이번 리뷰는 Anomaly detection 논문을 리뷰하고자 합니다.
해당 논문은 Anomaly detection을 위한 데이터 셋 MVTec ad에서 SOTA를 달성한 one-class learning 방법론 입니다.(Paper with code 기준)
Intro
anomaly detection이란?

위의 그림을 보면 이상한 점이 있습니다. 대부분의 물고기들은 왼쪽을 바라보고 있지만, 가운데 빨간색 물고기는 혼자 오른쪽을 바라보고 있습니다. 또한 열에 열의 사람들은 위의 그림에서 이상한 점을 물어본다면 빨간색 물고기를 지목하겠죠. 이처럼 사람은 특별한 룰을 제시하지 않아도 전체적인 흐름에서 이상한 점을 지목할 수 있는 능력이 있습니다.
이를 다시 해석하자면 데이터로부터 분포를 그렸을 때, 동떨어진 곳에 위치한 분포를 가진 이상치를 찾아내는 것을 anomaly detection이라고 하며, 사람은 상황에 맞게 추려낸 normal sample로부터 모든 normal data의 분포로 일반화가 가능합니다. 이를 토대로 abnormal data를 추려낼 수 있습니다.
즉, anomaly detection에서는 normal data의 분포를 잘표현할 수 있는 모델의 파라미터를 찾는 것이 목표로 둡니다.
또다른 특징으로는 abnormal data는 드문 경우에 발생하며 다양한 상황으로 발생하기 때문에 Supervised learning을 적용 시, Class-Imbalance 문제를 꼭 해결해야합니다. 그래서 대부분 anomaly detection 연구의 방법론들은 semi-supervised learning/unsupervised learning이 주를 이룹니다. 특히 AutoEncoder, GAN을 이용해 영상을 다시 만들어 비교하는 Reconstruction-based method와 영상으로부터 embedding vector를 추출하여 이용하는 embedding similarity-based method가 큰 축을 이룹니다.
이번 리뷰의 방법론 또한 이상치에 대한 라벨이 필요 없이 normal data로만 학습을 진행하는 unsupervised learning이며, embedding similarity-based method 입니다.
Anomaly Detection은 CCTV, 의료영상, Social Network, 제조 산업 등 특정 짓기 힘든 이상 상황을 검출하기 위한 목적으로 사용됩니다. 이번 리뷰에서는 영상으로 촬영된 산업 환경에서의 비정상 검출에 관한 연구를 다룰 예정입니다.

Fig 1은 MVTec AD라는 데이터 셋입니다. CVPR 2019에서 처음 선보인 데이터 셋으로 15가지 클래스(트랜지스터, 캡슐, 나무 판자 등) 가지며 각 클래스 별 약 240장의 이미지를 가지고 있습니다. 이 데이터 셋의 큰 기여는 실제 환경에서 발생하는 불량품을 직접 촬영한 점입니다. 또한 발생한 불량부의 위치를 segmentation을 진행함으로써, pixel-level의 anomaly detection이 가능해졌습니다.
리뷰의 방법론 또한 MVTec AD 데이터 셋을 이용했으며, pixel-level에서의 Anomaly Detection을 수행합니다. 자세한 방법론에 대해서는 다음 섹션에서 설명드리겠습니다.
Method
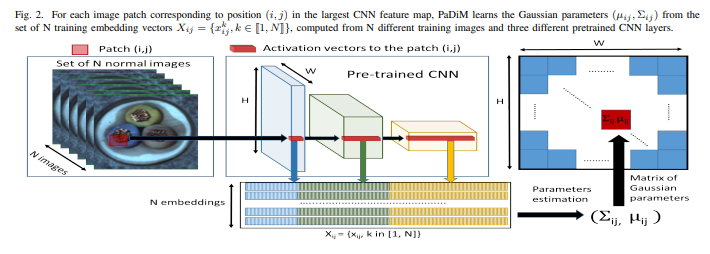
리뷰의 방법론은 매우 간단합니다. 방법을 간단하게 설명하자면 아래와 같습니다.
방법.
1. pre-trained CNN을 이용하여 normal data의 feature를 추출
2. 각 레이어의 feature를 concat.
3. Random Selecting Dimention
4. normal img ~ N개의 방법 3 값들의 분산과 평균을 patch 단위로 획득. ~ train data
5(inference). test img를 1~3을 수행하여 데이터를 얻은 후, 방법 4의 분산과 평균을 이용한 마할라노비스 거리 값을 획득함으로써, anomaly map을 얻습니다. (anomaly map에서 높은 값들을 anomaly pixel이라고 가정합니다.)
++ 왜 학습을 하지 않고 바로 pre-trained CNN을 사용했는지?.. 저자는 시간 복잡도와 데이터 사이즈가 커짐으로써 예측에 대한 코스트가 높아지는 경우를 막기 위해 사용했다고 합니다. (논문에는 따로 내용이 없지만 아마 CNN를 이용하고 싶지만 Class-Imbalance 문제에 당면하여 이에 대한 대안책으로 pre-trained CNN을 사용하고 이유를 나중에 붙인 것 같습니다.)
Experiment
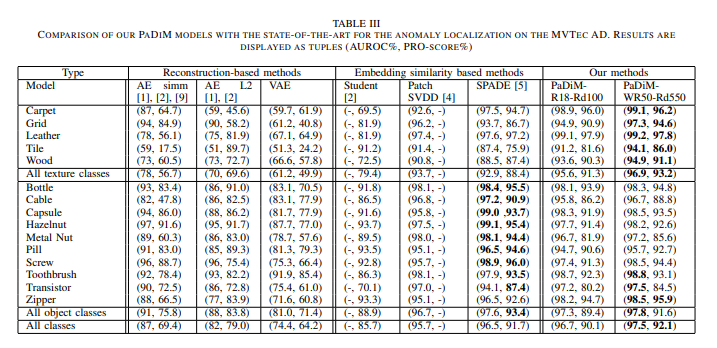

해당 방법론에서는 wise-ResNet50, EfficeintNet-B5, ResNet18을 이용하여 평가를 진행하였습니다. SOTA를 달성한 모델은 EfficientNet-B5을 bakcbone으로 사용했습니다. 성능은 TABLE 5와 같이 나왔습니다.
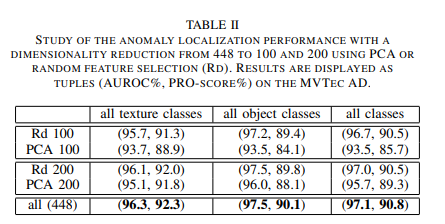
해당 방법론에서 흥미롭게 가져갈만한 특징으로는 PCA에 있습니다. 기존의 PCA는 고유 값을 정렬한 후, 차원 축소를 진행했습니다. 해당 방법론에서는 랜덤한 추출이 성능 향상을 가져온다고 주장합니다. TABLE 2는 그에 대한 실험 결과입니다.
++
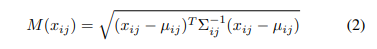
END
++ 해당 논문의 큰 기여는 사실 KNN을 사용하지 않고 CNN featrue를 이용했다는 점입니다. 이전의 Anomaly detection들은 KNN을 통해 이상치의 분포를 계산 했습니다. KNN을 이용하지 않은 방법론들은 CNN을 사용하지 않고, anomaly map을 만들었습니다.
정말 간단한 방법인데 SOTA를 달성하다니… 이는 anomaly detection 분야에 적용해볼만한 방법론이 많다는 뜻이기도 한 것 같습니다. 이번 한전 과제를 진행하면서 성능 향상에 도전해볼만한 가능성이 있다고 생각이 들게 만든 논문이였습니다.
우연히도 같은 논문을 리뷰하게 됬네요. 리뷰에 빠진 내용들이 좀 있는거같아서 차후 읽게 되실분들이 좀 더 이해하기 쉽도록 아래와 같이 남깁니다.
첫 째, “2.의 값을 PCA”를 수행. 이라고 하셨는데 논문에서 PCA를 사용하는 것보다 Random하게 차원을 축소시키는게 더 성능이 좋게 나와서 그렇게 사용했다고 논문에 나와있는거 같은데 확인해봐야할듯 합니다.
둘 째, 각 패치단위마다 corresponding하는 피쳐맵들이 있을텐데, H*W 차원이 바뀌면서 corresponding하는 피쳐맵들이 어떻게 매칭이 되는지 빠진거 같습니다.
셋 째, multivariate gaussian distribution의 파라미터인 뮤와 covariance 매트릭스를 estimate하고 해당 값들을 이용하여 embedding vector를 만드는 과정이 생략된거 같습니다.
추가로, 해당 논문에서 align을 깨트린 MVTEC-AD 데이터셋을 새로 만들어서 추가실험을 하였고, 해당 부분도 contribution중 한개로 가지고 갔는데 그 부분도 생략된거 같습니다.