안녕하세요, 허재연입니다. 오늘 리뷰할 논문은 AAAI2025에 게재된 논문으로, segmentation 기반 Video Scene Graph Generation을 다룬 논문입니다. 리뷰 시작하도록 하겠습니다.
자율주행 에이전트, 지능형 시스템, 로봇 등에 활용할 인공지능 시스템은 주변 실세계에 대한 포괄적인 이해가 필요합니다. Scene Graph Generation(SGG)은 이를 위한 task 중 하나로, 주어진 장면 내의 여러 entity들을 찾고 이들 간의 관계를 식별하는 것을 목표로 합니다. 보통 SGG에서 entity를 검출하는 부분은 bounding box 기반의 object detection으로 수행하는데, box 기반의 예측은 아무래도 사람이 시각적인 정보를 인식하는 것과 비교하면 세밀함이 떨어진다는 한계가 있습니다. 이런 한계를 극복하기 위해 제안된 pixel-level의 예측을 수행하는 segmentation 기반의 SGG를 panoptic scene graph generation이라고 합니다.
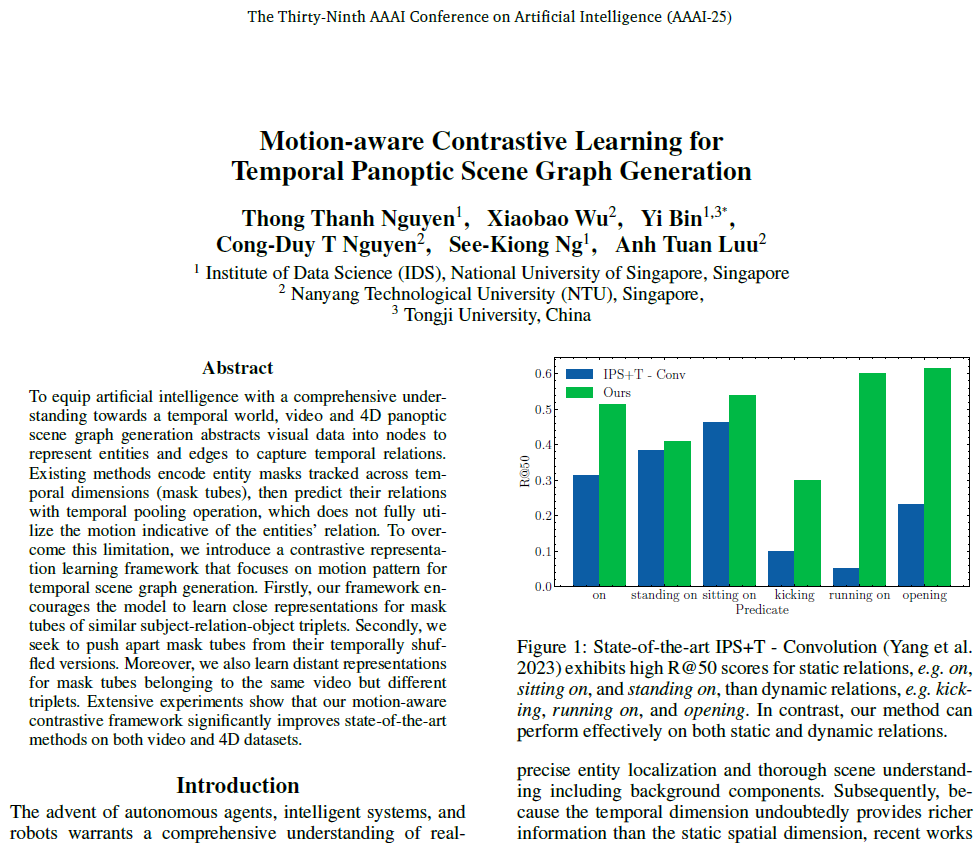
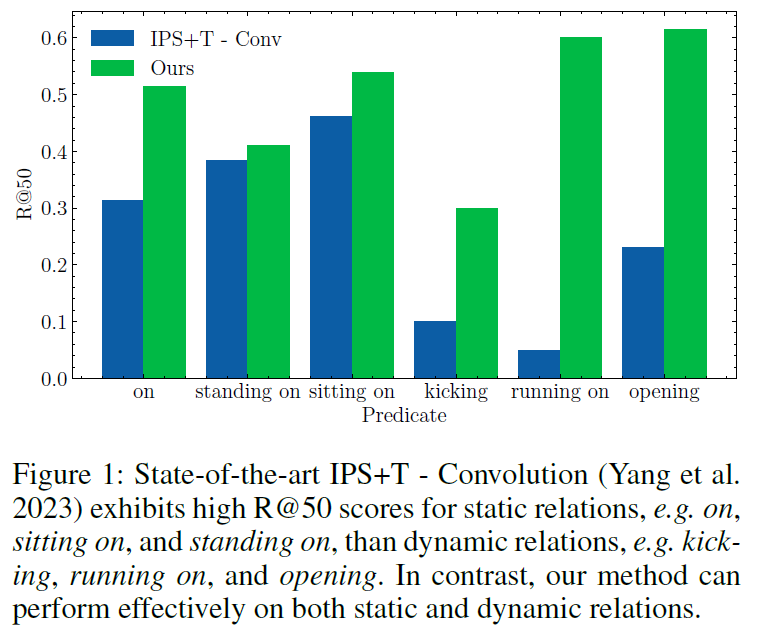
단순한 정적 이미지를 가지고 SGG 예측을 수행하는 것보다 당연히 시간 축 정보를 활용하는것이 더욱 풍부한 정보를 제공할 수 있기 때문에 최근에는 video / 4D scene 데이터로 연구가 확장되었습니다. 기존 Panoptic Video Scene Graph Generation(PVSG) 방법론들은 일반적으로 시간 축을 따라 entity mask를 이어붙인 mask tube를 생성한 다음, 이들 간의 temporal relation을 예측하는 방식으로 이루어졌습니다. relation 예측을 수행할 때 이런 방법론들은 특히 segmentation mask tube 인코딩 후 global pooling을 적용하고 이들의 relation을 분류하기 위해 MLP를 거쳤는데, 저자들은 global pooling 연산이 entity 간 relation을 결정하는데 중요한 시간적 패턴이나 모션 패턴을 표현하는데 부적절하다고 지적합니다. 결과적으로 기존 방법론들은 ‘on, standing on, sitting on, ..’과 같은 static relation은 어느 정도 예측해낼 수 있지만 ‘kickin, running on, opening, ..’과 같은 dynamic relation은 잘 예측하지 못하였다고 합니다. 아래 Figure 1. 에서 파란색 막대가 기존 방법론인데, static relation에 비해 dynamic relation을 예측하는 능력이 떨어지는 것을 확인할 수 있습니다. 반면에 제안 방법론인 초록색은 잘 되는 걸 보니, 저자가 강조하고 싶은 부분이 여기임을 알 수 있죠. 본인들의 방법론은 비교적 dynamic relation 예측이 잘 되는것을 어필하고 있습니다.
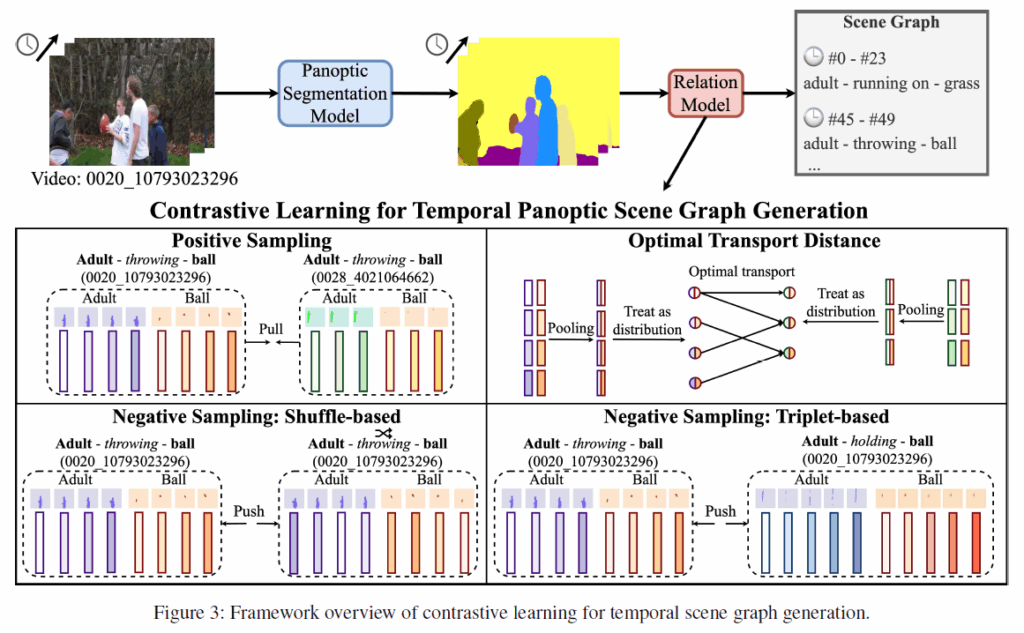
저자의 해법은 contrastive learning이었습니다. 기존 video 연구에서 temporal representation learning을 위해 contrastive learning을 도입하는것이 드문 일은 아니었는데, 저자들은 기존 대부분 연구들이 동일 비디오에서 나온 두 클립을 positive pair로 두는 것에 문제를 제기하였습니다. 이렇게 학습하면 모션 정보는 상대적으로 무시되고 시각적 장면의 semantic에 집중하게 된다는 것이죠. 또한 entity localization-level로 수행하지 않고 frame-level로 수행하는 점에도 문제가 있었습니다. 이렇게 contrastive learning을 수행하게 되면 target entity가 아닌 다른 부분의 모션 정보가 representation에 포함되어 segment들의 세밀한 relation 분류에 노이즈가 될 수 있었죠.
본 논문에서 저자들은 Temporal Panoptic Scene Graph Generaion에서 모션 패턴을 잘 포착하도록 하기 위해 segmented entity들의 mask tuve에 집중하여 contrastive learning을 수행하는 프레임워크를 제안합니다.
첫 번째로, 다들 비디오에서 마스크 튜브와, 유사한 <subject-relation-object> 의 representation을 positive로 두어 가까워지도록 하였습니다. positive mask tube를 서로 다른 비디오 클립에서 추출해 모델이 contrastive objective를 최적화할 때 visual semantic 대신 motion trajectory에 집중하게 하는 것이죠.
여기에 추가적으로 원본 tube를 시간 축으로 shuffle하여 생성된 negative mask tube끼리는 negative pair로 두어 서로 멀어지도록 하고, 동일한 비디오에 속하지만 서로 다른 triplet에 해당하는 mask tube representation도 멀어지게 하였습니다. 시각적 특징이 유사하지만 서로 다른 triplet에 해당하는 mask tube를 분리시켜서 모델이 visual semantic에 덜 의존하고 motion에 민감한 feature를 생성하도록 한 것입니다. 이 과정에서 외형적으로 유사한 negative mask tube는 hard negative sample 역할을 하기 기대합니다.
motion-aware contrastive learning 프레임워크를 구현하기 위해서는 mask tube 간 relationship을 정량화 할 필요가 있습니다(mask tube는 temporal 축으로 프레임에 걸쳐 있는 segmentation mask의 sequence이고, 이벤트마다 발생 시간이 다르기 때문에 tube의 길이는 서로 다를 수 있습니다).이 때, temporal pooling 이후 유사도를 추정하는 기존 방법론들의 경우 temporal dimension을 flatten하여 motion 특징이 무시되는 문제가 있었습니다. 이 문제를 해결하기 위해 저자들은 두 tiplet의 mask tube를 두 개의 분포로 간주하고 이들 간 optimal transportation map을 구한 다음, transport distance를 두 triplet tube 간 거리로 활용합니다. 이 방식은 두 triplet의 motion 상태를 동기화(synchronize)하는 역할을 수행할 수 있고, mask tube의 진행 과정을 활용할 수 있다는 장점이 있다고 합니다.
저자들이 주장하는 contribution을 요약하면 다음과 같습니다.
- 우리는 temporal panoptic scene graph generation을 위한 새로운 contrative learning framework를 제안한다. 이 방법은 유사한 motion pattern의 entity mask tube를 가까이, 서로 다른 motion pattern을 밀어내는 방식으로 동작한다.
- 다양한 실험을 통해 제안하는 프레임워크가 natural / 4D video 데이터셋 모두에서 동적인 relation을 인식하는데 기존 SOTA 방법론을 능가함을 확인했다.
Method
제안하는 전반적인 프레임워크는 다음 Figure 3에 나타나 있습니다.
Temporal Panoptic Segmentation
Video clip V가 주어지면, 우선 겹치지 않게 각 픽셀을 분할하고 추적합니다. 모델이 생성하는 entity masks 집합은 다음과 같이 나타낼 수 있습니다.
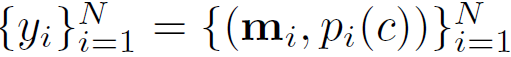
여기서 {m}_{i} ∈{0,1}은 추적된 비디오 마스크(mask tube)를 의미하고, {p}_{i}(c)는 튜브 {m}_{i}에 클래스 c를 할당할 확률을 나타냅니다. N은 entity 수입니다(panoptic segmentation이므로 thing과 stuff를 모두 포함)
Segmentation module.
기본적으로 트랜스포머 기반 모델을 활용합니다. 이 때 분할 방식에는 두가지 유형이 있습니다. 1. image panoptic segmentation combined with a tracker (IPS+T)과 2. video panoptic segmentation (VPS)입니다.
IPS+T는 비디오 프레임을 개별적으로 처리한 뒤 tracker를 사용하여 비디오 프레임 전체에 걸쳐 mask tube를 연결하는 방법이고, VPS는 각 video frame을 인접 timestamp의 reference frame과 함께 처리하는 방식입니다. 두 방법 모두 인코딩된 visual patch와 object query 간 cross-attention을 통해 예측하게 됩니다(DETR을 생각하시면 됩니다).
Training and inference
학습 중에 각 쿼리는 segmentation loss를 계산하기 위해 mask 기반 이분 매칭을 통해 GT mask와 매칭됩니다. 추론 과정에선 IPS+T는 각 프레임에 대해 panoptic segmentation mask를 생성하고, tracker를 사용하여 N개의 tracked mask tube를 생성합니다. VPS는 target frame과 reference frame의 두 가지 query embedding을 사용하고, 쿼리 별 similarity tracking을 수행하여 N개의 tracked mask tube를 생성합니다.
Relation Classification
segmentation 이후, relation module의 training 시에는 GT mask와의 tube IoU값을 기반으로 query tube를 GT mask와 매칭하고, inference 시에는 mask tube를 self-attention이나 convolution layer로 바로 forward하여 hidden representation {H}_{i}으로 인코딩합니다. 그런 다음, 모든 쿼리 튜브 representation 2개로 query pair를 구성하고(이 때 index는 i, j), 모든 쌍에 대해 각 mask tube representation의 temporal dimension으로 global pooling을 수행합니다.
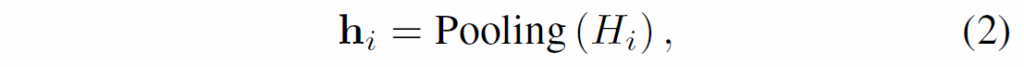
이후, {h}_{i}와 {h}_{j}을 concatenate하고 MLP로 전달해 relation category를 예측합니다.
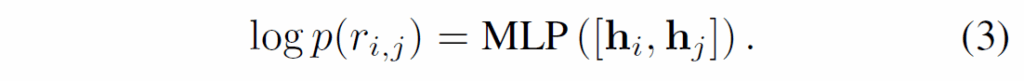
relation 분류 모델을 학습 시 loss는 예측된 log-likelihood와 GT를 기반으로 cross-entropy를 계산하여 사용합니다.
Contrastive Learning for Temporal Panoptic Scene Graph Generation
제안 프레임워크의 목표는 mask tube representation {{{H}_{i}}}_{i=1}^{N}이 motion 정보를 잘 포함하도록 하는 것입니다. 우선, GT <s-r-o> triplet에 매칭된 두 mask tube representation {H}_{i}^{sub}, {H}_{i}^{obj}을 concat하여 anchor representation인 {H}_{i,j}를 만듭니다.
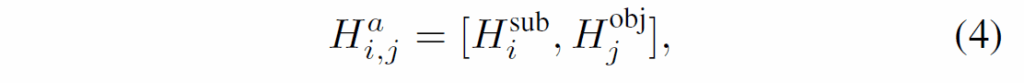
이후 contrative learning을 도입하여 모델이 motion 정보를 기반으로 mask tube를 연결하도록 유도하게 됩니다. 사용하는 contrastive loss는 다음과 같습니다. 수식(5)에서 sim은 mask tube representation pair에서 정의된 유사도 함수입니다.
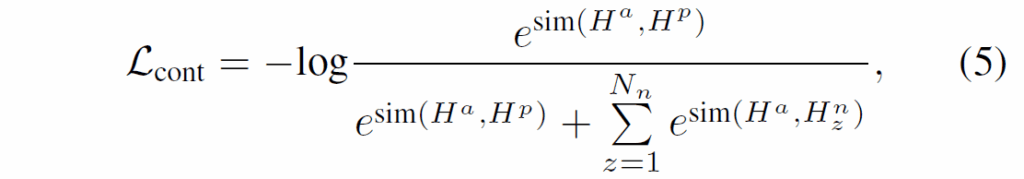
Positive sampling
앞에서 모델이 시각적 정보보다 모션 정보에 집중하게 하기 위해서 다른 비디오 클립에서 샘플링한 pair들을 positive로 둔다고 하였습니다. 다른 비디오에서 유사한 GT관계를 나타내는 동일한 주어, 목적어의 entity로부터 mask representation을 추출하여 사용합니다. 이렇게 형성된 pair는 서로 다른 visual feature를 갖고 있기에 모델이 외형적 정보보다는 <주어-관계-목적어> triplet에서 motion pattern에 집중하게 할 수 있습니다.
Negative Sampling
negative sampling에는 두가지 전략이 사용됩니다. 1. shuffle 기반 샘플링과 2. triplet 기반 샘플링으로, 하나씩 살펴보겠습니다.
Shuffle-based contrastive learning
셔플링 기반 접근법에서, anchor tube에 다음과 같이 temporal permutation π를 적용하여 shuffling을 통해 negative sample을 생성합니다.
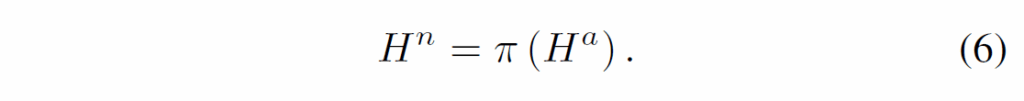
이를 통해 contrastive loss가 모델이 정상적인 순서를 가진 anchor tube의 representation을, 셔플링이 적용되어 모션 정보가 왜곡된 tube의 representation으로부터 강제로 분리하도록 유도합니다. anchor {H}^{a}와 negative sample tube {H}^{n}은 유사한 visual semantic을 공유하기 때문에 프레임 순서(모션 정보)를 통해서만 구분할 수 있습니다. 이런 방식은 학습된 representation이 frame의 시간적 순서에 민감해지도록(결국 motion에 집중하도록)유도합니다.
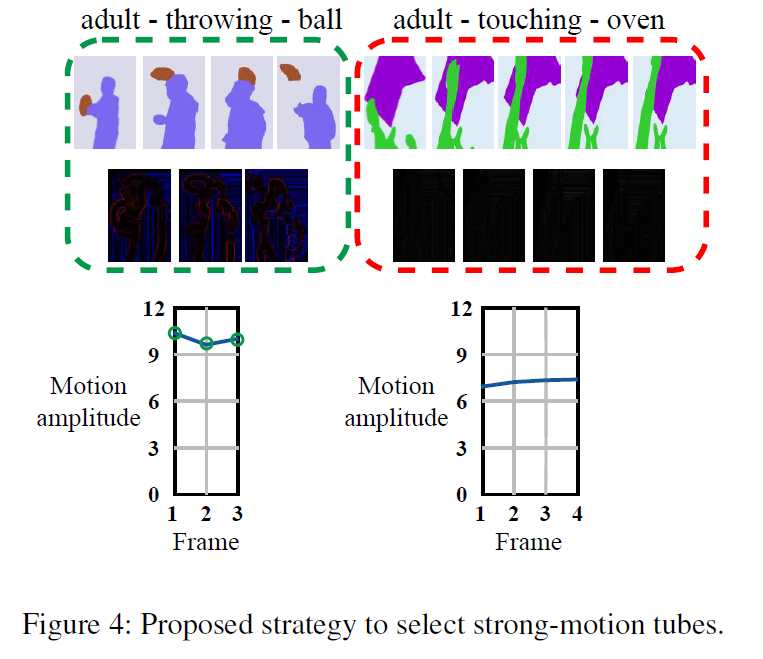
Selecting strong-motion mask tubes.
하지만 위와 같이 negative sampling을 할 경우, on, next to, in과 같은 정적인 relation의 경우 mask tube 자체에 움직임이 거의 포함되지 않을 수 있다는 문제가 있습니다. 이 경우 tube를 shuffling하더라도 anchor tube와 결과물이 거의 동일하기에 model이 이 둘을 구분하지 못해 제대로 된 학습이 이루어지지 않을 수 있습니다.
이를 해결하기 위해 Figure 4에 나타낸 것처럼 shuffling 대상으로 strong-motion을 수반하는 tube만을 선별하는 전략을 추가하였습니다.
비디오가 주어지면, mask tube의 움직임 정도를 정량화하기 위해 optical flow edges를 활용합니다. 우선 optical flow의 flow magnitude map에 sobel filter를 적용하여 흐름의 변화(edge)를 추정하고, 각 entity mask 영역 내에 해당하는 flow edge 픽셀 값들에 대해 중앙값(median)을 취합니다. 마지막으로 해당 mask tube 전체에 걸치 ㄴopticla flow 값 중 최댓값이 특정 임계값 γ을 초과하는 경우에만 셔플링 대상 튜브로 선택하게 됩니다.
Triplet-based contrastive learning
유사한 <subject-relation-object> 카테고리를 가진 triplet에서 motion-aware signal을 효과적으로 활용하기 위해 추가적으로 triplet 기반으로 negative sampling을 생성하는 방법을 적용하였습니다. 이 때 hard negative sample을 사용해 효율적으로 학습하기 위해 저자들은 anchor와 동일 비디오 내에서 negative mask tube를 선택하도록 설계하였습니다(완전히 다른 비디오/트래플렛을 활용하면 쉽게 구분이 되기에 학습 효율이 떨어짐). 이 때 다항 분포를 생성하여 anchor와 주어, 관계, 목적어 category를 더 많이 공유하는 triplet이 sampling될 확률을 높여 결과적으로 hard negative sample들이 anchor sample과 시각적으로 매우 유사하게 하였고, 이 샘플들을 학습에 활용하여 negative sample과 밀어내는 과정에서 motion semantic에 집중하도록 유도하였다고 합니다.
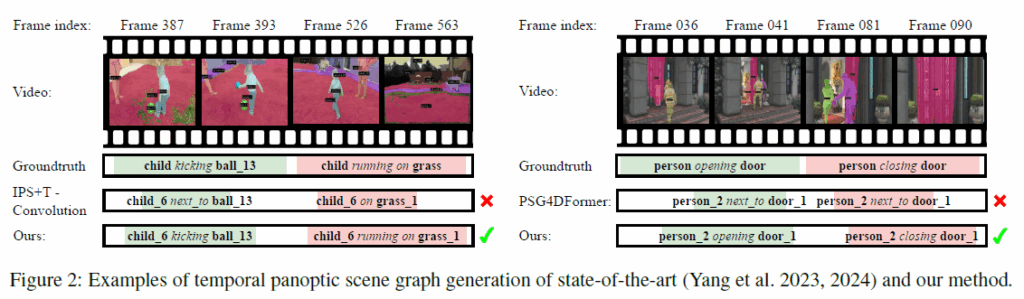
이렇게 학습한 모델은 다음 Figure 2에서 확인할 수 있듯, GT와 잘 정렬된 mask tube를 만들어내는것을 확인할 수 있습니다.
Experiment
실험은 Open-domain Panoptic video scene graph generation (OpenPVSG) 데이터셋과 Panoptic scene graph generation for 4D (PSG4D) 데이터셋에서 수행되었습니다.
OpenPVSG는 ViDOR에서 가져온 289개 3인칭 비디오와, Epic-Kitchens 및 Ego4D에서 가져온 111개의 1인칭 비디오를 포함해 총 400개의 비디오로 구성된 데이터셋이라고 합니다. scene graph 및 그 scene graph 내의 주어, 목적어 노드에 대응하는 segmentation mask로 구성됩니다.
PSG4D는 평균 길이 84초인 67개의 3인칭 비디오로 구성된 PSG4D-GTA와 평균 실이 20초인 2973개의 1인칭 비디오로 구성된 PSG4D-HOI로 만들어진 데이터셋이라고 합니다.
평가지표는 SGG쪽에서 항상 사용되는 Recall@K를 사용합니다.
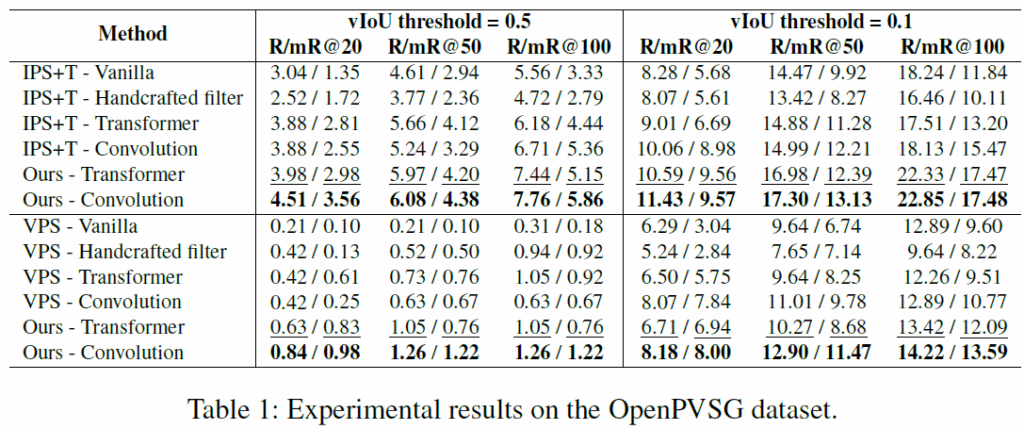
표 1은 OpenPVSG에서의 결과를 나타낸 것입니다. 표에서 확인할 수 있듯 기존 방법론들보다 제안한 contrastive learning 방법을 적용했을 때 성능이 개선되는것을 확인할 수 있습니다. 워낙 challenging한 task이다 보니 절대적인 수치가 그렇게 높지는 않네요. R@K쭌만 아니라 mR@K에서도 기존보다 개선된 결과를 보여주어 rare relation class에 대해서도 잘 동작한다는 것을 주장하고 있습니다.
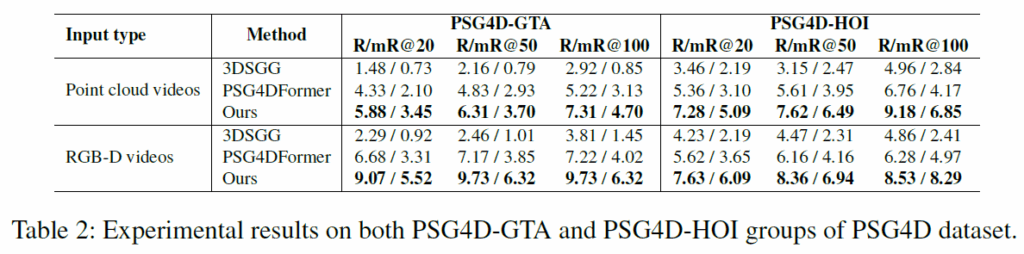
표 2는 PSG4D에서의 결과입니다. 제안하는 방법이 기존의 PSG4DFormer보다 개선된 결과를 보였습니다. PSG4D-GTA와 PSG4D-HOI 모두 기존보다 상당히 개선된 결과를 보여 제안 프레임워크가 1인칭 및 3인칭 비디오 모두에 잘 동작함을 보였습니다.
Ablation study
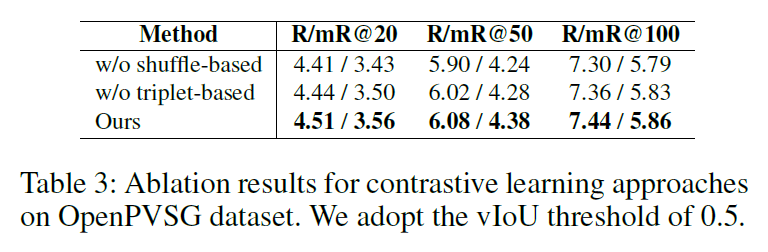
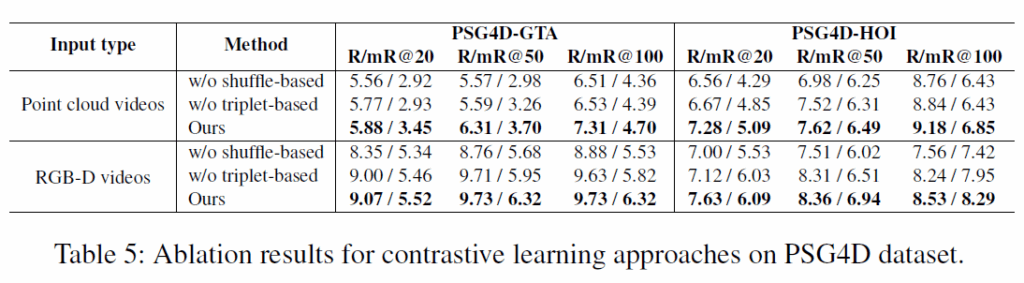
이어서 Ablation study를 살펴보겠습니다. 셔플 / 트리플렛 기반 contrastive loss에 대한 ablation을 수행했으며, negative sampling에 있어 shuffle 기반 방법과 triplet 기반 방법 모두 제거하면 성능이 저하됨을 확인하였고, 추가적으로 이 실험 결과를 바탕으로 저자들은 triplet 기반 contrastive learning이 shuffle 기반보다 더 근본적인 역할을 수행한다고 주장합니다.
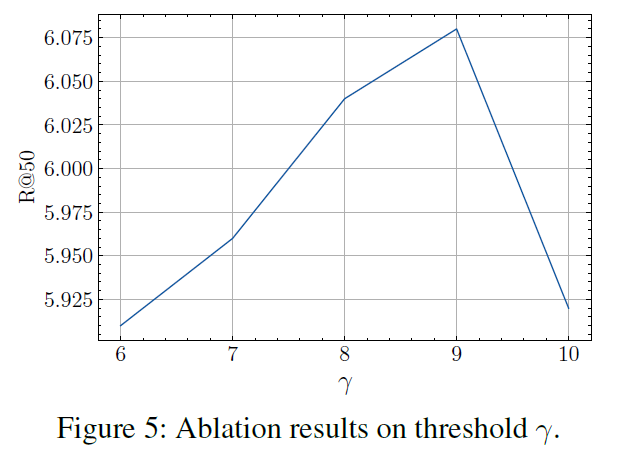
Figure 5에는 strong motion을 선택하기 위한 임계값을 높여가며 그 성능을 측정하였습니다. 임계값을 높일수록 성능이 개선되지만, 너무 많이 높이면 제거되는 mask tube가 많아져 motion-aware contrastive framework의 효과가 제한되어 성능 저하가 나타나게 됩니다.
Video Scene Graph Generation에서 모션 정보를 어떻게 활용할까 고민 중에 읽어본 논문입니다. segmentation 기반 방법론들은 detection 기반 방법론들보다도 발전 속도가 느린 느낌이 있네요. 모션 정보를 모델 구조가 아닌 contrastive learning으로 강조한 관점도 흥미로웠고, 세부 전략 설정에서 참고할 지점들이 있을 것 같습니다.
이만 리뷰 마무리하도록 하겠습니다.
감사합니다.