안녕하세요, 이번에는 로봇 조작 학습에서 데이터 다양성이 정말 항상 좋은 것인지에 대해 다룬 연구를 리뷰해보려고 합니다. Agibot에서 진행한 연구이고, 저자들은 task diversity, multi-embodiment pre-training, expert diversity에 대해 다양한 실험을 통해서 제시했습니다. 리뷰 시작하겠습니다.
Introduction

로봇 조작 분야에서 최근 가장 큰 흐름 중 하나는 대규모 데이터 기반의 일반화 정책을 만드는 것입니다. 하지만 로봇 조작 데이터는 이미지나 텍스트 데이터와 다르게 실제 물리적 행동을 통해 얻어야 합니다. 하나의 trajectory를 얻기 위해 사람이 로봇을 조작하거나, 시뮬레이션 환경을 설계하거나, 실제 로봇이 안전하게 동작하도록 세팅해야 합니다. 따라서 최대한 효율적인 데이터를 구성하기 위해 어떤 데이터를 모아야 하는지, 어떤 다양성이 실제로 학습에 도움이 되는지, 어떤 다양성은 오히려 학습을 방해하는지를 구분해야 한다고 문제를 정의했습니다.
저자들은 기존의 대규모 로봇 데이터셋들은 대체로 “more is better”라는 방향성을 가지고 Bridge Data, DROID, Open X-Embodiment, AgiBot World와 같은 데이터셋들은 더 많은 task, object, scene, camera view, robot embodiment를 포함하려고 노력했다고 주장합니다. 하지만 저자들은 이 생각이 무조건 맞는것은 아니라고 합니다. 중요한 것은 데이터의 양이 아니라, 로봇 학습에 유효한 데이터 분포가 무엇인지입니다. 이 관점에서 저자들은 로봇 조작 데이터의 다양성을 task diversity, embodiment diversity, expert diversity라는 세 축으로 나누어 분석합니다.
저자들은 task diversity는 beneficial하다고 정리합니다. 다양한 task를 포함한 pre-training data는 downstream 성능을 높이고, 충분한 task diversity가 유지되면 pre-training data scale에 따라 power-law 형태의 성능 향상이 나타납니다. 반면 embodiment diversity는 optional하다고 봅니다. 여러 robot embodiment를 반드시 pre-training에 포함하지 않아도, 고품질 single-embodiment data로 학습한 모델이 다른 embodiment로 전이될 수 있음을 보입니다. 마지막으로 expert diversity는 confounding할 수 있다고 설명합니다. 서로 다른 teleoperator의 습관과 속도 차이가 demonstration 분포를 복잡하게 만들어 imitation learning을 어렵게 만들 수 있기 때문입니다.

위 Figure 2를 보면 Push-T task에서 expert demonstration은 spatial multimodality와 velocity multimodality를 동시에 가집니다. Spatial multimodality는 왼쪽에서 접근할지, 오른쪽에서 접근할지처럼 서로 다른 전략을 의미하므로 보존해야 할 다양성입니다. 반면 velocity multimodality는 비슷한 경로를 가더라도 사람마다 수행 속도가 달라지는 현상입니다. 저자들은 이 속도 차이가 action chunk 기반 imitation learning에서 같은 상태에 대해 서로 다른 action supervision을 만들기 때문에 학습을 방해할 수 있다고 봅니다.
이를 해결하기 위해 저자들은 velocity model을 사용한 distribution debiasing을 제안했습니다. Spatial multimodality는 유지하면서, velocity multimodality로 생기는 불필요한 분포 복잡성만 줄이는 것입니다. 즉, 서로 다른 조작 전략은 보존하되, 사람마다 속도가 달라 생기는 학습 혼란은 줄이려는 접근입니다.
저자들의 contribution은 다음과 같슶니다. 첫 번째로 task diversity가 로봇 학습에 유익하며, pre-training data와 downstream performance 사이에 power-law 관계가 나타날 수 있음을 보였습니다. 두 번째로 multi-embodiment data가 cross-embodiment transfer를 위한 필수 조건은 아니며, single-embodiment data만으로도 다른 robot embodiment에 효과적으로 적응할 수 있음을 보였습니다. 세 번째로 expert diversity가 imitation learning을 방해하는 confounding factor가 될 수 있고, velocity multimodality를 선택적으로 제거하면 성능을 개선할 수 있음을 보였습니다.
Task Diversity
저자들은 pre-training 데이터를 구성할 때 하나의 task마다 demonstration 수를 많이 확보하는 것이 더 중요한지, 아니면 전체 task 구성을 더 다양하게 만드는 것이 더 중요한지를 실험했습니다. 로봇 데이터 수집에서는 특정 downstream task와 관련된 skill을 많이 반복해서 모을 수도 있고, 반대로 task coverage를 넓혀 다양한 상황을 포함할 수도 있는데, 이 관계에 대해 실험했습니다.
저자들은 이 질문을 확인하기 위해 GO-1을 policy architecture로 사용하고 데이터셋은 AgiBot World를 사용했습니다. AgiBot World는 모든 데이터가 AgiBot G1으로 수집되어 robot embodiment 차이를 배제하고, pre-training data의 task 구성 차이가 downstream 성능에 미치는 영향을 비교하였습니다.
학습 과정은 pre-training과 fine-tuning으로 구성했습니다. 먼저 서로 다른 구성의 대규모 manipulation dataset으로 pre-training을 수행하고, 이후 동일한 target evaluation task data로 fine-tuning합니다.
평가 task는 Wipe Table, Fold Shorts, Pour Water, Make Sandwich입니다. Wipe Table은 contact-rich cleaning을, Fold Shorts는 deformable object manipulation을, Pour Water는 fine-grained pouring을, Make Sandwich는 long-horizon assembly를 평가하기 위함입니다. 각 task는 in-domain scenario, object-environment generalization scenario, visual distraction scenario에서 평가되고, 각 scenario마다 10번의 trial을 수행했다고 합니다. Score는 미리 정의한 세부 action의 성공 정도를 1, 0.5, 0으로 나눈 normalized score로 계산됩니다.
저자들은 task diversity의 효과를 보기 위해 두 가지 pre-training dataset sampling 전략을 비교하였스빈다. 첫 번째는 task-based sampling입니다. 이는 downstream evaluation task와 관련성이 높은 10%의 task를 수동으로 선택하는 방식입니다. 이 경우 task diversity는 낮지만, target task에 필요한 skill과의 관련성은 높습니다. 두 번째는 episode-based sampling입니다. 이는 원본 dataset의 각 task에서 10%의 episode를 random sampling하는 방식입니다. 이 경우 전체 task variety를 유지하면서 데이터 양만 줄이기 때문에, task diversity는 훨씬 높게 유지됩니다.
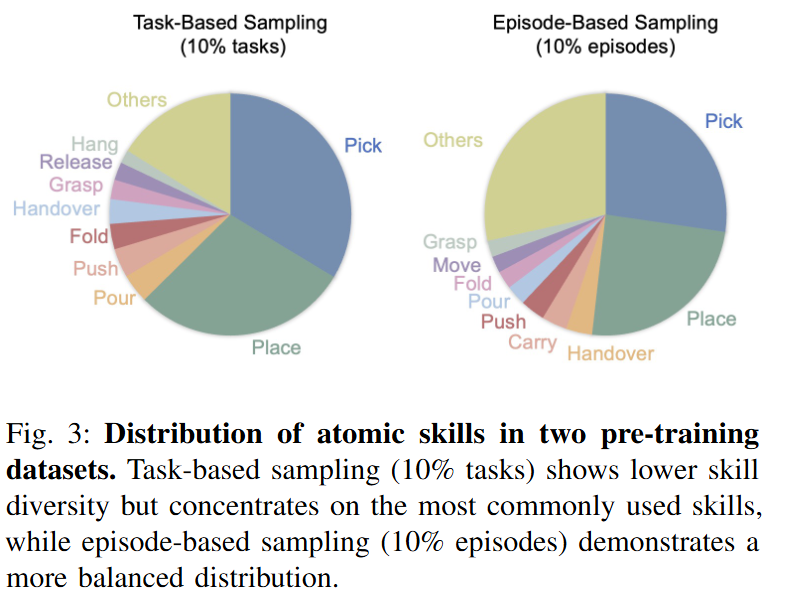
Figure 3은 이 두 sampling 전략이 atomic skill distribution에서 어떤 차이를 만드는지 보여줍니다. 저자들은 evaluation task에 필요한 주요 atomic skill을 pick, place, grasp, pour, fold로 정의합니다. Task-based sampling은 target task와 관련된 skill에 더 집중되어 있기 때문에 해당 skill 비율이 높습니다. Episode-based sampling은 target skill 비율은 낮지만, 전체 task와 skill의 분포가 더 균형 있게 유지됩니다.
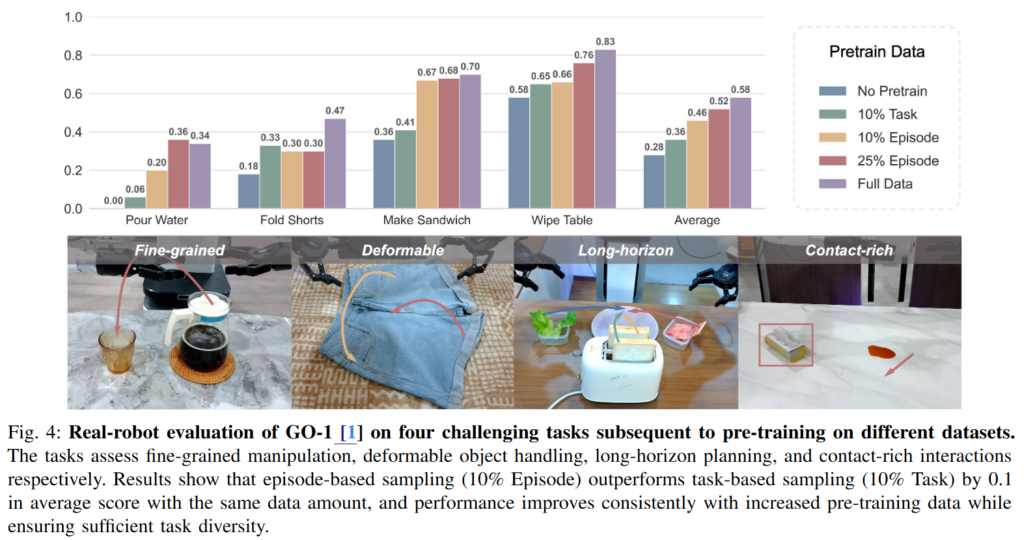
Figure 4를 보면 episode-based sampling에서 task-based sampling보다 평균 score가 높습니다. 저자들은 이런 task들이 단순한 motor skill만 필요한 것이 아니라 semantic understanding과 spatial understanding을 더 많이 요구하기 때문에, 특정 skill을 많이 반복하는 것보다 다양한 task context를 경험하는 것이 더 중요했다고 합니다.따라서 저자들은 같은 데이터 양이라면 target-related skill을 많이 반복하는 것보다 task diversity를 넓게 유지하는 것이 더 효과적이라고 봅니다.
또 저자들은 task diversity가 충분히 유지될 때 pre-training data scale을 키우면 성능이 계속 좋아지는지 확인합니다. AgiBot World는 217개의 일상 task와 87개의 자주 사용되는 skill을 포함했다고 합니다. 저자들은 No pre-training, 100K demonstrations, 250K demonstrations, 1M demonstrations 조건을 비교했고, GO-1의 average score는 각각 0.28, 0.47, 0.53, 0.58로 증가했습니다.
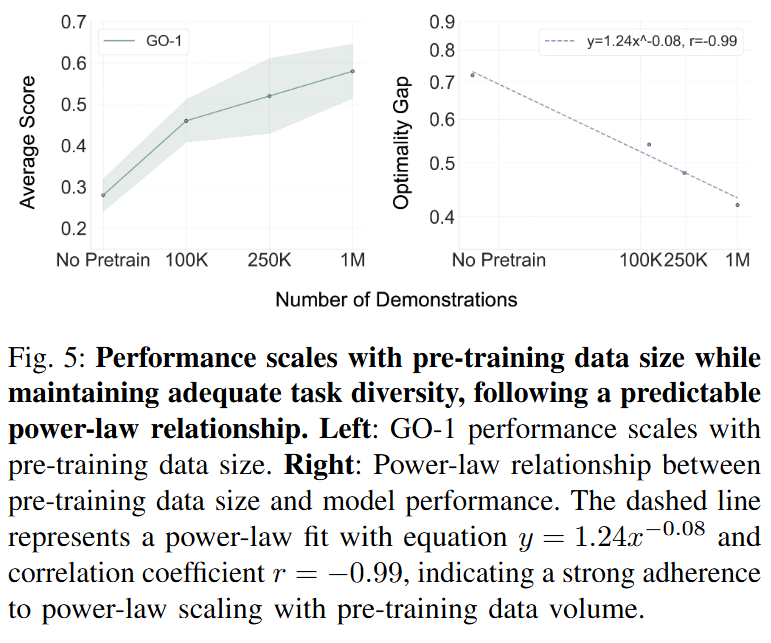
Figure 5를 보면 왼쪽 그래프에서는 pre-training data size가 증가할수록 GO-1의 평균 성능이 꾸준히 향상되는 것을 확인할 수 있습니다. 오른쪽 그래프에서는 optimality gap을 기준으로 power-law fitting을 수행한 결과가 제시됩니다. 여기서 optimality gap은 maximum score와 현재 normalized score의 차이, 즉 1 – normalized score로 정의됩니다. 저자들은 이 관계에서 Pearson correlation coefficient가 -0.99로 나타났다고 합니다. 따라서 저자들은 충분한 task diversity가 유지되는 조건에서는 로봇 조작 학습에서도 data scale이 예측 가능한 방식으로 성능 향상으로 이어질 수 있다고 정리했습니다.
Embodiment Diversity
저자들의 문제의식은 multi-embodiment training 자체가 복잡하다는 점에서 출발합니다. 서로 다른 로봇은 관절 구조가 다르고, action space와 proprioceptive state도 다릅니다. 이런 데이터를 하나의 모델에 함께 넣으려면 action representation을 맞추고, state representation을 정렬하고, robot morphology 차이를 처리해야 합니다. 그래서 저자들은 오히려 single-embodiment data로 충분히 큰 규모의 pre-training을 수행해도, downstream fine-tuning을 통해 다른 embodiment로 전이될 수 있는지에 대한 실험을 진행했습니다
실험에서는 AgiBot G1에서 수집된 AgiBot World의 1M trajectory를 single-embodiment pre-training data로 사용합니다. 그리고 비교 대상으로는 multi-embodiment dataset인 OXE로 pre-training된 RDT를 사용합니다. 평가는 세 가지 환경에서 진행됩니다. ManiSkill 시뮬레이션에서 Franka arm, RoboTwin 시뮬ㄹ이션에서 Arx arm, real world에서 Piper입니다. ManiSkill에서는 PegInsertionSide, PickCube, StackCube, PlugCharger, PushCube의 다섯 가지 task를 평가하고, RoboTwin에서는 BlockHammerBeat, BlocksStack, ContainerPlace, DualBottlesPick의 네 가지 task를 평가합니다. 실제 환경에서는 Package Product, Fold Shorts, Clean Trash, Industrial Sorting의 네 가지 task를 평가합니다. Simulation task는 평균 success rate로, real-world task는 평균 score로 성능을 측정합니다.
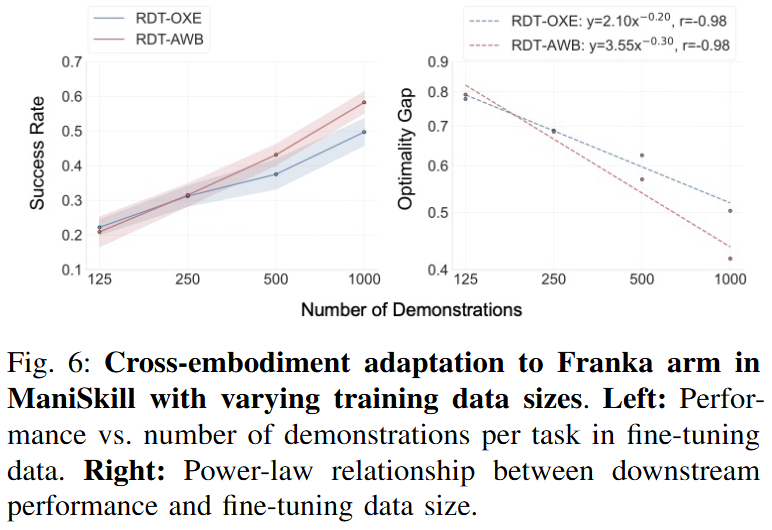
Figure 6를 보면 ManiSkill의 Franka arm으로 transfer할 때 125 samples per task에서는 RDT-OXE가 약간 더 좋은 성능을 보이지만 250 samples per task에서는 RDT-AWB가 RDT-OXE와 비슷한 성능에 도달하고, 더 많은 data가 주어지면 RDT-AWB가 RDT-OXE를 넘어섭니다.
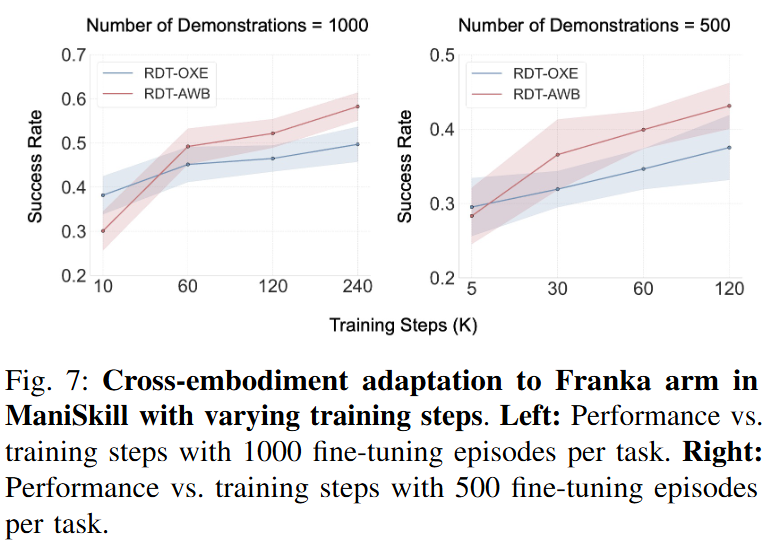
Figure 7은 같은 ManiSkill 환경에서 fine-tuning step 수를 기준으로 성능 변화를 보여줍니다. 여기서도 초기 step에서는 RDT-OXE가 더 빠르게 수렴합니다. 특히 약 10,000 step 정도의 초기 구간에서는 OXE pre-training이 유리한 모습을 보입니다. 하지만 training step이 늘어나면 RDT-AWB가 RDT-OXE를 따라잡고 이후 더 높은 성능을 보입니다. 1000 fine-tuning episodes per task 조건과 500 fine-tuning episodes per task 조건 모두에서 비슷한 경향이 나타납니다. Multi-embodiment pre-training이 초기 adaptation에는 유리할 수 있지만, 충분한 fine-tuning이 주어지면 single-embodiment pre-training도 다른 embodiment로 잘 전이될 수 있다는 결과입니다.
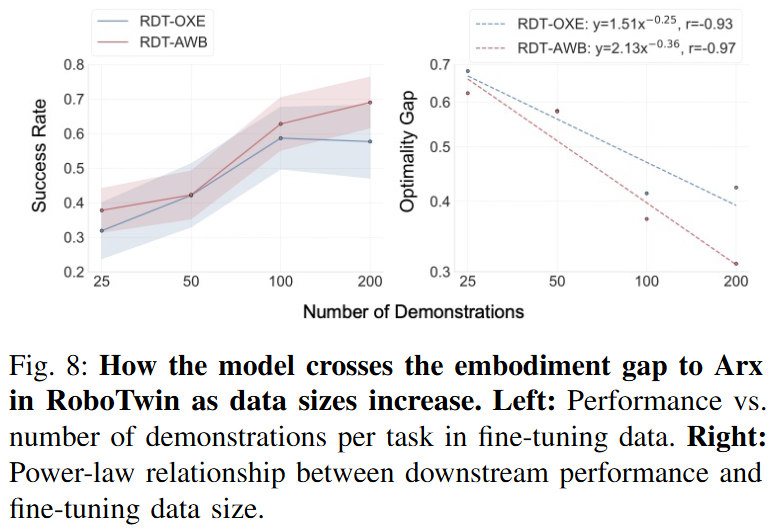
Figure 8을 보면 RoboTwin의 Arx arm으로 transfer할 때도 RDT-AWB는 적은 fine-tuning data만으로도 RDT-OXE와 비슷한 성능을 보이고, data size가 증가하면 Arx arm에 잘 적응합니다.

마지막으로 저자들은 real world에서도 RDT-OXE와 RDT-AWB를 비교합니다. Table I은 real-world Agilex environment에서 네 가지 task에 대한 성능을 보여줍니다. 동일하게 task당 100 demonstration을 사용해 fine-tuning했을 때, RDT-AWB는 Package Product, Clean Trash, Industrial Sorting의 세 가지 task에서 RDT-OXE보다 높은 성능을 보입니다.
Expert Diversity
로봇 데이터를 수집할 때 서로 다른 human demonstrator는 각자 다른 조작 습관과 속도, 움직임 패턴을 가집니다. 같은 task를 성공적으로 수행하더라도 어떤 사람은 빠르게 움직이고, 어떤 사람은 천천히 움직이며, 어떤 사람은 중간에 멈추거나 우회적인 경로를 선택할 수 있습니다. 이런 차이는 demonstration data의 분포를 다양하고 복잡하게 만듭니다.
저자들의 핵심 주장은 expert diversity가 항상 유익한 다양성은 아니라는 것입니다. 일부 차이는 의미 있는 multimodal behavior일 수 있습니다. 예를 들어 같은 목표를 달성하기 위해 왼쪽에서 접근할 수도 있고 오른쪽에서 접근할 수도 있다면, 이는 서로 다른 valid strategy이므로 학습해야 할 다양성입니다. 하지만 모든 차이가 유용한 것은 아닙니다. 특히 사람마다 execution speed가 달라지면서 생기는 velocity variation은 task strategy라기보다는 학습을 어렵게 만드는 distribution bias가 될 수 있다고 봅니다.

Figure 9을 보면 두 expert demonstration이 공간적으로는 같은 A에서 D까지의 trajectory를 따른다고 해도, 실행 속도가 다르면 action chunk가 다릅니다. 느린 demonstration에서는 같은 time window 안에서 A에서 B까지만 이동한 것으로 보이고, 빠른 demonstration에서는 A에서 D까지 이동한 것으로 보일 수 있습니다. 모델 입장에서는 비슷한 observation이 들어왔는데, 어떤 데이터에서는 짧게 움직이는 action이 정답이고, 다른 데이터에서는 길게 움직이는 action이 정답이 되기 때문에 이런 supervision은 모델이 핵심적인 spatial behavior를 학습하는 것을 방해할 수 있다고 합니다. 저자들은 이를 velocity multimodality로 보고, expert diversity 중에서도 제거해야 할 bias로 해석합니다.
저자들은 이 문제를 해결하기 위해 Velocity Model을 사용한 distribution debiasing을 제안합니다. VM은 observation을 입력으로 받아 해당 상황에서 기대되는 robot velocity를 예측합니다. 여기서 velocity는 end-effector action sequence의 상대 변위를 기반으로 정의됩니다. 저자들은 end-effector action을 정규화한 뒤 L1 norm으로 velocity metric을 계산하고, VM이 이 값을 예측하도록 MSE loss로 학습합니다.
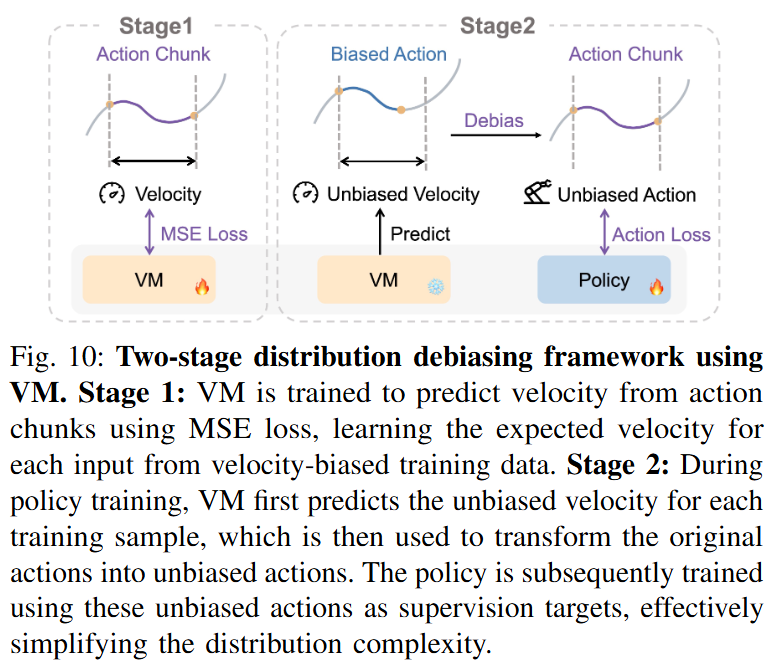
Figure 10은 VM을 이용한 distribution debiasing 과정을 보여줍니다. 첫 번째 단계에서는 biased demonstration data로부터 VM을 학습합니다. 이때 VM은 observation을 보고 평균적으로 기대되는 velocity를 예측하는 역할을 합니다. 두 번째 단계에서는 policy를 imitation learning으로 학습할 때, VM이 예측한 velocity와 가장 잘 맞는 action chunk length를 찾고, 해당 action sequence를 다시 고정된 chunk size로 interpolation합니다. 이렇게 하면 비슷한 observation을 가진 training sample들이 더 일관된 action velocity를 갖게 됩니다.
VM은 SigLIP visual encoder와 MLP head로 구성되고, 세 장의 입력 이미지를 SigLIP으로 feature extraction한 뒤 scalar velocity value로 변환합니다. 저자들은 VM을 통한 distribution debiasing을 pre-training 단계에 적용했을 때의 효과에 대한 실험을 진행했습니다.
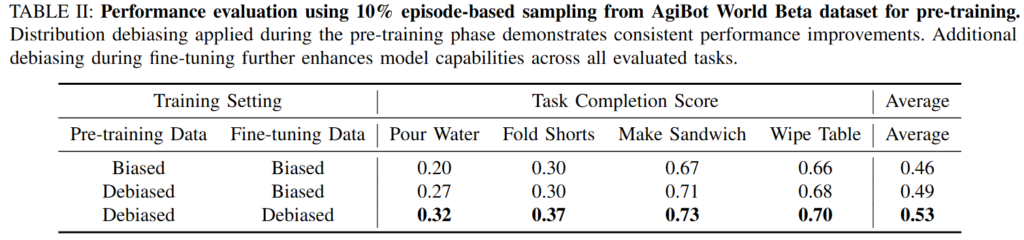
Table II를 보면 저자들은 해당 모듈을 통한 성능 향상이 Figure 4에서 pre-training data를 2.5배 늘렸을 때 얻는 효과와 비슷하다고 합니다. 즉, 데이터를 더 많이 모으는 것만큼이나 data distribution을 정리하는 것이 중요할 수 있다고 합니다. 특히 Pour Water나 Fold Shorts처럼 정밀한 action sequence와 복잡한 manipulation strategy가 필요한 task에서 debiasing 효과가 더 크게 나타났습니.
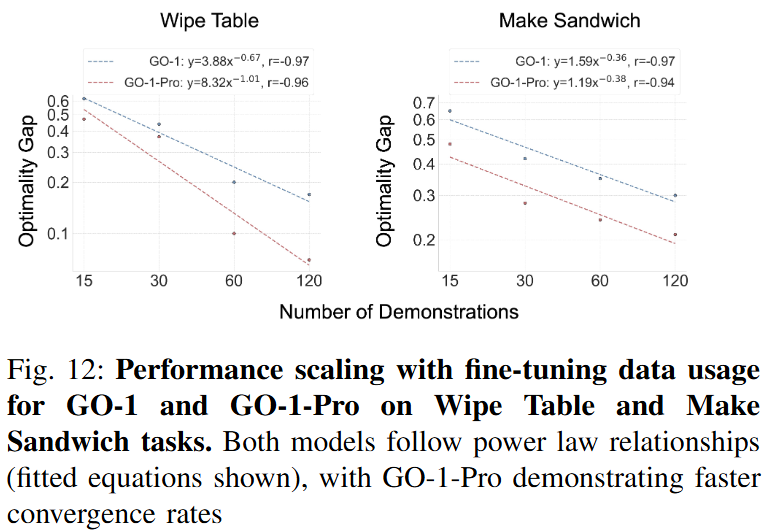
Figure 12를 보면 fine-tuning data scale에 따른 GO-1과 GO-1-Pro의 성능 변화를 power-law 관점에서 보여줍니다. 두 모델 모두 data scale이 커질수록 성능이 좋아지는 경향을 보이지만, GO-1-Pro는 더 좋은 scaling behavior를 보입니다. Make Sandwich에서는 두 모델의 exponent가 비슷하지만, GO-1-Pro가 모든 data scale에서 더 낮은 optimality gap을 보입니다.
서로 다른 spatial strategy는 보존해야 할 multimodality이지만, 같은 motion을 다른 속도로 수행하면서 생기는 velocity multimodality는 imitation learning을 방해할 수 있습니다. 저자들은 VM 기반 distribution debiasing을 통해 이 velocity bias를 줄였고, 그 결과 pre-training과 fine-tuning 모두에서 성능과 data efficiency가 향상 됐다고 합니다. 로봇 데이터셋을 scale up할 때 단순히 더 많은 demonstration을 모으는 것뿐만 아니라, demonstration의 분포를 어떻게 정제할 것인지도 매우 중요한 것을 볼 수 있ㅅ습니다.
Conclusion
저자들은 이 연구를 통해 로봇 조작 데이터 스케일링에서 중요한 것은 단순히 더 많은 데이터를 모으는 것이 아니라, 어떤 diversity를 어떻게 다룰 것인지라고 정리합니다. Task diversity는 downstream transfer와 scaling law 측면에서 도움이 되고, embodiment diversity는 cross-embodiment transfer를 위해 반드시 pre-training 단계에서 포함되어야 하는 조건은 아니었으며, expert diversity는 velocity multimodality로 인해 오히려 imitation learning을 방해하는 요소였다고 합니다. 특히나 로봇 데이터셋은 단순히 크고 다양한 것보다 학습에 유효한 다양성은 보존하고 불필요한 bias를 제거하는 방식으로 설계되어야 한다고 하빈다. 다만 저자들이 제안한 debiasing은 속도 변화 자체가 중요한 dynamic task에는 적합하지 않을 수 있다고 합니다. 또한 의미 없는 pause나 suboptimal behavior처럼 velocity 외의 expert bias도 여전히 남아 있기 때문에, 앞으로는 유익한 행동 다양성은 유지하면서 학습을 방해하는 expert variation을 식별하고 정제하는 방향이 중요해질 것 같습니다.
안녕하세요. 영규님 리뷰 감사합니다.
다양하고 많은 데이터셋이 있다면 이를 최대한으로 활용하는 것이 가장 좋은 것이라 막연하게 생각하였는데, 해당 논문은 그렇지 않음을 분석하고 해결책까지 제시하는 것이 인상적이었던 것 같습니다. 본 논문에서는 velocify만 언급하였지만, 추후에는 force도 비슷한 현상이 발생하지 않을까하는 생각이 들었습니다. 본 논문에서 추가로 force에 대해서 언급하거나 혹은 영규님께서도 force에도 debiasing하는 것이 추후 학습에 도움이 되실 거라고 생각하는지요?
감사합니다.
안녕하세요 주연님 댓글 감사합니다.
말씀하신대로 velocity 외에 force도 조작하는 사람이 달라지거나 기타 이유로 같은 상태에 대해 다른 성격의 데이터가 모일 수 있다고 생각하는데요, debiasing 해주게 될 경우 velocity도 dynamics가 중요한 task에서는 오히려 성능이 안 좋아 지는 경우들이 있었는데, force도 마찬가지로 dynamics와 연관이 있어서 조건부로 괜찮지 않을까 싶습니다
안녕하세요 영규님 좋은 리뷰 감사합니다.
예전에 읽을려고 찜 해놨던 논문인데 까먹었다가 영규님이 리뷰해주신걸 보고 달려왔습니다.
읽으면서 몇가지 궁금한 점이 생겼습니다.
downstream evaluation task라 함은 실제 수행할 target task와 유사한 데이터라고 이해했습니다. Fig. 4를 보면 task sampling 10% 는 낮은 성공률을 보이고, episode 10%는 task보다 더 높은 성공률을 보이며 25% 까지 증가시켰을 경우 성공률이 증가하는 모습을 보입니다. 이 부분을 보고 저자들이 task diversity는 중요하다고 하는 것 같은데.. 동의하지만 task sampling을 25% 까지 올렸을 경우에는 증가 폭이 더 크지는 않을지 영규님의 생각이 궁금합니다.
그리고 혹시 pour water task는 오히려 Full dataset의 성능이 떨어지는 모습이 보이는데 혹시 논문에는 이러한 이유가 언급이 되어있을까요? 다른 task와 경향성이 조금 달라보여 질문드립니다.
감사합니다.
안녕하세요 인하님 댓글 감사합니다.
해당 자료같은 경우는 같은 양의 데이터를 활용할 때 작업의 다양성이 모델에게 다양한 상호작용에 대한 지식을 알려줄 수 있다는 점을 어필한 결과라고 보시면 될 것 같습니다. 인하님이 말씀하신 부분은 저도 해봐야 알 것 같긴 합니다.
pour water task 같은 경우는 데이터셋 자체가 좀 noisy하지는 않았을까,, 의심해봅니다. 실제로 teleoperation할때 어려움도 있고 하지 않았을까요?
영규님 좋은 리뷰 감사합니다.
expert diversity가 항상 유의미한 요소가 아닐 수 있으므로, 이에 대하여 distribution debiasing을 통해 분포를 정제한다고 이해하였습니다. 그런데 조작하는 방향이 왼쪽이나 오른쪽이 되는 등 분포 차이가 큰 경우에도 효과적으로 동작할 수 있을지에 대해 궁금함이 있습니다.
안녕하세요 승현님 댓글 감사합니다.
distribution debiasing을 담당하는 모듈 자체가 속도에 대한 부분이라 좀 제한적이지 않을까 싶습니다. 저자들의 설계 의도가 다양한 사람들이 데이터를 수집할때의 속도가 다른 면에 집중했습니다.
추가적으로 오른쪽 왼쪽 등 분포 차이가 다른 경우는 VLA 모델의 설계상 생성형 모델이 다양한 액션들에 대한 분포를 잘 학습하지 않을까 싶습니다.
안녕하세요 영규님, 좋은 리뷰 감사합니다.
1. 저도 인하님과 동일하게, episode based sampling(10퍼) 가 task based sampling(10퍼) 보다 좋다는 결과로 task diversity가 중요하다고 결론지은 것 같은데, task sampling을 더 올리면 어떻게 될지가 궁금하네요.
2. task가 어려워지거나 길어질수록 subtask 로 쪼개서 생각하는 게 여전히 중요하다고 생각하는데, 각 subtask 별로 나눠서 diversity를 측정하고 판단하는 건 어떻게 생각하시는지 궁금합니다.
3. velocity diversity 속의 잠깐 멈춤동작이나 망설임동작, 급가속동작 등 시간 축에서의 다른 변동 요인에 대해서 저자들이 다루었는지 궁금합니다. 인하님이 말씀해주신 pour에 대해서 붓는 행위 자체는 원래 느리고 붓기 전에 이동은 원래 빠른 것이기 때문이 아닐까란 생각도 들었넨요.
안녕하세요 재찬님 댓글 감사합니다.
1. 저도 궁금하긴 한데 해당 연구 이후 비슷한 문제를 다룬 적이 있는지 보도록 하겠습니다.
2. 다양한 데이터 diversity를 두고 각 subtask에 대한 작업의 성공률을 비교 측정하자고 하신것으로 이해했는데 맞을까요? 흠.. episode diversity를 통해 다양한 작업을 배우는 것이 저자들의 분석을 따른다면 long horizon task를 수행함에 있어서 VLM이 만들어내는 semantic한 정보를 행동으로 옮기는데 도움을 줄 것 같기도 하지만,, 역시 해봐야 알 것 같습니다.
3. 명시적으로 망설임이나 급가속을 명시하지는 않았지만 모듈 설계상 velocity를 예측하면서 같은 timestep에 대해 다양한 action chunk를 적당하게 배우는 것이기 때문에 급가속하는 동작에 대해서는 어느정도 이점이 있을 것 같습니다.