이번 리뷰는 CVPR2017에 소개된 Densenet에 대하여 리뷰하고자 합니다.
지난번 김지원 연구원님의 세미나를 통해 알게 되었으며 Segmentation 성능에 좋은 성능을 보인다고 하여 읽어보게 되었습니다.
Introduction
해당 논문은 기존 backbone network 들이 정확도를 위해 점점 깊어지면서 발생하는 문제들(Gradient Vanish, wash out 등)을 해결하고 싶었고 그래서 새로운 형태의 네트워크를 제안합니다.
DenseNet을 소개하기에 앞서, 먼저 기존 네트워크들의 문제점에 대해 간단히 알아보겠습니다.
기존의 네트워크들은 단순히 input이 layer들을 따라 순차적으로 통과하면서 학습을 하게 되며, 이는 layer가 자기 앞에 있는 layer의 feature 를 받고 뒤에 layer에 전달해주는 간단한 진행 방식입니다.
하지만 이 방식은 어떠한 feature를 학습하여 새로운 feature를 뒤에 layer에 전달해주긴 하지만, 앞단에 특징들이 잘 보존되기에는 부족함이 존재합니다.
이를 해결해주기 위해 Resnet은 앞단의 feature를 뒷단에 layer의 더해줌으로써, 앞단의 특징들을 잘 유지하고자 하였습니다.
하지만 Resnet은 각각의 layer들이 가져야만 하는 고유의 weight들이 존재하기 때문에, 학습해야할 파라미터들이 많이 존재합니다.
논문의 저자는, 앞단에 특징들이 잘 보존되면서, 동시에 학습해야할 파라미터의 수를 최소화하는 네트워크를 만들고자 하였고, 그렇게 만들어진 것이 DenseNet입니다.
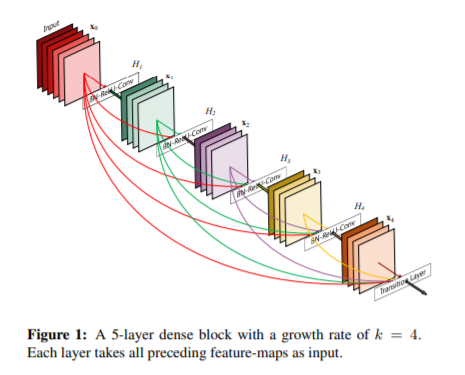
논문에서 제안하는 네트워크는 그림 1과 같이, L번째 feature map은 1~L-1번째 feature map들이 합쳐지는 형태를 하고 있으며, 이러한 연결 방식에 따라 이름을 DenseNet으로 이름지었다고 합니다.
DenseNet은 얼핏보면 Resnet과 유사하게 보일 수도 있지만, Resnet과 달리 해당 논문에서는 feature를 합칠 때 summation이 아닌 concatenating을 하는 특징을 가지고 있습니다.
이러한 feature combine 방식은 기존의 네트워크에 비해 더 적은 파라미터들을 사용할 수 있는 장점이 생기며, 그로 인하여 불필요한 feature map들을 재학습하는 것을 피할 수 있다고 합니다.
Resnet
보다 자세한 설명을 하기에 앞서, 간단히 용어에 대한 정리를 하고자 합니다.
- x_{0} : Single Image
- H_{\ell}(\dot) : non-linear transformation(e.g Batch Normalization, ReLU, Convolution)
- x_{\ell} : \ell^{th} layer의 output
먼저 Resnet은 전통적인 네트워크들과 동일하게 (\ell-1)^{th} 레이어에 non-linear 변환을 통하여 나온 결과값 x_{\ell-1}을 (\ell)^{th} 레이어의 입력으로 사용하였으며, skip-connection 기법을 통해 x_{\ell-1}를 더해주게 됩니다.
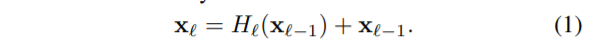
이러한 skip-connection 기법을 통해 ResNet은 gradient가 뒤에 레이어에서 앞단에 layer로 곧바로 전달될 수 있다는 장점이 존재합니다. 하지만 수식1과 같이 이후 결과와 입력을 더하는 연산을 통해 합치는 것은 네트워크가 순차적으로 흘러 학습하는데에는 방해가 된다고 합니다.
DenseNet
그래서 DenseNet에서는 레이어들 사이에 정보 흐름을 좀 더 향상시키기 위해, Resnet과는 다른 방식으로 레이어들을 연결하고자 합니다.
이는 위에 그림1과 함께 설명드렸다시피 앞단에 어느 레이어들로부터 자기 뒷단에 존재하는 모든 레이어들에게 바로 연결되게끔 하는 형태를 말합니다.
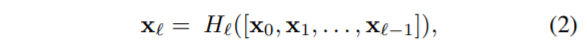
수식2는 DenseNet의 layer connect 방식을 수식으로 나타난 것으로, \ell^{th} 레이어는 그 이전에 모든 layer들(1~\ell -1)이 concat된 feature를 입력으로 합니다.
Pooling Layer
수식 2와 같이 앞단의 layer에서 나온 feature map들을 합쳐주기 위해서는 먼저 feature map들의 사이즈가 다 같아야만 하겠죠. 해당 논문에서는 최대한 down sampling을 용이하게 하기 위해서, 그림 2와 같은 구조로 네트워크를 구성하였습니다.
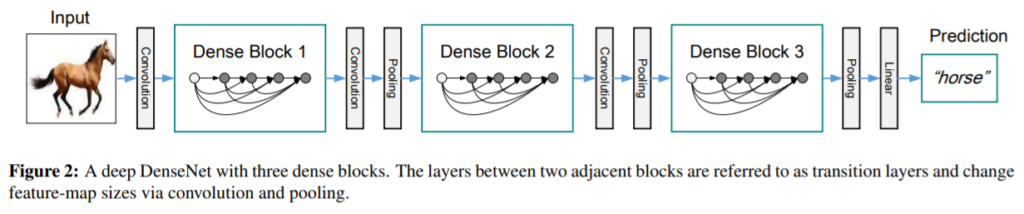
먼저 dense block들이 여러개 존재하며, 각각의 dense block들 사이에는 컨볼루션과 pooling으로 이루어진 transition layer들로 구성되어있습니다.
Growth rate
DenseNet은 기존 backbone Network와 달리 채널수가 매우 작아 상당히 좁은 형태로 이루어져있습니다.
만약 H_{\ell}가 k 개의 feature map들을 가지고 있다면, \ell^{th} 레이어는 k_{0} + k \times(\ell - 1) 채널의 입력 feature map을 가지게 됩니다. 여기서 k_{0}는 input layer의 채널 수를 의미합니다.
논문에서는 이 k를 하이퍼파라미터로 설정하며, 이 k 를 네트워크의 growth rate로 표현합니다. 해당 논문에서는 작은 growth rate만으로도 SOTA의 결과를 얻었다고 합니다.
이는 DenseNet의 가장 큰 특징인 연결방식 덕분에 각 레이어들이 자기 이전에 모든 feature map들에 대한 정보를 얻을 수 있었으며, 그러므로 네트워크의 집단지식?을 이끌었다고 합니다.
Feature map들을 네트워크의 전체적인(global) 상태로 볼 수 있으며, 이러한 관점에서 growth rate는 각 레이어들이 전체 네트워크 상태에 대하여 얼마나 많은 새 정보들을 기여하는지 제약을 거는 것으로 볼 수 있습니다.
한번 쓰여진 global state는 네트워크에 어디에서든지 사용될 수 있으며(concatenating을 통해) 이는 기존 backbone 방법론들이 레이어에서 레이어로 feature를 복제하는 방법에서 벗어나게 해주었습니다.
Experiments
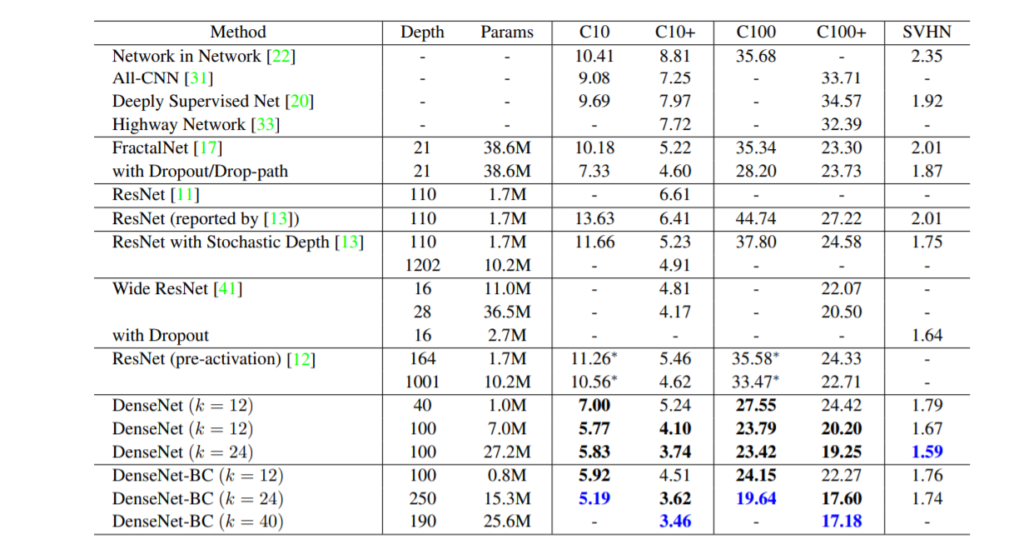
위에 표는 CIFAR와 SVHN 데이터 셋을 가지고 영상 분류를 수행한 정량적 결과표입니다. 보시면 DenseNet은 3.46이라는 error rate를 가지며 가장 좋은 성능을 내는 것으로 볼 수 있습니다.
파라미터 효율성 관점에서 보자면, DenseNet-BC (k=24)의 경우 파라미터 수가 Wid ResNet28과 FractalNet에 비하면 2배 이상 파라미터수가 적음에도 불구하고 성능이 더 우수한 것을 볼 수 있습니다.
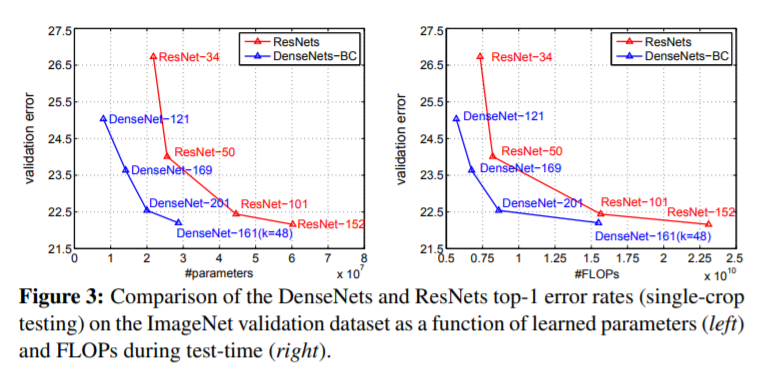
그림3은 ImageNet을 가지고 ResNet과 DenseNet을 비교한 그림입니다. 그림3의 좌측은 성능과 파라미터수의 관계를 나타낸 것으로, DenseNet이 ResNet에 비해 더 가벼우면서 성능도 좋은 것을 확인할 수 있습니다.
예시로 DenseNet 201과 Resnet-101은 서로 유사한 성능을 보이나, 파라미터 수가 각각 3\times10^{7}, 4.5\times10^{7}로 약 1.5배 차이가 납니다.