최근에 DeepSeek 에서 공개한 논문을 좀 리뷰한 것 같네요. 리뷰 링크는 아래에 적어두겠습니다
- [Arxiv 2025] DeepSeek-OCR: Contexts Optical Compression – 2025.12.01
- [Arxiv 2026] Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models – 2026.01.18
오늘 리뷰할 페이퍼는 1번 논문인 DeepSeek-OCR 그 다음 버전으로 DeepSeek-OCR 2 입니다. 제목 그대로 해당 논문의 분야는 OCR 입니다. (해당 페이퍼 역시 1월 28일에 공개한 따끈따끈한 논문이랍니다)
해당 논문은 단순히 OCR 성능을 향상시키기 위한 연구가 아닌, LLM 구조를 비전 모달리티에서도 사용할 수 있다는 가능성을 보여준 것이라 생각합니다. 하여 이런 점 공유하면 좋을 것 같아 이렇게 리뷰로 가져오게 되었습니다.
(2026) DeepSeek-OCR 2: Visual Causal Flow

- Conference: Arxiv 2026 (2026.01.28)
- Authors: Haoran Wei, Yaofeng Sun, Yukun Li
- Affiliation: DeepSeek AI
- Title: DeepSeek-OCR 2: Visual Causal Flow
- Code: GitHub
0. Background (about DeepSeek-OCR)
DeepSeek-OCR v2 라는 이름이 있는 만큼, DeepSeek-OCR을 알고 있어야 이해가 쉬울 것 같습니다. 하여, 본격적인 리뷰에 앞서 간단하게 DeepSeek-OCR가 무엇인지 알아보겠습니다.
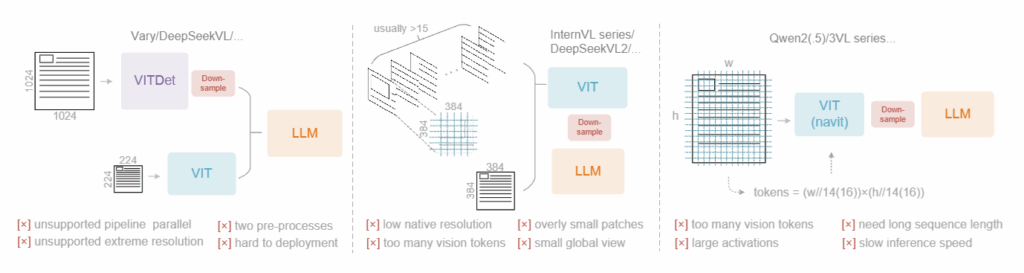
DeepSeek-OCR은 기존 LLM이 긴 문서를 처리할 때 겪는 long-context 한계에서 출발한 연구였습니다. 이 해결책으로 텍스트로 입력하면 수천 개의 토큰이 필요한 PDF·논문 문서를, 이미지로 입력하면 상대적으로 적은 수의 비전 토큰으로 압축할 수 있다는 점에 집중했죠. 즉, 저자들은 OCR을 단순 문자 인식 문제가 아니라 ‘시각을 활용한 텍스트 압축 문제’로 재정의하고, 얼마나 적은 비전 토큰으로도 문서의 의미를 복원할 수 있는 지를 고민하였습니다
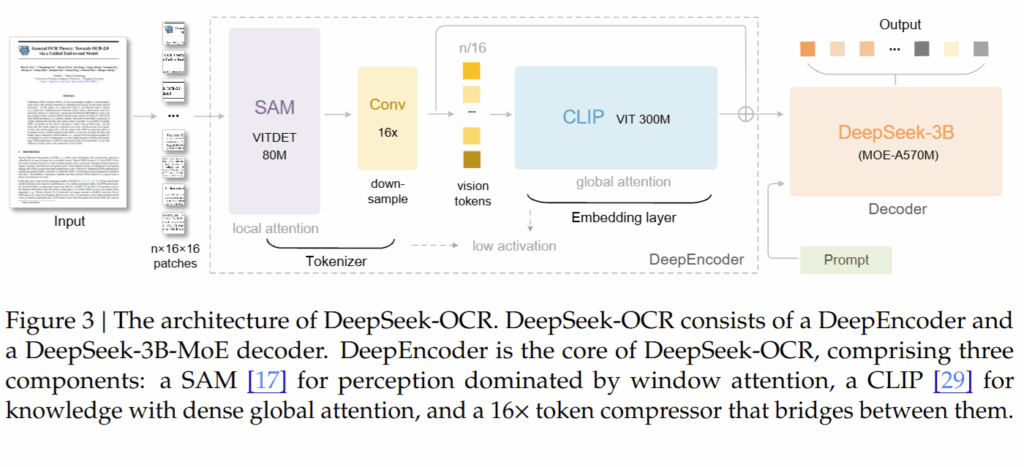
이를 위해 저자들은 고해상도 문서를 매우 적은 수의 비전 토큰으로 압축할 수 있는 전용 비전 인코더인 DeepEncoder를 설계하였습니다 (그림3). DeepEncoder는 문서의 Local한 시각 정보를 추출하는 Local Perception Module과, 문단 구조·레이아웃 같은 global한 맥락을 이해하는 Global Perception Module을 연결한 구조인데요, 두 모듈 사이에는 토큰 압축 모듈(16× compression)이 추가되어, 1024×1024 같은 고해상도 입력에서도 최종 비전 토큰 수를 수백 개 수준으로 제한하도록 설계되었습니다.
이렇게 생성된 압축 비전 토큰은 이후 MoE 기반 LLM 디코더로 전달되어 텍스트로 복원됩니다. 디코더는 단순한 OCR 출력기가 아니라, 압축된 시각 표현과 언어 표현 사이의 non-linear mapping을 학습하도록 설계되었고, 이를 통해 높은 압축률에서도 의미 있는 문서 복원을 보여주었죠. 결과적으로 DeepSeek-OCR은 OCR 정확도뿐 아니라, 비전 토큰 수–복원 성능 간의 정량적 트레이드오프를 처음으로 체계적으로 제시한 모델로 정리할 수 있을 것 같네요
참고로, 이것보다 더 자세한 내용이 궁금하시다면, 저의 지난 리뷰를 보는 걸 추천드립니다~~~~~
[Arxiv 2025] DeepSeek-OCR: Contexts Optical Compression
1. Introduction
방금까지 살펴본 DeepSeek-OCR에서 문서를 적은 수의 비전 토큰으로 압축해 LLM에 전달하는 구조를 제시했다면, OCRv2에서는 더 근본적인 질문을 던졌습니다: 인간의 시각체계는 문서를 어떤 순서로 이해하는가? 기존 VLM은 이미지를 ‘좌측 상단에서 우측 하단’ 이라는 고정된 순서로 패치를 펼쳐 처리하지만, 인간은 문서를 그렇게 읽지 않는다는 점에 주목한 것이죠.
사람은 문서를 볼 때 의미 단위에 따라 시선을 이동하며, 앞에서 본 정보가 다음 정보를 해석하는 근거가 되는 인과적인 시각 흐름 (Visual Causal Flow) 을 형성한다고 합니다. 특히 문서처럼 텍스트, 표, 수식, 레이아웃이 복잡하게 얽힌 입력에서는 “읽는 순서” 자체가 이해의 핵심이 되죠. 하지만 기존 VLM 인코더는 이러한 시각적 인과 관계를 고려하지 않은 채, 2D 이미지를 임의적인 1D 순서로 평탄화해 LLM에 전달해왔고, 저자들은 이것이 문서 이해 성능의 Bottleneck으로 보았습니다.
이러한 문제의식에서 출발해, 본 논문은 DeepSeek-OCR 2와 함께 새로운 인코더인 DeepEncoder V2의 설계 방법을 제안하였습니다. 목표는 단순히 더 정확하게 글자를 읽는 것이 아니라, 사람처럼 문서를 ‘읽는 흐름’을 모델 내부에 형성하는 것입니다. 즉, 비전 토큰을 얼마나 많이 쓰느냐가 아니라, 어떤 의미적 순서로 처리하느냐가 문서 이해에 더 중요하다는 관점이죠. 이를 바탕으로 기존 DeepSeek-OCR 구조를 재해석하고 확장하려는 시도가 본 연구의 출발점입니다.
컨셉적으로 해당 연구가 어떤 문제에 집중하는지는 이해하셨을 것이라 생각이 듭니다. 이제부터 본격적인 방법론을 알아보겠습니다.
2. Method
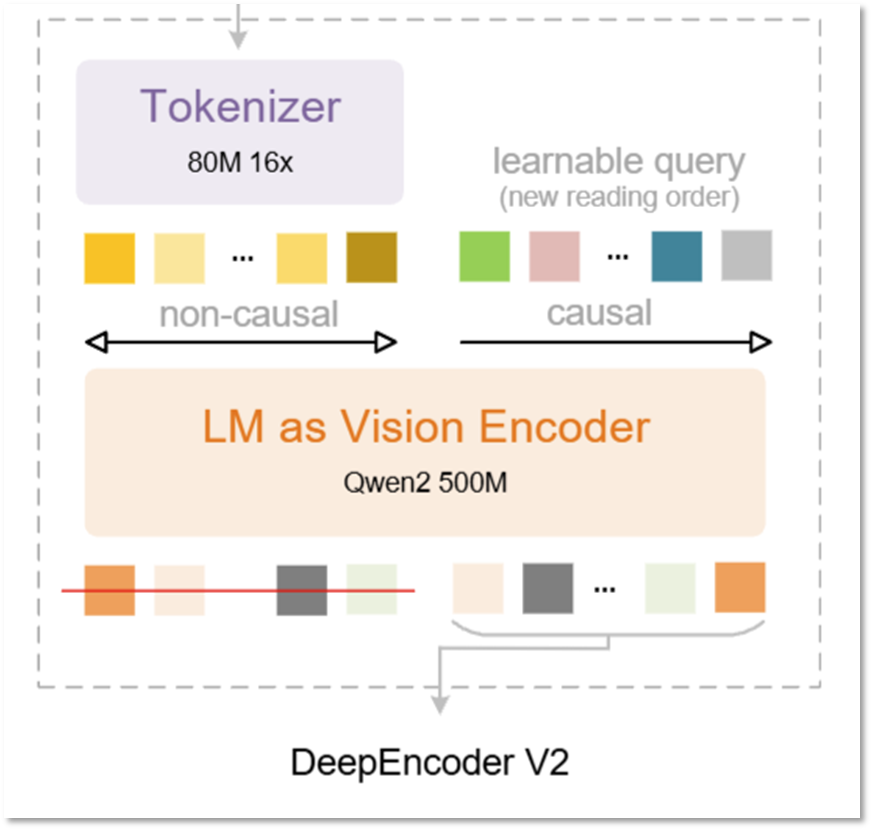
본격적인 방법론 설명에 앞서, DeepSeek-OCR과 비교했을 때 DeepEncoder V2가 어떤 방향으로 바뀌었는지를 그림 1을 통해 먼저 살펴보겠습니다.
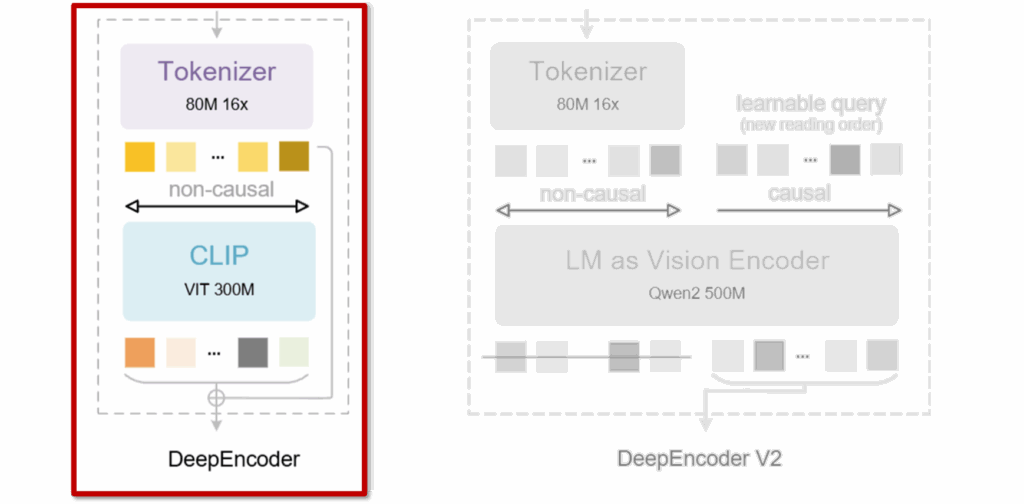
먼저 왼쪽은 DeepSeek-OCR에서 사용되었던 기존 DeepEncoder 구조로, CLIP 기반 Vision Encoder가 이미지 토큰을 non-causal (비인과적) 으로 한 번에 처리하는 방식이었습니다. 이 구조는 고해상도 문서를 적은 수의 비전 토큰으로 압축하는 데에는 효과적이었지만, 토큰이 처리되는 순서 자체는 여전히 좌상단 →우하단으로 고정되어 있었습니다. 즉, 문서를 어떤 의미 흐름으로 읽고 있는지에 대한 고려는 인코더 단계에서 명시적으로 반영되지 않았다고 볼 수 있죠
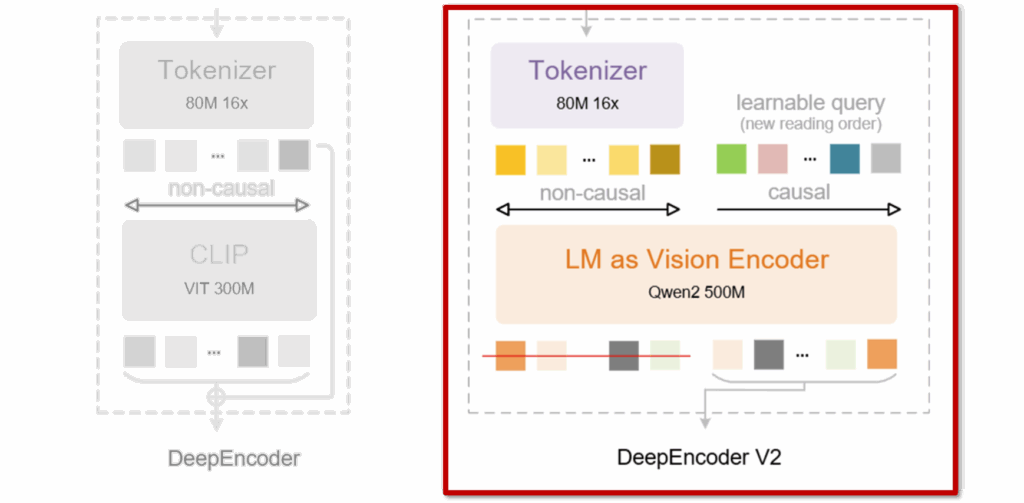
반면 오른쪽의 DeepEncoder V2에서는 먼저 기존 CLIP 모듈을 LLM 스타일의 인코더(LM as Vision Encoder)로 대체하고, 여기에 학습 가능한 query 토큰을 추가해 새로운 읽기 순서를 형성하도록 설계하였다고 합니다. 핵심은 모든 시각 토큰은 여전히 전역 정보를 자유롭게 바라보되 (non-causal), 이 위에 얹힌 query 토큰들이 앞선 정보에 의존하며 순차적으로(causal) 시각 정보를 재정렬한다는 점입니다.
즉, DeepEncoder V2는 이미지를 단순히 ‘압축된 시각 표현’으로 만드는 데서 그치지 않고, 의미에 기반한 읽기 흐름을 인코더 내부에서 형성하도록 유도한다고 볼 수 있죠. 이제 이 컨셉을 바탕으로, DeepEncoder V2가 실제로 어떻게 이러한 인과적 시각 (Vision Causal Flow) 흐름을 구현하는지 하나씩 살펴보겠습니다.
2.1 Vision Tokenizer: Efficient Visual Compression
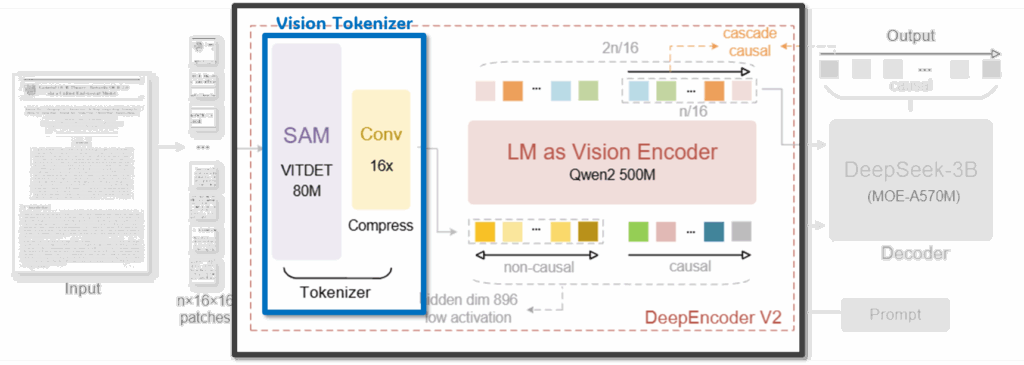
DeepEncoder V2의 첫 번째 단계는 Vision Tokenizer로, 고해상도 문서를 효율적으로 처리하기 위한 강한 시각 압축을 담당합니다. 이 구성은 기존 DeepSeek-OCR의 DeepEncoder 설계와 동일합니다 (80M SAM-base & 두 개의 convolution layer). 이 Vision Tokenizer의 핵심 역할은 이미지 정보를 약 16× 수준으로 토큰을 압축하는 것입니다.
참고로 저자들은 이 토크나이저를 필수 구성 요소로 보지는 않고, 해당 모듈은 단순한 patch embedding으로 대체될 수도 있습니다. 그럼에도 불구하고 기존 구조를 유지한 이유는, 비교적 적은 파라미터 수(80M)로도 강한 압축 효과를 얻을 수 있고, 이 규모가 LLM에서 일반적으로 사용하는 텍스트 임베딩 파라미터 수와도 유사해 전체 시스템 관점에서 균형이 맞아서 라고 합니다
2.2 LM as Vision Encoder: Rethinking the Encoder Design
DeepEncoder V2의 가장 큰 구조적 변화는, 기존 DeepEncoder에서 사용되던 CLIP 기반 비전 인코더를 제거하고, LLM 스타일의 Transformer 구조를 비전 인코더로 직접 사용했다는 점입니다. 그니까 Vision Token을 처리하는 데에 Vision Encoder가 아닌 LLM을 썼다는 겁니다
왜? 이미지가 아무리 2D 구조를 가지더라도, 최종적으로 이를 처리하는 LLM은 1D 시퀀스 입력에 특화된 모델이기 때문이죠. 그러니까 Vision Encoder 단계부터 LLM이 익숙한 연산 구조와 inductive bias를 따르게 하면, Vision 정보와 Language 모델 사이의 간극을 줄일 수 있다고 생각한 것이죠.
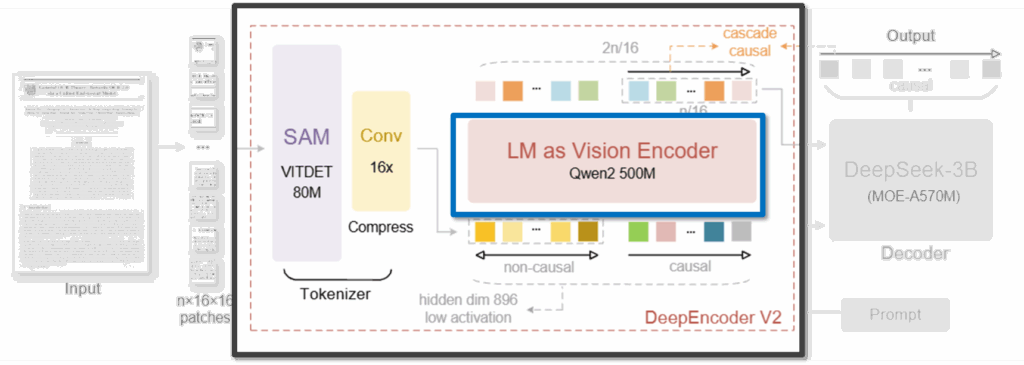
이러한 관점에서 DeepEncoder V2는 Qwen2 계열의 소형 LLM 구조를 Vision Encoder로 선택하였다고 합니다.
2.3 Causal Flow Tokens: Learning a Semantic Reading Order
DeepEncoder V2에서 가장 핵심적인 구성 요소는 저자들이 Causal Flow Tokens라고 부르는 learnable query tokens입니다. 이 토큰들은 이미지 패치나 국소 시각 정보를 직접 표현하기 위한 것이 아니라, 문서를 어떤 순서로 읽을 것인지를 학습하기 위한 토큰입니다.
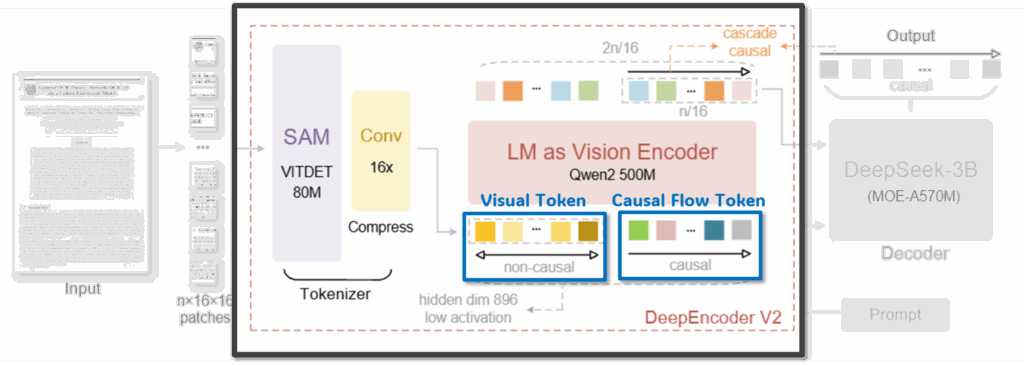
각 causal flow token은 모든 visual token과 이전 단계의 causal flow token에 접근할 수 있습니다. 이로 인해 모델은 앞에서 이미 해석한 시각 정보를 바탕으로, 다음에 어떤 정보를 중요하게 볼지 점진적으로 결정할 수 있게 되죠. 이러한 구조는 사람이 문서를 읽을 때 제목이나 앞 문단을 먼저 파악한 뒤, 그 맥락을 기반으로 표나 수식, 본문 세부 내용을 해석해 나가는 과정과 유사하다고 합니다
또한 저자들은 causal flow tokens와 visual tokens의 개수를 동일하게 유지하도록 설계했는데요. 이는 필요할 경우 이미 본 시각 정보로 다시 돌아가거나(refixation), 특정 영역을 반복적으로 참조할 수 있는 여유를 제공하기 위한 선택이라고 설명하였습니다. 그러니까 읽기 순서를 고정하는 것이 아니라, 의미에 따라 유연하게 시선을 이동할 수 있는 구조를 인코더 내부에 마련한 셈이죠
2.4 Attention Mask Design: Non-causal Vision, Causal Reading
DeepEncoder V2에서는 서로 다른 역할을 수행하는 토큰들을 구분하기 위해 attention mask를 설계하기도 하였습니다. 먼저 visual tokens는 이미지 전체를 자유롭게 볼 수 있도록 bidirectional attention, 즉 non-causal attention을 유지합니다. 이를 통해 문서의 전역 구조와 레이아웃 정보가 손실되지 않도록 하죠
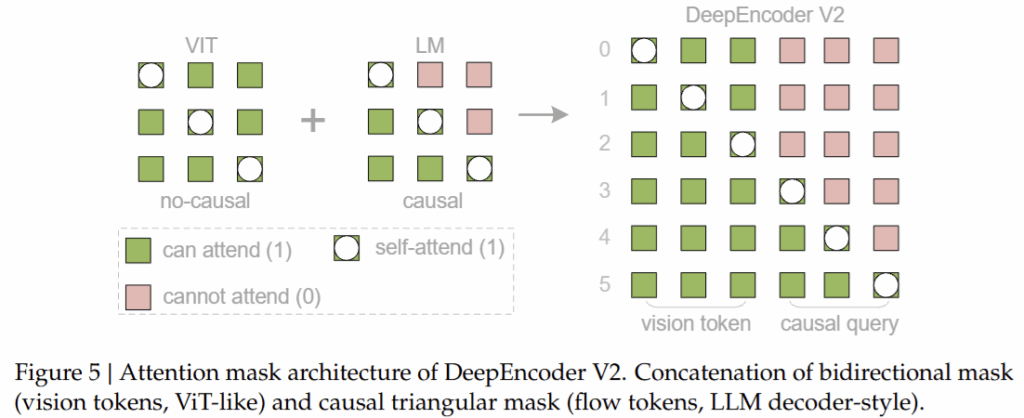
반면, causal flow tokens에는 causal attention이 적용됩니다. 각 causal token은 모든 visual token과 이전 causal token들만을 참고할 수 있으며, 이후에 등장하는 causal token에는 접근할 수 없습니다. 이 설계를 통해 causal flow tokens는 앞선 정보에 기반해 순차적으로 의미를 축적하며, 결과적으로 Visual Causal Flow 형성하게 됩니다.
이러한 attention 분리는 시각 정보를 한 번에 파악하는 능력과, 그 정보를 시간적으로 정리해 이해하는 능력을 하나의 인코더 안에서 동시에 구현하기 위함이라고 할 수 있습니다.
2.5 From Encoder to Decoder: Cascade Causal Understanding
DeepEncoder V2의 출력 중, 실제로 LLM 디코더에 전달되는 것은 causal flow tokens만입니다. 이는 디코더가 시각 정보 전체를 직접 처리하는 대신, 이미 의미적 순서로 정리된 표현만을 입력으로 받도록 하기 위한 설계라고 합니다.
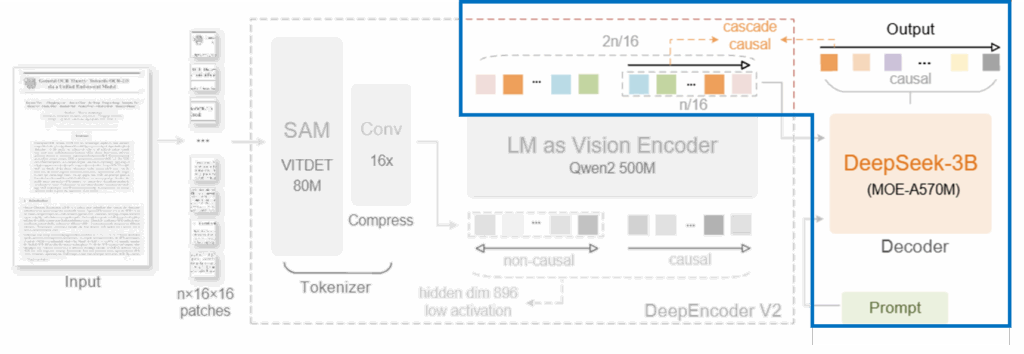
이러한 구조를 통해 시각 정보는 먼저 Vision Tokenizer에서 압축되고, LM-style 인코더 내부에서 Visual Causal Flow로 재구성된 뒤, 마지막으로 언어 모델에 전달됩니다. 결과적으로 LLM은 문서를 ‘보는’ 역할을 맡지 않고, 이미 읽기 순서가 형성된 시각 표현을 언어로 풀어내는 역할에 집중할 수 있게 되죠
정리하면, DeepEncoder V2는 단순한 비전 인코더 개선이 아니라, 시각 압축–의미 재정렬–언어 복원으로 이어지는 계단식(cascade) 문서 이해 파이프라인을 제안한 구조라고 볼 수 있습니다. 이 설계가 실제 문서 OCR 성능과 읽기 논리에 어떤 영향을 미치는지는, 다음 실험 섹션에서 본격적으로 살펴보겠습니다.
3. Experiment
앞선 섹션에서 살펴본 DeepEncoder V2는 단순히 OCR 정확도를 높이기 위한 구조라기보다는, 문서를 의미 흐름에 따라 읽도록 만드는 인코더 설계를 목표로 하고 있습니다. 따라서 실험의 핵심 질문 역시 ‘얼마나 잘 인식했는가’보다는, 이러한 Visual Causal Flow가 실제 문서 이해 성능에 어떤 영향을 주는가에 맞춰져 있다고 합니다. 저자들은 이를 검증하기 위해, 기존 DeepSeek-OCR과의 직접적인 비교를 중심으로 다양한 문서 OCR 벤치마크에서 성능을 평가했습니다.
특히 본 논문에서는 문서 OCR을 단순 문자 인식 문제가 아니라, 시각 압축–의미 재정렬–언어 복원으로 이어지는 전체 파이프라인의 성능으로 바라보았습니다.
3.1 Experimental Setup
Baseline
DeepSeek-OCR을 기본 베이스라인으로 두고, 동일한 디코더 구조 위에 DeepEncoder V2만을 교체하여 비교 실험을 수행하였습니다. 이를 통해 성능 변화가 단순한 모델 규모 증가나 디코더 차이가 아니라, 인코더 설계 자체에서 비롯된 것임을 명확히 하고자 한 것이죠. 입력 해상도, 비전 토큰 수, 디코더 구조 등은 가능한 한 기존 DeepSeek-OCR 설정과 동일하였습니다
Dataset
평가 데이터셋으로는 다양한 레이아웃과 구조를 포함한 문서 OCR 벤치마크가 사용되었으며, 텍스트 중심 문서뿐 아니라 표, 수식, 혼합 레이아웃을 포함한 입력에서도 성능을 측정합니다. 일반적인 문서 이해 전반에 기여하는지를 확인하기 위함이라고 하네요
3.2 Main Results
먼저 DeepSeek-OCR 2가 기존 DeepSeek-OCR 대비 실제 문서 OCR 성능에서 어떤 차이를 보이는지를 비교한 결과입니다. 핵심 비교 포인트는 단순 문자 인식 정확도가 아니라, 복잡한 문서 구조를 포함한 전체 문서 이해 성능입니다.
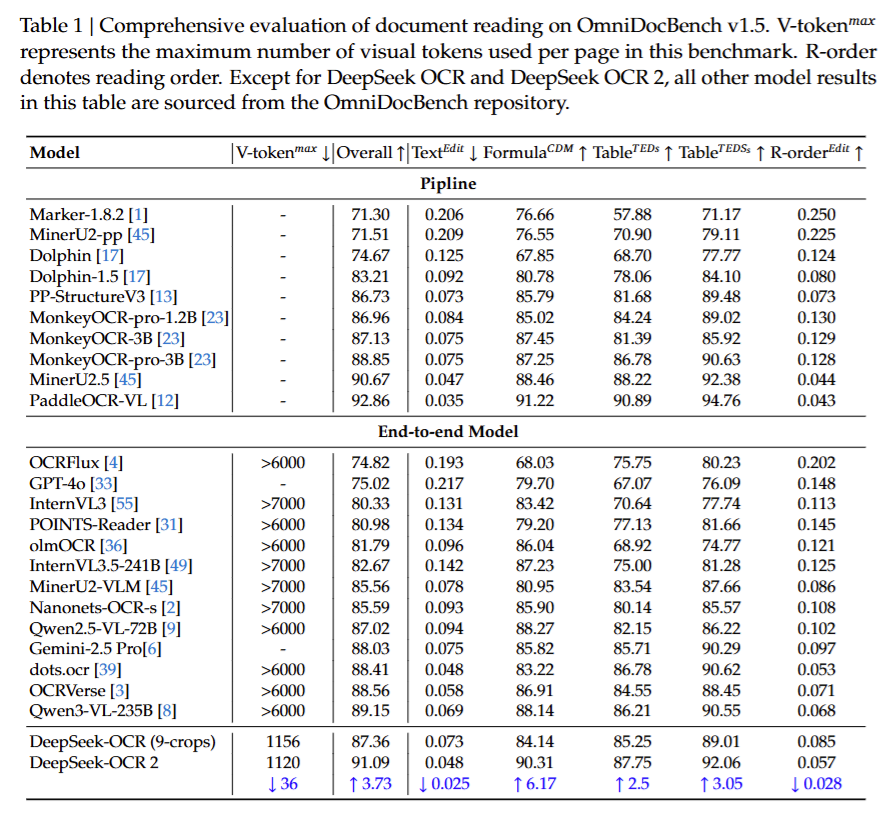
실험 결과, DeepSeek-OCR 2는 기존 DeepSeek-OCR 대비 전반적인 OCR 성능 향상을 보였으며, 특히 레이아웃이 복잡하거나 읽기 순서가 중요한 문서에서 개선 폭이 더 컸습니다. 이는 비전 토큰 수나 디코더 구조를 그대로 유지한 상태에서 얻은 성능 향상이기 때문에, 단순한 모델 규모 효과라기보다는 인코더 단계에서 도입된 Visual Causal Flow의 영향으로 해석할 수 있다고 합니다.
또한 저자들은 이를 통해, 문서 OCR에서 중요한 것은 ‘얼마나 많은 시각 정보를 보았는가’가 아니라, 그 정보를 어떤 순서로 구조화해 LLM에 전달했는가라는 점을 강조하였습니다. 즉, DeepSeek-OCR 2는 동일한 정보량을 더 잘 조직된 형태로 전달함으로써, 언어 모델의 문서 이해 능력을 효과적으로 끌어올렸다고 볼 수 있을 것 같네요
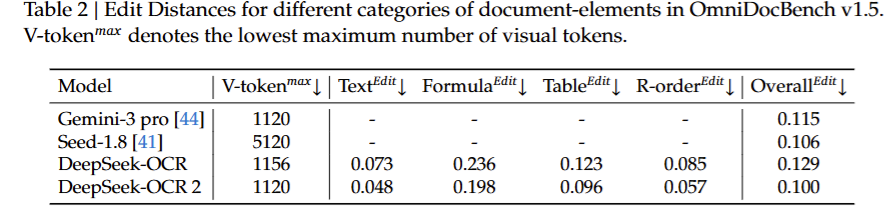
Table 2에서는 문서를 구성하는 요소를 텍스트(Text), 수식(Formula), 표(Table), 그리고 읽기 순서(R-order)로 나누어 세부적인 성능 비교를 수행했습니다. 모든 항목은 Edit Distance 기준으로 평가되었고, 특히 R-order 항목은 문서 내 요소 간의 읽기 순서 오류를 직접적으로 측정하는 지표라고 하빈다.
결과를 보면 DeepSeek-OCR 2는 모든 요소 유형에서 기존 모델 대비 낮은 오류율을, 그중에서도 R-order 항목에서 가장 큰 개선 폭을 보였습니다. 이는 DeepEncoder V2에서 도입한 causal flow 설계가 문서 요소 간의 논리적 순서를 보다 정확하게 포착한 것이죠. 또한 DeepSeek-OCR 2는 Gemini-3 pro와 유사한 수준의 시각 토큰 예산을 사용하면서도, 전체 OCR 오류율에서는 더 낮은 수치를 기록해 토큰 수 증가 없이 구조적 개선만으로 성능을 끌어올릴 수 있음을 보여주었습니다.
3.3 Improvement Headroom
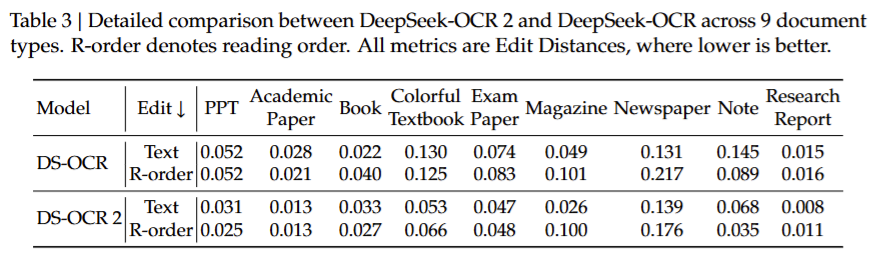
Table 3에서는 DeepSeek-OCR과 DeepSeek-OCR 2를 9가지 서로 다른 문서 유형에 대해 비교했습니다. 각 문서 유형별로 텍스트 인식 정확도(Text Edit)와 읽기 순서 오류(R-order Edit)를 분리해 측정함하여, 단순 인식 성능과 문서 구조 이해 능력을 구분하였다고 합니다
전반적으로 DeepSeek-OCR 2는 대부분의 문서 유형에서 더 낮은 Edit Distance를 기록했으며, 특히 신문, 노트, 연구 보고서처럼 레이아웃이 복잡한 문서에서 개선 폭이 컸습니다. 또한 R-order 지표에서도 일관된 성능 향상이 있었는데, 이는 제안된 ‘인과적 읽기’가 특정 문서 유형에 국한되지 않고, 다양한 실제 문서 환경 전반에서 효과적으로 작동함을 보여주는 결과였습니다.
3.4 Practical Readiness
마지막으로 Table 4에서는 실제 환경에서의 성능을 비교하였습니다. OCR 모델이 LLM 파이프라인에 포함되는 상황에서는 정답 텍스트를 직접 확인할 수 없기 때문에, 저자들은 반복 생성 비율(Repetition Rate)을 주요 지표로 사용했습니다. 값이 낮을수록 모델이 문서를 안정적으로 해석하고 있음을 의미한다고 합니다

실험 결과, DeepSeek-OCR 2는 기존 DeepSeek-OCR 대비 반복 비율을 유의미하게 감소시켰습니다. 온라인 사용자 로그 기반 이미지 입력과 사전학습용 PDF 데이터 모두에서 개선이 보였습니다. 이는 DeepSeek-OCR 2는 벤치마크 성능뿐 아니라 실제 서비스 환경에서도 안정적인 동작을 보이는 구조임을 확인할 수 있다고 합니다.
4. Conclusion
DeepSeek-OCR 2는 문서 OCR을 단순한 문자 인식 문제가 아니라, 시각 정보를 어떤 순서로 이해해야 하는가라는 질문을 고민한 연구라고 생각이 듭니다. 그러다보니 기존 DeepSeek-OCR이 ‘얼마나 적은 비전 토큰으로 문서를 압축할 수 있는가’에 집중했다면, 본 논문은 그 다음 단계로 ‘압축된 정보를 어떤 순서로 LLM에 전달해야 하는가’를 다루게 되었죠. 특히 인코더 단계에서부터 읽기 순서를 학습하도록 설계했다는 점은, OCR뿐 아니라 VLM 연구에서도 활용하면 좋을 것 같다는 생각이 들었습니다.
물론, 이러한 Causal Flow가 문서 OCR 이외의 일반적인 비전–언어 태스크에서도 동일한 효과를 낼 수 있을지에 대해서는 추가적인 실험이나 검증이 필요하긴 하겠죠. 그럼에도 불구하고, 본 연구는 ‘비전 인코더는 무엇을 보느냐보다 어떻게 읽느냐가 중요하다’는 점을 강조했고, 향후 VLM 인코더에서도 이러한 순서(order)를 중요하게 고려해야 한다는 가능성을 연 논문으로 기억할 것 같네요
안녕하세요 주영님 리뷰 감사합니다
입력되는 이미지의 영역을 학습하는 방법에 대한 제 이해가 맞는지 궁금합니다. 추가적인 Learnable query를 활용하여 positional embeding 같은 정보를 학습한다고 이해해도 될까요? 혹은 문맥 정보를 재서술 하는것이 더 가까울까요?
둘째로 LM 모델을 encoder 로 사용하는 방법이 궁금합니다. 토큰을 입력하며 프롬프트로 “토큰으로 압축”하라는 명령어를 추가하는건가요 아니면 해당 목적으로 학습된 LM인가요..?
1. learnable query는 위치(positional embedding)를 학습한다기보다는, 시각 토큰들을 어떤 의미적 순서로 읽을지 결정하는 ‘읽기 포인터’에 가까운 것 같습니다. 각 query는 모든 visual token과 이전 query들을 참고하면서, 문맥을 점진적으로 요약·재구성합니다. 따라서 단순 위치 정보라기보다는, 문맥 정보를 순차적으로 재서술하며 읽기 흐름을 형성하는 역할로 이해하시는 것이 더 정확할 것 같네요!
2. 프롬프트로 “압축하라”는 명령을 주는 방식은 아닙니다. 정말 단순하게, CLIP의 Vision Encoder 대신 LM으로 backbone을 교체한 것이죠. 비전 패치를 LM 구조에 입력하기 위해 Tokenizer로 80M SAM-base & 두 개의 convolution layer를 사용하여 정보를 약 16× 수준으로 토큰을 압축한 뒤, 이를 LM에 넣습니다. 이를 통해, LLM의 Transformer 구조와 inductive bias를 활용하되, 시각 토큰과 query 토큰을 입력으로 받아 압축 및 재정렬을 수행하도록 파라미터 자체가 학습됩니다.
안녕하세요 주영님 좋은 리뷰 감사합니다.
causal token이 방법론에서 몇 개가 사용되나요?? 만약 causal token이 여러개라면 서로 끼리도 어텐션 연산이 수행되는지 궁금합니다.
감사합니다.
causal token 개수는 고정값이 아니라, visual token 수와 1:1로 동일합니다.
따라서 설정에 따라 visual token이 256개면 causal token도 256개가 되겠죠?
그리고 causal token끼리도 어텐션 연산이 수행됩니다. 다만 causal attention이라서, 각 token은 모든 visual token + 이전 causal token들만 보게됩니다. 즉, 뒤에 있는 causal token은 보지 못하죠