안녕하세요 이번에 소개할 논문은 NVDIA에서 발표한 논문으로 롱비디오 이해에 있어 Mamba 기반 모델로 토큰 압축을 적용하여 시간 모델링을 보완하고 성능과 효율을 동시에 향상시킨 논문입니다.
1. Introduction
Video-LLM은 최근 몇 년 사이 빠르게 발전하면서, 비디오 이해 성능을 눈에 띄게 끌어올렸습니다. 다만 현재 주류 파이프라인은 여전히 “프레임을 개별 이미지처럼 인코딩한 뒤 LLM에 넣어 시간 추론을 맡기는” 구조에 가깝습니다. 이 방식은 이미지 인코더와 LLM을 결합했다는 점에서 분명 장점이 있지만, 특히 롱비디오 구간으로 가면 구조적 한계가 뚜렷해집니다. 이 한계를 설계 관점에서 분해해 보면, 결국 두 가지 문제로 정리됩니다.
첫째, 시간 정보를 어디서, 어떻게 모델 안으로 넣을 것인가?
둘째, 긴 비디오에서 중복 정보를 줄이면서도 중요한 단서를 어떻게 보존할 것인가?
먼저 첫 번째 질문과 관련해, 기존 방식은 명시적 temporal encoding이 약한 편입니다. 결과적으로 LLM이 정적 프레임열로부터 시간 관계를 추론해야 하므로 계산 부담이 커지고, 긴 맥락에서 비효율이 누적됩니다. 두 번째 질문에 대해선, LongVILA나 LongVA 같은 방법들이 토큰 수를 줄이기 위해 단순 프레임 서브샘플링을 쓰는데, 이 과정에서 핵심 이벤트가 빠질 가능성이 큽니다. 최근 LongVU는 질의 기반 토큰 선택을 제안했지만, 토큰 선택 이전에 시공간 정보를 충분히 전파하는 전용 모듈이 약하다는 점에서 정보 보존 측면의 아쉬움이 남습니다.
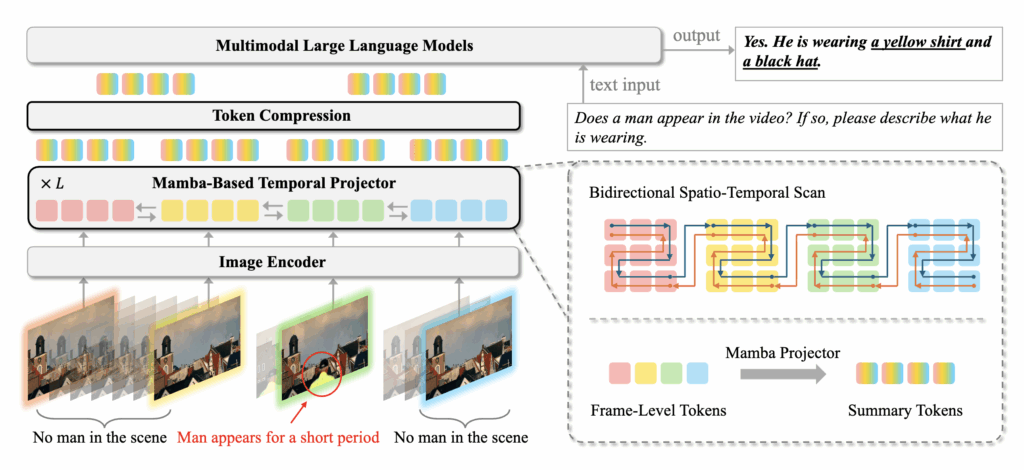
이러한 한계를 해결하기 위해 저자는 STORM (Spatiotemporal TOken Reduction for Multimodal LLMs)를 제안합니다. 핵심 아이디어는 단순합니다. 이미지 인코더와 LLM 사이에 전용 temporal encoder를 삽입해, 시간 동역학을 파이프라인의 앞단에서 먼저 정리한 뒤 LLM으로 넘기는 것입니다. 즉, LLM이 뒤늦게 시간 구조를 복원하느라 비용을 쓰는 대신, 입력 자체를 시간적으로 더 정돈된 형태로 바꾸겠다는 접근입니다.
저자가 제안하는 temporal encoder는 Mamba를 기반으로한 temporal layer으로 구성되어 있습니다. 기존에도 Mamba를 쓰는 비디오 모델은 있었지만, 대다수는 백본 대체 관점에 머물렀고, 멀티모달 LLM과 결합해 비디오 중복을 줄이기 위한 토큰 압축 방법으로 사용된 경우는 거의 없었습니다. 반면 STORM은 Mamba의 상태 압축 특성을 이용해 연속 프레임의 중복 정보를 상태 표현으로 적용하고, 그 결과 시간 이력이 담긴 시각 토큰을 구성합니다.
쉽게 말하면, “모든 프레임을 다 비슷하게 LLM에 던지는” 방식이 아니라, 시간축을 따라 누적된 핵심만 남긴 압축된 토큰 공간을 만들어 전달하는 구조입니다. 저자는 이를 위해 training-free 서브샘플링뿐 아니라 training 기반 압축(temporal/spatial token compression)까지 함께 고려합니다. 실험적으로 STORM은 롱비디오 입력에서 기존 베이스라인 대비 더 강한 성능을 보였고, 동시에 계산 효율 측면에서도 이점을 확인했습니다.
2. Method
그럼 저자들이 제안한 Mamba 기반 temporal projector와, 긴 비디오 처리를 위해 도입한 토큰 압축 전략을 설명드리겠습니다.
2.1. Preliminaries
먼저 SSM(State Space Model)와 Mamba에 대해 간락하게 설명드리겠습니다.
SSM은 입력 시퀀스 x1:T를 hidden state ht로 누적하면서 출력 yt를 만드는 재귀 구조를 가집니다.
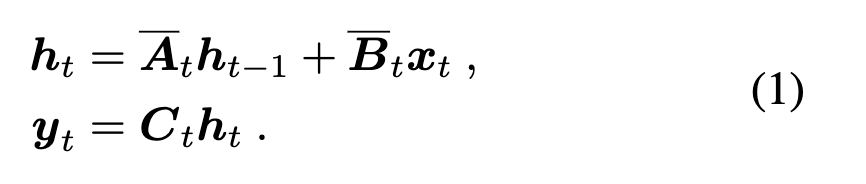
여기서 T는 시퀀스 길이, xt,yt∈RD 는 시간 t에서의 입력과 출력, ht∈RH는 x=<t 히스토리를 요약한 hidden state입니다. 핵심 포인트는 행렬 At,Bt,Ct 가 장기 의존성을 얼마나 잘 모델링하느냐인데, 만약 이 행렬들이 시간에 따라 고정(time-invariant)이라면 시간마다 연산식이 똑같아져 재귀를 순차적으로만 할 필요가 줄어들고 병렬화가 쉬워져 학습/추론 효율이 좋아집니다.
Mamba
한편 Mamba는 SSM의 시퀀스 모델링 능력을 더 키우기 위해 이 행렬들을 상수로 두지 않고, 현재 입력 xt에 조건부로 생성합니다.
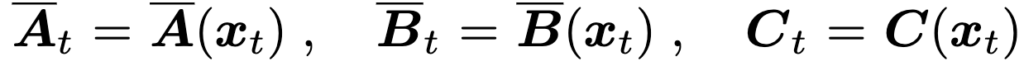
쉽게 말하면, 지금 들어온 토큰이 중요하면 더 살리고, 아니면 줄이는 식으로 동적으로 정보 흐름을 조절합니다.
저자들은 여기에 하드웨어 친화적 병렬 알고리즘을 붙여, 입력 의존 행렬을 쓰더라도 효율 저하를 최소화했다고 설명합니다.
2.2. Mamba-Based Temporal Projector
기존 Video-LLM은 프레임을 거의 독립적으로 처리하는 경우가 많아서, 시간 관계 추론 부담이 LLM 쪽으로 넘어갑니다.
문제는 두 가지입니다.
- 긴 비디오일수록 계산량이 급증하고,
- 연속 프레임의 중복(temporal redundancy)을 제대로 활용하지 못해 비슷한 정보를 반복 처리하게 됩니다.
이를 보완하기 위해 저자들은 Mamba 기반 temporal projector를 둡니다.
프레임 t의 ViT 토큰을 Xt∈RN^×D 라고 할 때, 먼저 선형층으로 프레임당 토큰 수를 N^→N^/r (r은 다운 샘플비율)로 줄입니다.
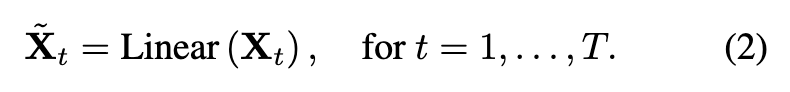
편의상 N=N^/r 라 두고, 전체 프레임 토큰을 쌓으면 다음과 같이 표현됩니다.
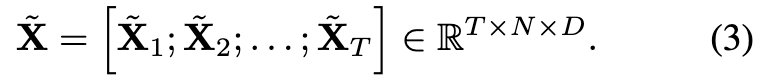
temporal projector의 핵심은 L개의 Mamba 레이어이며, 각 레이어에서 토큰에 시간 동역학 정보를 반복적으로 주입합니다.
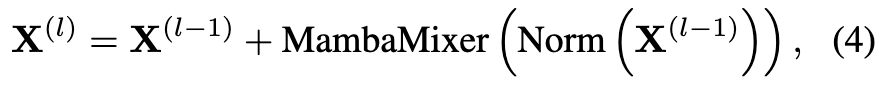
여기서 MambaMixer는 방법론 그림에 나온 것처럼 양방향 스캔을 사용해 프레임 내부(공간)와 프레임 간(시간) 의존성을 함께 포착합니다. 결과적으로 최종 토큰들은 프레임 단독 토큰이 아니라, 비디오 전역 문맥의 정보를 가지고 있는 토큰이 됩니다.
2.3. Training-Time Token Compression
긴 비디오를 LLM에 넣을 때는 보통 두 가지 문제가 먼저 발생합니다.
첫째, 모든 프레임을 그대로 처리하면 계산량이 너무 커집니다. 그래서 시퀀스 병렬화나 멀티 GPU 같은 시스템 최적화가 사실상 필요해집니다.
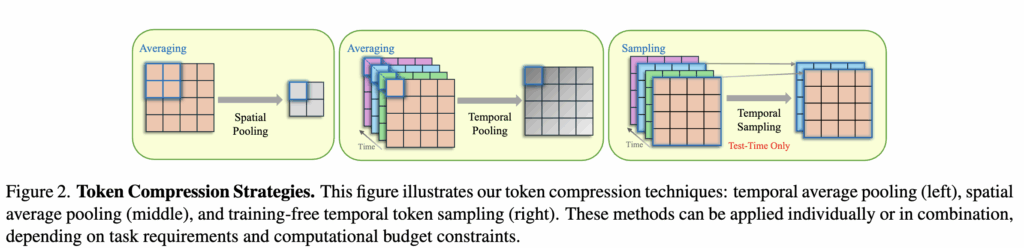
둘째, LLM은 입력 가능한 컨텍스트 길이가 제한되어 있습니다. 예를 들어 LLaMA 3의 8K 컨텍스트 기준에서 프레임당 256 토큰을 쓰면 약 32프레임 정도만 입력 가능합니다. 즉, 토큰 압축 없이 긴 비디오를 넣으면 입력 한도를 금방 넘고, 성능도 떨어지게 됩니다. 따라서 저자는 학습 중 시간 축과 공간 축에서 토큰 수를 함께 줄여서, 계산 비용을 낮추고 컨텍스트 길이 제한도 넘지 않게 하는 것을 목표로 방법론을 설계합니다. (Figure 2의 left, middle)
(a) Temporal Pooling
Figure 2 middle에 있는 Temporal Pooling부터 살펴보겠습니다.
먼저 연속 프레임은 비슷한 정보가 많아 temporal average pooling으로 k개 프레임 단위 평균을 냅니다
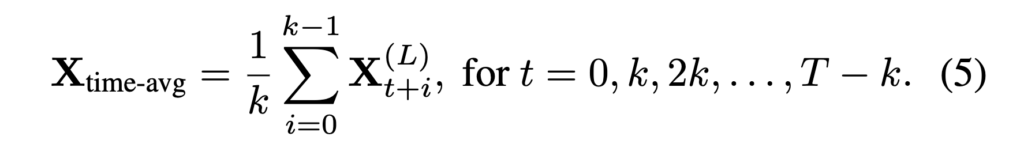
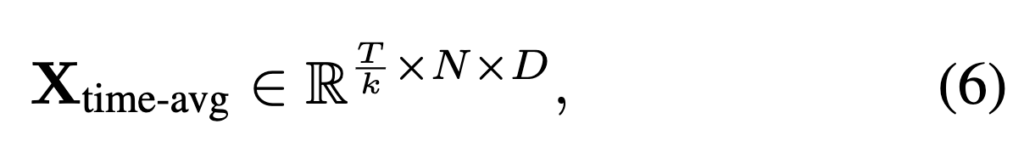
아이디어 자체 temporal average pooling을 적용하는 것이라 단순하지만 LLM이 처리하는 토큰 수를 효과적으로 감소시키면서도 중요한 정보의 손실은 최소화할 수 있다고 저자는 주장합니다.
(b) Spatial Pooling
시간축뿐 아니라 공간축도 줄이는데 여기서도 우리가 아는 average pooling을 적용하여 토큰을 압축합니다.
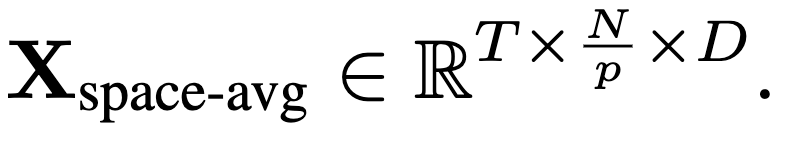
2.4. Training-Free Temporal Token Sampling
Temporal projector를 거친 뒤에는 각 시각 토큰이 시공간 정보를 함께 담게 됩니다. 즉, 각 토큰은 자기 프레임의 정보만 담는 것이 아니라 비디오 전체의 다른 프레임들에서 온 특징도 함께 반영합니다.
이처럼 전역 정보가 토큰에 인코딩되어 있기 때문에, 테스트 단계에서는 시간 축을 따라 토큰을 부분 샘플링(subsample)해도 정보 손실이나 성능 저하를 크게 유발하지 않으면서 LLM에 입력되는 토큰 수를 더 줄일 수 있습니다.
이 시간 축 토큰 부분 샘플링은 앞서 제안한 pooling 기법과 함께 써도 되고, 별도로 써도 됩니다. 프레임을 바로 샘플링해 중요한 시간 단서를 놓칠 수 있는 기존 방식과 달리, 저자 방식은 temporal encoding 이후 토큰이 가진 시공간적 풍부함을 활용한다는 점이 차별점입니다. 시간 축 토큰 샘플링 방식은 Figure 2(right)에 나와 있습니다.
이를 식으로 살펴보면, subsampling layer의 입력 토큰을 X라고 하면, 이 X는 visual encoder의 출력 X(L)일 수도 있고, 압축 모듈 출력인 Xtime-avg 또는 Xspace-avg일 수도 있습니다. 여기서 T와 N은 temporal/spatial pooling 이후의 시간·공간 차원을 의미합니다. 저자들은 시간 축에 대해 샘플링 비율 s를 두고 균일(uniform) 부분 샘플링을 적용합니다.
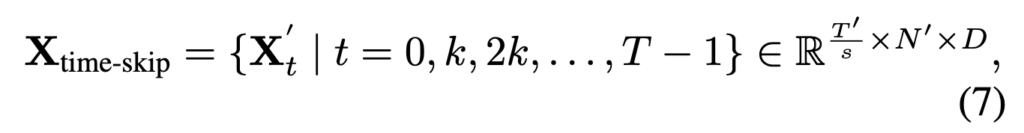
결과적으로 얻는 Xtime-skip은 시간 축 길이가 T/s로 줄어든 토큰 집합입니다.
3. Experiments
Experiment Details
Training
저자들은 비전 인코더와 LLM으로 각각 PaliGemma의 사전학습된 SigLIP Qwen2-VL을 사용하며, 학습은 multi-stage로 진행됩니다.
- 1단계: Alignment Stage
이미지 인코더와 LLM은 freeze하고, 이미지-텍스트 데이터셋 SVIT으로 Temporal Projector만 학습합니다.
Mamba 레이어가 시간 스캔뿐 아니라 이미지 내부의 공간 스캔도 수행하므로, Temporal Projector 사전학습에는 이미지-텍스트 쌍만으로도 충분하다고 저자는 설명합니다. - 2단계: SFT (Supervised Fine-Tuning)
text-only, image-text, video-text data를 포함한 대규모 데이터셋으로 세 구성요소를 모두 파인튜닝합니다.
이 단계에서 비디오 입력은 32프레임을 사용합니다.
추가적으로 training-time token compression 모듈은 128프레임 long-video 입력으로 추가 파인튜닝을 수행합니다.
Models
STORM은 NVIDIA에서 만든 VILA 모델을 베이스모델로하며 여기에 저자들이 제안한 Mamba 모듈과 압축 메커니즘을 통합합니다.
Results on Video Understanding Benchmarks
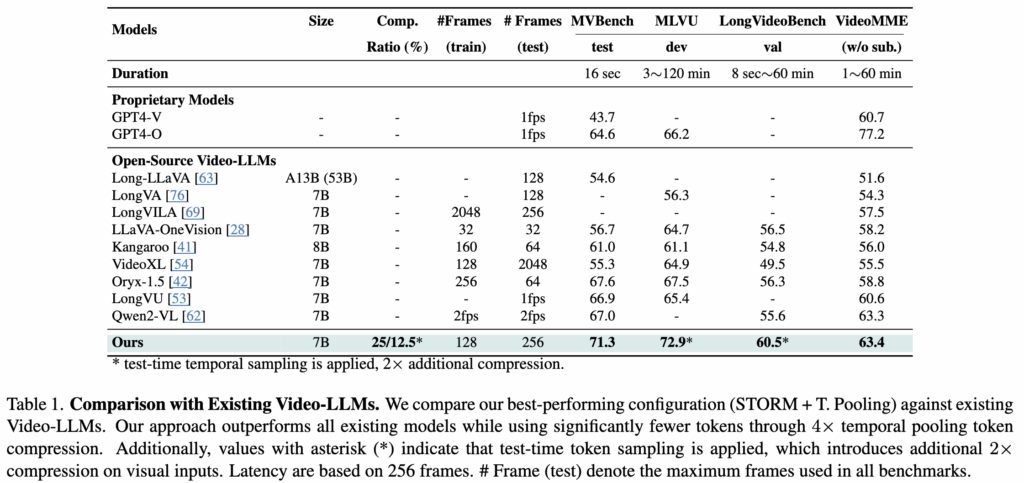
먼저, 저자들은 STORM + T. Pooling (+ T. Sampling) 설정을 기존 Video-LLM들과 비교합니다. Table 1에서 보이듯, STORM + T. Pooling은 모든 롱비디오 벤치마크에서 SOTA 성능을 달성했습니다. 여기서 STORM + T. Pooling이 LLM에 넣기 전에 시각 토큰을 원래의 25%로 압축하면서도 높은 성능을 유지했습니다. 또한 여기에 테스트 시점 시간 샘플링을 추가한 STORM + T. Pooling + T. Sampling은 효율을 더 높여 토큰 수를 12.5%까지 줄이면서도 높은 성능을 유지합니다.
STORM vs Baseline VILA
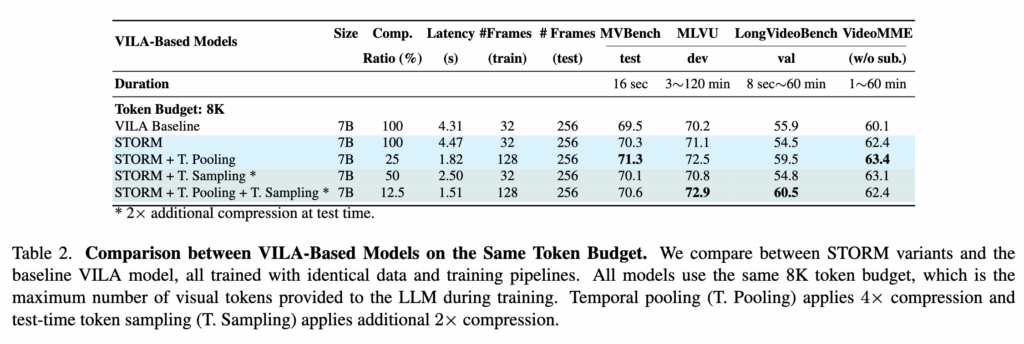
다음으로 저자들은 Table 2에서 VILA 기반 모델 내부의 ablation 실험을 통해 저자가 제안하는 모듈의 이점을 분석합니다. 먼저 VILA 베이스라인과 STORM을 비교하면, Mamba 모듈을 추가한 STORM이 4개 벤치마크 중 3개에서 성능 향상을 보이며, 특히 VideoMME에서 +2.3%의 개선을 보였습니다.
또한 테스트 시점 시간 토큰 샘플링을 붙인 STORM + T. Sampling은 효율을 더 높여 추론 시간을 43% 줄이면서도 성능을 유지하거나 소폭 향상시켰습니다(VideoMME 추가 +0.8%). 저자들은 이를 Mamba가 프레임 간 시간 정보를 효과적으로 전파해, 중복 토큰을 버려도 전체 이해력이 유지되기 때문이라고 설명합니다.
STORM + T. Pooling에서는 성능이 향상될 뿐만 아니라 효율 또한 향상되는 것을 확인할 수 있습니다. 여기에 T. Sampling을 결합하면 추론 시간을 65.5%까지 더 줄이고, VILA 대비 토큰을 12.5%만 사용하면서도 성능 저하가 없는 모습을 보입니다.
저자들은 테스트 시점 시간 샘플링의 효과가 MVBench/VideoMME보다 MLVU/LongVideoBench에서 더 크게 나타난다고 설명합니다. 그 이유는 MLVU, LongVideoBench는 롱비디오의 전역 맥락 이해가 중요하여 Mamba + 테스트 압축이 핵심 문맥 요약에 유리하고, MVBench, VideoMME는 특정 프레임의 세부 시각 정보가 중요하여 Mamba + 풀링 중심 방식이 프레임 디테일을 더 잘 보존하기 때문이라 설명합니다.
4. Analysis
Mamba Module Improves Simple Token Compression
Figure 1에서 보이듯, Mamba 기반 temporal projector는 입력 토큰을 시간·공간 축으로 함께 스캔합니다. 핵심은 압축 전에 토큰을 먼저 정제한다는 점입니다. 그래서 단순 압축에서 자주 사라지는 중요한 단서(예: 어떤 위치의 프레임이 풀링됐는지 같은 정보)를 더 잘 남길 수 있습니다. 결과적으로 baseline보다 단순한 압축 기법도 긴 비디오에서 더 안정적으로 작동합니다(Table 4)
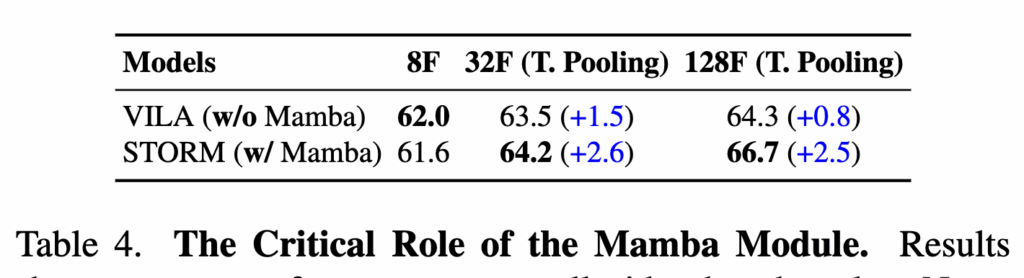
실험에서도 이 경향을 확인할 수 있는데 STORM은 입력 길이가 길어질수록 성능이 꾸준히 오르는 반면 baseline VILA는 개선 폭이 작습니다. 즉, 긴 입력에서 성능을 지키며 압축하기 위해 Mamba 모듈이 효과적이라는 것을 알 수 있습니다.
Token Compression Improves Model Efficiency
Figure 3에서 효율 분석을 제시합니다.
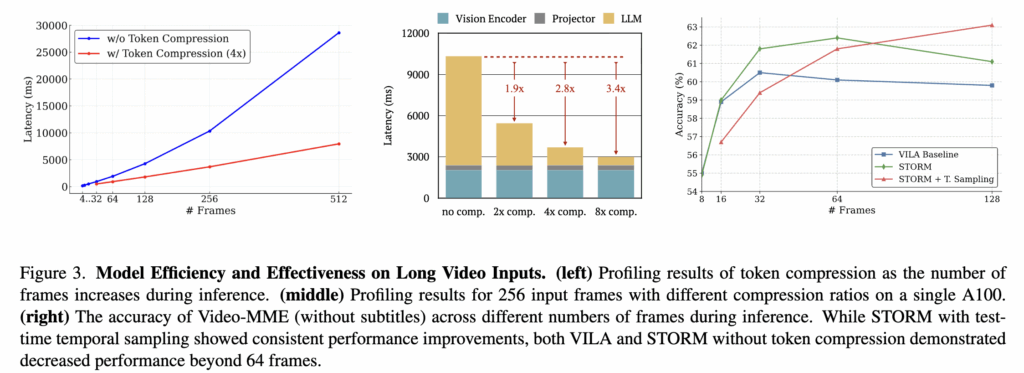
Figure 3 (left)에서는 압축 유무와 입력 프레임 수에 따른 지연시간을 비교합니다. 시퀀스 길이가 늘어날수록 두 설정의 지연 격차가 크게 벌어집니다. Figure 3 (middle) 256프레임 처리 시 모듈별 지연시간 측정 결과입니다. 압축이 없으면 전체 지연의 약 80%가 LLM에서 발생합니다. 압축비 4를 쓰면 LLM 지연이 원래의 약 35%까지 줄어듭니다. 중요한 건, temporal projector 덕분에 성능을 크게 해치지 않고 압축이 가능하다는 점입니다. 그리고 일부 벤치마크에서는 계산량이 줄었는데 성능이 오히려 좋아지는 모습까지 보입니다. Figure 3 (right)에서는 VideoMME에서 프레임 수를 늘려가며 성능이 어떻게 변화하는지 리포팅합니다. VILA baseline은 32프레임까지 상승 후 하락하며 압축을 사용하지 않은 STORM은 64프레임까지 유지 후 소폭 하락합니다. STORM + temporal sampling에서는 128프레임까지 성능을 계속 개선하며 토큰은 50% 압축시킬 수 있습니다. 즉, 128프레임의 STORM + T. Sampling은 다른 두 모델의 64프레임과 같은 수준의 시각 토큰만 쓰고 더 긴 문맥을 활용합니다.
리뷰 잘 읽었습니다
아무래도 Temporal projector(Mamba) 설계 관점에서 궁금증이 생기네요.
MambaMixer의 ‘양방향 스캔’이 causal한 Video-LLM 세팅과 어떻게 공존하는지 궁금합니다
그러니까 projector는 양방향으로 시간 정보를 섞고, 최종적으로 LLM은 causal generation을 하는 것 같습니다. 이때 projector가 미래 프레임 정보를 현재 토큰에 섞는 게 허용되는 건지 아니면 online/streaming에서도 가능한 구조인건가요?
안녕하세요 주영님 좋은 리뷰 감사합니다.
먼저 Projector의 양방향 시간 혼합과 LLM의 causal generation은 오프라인 설정에서는 충돌하지 않습니다. 하지만 이를 스트리밍까지 요구한다면 projector를 causal 기반으로 재설계해야 할 것 같습니다.
감사합니다.
안녕하세요 의철님, 좋은 리뷰 감사합니다. temporal encoder를 통해 토큰에 시공간 정보를 주입해서 전역적 정보를 담아두었기 때문에, 단순한 방식으로 토큰을 압축해도 비디오 이해 능력이 좋아진다고 이해했습니다.
질문이 하나 있는데, Mamba를 설명해주실 때 ‘지금 들어온 토큰이 중요하면 더 살리고, 아니면 줄이는 식으로 동적으로 정보 흐름을 조절’한다고 하셨는데, 특정 기준에 의해 결정되는 건가요? 특정 토큰이 중요한지 어떻게 판단하는지 궁금합니다.
안녕하세요 재윤님 좋은 질문 감사합니다.
Mamba에서 특정 토큰의 중요도는 규칙으로 지정하는 것이 아니라, 입력 x로부터 생성되는 게이팅 계수를 통해 데이터 기반으로 학습됩니다. 즉, 어떤 토큰이 중요한지는 모델이 최종 목적 손실을 최소화하도록 end-to-end로 학습하면서 결정됩니다
감사합니다.
안녕하세요 의철님 리뷰 감사합니다
Temporal projector를 거친 시각토큰이 시공간 정보를 함께 담고 있다보니 해당 프레임만이 아니라 앞뒤 문맥이 함께 반영되어 있어서 나중에 토큰을 일부는 버려도 남아있는 토큰이 담고있는 정보로도 어느정도 성능 유지가 가능하다는 것 같은데
이때 Mamba temporal projector가 실제로 temporal reasoning 능력 자체를 강화 한건지 아니면 중복 제거 덕분에 LLM 부담이 줄어서 간접적으로 좋아진건지 따로 논문에 언급하거나 분석한게 있는지 궁금합니다!
안녕하세요 찬미님 좋은 질문 감사합니다.
논문에서 projector로 토큰 자체가 시공간 요약을 갖게 되어 reasoning에 유리하다는 주장과 redundancy 감소와 LLM 처리 부담 완화를 함께 이야기하지만 둘 중 무엇이 본질적 원인인지 분리해 증명하는 분석은 없고 대신 동일 토큰 예산 비교를 통해 성능 향상이 단순히 LLM의 입력 수를 줄여서 발생한 것은 아니라는 것을 알 수 있습니다.
감사합니다.