안녕하세요, 이번주는 NVIDIA에서 최근에 발표한 연구에 대해 리뷰해보려고 합니다. 최근 로봇 데이터가 아닌 다른 도메인의 데이터가 어떻게 학습에 사용될까?에 대한 궁금증이 늘 있는데, 해당 연구에서 꽤 흥미로운 발견을 한 것 같습니다. Ego centric human video도 scaling이 가능한 데이터인데, 이게 어떻게 VLA 모델에 주입되는게 맞는지, 로봇은 어떤걸 학습하는건지, 더 나아가서 어떻게 하면 최소한의 로봇 데이터로 general한 manipulation을 학습시킬 수 있는지에 대해 조금이나마 다룬 연구라고 생각합니다. 특히 이전 연구들은 human video를 단순히 vision encoder를 학습시키거나 retargeting 하는 용으로 사용하는 경우가 많아 생각보다 적은 양을 사용했는데, human data를 scaling하며 action이 포함된 manipulation 자체를 학습시키는 접근이 로봇 데이터쪽의 효율을 챙겨준 것 같습니다. 리뷰 시작해보도록 하겠스빈다.
Introduction
저자들은 로봇의 physical 능력을 학습시키는데 있어 human video가 과연 scaling이 의미있는 자원이 될 수 있는가? 라는 질문으로 시작합니다. 사람들은 일상에서 다양한 task의 dextrous manipulation을 하며 살아가기 때문에, teleoperation으로 수집하는 robot 데이터와 비교했을때 근본적으로 scaling의 정도가 굉장히 많이 차이가 난다고 합니다. 최근 로봇들은 기구학적으로도 인간의 작업을 모사하기 용이하게 발전하는 중인데, 이런 시점에서 인간 데이터를 dextrous manipulation의 주요 supervision으로 사용할 수 있는가?의 의문을 품었다고 합니다. 이전 연구들은 human video를 사용하기는 하지만, ‘로봇으로의 transfer가 가능하다’만을 보여주는데서 그치면서 observation이나 action을 정렬하는 방식으로만 이루어졌고, 그렇기 때문에 robot data 대비 항상 제한적인 데이터만을 활용했다는 점을 문제로 삼았습니다.
저자들은 보통 수십시간~수백시간 정도의 human video를 사용해 로봇을 학습시켰기 때문에 human data scaling이 manipulation으로 이어질 수 있는가?의 근본적인 문제에는 접근해본적이 없고, gripper를 활용한 조작을 중심으로 연구해 사람 손의 articulation이 포함된 human video가 정말로 dextrous한 manipulation에 영향을 줄 수 있는가에 대한 답을 얻을 수 없었다고 합니다. 저자들은 해당 문제들을 주로 풀었고, 그 결과로 dexterous manipulation에서 human-to-robot transfer가 본질적으로 scaling phenomenon이라고 주장하며, 이를 위해 대규모 egocentric human data를 기반으로 하는 human-to-dexterous-manipulation transfer 프레임워크인 EgoScale을 제안했습니다. 저자들의 EgoScale은 심지어 dextrous hand를 사용하지 않는 더 적은 DoF hand로도 확장할 수 있었다고 합니다.
저자들은 EgoScale을 통해 인간의 손목과 손의 행동을 예측하는 정확성이 human video 데이터 양과 log-linear 관계를 따른다는 것을 확인했다고 합니다. 이 결과를 통해 인간 데이터가 늘어날수록 validation loss가 계속 감소하고, 그렇게 학습된 representation은 일반화의 방향성을 예측 가능하게 만들기 때문에 해당 관계가 중요했다고 합니다. 뿐 만 아니라 저자들은 human action prediction의 loss가 long-horizon task의 성능과 강하게 상관된다는 점까지 관측할 수 있었다고 합니다. 정리하자면 human video 기반의 학습 손실이 로봇 성능을 예측하는 좋은 proxy가 되며, 이는 large scale ego centric human video를 dexterous manipulation policy 학습을 위한 확장 가능하고 예측 가능한supervision source 감독 신호로 정립하는 근거가 된다고 합니다.
저자들은 추가로 데이터 규모 뿐 만 아니라 실제로 transfer가 잘 되도록 어떻게 supervision을 줄거냐에 대한 내용도 강조하고 있는데, 어떻게 인간의 행동과 로봇의 행동을 align된 action space로 표현했는지, 어떻게 task-agnostic visual feature만을 학습하는 용도에서 manipulation 자체를 학습시켜 실제 robot이 task를 수행할 때 one shot transfer가 가능했는지는 method 쪽에서 풀어보도록 하겠습니다.
정리하면 저자들의 contribution은 다음과 같습니다.

Related Works
Human data를 활용한 로봇 학습 연구는 high-level intent recognition에서 direct motor control까지 발전해 왔지만, dexterous manipulation을 스케일링하는 문제는 여전히 핵심 문제로 남아 있었다고 합니다. 초기 접근법들은 주로 human video를 representation learning이나 reward specification에 활용했고, 실제 policy execution을 위해서는 늘 많은 양의 로봇 데이터에 의존했다고 합니다. 이후 연구들은 hierarchical framework를 통해 human video를 통해 high-level planning을 수행하고 low-level control을 위해 robot demonstrations이나 RL을 도입하는 방식으로 발전했다고 합니다.
최근의 방법들인 EgoMimic과 DexWild는 human video를 직접 모방하는 direct imitation이나 domain adaptation을 통해 사람과 로봇의 embodiment gap 자체를 줄이면서 action 자체를 학습하려는 시도를 했지만, 작은 규모의 데이터에 의존하거나 (저자들은 많아야 몇십 시간이라고 합니다), 단순화된 그리퍼 동작을 학습시켰다고 합니다. 저자들은 20,000시간이 넘는 egocentric human video로 pretraining을 scaling함으로써, high DoF dexterous hand에 대해 transferable motor prior를 학습할 수 있음을 보여준다는 점에서 해당 연구가 기존과 다르다고 합니다. 또한 retargeting이나 대량의 로봇 데이터를 필요로 해야만 dexterity를 달성할 수 있었던 기존 연구들과 달리, human motion prediction을 fine-grained physical interaction을 위한 foundational supervision signal로 활용하는 pretrain-then-adapt 패러다임을 제시했다고 합니다.
Methods
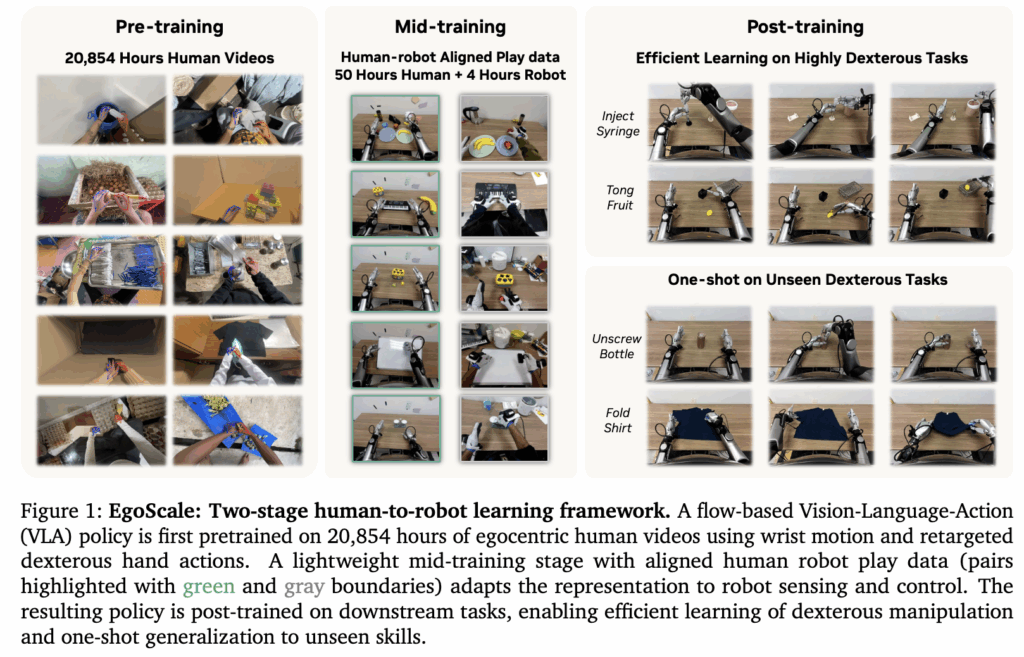
방법론의 핵심은 2stage transfer를 통해 noisy하고 align되지 않은 human video와 정밀한 robot control을 연결해주는 것입니다. 저자들은 human demonstration이 로봇과 직접적으로 pairing된 데이터가 아니고, embodiment gap이 크기 때문에 20,000시간이 넘는 egocentric 비디오에 대해 손목의 움직임과 손 관절 동작에 대한 명시적인 supervision (아래처럼 손목에 tracker를 붙이고 manus 장갑을 활용해 손목의 pose와 finger의 구조를 전부 world 좌표계로 변환해줍니다)을 사용해 pretraining을 수행합니다. 이를 통해 모델이 물리적으로 grounded된 action representation, 즉 손이 세계와 어떻게 상호작용하는지를 학습한다고 합니다. 이후 이러한 일반적인 이해 (manipulation 자체가 어떤 행동인지)를 실제 실행 가능한 robot action으로 변환하기 위해, 이전의 hum-sim co-training과 같이 human-robot align된 데이터를 co-training해 mid-training을 진행합니다. (위 Figure 1의 mid training부분을 참고하시면 데이터의 구성을 볼 수 있습니다.) 저자들은 이를 통해 많은 양의 human video를 실제 robot action으로 align하는 과정을 분리해서 소규모의 paired demonstration과 최소한의 robot data를 통해dexterous manipulation이 가능하다고 합니다. 밑에서 더 자세하게 풀어보도록 하겠습니다.
Human Action Representation
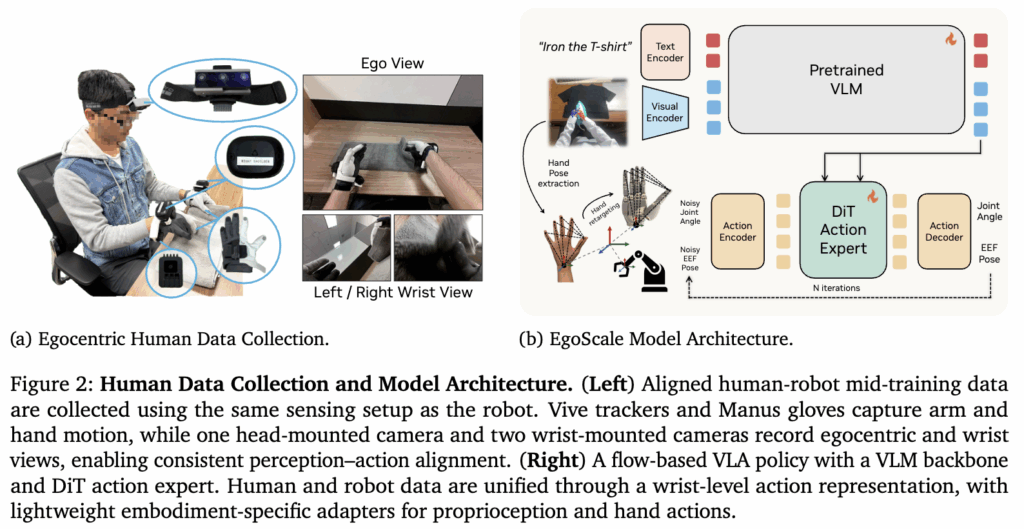
Egocentric video를 로봇이 학습 가능한 형태로 변환하기 위해, 저자들은 noisy한 human 데이터를 embodiment가 로봇과 통합된 action space로 변환합니다. 최근의 연구들과 비슷한 구조입니다. 먼저 머리쪽의 RGB 비디오와 SLAM을 통해 추정된 카메라 포즈를 통해 21개의 hand에 대한 키포인트 (손목 + finger)를 추출합니다. 손가락의 키포인트는 kinematic constraints을 만족하도록 최적화를 사용해 인간 손 키포인트를 로봇 손에 맞는 space로 리타게팅한다고 합니다. (찾아보니 CasADi와 IPOPT를 사용했다고 하네요.) 데이터 생성 생성 자체는 전부 기존의 방법을 따라서 진행하는 것 같습니다. 특이한 점은 손목에 달린 카메라가 안쪽 손목에 달려서 손바닥을 관찰한다고 합니다. Head cam으로 팔의 움직임 까지는 supervision이 가능하지만 dextrous한 행동을 위해서는 손 자체를 잘 관찰해야한다고 합니다.
사람의 팔의 움직임에 대해서는 world 좌표계에서 상대적인 손목 움직임 (wrist pose의 델타값)을 계산하여 카메라 위치에 불변한 action space를 구성하고, 이를 통해 착용자의 머리 움직임의 영향을 효과적으로 걸러낸다고 합니다. 저자들은 추가로 데이터의 양이 많아지는것 자체로도 카메라의 움직임에 대한 불변성은 어느정도 생긴다고 합니다. 이렇게 데이터를 처리해 직접적인 로봇 supervision이 없더라도 모델이 dexterous manipulation의 복잡한 특성을 담아내는 물리적으로 그럴듯한 정책을 학습할 수 있다고 합니다. 제가 이해한 바로는 이 단계의 데이터를 통해서는 dextrous manipulation이라는게 ‘어떤 행동인지 (팔은 어떻게, 손가락은 어떻게 움직여야 하는지)’를 사람을 관찰하며 구체적으로 배우는 것 같습니다. 이걸 모델 입장에서 좀 더 명시적으로 학습할 수 있게 world 기준으로 통합된 상대 pose로 정리한 것 같습니다.
Human Data Sources and Processing
저자들은 학습 프레임워크 자체를 Stage 1과 Stage 2를 분리해서 Stage 1에서는 human video로 대규모 스케일을 확보하고 다른 한쪽에서는 alignment를 정밀하게 하는 방식으로 구성했습니다. 이를 통해 action 자체를 학습하는 human data의 scale과 그 데이터로 학습한 지식을 로봇으로 align하는 문제를 분리해서 다루었습니다. 쉽게 Stage 1이 로봇에게 행동 자체에 대해 일반적으로 학습시키는 과정, Stage 2가 로봇 제어에 맞게 바꾸는 과정이라고 보시면 됩니다.
Stage I에서는 대규모 egocentric human pretraining 데이터를 구축했습니다. 저자들은 총 20,854시간 분량의 egocentric human activity 데이터셋을 사용했다고 합니다. 데이터는 in-the-wild의 egocentric 영상으로 구성되었고, 환경도 매우 다양하게 포함되어있다고 합니다. 가정, 산업, 교육 환경 등 서로 다른 환경을 포괄하도록 구성되어 단순히 양치기만 한게 아니라, 9,869개의 scene, 6,015개의 task, 43,237개의 object를 포함하고 있어, long-tail 조작 행동을 넓게 커버할 수 있도록 설계됐다고 합니다. 모든 데이터는 RGB 카메라를 통해 30 FPS로 수집했습니다. 예시는 아래Figure 2의 (a)와 같습니다.
Stage 1 데이터는 수집 과정이 unconstrained이기 때문에 off-the-shelf SLAM과 hand-pose estimation 파이프라인을 통해 카메라와 hand의 궤적을 복원해서 사용했다고 합니다. 저자들은 이런 노이즈가 있음에도 불구하고 데이터의 규모와 다양성 자체가 로봇에 transfer 가능할 정도로 action representation을 학습하는 데 효과적인 supervision으로 작동하는 것을 확인 했다고 합니다. 특히 데이터 양이 증가할수록 downstream 성능이 계속 향상된다고 합니다.
저자들은 추가로 Stage 1의 noisy supervision을 보완하기 위해 829시간 규모의 EgoDex 데이터셋을 추가했다고 합니다. EgoDex 데이터는 Apple Vision Pro를 사용해 손목과 손의 tracking 정확도가 높아 추가했다고 합니다. 훨씬 정밀한 wrist/hand의 kinematic signal을 제공해 pretraining에서 anchor 역할을 기대했다고 하네요. Vision Pro가 성능이 좋은 부분이 확실히 있는 것 같습니다.
Stage 2에서는 인간 시연과 로봇 실행 사이의 embodiment gap을 더 직접적으로 줄이기 위한 aligned human-robot mid-training 데이터셋을 구축했습니다. Stage 2 데이터셋은 human 데이터와 teleoperated robot 데이터를 pairning해 구성했습니다. 344개의 tabletop manipulation task로 이루어져 있고, 각 task마다 human trajectory 30개, robot trajectory 약 5개씩 수집했다고 합니다. Align된 데이터 역시 human video의 양이 더 많았습니다.
이 때 시각 관측과 동작 측정이 모두 로봇 기준에 맞춰 정렬되었다는 점이 핵심이라고 합니다. Figure 2의 (a)와 같이 로봇과 같은 위치에 같은 카메라를 부착해 단순히 같은 task를하는 pair가 아니라 pretrained visual representation이 로봇 카메라 입력으로 자연스럽게 이어질 수 있도록 할 수 있고, 이게 align의 핵심이었다고 합니다. 이 대목에서 보면 시뮬레이션 데이터를 활용하더라도 현실적인 텍스쳐와 카메라 시점 일치는 정말 중요할 것 같다는 생각이 듭니다.
손과 손가락의 위치도 로봇 teleoperation과 동일하게 얻을 수 있도록 manus gloves를 활용한 motion capture를 사용해 구한 뒤 motion signal을 비디오 스트림과 동기화했다고 합니다. 동기화가 중요한 이유는 Stage I 서는 SLAM과 hand-pose estimation을 통한 noisy한 신호를 사용했기 때문에 Stage 2 에서는 로봇 teleoperation과 동일한 계측 체계를 통해 훨씬 정밀하고 embodiment-aligned된 motion 데이터가 필수적이었다고 합니다.
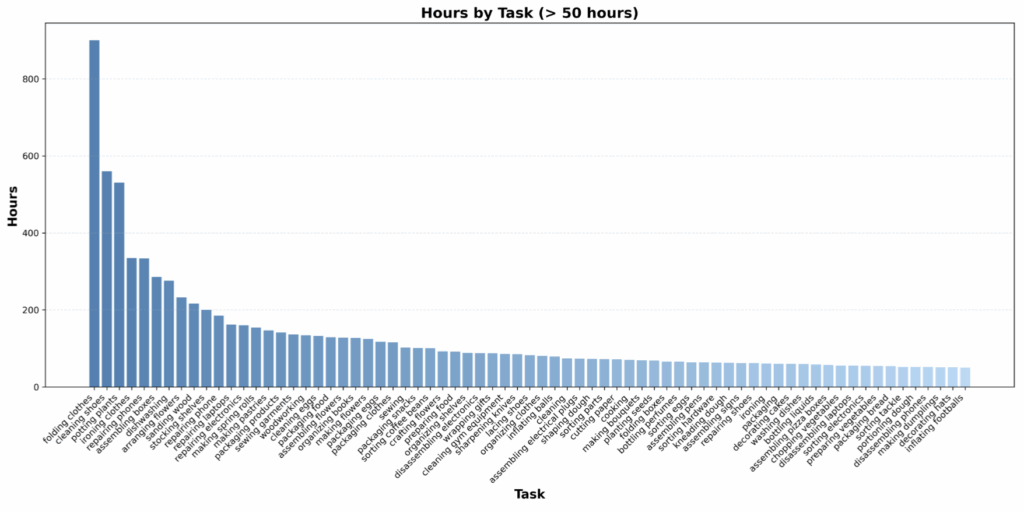
아래는 혹시나 human video 데이터의 구성을 궁금해하실 분들을 위한 자료입니다. 각 task에 대한 비중과 그 시간입니다. cloth가 대략 800시간 정도임을 참고하시면 될 것 같습니다.

Model Architecture
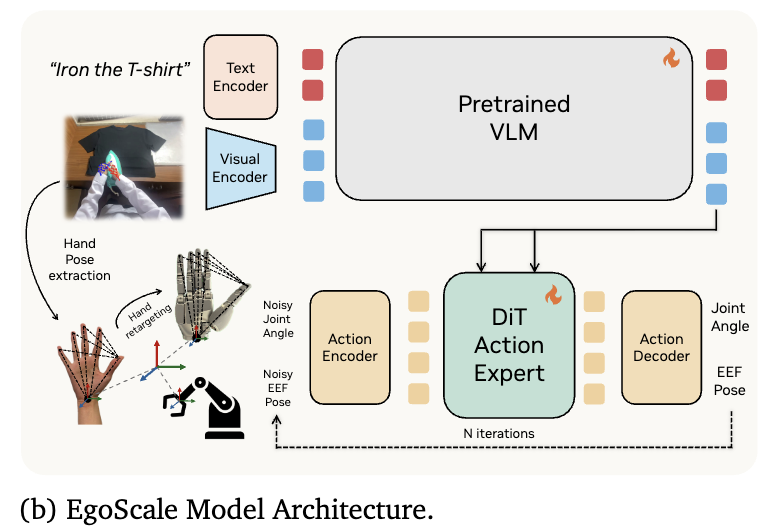
모델 아키텍쳐는 위 Figure 2의 (b)와 같습니다. 구조 자체는 gr00t N1과 별 다를것 없이 VLM을 통해 임베딩 된 이미지와 language instruction을 observation으로 condition된 Flow Matching 기반의 action expert입니다. 여기에 다양한 embodiment와 다양한 DoF의 hand를 커버하기 위해서 proprioception과 hand action decoding을 위한 어댑터를 도입했고, Stage 1에서의 proprioception 부재를 커버하기 위해 learnable placeholder token을 도입했다고 합니다. Placeholder token은 무작위 값이 들어가지만 모델이 학습을 해가면서 점차 이 토큰은 그냥 자리 채우기용 의미없는 토큰이구나를 배울 수 있다고 합니다. (요 부분 제가 잘못 이해한 거면 지적 부탁드립니다,,)
Experiments
저자들은 크게 아래와 같이 5개의 Research Question을 가지고 해당 질문들의 답을 찾아가도록 실험을 설계했다고 합니다. 하나씩 살펴보도록 하겠습니다.
- RQ1: Does large-scale egocentric human pretraining improve downstream dexterous manipulation performance compared to training from scratch or embodiment-aligned data alone?
- RQ2: How does the scale of human pretraining data affect representation quality and real-robot performance?
- RQ3: What role does mid-training play in enabling few-shot adaptation and generalization to novel tasks?
- RQ4: Do human-pretrained representations transfer across robot embodiments with substantially different kinematics and control interfaces?
- RQ5: How does the choice of human action representation during pretraining affect downstream dexterous manipulation?
Experiment Setup

실험에는 Galaxea R1 로봇과 22 DoF sharpa hand가 사용되었고, task는 각각 옷 개기, 카드 스택에서 한 장 뽑아 꼽기, 집게를 사용해 바구니에 물체 옮긴 후 제자리에 두기, 병뚜껑 열기, 주사기로 액체 옮기기를 통해 평가했습니다. Task 구성이 하나같이 다 ‘그래… 이정도는 돼야 dextrous manipulation이고 그래야 hand도 의미가 있지’ 싶어서 흥미진진 해졌습니다. 각 task에는 100개의 episode를 사용했고, 옷 접기의 경우에는 비교적 쉬운 task라고 판단해 50개의 episode만 사용했다고 합니다. (근데 human video의 구성을 보면 옷 개는 데이터가 압도적으로 제일 많이 들어있습니다.) 평가 지표로는 10회의 시도에 대한 task progress와 success Rate를 사용했습니다.
A1. Large-Scale Human Pretraining Is Key to Strong Dexterous Manipulation Policy Performance
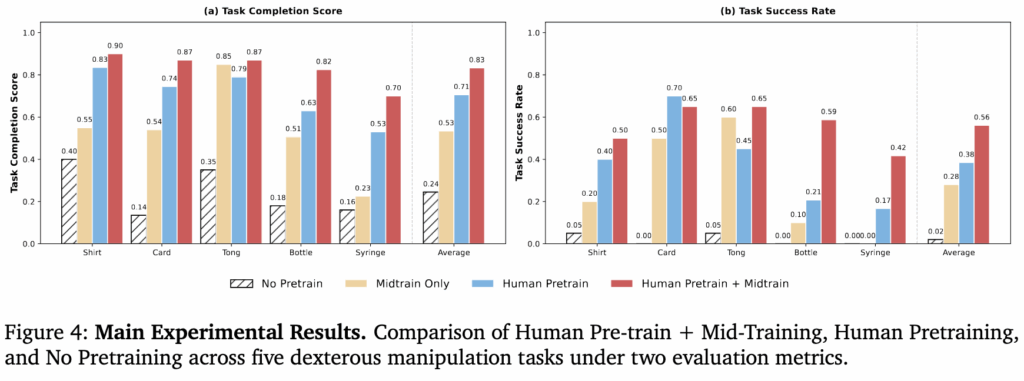
Pretrain 없이 로봇 데이터로만 학습한 경우, human-robot aligned 데이터로만 pretrain한 경우 (stage 2), human pretrain만 진행한 경우 (stage 1), 전체 파이프라인으로 학습한 경우 (stage 1 + 2) 로 비교실험한 결과입니다. 이 실험을 통해서 Human Pretraining의 강력한 Inductive Bias를 확인할 수 있습니다. 대규모 Human Data 학습만으로도 no pretrain 대비 50% 넘게 향상된 성능을 볼 수 있었스빈다. Human video를 대규모로 pretraining 시키는 것만으로도 로봇이 물리적 세계에서 어떻게 손을 쓰고 물체를 다뤄야 하는지에 대한 감각을 배울 수 있었다고 저자들이 분석했습니다.
또 이 때 데이터의 scale과 diversity가 human video의 로봇 기준 정밀함보다 중요할 수 있다고 언급했습니다. Unaligned 이지만 대규모 human data로만 학습한 모델이 로봇 데이터나 align된 소규모의 데이터로 tuning했을 때. 보다 더 나은 성능을 보였기 때문에 로봇 학습에 있어 데이터의 규모와 다양성이 제공하는 inductive bias가 정밀함보다 더 중요한 요소일 수 있다고 합니다. 추가로 human video와 aligned pair data의 상호보완성도 입증이 됐다고 생각합니다. 다만 task마다 success rate가 우세한 세팅이 좀 달라지는 것은 더 고민을 해봐야 할 것 같습니다. 카드 한 장 뽑아서 꼽기나 주사기로 액체 옮기기와 같이 정교함이 요구되는 동작에 있어서 로봇 align된 데이터가 더 효과가 좋을 것 같았는데, 오히려 이런 경우에 대규모의 데이터가 더 중요한 것이 좀 신선했습니다.
A2. Policy Performance Scales with Pretraining Data Size
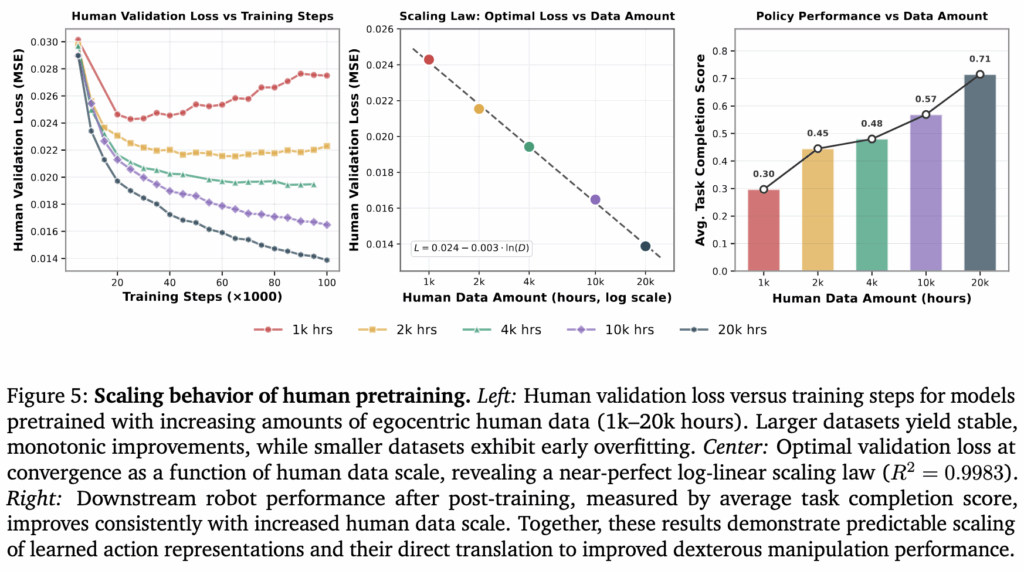
Figure 5를 보면 human data의 scale과 policy performance 간에 명확한 상관관계가 있는 것을 알 수 있습니다. 저자들은 이를 통해서 Human-to-Robot Transfer는 결국 데이터 스케일링 문제였다는 것을 입증했다고 합니다. 한 번도 보지 못 한 human video 데이터에 대한 validation loss로 분석했을 때 1,000시간의 데이터로는 overfitting이 발생하지만, 점점 데이터가 커질수록 loss가 꾸준히 감소하며 안정적으로 수렴하는 모습을 볼 수 있었고, 이를 통해 역시 대규모 데이터가 학습 안정성에 필수적이라고 주장합니다. 특히, 데이터 양(D)과 validation loss(L) 사이에는 L = 0.024 − 0.003 · ln(D) 의 remarkably clean log-linear scaling law가 성립함이 발견되었다고 합니다. 이를 통해 human video 데이터가 늘어날수록 모델의 성능이 예측 가능하게 향상됨을 수학적으로 증명했다고 합니다. Pi 0.5 저자는 수학적으로 명확히 확인할 수 없어서 실제로 실험을 통해 경험적으로 알기 전 까지는 배경 다양성과 zero shot environment에서의 성능에서 scaling law를 알 수 없었다고 했는데, 뭔가 둘이 다른게 있나봅니다.
저자들은 scaling law에 대해서 추가적으로 강조했는데 중요한 점이 validation loss의 감소가 단순히 video 데이터에 대한 예측 성능 향상만 일어나는게 아니라 task completion과 직결된다는 것이라고 합니다. 이 내용만 보면 로봇 데이터를 그렇게까지 엄청나게 수집하지 않아도 human video를 scaling하는 것만으로도 로봇의 조작 능력이 좋아질 수 있는거 아닌가..? 싶습니다. 결국 Meta의 aria glasses와 같은 장비가 대중들에게 보급되고 passive한 데이터가 수집되는 순간 manipulation이 풀릴 수도 있다고 했던 CoRL에서의 패널 토크가 갑자기 생각나네요,,
A3. Aligned Human-Robot Mid-Training Enables One-Shot Transfer
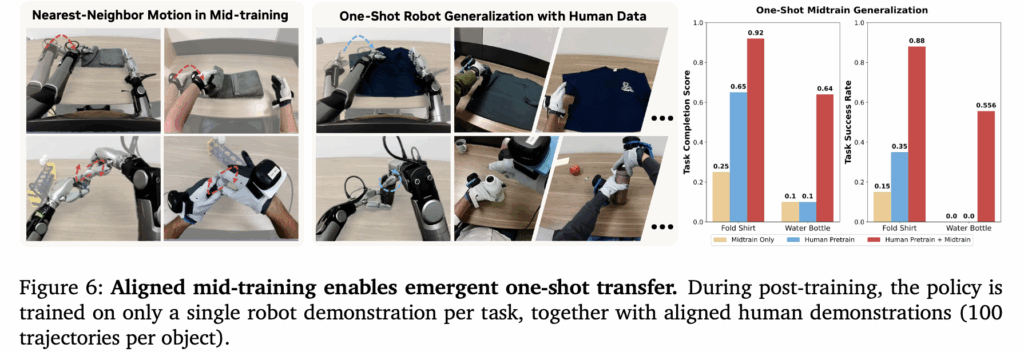
해당 실험을 통해서는 EgoScale의 two-stage 구조 학습 프레임워크의 one shot transfer 가능성에 대한 실험 결과를 볼 수 있습니다. Fold shirt와 unscrew bottle task에서 human pretraining만 적용하거나 aligned mid-training만 적용한 모델은 SR이 낮고 병뚜껑의 경우 0인것을 볼 수 있습니다. Human data pretraining + aligned data midtraining 구조를 통해서 대규모 human data가 조작 자체의 prior를 제공하고, aligned data를 통해서 control 능력으로 연결해주는 상호보완적인 면이 입증됐다고 볼 수 있을 것 같습니다.
제일 놀라웠던 점은 human-robot aligned 데이터에는 fold shirt와 unscrew bottle에 대한 데이터가 포함되어 있지 않다는 점입니다. 결국 general한 task에 대한 이해와 그것을 로봇의 control로 변화시키는 부분이 명확히 나눠져있고, 각각의 효율에 대해서도 추가적으로 연구할 수 있지 않을까 싶습니다. 저자들은 figure 6의 실험을 통해 EgoScale이 단순한 모방 학습을 넘어, 인간의 행동 데이터로부터 로봇이 새로운 환경과 task에 적응할 수 있음을 증명했다고 합니다.
A4. Human Pretraining Enables Cross-embodiment Transfer
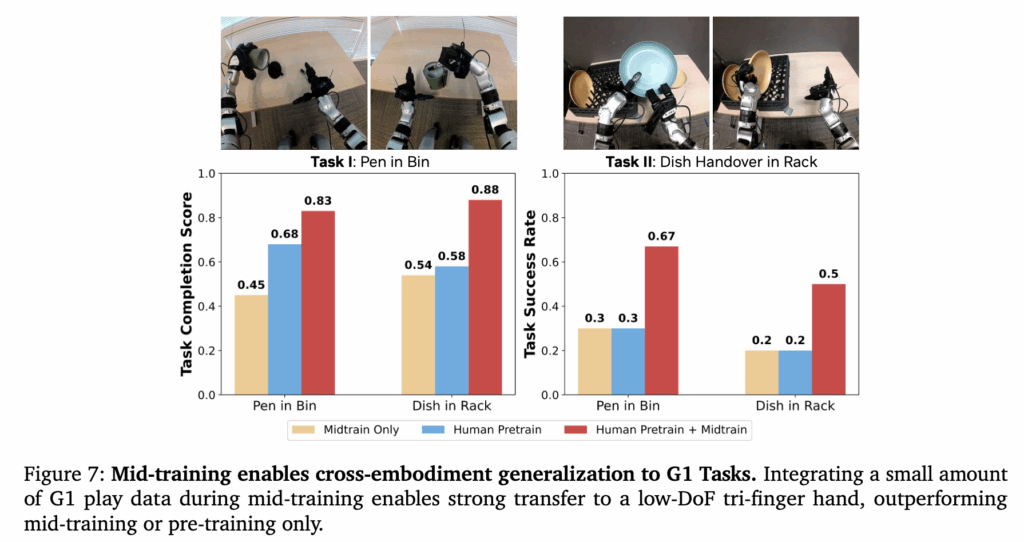
Figure 7은 large scale human data pretraining의 cross embodiment transfer 가능성과 효과에 대한 실험결과입니다. 22 DoF인 sharpa hand뿐만 아니라, Unitree G1의 hand(7-DoF)와 SCHUNK hand(9-DoF) 같은 완전히 다른 구조와 적은 자유도를 가진 로봇 손에 대해서도 transfer가 가능하다고 합니다. Hand에 대한 transfer는 앞에 method에 설명한 어댑터에 대한 실험인 것 같습니다. 실험 결과, human pretraining만 적용하거나 aligned data로만 pretraining하는 경우보다 둘 다 적용했을 때 훨씬 성능이 좋은 것을 학인할 수 있습니다. 이 또한 결국 large scale의 human data로 학습하는 것이 embodiment agnostic한 범용적인 행동을 제대로 학습시키고 이를 다양한 로봇 플랫폼으로 확장(저자들의 경우 translation만 시켜주면 된다는 표현을 했습니다)이 가능함을 보이는 실험이라고 생각하면 될 것 같스빈다.
A5. Hand Action Space Design for Human Pretraining
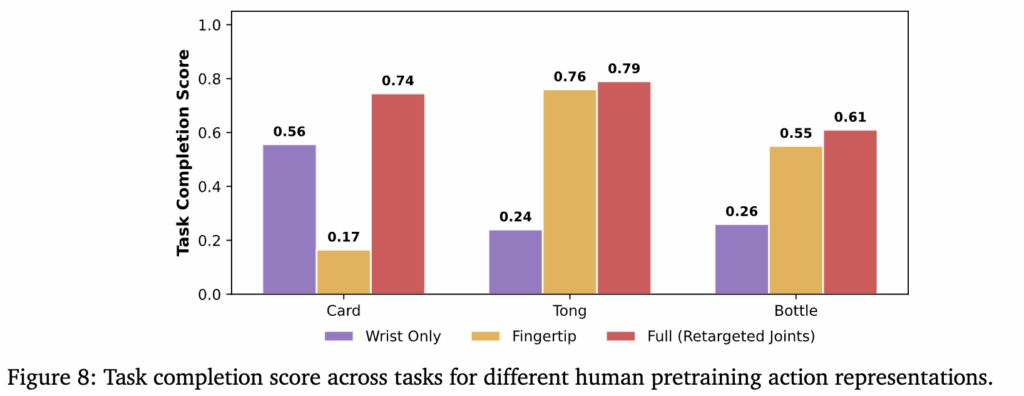
해당 실험에서는 pretraining에 사용되는 human data의 action representation 방식이 뭐가 좋은지를 볼 수 있습니다. Wrist only,fingertip based, retargeted joint space hand actions(ours)로 나눠서 실험했습니다.
Wrist only는 손목 움직임만 학습하고 손가락 움직임은 무시하는 방식이라고 합니다. 해당 방법은 card를 한 장 뽑아서 꼽는 정교한 손가락 조작과 접촉 타이밍이 필요한 작업에서 매우 저조한 성능을 보였다고 합니다. 이를 통해서 손가락 끝의 미세한 제어가 dextrous 작업에 필수적이고, 이 부분이 human data에 표현돼야 하는 것을 알 수 있습니다.
Fingertip based는 손가락 끝의 pose를 추가해 학습하는 방식입니다. 전체적인 손을 포함한 동작에 대한 geometric supervision을 줄 수 있어서 일부 task에서는 wrist only보다 나은 성능을 보였지만 implausible configuration이나 unstable grasps에 빠져 성능이 안 좋았다고 합니다. Hand의 경우 모델 자체에서도 어댑터가 joint space로 출력하는데, singularity 문제가 DoF가 많을수록 일어나는 것 같습니다.
마지막으로 프레임워크에 사용된 retargeted joint space hand actions은 모든 작업에서 일관되게 향상된 성능을 달성했다고 합니다. 사람의 손 구조를 로봇의 joint space에 직접 매핑될 수 있는 형태로 표현하는 것이 당연하겠지만 dextrous manipulation의 핵심중에 하나라고 합니다.
Conclusion
해당 연구를 통해서 여러 생각을 해볼 수 있었는데요, 물론 이 연구만 본 것이고 한계도 많겠지만 human video 쪽에서 scaling law가 통하는게 맞고, 어떤 task를 수행하는데 필요한 행동의 개념 자체를 잘 학습할 수 있다면 특히나 제한적인 환경에서는 생각보다 문제가 꽤 풀릴 수 있을 것 같다는 생각이 들었고, hand 연구도 이런 관점으로는 시도해볼 수 있는건가? 싶기도 했습니다. 어떻게 보면 사람 기준으로만 영상을 잘 만들어내는 video model들을 효과적으로 활용하면서 비디오 모델이 로봇의 dynamics 자체를 추론하게 하지 않고 VFM들만 잘 활용해서 풀어낼 수 있는 부분들도 있지 않을까 싶기도 합니다. 모델의 아키텍쳐 자체는 크게 변한게 없는데 데이터를 바라보는 관점을 바꾸고 정제해서 dextrous하고 long horizon 하기도 한 task의 성능을 끌어 올렸다는 점도 나름 인상깊으면서 데이터를 모으고 실험만 하는 13명의 전문 로보틱스 인력에 대한 감사 글에서는 벽이 좀 느껴지기도 했습니다,, 고품질 open dataset이 많아졌으면 하네요. 또 읽는 내내 meta의 aria glasses가 생각났습니다,, ㅋㅋㅋ
안녕하세요 영규님, 좋은 리뷰 감사합니다.
대규모 egocentric human video 스케일링에 대한 내용을 자세히 작성해주셔서 이해하는데 큰 도움이 된 것 같습니다.
사람의 손 동작을 로봇의 관절 공간으로 변환하는 방식을 사용했다고 하셨는데, 자유도가 높은 로봇 손의 경우 관절이 중복되거나 특정 자세에서 특이점 문제가 발생할 가능성도 있을 것 같습니다. 이러한 운동학적 중복성이나 특이 자세 문제는 어떻게 다루었는지 궁금합니다.
좋은 리뷰 감사합니다.🖐️
안녕하세요 영규님 좋은 논문 리뷰 감사합니다.
scaling human data로 전반적인 manipulation을 학습하고, human-robot align data로 model에게 dexterity한 task를 학습시키는 방식이 신기하네요.
제가 이번에 리뷰한 논문도 이러한 curriculum learning 방식으로 stage를 나누어 model을 학습시키던데 상호보완적인 데이터의 활용과 simple to complex learning 방식이 robot에게 맞는 학습 방식일 수도 있지 않을까 생각이 듭니다.
읽으면서 궁금했던 점 몇가지 물어보겠습니다.
Q1. Tactile data는 사용된건가요? 저는 sharpa hand가 tactile sensing을 지원하는 것으로 알고있습니다. 만약 tactile data가 사용되지 않았다면 왜 사용되지 않았을까요? human raw data에 tactile data가 없어서?
Q2. wrist only 방식이 card task에서 좋지 않은 성능을 보여줬다고 하셨는데 figure 8을 보면 card task에서 좋은 성능을 보이는 것 처럼 보입니다. 제가 Tong task랑 헷갈리는걸까요?
Q3. hand가 아닌 robot hardware를 바꿔서 실험한 결과는 따로 없나요?
human data를 사용하는 것이 robot domain에서 정말 큰 장점이 될 것 같습니다. 하지만 manipulation task 관점에서는 dexterity한 task를 수행하기 위해서는 tactile data가 매우 중요하다고 생각합니다. CoRL 패널 분이 이야기 하신 것 처럼 human data가 해결 되어도 이러한 tactile data는 어떻게 해결할지.. 궁금하네요.
좋은 리뷰 감사합니다.