안녕하세요 이번에 들고온 논문도 마찬가지로 VLM 에서의 Token pruning 논문입니다.
Abstract
대형 Vision-Language Models (LVLMs) 는 일반적으로 텍스트 토큰보다 훨씬 많은 수의 시각 토큰을 포함하고 있으며, 이로 인해 상당한 계산 비용이 발생합니다. 25 뉴립스 기준으로는 기존의 token pruning 방법론들은 보통 text-vision crossa-attention 또는 CLIP ViT의 [CLS] attention을 사용하여 visual token의 중요도를 평가하고, redundant한 visual token을 제거해왔습니다.
저자의 연구에서는 이러한 attention-first pruning approach의 한계를 언급하고, attention을 우선적으로 사용하는 pruning 방법론들이 의미적으로 서로 비슷한 token을 보존하는 경향이 있어서 높은 pruning ratio에서는 뚜렷한 성능 저하가 발생한다고 언급하고있습니다.
이를 해결하기 위해서 저자는 HoloV를 제안하고 이는 제가 계속 리뷰해왔던 plug and play 방식의 visual token pruning 방법론입니다. 구체적으로 HoloV는 서로 다른 spatial crop 에 pruning budget을 adaptvie하게 분배하고 이를 통해 남겨진 token들이 고립된 salient feature만 포착하는 것이 아니라, global visual context를 포착하도록 합니다. 이 방식이 representional collapse를 최소화하고 aggressive pruning 상황에서도 task-relevant information을 유지하도록 한다고 합니다.
Introduction
우선 저자는 Multimodal Large Language Models, MLLMs가 image captioning, visual question answering 같은 다양한 task 에서 뛰어난 성능을 보이고 있다고 합니다. 하지만 이러한 MLLM 들이 누누히 말해온 visual token 들의 redundant 한 token수 때문에 high-resolution imgae 나 multi-frame video 에서 입력 토큰 낭비를 일으킵니다. 즉 inference cost가 증가하고 computational complexity가 크게 증가한다고 할 수 있습니다.
이 문제를 해결하기 위해서 기존 방법들은 보통 중요한 visual token, 즉 highlighted visual token은 유지하고, 나머지 token은 제거하여 MLLM inference를 가속하려는 방식입니다. 이러한 토큰을 구하기 위해서 attention score나 gradient information 같은 기준을 사용합니다. 그리고 inference phase 에서 덜 중요한 token을 제거함으로써 속도와 성능 사이의 trade-off를 맞추려고 합니다. 하지만 저자는 이러한 방식에는 한계가 있다고 합니다.
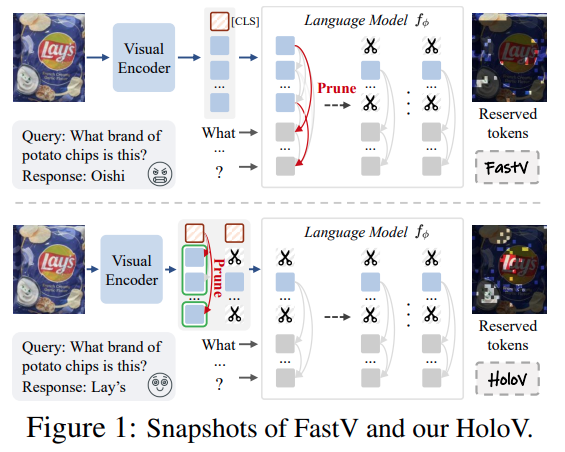
Figure1에서 보이는 것처럼 대표적인 방법론인 FastV는 서로 다른 layer에서 visual token의 attention distribution을 기반으로 token 을 ranking 하고 computational budget에 따라 하위 R% 의 token을 제거합니다. 즉 attention score가 높은 token은 남기고 낮은 token 은 pruning 하는 직관적인 방식입니다. ( 요즘에는 FastV를 메인으로 지적하면서 Figure를 만들면 아마 좋은곳에 붙지 못할정도로 예전 고전 논문입니다.) 이후 많은 연구들도 이 paradigm을 따라서 LLM 내부의 cross-modal attention 쪽을 연구해왔습니다.
또 다른 흐름은 vision-centric pruning method입니다. 에를들어 FasterVLM 같은 방법은 ViT의 [CLS] token과 correlation이 낮은 visual token, 또는 feature 가 중복되는 token 을 redundant 하다고 보고 제거하는 방법입니다. 즉 LLM 내부 attention을 쓰는 방법도 있고, vision encoder 내부의 [CLS] attention이나 feature duplication을 기준으로 token을 줄이는 방법이 주류였습니다.
하지만 저자는 이러한 pruning method들이 visual token이 비효율성을 인식하고 있음에도, 항상 효과적인 것은 아니라고 말합니다.
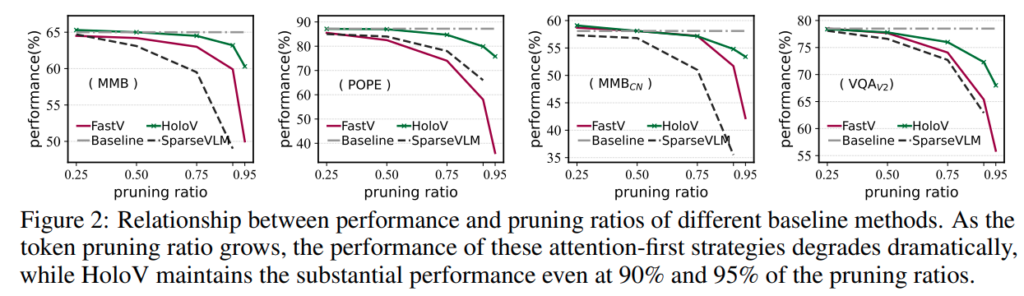
Figure 2 를 보면 pruning ratio가 증가할수록 기존 attention-first strategty들의 성능이 크게 떨어집니다. 특히 90% 95% 처럼 매우 강하게 pruning 할수록 성능 저하가 뚜렷하게 나타납니다. 반면 HoloV는 높은 pruning ratio 에서도 상대적으로 성능을 잘 유지한다고 합니다.
저자의 주장은, 기존 방법들이 암묵적으로 attention이 높은 visual token일수록 더 informative하다고 가정하기 때문에 문제가 생긴다는 것입니다. 하지만 attention score가 높다는 것이 반드시 이미지 전체 이해에 필요한 정보를 담고 있다는 뜻은 아닙니다. 이런 방식은 visual scene의 spatial-semantic relation, 즉 공간적 의미적 관계를 충분히 고려하지 못하고 결과적으로 attention 이 몰리는 localized salient region의 token 만 남기기 쉽다는 것입니다. 이미지 전체의 holistic semantic comprehension이 필요한 token을 버릴 수도 있어서 저자는 이렇게 하이라이트된 token 만 남기면 object 사이의 relative position ,semantic connectivity, 또는 질문의 subject와 관련된 key token이 사라질 수 있다고 하는 것입니다. 그 결과 성능이 크게 떨어질 수 있다고 합니다. 또한 저자는 attention mechanism 자체에도 systematic bias가 있다고 말하는데 트랜스포머 기반 MLLM의 positional encoding 매커니즘이 spatial prior를 만들 수 있고 이로 인해 이미지 위쪽이나 아래쪽 영역에 visual token 들의 attention score가 높게 쏠릴 수 있습니다.

해당 attention shift는 25년도에 token pruning 을 다뤘던 논문들이 주로 다루는 가장 화제였던 문제점입니다.
저자는 위의 attention 기반의 방법론들을 까기 위해서 인간의 visual system이 local feature와 global scene cue를 통합하여 완전한 semantic understanding을 형성한다는 점을 언급합니다. 예를 들어 background texture나 spatial layout 같은 정보도 전체 장면 이해에 중요하다는 것입니다. MLLM에서도 저자는 서로 다른 visual token들이 text와 어떻게 mapping 되는지 분석했고, Figure 3 왼쪽에서 보이는 것처럼 scene 안의 object나 context는 이미지의 여러 crop 에 흩어진 소수 token 들로 표현될 수 있다고 합니다. 예를 들어 snow , ski , hills 같은 token 들은 서로 떨어져 있어도 함께 보면 전체 장면을 이해하는 데 중요한 semantic relation을 형성합니다.
이러한 insight 를 바탕으로 저자는 HoloV를 제안하고 visual token pruning 과정에서 overall semantic connectivity와 contextual attention 을 명시적으로 균형 있게 고려합니다. 이를 통해 attention first strategy 가 가지는 critical limitation, 즉 attention이 높은 token 만 따라가다가 redundancy가 생기고 holistic context를 잃는 문제를 해결하려고 합니다.
Information Redundancy in Highlighted Tokens
다시 말하면 저자는 attention score만을 기준으로 visual token을 선택하면, 모델이 서로 비슷한 token cluster를 남기게 되고, 그 결과 information redundancy가 발생한다고 설명합니다. 즉, attention이 높은 token을 남긴다고 해서 항상 다양한 정보를 보존하는 것은 아니라는 것입니다.

Figure 4 왼쪽을 보면, 비슷한 visual feature를 가진 인접 token들이 비슷한 attention score를 받는 경우가 자주 나타납니다. 특히 flat background나 repetitive texture처럼 시각적으로 반복되는 영역에서는 주변 token들이 서로 유사한 정보를 담고 있기 때문에 attention score도 비슷하게 나올 수 있습니다. 이런 token들은 공간적으로도 가까이 있기 때문에 서로 overlapping feature를 포착하게 되고, 결과적으로 highlighted되지는 않았지만 실제로 informative한 token을 구분하기 어려워진다고 합니다.
즉, 기존 attention-first pruning은 attention이 높은 token을 잘 고르는 것처럼 보이지만, 실제로는 특정 영역의 유사한 token들을 여러 개 남기는 문제가 생길 수 있습니다. 이게 저자가 말하는 highlighted token 내부의 information redundancy입니다.
Positional Bias
다음으로 저자는 attention-based pruning method를 더 자세히 보기 위해 FastV를 예시로 retained visual token의 분포를 시각화합니다.
Figure 4 오른쪽을 보면, FastV에서 보존되는 token들이 이미지 전체에 균등하게 퍼지는 것이 아니라, 특정 위치에 반복적으로 몰리는 경향이 나타납니다. 저자는 image token의 attention score가 일관된 pattern을 보인다고 말합니다. 특히 visual token sequence의 앞부분과 끝부분에 위치한 token들이 더 높은 attention을 받는 경향이 있고, 이 token들이 pruning 과정에서 더 자주 보존됩니다. 이것을 저자는 positional bias라고 부릅니다.
저자는 VQA V2의 text-based VQA task sample들에 대해서도 통계를 냈는데, task가 다르더라도 같은 layer에서 image token들의 attention distribution이 상당히 유사하게 나타났다고 합니다. 즉, 특정 sample에서 우연히 그런 것이 아니라, MLLM 내부에서 반복적으로 나타나는 attention pattern이라는 것입니다.
layer에 따라 attention distribution의 전체 shape은 조금씩 바뀌지만, 상대적으로 높은 attention을 받는 token들의 위치는 안정적으로 유지된다고 합니다. 저자는 이러한 현상이 모든 visual token이 decoding 과정에서 text token과 같은 방식으로 처리되기 때문에 발생한다고 해석합니다.
조금 풀어서 말하면, text에서는 sequence의 앞이나 뒤, 또는 boundary position이 중요한 정보를 담는 경우가 많습니다. 그런데 transformer의 positional encoding이나 decoding 구조가 이런 text bias를 visual modality에도 가져오면서, image token에서도 sequence boundary 쪽 token들이 중요하다고 잘못 판단될 수 있다는 것입니다. 하지만 이미지에서는 보통 중요한 object가 중앙에 있는 경우가 많기 때문에, 이런 positional bias는 실제 visual semantics와 맞지 않을 수 있습니다.
Holistic Context Trumps Local Duplicates
이전 분석을 바탕으로 저자는 attention-first pruning method들이 over-localization 문제를 가진다고 말합니다. 즉, attention score에 지나치게 의존하면 특정 지역에 token이 몰리게 되고, spatial-semantic relationship이 깨질 수 있다는 것입니다. 예를 들어 multi-object interaction이 있는 이미지에서는 object들 사이의 occlusion hierarchy나 relative position이 중요할 수 있습니다. 그런데 attention score가 높은 object patch만 남기면, object 간 관계나 background context가 사라질 수 있습니다.
그래서 저자의 핵심 insight는 다음입니다. visual token의 중요도는 isolated attention magnitude만으로 평가하면 안 되고, holistic context와 local saliency를 함께 고려해야 한다. 즉, token 하나하나의 attention score만 보는 것이 아니라, 이미지 전체 맥락 안에서 해당 token이 어떤 semantic connectivity를 가지는지를 봐야 한다는 것입니다.
저자는 이 가설을 검증하기 위해 아주 단순한 실험을 합니다. 바로 random mask를 이용해 visual token을 pruning하는 것입니다.
이 random strategy는 attention score를 기준으로 highlighted token만 남기는 것이 아니라, 이미지의 여러 region에서 token이 랜덤하게 남게 됩니다. 따라서 특정 salient region에만 token이 몰리는 것을 막고, 전체적인 visual context를 어느 정도 보존할 수 있습니다.
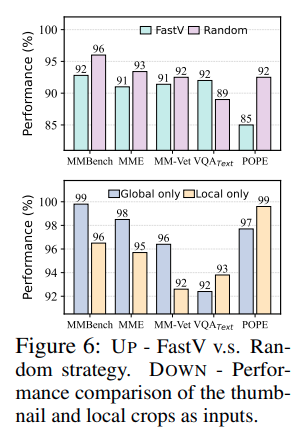
Figure 6 위쪽을 보면, 이 random strategy가 FastV보다 절반 이상의 benchmark에서 더 좋은 성능을 보입니다. 이는 매우 중요한 결과입니다. 왜냐하면 random pruning이 sophisticated한 attention-based pruning보다 나은 경우가 있다는 것은, attention score만 쫓는 방식이 실제로 holistic context를 충분히 보존하지 못한다는 뜻이기 때문입니다.
다만 TextVQA에서는 random strategy가 실패했다고 합니다. 이유는 TextVQA처럼 작은 글자나 특정 local detail이 중요한 task에서는 random pruning이 salient fine-grained information을 버릴 수 있기 때문입니다. 이 결과는 holistic context만으로도 부족하고, local saliency 역시 반드시 필요하다는 것을 보여줍니다.
즉, 저자는 random pruning 실험을 통해 다음을 보입니다. 전체 context를 유지하는 것은 중요하지만, fine-grained task에서는 salient local token도 필요하다. 따라서 좋은 pruning은 holistic context와 local saliency를 모두 고려해야 한다.
Methodoogy
앞선 분석을 기반으로 저자는 HoloV를 제안합니다. HoloV는 visual understanding을 위해 이미지의 holistic context를 더 잘 보존하는 visual token pruning 방법입니다.
중요한 점은 HoloV가 LLM decoder 이전에 redundant visual token을 제거한다는 것입니다. 즉, LLM 내부에서 pruning하는 방식보다 더 빠른 inference가 가능합니다. 왜냐하면 LLM에 들어가기 전에 token 수 자체가 줄어들기 때문에, 이후 attention 연산과 KV cache 부담이 함께 줄어들기 때문입니다.

Figure 7은 HoloV의 전체 구조를 보여줍니다. 저자는 특히 high pruning ratio에서도 semantic completeness를 유지하기 위해 HoloV가 visual token compression을 어떻게 가이드 하는지 보여줍니다.
저자는 Sec. 1에서 제기한 핵심 질문, 즉 highlighted되지는 않았지만 holistic visual understanding에 중요한 token을 어떻게 보존할 것인가에 답하기 위해 HoloV framework를 제안합니다.
HoloV의 핵심은 crop-wise adaptive allocation입니다. 이는 이미지 전체 token을 한 번에 top-k로 자르는 것이 아니라, visual token을 crop 단위로 나누고, 각 crop에 적절한 token budget을 할당하는 방식입니다. 이를 통해 attention이 특정 highlighted region에만 몰리는 것을 막고, non-highlighted but heterogeneous token, 즉 강조되지는 않았지만 서로 다른 정보를 담고 있는 token들도 보존하려고 합니다.
저자는 positional bias에 대한 분석을 바탕으로, 먼저 visual token을 local crop들로 재배열합니다. 전체 image token 수를 N_v라고 하면, 이를 C개의 crop으로 균등하게 나눕니다. 이렇게 하면 모델이 spatial granularity를 유지할 수 있고, local statistics와 global statistics를 모두 계산할 수 있습니다.
각 crop c에 대해 normalized embedding을 다음과 같이 둡니다.
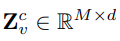
여기서 M은 하나의 crop 안에 있는 token 수이고, d는 embedding dimension 입니다.
먼저 crop 내부 token 들 사이의 similarity matrix를 계산합니다.

여기서 I 는 identity matrix로 자기 자신과의 내적은 masking 해준다 생각하면 됩니다. 그 다음 intra crop diversity 를 semantic distribution의 variance로 계산합니다.
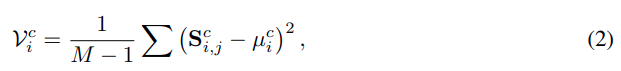
여기서 V값이 높다는 것은 i 번째 token 이 crop 내부의 다른 token 들과 다양한 관계를 가지고 있다는 의미입니다. 즉 이 token 이 crop 내부에서 중요한 visual semantics를 담고 있을 가능성이 높다고 보는 것입니다. 이후 holoV는 contextual diversity와 attention saliency를 결합한 balanced scoring mechanism을 만듭니다. 구체적으로 crop 내부 variance와 [CLS] attention 을 adaptive scaling을 통해 결합합니다.
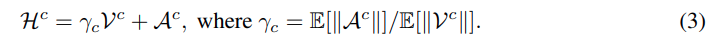
Adaptive Holistic Token Allocation
다음으로 HoloV는 전체 scene semantics와 spatial diversity를 보존하기 위해 crop-level priority score를 계산합니다. 각 crop 에 있는 token score의 평균을 사용해서 crop 의 중요도를 계산하고 ,전ㅊ ㅔretained token budget 을 crop 의 중요도에 따라 동적으로 배분합니다.
즉 모든 crop 에 같은 수의 token을 주는 것이 아니라 더 informative 한 crop 에는 더 많은 token 을 주고 덜 중요한 crop ㅇ네느 더 적은 token 을 주는 방식입니다.
crop importance weight는 다음과 같이 계산됩니다.
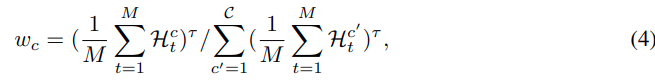
여기서 τ는 allocation의 sharpness를 조절하는 값입니다. 다만 discrete allocation을 하다보면 crop 별 토큰 합이 정확히 맞지 않을 수 있고, 특정 crop에 너무 많은 token이 할당되는 overlfow가 발생할 수 있습니다. 그래서 저자는 iterative reallocation procedure를 통해 rounding 과 overflow 문제를 해결합니다. 만약 어떤 crop 에 할당된 token 수가 crop capacity를 초과하면, surplus token을 다른 crop에 다시 나눠주고 반대로 토큰이 부족하면 남은 token을 crop level score가 높은 crop 에 추가로 할당합니다. 각 crop 에서는 Holistic score가 높은 token 을 결정하게 됩니다.
Fast Visual Context Refetching
저자는 추가적으로 visual context refetching이라는 mechanism도 제안합니다. 이는 attention sink와 visual token pruning 과정에서 발생할 수 있는 information loss에서 동기를 얻은 것입니다.
구체적으로, HoloV는 pruning된 token들을 완전히 버리는 것이 아니라 supplementary evidence로 간주하고, inference 중 모델의 uncertainty가 높게 나타날 때 이 token들을 다시 보충 정보로 사용합니다.
저자는 pruned token들을 MLLM의 middle trigger layer에서 FFN을 통해 key-value memory처럼 다시 주입한다고 설명합니다. 즉, 평소에는 pruning된 token을 사용하지 않다가, 모델이 불확실해 보이는 경우에 빠르게 visual holistic context를 보완하는 방식입니다.
다만 이 부분은 본문에서는 자세히 설명하지 않고, 세부 내용은 Appendix D에 있다고 합니다.
Experiments
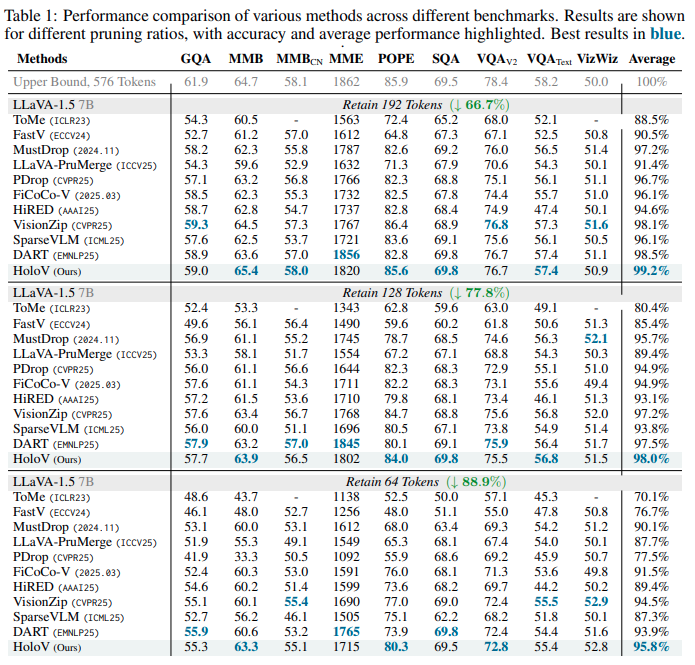
다른 방법론들이 보통 5~6 개정도 방법론들을 reporting 하는 반면 해당 논문은 좀 더 리포팅한 것을 확인할 수 있습니다. 기존 방법론들과의 비교를 계열을 나눠서 하지는 않아 이렇게 한 것 같습니다. 요즘 방법론들은 32 token 을 retain 하는것이 거의 기본으로 바뀌긴 해서 해당 방법론도 32 token으로 줄이면 얼마나 성능이 drop 될지 궁금하긴 합니다.
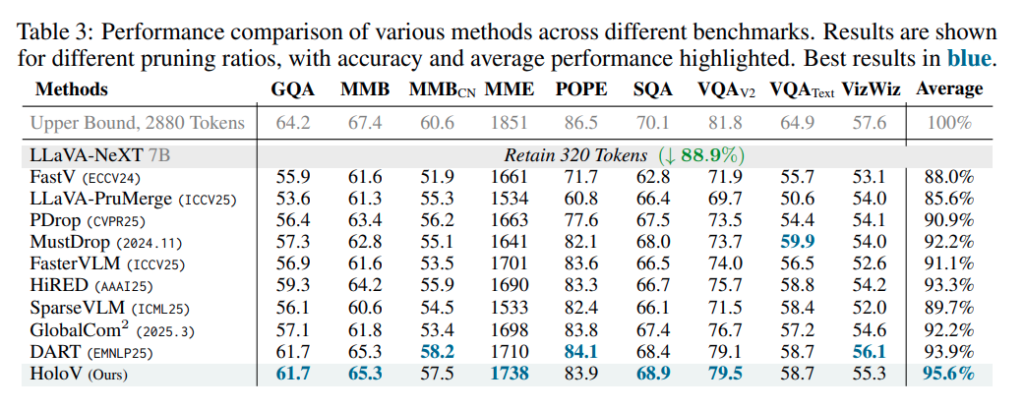
다음으로 저자는 high resolution MLLM 인 LLaVA-NeXT 에서도 HoloV를 평가합니다. 기존 SOTA 대비 2퍼센트가량 성능을 올렸습니다.
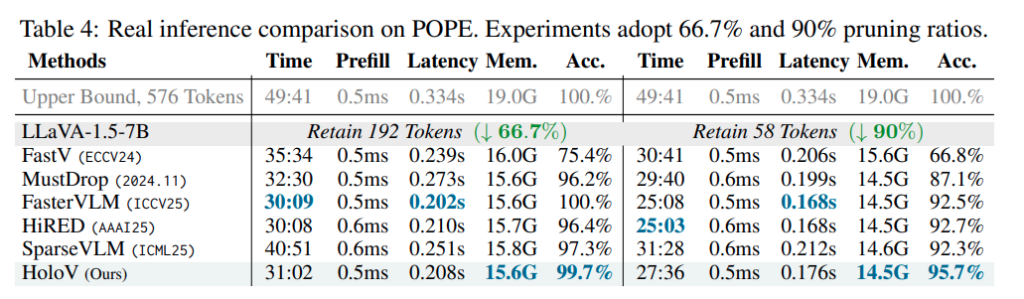
저자는 HoloV의 효율성을 평가하기 위해 LLaVA-1.5-7B에서 total inference time, prefill time, end-to-end latency, GPU memory usage, accuracy를 비교합니다. Table 4는 POPE benchmark에서 real inference 결과를 보여줍니다.
우선 Upper Bound는 576 token을 모두 사용하는 원본 모델입니다. 전체 inference time은 49분 41초, latency는 0.334s, GPU memory는 19.0G입니다. 저자의 방법론은 원본 대비 inference time 과 latency를 꽤 줄이면서도 accuracy는 거의 유지합니다. 192 token 기준에서는 FasterVLM에 지지만 58에서는 SOTA를 달성한 모습입니다.
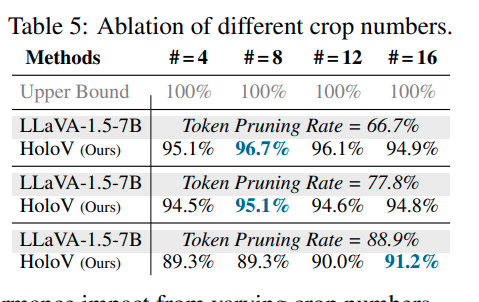
저자의 방법론이 아무래도 crop 수와 연관이 있기 때문에 crop ablation을 진행하였습니다. 결과적으로 crop 수가 최종 성능에 크게 영향을 주는 것 같지는 않습니다. 오히려 해상도에 따라서 결과가 좀 유의미했다고 하네요.

요즘에는 이렇게 FastV랑 비교하지는 않지만 저자의 pruning 방법론을 적용했을때 살아남는 구역입니다. text guided는 아니라 질문을 그림에 포함시키지는 않았고 그냥obejct centric한 부분이나 전체적인 crop들에서 token들이 잘 살아남는 모습입니다.
이후 qwen 계열에서도 성능 리포팅을 진행하는데 해당 리포팅은 LLaVA 버전에서만 유효한건지를 보여주는 결과라 이미지는 첨부하지 않았습니다.
Conclusion
결과적으로 HoloV는 attention score가 높은 token만 쫓는 기존 pruning 방식의 한계를 지적하고, visual token을 holistic context 관점에서 다시 선택하려는 방법입니다. 이를 위해 token의 attention saliency뿐 아니라 crop 내부 contextual diversity와 crop 간 token allocation을 함께 고려합니다. 그 결과 high pruning ratio에서도 이미지 전체 의미 구조와 세부 정보를 동시에 유지할 수 있었다고 저자는 주장합니다.
감사합니다.
안녕하세요 인택님 리뷰 감사합니다.
질문이 하나 있어서 댓글을 남깁니다. crop 마다 토큰의 개수가 다를 수 있다고 이해했는데, table 5는 crop 수를 기준으로 성능을 리포팅한 것 같습니다. 토큰 수는 실험에서 모두 동일한가요? 해상도에 따라서 결과가 차이가 있었다는 것은 동일한 crop일 경우 높은 해상도일때 더 성능이 좋았다고 이해하면 되는지 긍금합니다
감사합니다
안녕하세요 유진님 좋은 답글 감사합니다.
질문에 대해 답변해드리자면 crop 마다 토큰 수는 다르지만 최종 유지해야할 토큰수는 같다고 생각하시면 될 것 같습니다. 그리고 해상도에 대한 답변은 해상도가 낮은 이미지의 경우에는 crop 수에 따라 성능차이가 크지 않았지만 해상도가 높은 이미지일수록 crop 수에 따라 성능 변화가 생기더라~ 즉 해상도가 높을수록 spatial 한 crop 마다의 정보량 차이가 더 뚜렷해질테니 그러한 현상이 생기는 것 같습니다.
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
논문에서는 attention-based pruning의 한계로 positional bias를 언급하는데, 혹시 그 외에도 attention score 자체가 visual token의 중요도를 안정적으로 반영하지 못하는 문제가 있을까요? 예를 들어 attention이 특정 위치나 일부 유사한 token들에 퍼지거나 몰리면서 실제로 필요한 visual context를 놓칠 가능성은 어떻게 보나요?
감사합니다.
안녕하세요 의철님 좋은 답글 감사합니다.
논문에서 제가 언급한 attention bias 는 attention shift 문제로 llm decoding 과정에서 생기는 문제입니다. 제가 이때까지 읽은 논문들은 사실 해당 문제를 어떠어떠한 문제때문일거라는 추측정도에 그런 현상이 있더라를 그냥 정량적으로 보여주는 수준이었습니다. 해당 문제가 있다는 것을 인지하고 llm decoding 전에 pruning 하는 방법론들이 대세가 되거나, 혹은 llm decoding 과정에서 attention 정보를 활용하지 않는 식으로 발전되었는데, 의철님이 궁극적으로 질문해주신 attention 특정 위치에 몰리거나 잘못된 위치에 몰리면서 중요한 visual context를 당연히 놓치고 있을거고, attention 의 관점에서 이상적인 흐름은 아니라 생각합니다. 이번 승현님이 작성해주신 논문에서 비슷한 관찰이 있던거같은데, 저런 data 적 bias 를 학습해버린 vlm 을 training-free 방법으로 고쳐낼 방법이 생각나지는 않아서 실제 중요한 visual token을 놓치고 있을 것 같지만 해결 방법이 떠오르진 않습니다.
감사합니다.