제가 리뷰할 논문은 Learning Deep Features for Discriminative Localization 입니다.
제가 이 논문을 고른 이유는 Pedestrian detection task를 진행 중 제 모델이 인풋 이미지에서 어디를 보고있는지가 궁금해져서 activation map/heat map으로 검색을 하다보니 해당 논문이 나왔고 구현에 있어 많이 어렵지 않겠다 생각이 들어 읽어보게 되었습니다. 본 논문은 visualization에 대한 내용이 있지만 그를 이용해 detection이 가능하다는 내용도 있습니다.
Introduction
이 논문이 쓰일 당시 CNN의 convolution layer가 object의 위치에 대한 학습이 없어도 실제로 detector로 동작을 한다는 것에 대한 연구가 있었습니다.(Object Detectors Emerge in Deep Scene CNNs) 하지만 CNN에서 classification을 위한 fc layer를 거치면서 사물에 대한 뛰어난 localize 성능은 사라집니다.
그래서 뛰어난 성능을 유지하기 위해 Network in Network 나 GoogleNet과 같은 유명한 fully-Convolutional neural network가 제안되었습니다.
+fully-Convolutional neural network를 사용하면 fc layer를 사용하는 것 보다 파라미터 수도 적어짐.
그래서 이 논문에서는 파라미터 수를 줄이고 높은 성능을 유지하기 위해 global average pooling(gap)을 사용합니다. 기존에는 gap가 학습하는 동안 오버피팅을 방지해 주는 regularizer로 사용되었다면 본 논문에서는 약간의 조정을 통해 gap를 단순히 regularizer가 아닌 뛰어난 localization 능력을 마지막 레이어에서도 갖을 수 있게 해주는 역할로 사용합니다. 앞서 말한 약간의 조정으로인해 single foward로 discriminative한 이미지 영역을 쉽게 구분할 수 있게 됩니다. 즉, object dection을 위한 네트워크가 아니여도 object detection을 할 수 있다는 이야기입니다.

[그림 1]에서 아래에 위치한 사진과 같이 각 이미지에 해당하는 label을 가진 object의 영역을 알 수 있기에 detection이 가능합니다
Related Work
앞서 말한 것과 같이 convolution layer가 object의 위치에 대한 학습이 없어도 detection을 할 수 있다는 내용의 연구가 있었고 그와 비슷한 맥락으로 Weakly-supervised object localization에 대한 연구들이 있었습니다. 그 연구들은 end-to-end가 아니고 object localization을 위해 네트워크를 multiple forward pass해야 했습니다. 하지만 이런 연구들과는 다르게 본 논문에서는 end-to-end로 학습되었으며 single forward pass로 object를 찾을 수 있습니다.
Contribution
Class activation map(CAM)은 각 이미지에 대해 생성된 weighted map을 말하는데 간단히 하자면 모델이 이미지에서 어디를 보고 있는지를 나타내는 map입니다. 특정 카테고리에 대한 CAM은 그 카테고리를 식별하기 위해 사용된 이미지에서의 discriminative한 영역을 나타냅니다.
Class Activation Mapping은 다음과 같이 이루어집니다.
- 마지막 output layer 바로 직전(분류의 경우 softmax)에서 feature map에 대해 gap를 수행한다.
- Gap를 통해 나온 값을 fc layer에 통과시킨다.
- Output layer의 weights를 convolutional feature maps에 projection 시킨다.
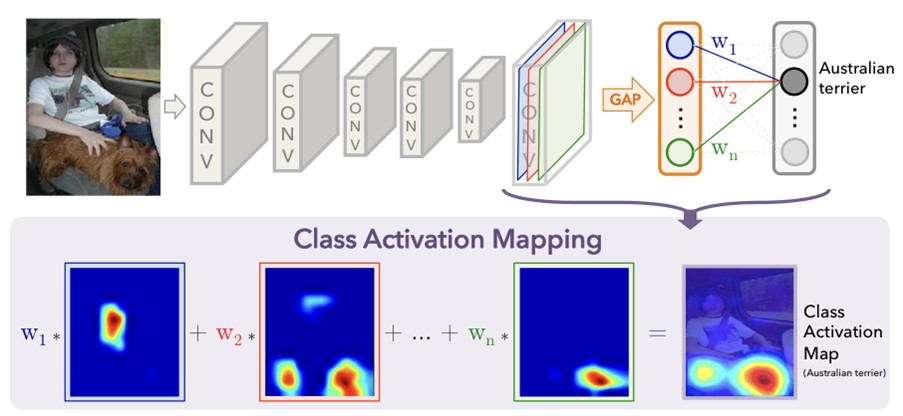
[그림 2]를 보면서 조금 더 설명하자면 gap를 통해 반환된 값은 gap의 input으로 들어오는 feature map에서 각 채널의 spatial한 average값이고 이 spatial한 값은 feature map의 각 채널의 공간정보를 담고 있습니다. 이 값의 weighted sum은 마지막 output을 만들 때 사용됩니다. 이와 유사하게 마지막 convolutional layer와 gap를 통해 나온 값의 weighted sum을 함으로써 CAM을 얻을 수 있습니다.
저자는 이 과정을 softmax를 예로 formal하게 설명합니다.
주어진 이미지에 대해 fk(x,y)를 마지막 레이어의 특정 위치(x,y)에서 k번째 채널의 activation을 나타낸다고 할 때, 채널 k에 대해서 gap의 결과를 Fk라하고 Fk는 fk(x,y)의 합이라 합니다.
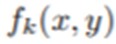
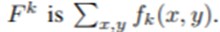
그렇기에 클래스c에 대한 softmax의 인풋 Sc는 wkc*Fk의 합(weighted sum)으로 나타낼 수 있고, wkc는 채널 k에서 클래스c와 대응하는 weighted를 말합니다.(weight => gap의 output)
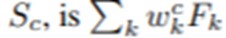
그래서 클래스 c에 대한 softmax의 output은 모든 클래스에 대한 Sc로 특정 클래스에 대한Sc를 나눈 값으로 표현할 수 있습니다
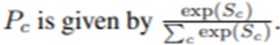
Softmax의 인풋인 Sc는 wkc*Fk의 합이기에 다음과 같이 표현 가능합니다.
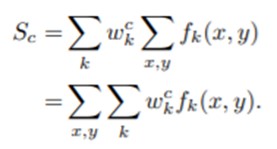
이렇게 표현한 식에서 클래스 c에 대한 activation map을
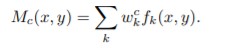
라고 표현합니다.
이 식을 가지고 Sc를 다시 보면
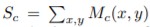
이렇게 표현할 수 있고, 각 클래스에 대한 activation map은 이미지에서 클래스 c로 분류하는 특정 공간(x,y)에서 activation의 중요성을 직접 나타내게 됩니다.
Activation map을 visualization 하고 싶다면 단순히 input image의 크기로 upsampling 해주면 됩니다. Activation map을 visualization한 결과는 다음 [그림 3]과 같습니다.
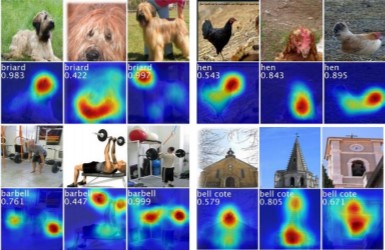
Result
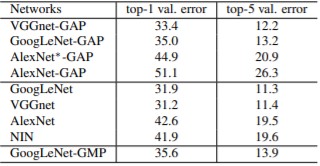
Classification의 성능은 1~2%정도 떨어졌습니다. 왜냐하면 Network에서 몇몇 convolution layer를 제거했기 때문입니다.
Layer를 제거한 이유는 GAP 전 마지막 convolutional layer의 resolution이 higher할수록 localization ability가 높아진다는 사실을 발견했기 때문입니다.
Localization을 수행하기 위해 bounding box를 만들어야 했습니다. CAM을 기반으로 bounding box를 만들기 위해 heat map에 segmentation을 하는데 먼저 CAM의 최대 값의 20%이상의 영역만 segmentation합니다. 그런 다음 만들어진 segmentation map에서 가장 크게 만들어진 부분을 bounding box로 사용합니다.
그렇게 만든 bounding box를 가지고 detection을 가지고 이미지에 localization을 한 결과는 [그림 4]와 같이 나타나게 됩니다.

a)는 GoogleNet-GAP에서의 localization 예시이고, b)는 GoogleNet-GAP와 기존 localization을 위한GoogleNet의 비교입니다. (위:GoogleNet-GAP, 아래: GoogleNet)
ILSVRC validation set 에 대한 Localization 성능 평가는 [표 2]와 같습니다.
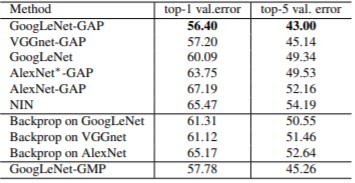
결론은는 CAM을 적용한 모델이 Classification에서는 1~2%의 성능 하락이 있었지만, weakly-supervised object localization으로 Localization의 성능이 잘 나올 수 있다는 것과 gap를 통해 파라미터 수를 줄였다는 것입니다.
추가로 class activation map을 이용하면 누군가에게 설명을 하거나 설득을 할 때 조금 더 긍정적인 효과를 볼 수 있지 않을까 싶습니다.
좋은 리뷰 감사합니다. 혹시 해당 내용을 구현 및 적용하셔서 RCV 연구실 내부에 공유해주실 의향이 있으신가요?
네 그럴 의향은 충분히 있습니다!
글 잘 읽었습니다.
한가지 궁금한 점이 있는데, 본문에 내용 중 분류 성능이 1~2% 하락한 이유는 conv layer를 일부 제거하였기 때문이고, 이를 제거한 이유는 conv layer를 더 통과하면 feature map의 resolution이 down sampling되어 localization ability가 떨어지기 때문이라고 말씀하신게 맞나요?
만약 맞다면, 컨볼루션 연산을 할 때 stride를 1로 하거나, padding size를 키워서 feature map의 resolution이 변경되지 않도록 하면 conv layer를 제거할 필요가 없으니 localization ability와 성능 모두 유지되지 않았을까요?
네 말씀하신 방법대로 모델을 만들면 classification 성능도 아마 유지가 될 것 같다고 생각됩니다.
하지만 본 논문의 저자가 말하길
“Note that removing fully-connected layers largely decreases network parameters (e.g. 90% less parameters for VGGnet)”
fc layer를 제거하는 것이 파라미터 수를 크게 감소 시킨다고 하고 VGG를 예시로 90%의 파라미터가 감소하였다고 합니다. 성능 1~2%대신 가벼운 모델을 선택한 것 같습니다.
VGGnet에서는 conv5_3이후의 레이어는 다 remove했다고 합니다.