Visual Place Recognition(VPR)은 로보틱스와 자동화 시스템에서 뜨거운감자로 다양한 관련 연구가 나오고 있다 . 특히 맵이 있는 상황에서 사용자의 위치를 찾는 것과 Simultaneous Localization And Mapping(SLAM)의 주요 구성요소로서 각광을 받고있다.
VPR의 주요 시스템으로는 Image Retrieval 이 있다. 이는 그림 2 와 같이 Database로 구축된 이미지들 속에서, 사용자가 찾는 영상과 가장 유사한 영상을 검색하는 시스템으로 이해하면 좋겠다.

이 Image Retrieval 할때 필수적으로 진행되는 영상과 영상의 비교는 단순히 영상의 픽셀 값으로 하는 것이 아니다. 영상의 표현할수 있는 대표 Desciptor로 변환한후 그 Descriptors 끼리 비교하는 것이 일반적이다. 영상을 대표하는 Descriptor의 종류는 크게 두가지 Global Descriptor와 Local Descriptor로 나눌 수 있다. 먼저 Local Desciptor는 한장의 영상에 Patch 별로 Gradient Historgram 값으로 나타낸 지역불변특진인 SIFT 와 같은 영상 한장의 특징을 표현할 수 있는 것을 뜻한다. Global Descriptor는 Database 전체의 Local Descriptor를 고려하여 영상을 하나의 Vector로 만들어 Global한 정보를 표현한다 해서 Global Descriptor라 이해하면 좋을 듯 하다. 이 Global Desciptor는 하나의 Vector로 되어있어서 모든 Database와 연산하여 비교할때 Local Descitpro에 비해서 매우 빠른 속도를 자랑한다. 또한 모든 Local Desciptor를 고려했기 때문에 영상의 밝기나 생김새 미세한 달라짐에 강인하다. 반대로 Local Descriptor는 단 두장의 영상을 비교한다 했을 때, 보다 디테일하게 비교를 하여 정확한 6-DoF를 추정할 수 있다는 장점이 있다.
이러한 두 Descriptor의 장점을 잘 융합하여 VPR 의 성능을 올리는 것이 이 Patch-NetVLAD의 가장 큰 Contribution이라고 할 수 있다. 그 외에 다른 Contribution 을 정리하면 다음과 같다.
- Locally-Global Descriptor를 통해서 영상 페어의 Score를 얻는 새로운 위치인식 시스템을 제안한다.
- Locally-Global Descriptor를 Single Size에서만 얻지 않고 Multi Size에서 얻은 후 그 정보를 융합하는 방식을 제시하여 Single Size의 성능보다 우수한 성능을 기록했다.
- 빠른 연산을 위한 새로운 적분 공간을 제시하며, 기존 영상 매칭 방식보다 훨씩 바른 속도와 성능을 보였다.
- Method
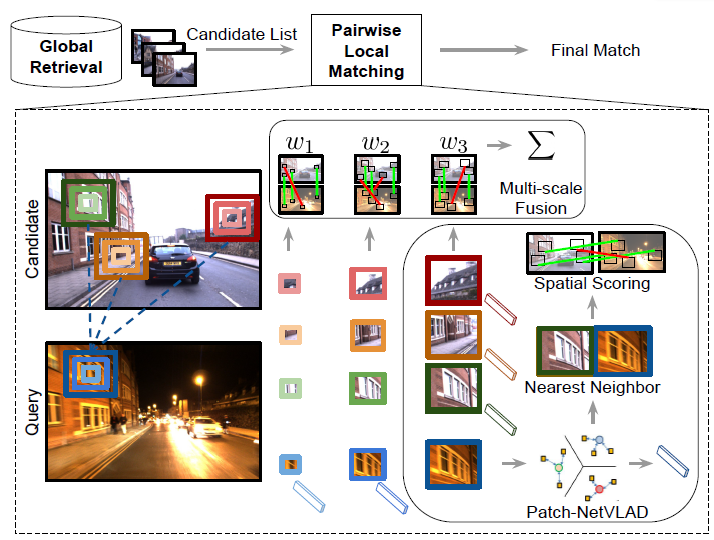
Patch-NetVLAD의 전체 파이프라인은 그림 3과 같다. 먼저 DataBase에서 Candidate List를 NetVLAD를 이용해 100장을 뽑은 후 ,제안하는 Patch-NetVLAD로 가장 유사한 영상을 찾는 Reranking 과정을 거쳐 최종적으로 Retrieval이 끝나게 된다.
1.2 Original NetVLAD
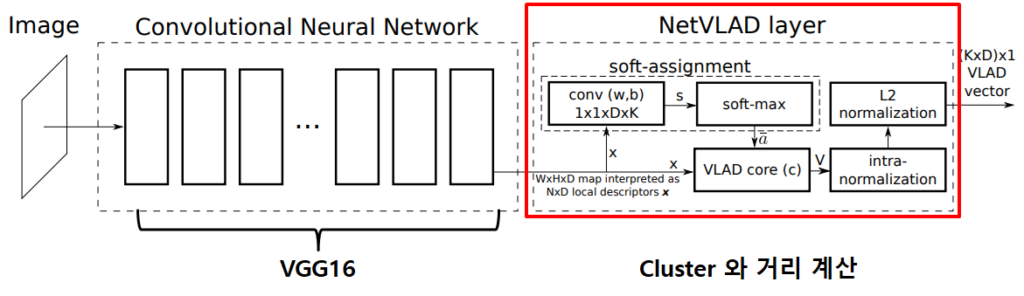
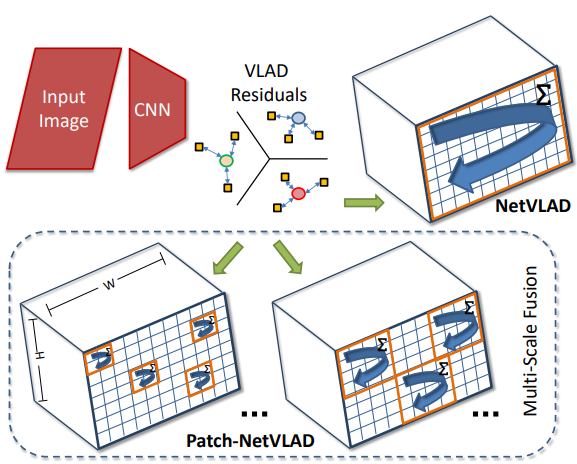
NetVLAD는 HandCraft 방식인 VLAD를 CNN 방식으로 바꾼 Global Descriptor로, 그림 4와 같이 Database를 대표하는 Cluster Center를 학습을 통해 학습한 후 그 Cluster Center와 영상의 CNN feature를 비교해서 하나의 vector로 나타낸 것으로 , Image Retrieval에서 베이스 방법론이라고 할 수 있겠다.
이 논무에서 제안하는 Patch – NetVLAD는 이 NetVLAD를 Local Patch를 대표하는 Descriptor로 사용해서 Image Pair를 Matching 할 때 사용하였다. 즉 그림 3과 같이 영상의 Local Patch에서 Multiscale의 NetVLAD를 뽑은 후 그것을 Local Descriptor로 한 후 KNNSearch를 이용해 두 Local Descriptor를 Matching 한 것이다.
1.2 Patch-level Global features
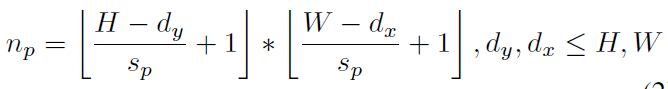
영상 전체에서 Patch를 Dense하게 식 1에서 계산되는 갯수 만큼 추출한다. Patch 의 모양은 실험으로 정사각혀이 가장 좋은 것을 확인했다 하며, 각 Patch 마다 전부 NetVLAD 를 추출한다. 추출한 NetVLAD 에 PCA를 적용하는 것이 성능과 속도 측면에서 모두 좋았다고 한다.
1.3 Mutual Nearest Neighbours
Np개의 NetVLAD patches를 얻은 후 Database영상과 사용자의 영상(Query)를 비교해서 쌍이 맞는 Patch를 찾기 위해서 Nearest Neighbor (NN)방식을 사용한다. 모든 패치간의 거리를 구한후 NN을 통해서 가장 가까운 패치를 Retrieval 하여 Patch간의 Matching을 진행한다. 그리고 각 Patch를 비교할때 Euclidean distance를 사용하고 이를 각 Matching의 Score로 사용한다.
1.4 Spatial Scoring
매칭을 한 후 두 이미지의 유사도 지수를 계산하기 위해서 두가지 계산을 제시한다. 첫번째는 속도는 좀 느려지지만 성능을 향상시키는 RANSAC 방식과 성능의 약간의 손실이 있지만 속도향상이 있는 공간 Scoreing 방식이다.
첫번째 RANSAC 방식은 매칭된 Patch를 RANSAC을 통해서 Inlier를 구하고 Inlier들의 Score를 더하고 Patch 갯수로 Normalize하여 Score를 계산한다.
두번째 방식은 매칭 없이 X방향과Y 방향으로 Patch들을 비교하여 성능을 Score를 내는 것이다. 물론 식안에 정의가 더욱들어 가있지만 생략하도록 한다.
1.5 Multiple Patch size
Patch Size를 다양하게 한 후 식 2 와 같이 각 다 다른 weight를 줘서 합친 것이 최종 Score가 된다.
2. Result
2.1 Implementation
영상 사이즈는 640 x 480으로 하고 , PatchSize는 2,5,8로 하고 각각 0.42,0.15,0.4의 Weight를 줬다고 한다.

데이터셋이 바뀌더라도 Patch NetVLAD의 성능이 가장 좋은 것을 볼 수 있다.

Multi RANSAC 이 가장 좋은 성능을 보인다.

SuperGlus 보다 Dimension이 큼에도 불구하고 속도가 모든 방법이 다 빠르면서, 성능은 더욱 좋은 것을 볼 수 있다.

Patch NetVLAD를 이용한 것이 옳은 Retrieval 결과를 뱉는 것을 볼 수 있다.
음… 리뷰 내용을 토대로 이해한 바로는 Path-NetVLAD는 end-to-end 방식이 아닌 걸로 보이고,
하나의 Place recognition 전략을 소개한 논문으로 보입니다. 제대로 이해한게 맞나요?
++ 해당 방법론의 속도에 대한 리포팅은 없나요? 영상을 패치(scale+window) 단위로 NetVLAD feature를 뽑고, 이를 이용해서 feature matching을 진행하면 엄청 느릴거라고 생각이 듭니다.
속도에 대한 리포팅은 위에 표 3 에 있습니다
뭐 Reranking 방식을 제안했다고 생각하면 쉬울거 같습니다