안녕하세요 이번에 들고온 논문도 VLM 에서의 token pruning 논문입니다. 제가 분석하고있는 방법론과 비슷한 방법을 사용하고, 기존 방법론들이 성능 올리고 어거지로 주장하는 느낌보다는 분석적인 내용도 깔끔하고 그 전개도 괜찮아서 리뷰하게 되었습니다. 경북대 학생이랑 LG Electronics에서 공동연구로 작성되었는데 한국인이 보이니까 또 반갑네요.
Abstract
매번 언급하는거지만 대규모 VLM 들 즉 LVLM들은 긴 visual token sequence 로 인해 발생하는 상당한 계산 overhead를 줄이기 위해 visual token pruning 전략을 도입해왔습니다. 기존 연구들은 attention-based pruning 방법 또는 diversity-based pruning 방법 중 하나에 초점을 맞춰 왔습니다. 하지만 이러한 접근법들이 각각 어떤 특성과 한계를 가지는지에 대한 심층적인 분석은 아직 충분히 이루어지지 않았다고 합니다.
저자의 연구에서는 feature diversity를 측정하기 위한 effective rank, erank 와 attention score entropy를 사용하여 visual token processing mechanism 을 조사하고, 각 접근법의 장단점을 실증적으로 분석합니다. 저자의 insight 는 크게 두가지인데
- erank 기반 정량 분석을 통해 많은 diversity-oriented pruning 방법들이 의도했던 것보다 훨씬 적은 feature diversity만을 보존한다는 것을 확인했습니다. 나아가서 CHAIR datset을 사용한 분석에서는 이들이 보존하는 diversity가 attention-based pruning에 비해 더 높은 hallucination frequency와 밀접하게 관련되어 있는 것을 보였습니다.
- 저자는 attention-based 접근법이 visual evidence가 특정 영역에 집중되어 있는 simple image에서 더 효과적이라는 점을 관찰하였고 반면 diversity-based 방법에서는 feature가 여러 영역에 분산되어 있는 complex image를 더 잘 처리하는 경향을 보였습니다.
이러한 실증적 인사이트를 통해서 저자는 기존 hybrid pruning strategy에 image-aware adjustment를 통합하면 성능이 일관되게 향상된다는 것을 보였습니다.
Introduction
우선 저자는 최근 Large Vision-Language Models, LVLMs가 이미지, 텍스트, 비디오와 같은 다양한 modality를 통합하면서 사람 수준에 가까운 vision-language reasoning 능력을 보이고 있다고 설명합니다. 특히 이미지 정보는 language model이 처리할 수 있는 visual token embedding 형태로 변환되는데, 이 과정에서 수백 개의 visual token이 생성됩니다. 문제는 visual token 수가 많아질수록 attention 기반 연산의 complexity가 quadratic하게 증가하기 때문에, inference speed와 efficiency에 큰 영향을 준다는 점입니다.
이러한 문제를 해결하기 위해 기존 연구들은 token pruning 방법을 통해 불필요하거나 redundant한 visual token을 제거하려고 했습니다. 기존 방법은 크게 두 가지로 나눌 수 있습니다. 첫 번째는 attention-based method이고, 두 번째는 diversity-based method입니다. Attention-based method는 attention score가 높은 token을 중요한 정보로 보고 나머지를 제거하는 방식입니다. 반면 diversity-based method는 visual token 간 feature similarity를 기반으로 redundancy를 줄이는 방식입니다.
저자는 이 두 접근이 서로 다른 성향을 가진다고 설명합니다. Attention-based method는 높은 attention weight를 받은 token을 우선적으로 보존하기 때문에, 중요한 object나 salient region을 잘 남길 수 있습니다. 하지만 선택이 특정 영역에 집중되기 쉬워, 비슷한 token들이 반복적으로 남는 문제가 생길 수 있습니다. 반대로 diversity-based method는 더 넓은 coverage를 유도하지만, 중요한 token을 놓칠 수 있는 문제가 있습니다. 즉, attention-based 방식은 중요도 보존에는 강하지만 중복 선택 문제가 있고, diversity-based 방식은 다양성 보존에는 강하지만 semantic importance를 놓칠 수 있다는 trade-off가 존재합니다.
또한 최근에는 attention-based와 diversity-based strategy를 결합한 hybrid pruning method들도 등장했습니다. 하지만 저자는 이러한 attention-based, diversity-based, hybrid pruning 전략들이 실제로 어떤 token을 남기고, 어떤 특성을 가지는지에 대한 분석이 아직 충분하지 않다고 지적합니다. 특히 기존 방법들이 실제로 feature-space diversity를 얼마나 보존하는지, retained token의 특성이 hallucination tendency에 어떤 영향을 주는지, 그리고 이미지 종류에 따라 attention-based 방식과 diversity-based 방식 중 무엇이 더 적합한지가 체계적으로 분석되지 않았다고 합니다.
이를 명확히 하기 위해 저자는 두 부분으로 empirical analysis를 수행합니다. 첫 번째는 기존 pruning paradigm들의 intrinsic behavior를 분석하는 것입니다. 여기서는 effective rank, erank를 사용하여 retained token set이 얼마나 feature diversity를 보존하는지 정량화하고, 이것이 image type별 hallucination pattern과 어떤 관계가 있는지 분석합니다. 두 번째는 image-level complexity에 따라 pruning effectiveness가 어떻게 달라지는지 분석하여, 어떤 상황에서 attention-based pruning이 유리하고 어떤 상황에서 diversity-based pruning이 유리한지 확인합니다.
저자의 분석 결과는 크게 두 가지입니다.
첫 번째는 method-level behavior, 즉 diversity와 hallucination에 대한 분석입니다. 저자는 많은 diversity-aware pruning method들이 의도했던 것보다 실제로는 훨씬 적은 diversity만을 보존한다는 것을 보입니다. 더 중요한 점은, retained diversity가 높을수록 CHAIR benchmark 기준 hallucination frequency가 증가하는 경향이 있다는 것입니다. 반면 attention-based pruning은 diversity가 낮은 token set을 유지하지만, 더 conservative한 output을 생성하여 hallucination을 억제하는 경향이 있다고 합니다.
이 부분은 꽤 흥미롭다고 하는데, 일반적으로는 diversity를 많이 보존하면 좋은 것처럼 생각하기 쉽지만, 저자는 retained feature diversity가 높다고 항상 좋은 것은 아니라고 봅니다. 너무 다양한 visual token을 남기면 LLM이 이미지 내 여러 candidate evidence를 과하게 참조하거나, 실제 질문과 무관한 visual cue까지 활용하면서 hallucination이 증가할 수 있다는 식으로 해석할 수 있습니다. 반대로 attention-based pruning은 token selection이 집중되지만, 그만큼 모델이 더 보수적으로 답변하게 되어 hallucination이 줄어드는 경향이 있다는 것입니다.
두 번째는 image-level behavior, 즉 image complexity에 따라 적합한 pruning 방식이 달라진다는 분석입니다. 저자는 essential visual cue가 소수의 token에 집중되어 있는 simple image에서는 attention-based pruning이 더 효과적이라고 합니다. 반면 semantic information이 이미지 전반에 넓게 분산되어 있는 complex image에서는 diversity-based pruning이 더 좋은 성능을 보인다고 합니다.
쉽게 말하면, 단순한 이미지에서는 중요한 object나 region이 명확하기 때문에 attention score가 높은 token만 잘 남겨도 충분합니다. 하지만 복잡한 이미지에서는 여러 object, background, relation, context가 함께 중요할 수 있기 때문에, attention이 가장 높은 token만 남기면 정보가 부족해질 수 있습니다. 이런 경우에는 다양한 feature를 보존하는 diversity-based pruning이 더 유리하다는 주장입니다.
저자는 이러한 empirical finding이 단순한 분석에 그치지 않고 실제 pruning 성능 개선에도 활용될 수 있음을 보입니다. 기존 pruning strategy들, 특히 hybrid approach나 attention-diversity mixture 방식에 저자들이 분석한 image-aware adjustment를 적용하면 benchmark 전반에서 성능이 일관되게 향상된다고 합니다. 즉, 이미지가 단순한지 복잡한지에 따라 attention과 diversity의 비중을 조절하는 것이 실제로 도움이 된다는 것입니다.
추가적으로 저자는 위 empirical behavior를 실제로 구현한 간단한 threshold-based pruning procedure도 제안합니다. 이 방법은 token을 attention score가 높은 순서대로 탐색하면서, 이미 선택된 token들과 similarity가 높은 redundant token을 제거합니다. 이때 threshold는 image-level complexity에 따라 adaptive하게 설정됩니다. 즉, 기본적으로는 attention order를 따르되, similarity 기반 redundancy 제거를 같이 수행하고, 이미지 복잡도에 따라 pruning 강도를 조절하는 구조입니다.
흥미로운 점은 이 방법이 의도적으로 매우 단순하게 설계되었음에도, 9개의 standard dataset에서 강한 성능을 보이며 기존 pruning method와 비슷하거나 더 좋은 성능을 달성했다는 점입니다. 또한 CHAIR benchmark에서도 hallucination tendency를 완화하는 결과를 보였다고 합니다. 따라서 저자는 본 논문에서 발견한 empirical principle이 단순히 설명적인 분석에 그치지 않고, 실제 pruning method로도 효과적으로 이어질 수 있다고 주장합니다.
또한 저자는 이러한 behavior와 성능 개선이 특정 모델에만 제한되지 않는다고 설명합니다. LLaVA-1.5-13B, LLaVA-NeXT-7B, Qwen2.5-VL-7B와 같이 더 크거나 구조가 다른 LVLM에서도 동일한 경향이 관찰되었기 때문에, 본 논문에서 발견한 principle은 model-agnostic하고 robust하다고 주장합니다.
저자의 기여도를 요약하면 크게 3가지입니다.
- 기존 pruning method들이 feature diversity를 어떻게 보존하는지, 그리고 이 retained diversity가 hallucination behavior와 어떤 관계를 가지는지를 erank 기반으로 처음 체계적으로 분석함
- Image complexity에 따라 attention-based pruning과 diversity-based pruning 중 더 적합한 방식이 달라진다는 점을 보이고, 각 paradigm이 언제 성공하거나 실패하는지 설명함
- 이러한 empirical principle이 실제로 활용 가능함을 보이기 위해, 기존 pruning method를 개선하고, 간단한 adaptive pruning mechanism을 제안하여 여러 benchmark에서 강하고 일관된 성능을 달성함
한 줄로 정리하면, 이 논문은 단순히 새로운 token pruning 방법을 제안하는 것보다, attention-based pruning과 diversity-based pruning이 실제로 어떤 특성을 가지는지 erank와 attention entropy로 분석하고, 이미지 복잡도에 따라 두 전략을 adaptive하게 조절하는 것이 더 효과적이라는 점을 보이는 논문이라고 보면 됩니다.
Preliminaries
우선 이 섹션은 저자의 방법론을 설명하기 전에, 논문에서 계속 사용할 두 가지 분석 기준인 attention entropy와 erank를 정의하는 부분입니다. 즉, 이 논문의 핵심은 단순히 pruning method를 제안하는 것이 아니라, 기존 attention-based pruning과 diversity-based pruning이 실제로 어떤 특성을 가지는지를 정량적으로 분석하는 것이기 때문에, 이를 위한 metric을 먼저 소개하는 것입니다.
Attention Concentration via Attention Entropy
저자는 vision encoder 내부에서 attention이 얼마나 집중되어 있는지 측정하기 위해 Shannon entropy를 사용합니다. 여기서 보는 attention은 class token, 즉 [CLS] token의 attention score입니다. 구체적으로 vision encoder의 penultimate layer 에서 head-averaged attention score 를 얻고, CLS토큰을 제외한 남은 visual token들에 대한 attention score을 다시 normalize해서 valid probability distribution 으로 만듭니다.
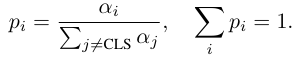
이렇게 만든 p는 [CLS] token 의 attention 이 visual token 들 사이에 어떻게 분포되어 있는지를 나타내는 probability distribution입니다. 그다음 Shannon entropy를 계산합니다.
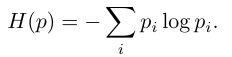
여기서 엔트로피값 H는 attention token들 사이에 얼마나 넓게 퍼져 있는지를 나타냅니다. entropy 가 낮으면, [CLS] 토큰이 visual token에 강하게 집중하고 있다는 뜻이며 즉 attention 이 특정 object나 salient region에 몰려 있는 경우입니다.
반대로 entropy가 높으면 [CLS] token 의 attention이 여러 visual token에 비교적 균등하게 분포되어 있다는 뜻입니다. 즉, 이미지 전체에 attention이 넓게 퍼져 있는 경우입니다.
저자는 이후 논문에서 이 값을 attention entropy라고 부릅니다.
Token Embedding Diversity via erank
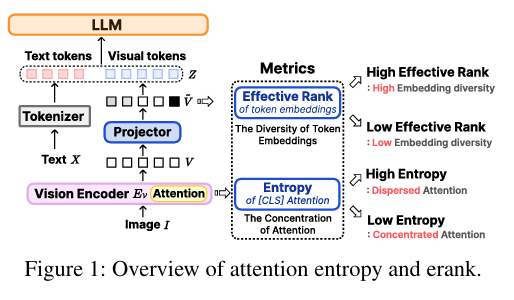
다음으로 저자는 visual token embedding이 feature sapce에서 얼마나 다양한지를 측정하기 위해 effective rank, erank를 사용합니다.
일반적인 matrix rank는 non-zero singular value의 개수를 세는 방식입니다. 하지만 실제 neural feature에서는 singular value들이 연속적인 크기를 가지기 때문에, 단순 rank만으로는 feature representation이 실제로 몇개의 중요한 demension을 사용하는지 보기 어렵습니다. 그래서 저자는 entropy 기반 measure인 erank를 사용합니다. erank는 matrix가 얼마나 많은 dimension을 효과적으로 활용하고 있는지를 나타내는 값입니다. token embedding matrix를 다음과 같이 둡니다.
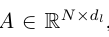
여기서 N은 token 수이고 d는 embedding dimension입니다.
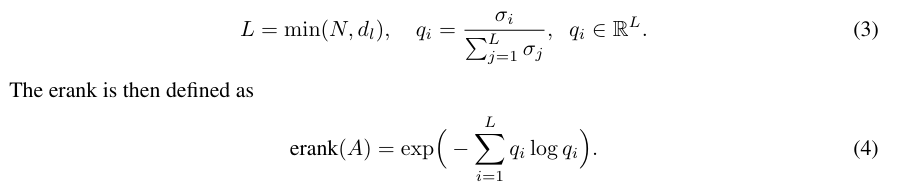
위의 수식에서 qi는 singular value 분포를 probability distribution처럼 볼 수 있습니다.
Empirical Studies
우선 저자는 이 섹션에서 attention-based pruning과 diversity-based pruning이 실제로 어떤 특성을 가지는지 실험적으로 분석합니다. 크게 두 가지를 봅니다. 첫 번째는 기존 방법들이 pruning 이후 얼마나 많은 feature diversity를 보존하는지, 그리고 이것이 hallucination과 어떤 관계를 가지는지입니다. 두 번째는 image complexity에 따라 attention-based 방식과 diversity-based 방식 중 어떤 전략이 더 적합한지를 분석하는 것입니다. 이후 이 두 분석에서 얻은 insight를 바탕으로 간단한 adaptive pruning framework를 제안합니다.
Attention-based / Diversity-based Pruning의 Empirical Analysis
저자는 기존 pruning paradigm들의 intrinsic behavior를 이해하기 위해 erank를 사용합니다. erank는 token-level visual feature가 얼마나 다양한 feature direction을 활용하는지 측정하는 지표입니다. 즉, pruning 이후 남겨진 token set이 실제로 얼마나 다양한 semantic information을 담고 있는지를 보려는 것입니다.
이 분석의 목적은 단순히 “어떤 방법이 성능이 높다”를 보는 것이 아니라, 각 pruning 방식이 semantic diversity를 얼마나 보존하는지, 그리고 이 diversity 차이가 최종적으로 hallucination behavior에 어떤 영향을 주는지를 보는 것입니다.
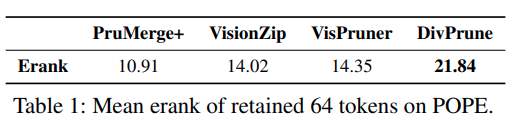
Table1에서는 POPE benchmark 에서 64token만을 남겼을 때 각 방법의 평균 erank를 비교합니다. 여기서 DivPrune이 가장 높은 erank를 보입니다. 이는 DivPrune이 token 간 geometric dispersion, 즉 서로 다른 feature를 가진 token들을 남기는 것을 명시적으로 목표로 하기 때문입니다. 반대로 PruMerge+는 erank가 가장 낮은데, 이는 spatial sampling 전략만으로는 충분한 feature diversity를 유지하기 어렵다는 것을 의미합니다.
VisionZip과 VisPruner는 중간 정도의 erank를 보입니다. 둘 다 PruMerge+보다는 다양성이 높지만, DivPrune보다는 낮습니다. 이 결과는 같은 token budget, 즉 같은 수의 token만 남기더라도 어떤 pruning 전략을 쓰느냐에 따라 남겨지는 token들의 semantic diversity가 크게 달라진다는 것을 보여줍니다.
저자는 여기서 더 들어가서, VisPruner, VisionZip, PruMerge+가 모두 기본적으로 high attention token을 우선시하는 방식이지만, 부가적으로 diversity를 보존하는 mechanism의 강도가 다르다고 설명합니다.
예를 들어 VisPruner는 attention filtering 전에 feature-redundant token을 제거하기 때문에 attention-driven method 중에서는 비교적 diversity 보존이 강합니다. 그래서 VisionZip보다 약간 높은 erank를 보입니다. 반면 VisionZip의 token merging이나 PruMerge+의 spatial sampling은 dispersion을 일부 도입하긴 하지만, 여전히 attention-guided selection에 강하게 묶여 있기 때문에 전체 diversity는 제한적입니다.
즉 이 분석의 핵심은 다음과 같습니다.
attention-based 계열 방법들은 중요한 token을 잘 남길 수 있지만, selection 기준이 attention에 묶여있기 때문에 feature diversity는 제한될 수 있고, diversity-based 방법인 DivPrune은 훨씬 높은 erank를 보입니다.

Pruning Method와 Hallucination의 관계
그다음 저자는 object hallucination 관점에서 attention-based 방식과 diversity-based 방식을 비교합니다. 여기서 사용하는 benchmark는 CHAIR입니다. CHAIR는 image captioning task에서 생성된 caption에 실제 GT annotation에 없는 object가 얼마나 포함되는지를 측정합니다. 지표는 두 가지입니다.
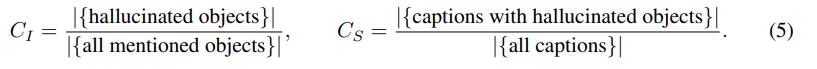
여기서 Ci 는 instance-level hallucination이고 Cs 는 sentence-level hallucination 입니다. 둘 다 낮을수록 좋고 추가적으로 Recall 과 Len도 봅니다. Recall은 생성 caption이 GT object를 얼마나 많이 언급했는지를 의미하고, Len은 생성 문장의 평균 길이입니다.
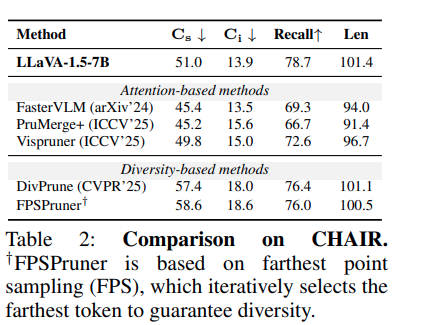
여기서 중요한 점은 diversity-based method가 recall은 높지만 hallucination도 높다는 것입니다. 즉, 더 많은 object를 언급하긴 하는데, 그중 실제 이미지에 없는 object까지 같이 말할 가능성이 커진다는 것입니다. 반대로 attention-based method는 recall은 낮아지는 경향이 있지만, hallucination 지표인 Cs와 Ci가 낮습니다. 즉, 더 보수적으로 답변하고, 없는 object를 덜 말하는 경향이 있습니다.
저자는 Figure 2에서도 이 차이를 시각적으로 보여줍니다. DivPrune은 더 넓고 풍부한 description을 생성하지만, speculative expression이나 hallucinated object가 같이 섞일 수 있습니다. 반면 FasterVLM은 주요 object 중심으로 더 conservative하고 reliable한 설명을 생성합니다.
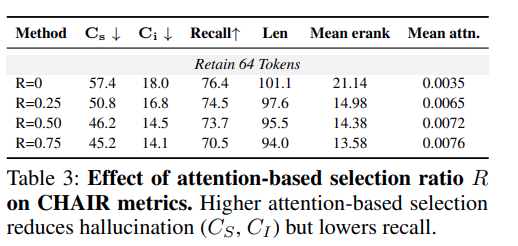
결과를 보면 attention-based selection 비율이 높아질수록 Cs와 Ci가 계속 감소합니다. 즉 hallucination이 줄어들고 대신 recall은 조금씩 낮아집니다. 앞의 주장과 일관되는데 diversity만 보고 token을 고르면 다양한 object evidence를 남기지만 그만큼 모델이 많은 object를 언급하면서 hallucination이 늘어날 수 있습니다. 반대로 attention score가 높은 token은 critical information에 더 집중되어 있어, 신뢰도 높은 caption을 생성하는 데 더 유리할 수 있습니다.
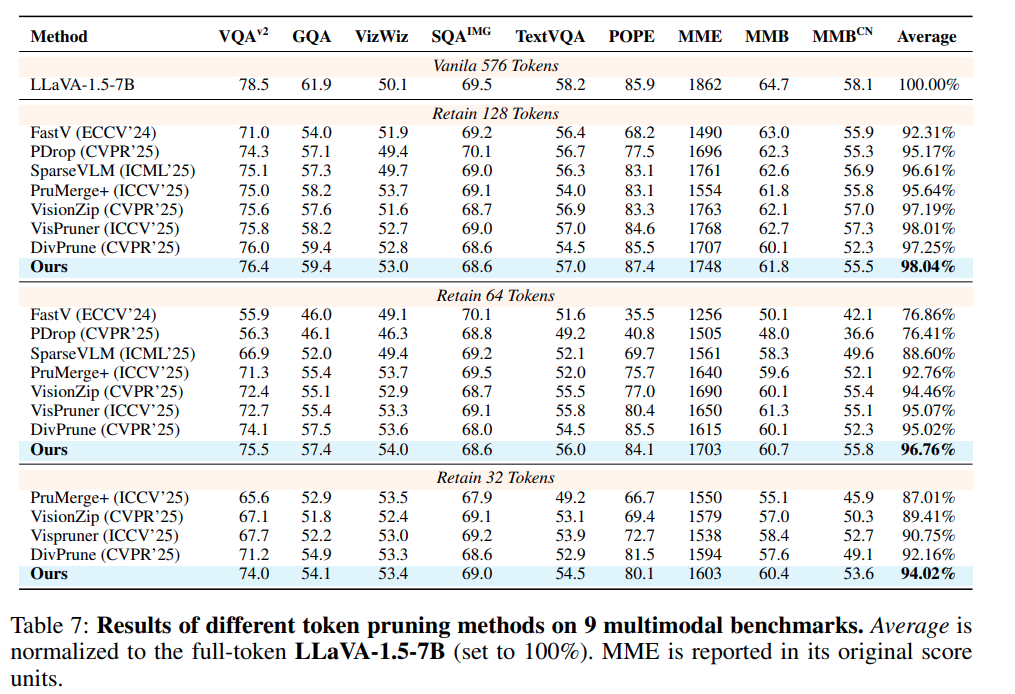
다음은 main table로 기존 SOTA 방법론을 제친 모습을 보여줍니다. text-relevant한 방법론들에 비해 성능은 다소 떨어지나 분석이 깔끔하다고 생각합니다.
Conclusion
결론적으로 저자는 본 논문에서 LVLM의 visual token pruning에 대한 체계적인 empirical study를 수행했다고 합니다. 여기서 핵심 분석 지표로는 effective rank, erank와 attention entropy를 사용했습니다. 저자의 분석 결과, 기존 연구에서 충분히 정리되지 않았던 두 가지 일관된 behavioral pattern을 확인했다고 합니다.
첫 번째는, pruning 방법마다 최종적으로 보존하는 feature diversity가 크게 다르며, 이렇게 보존된 diversity가 hallucination tendency와 밀접하게 연결되어 있다는 점입니다. 즉, diversity를 많이 남기는 방법은 더 많은 시각 정보를 포괄할 수 있지만, 동시에 모델이 없는 object까지 언급하는 hallucination을 증가시킬 수 있다는 것입니다. 반대로 attention-based pruning은 더 conservative한 token set을 남기기 때문에 hallucination을 줄이는 경향이 있다고 볼 수 있습니다.
두 번째는, attention-based pruning과 diversity-based pruning 중 어떤 방식이 더 효과적인지가 image complexity에 따라 예측 가능하게 달라진다는 점입니다. 단순한 이미지에서는 중요한 visual evidence가 소수의 token에 집중되어 있기 때문에 attention-based selection이 더 유리하고, 복잡한 이미지에서는 정보가 여러 region에 분산되어 있기 때문에 diversity-based retention이 더 효과적이라고 합니다.
저자는 이러한 분석이 서로 다른 pruning strategy가 언제, 왜 성공하거나 실패하는지 설명할 수 있는 통합적인 관점을 제공한다고 주장합니다. 이 empirical understanding을 바탕으로, 저자는 기존 hybrid pruning method와 mixed pruning method에 image-aware adjustment를 추가하면 여러 benchmark에서 일관된 성능 향상이 나타난다는 것을 보였습니다. 이는 저자들이 발견한 empirical principle이 특정 모델이나 특정 방법에만 국한되지 않고, 비교적 넓게 적용 가능한 model-agnostic principle이라는 점을 보여줍니다.
또한 저자는 이러한 원리를 최소한의 형태로 구현한 adaptive thresholding procedure를 제시했습니다. 이 방법은 강한 성능을 달성하면서도 hallucination을 줄이고, 동시에 computational cost를 크게 낮춥니다.
전체적으로 이 연구는 LVLM에서 pruning paradigm의 내부 동작을 이해하는 것이 중요하다는 점을 강조합니다. 단순히 token 수를 줄이는 것만 보는 것이 아니라, 어떤 token을 남겼는지, 남겨진 token들의 diversity가 어떤지, 이미지 복잡도에 따라 어떤 pruning 방식이 적합한지를 분석해야 한다는 것입니다. 그리고 이러한 empirical principle은 향후 adaptive pruning strategy를 설계하는 데 중요한 가이드라인이 될 수 있다고 저자는 마무리합니다.
감사합니다.
안녕하세요 인택님 리뷰 감사합니다!
뭔가 단순한 image-aware adjustment 설계만으로도 성능이 잘 나온다는 점이 흥미로웠습니다. 결국 이미지가 단순한지 복잡한지에 따라 두 전략을 adaptive하게 조절하는것이 효과적이라는 것을 간단하지만 강하게 보여준건 같습니다!
한가지 궁금한점은 그럼 이미지 복잡도라는걸 어떻게 판단하느냐가 중요할것 같은데
예를 들어서 object수는 적어도 관계나 세부적인 속성을 봐야하는 이미지는 attention entropy기준으로는 단순하게 판단 될수도 있을거 같고 반대로 배경은 복잡해도 실제로 봐야하는 정보가 한쪽에 쏠려있을수도 있을것 같아요!
그럼 이런 경우에도 attention entropy가 복잡도를 잘 반영할수 있을지 인택님의 생각이 궁금합니다!
안녕하세요 찬미님 좋은 답글 감사합니다.
흐음… 그런 상황에서는 attention entropy가 adaptive 하게 작동하지 않을 수도 있지만, 뭐 사실 그건 text 를 쓰느냐 안쓰느냐에 따른 질문에서도 똑같이 적용될 수 있을 것 같습니다.
해당 방법론은 text 를 쓰지도 않고, 위에 찬미님이 언급한 그러한 문제를 잘 반영하는지 아닌지를 그냥 성능으로 보여주고 있습니다.
물로 찬미님이 질문해주신 그런 세팅을 나눠서 성능 리포팅을 하면 그게 베스트긴 하지만 그렇게 세부적인 실험까지 돌릴 것 같지는 않네요..
감사합니다.
안녕하세요 인택님 좋은 리뷰 감사합니다.
simple image와 complex image를 나누는 기준이 조금 궁금한데 리뷰에서는 attention entropy나 erank를 사용해 pruning method의 특성을 분석한 것으로 보이는데 실제 adaptive pruning 과정에서도 이 값들을 이용해 이미지 복잡도를 판단하는 것인지 궁금합니다. attention entropy나 erank가 단순히 분석용 metric으로 사용된 것인지,아니면 실제 inference 단계에서 threshold를 조절하기 위한 기준으로도 사용되는 건지 궁금합니다. 감사합니다.
안녕하세요 우현님 좋은 댓글 감사합니다.
이해하신게 맞고 adaptive pruning 과정에서도 해당 값들을 통해 이미지의 복잡도를 판단하고 threshold 처럼 사용하여 전체 토큰 budget을 결정하게 됩니다.
감사합니다.