주었는데. SOTA(InternVideo2)에는 못 미치지만, Qwen2-VL이 가진 비디오 이해 능력을 LamRA가 유지하고 있다는 식의 언급을 하였습니다
4. Conclusion
LamRA는 멀티모달 retrieval 태스크가 점점 복잡해지는 상황에서, 기존 VLP 기반 dual-encoder를 태스크별로 튜닝하는 흐름에서 벗어나 Large Multimodal Model(LMM)을 retrieval assistant로 재활용하자는 방향을 제안한 논문이었습니다. 핵심은 LMM에서 바로 retrieval embedding이 나오지 않는다는 한계를 EOL 기반 embedding 추출로 정리하고, 이를 기반으로 Universal Retriever(LamRA-Ret) 와 Universal Reranker(LamRA-Rank) 를 결합해 “임베딩 기반 1차 검색 → top-K reranking” 파이프라인을 하나의 프레임워크로 통합했다는 점이었습니다.
다만 아쉬운 점은 LMM 기반 retrieval이 갖는 구조적 비용 문제도 남아 있었습니다. 특히 reranking은 후보 수만큼 inference가 늘어나거나(pointwise), 컨텍스트 길이 제한에 걸리거나(listwise) 하는 트레이드오프가 있고, 전체적으로 dual-encoder 대비 inference cost가 무겁다는 점을 저자들도 직접 언급했죠. 아마 실제 적용에서는 후보 풀 임베딩을 미리 계산해두는 식의 최적화나, QPS가 낮은 환경에서의 활용을 함께 고려해야 할 것 같ㅎ습니다
안녕하세요 주영님 좋은 리뷰 감사합니다.
“3.5 Ablation Study – Two-stage training 필요성”의 실험 결과를 보면, Pre-training과 Instruction Tuning을 비교했을 때 Instruction Tuning만 거쳐도 모델 성능이 크게 향상되는 것을 확인할 수 있습니다. 이를 통해 Instruction Tuning 단계가 모델 성능 향상에 매우 중요한 역할을 한다는 점을 알 수 있을 것 같습니다.
Video retrieval에서도 zero-shot 성능에서 높은 성능을 보여주었는데, 여기서 fine-tuning은 안했더라도 Pre-training과 Instruction Tuning도 안하나요? 만약 진행한다면 Pre-training은 어떤 데이터셋으로 했고 Instruction Tuning은 어떻게 구성되어 있는지 궁금합니다.
감사합니다.
Q. Video retrieval zero-shot에서 학습(Pre-train/Inst-tune) 했는지?
네 맞습니다. 즉, 논문에서의 “zero-shot” 은 비디오 데이터로 추가 fine-tuning을 안 했다는 의미입니다.
대신 LamRA 자체는 논문에서 제안하는 2단계로 학습되어 있습니다
1. Pre-training: NLI 데이터셋 사용 (텍스트-텍스트 retrieval 성격으로 LoRA 학습)
2. Instruction Tuning: M-BEIR 데이터셋 사용 (멀티모달 instruction tuning)
참고로, M-BEIR 데이터셋은 (8 tasks, 10 datasets) 기반으로 task-specific instruction을 붙여 학습하였습니다
https://huggingface.co/datasets/TIGER-Lab/M-BEIR