안녕하세요 이번에 소개할 논문은 롱비디오 이해에서 단일 MLLM으로 추론 하는 한계를 지적하고 이를 multi-agent 협업 구조로 보완하는 LVAgent 프레임워크를 제안한 논문입니다. 그럼 바로 리뷰 시작하겠습니다.
1. Introduction
롱폼(long-form) 비디오는 인터넷 데이터에서 이미 큰 비중을 차지하고 있고, 의료·교육·엔터테인먼트 같은 실제 응용 분야에서도 중요도가 계속 커지고 있습니다. 하지만 대규모 멀티모달 데이터로 사전학습까지 잘 된 멀티모달 대규모 언어모델조차도 분 단위에서 시간 단위까지 이어지는 장기 시간 맥락(long-term temporal context)을 모델링하는 데 어려움을 겪고 있습니다. 예를 들어 문제는 초당 1프레임만 넣더라도 프레임 수가 기하급수적으로 늘어나고, 이를 그대로 단일 MLLM에 밀어 넣으면 계산 비용은 높아지고, 중복 정보(redundancy)는 과도해져 성능은 저하됩니다.

실제로 Figure 3의 예시처럼, 전체 비디오를 Gemini 1.5Pro, GPT-4o, Qwen2-VL, InternVL-2.5에 입력했을때 이 모델들은 공통적으로 정답을 못 맞추는 모습을 보입니다. 저자 설명에 따르면 원인은 비디오 안에 쌓여 있는 redundant하고 헷갈리는 정보 때문이고, 그게 색깔 텍스트로 표시되어 있습니다. 즉, 모델이 중요 단서만 선택해야 하는 상황에서 오히려 정보 과잉으로 올바른 답변을 제공하지 못하고 있습니다.
그래서 최근에는 에이전트(Agent) 기반 접근이 롱 비디오 이해에서 해법으로 제시되고 있습니다. 에이전트는 어려운 문제를 쪼개고, 필요하면 도구(tool)를 자율적으로 호출해서 긴 영상에서 핵심 정보만 뽑아낼 수 있습니다. 다만 기존 에이전트를 활용한 방법에도 개선 시킬 부분이 있습니다. 예를 들어 일부 방법들은 CLIP으로 키프레임을 검색해서 롱 비디오 이해를 수행하는데 CLIP 자체가 장기 시간 정보 검색에 약한 편이고, 사전학습 데이터가 롱폼 비디오 도메인과 domain gap이 있다는 지적이 있습니다. 또 다른 흐름은 메모리 뱅크나 RAG 같은 외부 도구로 MLLM을 보조하는 방식인데, 도구를 붙여도 결국 단일 MLLM이 혼자 답한다는 구조는 비디오 전체를 부분적으로만 이해한 상태에서 답을 만드는 문제가 남아서 성능이 제한되는 문제가 있습니다. 결국 저자들이 보는 롱 비디오 이해의 핵심 문제는 두 가지로 정리됩니다.
1. 질문(query)에 맞는 핵심 정보가 들어 있는 비디오 클립을 어떻게 더 잘 retrieve할 것인가?
2. 여러 에이전트가 협업(multi-agent collaboration)해서 롱폼 비디오를 더 잘 이해하게 만들려면 구조를 어떻게 구성할 것인가?
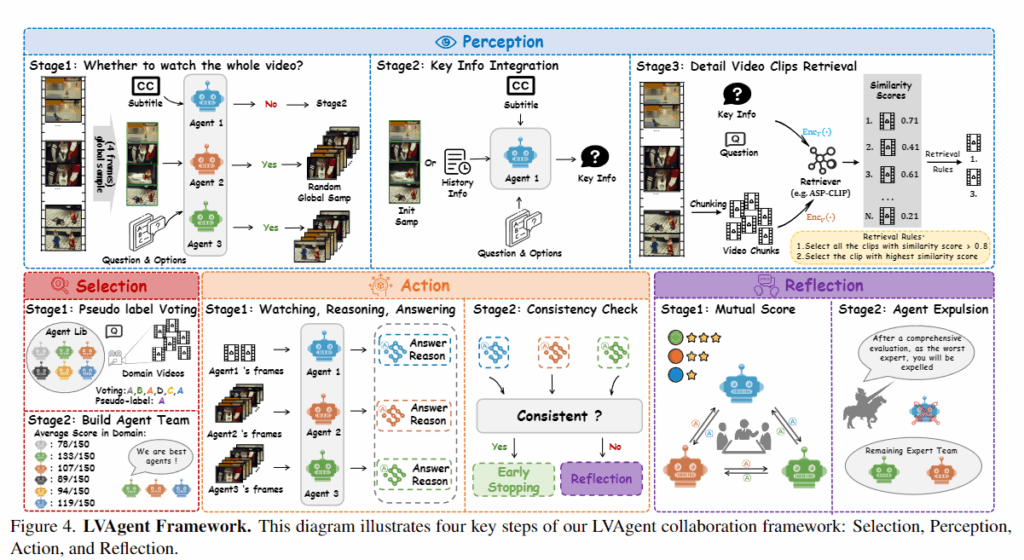
이 두 문제를 풀기 위해 저자들은 에이전트의 동적 협업을 4단계로 정리한 Selection–Perception–Action–Reflection 패러다임을 제안합니다.
(1) Selection: 먼저 에이전트 라이브러리(예: Qwen2-VL, InternVL-2.5 같은 주류 MLLM들)에서 이번 질의에 가장 적합한 팀을 선발합니다.
(2) Perception: 다음은 retrieval 단계인데, 특히 CLIP이 장기 시간 정보를 잘 못 잡는 문제를 의식해서 adaptive frame extraction과 롱 비디오 전용 retrieval 파이프라인을 설계합니다.
(3) Action: 이렇게 query 관련 클립을 뽑아놓고 나면, 에이전트들이 실제로 질문에 답하고, 답의 근거(reason)를 제시합니다.
(4) Reflection: 다음으로 매 라운드 토론에서 각 에이전트의 성능을 평가해 점수를 매기고, 잘못된 추론을 하는 에이전트는 걸러내며, 질의마다 동적으로 협업 구성을 바꿉니다.
이 네 과정 전체를 통해 에이전트들은 토론하면서 필요한 영상 구간을 다시 찾고 서로 정보를 통합하면서 답을 점진적으로 다듬습니다. 저자들은 이를 4개 롱 비디오 벤치마크(EgoSchema, VideoMME, MLVU, LongVideoBench)에서 검증했고,주류 롱 비디오 태스크에서 80%가 넘는 정확도를 달성했다고 리포팅합니다. contribution는 크게 세 가지로 정리됩니다.
1. 롱 비디오 이해를 위한 멀티 에이전트 협업 파이프라인 LVAgent 제안
2. 멀티 라운드·멀티 스텝의 동적 협업 구조로 장기 시간 맥락을 통합
3. 4개 롱 비디오 벤치마크에서 높은 정확도를 보이고, 특히 LongVideoBench에서 SOTA 대비 최대 13.3% 향상을 달성
2. Method
그럼 LVAgent의 ‘Selection–Perception–Action–Reflection’ 4개의 프로세스를 더 자세히 살펴보겠습니다.
2.1 Selection
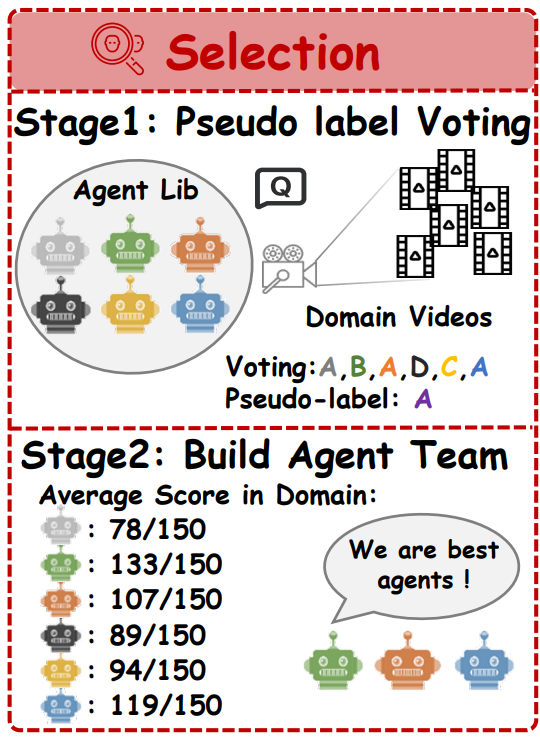
멀티 에이전트 시스템을 구축할때 생기는 하나의 문제는 에이전트마다 도메인/태스크에 따라 성능 편차가 크고, 성능이 낮은 에이전트가 협업을 방해하고 계산도 낭비된다는 점이 있습니다. 그래서 저자들은 Agent Library(Qwen2-VL, InternVL-2.5, LongVU, LLaVA-Video)를 만들어두고, 여기서 사전 선발(pre-selection)을 합니다. 사전 선발을 하기 위해 라벨이 없는 데이터에서 pseudo label을 만듭니다.
먼저 데이터셋 D에서 라벨 없이 150개 비디오 샘플 S를 뽑고, 각 비디오 케이스 V(질문 Q, 자막 T, 옵션 O 포함)에 대해 답변 후보 집합 Sans를 얻습니다. 그중 가장 많이 나온 답을 그 비디오의 pseudo label LV로 둡니다. 그리고 각 에이전트 Ai가 이 pseudo label을 얼마나 맞추는지 정확도(Acc)로 평가해서 상위 3개 에이전트를 팀으로 뽑습니다.
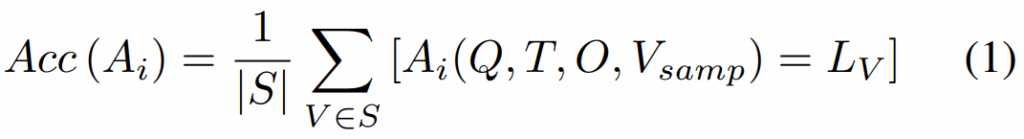
2.2 Perception
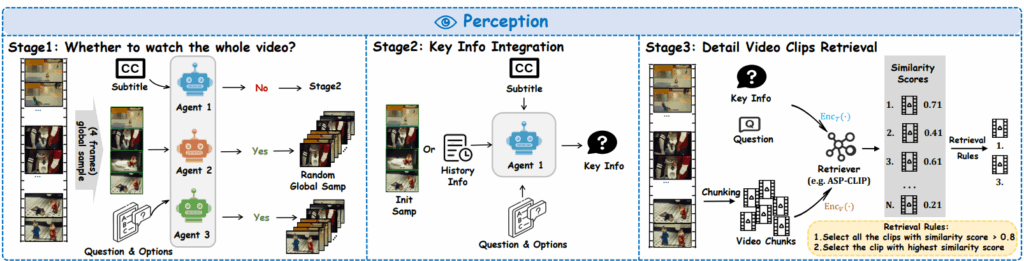
Perception은 중복 정보의 간섭을 줄이고, 비디오의 핵심 영역을 검색하며, 질문에 더 효과적으로 답하기 위해 3단계 인식 파이프라인을 제안합니다.
Stage 1 에서는 전체 비디오를 볼지 말지 에이전트가 먼저 판단하게 합니다. 일단 비디오에서 랜덤 4프레임 v만 샘플링합니다. 그런 다음 각 에이전트가 v,Q,T,O를 보고 전체를 봐야 하는지 결정합니다(Di).
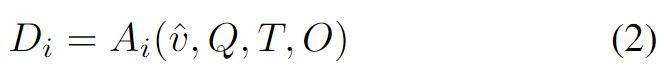
“Yes”면 global sampling으로 16프레임을 추가로 뽑아 전체를 더 넓게 커버하고, “No”면 바로 Stage 2로 넘어갑니다.
Stage 2 에서는 답에 필요한 핵심 정보를 텍스트 형태로 요약 생성 (Key info Ki) 합니다. 여기서 중요한 게, 에이전트가 단순히 답만 내는 게 아니라 retrieval을 위한 힌트 Ki를 생성한다는 점입니다. 먼저 첫 라운드에서는 v,Q,T,O를 보고 핵심 정보를 Ki로 뽑고,
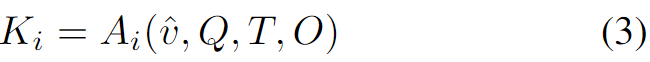
이후 라운드에서는 히스토리 Hinfo(각 에이전트의 답/근거/점수/퇴출 여부 등)를 참고해 더 정제된 Ki를 만듭니다.
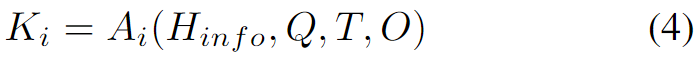
Stage 3 에서는 비디오를 6개 chunk로 쪼개고, chunk 단위로 retrieval을 단순화 합니다. 여기서 저자들은 retrieval 난이도를 줄이기 위해 전체 비디오에서 프레임을 찾는 문제를, 6개 chunk 중에 어디가 핵심인가? 로 바꿉니다. 먼저 비디오를 6개 동일 {chk1…chk6}로 나누고 각 chunk에서 16프레임씩 샘플링해서 fi를 만들고 ASP-CLIP( 저자의 LongVR 데이터셋으로 파인튜닝됨)으로 각 chunk에 대한 CLIP 점수를 계산합니다. Chunk 전체 score가 0.8을 넘으면 해당 chunk의 프레임을 선택하고, 없으면 최고 점수 chunk 선택하여 프레임을 선택합니다.
LongVR dataset for Long Video Retrieval
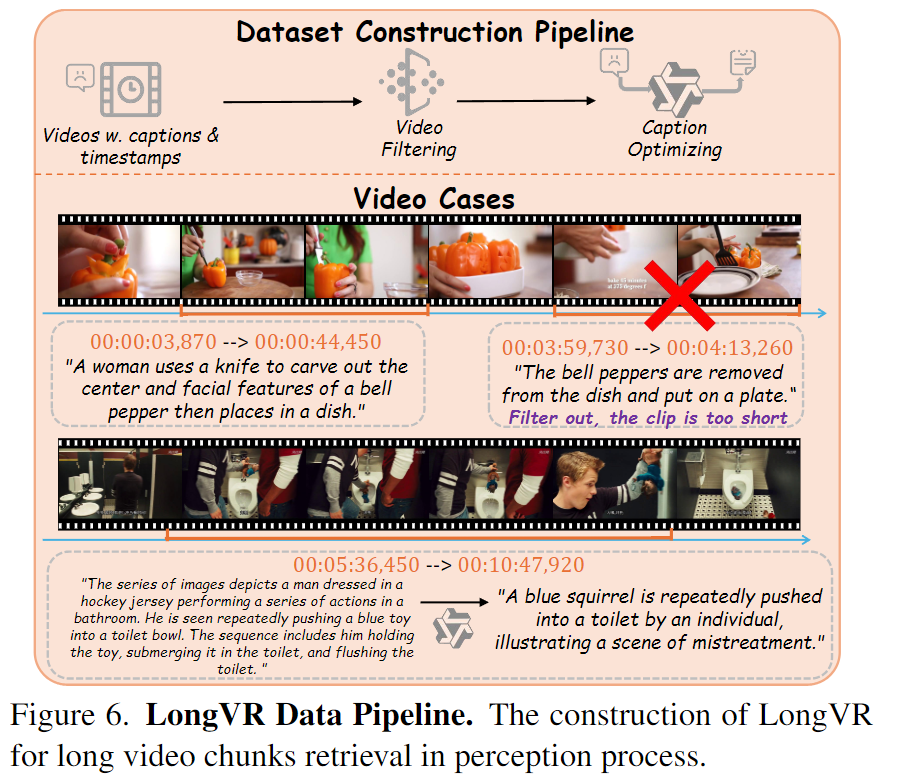
추가적으로 저자들은 CLIP의 domain gap을 해결하기 위해 ASP-CLIP을 LongVR 데이터셋으로 파인튜닝합니다. LongVR은 5개 데이터셋(ActivityNet, OpenVid-1M, ViTT, MovieChat-Caption, Youcook2)에서 크롭한 82K clips로 구성하고, 5초 미만이거나 12분 초과되는 비디오 클립은 제거합니다. 캡션이 너무 길면 CLIP 컨텍스트 한계가 있어 Qwen2-VL로 캡션을 최적화 합니다. 또한 캡션 토큰 20 미만은 너무 짧아서 제거하여 최종 평균 길이 145.6초, 캡션 평균 71 tokens를 가지는 데이터셋을 만듭니다.
2.3 Action
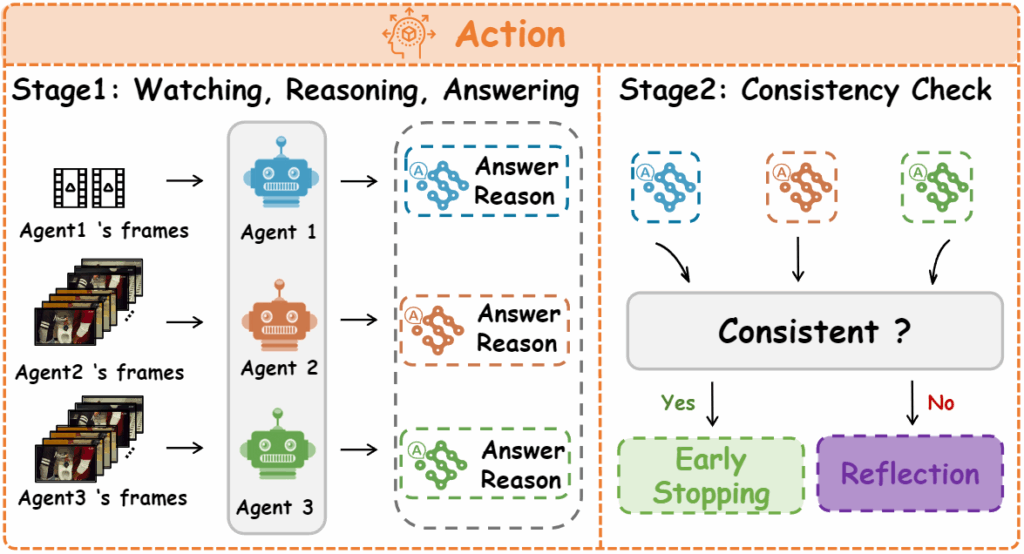
Action 단계는 단순한데 Perception으로 뽑은 프레임 Vsamp기반으로 각 에이전트가 답 ansi와 이유 Ri를 생성하고 에이전트 답변이 과반수를 넘으면 그 답으로 early stop을 하고 합의를 실패하면 Reflection을 하게 됩니다.
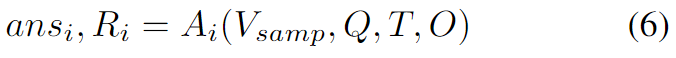
2.4 Reflection
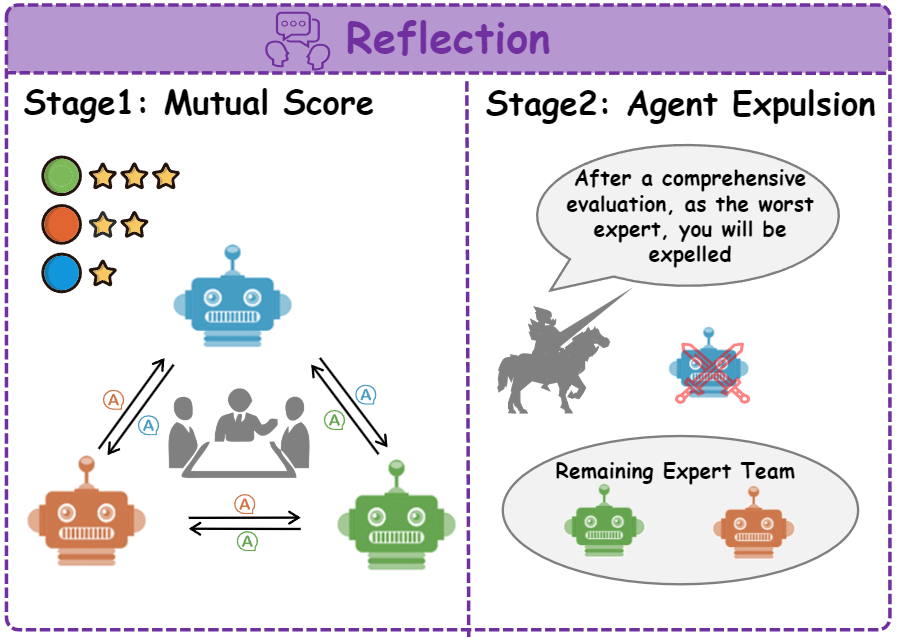
Reflection은 먼저 각 에이전트가 자기와 다른 에이전트의 reasoning을 평가해 점수를 매깁니다. 점수 최하 에이전트는 해당 질문에서 제외하고 남은 에이전트들이 이전 라운드 답+근거+점수 히스토리를 바탕으로 새로운 Ki를 다시 생성합니다. 그 Ki로 다음 round Perception을 수행합니다.
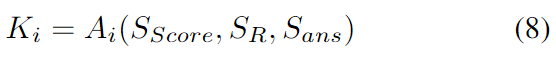
2.5 Multi-Round Dynamical Collaboration
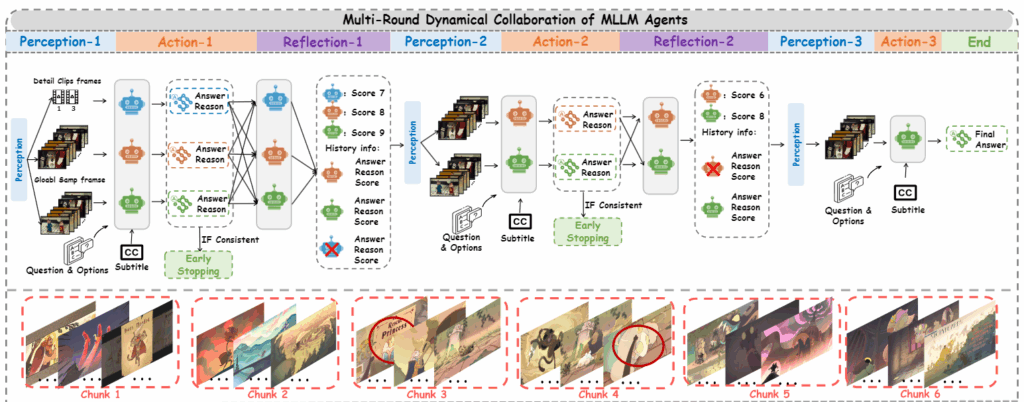
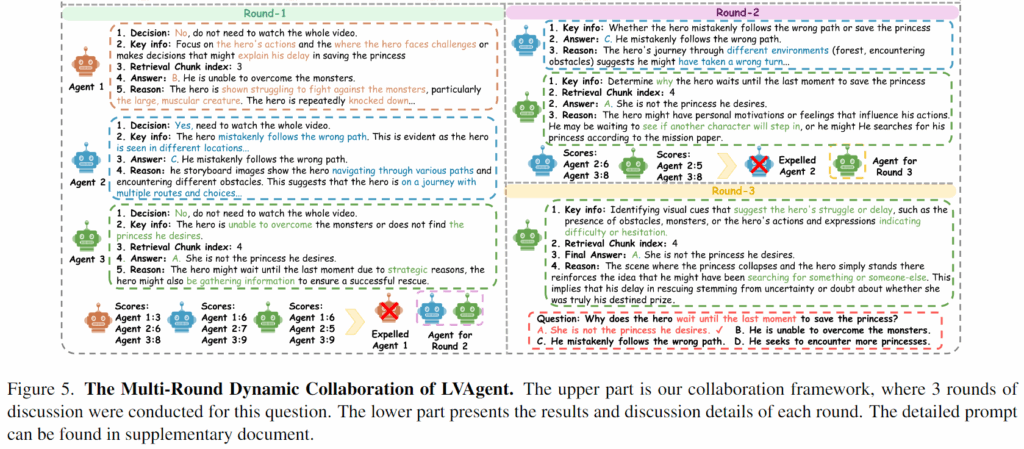
Perception, Action, Reflection을 포함한 전체 과정은 그림 5에 나와 있습니다. 그림 5의 상단 부분은 다중 협업의 전체 과정을 보여줍니다. 첫 번째 협업 라운드에서는 세 개의 에이전트가 각각 Perception, Action, Reflection 과정을 수행하여 서로 상호작용합니다. 그 후, 각 후속 협업 라운드는 이 세 가지 과정의 순환을 포함하고 있습니다. 그림 5의 하단 부분은 각 에이전트의 특정 출력 결과를 보여줍니다. 첫 번째와 두 번째 토론 라운드에서는 모델들이 통일된 결과에 도달하지 못했지만 여러 라운드의 토론 끝에 올바른 결과를 얻는 모습을 보여줍니다.
3. Experiment
다음으로 실험결과 살펴보겠습니다.
Comparison with SOTA
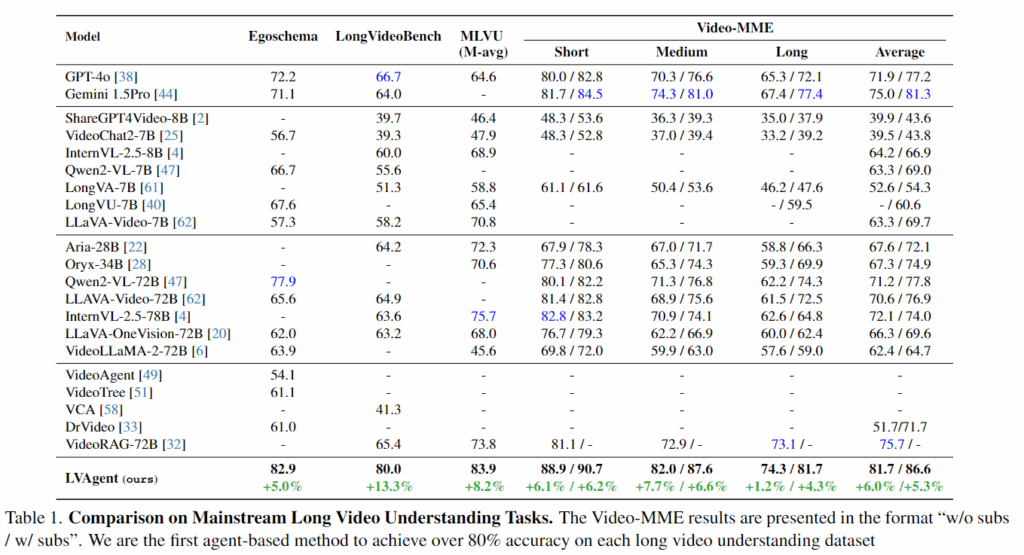
Table 1에서는 closed-source 모델들, open-source MLLM들, 그리고 agent-based 시스템들을 폭넓게 비교합니다. LVAgent는 4개 벤치마크 모두에서 80% 이상의 정확도를 달성해 SOTA를 달성했습니다. 특히 LongVideoBench에서 GPT-4o 대비 13.3%p 향상이 되었고 MLVU에서는 GPT-4o 대비 19.3%p, InternVL-2.5 대비 8.2%p 앞선 모습을 보입니다.
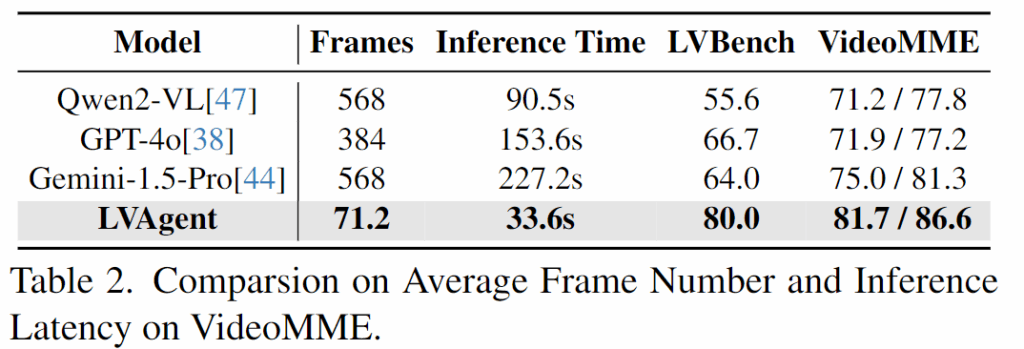
Table 2에서 VideoMME 벤치마크에서 기존의 최신 모델들과 비교하여 효율성과 성능을 어떻게 개선했는지 보여줍니다. LVAgent는 다른 모델들에 비해 훨씬 적은 수의 프레임(71.2)을 사용하고,추론 속도도 또한 33.6s로, 다른 모델들보다 빠른 추론 속도를 보입니다.
Ablation Study
Key steps ablation
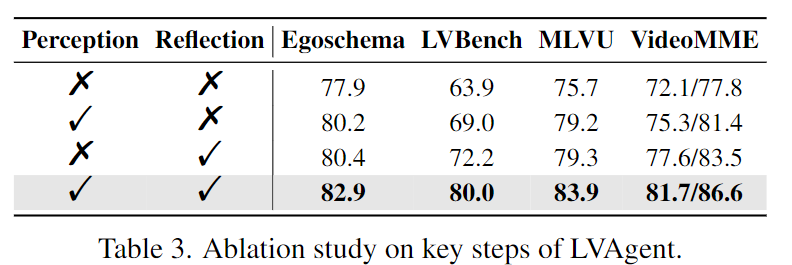
Table 3에서 Perception과 Reflection에 대한 Ablation stydy 결과를 리포팅합니다. Perception만 쓰거나 Reflection만 써도 성능이 오르지만, 둘을 결합했을 때 가장 성능이 많이 올라 EgoSchema 82.9%, LongVideoBench 80.0%를 달성합니다.
Number of Agents
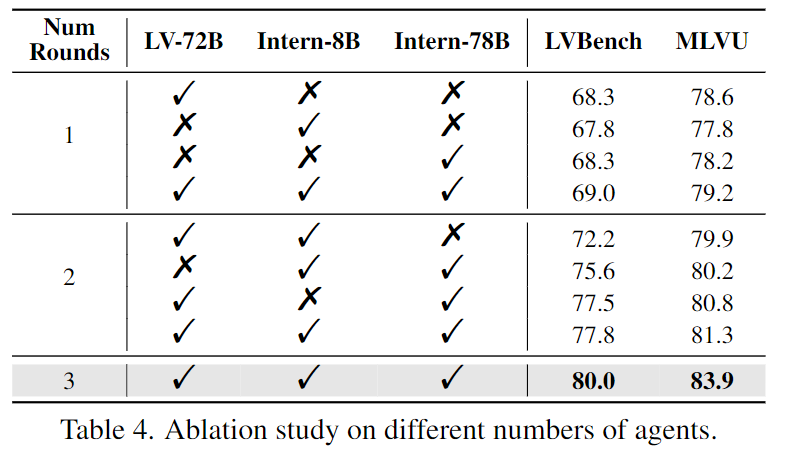
Table 4에서 LLaVA-Video-72B, InternVL-2.5-8B, InternVL-2.5-78B 에이전트 조합과 협업 라운드 수를 분석한 결과를 나타냅니다. 단독 성능은 LVBench에서 각각 68.3%, 67.8%, 69.0%이고 협업 라운드가 늘어날 수록 성능이 증가하여 최종적으로 세 에이전트를 모두 결합하면 LVBench 80.0%, MLVU 83.9%로 최고 성능을 달성합니다.
안녕하세요 의철님! 좋은 리뷰 감사합니다
LVAgent가 Perception 오류를 수정한다기 보다는 Reflection 단계에서 에이전트 제거를 통해 오류를 우회적으로 해결하는 구조로 이해했습니다!
과정을 반복하며 다음 라운드에서 달라지는건 key info 뿐인데 라운드가 진행될수록 Key info가 잘못된 가설로 수렴할 경우 전체 추론이 그 방향으로 고착될 위험은 없는지 궁금합니다!
안녕하세요 찬미님 좋은 질문 감사합니다.
Perception 단계에서는 key info 뿐만 아니라 이전 라운드에서 각 에이전트들이 결정한 내용들, 제거된 에이전트 등의 내용이 history info에 함께 요약 저장되기 때문에 라운드가 진행될수록 오히려 잘못 추론한 내용을 수정되므로 잘못된 방향으로 고착될 위험은 줄어든다 할 수 있겠습니다.
감사합니다.