Qwen3-VL을 바탕으로 Universal Multimodal Retrieval and Ranking 연구를 리뷰해보려고 합니다.

- Venue: Arxiv 2026 (2026.01.21.)
- Authors: Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, Junyang Lin
- Affiliation: Alibaba Group (Tongyi Lab)
- Title: Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
- Code: HuggingFace , GitHub
0. Universal Multimodal Retrieval
본 논문이 다루는 태스크는 저자들이 Universal Multimodal Retrieval이라 부르는 설정입니다. 이는 입력 쿼리나 검색 대상의 모달리티가 고정되어 있지 않고, 텍스트, 이미지, 문서 이미지, 비디오 등 다양한 형태의 입력이 자유로운 멀티모달 검색 문제를 의미합니다. 예를 들어 텍스트 쿼리로 이미지를 검색하거나, 이미지나 비디오를 쿼리로 사용해 텍스트 문서를 찾는 경우 모두 하나의 태스크로 포함됩니다.
그러다보니 특정 모달리티에 특화된 검색 모델보다, 서로 다른 입력을 하나의 의미 공간에서 비교할 수 있는 통합 표현 학습이 핵심입니다. 즉, 중요한 것은 입력의 형태가 아니라 그 입력이 담고 있는 의미이고, 검색 시스템은 모달리티에 관계없이 의미적으로 유사한 항목을 찾아야 합니다. 본 논문은 이러한 관점에서 멀티모달 검색을 하나의 통합된 retrieval 문제로 재정의합니다.
1. Introduction
멀티모달 검색 파이프라인에서 핵심은 공통 표현 공간을 학습하는 Embedding 모델 과, 검색 결과의 관련도를 정밀하게 조정하는 Reranking 모델입니다. CLIP 이후 대규모 VLM이 등장하면서, 최근 연구들은 VLM이 이미 갖고 있는 cross-modal alignment 능력을 활용해 통합 멀티모달 임베딩을 학습하는 방향으로 확장되고 있습니다.
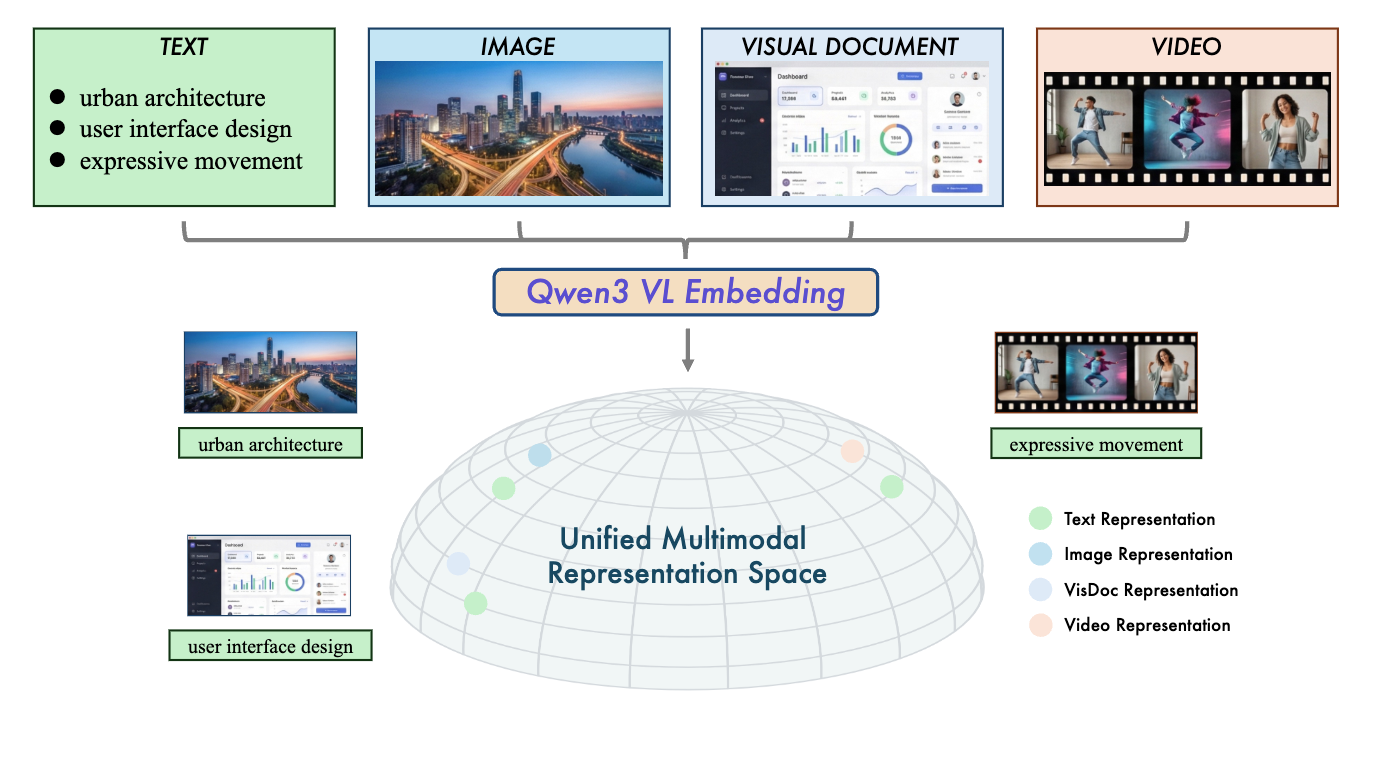
상단 그림처럼, 본 논문에서는 텍스트, 이미지, 문서 이미지, 비디오와 같이 서로 다른 형태의 입력을 Qwen3-VL-Embedding을 통해 하나의 Unified Multimodal Representation Space로 매핑하고, 동일한 의미를 가진 개념들은 모달리티와 관계없이 가까운 위치에 정렬되도록 학습합니다. 예를 들어 ‘urban architecture’라는 텍스트와 해당 개념을 담은 이미지나 비디오는 같은 의미적 위치로 수렴하는 것이 목적이죠
이를 바탕으로 본 논문은 Qwen3-VL을 기반으로 한 Qwen3-VL-Embedding과 Qwen3-VL-Reranker 모델을 제안했습니다. 멀티모달 임베딩과 리랭킹을 하나의 일관된 구조로 통합하였다는 것이 제법 인상적인데요, 뿐만 아니라 다양한 멀티모달 검색 벤치마크에서 높은 성능과 실용성을 동시에 달성할 수 있음을 보이기도 했죠. 본격적인 리뷰 시작하겠습니다.
2. Method
저자들은 Universal Multimodal Retrieval을 위한 방법을 제안하였는데요. 기본적으로 Qwen3-VL을 공통 백본으로 사용하고, 멀티모달 검색 파이프라인에서 서로 다른 역할을 수행하는 Embedding 모델과 Reranking 모델을 분리해 설계한 것이 특징입니다.
2.1 Overall Architecture: Embedding vs Reranking
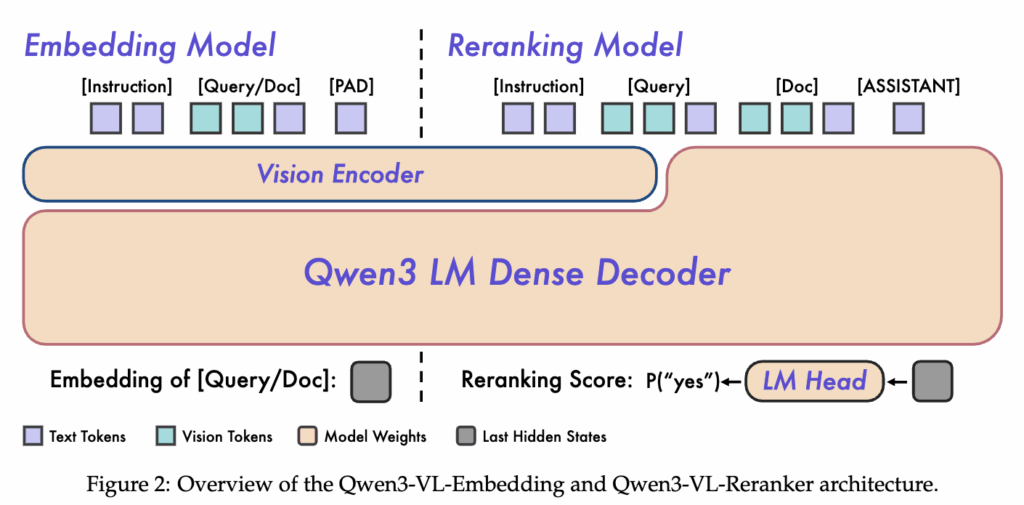
Qwen3-VL-Embedding과 Qwen3-VL-Reranker는 동일한 Qwen3 LM Dense Decoder를 공유하지만, 입력 구성과 출력 형태에서 차이를 보입니다. Embedding 모델은 Query 또는 Document를 독립적으로 인코딩해 고정 차원의 벡터를 생성하고, Reranking 모델은 Query와 Document를 함께 입력받아 두 입력 간의 상호작용을 직접 모델링합니다.
2.2 Qwen3-VL-Embedding
Qwen3-VL-Embedding의 목표는 텍스트, 이미지, 문서 이미지, 비디오와 같이 서로 다른 형태의 입력을 하나의 Unified Multimodal Representation Space로 매핑하는 것입니다. 이를 위해 본 논문에서는 모든 입력을 instruction + instance 형태로 고정하였습니다

상단 그림처럼 임베딩 모델의 입력은 system 영역에 instruction이, user 영역에 instance가 위치하는 구조인데요. 여기서 instruction은 모델이 수행해야 할 검색 기준이나 의미 정렬 방식을, instance는 실제로 임베딩하고자 하는 입력 데이터에 해당합니다.
그리고 instance는 query에 해당하는 실제 검색 대상이며, 모달리티에 관계없이 동일한 입력으로 들어갑니다. 이러한 설계를 통해 Qwen3-VL-Embedding은 텍스트–텍스트, 텍스트–이미지, 이미지–비디오 등 다양한 조합의 입력을 하나의 모델로 자연스럽게 처리할 수 있었습니다.
2.3 Qwen3-VL-Reranker
Qwen3-VL-Reranker는 Embedding 단계에서 검색된 후보 document들 중, 실제로 query에 가장 적합한 항목을 선별하기 위한 모델입니다. Embedding 모델이 공통 표현 공간에서의 근사적인 유사도를 계산한다면, Reranker는 Query와 Document를 동시에 고려해 보다 정밀한 관련도 판단을 수행하는거죠. 이를 위해 본 논문에서는 cross-encoder 구조를 사용했습니다.

상단 그림처럼, Reranker의 입력 역시 system 영역에 instruction이 위치하며, 이 instruction은 모델에게 주어진 Query와 Instruction을 기준으로 Document가 요구 조건을 만족하는지 판단하라 는 명시적인 지시를 제공하죠. 특히 출력은 “yes” 또는 “no”로 제한함으로써, 이는 생성 자체가 목적이 아니라 판단(judgement)이 목적임을 분명히 하고자 하였습니ㅐ다
이때 Reranker의 최종 출력은 텍스트 응답 자체가 아니라, “yes” 토큰에 대응되는 likelihood 또는 score라고 합니다. 이 값은 해당 Document가 Query에 얼마나 적합한지를 나타내는 정량적 지표로, 검색 결과의 최종 순위를 결정하는 데 활용됩니다. 즉, Reranker는 언어 모델의 생성 능력을 활용하되, 이를 확률 기반의 relevance estimation 문제로 변환해 사용하고 있다고 볼 수 있습니다.
정리하면, Embedding이 빠르고 범용적인 후보 검색을, Reranker는 instruction에 기반한 정밀 판단을 통해 최종 검색 품질을 끌어올리는 역할을 수행합니다
3. Data
3.1 Dataset Format
본 논문에서 가장 중요한 데이터 설계의 특징은, 다양한 멀티모달 태스크를 개별 문제로 다루지 않고 하나의 Universal Multimodal Retrieval 문제로 통합했다는 점입니다. 이를 위해 저자들은 모든 학습 데이터를 Instruction–Query–Document–Relevance라는 공통된 형식으로 정의하였습니다.
여기서 핵심은 Query와 Document가 특정 모달리티로 제한되지 않는다는 점입니다. Query는 텍스트, 이미지, 비디오 혹은 이들의 조합일 수 있으며, Document 역시 동일하게 멀티모달 형태를 가질 수 있습니다. 이 구조 덕분에 이미지 분류, 비디오 QA, 멀티모달 검색과 같은 서로 다른 태스크들이 모두 “주어진 Query에 가장 관련 있는 Document를 찾는 문제”로 통합될 수 있죠.
Instruction은 해당 데이터셋에서 무엇을 ‘관련 있음(relevant)’으로 볼 것인지를 정의하는 역할을 합니다. 예를 들어, 단순한 시각적 유사도를 찾는 것인지, 특정 행동이나 의미를 만족하는지를 판단하는 것인지가 instruction을 통해 명시됩니다.
마지막으로 Relevance 는 각 Query에 대해 어떤 Document가 positive이고, 어떤 Document가 negative인지를 의미합니다. 여기서 positive/negative는 단순한 정답 여부가 아니라, instruction에서 정의된 기준을 만족하는지 여부에 따라 결정된다고 합니다.
3.2 Data Synthesis
저자들은 실제 수집 데이터에 의존하지 않고 대규모 데이터를 합성(data synthesis)하였습니다. 구체적으로는, 고품질의 이미지·비디오 seed pool을 먼저 구축한 뒤, 이를 기반으로 다양한 retrieval 시나리오를 생성한 것이죠. 이는 단순히 시각적 유사성만을 반영하는 것이 아니라, 의미 수준의 다양성과 난이도를 함께 확보하기 위함이었습니다
데이터는 크게 이미지 기반 태스크와 비디오 기반 태스크로 나뉩니다. 이미지의 경우, 분류, 질문 응답, 이미지 검색과 같은 다양한 태스크를 retrieval 문제로 변환해 구성하였습니다. 예를 들어, 이미지 분류 태스크에서는 이미지가 Query가 되고, 카테고리 레이블이 Document 가 되죠. 이미지 검색 태스크에서는 반대로 텍스트가 Query가 되고, 이미지가 Document가 됩니다. 이때 Query는 단순한 객체 나열부터, 추상적인 상황 설명이나 조합적 조건을 포함하는 문장까지 다양하게 설정됩니다
비디오 데이터 역시 유사한 방식으로 구성되지만, 시간적 정보가 추가된다는 점에서 더 다양한 태스크가 포함됩니다. 비디오 분류, 비디오 QA, 비디오 검색, 그리고 특정 구간을 찾는 moment retrieval까지 모두 retrieval 형태로 변환됩니다. 이 과정에서 Query는 비디오 자체일 수도 있고, 텍스트 설명일 수도 있으며, Document는 전체 비디오이거나 특정 시간 구간이 됩니다.
3.3 Hard Negative Mining
instruction 기반 데이터 구성뿐 아니라, positive refinement와 hard negative mining을 통해 학습 데이터의 품질을 추가로 정제하였는데요. 이는 단순히 많은 데이터를 사용하는 것보다, 어떤 negative를 학습에 포함시키느냐가 표현 학습 성능에 중요하기 때문이죠
먼저 embedding 모델을 사용해 각 Query에 대해 상위 K개의 candidate Document를 검색합니다. 이후 relevance filtering 단계에서, 일정 임계값 이상으로 유사도가 높은 positive가 존재하지 않는 Query는 제거하여 noisy한 학습 샘플을 걸러냅니다.
Hard negative는 positive와 완전히 무관한 document가 아니라, positive와 유사하지만 instruction 관점에서는 틀린 애매한 document입니다. 이를 위해 positive 문서들의 평균 점수를 기준으로, 그와 근접한 점수를 가지는 non-positive 문서만을 hard negative로 사용합니다.
4. Training Strategy
본 논문은 Qwen3-VL-Embedding과 Qwen3-VL-Reranker를 단일 단계로 학습하지 않고, 여러 단계에 걸쳐 성능과 데이터 품질을 함께 올리는 multi-stage training 전략을 사용합니다. 아래 그림은 이러한 학습 과정을 보여주는데, 전체 흐름은 대규모 데이터 → 정제된 데이터 → 정밀한 판단 모델 → 다시 Embedding 강화 라는 구조로 설계되어 있습니다.
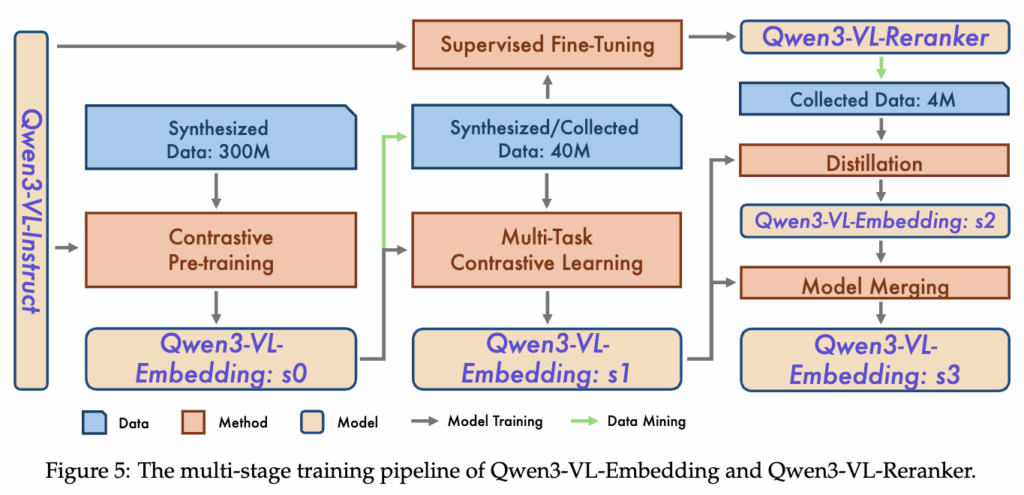
이 구조의 핵심 목적은 두 가지입니다. 첫째, 대규모로 확보 가능한 합성 데이터의 장점을 최대한 활용하되, 노이즈로 인한 성능 저하를 방지하는 것입니다. 둘째, 학습이 진행될수록 모델이 더 좋은 데이터를 스스로 선별하도록 만들어, 데이터와 모델을 함께 부트스트랩하는 것입니다.
Stage 1: Contrastive Pre-training (Qwen3-VL-Embedding: s0)
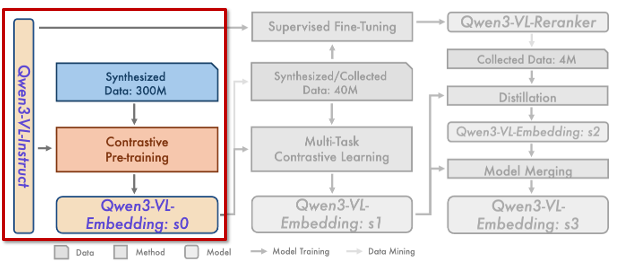
그림의 왼쪽을 보면, 첫 단계에서는 약 3억 개의 대규모 합성 데이터가 사용됩니다. 이 데이터는 품질은 균일하지 않지만, 모달리티와 태스크 다양성이 매우 크다는 장점이 있죠. 저자들은 이 데이터를 활용해 Qwen3-VL-Embedding을 contrastive learning 방식으로 사전 학습합니다.
이 단계의 목표는 정밀한 relevance 판단이 아니라, 멀티모달 입력을 공통 표현 공간에 대략적으로 정렬하는 초기 능력을 확보하는 것입니다. 즉, “어느 정도 비슷한 것들은 가까이 모이게 만드는” 기반 표현을 만드는 단계라고 볼 수 있습니다. 이 과정을 통해 초기 Embedding 모델인 Qwen3-VL-Embedding: s0가 생성됩니다.
Stage 2: Multi-task Contrastive Learning & Reranker Training (s1)
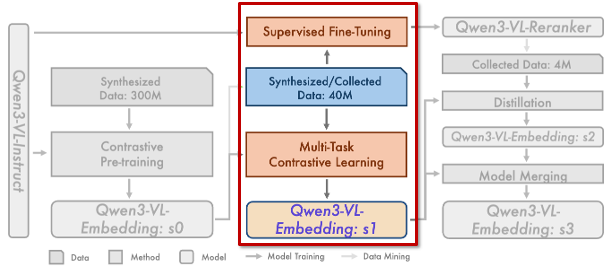
두 번째 단계에서는 여기서는 공개 데이터와 그리고 일부 선별된 합성 데이터를 함께 사용하여 태스크 균형과 데이터 품질을 동시에 고려한 학습을 수행합니다. 중요한 점은, 이 시점부터는 1단계에서 학습된 s0 모델을 활용해 데이터 마이닝을 수행한다는 것입니다.
즉, Embedding 모델이 어느 정도 의미 구조를 이해하게 된 상태에서, 이를 이용해 더 “쓸 만한” 학습 샘플을 고르는 단계입니다. 이 데이터로 다시 multi-task contrastive learning을 수행해 Qwen3-VL-Embedding: s1을 학습합니다.
동시에, 이 단계에서 Qwen3-VL-Reranker가 처음으로 학습됩니다. Reranker는 retrieval 중심 데이터만을 사용해, Query와 Document를 함께 보고 relevance를 판단하는 역할에 특화됩니다. 이 시점부터 Embedding은 recall을, Reranker는 precision을 담당하는 구조로 분리됩니다.
Stage 3: Reranker-guided Distillation & Model Merging (s3)
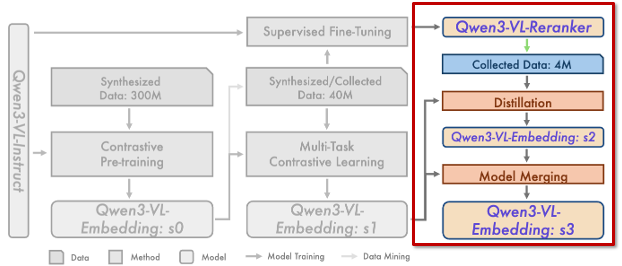
마지막 단계는 이미 학습된 Reranker가 relevance 판단에 있어 Embedding보다 더 강한 감독 신호를 제공할 수 있다고 보고, 이를 다시 Embedding 학습에 활용합니다.
Reranker를 사용해 소규모 고품질 데이터에 대해 fine-grained relevance score를 생성하고, 이를 supervision으로 Embedding을 다시 학습합니다. 이 과정을 통해 Qwen3-VL-Embedding: s2가 만들어지는데, retrieval 성능은 크게 향상되지만 분류나 QA 태스크에서는 다소 성능 저하가 발생합니다.
이를 보완하기 위해, 저자들은 s1과 s2를 모델 병합(model merging) 방식으로 결합하였는데요. 그 결과 생성된 최종 모델이 Qwen3-VL-Embedding: s3이며, 이는 retrieval 성능과 범용 태스크 성능 사이에서 가장 균형 잡힌 결과를 보였다고 합니다
5. Experiment
본 논문은 Qwen3-VL-Embedding과 Qwen3-VL-Reranker를 Universal Multimodal Retrieval 관점에서 평가합니다. 따라서 실험 역시 특정 태스크 하나에 국한되지 않고, 텍스트·이미지·비디오·문서 이미지를 포함한 다양한 멀티모달 검색 시나리오 전반에서 수행됩니다.
5.1 Evaluation Setup
Embedding 모델은 주로 MMEB-V2와 MTEB(Multilingual) 벤치마크를 중심으로 평가됩니다. MMEB-V2는 멀티모달 입력 간 의미 정렬 능력을 평가하는 데 초점을 둔 벤치마크로, 다양한 모달리티 조합을 포함합니다. 반면 MTEB는 텍스트 기반 검색과 분류 태스크를 포함하고 있어, 멀티모달 모델이 텍스트-only 환경에서도 성능 저하 없이 작동하는지를 확인하기 위한 용도로 사용됩니다.
Reranker 모델은 image retrieval, video retrieval, moment retrieval, visual document retrieval과 같이 retrieval 중심 태스크에서 평가됩니다. 이때 Reranker는 Embedding으로 추려진 후보들에 대해 재정렬을 수행하는 방식으로 사용됩니다.
5.2 Embedding Model Performance
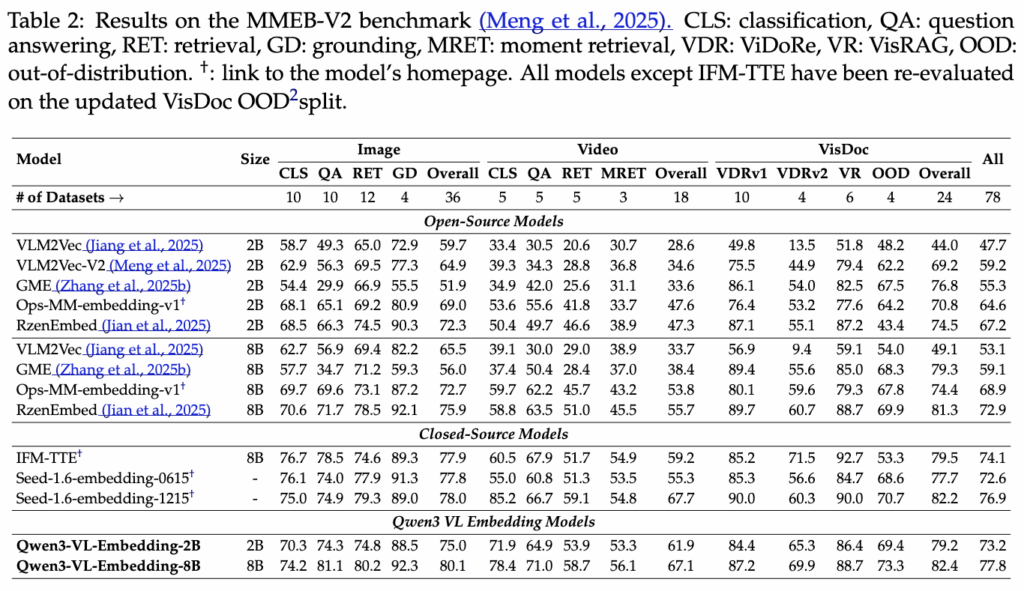
표를 보면 Qwen3-VL-Embedding-8B는 전체 평균(All) 기준으로 77.8점을 기록하며, 공개 모델뿐 아니라 일부 closed-source 모델을 포함해 가장 높은 성능을 보여씁니다. 특히 Image, Video, VisDoc 세 영역 모두에서 고르게 높은 점수를 기록했다는 점이 인상적인데, 이는 특정 모달리티에 치우치지 않고 공통 표현 공간을 안정적으로 학습했음을 의미한다고 합니다.
그리고 Qwen3-VL-Embedding이 retrieval(RET, MRET)뿐 아니라 classification(CLS), question answering(QA)과 같은 태스크에서도 어느정도 성능을 보이는데요. 이는 Embedding 모델이 retrieval 전용 표현에만 특화된 것이 아니라, 보다 범용적인 의미 표현을 유지하고 있음을 보여주는 결과라고 합니다
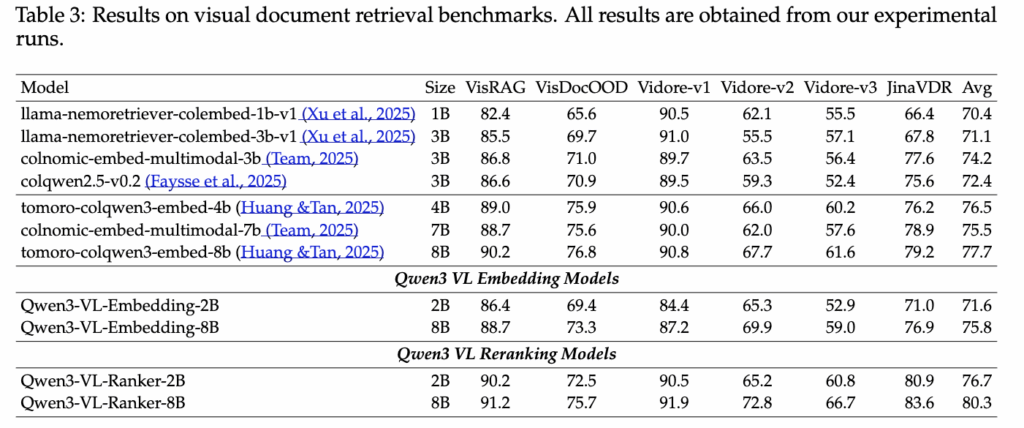
Table 3은 보다 retrieval 중심적인 벤치마크 결과를 정리한 표로, visual document retrieval과 관련된 다양한 실제 검색 시나리오에서의 성능을 비교였습니다. 먼저 Embedding 모델만 비교했을 때, Qwen3-VL-Embedding-8B는 평균 성능에서 기존 멀티모달 임베딩 모델들과 유사하거나 소폭 높은 수준을 보입니다. 이는 Embedding 단독으로도 충분히 강력한 recall 성능을 제공한다는 점을 보여줍니다.
하지만 표의 하단을 보면, Qwen3-VL-Reranker가 적용되었을 때 성능이 크게 상승하는 것을 확인할 수 있습니다. Qwen3-VL-Reranker-8B는 평균 80.3점으로, Embedding 단독 사용 대비 뚜렷한 성능 향상을 보입니다. 특히 VisDocOOD, Vidore-v3와 같이 문서 구조 이해나 시간적 맥락이 중요한 태스크에서 개선 폭이 더 크게 나타났습니다
이 결과는 Reranker가 단순한 후처리 단계가 아니라, Query–Document 간의 fine-grained 관계를 실제로 학습하고 있음을 보여주는 증거라고 볼 수 있다고 하네요. 즉, Embedding이 넓은 후보를 안정적으로 모아주는 역할을 수행하고, Reranker가 instruction을 기준으로 정밀한 판별을 수행함으로써 전체 검색 파이프라인의 성능이 완성되는 구조였습니다
5.3 Multilingual Generalization
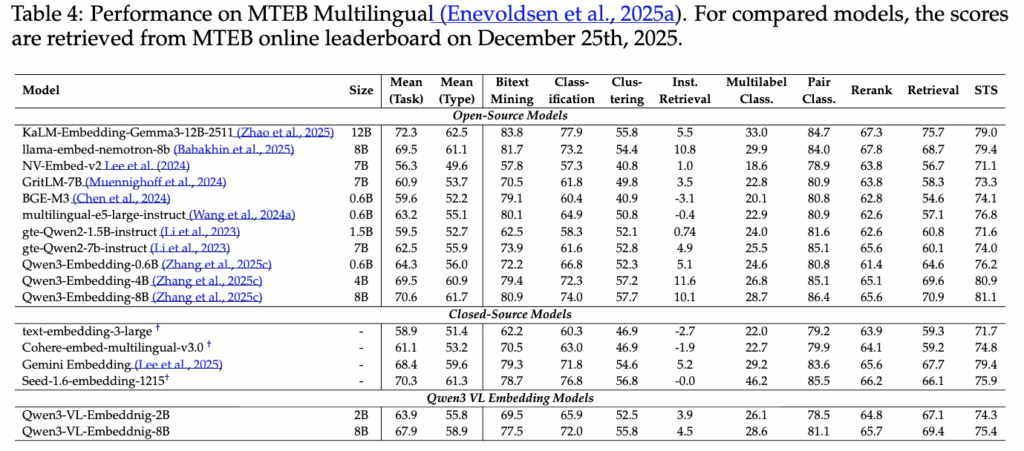
Table 4는 MTEB Multilingual 벤치마크 결과로, 텍스트 중심의 다국어 태스크에 대한 일반화 성능을 평가합니다.
흥미로운 점은 Qwen3-VL-Embedding이 멀티모달 모델임에도 불구하고, 다국어 텍스트 임베딩 태스크에서도 경쟁력 있는 성능을 보였다는 점입니다. 이는 모델이 단순히 시각–언어 정합에만 최적화된 것이 아니라, instruction 기반 학습을 통해 의미 공간 자체를 안정적으로 학습했음을 의미합니다.
5.4 Reranking
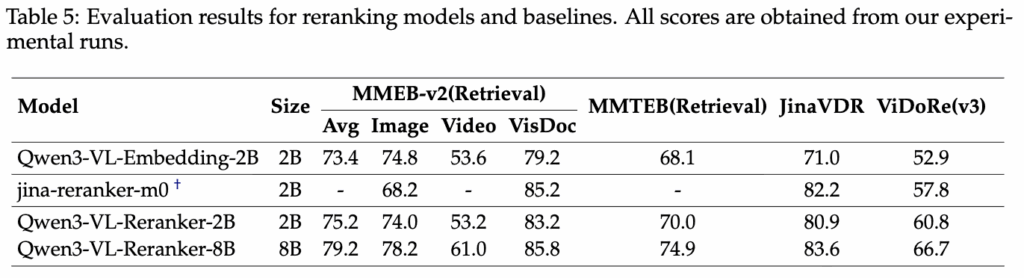
Table 5는 reranking 모델의 성능을 직접 비교한 결과입니다. Qwen3-VL-Reranker는 이미지·비디오·문서 검색 전반에서 기존 임베딩 단독 방식보다 성능이 좋았고 비디오와 문서 검색에서 그 효과가 뚜렷했습니다 이는 reranker가 embedding 단계에서 포착하기 어려운 세밀한 의미 차이와 instruction 조건을 토큰 수준 상호작용으로 보완할 수 있기 때문입니다.
6. Conclusion
이 논문은 멀티모달 임베딩과 리랭킹을 개별 태스크 최적화 문제가 아닌, instruction 기반의 범용 검색 문제로 재정의하며 Qwen3-VL-Embedding과 Qwen3-VL-Reranker라는 파이프라인을 제안했습니다. 대규모 합성 데이터, multi-stage 학습 방식, 그리고 embedding–reranking의 역할 분리를 통해 이미지, 비디오, 시각적 문서 전반에서 뛰어난 성능을 달성했다는 점이 인상적이었습니다. 비록 비디오의 시간적 특성을 깊게 다루지는 않지만, 본 연구는 향후 비디오 특화 temporal modeling 연구로 확장되는 데에 베이스로도 활용할 수 잇지 않을까하는 생각이 듭니다.
좋은 리뷰 감사합니다.
modality-agnostic한 task라니, 기술의 발전이 무섭네요…
궁금한게 Qwen3-VL-Embedding은 어떤 모달리티의 데이터가 들어와도 동일한 임베딩 공간에 projection 시켜야 하는데, 그럼 모달리티별로 특화된 인코더가 있는건가요? ‘모든 학습 데이터를 Instruction–Query–Document–Relevance라는 공통된 형식으로 정의’했다고 하니 입력 형태를 모두 동일하게 맞춰주는건가요?
Qwen3-VL-Embedding은 모달리티별로 완전히 분리된 임베딩 공간을 쓰는 방식이 아니라, 모달리티별 인코더를 거친 입력을 하나의 공통 표현 공간으로 정렬(alignment)하는 구조입니다. 이미지·비디오 입력은 비전 인코더를 통해 비전 토큰으로 변환되고, 텍스트는 텍스트 토큰으로 처리되지만, 이후에는 동일한 Qwen3-VL 백본에서 joint representation을 학습하는 구조이죠
Instruction–Query–Document–Relevance라는 공통 포맷은 입력 의미를 통일하기 위한 것이지, 모든 입력을 동일한 모달리티로 변환한다는 뜻은 아닙니다. 즉 입력 단계에서는 모달리티별 처리가 유지되며, 학습 과정에서 서로 다른 모달리티의 Query/Document가 동일한 의미라면 임베딩 공간에서도 가깝게 위치하도록 학습되는 구조라고 이해하면 좋을 것 같습니다
주영님 좋은 리뷰 감사합니다.
해당 방법론의 Qwen3-VL-Embedding 과정에서 정해진 instruction+instance 형태로 고정하고 있는데, 어떤 도메인인지에 대한 정보는 고려되지 않는 것 같습니다. input 형식의 다양성을 각 도메인별로 전처리하는 과정은 따로 설명이 없는 지 궁금합니다.
또한 정해진 instruction 형태가 있어서 확장에 어려움이 있지는 않을 지 궁금합니다.
Qwen3-VL-Embedding에서는 도메인별 전처리 규칙을 분리하기 보단, instruction 자체에 도메인 및 태스크 맥락을 포함시키고자 하였다고 합니다. 즉 입력 형식은 고정되어 있지만, 무엇을 관련성 판단 기준으로 삼을지는 instruction을 통해 학습되는것이죠
그리고 정해진 템플릿이 존재하는 것은 사실이지만, 이는 입력을 제한하기보다는 다양한 태스크를 하나의 retrieval 문제로 통합하기 위한 구조로 보입니다. 또한 instruction을 통해 비교적 자연스럽게 확장 가능하도록 설계된 것 아닐까 싶네요
안녕하세요 주영님 좋은 리뷰감사합니다.
리랭킹 과정에서 Embedding 후에 검색된 후보 중 더 적합한 항목을 선별한다고 하셨는데, 이 검색된 후보는 몇 개를 사용하나요? 그리고 벤치마크에서 평가에 사용된 비디오 벤치마크는 무엇인지 궁금하고, 5.4 Reranking에서 2B 모델의 성능이 떨어진 결과에 대한 분석 결과가 있는지도 궁금합니다.
감사합니다.
1. 리랭킹에 쓰는 후보 개수?
논문에서 정확한 K 값을 고정해서 명시하진 않습니다. 다만 구조상 Embedding으로 top-K 후보를 먼저 뽑고, 그 중에서만 Reranker를 적용하는 전형적인 two-stage retrieval 입니다. 따라서 실험 스케일이나 벤치마크 특성을 보면 수십 개 단위(top-20~100 수준)로 보는 게 좋을 것 같습니다
2. 비디오 벤치마크?
비디오 쪽 평가는 MMEB-v2 안의 Video Retrieval / Moment Retrieval 파트, 그리고 별도로 ViDoRe, JinaVDR 같은 retrieval 중심 벤치마크를 사용합니다.
3. 5.4에서 Reranker-2B 성능이 애매한 이유 분석?
논문에는 따로 분석이 존재하진 않긴 합니다.
다만 Reranking은 query–candidate 간 토큰 단위 상호작용이 핵심인데, 2B 모델은 긴 비디오 표현/복잡한 시각 문서/미세한 relevance 차이 를 구분하기엔 용량이 빠듯할 것 같긴 합니다. 그러다보니 embedding 단계에서는 괜찮다가도, reranking처럼 판별 난이도가 높은 단계에서는 모델 사이즈 차이가 성능으로 드러나는 것이 아닐까요
안녕하세요 좋은 리뷰 감사합니다
간단하게 궁금한점이 하나 있는데 Reranker를 query와의 적합성을 LLM을 통해 판독하게 한것으로 이해했습니다. 이것이 단순 유사도 계산과 다르게 작동하는 이유가 언급 되어있을까요?
Reranker는 refine의 역할을 한다고 보면 좋습니다.
구체적으로 말하자면, query가 요구한 조건을 document가 만족하는지를 판단하도록 설계된 것이죠.
그래서 embedding처럼 거리 기반 유사도를 보는 게 아니라, query·document·instruction을 함께 넣고 LLM의 조건 판별 능력을 활용하는 방식으로 동작합니다. Embedding을 통해 유사도 계산을 했다면, Reranker는 그 값을 바탕으로 query 와의 더 세밀한 interaction 을 통해 document를 찾아내는 것이죠
안녕하세요 주영님 좋은 글 감사합니다.
읽어오면서 궁금한 점들이 있어 질문드립니다.
1. Reasoning Model 에서 [ASSISTANT]로 되어있는 부분이 positive,negative로의 점수로 나오는 0~1의 점수로 생각하면 되나요?
2. 제가 이해하기로는 Qwen3VL-instruct 라는 사전학습된 모델을 가져와서 시작하는거로 이해를 했는데, stage 0 에서 대조학습 방식으로 3억개의 합성데이터로 재학습하는 과정에서 causal masking은 그대로 존재하는지, 혹은 없이 진행되는건지 궁금합니다. 만약 없앤다면 동일 모델 구조라지만 autoregressive하게 생성하던 모델이 모든 토큰을 참조하게 되면서 생기는 문제점이나 해결 트릭같은게 있는지 궁금합니다. (제 단순 추측이라 애초에 그런 문제가 안생길수도 있습니다..)
감사합니다.