안녕하세요 저번 리뷰에 이어 이번에도 6D pose estimation을 다루겠습니다. 해당 리뷰만 읽어도 이해하는데 지장이 없을정도로 자세하게 작성할 예정이지만, 해당 분야에 좀 더 배경지식이 필요하신분들은 아래에 제가 지난주 작성했던 리뷰인 PVNet을 참고해주세요.
배경
항상 task를 이해하려면 어떠한 분야에 활용될 수 있는지 생각해야합니다. 6DoF pose estimation은 왜하는 것이며, 어떠한 분야에 활용될 수 있을까요? 그 전에 6DoF가 무엇을 의미할까요? 쉬운 내용이지만 혹시나 하는 마음에 간단히 언지하고 넘어가겠습니다.
6DoF는 6자유도를 의미합니다. 즉, x, y, z좌표축의 위치에 대한 정보 3개와 x, y ,z 방향 회전에 대한 정보 3개가 모여서 총 6자유도를 지닙니다. 즉 모든 물체의 자세(pose)는 6자유도로 나타낼 수 있습니다.
그렇다면 물체가 갖는 6자유도를 추정하는 이유가 무엇일까요?
예를들어 커피잔을 잡는다고 생각해보세요. 사람은 무의식중에 손을 움직여서 손잡이를 잡고 들어올립니다. 그러나 기계손이 커피잔을 잡는다고 생각하면 생각보다 쉽지않은 일이될 수 있습니다. 우선, 기계손의 관절 한개한개가 어떠한 자세를 취하고있는지 알아야합니다. 또한, 커피잔의 위치가 3D좌표계상에서 어디에 잇는지 알아야합니다. 그리고, 커피잔의 손잡이가 어디방향으로 돌아가있는지 알아야합니다. 이러한 정보를 종합하여 기계손은 움직일 경로를 설계합니다. 그리고 최종적으로 커피잔을 잡을 수 있습니다. 해당 예시에서 필요한 정보가 바로 물체의 6D 정보입니다.
사람이 커피잔을 들어올리는 과정을 로봇으로 비유하면, 사람은 로봇에 해당합니다. 커피잔은 물체에 해당하고, 손은 manipulator에 해당합니다. 사람의 팔목, 팔꿈치 등은 로봇의 관절에 해당하고 자유도를 높여주는 역할을 합니다. 활용 분야에 따라 manipulator를 용접봉, 절삭장치, 그래버 등등… 다양하게 변경할 수 있습니다.
위에서는 이해를 쉽게하기위해 커피잔을 예시로 들었지만, 실제론 좀 더 실증적인 다양한 활용사례가 있습니다. 예를들어 물류센터에서 박스를 옮기는 로봇, 볼트,너트 체결을 하는 로봇, 용접을 하는 로봇 등등… 물체가 놓여있는 위치를 정확히 알아야하는 경우에 활용 될 수 있습니다.
추가적인 배경지식으로, 각각의 관절에 들어가는 서보모터의 개수에 따라 자유도가 늘어날 것입니다. 서보모터에 걸리는 전압에 따라서 로봇의 움직임이 달라질 것입니다. 로보틱스에서 관심있는 부분은 서보모터에 걸리는 전압을 제어하여 원하는 대로 로봇을 움직이는 것 입니다. 해당 과정을 역기구학이라고 하는데, 자유도가 1개만 올라가도 수식은 훨씬 복잡해지기 때문에 쉬운과정이 아닙니다. 회사에가면 역기구학만 하루종일 연구하는 연구원들도 있다고 합니다. 자유도가 낮은 로봇의 경우 이미 솔루션이 나온경우도 있지만, 자유도가 조금만 높아져도 근사시켜서 구하는 방법을 사용합니다. 이미 구한 솔루션들도 명쾌하게 구했다기보단 직관적으로 생각해내기 힘든 경험에 의한 trick들과 trial-error 방식으로 구한 경우가 대부분이라 아직 해결해야할 점들이 많습니다.
우리가 다루고싶은 주제는 컴퓨터비전이지만, 로보틱스쪽도 밀접한 연관이 있기때문에 알고있으면 좋을 지식이라고 생각되어 언급해보았습니다. 사실 간략하게만 언급하였는데, 좀 더 자세하게 로보틱스 쪽에 대한 배경지식을 얻고 싶으신분들은 제가 저번에 작성했던 리뷰를 참고해주세요.
논문소개
지난주에 제가 리뷰했던 PVNet을 읽으셨나요? 해당 논문에서도 지난주에 리뷰했던 PVNet과 마찬가지로 코드를 공개하였습니다. 코드를 공개한 repo의 README에는 흥미로운 글이 실려있습니다.
It is straightforward to merge with other correspondence-extraction networks SegDrivenPose or PVNet to obtain an end-to-end 6D pose framework.
원문을 가지고 와봤는데… PVNet에도 적용이 가능하다 라는 내용이 실려 있었습니다. 논문 서베이를 하면서 Abstract, conclusion, github에 공개된 readme 등을 읽어가며 흥미로운 논문들을 찾았었는데, 해당 과정에서 저 글을 읽고 흥미가 가서 리뷰를 진행하게 되었습니다. 마침 CVPR 2020에 공개된 논문이고, 인용수 또한 2020년에 공개된거 치고 13으로 준수한거 같아서 리뷰하기로 마음먹었습니다.

본격적으로 논문을 리뷰해나가기 전에 figure 1을 가지고 왔습니다. 항상 figure 1을 먼저 보고 논문을 읽으면 논문을 빠르게 이해하는데 도움이 되는거 같습니다. 해당 figure가 말하고자 하는 것은 무엇일까요? 최근 6D pose estimation에서는 주로 3D 바운딩 박스의 코너와 2d 이미지 픽셀에서의 correspondences를 구하고 그 오차의 평균을 최적화 하는 형태로 학습을 했습니다. 마찬가지로 지난주에 리뷰했던 PVNet의 경우 Mahalanobis distance를 최적화 시키는 방향으로 학습을 했습니다. 그러나 이러한 경우 instance가 여러개인경우 평균을 이용하여 학습을 하기 때문에 다른 경향성을 보이더라도 평균은 비슷한 경우가 생길 수 있습니다.
위의 그림(a)을 보시면 green과 red의 pose정보(좌표축 위치와 방향)이 약간 다른걸 보실 수 있는데 이는 위에서 언급한 문제 때문에 일어난 현상이라고 주장하고있습니다. 또한, (b)에서는 3D keypoints의 순서에 따라서도 영향을 받는 것을 정성적으로 보여줍니다.
위에서 한 얘기를 나이브하게 예시를 들자면, 3D 바운딩박스의 키포인트로 코너 8개를 사용한다고 했을때, 그와 2d 이미지에서의 correspondences가 있을것 입니다. 이때, 최근 연구들은 해당 correspondences의 평균을 최적화 하는 방향으로 학습을 합니다. 해당 논문에서는 “평균을 최적화” 하면 성능이 저하되는 요인 이 될수 있다고 주장합니다. 또한, 8개의 키포인트들의 순서를 바꾸는 것 또한 성능 저하의 요인이 될 수 있다고 말합니다.
해당 논문에서 말하고자 하는 바
항상 논문을 읽다보면 이해하는데 치중하다 말하고자하는 핵심을 놓치는 현상이 발생합니다. 그래서 의식적으로 내가 읽는 논문에서의 핵심이 무엇인지 파악하는 것이 중요합니다. 그러한 내용은 주로 Abstract와 conclusion에 나와있습니다. 그래서 해당 부분을 먼저 가볍게 읽고 내가 찾고자 하던 논문이 아니면 읽지 않는 것이 하나의 전략이 될 수 있습니다. 어차피 볼 논문은 많기 때문이죠. 그래서, 이번 리뷰에서는 일단 해당 논문이 말하고자 하는 바를 먼저 소개하고자 합니다.
간단하게 핵심을 말하자면 one-stage이라서 빠르고, 성능도 two-stage 방법론들을 이겼다. 이것이 핵심입니다. 그럼 과연 어떻게 성능을 올렸을까요? 지금까지 얘기한 내용을 토대로 생각해보면 간단히 추론할 수 있습니다. 위에서 figure 1을 소개하면서 해당 논문에서 문제점들을 제기한것을 보았습니다. 그를 통해 해당 논문에서 제안하는 방법이 좋은 성능이 나온 이유가 해당 문제들을 해결했기 때문임을 추측 할 수 있습니다. 과연, 해결하지 못한 문제이면 논문 첫페이지 figure1 에다가 해당 그림을 올려두었을까요?
좀 더 구체적으로…
그렇다면 좀 더 구체적으로 해당 논문의 contribution에 대해서 알아봅시다. 해당 논문에서 제안하는 네트워크는 simple하지만 effective하게 6D pose를 직접적으로 regression하여 구합니다. 해당 과정에서 order of correspondences에 상관없이 6D pose를 regression합니다. 그리고 기존 two stage방식을 one-stage로 해결하였고, end-to-end의 학습을 가능하게 하였습니다.
또한, generality를 테스트하기위한 실험에서 현존하는 SOTA correspondence extraction framework에 적용하였을때, 해당 방법론들의 성능을 이기고 SOTA를 달성하였고, speed또한 더 빨랐습니다. 여기서 현존하는 SOTA correspondence extraction framework 중 한개가 바로 지난주에 리뷰했던 PVNet입니다. 즉, PVNet에서 voting하는 방법으로 correspondences를 뽑은 후 해당 correspondences를 해당 논문에서 제안하는 one-stage 네트워크에 태우면 성능향상이 일어나고, 속도또한 빠르다는 것 입니다.
기존 연구들
보통 related-works를 읽는걸 좋아하지 않아 가볍게 읽고 넘기는 편인데 해당 논문에서 기존연구들에 대한 설명이 자세하게 명시되어 있어서 이번에는 리뷰에 포함해보았습니다.
6D pose estimation을 하는 방법에는 가장 classical 한 방법으로 RANSAC-based PnP 알고리즘을 적용하는 것입니다. 해당 방법론들은 아래와 같습니다.
- David G. Lowe. Distinctive Image Features from ScaleInvariant Keypoints. International Journal of Computer Vision, 20(2):91–110, November 2004. 2
- Engin Tola, Vincent Lepetit, and Pascal Fua. DAISY: An Efficient Dense Descriptor Applied to Wide Baseline Stereo. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(5):815–830, 2010. 2
- Tomasz Trzcinski, C. Mario Christoudias, Vincent Lepetit, and Pascal Fua. Learning Image Descriptors with the Boosting-Trick. In Advances in Neural Information Processing Systems, December 2012. 2
- Shubham Tulsiani and Jitendra Malik. Viewpoints and Keypoints. In Conference on Computer Vision and Pattern Recognition, 2015. 2
- Georgios Pavlakos, Xiaowei Zhou, Aaron Chan, Konstantinos G. Derpanis, and Kostas Daniilidis. 6-DoF Object Pose from Semantic Keypoints. In International Conference on Robotics and Automation, 2017. 2
- Yuki Ono, Eduard Trulls, Pascal Fua, and Kwang Moo Yi. LF-Net: Learning Local Features from Images. In Advances in Neural Information Processing Systems, 2018. 2
링크를 달아두었습니다. 참고하실분들은 참고해주세요.
가장 나이브하게 곧바로 6D pose parameter를 regression하는 시도도 있었는데 그는 아래와 같습니다.
- Wadim Kehl, Fabian Manhardt, Federico Tombari, Slobodan Ilic, and Nassir Navab. SSD-6D: Making Rgb-Based 3D Detection and 6D Pose Estimation Great Again. In International Conference on Computer Vision, 2017. 2
- Yu Xiang, Tanner Schmidt, Venkatraman Narayanan, and Dieter Fox. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Robotics: Science and Systems Conference, 2018. 2, 5, 6, 7, 8
그러나 이와같은 나이브한 접근방식은 당연히 성능이 잘 나오지 않았습니다. 대신, 3D-to-2D correspondences를 구한 다음 RANSAC-based PnP를 태우는 2 stage방식이 SOTA를 달성했고 해당 방식들은 아래와 같습니다. (이와같은 방식이 저번주에 리뷰했던 PVNet입니다.)
- Mahdi Rad and Vincent Lepetit. Bb8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects Without Using Depth. In International Conference on Computer Vision, 2017. 1, 2, 4, 5, 6
- Bugra Tekin, Sudipta N. Sinha, and Pascal Fua. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Conference on Computer Vision and Pattern Recognition, 2018. 1, 2, 5, 6
- Markus Oberweger, Mahdi Rad, and Vincent Lepetit. Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation. In European Conference on Computer Vision, 2018. 1, 2, 4
- Omid Hosseini Jafari, Siva Karthik Mustikovela, Karl Pertsch, Eric Brachmann, and Carsten Rother. Ipose: Instance-Aware 6D Pose Estimation of Partly Occluded Objects. In Asian Conference on Computer Vision, 2018. 1, 2
- Yinlin Hu, Joachim Hugonot, Pascal Fua, and Mathieu Salzmann. Segmentation-Driven 6D Object Pose Estimation. In Conference on Computer Vision and Pattern Recognition, 2019. 1, 2, 4, 5, 6, 7, 8
- Sida Peng, Yuan Liu, Qixing Huang, Hujun Bao, and Xiaowei Zhou. PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation. In Conference on Computer Vision and Pattern Recognition, 2019. 1, 2, 3, 4, 5, 6, 7, 8
- Sergey Zakharov, Ivan Shugurov, and Slobodan Ilic. DPOD: 6D Pose Object Detector and Refiner. In International Conference on Computer Vision, 2019. 1, 2, 5
- Kiru Park, Timothy Patten, and Markus Vincze. Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation. In International Conference on Computer Vision, 2019. 1, 2
- Zhigang Li, Gu Wang, and Xiangyang Ji. CDPN: Coordinates-Based Disentangled Pose Network for RealTime RGB-Based 6-DoF Object Pose Estimation. In International Conference on Computer Vision, 2019. 1, 2
correspondence가 서로 independent하지 않다고 주장하는 논문
이러한 배경에서 PnP를 deep net으로 대체하기 위한 시도는 다양하게 있었으나, 아직까지 satisfying한 solution을 내놓은 논문은 없었습니다. 다양한 시도는 해당 논문의 related work를 참고해주세요. 논문 이해를 위해 크게 중요한 부분이 아니라 다루지 않았습니다.
방법론
먼저 익숙한 수식부터 보겠습니다.

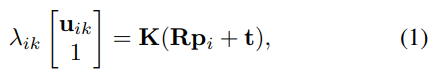
노테이션을 항상 작성하는게 번거로워서 본문을 끌어왔습니다. 람다는 스케일팩터를 의미합니다. 해당 수식은 아마 모든 연구원이 익숙하실거라 생각합니다.
고전적인 방법에서는 RANSAC-based PnP를 이용하여 R과 t를 구했습니다. 해당 논문에서는 이 과정을 아래와같은 수식으로 대체합니다.
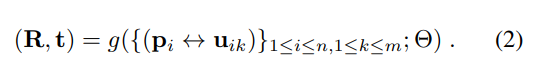
결국 네트워크를 태웠다는 얘기인데… 좀 있어보이게 수식으로 나타낸거같네요. notation은 논문을 참고해주세요. 딱히 중요한 수식은 아닌거같아서 여기까지만 언급하겠습니다.
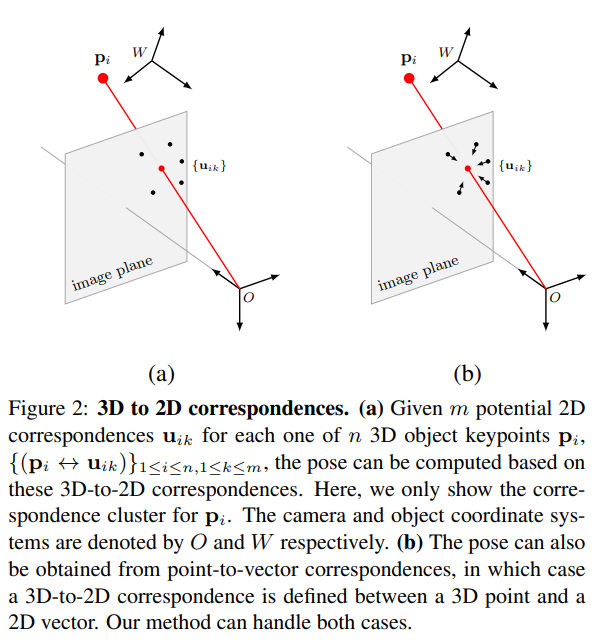
해당 논문에서는 3D keypoint와 와 2D 사이의 correspondence를 위와같이 나타냈습니다. 이때 p를 나타내는 3D좌표계상에서의 keypoint를 해당 논문에서는 cluster라고 명시한단점을 참고해주세요. (a)와 (b)의 차이가 보이시나요? a와 다르게 b는 벡터형태로 이루어져있습니다. 딥러닝으로 풀려고할때, 벡터형태로 나타내는것이 더 성능이 좋다고 하네요. 그래서 저번주에 리뷰했던 PVNet에서도 벡터형태의 voting을 했나봅니다.
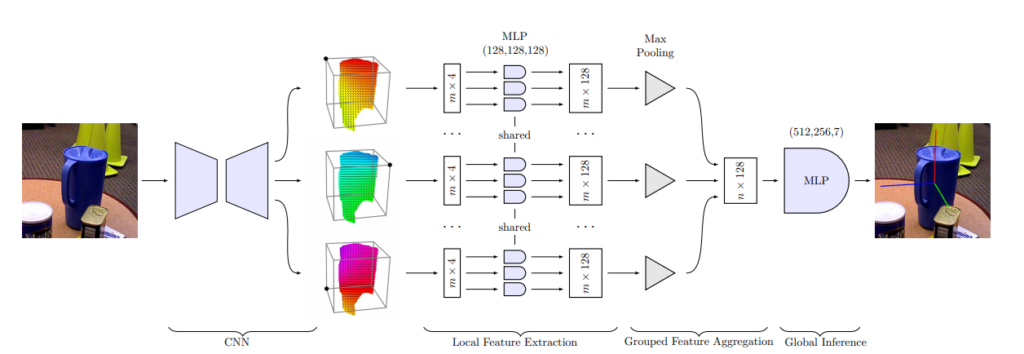

드디어 전체적인 아키텍쳐인데요. 아키텍쳐는 크게 3개의 모듈로 이루어져있습니다. 앞단에서 Segmentation에서 사용하는 Encoder-decoder방식의 CNN을 태워서 3D와 2D 사이의 correspondences를 뽑아내고 해당 correspondences는 Local Feature Extraction 모듈에 들어갑니다. correspondences는 위의 그림에서는 총 3개의 cluster에 대해서 다루었는데 3D 바운딩 박스의 모서리가 8개인점을 감안하면 총 8개의 세트가 있을 것 입니다.
Local Feature Extraction 모듈은 weight를 share하는 특이점을 제외하곤 그냥 단순한 MLP(멀티 레이어 퍼셉트론)모듈입니다.
이 후 grouped feature aggregation 모듈에서는 각각의 cluster에 속하는 point들의 order에 영향을 덜 받게 하기위해 PointNet에서 제안하는 방법의 반대방법을 사용한다고 합니다. 제가 PointNet 논문을 읽어본적이 없어서 정확하진 않다고 생각되지만, 이 부분은 아마 Concatenate하는 과정에서 순서를 부여하는 느낌으로 접근하는거 같습니다. 실제로 앞에서 3D keypoint(cluster)들의 순서를 fix시켜 버렸고, 이를 통해 order의 변화로 생기는 2D projection error를 없앴습니다. 같은원리로 point들의 순서 변화로 생기는 에러를 없애기 위해 비슷한원리를 적용한거같습니다.
최종적으로 Global Inference 모듈을 통해 앞에서 concat한 텐서를 바탕으로 최종 pose를 예측합니다. 이때 결과는 quaternion과 translation으로 나옵니다. 즉, 회전(롤, 피치, 요)과 병진에 대해서 나옵니다.
학습을 위한 loss는 아래와 같이 사용됩니다.
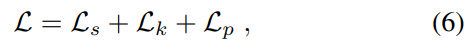
해당 식에서 s는 Focal loss 를 의미하고, k는 저번주에 리뷰했던 논문 PVNet에서 사용했던 regression term와 같습니다.
그리고 p는 3D reconstruction loss입니다.
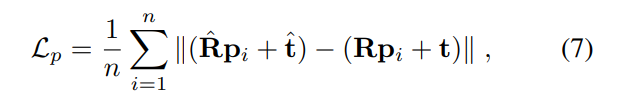
R과 t는 아시다시피 rotation, translation을 의미하는데 햇이 붙은것은 예측값, 안붙은건 GT값 입니다. 그냥 L1 distance 느낌으로 뺀다음 나누어준 값이라고 생각하면 됩니다. 물론 선형, 연속함수이며 극한값이 정의역 전체범위에서 존재하므로 미분가능하고요.
예시를 통한 설명
저번주차 리뷰에서와 같이 예시를 들어보겠습니다. 개인적으로 예시를 통한 설명이 가장 이해하기 쉬운거 같습니다.
h * w * 3의 RGB이미지가 있다고 해봅시다. 최종적인 아웃풋은 H*W*C가 나옵니다. 이때 H 와 W는 h와 w에 비례합니다. 이와같이 좀더 일반적으로 설계한이유는 아마도 다양한 방법으로 extract된 correspondences 사용하기 위함인거 같습니다. 즉, 인풋 이미지의 사이즈가 바뀌어도 아웃풋의 사이즈가 바뀔뿐 모델은 동작합니다.
위에서 아웃풋이 H*W*C 라고 했는데 좀 더 자세히 알아보겠습니다.
이때 C = (클래스의 개수 + 1)+2*n이 됩니다. 클래스의개수+1은 segmentation을 하는 과정에서 어떠한 class에 속하는지 혹은 배경에 속하는지에 대한 classification score이고, 2*n은 3D cluster에 상응하는 2D location에 대한 정보입니다. 이때 2*n 개의 채널의 값은 단순 point가 될수도있고, x,y 성분을 가지는 vector가 될 수도 있습니다. 위에서 설명했듯 x, y성분을 가지는 벡터를 사용하는게 좀더 learnable하다고 합니다.
Experiment
실험은 synthetic data와 Occluded-LINEMOD, YCB-Video에서 진행했습니다. 그리고 그 결과를 classical한 PnP방법 기반과, two-stage 기반의 방법들과 비교했습니다.
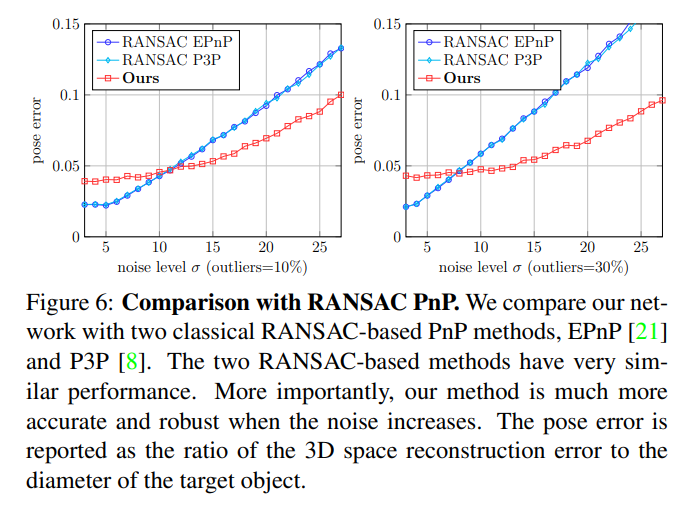
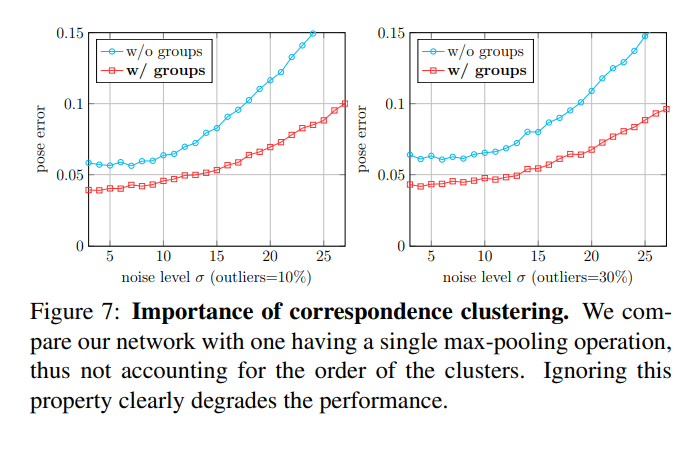
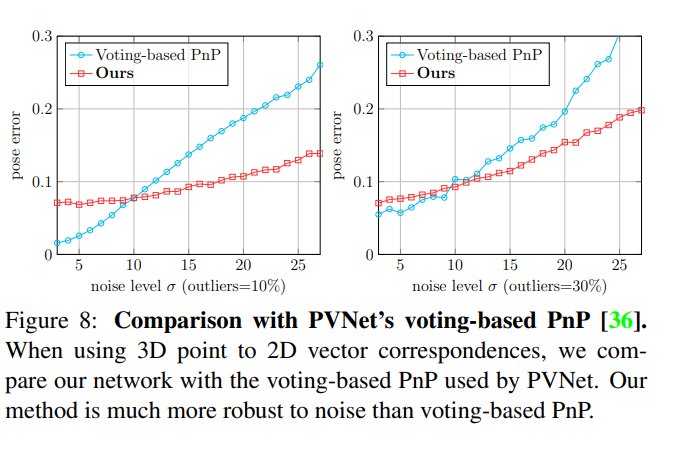

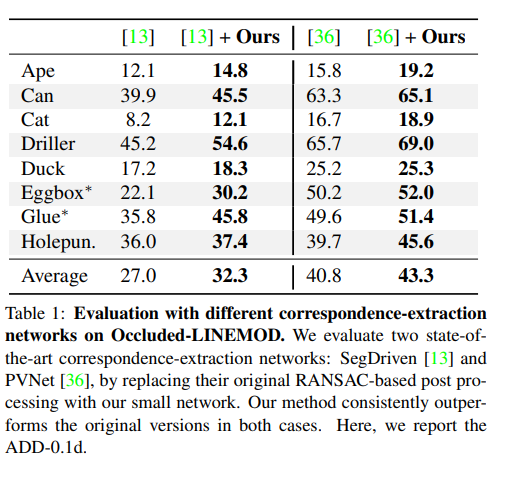
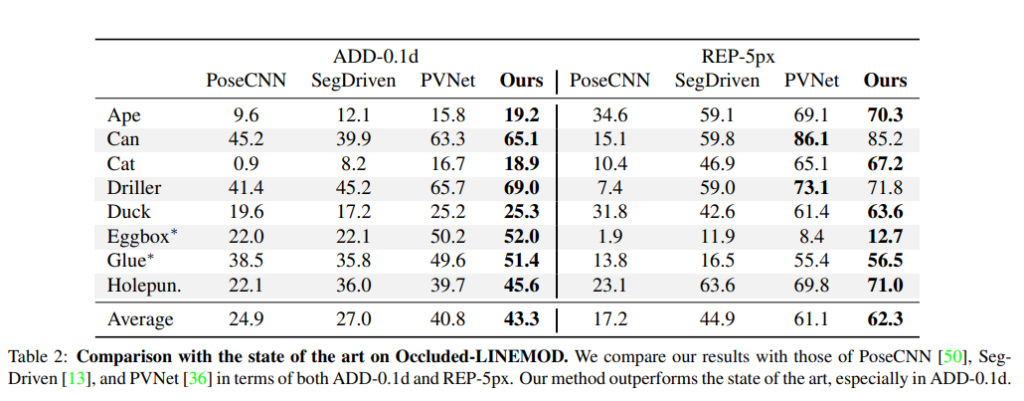
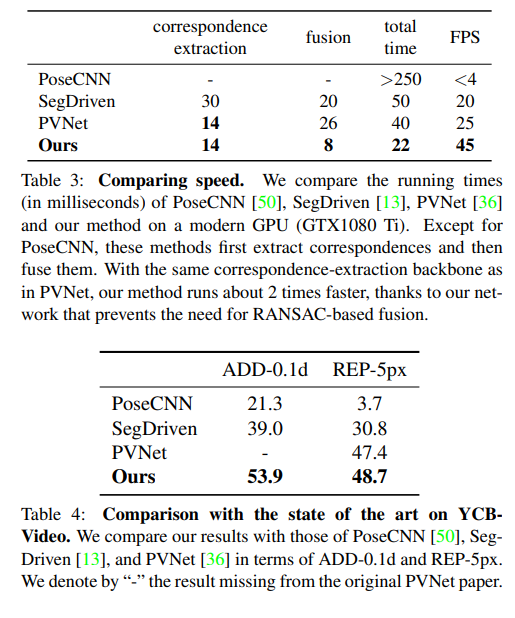
결론적으로 다양한 실험을 한결과 속도도 더 빠르고, 성능도 더 좋았다. 그리고 고전적인 방법에 비해 noise에 더 robust했다. 이게 결론입니다. 다만 noise level이 적을때는 고전전인 방법에 약간 밀리는 성능을 보이네요.
이상 리뷰 마치겠습니다.