안녕하세요 이번에 들고온 논문은 CLIP 의 Vision 과 Text embedding의 similarity map 이 기대하는 경향성과는 반대라는점을 밝히고 개선한 논문입니다.
Abstract
우선 저자는 Contrastive Language-Image Pre-training, CLIP이 자연어 supervision을 활용해서 rich representation을 학습한다고 설명합니다. CLIP은 image-text pair를 대량으로 사용해서 이미지와 텍스트를 같은 embedding space에서 맞추는 방식으로 학습되었고, 그 결과 zero-shot classification, long-tail classification, segmentation, retrieval, caption, video task 등 다양한 downstream vision task에서 성능 향상을 보여주었습니다.
하지만 저자는 CLIP의 성능 향상과는 별개로, CLIP의 visual explainability, 특히 raw feature map 수준에서의 설명 가능성은 거의 연구되지 않았다고 말합니다. 즉, CLIP이 어떤 이미지 영역을 보고 특정 text와 맞다고 판단하는지에 대한 분석이 부족하다는 것입니다.
이를 위해 저자는 CLIP prediction을 시각적으로 설명하기 위한 Image-Text Similarity Map, ITSM을 제안합니다. ITSM은 말 그대로 image token feature와 text feature 사이의 similarity를 계산해서, 이미지의 어떤 영역이 해당 text와 더 잘 맞는지를 시각화한 것입니다.
그런데 이 ITSM을 통해 저자는 CLIP은 foreground보다 background region을 더 선호하는 경향을 보이고, human understanding과 반대되는 잘못된 visualization 결과를 나타낸다는 것을 발견합니다. 일반적으로 사람은 class text와 관련된 object foreground를 볼 것이라고 기대하지만, CLIP의 raw feature map을 보면 오히려 background 쪽이 text feature와 더 가깝게 나오는 경우가 있다는 주장입니다.

저자는 이 현상이 ViT backbone뿐만 아니라 CNN backbone에서도 공통적으로 나타난다고 말합니다. 즉, 이 문제가 특정 network architecture 때문에 생기는 것이 아니라, CLIP 구조나 pooling 방식과 관련된 더 일반적인 문제라는 것입니다.
실험적으로 저자는 문제의 원인이 pooling 방식에 있다고 언급합니다. 부적절한 pooling 방식이 semantic shift라는 현상을 만들고, 이 때문에 CLIP의 visualization이 잘못된다는 것입니다.
이를 해결하기 위해 저자는 Explainable Contrastive Language-Image Pre-training, ECLIP을 제안합니다. ECLIP은 Masked Max Pooling, MMP를 통해 CLIP의 explainability를 보정하는 방법입니다.
구체적으로는 semantic shift를 피하기 위해 기존의 attention pooling을 max pooling으로 대체합니다. Max pooling은 confident foreground에 더 집중할 수 있기 때문입니다. 또한 training 과정에서는 free attention, 즉 별도의 annotation 없이 얻을 수 있는 attention mask를 사용해서 foreground alignment를 guide합니다.
세 개 dataset에서 실험한 결과, ECLIP은 CLIP의 explainability를 크게 향상시켰고, 기존 explainability method들보다도 큰 margin으로 좋은 성능을 보였다고 합니다.
Introduction
우선 저자는 pre-training이 image classification, object detection, semantic segmentation 같은 다양한 computer vision task에서 널리 사용되고 있다고 설명합니다. 기존에는 많은 label이 필요했기 때문에, label 의존성을 줄이기 위해 weakly-supervised pre-training이나 self-supervised pre-training 방법들이 제안되어 왔습니다.
최근에는 Contrastive Language-Image Pre-training, CLIP이 4억 개의 image-text pair로 pre-training을 수행하여 굉장히 좋은 결과를 보여주었습니다. CLIP은 raw text와 대응되는 image를 직접 매칭하는 방식으로 representation을 학습합니다. 이 CLIP의 성공은 zero-shot classification, long-tail classification, domain generalization, segmentation, retrieval, video classification 등 다양한 downstream task에서 성능 향상으로 이어졌습니다.
하지만 저자는 CLIP을 개선하거나 downstream task에 활용하려는 연구는 많았지만, CLIP 자체의 explainability는 상대적으로 덜 주목받았다고 말합니다. 기존 explainability 연구 중 하나는 text와 관련된 image를 생성하는 방식으로 CLIP의 active 뉴런을 해석하려고 했지만, CAM이나 Grad-CAM류처럼 discriminative region을 직접 locate하는 방식은 아니었습니다.
또 다른 explainability 방법은 CLIP을 vision transformer로 보고, ViT의 self-attention을 이용해 이미지를 설명하려고 했습니다. 이후 rollout을 통해 class-agnostic attention map을 class-specific map으로 확장합니다. 하지만 저자는 CLIP의 self-attention quality가 좋지 않기 때문에, 이런 방식은 좋지않은 결과를 만들고 일부 region에만 집중하는 문제가 있다고 설명합니다.
저자는 위 방법들이 CLIP의 raw prediction을 visual explanation에 직접 사용하지 않는다는 점이 문제라고 합니다. CLIP의 raw prediction은 image feature와 text feature의 similarity에서 나오기 때문에, 사실 visual explanation을 위한 자연스러운 cue가 될 수 있는데 기존 방법들은 이를 충분히 활용하지 않았다는 것입니다.
그래서 저자는 CLIP의 raw prediction을 설명하기 위해 Image-Text Similarity Map, ITSM을 제안합니다. ITSM은 image token feature와 text feature 사이의 similarity map을 계산해서, CLIP이 어떤 visual region을 text와 가깝다고 판단하는지 보여줍니다.
그런데 이 ITSM으로 CLIP의 prediction을 시각화하면 위의 Abstract에서 언급한 문제점이 생깁니다. 구체적으로, image token들의 feature와 text feature 사이의 similarity를 시각화했을 때, foreground token보다 background token의 image feature가 text feature에 더 가깝게 나온다는 점입니다.
저자는 이 문제의 원인을 찾기 위해, 더 좋은 representation ability나 high-quality self-attention이 이 문제를 해결하는지 확인합니다. 하지만 결론적으로 그것만으로는 해결되지 않았고, 문제는 pooling part에 있다고 말합니다.
구체적으로 저자는 기존 attention pooling을 global average pooling과 global max pooling으로 각각 바꿔보았습니다. 그런데 이 문제는 max pooling에서만 사라졌습니다. 반면 average pooling은 attention pooling과 비슷하게 동작했습니다. 왜냐하면 attention pooling도 결국 weighted average pooling처럼 볼 수 있기 때문입니다.
저자는 그 이유를 더 분석하고, 하나의 중요한 요인을 발견합니다. 바로 semantic shift입니다. Average-like operation 때문에 discriminative location에 있던 feature가 반대 semantic region으로 shift된다는 것입니다. 쉽게 말하면 원래 object foreground에 있어야 할 class-discriminative feature가 pooling 과정에서 background 쪽 representation과 섞이거나 이동하는 현상이 생긴다는 것입니다. 이는 backbone 에 상관없이 CNN like 방식과 ViT 계열 모두에서 생길거라 예상할 수 있습니다. 그 결과 target text feature가 foreground가 아니라 background region과 매칭되어, 잘못된 시각화가 발생합니다.
이 semantic shift를 보정하기 위해 저자는 기존 attention pooling을 max pooling으로 대체합니다. Max pooling은 confident한 foreground 지역에 집중할 수 있기 때문입니다. 또한 text token이 foreground image 토큰과 더 잘 align되도록 하기 위해, self-supervised model에서 얻은 attention map을 mask로 사용해 training을 guide합니다. 이 mask는 manual annotation 없이 얻을 수 있기 때문에 저자는 freely available하다고 표현합니다.
중요한 점은 이 attention mask가 test phase에서는 사용되지 않는다는 것입니다. 또한 recognition 성능이 손상되지 않도록, 대부분의 parameter는 freeze하고 추가 projection layer만 학습합니다. 즉, 원래 CLIP의 recognition 성능은 유지하면서 explainability만 개선하려는 구조입니다.
이후 저자는 세 개 dataset에서 mask level과 score level의 explainability를 측정하는 실험을 수행합니다. 결과적으로 ECLIP은 original CLIP과 기존 conventional explainability method들을 큰 차이로 능가하며, recognition accuracy의 손실 없이 explainability를 개선한다고 주장합니다.
저자의 contribution은 크게 네 가지입니다.
첫 번째로, 저자는 CLIP의 raw prediction을 설명하기 위해 Image-Text Similarity Map을 적용했습니다. 이를 통해 CLIP이 foreground보다 background region을 더 선호하며, human understanding과 반대되는 visual result를 보인다는 것을 발견했습니다. 이 현상은 vision transformer와 convolutional network 모두에서 나타났습니다.
두 번째로, 저자는 이 문제의 원인이 pooling module에 있음을 분석했습니다. 특히 average-like operation 때문에 discriminative feature가 반대 semantic region으로 이동하는 semantic shift가 발생한다고 설명합니다.
세 번째로, 저자는 visualization result를 보정하기 위해 Masked Max Pooling을 제안했습니다. 이는 manual annotation 없이 text token을 discriminative image 토큰쪽으로 align시키며, recognition performance의 손실 없이 explainability를 개선합니다.
네 번째로, 저자는 ECLIP과 더 단순한 version인 RCLIP을 제안했습니다. 이 방법들은 original CLIP과 기존 explainability method들을 큰 margin으로 능가합니다. 예를 들어 CLIP ResNet101 기준 세 개 dataset에서 mIoU 평균이 27.26% 향상되었다고 합니다.
Methodoogy
Image-Text Similarity Map
우선 저자는 CLIP의 구성 요소를 먼저 정의합니다. CLIP은 크게 이미지 인코더, 텍스트 인코더, 그리고 각각의 특징을 같은 공간으로 보내기 위한 Projection layer로 구성됩니다. 텍스트 입력이 들어오면 텍스트 인코더는 텍스트 특징 F_t를 만들고, 이미지 입력이 들어오면 이미지 인코더는 분류용 클래스 토큰 F_c와 나머지 이미지 토큰 특징 F_i를 만듭니다. 여기서 클래스 토큰은 CLIP이 최종 예측에 사용하는 전역 이미지 표현이고, 이미지 토큰 특징은 공간적인 위치 정보를 가진 원본 특징맵에 해당합니다.
기존 CLIP은 보통 클래스 토큰만 사용해서 텍스트 특징과 유사도를 계산합니다. 즉, 이미지 전체를 하나의 벡터로 대표시킨 뒤, 이 벡터가 텍스트와 얼마나 가까운지를 보는 구조입니다. 하지만 저자는 CLIP의 예측을 시각적으로 설명하려면 클래스 토큰만으로는 부족하고, 각 이미지 토큰이 텍스트와 얼마나 유사한지를 봐야 한다고 말합니다. 요즘에는 흔하게 시각화하는 방식이라 생각하는데, 저자가 논문을 쓴 시기가 2022인걸 감안하면 꽤나 초창기에 제안했다고 생각합니다.
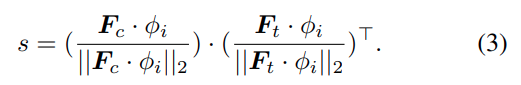
CLIP의 원래 confidence score는 이미지 클래스 토큰과 텍스트 특징을 각각 Projection 한 후 정규화하고, 두 특징 사이의 내적 유사도를 계산하는 방식입니다. 저자는 여기서 클래스 토큰대신 이미지 토큰 특징을 넣습니다. 그러면 각 이미지 토큰과 텍스트 토큰 사이의 유사도 행렬이 만들어지고, 이를 다시 원본 이미지 크기에 맞게 resize, normalization해서 최종 ITSM을 얻습니다.
쉽게 말하면, ITSM은 “CLIP이 이 텍스트를 보고 이미지의 어느 위치를 관련 있다고 판단하는가”를 보여주는 지도입니다. 예를 들어 텍스트가 “car”라면, 정상적인 경우 자동차 영역의 유사도가 높게 나와야 합니다. 그런데 저자는 다양한 CLIP backbone에서 ITSM을 만들어본 결과, CLIP의 ITSM이 사람의 이해와 반대로 잘못된 결과를 보인다고 말합니다. 즉, foreground object보다 background 쪽이 텍스트와 더 유사하게 나오는 문제가 나타난다는 것입니다.
The Devil Is in the Pooling Module
저자는 이 이상한 시각화 결과의 원인을 찾기 위해 먼저 이미지 인코더의 표현력이 문제인지 확인합니다. 즉, CLIP 이미지 인코더의 localization ability가 부족해서 background를 보는 것인지 실험한 것입니다.

이를 위해 저자는 이미지 인코더를 self-supervised 방식으로 학습된 DINO로 바꿔봅니다. DINO는 일반적으로 object localization이 잘 되는 attention map을 보여주는 모델입니다. 실제로 DINO를 사용하면 마지막 transformer layer의 self-attention quality는 CLIP보다 좋아집니다. 즉, attention map 자체는 더 foreground를 잘 잡습니다. 하지만 ITSM을 만들어보면 여전히 background에 집중하는 문제가 남아 있습니다.
따라서 저자는 이 문제가 단순히 이미지 인코더의 표현력이나 localization ability 때문이 아니라고 봅니다. 더 좋은 self-attention을 가진 backbone을 써도 ITSM이 여전히 반대로 나오기 때문입니다.
그다음 저자는 두 번째 요인으로 pooling method를 봅니다. CLIP의 parameter는 고정한 상태에서, 새로운 Projection layer를 추가하고 pooling 방법을 다르게 바꿔 실험합니다. 기존 attention pooling, global average pooling, global max pooling을 비교한 것입니다.
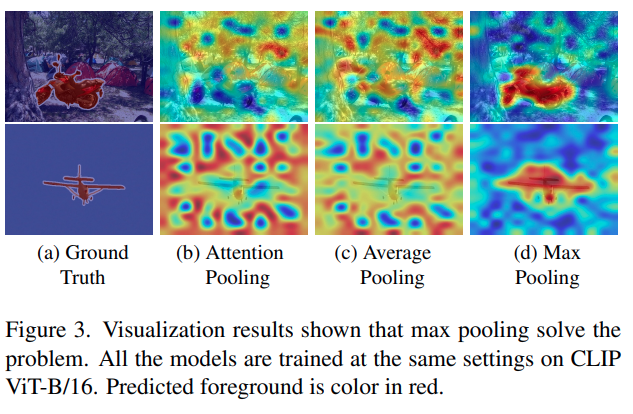
실험 결과, global average pooling은 attention pooling과 비슷한 문제를 보입니다. 이는 attention pooling도 결국 가중 평균 pooling처럼 볼 수 있기 때문입니다. 반면 max pooling을 사용했을 때만 문제가 해결됩니다. 즉, foreground 쪽이 더 잘 강조되고, 시각화 결과가 ground truth와 더 잘 맞게 됩니다. 그래서 저자는 문제의 핵심이 pooling module에 있다고 결론 내립니다.
Semantic Shift 분석
저자는 pooling module이 왜 이런 문제를 만드는지 더 분석합니다. 이를 위해 pooling 방법별로 element-wise feature comparison을 수행합니다.
방법은 각 채널마다 하나의 점을 이미지 위에 찍는 것입니다. 이때 점의 위치는 해당 채널 map에서 pooled score와 가장 가까운 값을 가진 pixel 위치입니다. 즉, 각 채널의 pooling 결과가 이미지의 어느 위치에서 주로 온 것인지를 시각화하는 방식입니다.

Max pooling의 경우 점들이 특정 영역에 강하게 모여 있습니다. 이는 max pooling이 가장 강하게 반응하는 discriminative location, 즉 foreground 쪽 특징을 잘 잡는다는 의미입니다. 반면 average pooling과 attention pooling에서는 점들이 더 넓게 퍼집니다. 저자는 이를 feature shift라고 부릅니다. 즉, 원래 discriminative location에 있어야 할 feature가 다른 위치로 퍼지거나 이동하는 현상입니다.
특히 foreground와 background 사이에서 feature가 이동하면, 이것을 semantic shift라고 설명합니다. 예를 들어 foreground object에 해당해야 할 특징이 background 쪽으로 이동하거나, 반대로 background 특징이 foreground처럼 보이게 되는 것입니다. 이 때문에 텍스트 특징이 실제 object foreground가 아니라 background region과 더 잘 match되는 이상한 ITSM 결과가 나타납니다.
정리하면, 저자의 주장은 이렇습니다. CLIP의 잘못된 시각화는 단순히 attention map이 나빠서 생기는 문제가 아니라, average-like pooling 과정에서 feature가 원래 의미 위치에서 다른 의미 영역으로 shift되기 때문에 생깁니다. 그래서 foreground가 background처럼, background가 foreground처럼 매칭되는 반대 시각화 결과가 나타난다는 것입니다.
3.3 Masked Max Pooling
앞선 분석을 바탕으로 저자는 CLIP의 설명 가능성을 개선하기 위한 첫 번째 원칙이 average-like pooling으로 인한 semantic shift를 피하는 것이라고 말합니다. 즉, attention pooling이나 average pooling처럼 여러 위치를 평균적으로 섞는 방식은 피하고, 더 확신 있는 foreground 특징을 직접 잡는 방식이 필요하다는 것입니다.
또 하나의 목적은 foreground feature를 더 강조해서 텍스트와 이미지 토큰 사이의 정렬을 강화하는 것입니다. 앞에서 DINO 같은 self-supervised model의 attention map은 CLIP보다 localization이 좋다고 했습니다. 다만 이 attention map은 class-specific하지 않고 class-agnostic합니다. 즉, 특정 class를 설명하는 map은 아니지만, object가 있을 만한 salient region은 비교적 잘 잡습니다.
저자는 이 class-agnostic attention map을 활용해서 CLIP의 설명 가능성을 보정하고, 최종적으로 class-aware visualization map을 얻고자 합니다. 이를 위해 Masked Max Pooling, MMP를 제안합니다. MMP는 semantic shift를 보정하면서 discriminative feature를 강조하기 위한 pooling 방식입니다.
중요한 점은 원래 CLIP의 recognition ability를 유지하기 위해 CLIP의 모든 parameter를 고정한다는 것입니다. 대신 이미지 인코더와 텍스트 인코더 뒤에 새로운 선형 투영층 한 쌍만 추가로 학습합니다. 즉, 원래 CLIP 자체를 크게 바꾸는 것이 아니라, 설명 가능성을 보정하기 위한 projection만 따로 학습하는 구조입니다.
또한 저자는 DINO나 MoCo 같은 offline self-supervised model에서 얻은 self-attention mask를 사용합니다. 이 attention mask는 마지막 transformer layer의 multi-head attention에서 나오며, head dimension을 평균내고 이미지 특징과 같은 shape으로 확장합니다. 이렇게 얻은 attention map을 이미지 특징에 element-wise로 곱합니다.
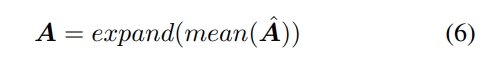
그다음 masked image feature에 대해 global max pooling을 수행합니다.
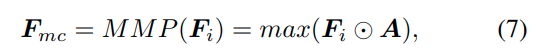
이 attention mask는 training 과정에서만 사용되고, test phase에서는 사용되지 않습니다. 즉, 학습할 때만 foreground alignment를 guide하는 역할을 하고, 실제 평가에서는 추가 mask 없이 ITSM을 생성합니다.
이후 저자는 새로 추가한 이미지-텍스트 투영층을 contrastive loss로 학습합니다. 결론적으로 MMP는 recognition performance를 건드리지 않으면서, 더 합리적인 localization result를 얻기 위한 projection을 학습하는 방식입니다.
ECLIP and RCLIP
저자는 전체 방법을 Explainable CLIP, ECLIP이라고 부릅니다. ECLIP은 크게 세 부분으로 구성됩니다.
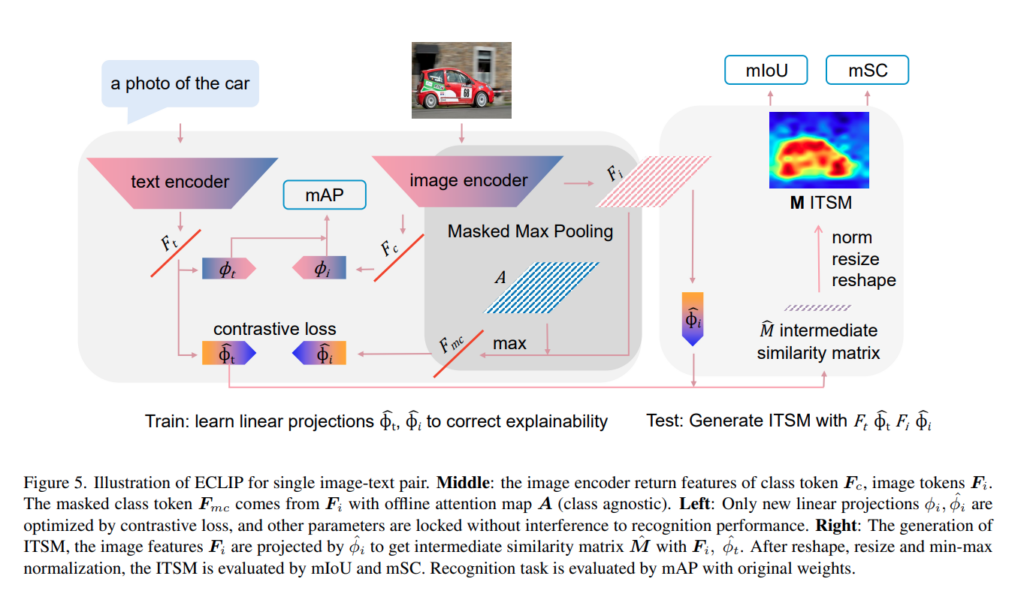
첫 번째는 새로 추가된 선형 투영층입니다. 이 투영층은 CLIP의 설명 가능성을 보정하기 위해 학습됩니다. 하지만 recognition task는 기존 CLIP parameter를 그대로 사용해서 평가합니다. 즉, 원래 CLIP의 분류 성능이 손상되지 않도록 설계한 것입니다. 저자는 계산 자원이 제한적이기 때문에 원래 CLIP처럼 대규모 데이터로 다시 학습하지 않고, 작은 dataset으로 explainability만 보정한다고 설명합니다.
두 번째는 앞에서 설명한 Masked Max Pooling입니다. Max pooling은 confident foreground를 찾는 역할을 하고, offline attention mask는 training 과정에서 foreground와 텍스트의 정렬을 guide합니다. 이 mask는 test phase에서는 사용되지 않습니다.
세 번째는 ITSM 생성 과정입니다. 새로 학습한 projection을 사용해서 이미지 토큰 특징과 텍스트 특징 사이의 similarity map을 만들고, 이를 reshape, resize, normalization해서 최종 시각화 지도를 얻습니다.
정리하면, ECLIP은 원래 CLIP의 recognition 능력은 그대로 두고, CLIP의 raw prediction을 더 사람의 이해와 맞게 설명하기 위해 projection과 pooling 방식을 보정한 framework입니다.
추가로 저자는 학습 없이 사용할 수 있는 단순한 버전인 RCLIP도 제안합니다. RCLIP의 아이디어는 CLIP의 실수를 역으로 이용하는 것입니다.
앞서 본 것처럼 CLIP의 ITSM은 foreground보다 background를 더 선호하는 반대 시각화 결과를 보입니다. 저자는 이것이 semantic shift 때문이라고 분석했습니다. 그렇다면 아주 단순하게 ITSM을 뒤집으면 foreground에 가까운 결과를 얻을 수 있다는 아이디어입니다.
그래서 RCLIP은 다음처럼 정의됩니다.
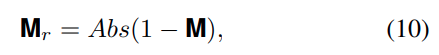
여기서 M은 기존 CLIP의 ITSM이고, Mr이 뒤집은 RCLIP의 prediction map입니다. 즉, CLIP이 background를 높게 본다면 그 반대 영역을 foreground로 보는 식입니다. 학습 없이 간단히 적용할 수 있다는 장점이 있지만, 근본적으로는 ECLIP처럼 projection을 학습해 explainability를 보정하는 방식은 아닙니다.
Experiments
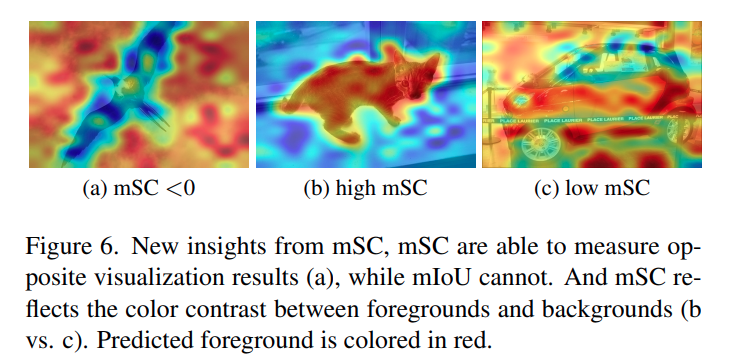
저자는 explainability를 score level에서도 보기 위해 mSC, 즉 mean Score Contrast라는 지표를 제안합니다. mSC는 foreground의 평균 score에서 background의 평균 score를 뺀 값입니다. 범위는 100%에서 -100%까지입니다. 만약 mSC가 0보다 작다면, foreground보다 background score가 더 높다는 뜻입니다. 즉, 모델이 background를 더 선호하는 반대 시각화 문제가 있다는 것을 의미합니다.
mSC가 필요한 이유는 두 가지입니다. 첫 번째로, mIoU만으로는 opposite visualization을 제대로 측정하기 어렵습니다. 예를 들어 모델이 foreground와 background를 반대로 보고 있어도, threshold나 mask 형태에 따라 mIoU만으로는 그 현상이 명확히 드러나지 않을 수 있습니다. 반면 mSC는 background score가 foreground보다 높으면 음수로 나오기 때문에, CLIP이 background를 더 선호하는 현상을 직접 보여줄 수 있습니다. 두 번째로, mSC는 foreground와 background 사이의 색상 대비, 즉 score contrast를 반영합니다. mSC가 높다는 것은 foreground와 background의 score 차이가 뚜렷하다는 뜻이고, 시각화 결과가 더 명확하다는 의미입니다. 반대로 mSC가 낮으면 foreground와 background의 구분이 흐릿해서 explainability가 좋다고 보기 어렵습니다.
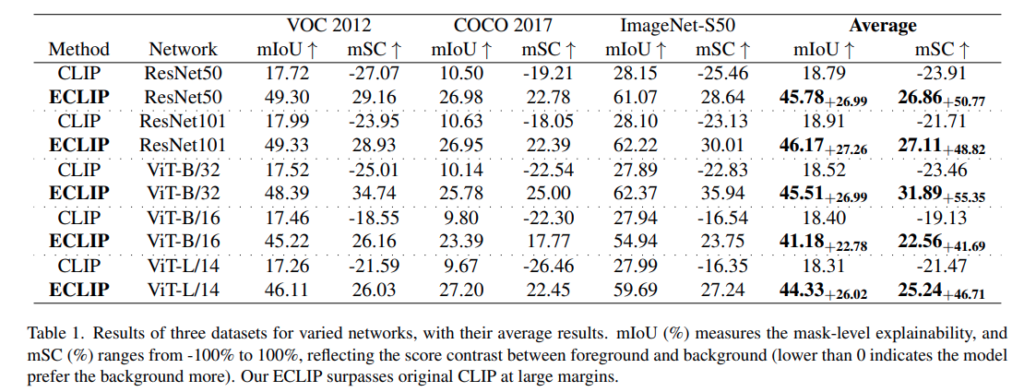
먼저 저자는 세 개 데이터셋에서 original CLIP과 ECLIP을 비교합니다. Table 1을 보면 ECLIP은 original CLIP에 비해 explainability 성능을 매우 크게 향상시킵니다. 이 개선은 ViT뿐만 아니라 ResNet 같은 convolutional network에서도 공통적으로 나타납니다. 즉, 앞에서 말한 background preference 문제가 특정 backbone의 문제가 아니라는 주장과 연결됩니다. mSC에서도 차이가 훨씬 명확합니다. Original CLIP의 mSC는 대부분 음수입니다.
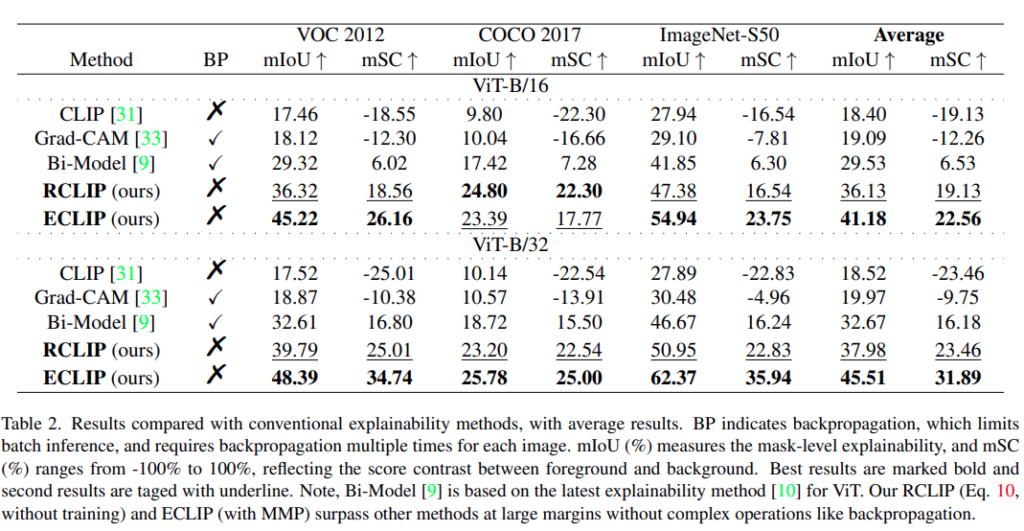
다음으로 저자는 ECLIP을 기존 설명 가능성 방법들과 비교합니다. 여기서는 ViT-B/32와 ViT-B/16을 backbone으로 사용합니다. ViT-B/32는 앞선 결과에서 성능이 가장 좋았고, ViT-B/16은 상대적으로 가장 낮았기 때문에 두 경우를 비교 대상으로 삼은 것입니다.
비교 방법으로는 대표적인 gradient-based method인 Grad-CAM과, transformer 기반 최신 explainability method인 Bi-Model을 사용합니다. 그리고 CLIP의 ITSM, 학습이 필요 없는 RCLIP, 그리고 ECLIP도 함께 비교합니다.
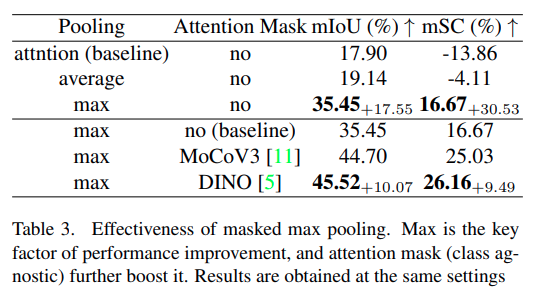
다음으로 저자는 Masked Max Pooling이 실제로 중요한지 ablation study를 통해 확인합니다. 결과를 통해 Max pooling이 반대 시각화 문제를 해결하는 핵심이고, self-supervised attention mask는 salient region을 학습 중에 guide해서 성능을 추가로 높이는 역할을 한다는 것을 알 수 있습니다.

Conclusion
결론적으로 저자는 CLIP의 raw prediction map을 직접 시각화해서 CLIP의 설명 가능성을 분석했다고 정리합니다. 기존 explainability 방법처럼 attention map이나 gradient를 우회적으로 보는 것이 아니라, CLIP이 실제로 prediction에 사용하는 image-text similarity를 기반으로 시각화했다는 점이 핵심입니다. 그리고 발견한 attention 역전 현상을 간단한 Pooling layer학습만으로 해결했습니다.
전체적으로 실험이나 분석이 좀 더 딥한게 많았다면 좋았을텐데, 좋은학회에 제출했다가 떨어지게 됐네요. 해당 랩에서 후속연구로 제출한 논문들은 그래도 탑티어 학회에 모두 붙은거로 확인했습니다.
감사합니다.
안녕하세요 인택님. 좋은 리뷰 감사합니다.
semantic shift의 경우 객체의 형태가 전반적으로 다른 윈도우로 밀리는 현상을 의미하나요?
이를 개선하기 위해 단순히 물체 영역을 믿는것이 아닌 디노이징 기법으로 shift를 개선하여 ITSM을 생성 모듈을 학습한 것이 맞나요?
안녕하세요 유진님 좋은 댓글 감사합니다.
객체의 형태가 전반적으로 다른 윈도우로 밀렸다기보다, global 한 정보를 뽑아내는 방식으로 학습되거나 그러한 semantic 한 정보 하나로 표현되게끔 학습된 CLIP like 모델의 경우(CNN 백본과 ViT 백본 모두 동일하며 DINO 백본까지도 동일현상 포착) 간단한 MLP 를 통과시켜 Max pooling으로 간단한 추가학습만으로 저희가 Text & Patch similarity로써 기대하는 local 정합을 만들 수 있더라를 보여준 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
ECLIP은 recognition performance를 유지한다고 하지만,실제 map 생성에는 새로 학습한 projection layer가 사용되는 것으로 이해했는데, 뭔가 제가 잘 이해를 못한거 일 수 있는데 원래 CLIP의 explainability와 공정하게 비교하려면 추가 projection layer를 학습하지 않은 조건도 있어야할 거 같은데 관련된 실험이 있었는지 궁금합니다. 감사합니다.
안녕하세요 인택님, 좋은 리뷰 감사합니다.
CLIP의 vision, text embedding의 유사도 맵이 기대하는 경향성이 반대라는 점이 흥미로웠습니다.
질문이 있어, 댓글로 남기겠습니다.
1 ) Methodoogy – Image-Text Similarity Map (3) 번 식의 s는 기존의 CLIP의 confidence score를 의미하는 것이고 해당 식에서 F_c 클래스 토큰을 F_i 이미지 토큰으로 대치하여, M_hat이라는 ITSM 식을 만들었다는 것인가요? (이를 원복 이미지 크기에 맞게 변환하여 시각화)
2) Attention map, ITSM을 통해 모델이 어느 영역을 집중하고 있는지 확인하는 실험에서, DINO로 바꾸었을 때 attention 자체는 foreground를 잘 잡는 것을 확인하였습니다. 그러나, ISTM에서는 여전히 foreground를 잡지 못하는 것이, 쉽게 이해가 가지 않습니다. 또한, 실제로 task를 수행함에 있어서, attention이 잘 잡은 Foreground를 잘 활용하지 못한다는 것인지 의문이 생깁니다.
감사합니다.