소개
본 논문은 Contrastive Learning 에서 유사성 최적화에 대한 새로운 관점을 소개한다. Contrastive Learning 은 Self-supervised learning에서 많이 사용되는 접근법으로 한국어로는 대조 학습이라 불리며 within-class(클리스 내) 요소간의 유사도는 높게, between-class(클래스 간) 요소간의 유사도는 낮게 측정되는 방향으로 학습을 진행하는 것이다.
본 논문에서 클래스 내 유사도를 Sp 클래스 간 유사도를 Sn라 할때 대부분의 contrastive learning의 loss 함수가 (Sn – Sp)를 최소화 하는 방향으로 최적화를 한다고 정의를 하였으며, 다음의 최적화 방식에서 발행하는 문제를 정의하였다.
정의한 문제점은 다음과 같다.
1. corner cases 문제
단순히 (Sn-Sp) 를 최소화 하는 방향은 각 요소의 상태를 반영하지 못한다는 단점이 있다. 가장 극적으로는 Sp 는 아직 최대화되지 못했지만, Sn은 이미 0으로 수렴하여, 학습 전체의 로스가 어느정도 최적화 된 상황을 들 수 있다.
2. 모호한 상태 문제
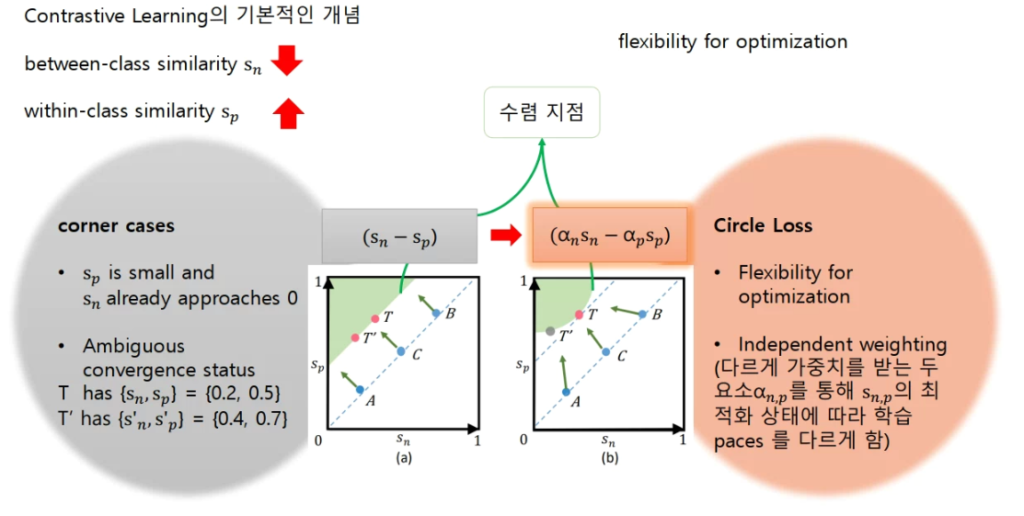
(Sn-Sp)는 요소의 상태를 반영하지 못한 두 요소간의 차를 이용하는 최적화 방식으로 실제 두 요소의 상태를 반영하지 못하고, 두 상태의 차이로 인해 같은 상태로 인식될 수 있다는 점이다.
이는 그림2의 (a)와 같은 학습 진행방향을 보인다. 즉, (a)의 어떤 상태(A, B, C)든 같은 방향으로 학습하여 원하지 않는 학습의 방향으로 수렴할 수 있다는 뜻이다. 그림의 초록색 영역이 수렴 상태를 뜻하며, (a)의 수렴상태는 Sn-Sp 상태는 같으나, 각 요소에 따라 수렴의 상태가 동일하다 할 수 없는 영역이 같은 수렴상태로 여겨지고 있다. 본 논문에서는 이러한 수렴 영역을 (b) 와 같은 원형의 경계라인으로 바꾸기 위해 각 요소(Sn, Sp)의 수렴상태를 반영하는 파라미터를 도입하여 문제를 해결하였다. 그림 2의 (b)를 통해 이러한 학습 방식이 기존의 방식보다 납득 가능함을 알 수 있다. (그림 b의 A 점은 Sn은 0에 가깝게 수렴한 반면에, Sp는 비교적 1에 가깝게 수렴되지 못하였다. 이러한 각 요소의 최적화 상태를 반영하여 Sp에 대한 최적화를 포기하는 (a)의 A 학습 방향과 달리, Sp에 강한 가중치를 주어 T’의 방향으로 학습을 진행한다.)
수식
각 상태를 반영하는 Circle Loss의 식은 다음과 같다.
수식 1은 본 논문에서 기존의 다른 Contrastive Learning 의 Loss를 표현한 식이고, 수식 2가 제안하는 Circle Loss 식이다. 간결하게 표현하면 그림2에 보인것처럼 {(αn)(Sn) − (αp)(Sp)}와 같다. 직관적으로 α 변수를 통해 각 요소에 자신의 수렴상태를 반영하여 가중치를 조절하는 것이다.
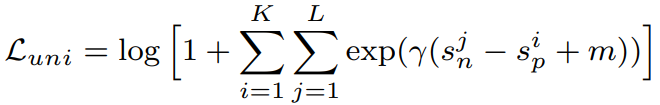
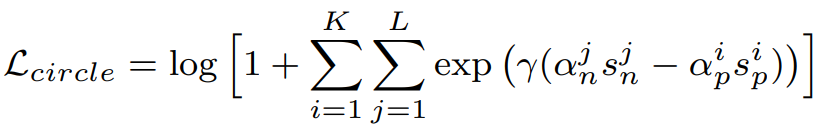
이때 α 함수는 수식 3과 같이 정의된다. 본 요소 α 를 통해 요소 S가 최적화값에서 크게 벗어날수록 학습에 큰 가중치를 받도록 한다. 수식 3에서 []+는 “cut-off at zero” 필터를 뜻하며 O는 최적화 값이다. (Op는 Sp의 maximize값인 1, On은 Sn의 minimize 값인 0이며 각 값은 마진을 설정할 수 있다. Op=1+m, On=-m, m은 마진 값)
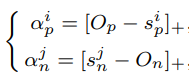
제안하는 로스의 구현이 간단한 만큼 다양한 코드가 공개되어 있어 사용이 편리하므로 필요할때 꼭 사용해 보기를 추천드린다.
실험
논문에서는 다양한 실험을 진행하였다. 본 논문에서는 실험에 대해 크게 두가지로 나누었으며 (class level labels, pair-wise labels) 세가지 테스크의 실험을 진행하였다. ( face recognition (class-level), person re-identification (class-level) , fine-grained image retrieval (pairwise-level) )
- face recognition
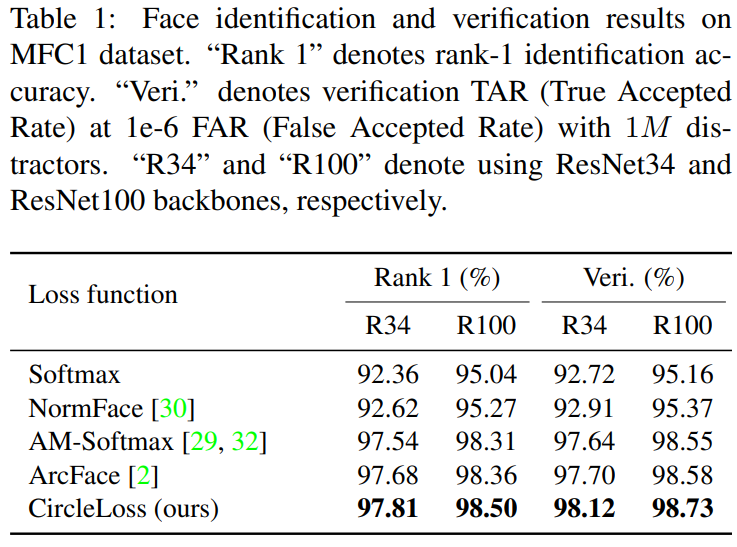
본 실험은 유명한 데이터셋인 MS-Celeb-1M를 통해 모델을 학습하였으며, MegaFace Challenge 1 dataset (MFC1) 으로 테스트한 성능을 보였다. class level label을 이용한다. 실험 파라미터로 스케일 파라미터 γ 은 256 , 마진 파라미터 m 은 0.25 을 사용하였다.
- person re-identification
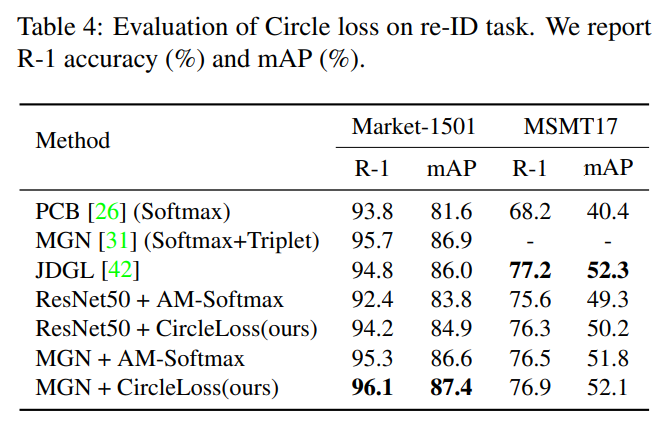
본 실험은 다른 관점, 관찰상황에서 같은 사람을 발견하는 것을 목표로 하는 실험으로 face recognition과 같이 class level label을 이용한다. 실험으로는 유명한 데이터셋인 Market-1501, MSMT17 를 사용하였다. 실험 파라미터로 스케일 파라미터 γ 은 256 , 마진 파라미터 m 은 0.25 을 사용하였다.
- fine-grained image retrieval
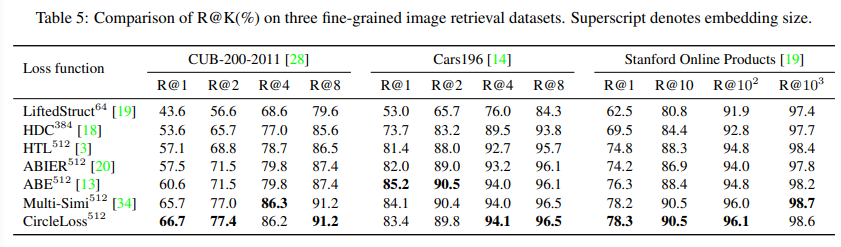
본 실험은 세분화된 이미지 검색 실험으로 유사해 보이는 클래스간의 retrieval task를 통해 circle loss의 작동을 더욱 잘 검증한다. 데이터셋으로는 다양한 새를 분류하는 CUB200-2011 , 다양한 차를 분류하는 Cars196 와 다양한 물품을 포함하는 Stanford Online Products 데이터셋을 사용하였다. 실험 파라미터로 스케일 파라미터 γ 은 80 , 마진 파라미터 m 은 0.4 을 사용하였다.
사과의 말
지난번 세미나시 완벽하지 못한 이해로 발표를 부드럽게 하지 못한점 다시한번 죄송함을 전합니다.
저번 세미나를 통해서 해당 contrastive loss를 이용한다면 같은 장소지만 조도 변화와 씬의 변화가 있는 곳을 within-class로 다른 장소를 between-class로 하여 차별성을 가질 수 있다고 생각하여 큰 감명을 받았습니다. 좋은 논문 발표해주셔서 감사드립니다.
해당 리뷰에 Sn과 Sp, O값을 구하는 방법에 대해 적혀있지 않아 논문에서는 어떻게 구하는지 궁금하네요. 논문에 기술되어 있다면 답변 부탁드립니다.
Sp는 클래스 내 유사도를 Sn은 클래스 간 유사도를 나타내며, 사용하시는 방법론에 다양하게 적용 가능합니다. 또한 Op는 1, On은 0으로 정의되며 튜닝 변수인 마진값 m에 따라 Op=1+m, On=-m로 정의할 수 있습니다. 감사합니다
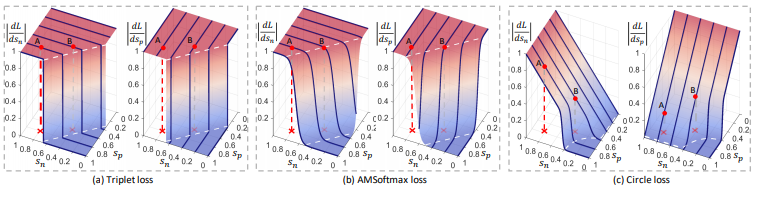
그림 1에 대한 설명을 이해하지 못하였는데 파라미터의 상태를 고려하는 것이라 하면 어떤 것을 의미할까요? 모멘텀을 계산한다고 생각하면 될까요??
Sn, Sp파라미터에 따라 loss로 인한 변화율이 다르다는 의미로, 그림을 보시면, (a), (b)는 미분 변수에 따라 변화율이 변하지 않지만, (c)는 미분 변수에 따라 변화율이 크게 다름을 확인할 수 있습니다!