이번에 소개드릴 논문은 지난주 세미나에서 발표한 MineWorld라는 논문입니다. Microsoft 연구팀이 테크니컬 리포트로 작성한 문서로 가볍게 읽어보기 좋을 것 같아서 가져왔습니다.
일단 논문 소개에 들어가기에 앞서서 왜 마인크래프트 세상에 대하여 world-model을 만드는 것인지, 그리고 이러한 mineworld라는 것이 어떤 목적으로 사용되는가에 대해 세미나 댓글에 많이 달려 있어서 그러한 부분도 답변을 먼저 드리고자 합니다.
우선 Minecraft World-Model이란 마인크래프트 세상에 대한 시각적 관측과 물리적 상호작용을 모델이 이해하고 모델링할 수 있는 것을 의미합니다.

그래서 위의 정성적 결과와 같이 제일 좌측 열에 해당하는 그림에서부터 위의 텍스트로 서술된 action 값이 모델에게 주어졌을 때 모델이 실제로 그러한 행위가 취해졌을 때의 visual oberservation을 예측하는 것을 볼 수 있습니다.
마인크래프트라는 게임은 초등학생 친구들이 즐겨하는 간단한 게임같아 보이지만 사실 해당 게임은 상당히 다양한 지형지물과 오브젝트들이 존재합니다. 만약 모델링해야하는 세상이 단조로우면 world-model이 그냥 해당 공간 자체를 외워버릴 수도 있겠지만, 마인크래프트가 가지는 다양성으로 인해 모델이 단순 암기가 아닌 실제로 이해를 해야합니다.

두번째는 agent가 어떠한 임무를 수행하는데 있어 long-horizon task를 설계하는 것에도 용이합니다. 아래 사진과 같이 다이아몬드 곡괭이를 만들기 위해서는 나무를 캐는 것부터 해서 다양한 광물과 장비 제작을 통해 달성이 되기에 모델이 long-horizion task를 잘 수행하는지 평가하기에도 용이합니다.

그리고 마인크래프트는 예전부터 인기가 있었던 덕분인지 유튜브나, 트위치와 같은 온라인 스트리밍 서비스에서 방대한 양의 마인크래프트 게임 플레이 영상을 취득하기에도 용이합니다.
이러한 점들을 통해서 minecraft에서 world-model 연구를 하는 것이 생각보다 용이하다?라는 점이 있겠습니다. 그리고 많은 분들이 궁금해하셨던 부분 중 하나가 이러한 Minecraft world-model이 실제 현실 세계에서의 world-model처럼 활용이 가능한 것인지에 대한 부분입니다.
많은 분들이 아무리 마인크래프트가 다양성이 넘치고 long-horizon task가 있다고 하더라도 결국 현실세계와는 다른 물리적 상호작용을 하는 세상인데 해당 환경에서 학습한 모델이 무슨 의미가 있는지에 대해 궁금해하셨던 것 같습니다.
그 부분에 대해서 제 생각을 답변드리면 우선 예상하신대로 MineWorld가 현실세계의 물리적 모델링을 절대로 표현할 수는 없습니다. 실제로 게임 속 세상에서의 물리적 행동과 실제 세상의 물리적 행동은 매우 다르기 때문이죠. 그럼 도대체 Minecraft에서 world-model 연구를 왜 하는지 궁금해하실 것 같은데 제 생각에는 2가지 이유가 있는 것 같습니다.
첫번째 이유는 게임 속에서도 자율적인 agent가 필요하다고 봅니다. 게임의 장르마다 다르긴 하겠지만, 자유도가 상당히 높은 open-world 장르의 게임들이 존재합니다. 이러한 게임은 탐험해야할 요소가 가득하기도 하고, 탐험하다가 마주하는 무작위의 요소들도 등장합니다. 그리고 이러한 사물 또는 npc들과의 상호작용이 더욱 현실적이면 현실적일수록 게임을 하는 게이머들은 더욱 흥분?하게됩니다.
또는 이러한 오픈월드류의 게임이 아니더라도, 마치 혼자 게임을 하지만 같이 협력하는 AI 팀원들이 실제 사람들과 비슷하게 행동하고 유저와의 의사소통이 자연스러우면 게임을 즐기는 유저 입장에서는 더욱 즐겁게 게임에 몰입할 수도 있습니다. 이처럼 사람과 같이 말하고, 행동하고, 자연스러운 상호작용이 가능한 AI agent가 게임 산업에서도 필수적이라고 생각이 드는데, 이러한 관점에서 게임 세상 속을 이해하고, 모델링하며 유저와의 소통이 가능한 연구들도 필요하다고 봅니다. 그리고 만약 World-model이 어떠한 게임 세상을 굉장히 잘 묘사할 수 있으면 사실 프로그래머들이 게임을 직접 제작할 필요 없이 해당 world-model로 게임을 직접 구동시킬 수도 있다는 점도 있긴 합니다. 아무튼 너무 현실 세계에서의 물리적 상호작용만을 world-model로 보지 말자는 것이죠.
그리고 두번째로는, 현실세계만큼 복잡하고 다양성이 보장된 세상에서 world-model을 구축하기 위해 필요한 아이디어나 기술들이 실제 현실 세계에서의 world-model을 구축하고 학습시키는데에도 충분히 활용될 수 있습니다. world-model의 중요한 역할 중 하나가 관측된 시각적 입력과 어떠한 action 값이 주어졌을 때 해당 action을 취한 뒤 나타나는 미래 oberservation을 예측해야하는 것이 주요 task 중 하나라면 이러한 task를 효율적으로 수행하기 위해 고안된 방법론이 현실세계를 대표하는 world-model을 구축할 때에도 사용될 수 있따는 것이죠.
Intro
지금까지 마인크래프트에서 world-model 등의 연구를 수행하는 이유에 대해서 제 생각을 간략하게 말씀드렸다면 본격적으로 본 논문에 대한 소개로 넘어가겠습니다.
해당 논문에서 저자들이 말하는 문제 정의는 다음과 같습니다.
- 많은 world-model들이 유저의 action에 대하여 정확하고 엄격하게 visual observation을 만들어내지 못한다.(좌측 45도로 돌아 라는 action이 주어졌을 때 실제 관측값은 90도를 돈 결과가 나오는 등)
- 고품질의 디퓨전 기반 모델들을 사용하다보니 실시간 interaction를 수행해야하는 관점에서 너무 느리더라.
그래서 저자들이 제안하는 MineWorld라는 것은 실시간 추론성을 유지한체 action-following 능력을 크게 높이는 방향으로 설계되었다고 합니다. 이를 위해서 Visual-action autoregressive transformer라는 구조를 채택하였으며, parallel decoding이라고 하는 효과적인 디코딩 방식을 제안합니다.
Method
우선 저자들이 제안하는 방법론의 구조는 다음과 같습니다.
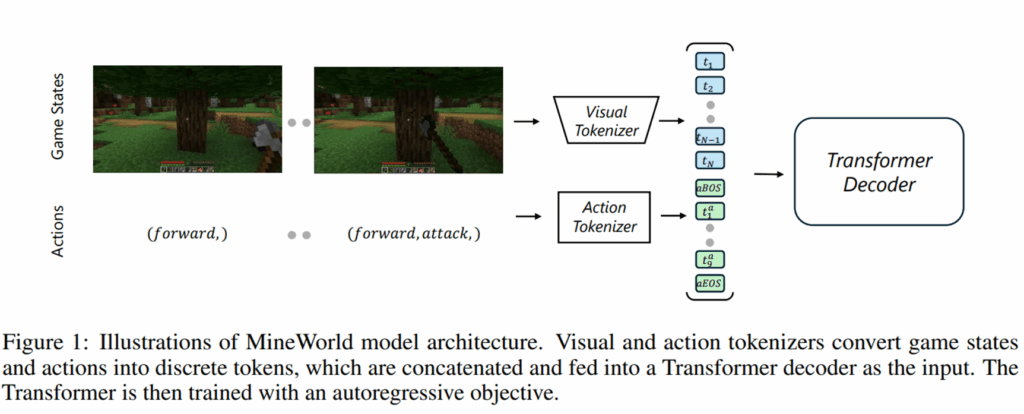
대략 살펴보시면 시각적 관측치와 그에 대응되는 user action이 주어졌을 때 모델이 그에 대응되는 미래 시점의 state를 다시 예측하는 것입니다.

노테이션부터 빠르게 살펴보시면 위와 같습니다. state를 크게 시각적인 state와 그에 대응되는 action state이 항상 pair로 존재합니다.
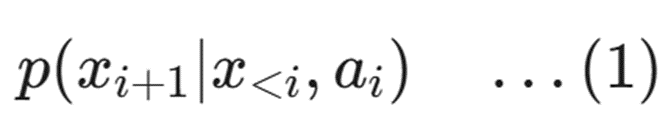
그리고 world model은 위의 수식1을 학습 목표로 삼게 되는데 i번째까지의 시각적 state와 i번째에 대응되는 action이 주어졌을 때 i+1번째의 visual state를 예측하는 것을 의미합니다.
우선 입력으로 visual state와 action이 사용되기 때문에 이들을 토큰화 시켜줄 tokenizer가 필요로합니다. 보통 시각적 입력으로는 아래와 같이 비디오 형식이 사용이 됩니다.
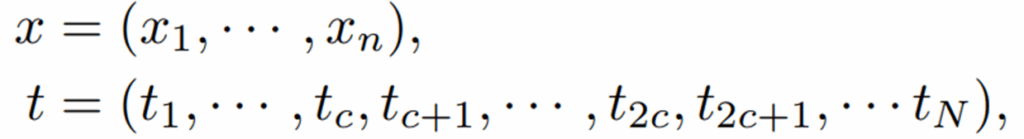
위의 표기에 대한 notation 설명은 아래와 같습니다.

즉 n개의 프레임으로 구성된 비디오 클립이 있으면 visual tokenizer를 통과하여 t라는 시각 토큰으로 만들게 됩니다. 이때 하나의 frame에 대한 visual token들을 총 c개로 표현하게 되며 temporal 축에 대하여 n개의 토큰들이 다 적용되기에 n*c개의 시각 토큰들이 최종적으로 생상된다고 이해하시면 될 것 같습니다.
Action tokenizer
다음은 action tokenizer에 대한 부분입니다. action tokenizer는 총 11개의 길이의 token을 생성하게 되는데 우선 action의 시작과 끝을 알리는 [aBOS], [aEOS] 토큰이 총 2개 존재합니다.
그리고 실제 action값을 의미하는 토큰이 9개가 존재하게 되는데 전진/후진/좌회전/우회전 등과 같은 움직임과 실제 게임 속 마우스 클릭을 통한 행동과 camera pose 등을 의미합니다.
action token을 정리해보면 아래와 같습니다.

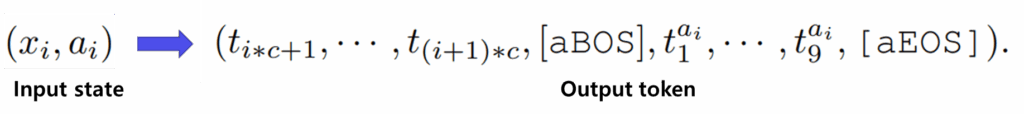
결과적으로 어떠한 visual state와 action state가 입력으로 들어왔을 때, 토크나이저를 통해서 생성되는 output 겨과물이 위와 같이 정의됩니다.
Transformer Decoder
이렇게 state들을 잘 토큰화하였으면 그 다음에는 transformer decoder를 타고 i+1번째의 state를 예측하게 됩니다. 여기서 일반적인 ViT의 decoder를 활용하는 것이 아니라 라마에서 사용한 cross-attention이 없는 디코더 구조를 채택하였다고 합니다. (아래 그림의 우측에 해당하는 구조)
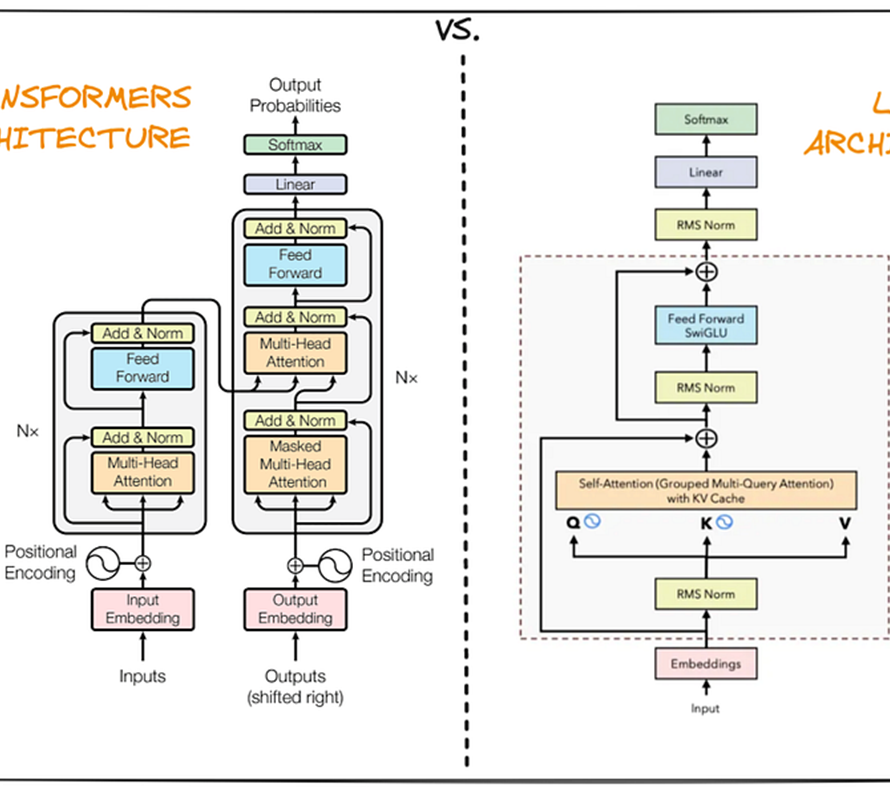
그리고 저자들은 단순히 visual oberservation만을 decoding하는 기존의 world-model들과 다르게, action도 같이 예측하는 visual-action autoregressive deocder를 사용합니다. 그래서 실제 학습도 아래와 같이 visual token x만 예측하는 것이 아닌 action도 포함된 t state를 예측하는 것을 학습 목표로 삼습니다.
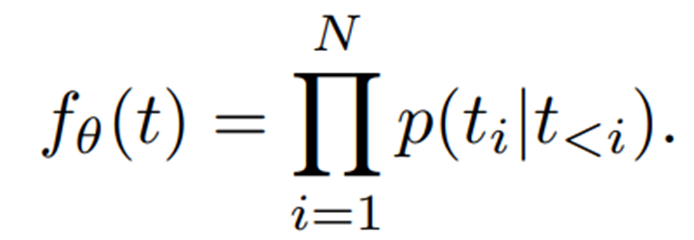
Parallel Decoding
다음은 저자들이 새롭게 제안한 parallel decoding 방식입니다. 원래 기존의 world-model들은 Raster Scan Order로 visual state를 디코딩하였다고 합니다.
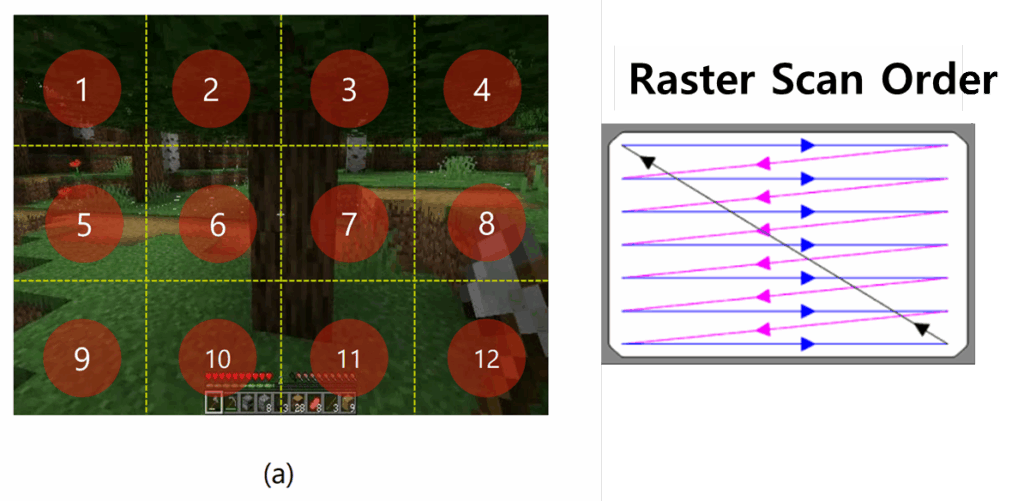
Raster Scan이란 위의 예시에서 볼 수 있듯이 왼쪽부터 오른쪽으로 한 행을 훑고, 그 다음 다음 행으로 넘어가서 다시 훑는 식의 스캔 방식입니다. 즉 영상을 디코딩할때에도 한행씩 한땀한땀 디코딩을 진행했다는 것을 의미하는 것이죠.
이러한 방식이 생성해야하는 영상의 해상도가 너무 높을수록 너무 많은 비용을 잡아먹고 비효율적이라고 저자들은 판단해서, 대각 방식의 디코딩을 새롭게 제안합니다.
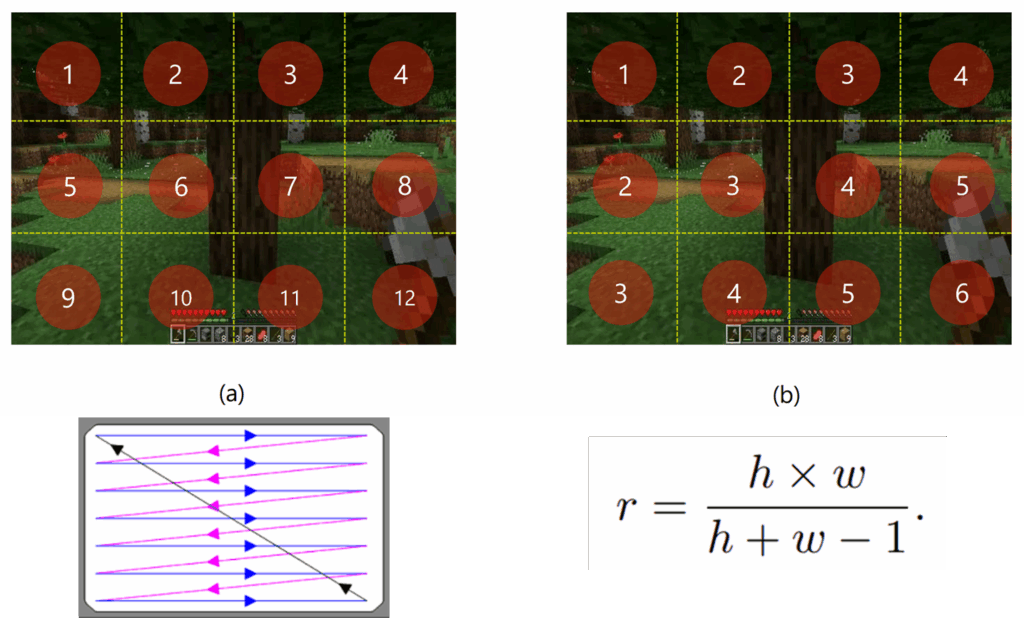
위의 우측 방식이 저자들이 제안하는 대각 디코딩 방식인데 숫자 넘버링을 살펴보시면 아시겠지만 하나의 행을 다 훑을 때까지 다른 행에 대한 디코딩을 하지 않는 기존 방식과 달리 다중 행과 열을 디코딩하는 모습입니다. 이러한 방식을 취했을 때 위의 수식과 같이 해상도에 따라서 r만큼의 연산 효율을 얻는다고 합니다. 그리고 이러한 디코딩은 하나의 frame뿐만 아니라 multi-frame에서도 이루어지기 때문에 더 빠른 디코딩이 가능하다고 합니다.
Experiments
그럼 실험 결과 살펴보고 마무리 짓도록 하겠습니다.
우선 저자들은 VPT dataset이라는 것을 통해 학습 및 평가를 진행하였으며, 본 연구에서는 visual state와 action state를 모두 예측하기 때문에 시각적 평가와 action 평가에 대한 지표가 따로 존재합니다.
시각적 평가를 위한 메트릭은 아래와 같습니다.

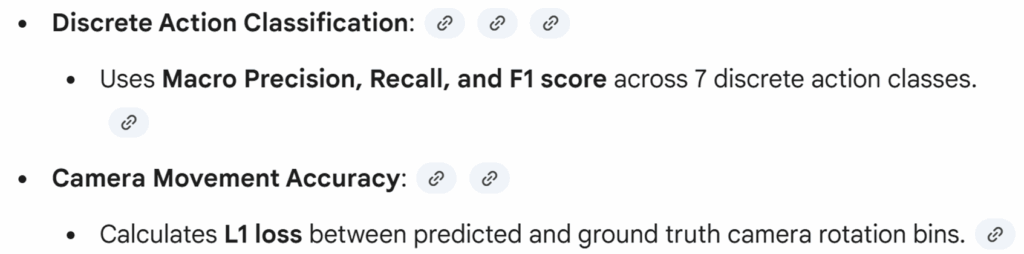
그리고 action 대한 메트릭으로는 저자들의 action 값이 다 이산화 되어있기 때문에 Precision, recall, F1 Score 등으로 평가가 가능하며, Camera movement에 대한 정확도는 rotation bin에 대한 L1 loss를 계산하였다고 합니다.
그럼 우선 기존의 SoTA 방법론인 Oasis 방법론과의 비교 실험입니다.
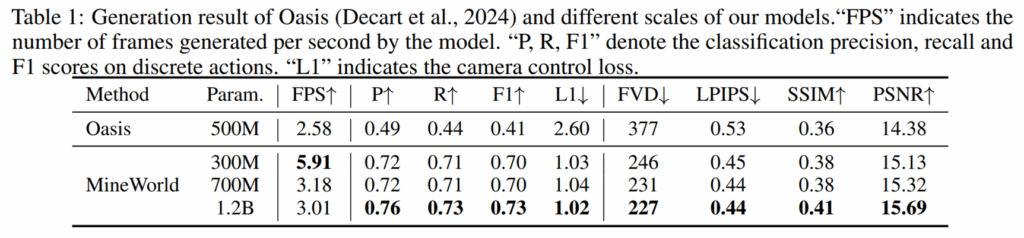
우선 Oasis 방법론과 저자들의 MineWorld가 동일 parameter 모델은 없긴 하지만 눈여겨볼 점으로는 가장 큰 모델인 1.2B짜리 모델이 500M짜리 Oasis 모델보다 FPS가 더 빠르다는 점입니다. 이것이 저자들이 제안하는 parallel decoding 방식을 적용했기 때문이라고 유추할 수 있습니다.
그리고 action에 대한 정확도도 모든 모델에서 더 높은 것을 볼 수 있으며 영상 품질 퀄리티도 저자들의 world-model이 모델 사이즈에 상관없이 항상 Oasis 모델보다 더 좋은 것을 확인하실 수 있습니다. 다만 SSIM이 30%대 후반, 40% 초반이라는 점은 여전히 사람의 눈으로 보았을 때 상당히 화질이 떨어진다는 것이기 때문에 영상 품질 측면에서는 갈 길이 먼 것 같습니다.
그리고 저자들의 모델이 real-time을 추구한다고 했었는데 가장 작은 모델의 속도가 6FPS정도 수준이라는 점에서 의문을 품으실 수도 있습니다. 저자들은 보통 게임을 하는 사람들의 평균 APM(분당 action 수)이 150이라는 점을 생각해보았을 때, world-model이 생성하는 frame 수가 2FPS 이상이면 충분하며, 프로선수들의 경우 300APM정도가 평균이 되는데 이를 위해서는 5FPS 이상의 추론이 필요하다고 주장합니다. 그러한 관점에서 저자들이 제안하는 300M 모델은 5.91 FPS를 가지기 때문에 프로급의 유저들이 해당 모델에서 action을 입력하는 것에 무리가 없다고 생각하는 듯 합니다.
다음은 정성적 결과입니다. 리뷰 첫 시작에서 한번 정성적 결과를 보여드렸었는데, 아래 정성적 결과는 동일한 visual state에서 다른 action을 주었을 때 어떻게 결과값이 바뀌는지에 대한 정성적 결과로 이해해주시면 되겠습니다.

그리고 한가지 재밌는 점은 저자들이 제안하는 MineWorld는 하나의 agent로서 역할을 수행할 수 있다는 점입니다. 해당 world-model은 visual state뿐만 아니라 해당 state에 어울리는 action도 같이 예측을 수행할 수 있기 때문에 자신이 예측한 visual state와 action값을 다시 입력으로 삼아 그 다음에 올 action과 visual state를 반복적으로 예측할 수 있게 됩니다. 이를 통해 agent는 자신이 구축한 world에서 뛰어놀고 있는 것이죠.

결론
처음에는 world-model에 대해서 서베이를 해보다가 마인크래프트 세상에서 world-model을 연구하고 있다길래 궁금해서 읽어보게되었습니다. 마침 저자들도 마이크로소프트 연구팀이길래 신뢰를 가지고 본 것도 있었구요. 테크니컬 리포트다보니깐 논문 글 자체는 상당히 담백하게 담겨져있고 실험도 빡빡하지는 않아 보이긴 했습니다만, refresh하는 관점에서 상당히 재밌게 읽었던 논문이었습니다.