안녕하세요, 허재연입니다. 오늘은 DETR 관련 논문을 들고왔습니다.
요즘 비전 쪽 모델 보면 DETR 구조를 기반으로 변형된 모델들이 굉장히 많고, 다양한 분야의 task에서 DETR 구조를 도입하고 있습니다. 제가 집중하고 있는 Scene Graph Generation도 그렇고, 요즘엔 뭐 Segmentation, Video Moment Retrieval 등등 워낙 다양한 vision task에서 널리 활용되고 있는 것 같습니다. 때문에 DETR구조에 대해 깊게 알고 있으면 낮선 분야라도 모델의 동작 메커니즘 이해나 깊은 분석이 더 수월한 것 같아요.
이 논문도 그런 맥락에서 인사이트를 얻기 위해 논문들을 뒤적거리다가 읽어보았습니다. 제가 베이스라인으로 삼은 VidSGG 모델이 DETR구조 기반임에도 각 쿼리들의 예측에 중복이 많아서, ‘어, 원래 DETR 예측엔 중복이 없는데 왜 이러지?’궁금해져서 서베이를 좀 해봤습니다. 지금 생각해보니 막연하게 NMS없이도 중복 예측 안되도록 잘 학습된다 정도로만 알고 있었지, 자세한 메커니즘에 대한 이해는 부족했었네요.
결론은 ‘원래 중복 방지 시그널은 GT에 매칭되지 않는 쿼리들을 전부 배경 처리(‘no object’)하는데 에서 오고, 실제로는 decoder의 Self-Attention(SA) layer에서 쿼리들 간 attention 통신 과정에서 중복적인 예측을 피하는 상호작용(internal NMS)이 일어나야 하는데, Action Genome 데이터셋의 경우 annotation이 sparse해서 베이스라인 모델이 잘못된 학습 신호를 방지하기 위해 GT와 매칭되는 쿼리들에게만 학습 신호를 주었기에(즉, 다른 쿼리들에게 no object로 penalty를 주지 않았기에) 학습 과정에서 중복 방지 신호가 사라졌다’ 정도로 낼 수 있을 것 같습니다.
이 논문을 리뷰하는 이유는 기존에 알려진 ‘DETR의 느린 수렴은 디코더 때문이다’에서 한발 더 나아가, ‘Self-Attention(SA) layer의 internal NMS 작용과, Cross-Attention(CA) layer의 여러 예측을 응집하는 작용이 서로 상충되어 수렴이 느려진다’는 분석을 제시했기 때문입니다. 이 점을 염두해둔다면 나중에 DETR 기반 모델을 바라볼 때 모델 내부 동작에 대한 더 깊은 이해가 가능해질 것 같습니다.
서론이 길었네요, 리뷰 시작하겠습니다.

앞서 얘기한 부분에 이어서 논문 내용을 좀 요약하자면 ‘DETR decoder에서 SA랑 CA가 상충하니까 그냥 브랜치 쪼개버리자’입니다.
기존 CNN기반 detector들은 그 구조가 비교적 복잡하고 anchor 설정이나 NMS 과정 등 휴리스틱한 전처리 / 후처리가 필요했습니다. 하지만 DETR이 제안되면서 그런 휴리스틱한 요소들을 효과적으로 제거할 수 있었고, 진정한 의미의 end-to-end detection이 가능해졌습니다. 하지만 vanilla DETR에도 여러 문제가 있었는데요, 가장 자주 언급되는 문제 중 하나는 수렴이 굉장히 느리고 어렵다는 점이었습니다. DETR쪽 한번 쭉 흐름 따라와보신 분들은 DETR -> Deformable DETR -> Conditional DETR -> DAB-DETR -> DN-DETR -> DINO로 이어지는 발전 과정을 잘 아실텐데요, 결국 수렴 잘 안되니 query 초기화를 잘 해보던지, attention 효율 높이기 위해 deformable attention을 추가하던지, 추가적인 학습 signal을 위해 DN loss를 추가해보던지.. 하는 흐름이었습니다. 수렴이 느린 게 디코더 때문이고, 초반에 bipartite matching이 일관적으로 되지 않아서 학습이 불안정하다. 쿼리가 너무 자유분방하게 랜덤 초기화 되어 있으니까 inductive bias를 주기 위해 position / content 나눠서 위치 잘 잡게 해보자. 이런 노력들이 있었죠.
본 논문은 조금 다른 관점으로 접근합니다. DETR 디코더 내부의 Cross-Attention과 Self-Attention layer 사이의 협력 관계에 집중한 것이죠. 저자들은 이 두 계층의 협력 과정에서 서로 다른 attention type이 실제로는 object query에 대해 서로 상충되는 영향(opposing impact)를 미친다는 점을 발견하고 제시했습니다. DETR이 잘 동작하는데 이 두 영향이 모두 중요하긴 하지만, 학습 효율성을 저하시킵니다.
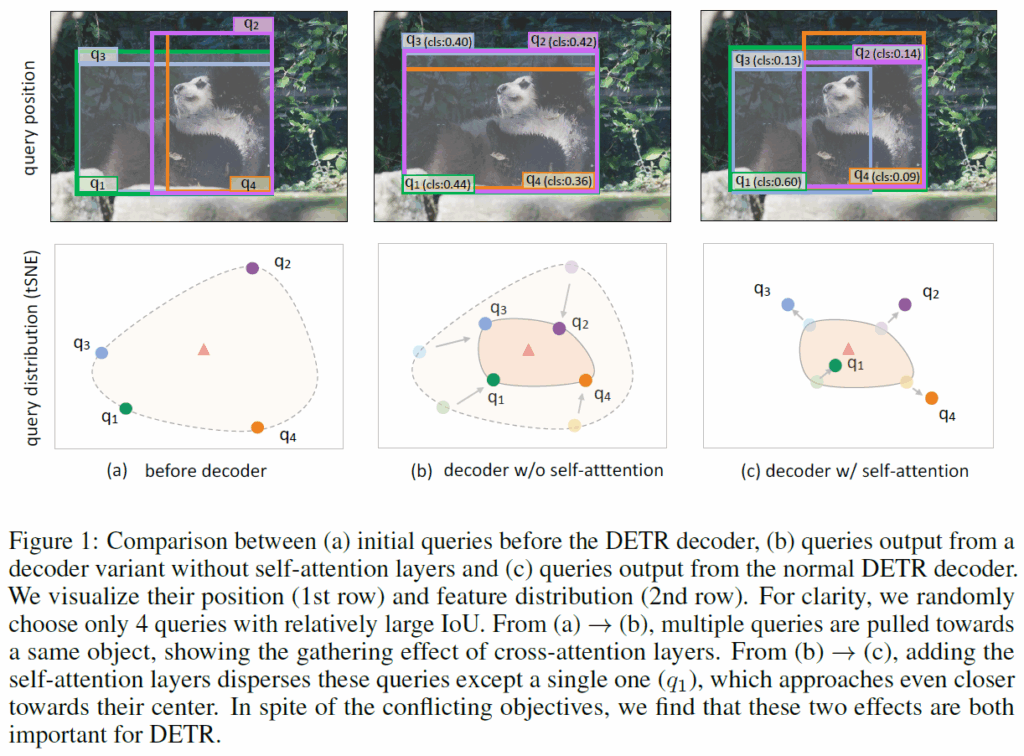
좀 더 구체적으로, 저자들은 DETR 디코더의 CA layer가 단일 object 주변으로 여러 쿼리를 응집(gather)시키는 경향이 있는 반면, SA은 이 쿼리들을 서로 멀리 분산(disperse)시킨다는 점을 관찰했다고 합니다. 위 Figure 1을 보시면 이 gather-disperse 현상은 위치 관계뿐만 아니라 feature 거리에서도 나타납니다(위 그림 t-SNE).
그림을 보시면 (a)는 DETR decoder 이전의 initial query를, (b)는 self-attention 계층을 제거한 디코더에서의 query를, (c)는 기존의 self-attention을 거치는 normal detr의 decoder query 출력을 나타낸 것입니다. 그림에서 확인할 수 있듯, 디코더의 모든 self-attention 계층을 제거하면 중복된 detection 결과가 많이 보입니다(여러 쿼리가 동일하게 곰을 localize했죠.). 반대로 SA layer를 복구시키면 쿼리들은 position / feature distance 측면에서 다시 서로 멀어지게 됩니다. 대부분의 쿼리가 원래의 중심점에서 멀어지는데, 가장 높은 score를 가진 쿼리 하나(q1)만이 중심에 더 가까워졌습니다. SA이 중복 예측 제거에 결정적이라는 것을 다시 한번 확인한 것입니다.
SA와 CA의 gather / disperse 특성 둘 다 DETR이 잘 작동하는데 중요하지만 학습을 매우 불안정하게 만듭니다. 저자들은 이 대립 구조에서 Cross-Attention을 분리하여 학습 효율성을 개선한 Divide-And-Conquer DETR (DAC-DETR)을 제안하였습니다(다들 아시다시피 Divide-and-Conquer는 자료구조/알고리즘에서 배우는 분할 정복법인데, 네이밍을 재미있게 한 것 같습니다). 방법론을 요약하면 다음과 같습니다 :
- Devide : Cross-Attention layer들의 학습에만 집중하는 추가적인 auxiliary decoder를 도입하였습니다. auxiliary decoder에는 self-attention 계층들이 없고, original decoder(O-Decoder)와 모든 파라미터를 공유합니다(CA layers 및 FFN). 이 auxiliary decoder는 cross-attention을 강조하기 위해 C-Decoder라고 지칭합니다.
- Conquer : 학습 중, DAC-DETR은 병렬로 모든 쿼리들을 두 인코더에 입력합니다. O-Decoder는 non-duplicate detection을 위해 일대일 매칭을 사용하고, 반대로 C-Decoder는 각 object에 multiple positive query들을 할당하는 일대다 매칭을 사용합니다. C-Decoder는 SA이 없어 검출 결과가 중복되기 쉽기 때문에 일대다 label 할당이 적절하고, 더 많은 positive query로 gathering 효과를 학습하는데 도움을 주게 됩니다. 학습이 완료되고 추론 시에는 C-Decoder를 제거해서 기존 모델들의 효율성을 유지하도록 하였습니다.
위 ‘devide and conquer’를 통해 DETR 학습 시 발생하는 gather 및 disperse 간 대립을 해소하고 중복 예측 제거 후 탐지 정확도를 높일 수 있었습니다. 다양한 실험을 통해 제안하는 방법론이 다양한 DETR 모델들에서 상당한 성능 개선을 만들었다고 합니다.
Methods
큰 그림은 이미 앞에서 다 설명해서, 중요한 부분만 짚어보겠습니다. 방법론은 굉장히 간단합니다.
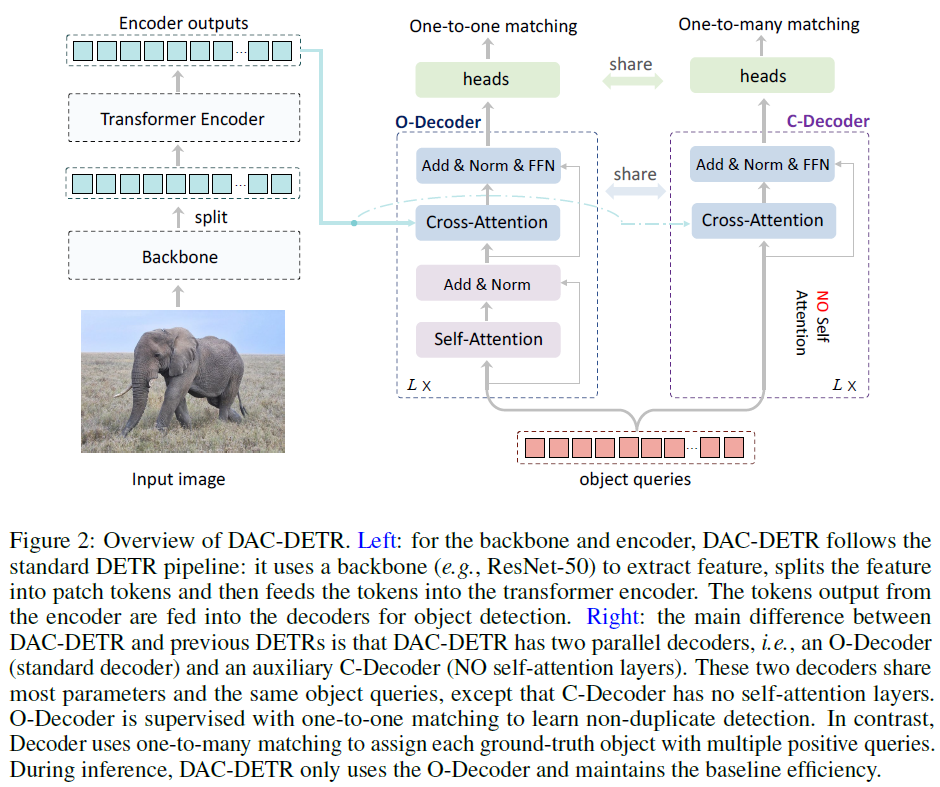
DAC-DETR은 O-Decoder와 C-Decoder 두 개의 병렬 디코더로 구성됩니다. O-Decoder는 일반적인 DETR decoder이고, C-Decoder는 SA layers를 제거한 디코더입니다. 쿼리도 두 디코더에 병렬적으로 입력됩니다.
O-Decoder
O-Decoder({Q}_{o})는 각 블럭이 Self-Attention(SA) layer, Cross-Attention(CA) layer, FFN으로 구성된 전형적인 DETR 디코더입니다. l번째 디코더 블럭은 우선 SA으로 모든 쿼리를 업데이트합니다.
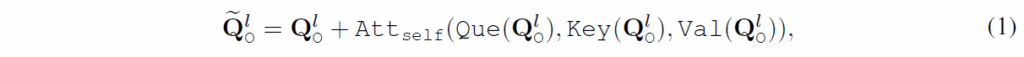
여기서 Que, Key, Val은 각각 query, key, value embedding을 projection 한 것입니다. Layer norm과 Dropout은 표기에 생략하였습니다.
이전 SA layer에서 출력된 쿼리는 다음과 같이 image feature와 CA를 수행합니다. 이 과정에서 어떤 물체가 이미지의 어디에 있는지 탐색하게 됩니다.
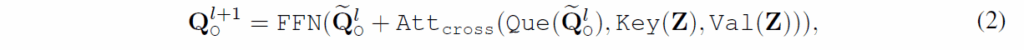
여기서 Que, Key, Val는 SA과 기호가 동일하지만 (계층이 다르니 당연히도)파라미터는 다릅니다.
마지막으로, 출력 임베딩{Q}_{o}^{l+1}은 이후 predictor head로 입력되어 label / position 예측을 수행합니다. 예측 값들은 기존 DETR과 동일하게 GT와 일대일 이분 매칭이 수행되고 hungarian loss로 학습됩니다.
C-Decoder
C-Decoder({Q}_{c})는 각 디코더 블럭에서 모든 Self-Attention 계층을 제거하고 다른 모든 파라미터를 O-Decoder와 공유합니다. 따라서 C-Decoder 쿼리는 feature embedding Z와의 Cross-Attention 및 FFN만을 거칩니다.
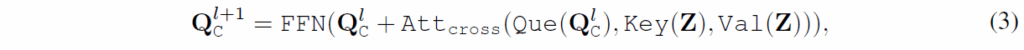
여기서 모든 모델 파라미터는 O-Decoder와 공유됩니다.
O-decoder가 이분 매칭을 수행하는 것과 달리, C-Decoder는 각 정답 object에 여러 쿼리를 할당하는 one-to-many assignment를 사용해 학습합니다. GT annotation y = [\hat{c}, \hat{b}] 및 object가 주어지면(여기서 \hat{c}, \hat{b}는 각각 class 및 bounding box), 모든 쿼리의 예측값에 대해 matching score를 다음 (4)와 같이 측정합니다.
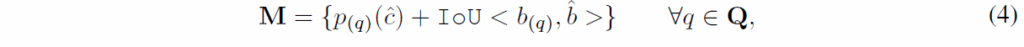
{p}_{(q)}{(\hat{c})}는 클래스 c에 대한 예측 라벨 스코어를, <,>는 예측 박스 및 GT 박스 간 IoU를 의미합니다. 정답 object에 대한 매칭 점수 M이 주어지면, 두가지 기준에 따라 여러 positive predictions를 선택합니다. 1) 매칭 점수가 임계값 t보다 커야 하고, 2) 매칭 점수가 M에서 top-k안에 들어야 합니다. 두번째 기준은 서로 다른 object에 대한 label 불균형을 막기 위한 것으로, 두 조건을 동시에 충족시켜야 합니다. 해당 object에 대해 다른 모든 예측값들은 negative label로 할당됩니다. 할당된 label을 사용하여 C-Decoder의 예측값들을 일반적인 detection loss로 학습시킵니다.
학습 중에는 {L}_{O-Decoder} 및 {L}_{C-Decoder}의 loss term을 더해 사용하고, 추론 시에는 C-Decoder를 버리고 기존의 DETR과 동일한 파이프라인을 사용해 효율성을 유지하게 됩니다.
Mechanism Analysis
how many queries can each ground-truth object gather in DAC-DETR and in the baseline?
이 분석에서는 각 object와 큰 친화도(affinity. 위 식 (4)의 매칭 점수 사용)를 갖는 쿼리의 평균 개수를 계산하였습니다. 저자의 설명에 따르면 높은 매칭 점수를 가진 쿼리는 대응하는 물체로부터 풍부한 정보를 집계하였으므로 물체를 예측할 잠재력이 높은 일종의 object proposal 같은 역할을 하기 때문에 detection이 잘 수행되는 데 있어 중요하다고 합니다. 이 매칭 쿼리들(proposal)을 바탕으로 SA layer가 중복 쿼리를 제거하고 최종적으로 예측을 수행하게 됩니다.
아래 Figure 3에는 DAC-DETR 및 Deformable-DETR 베이스라인을 비교한 것입니다.
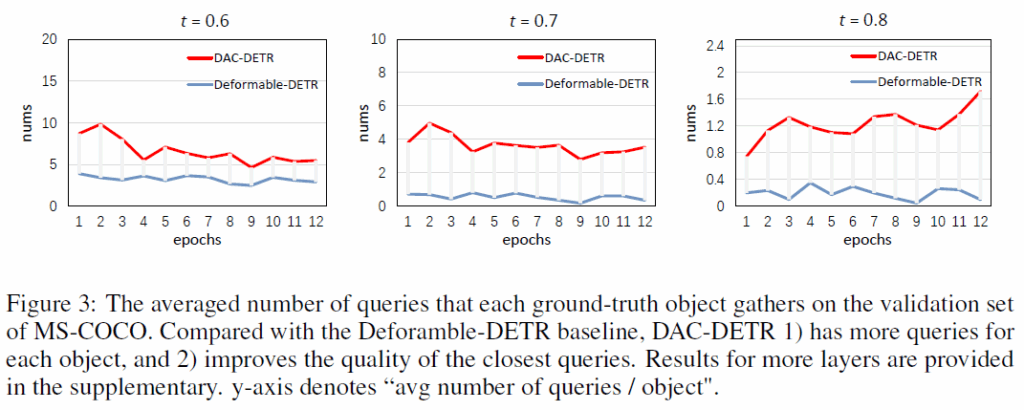
위 Figure 3을 통해 저자들은 다음과 같은 관찰 결과를 제시하였습니다 :
- Remark-1 : DAC-DETR은 각 object에 gathering된 쿼리의 수를 증가시킨다. 여러 matching threshold(ㅅ=0.6, 0.7, 0.8)에서 DAC-DETR과 베이스라인 모델을 비교할 결과, 일관적으로 각 single object에 대해 DAC-DETR이 더 많은 쿼리를 응집(gather)시키는 것을 관찰하였다(모든 쿼리의 개수는 baseline과 DAC-DETR이 동일).
- Remark-2 : DAC-DETR은 각 object에 대한 best queryies의 품질을 개선시킨다. 큰 임계치(ex : t=0.8)에서 베이스라인 모델은 고품질 쿼리가 거의 없는 반면, DAC-DETR은 각 object당 약 1개의 고품질 쿼리를 가지는 것을 확인할 수 있다. 매칭 점수가 IoU와 classification score로 구성되는 것을 감안하면, 이는 DAC-DETR의 일부 쿼리가 정답 물체에 대해 좋은 IoU / 높은 confidence를 가지고 있음을 의미한다.
위 두 사실을 종합하면, DAC-DETR이 각 object에 대한 쿼리의 수량과 품질을 모두 개선한다는 결론을 내릴 수 있습니다.
Experiments
기본적으로 제안하는 DAC-DETR을 COCO 2017 detection dataset에서 평가하였습니다. 백본은 ResNet-50(ImageNet-1k) 이랑 Swin-Large(ImageNet-22k)을 사용했다고 합니다. 베이스라인 모델로는 Deformable-DETR, Deformable DETR을 개선시킨 Deformable++, DINO를 사용하였습니다.
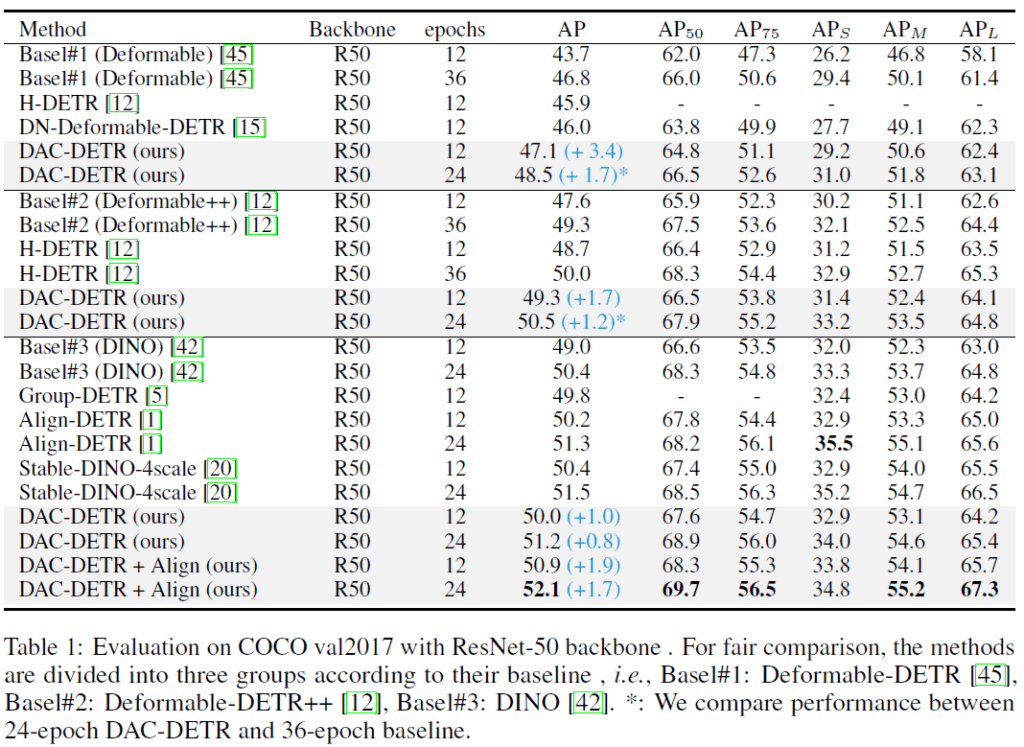
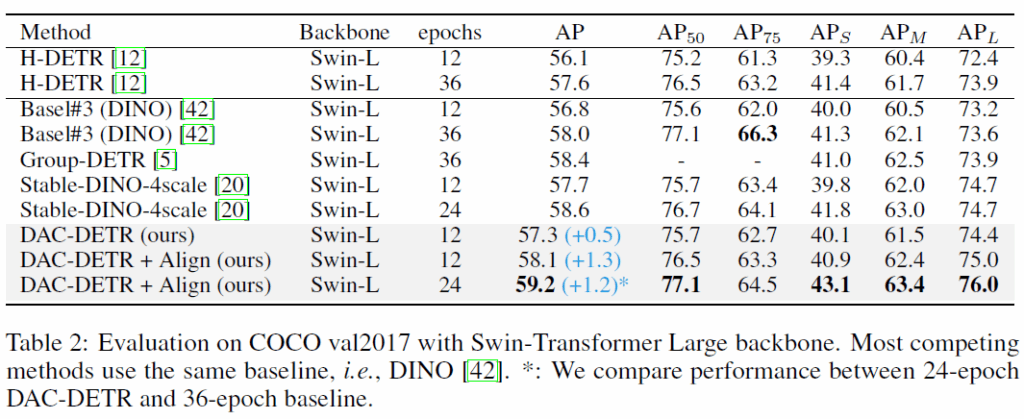
Table 1,2에서는 각각 ResNet-50 및 Swin-L backbone에 대한 결과입니다. DAC-DETR은 일관적으로 베이스라인 모델 대비 성능 개선을 보여주었고, 기존 SOTA 모델들과 비교해서 경쟁력 있는 결과를 보여주었습니다.

Table 3에서는 다음 두가지 질문에 대한 실험을 수행하였습니다.
- CA layer가 이미 C-Decoder에서 학습을 거치는데, O-Decoder에서 이를 Freeze할 수 있을까?(Variant1)
- C-Decoder에 SA layer를 제거하고 일대다 매칭을 사용하는게 중요한가?
이에 대해, C-Decoder에 SA layer를 추가한 Variant-2와 일대일 매칭을 수행하는 Variant-3을 구현하여 비교하였습니다.
결과적으로, 저자들은 표 3의 결과에서 다음 두 가지 관찰 결과를 제시합니다 :
첫 번째로, O-Decoder의 Cross-Attention layer를 freeze하는 것은 DAC-DETR의 성능을 상당히 저해하지만(-1.2AP), 여전히 베이스라인보다는 개선된 수치를 보인다(+2.2AP). 이는 CA layer를 C-Decoder에서만 학습시키는 것만으로도 경쟁력 있는 DETR detector를 만들 수 있다는 점을 보여준다. 따라서 우리는 C-Decoder가 CA layer를 학습하는데 중요한 역할을 한다고 생각한다. O-Decoder 측면에서는 CA layer에 상대적으로 적게 영향을 미치며, SA layer를 학습하는데 더 집중하게 된다.
두 번째로, C-Decoder에 SA를 추가하거나 일대일 매칭을 사용하는 것 모두 DAC-DETR의 성능에 악영향을 미친다. 따라서 우리는 SA 계층을 제거하고 일대다 매칭을 사용하는게 가장 좋다는 결론을 내렸다.
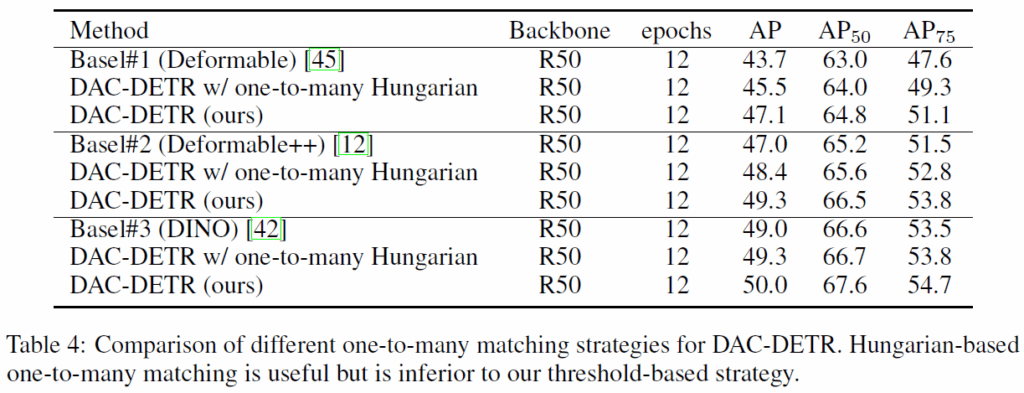
AC-DETR에서 C-Decoder는 임계값 기반(Threshold-based) 일대다 매칭 전략을 사용합니다. Table 4에서는 H-DETR의 repeated GT를 사용한 헝가리안 매칭이라는 방법을 활용하여 함께 실험을 수행하였습니다. 결론적으로, 베이스라인과 비교하면 DAC-DETR w/ one-to-many Hungarian을 사용했을 때 일관된 성능 개선을 보여 C-Decoder가 헝가리안 기반 일대다 매칭과도 잘 호환됨을 보였고, 두 일대다 전략을 서로 비교했을 때 저자들이 사용한 threshold 기반 전략이 더 우수했다고 합니다.
기존과는 약간 다른 관점으로 DETR의 디코더를 개선한 연구였습니다. 오랜만에 SGG 말고 detection 쪽 논문 읽으니 재밌네요. 제안한 방법론이 수렴을 빠르게 하는지에 대한 정량적 분석이 있었으면 좋았을텐데, 그런게 없었던것은 개인적으로 좀 아쉽습니다(하지만 intro에서 수렴 속도를 직접적으로 비중있게 다루진 않아서 문제가 있지는 않을 것 같습니다).
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.
안녕하세요 재연님 좋은 리뷰 감사드립니다!
figure 1에서 말하는 gather/disperse 현상이 직관적으로는 이해가 되는데 CA는 모으고 SA는 흩뿌린다는 것이 항상 성립하는 일반적인 현상인지가 궁금합니다! 뭔가 이러한 현상이 레이어 깊이나 학습초반의 불안정한 매칭이나이런 것 때문인지 CA/SA의 구조적 특징에 영향을 받아 이런 현상이 발생하는지가 궁금해서 질문드립니다! 감사합니다!
안녕하세요, 안우현 연구원님. 답변 드리도록 하겠습니다.
gather / disperse 경향성은 리뷰에서 설명되어있듯 레이어 깊이, 불안정한 매칭 때문이라기보다는 DETR의 학습 신호 세팅 때문이라고 보시는게 맞습니다. DETR 디코더에서는 query랑 feature map이 상호작용하면서 물체를 잡으려고 할 것이고, 그 상호작용이 결국 CA기 때문에 각 쿼리들이 물체를 detect하기 위해 비슷하게 gathering됩니다.
하지만 DETR 학습에서 GT와 bipartite matching되지 않은 모든 쿼리들은 배경 처리(‘no object’에 매칭)되기 때문에 강력한 패널티를 받게 됩니다. 쿼리 하나 빼고 다른 모든 쿼리들은 해당 object를 예측하지 않는 방향으로 학습하게 되는데, 그럼 결국 object에 할당된 단 하나의 쿼리를 정하는 쿼리 간 통신이 SA에서 일어나는 것입니다. 쿼리들 간 정보의 상호작용이 있어아 어떤 쿼리 하나가 object에 배정될 지 쿼리끼리 결정을 내리게 되는데, 쿼리들 간 정보를 교환하는 layer가 SA이기 때문에 SA에서는 할당 쿼리 하나를 제외하곤 모두 멀어지는 disperse 현상이 일어나는 것입니다.
감사합니다.