

이번 리뷰에서 다룰 논문은 Video-to-video retrieval 연구를 하면서 video의 특성에 대해 재고할 기회를 준 “What Makes a Video a Video” 입니다. 이 논문은 이전 황유진 연구원이 X-리뷰에서 한번 다룬 적이 있으나 저에게 중요하다고 생각되는 논문이라 스스로 정리하는 차원에서 작성하게 되었습니다.
최근 Video와 관련된 연구들은 frame 간의 motion 정보를 모델링하는 것을 목표로 두고 있습니다. 그러나 이는 매우 쉽지 않았기에 본 논문의 저자는 과연 Video의 여러 task 중 특히 action recognition에서 motion 정보가 얼만큼 중요할까라는 것에 대해 질문을 던졌고 이를 확인하기 위한 실험들을 진행하였습니다.
1. Class-Agnostic Temporal Generator
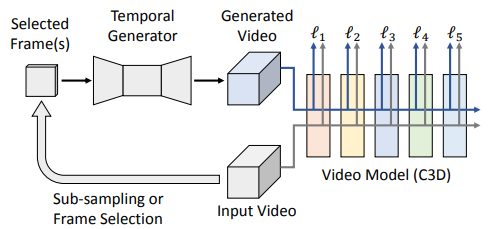
Video motion 정보의 중요성을 판단하기 위해 두 가지의 framework를 제안하였습니다. 그 중 하나는 Class-Agnostic Temporal Generator 입니다. 여기서 Class-Agnostic 이라는 뜻은 ‘물체의 종류를 모르는’ 이며, 주로 Object detection 분야에서 Objectness 만을 판단할 때 사용되는 단어입니다.
Action recognition 분야에서는 이를 위한 모델을 학습시킬 때 Video 에서 일정 frame을 추출하고 (주로 16 frame), 이를 입력으로 class에 대한 label을 주어 임의의 모델을 학습시키곤 합니다. 16 frame은 UCF101이나 Kinetics 같이 평균 길이가 10초 이내인 Video dataset에서는 frame 간의 motion 정보를 얻어내기 충분한 양이며, 여기서 얻은 결과에는 Temporal 정보와 Spatial 정보가 entangle되어 있게 됩니다. 이러한 결과에서 motion 정보의 효과를 확인하고자 Class-Agnostic Temporal Generator에서는 16 frame 중 일부 frame을 sub-sampling 하여 입력으로 사용하여 C3D를 학습하였을 때의 성능을 비교하였습니다. 그리고 Sub-sampling된 frame을 사용할 시 입력의 개수를 맞춰주기 위해 CycleGAN의 generator를 확장시켜 사용하며, Generator로 만든 synthesized video가 sub-sampling 된 frame으로 제거된 motion 정보를 보완하기 위한 frame 생성을 위해, Generated Video와 기존 Video를 입력으로 각각 사용할 때의 비슷한 feature representation을 돕는 Perceptual Loss로 Generator를 학습시킵니다. 이는 Convolution layer에서 높은 invariance를 지니는 high-level feature의 특성에서 영감을 받았으며, Fig 3에서 이를 정성적으로 나타냅니다. 그리고 Perceptual Loss를 사용하여 sub-sampling 된 frame로 synthesized video를 만드는 generator를 학습시키기에 해당 video에 대한 class는 따로 제공되지 않으며 이와 같은 이유로 Class-Agnostic Temporal Generator라고 불리웁니다.

2. Motion-Invariant Frame
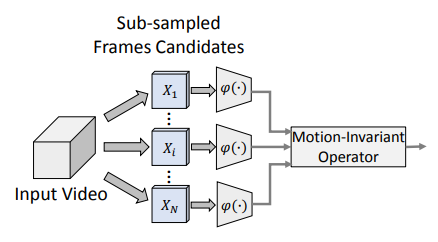
본 논문의 주된 질문인 Action recognition에서 motion 정보가 얼마나 중요할까에 대해 이전 framework에서는 motion 정보가 제거되어 sub-sampling된 frame으로 synthesized video를 만들었을 때 어느정도까지 손실된 정보를 대체할 수 있을지에 대해 다루어 motion 정보의 중요성에 답변하려고 했다면, 이번에는 frame의 품질이 전체에 어떤 성능을 미치는지에 대해 다룹니다. 만약 motion 정보보다 frame의 품질이 중요하다면 입력으로 굳이 motion 정보를 담기 위해 여러 frame을 추출하는 것이 아닌 특정 높은 품질의 frame을 추출하면 좋은 성능을 얻을 수 있습니다. 또한 본 framework에서 높은 품질의 frame이라하면, 현재 주된 질문에 답을 하기 위해 추가적인 motion 정보가 필요하지 않는 motion-invariant 한 frame을 의미하기 때문에 frame selector가 이와 같은 frame을 뽑는 두가지 방식을 제안합니다.
- Max Response
이 방식은 모든 n개의 frame에서 response function을 통과 시키고 나온 class에 대한 확률분포 중 가장 큰 값을 나타낸 class를 찾고, 이 n개의 값들 중 가장 큰 값을 가지고 있는 frame을 하나 선정해 motion-invariant frame으로 학습하는 것입니다. 이를 통해 이상적으로는 가장 높은 값을 가지는 frame이 좀 더 그에 해당하는 class를 나타내도록 response function을 학습할 수 있게 됩니다.
- Oracle
이 방식은 Max Response와 비슷하게 response function을 학습시키나 Ground Truth를 제공한다는 점에서 차이가 있습니다. n개 frame의 확률분 포중 가장 큰 값을 나타낸 class를 찾았을 때 그 class가 해당 video와 같은 class를 갖는다면 motion-invariant한 frame으로 선정하는 방식으로 평가 시에도 Ground Truth가 필요하기에 Cheating을 수반한 방식입니다. 이와 같이 Cheating임에도 불구하고 frame selector의 upper bound를 보일 수 있기에 유의미한 방법론 입니다.
3. Experiments
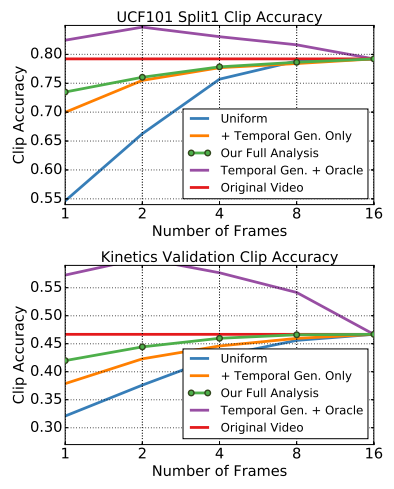
Fig 5에서 Original video는 기존 방식으로 16개의 frame으로 C3D를 평가한 것을 의미하며, Uniform은 이들을 Uniform하게 sub-sampling만 하여 보인 성능을 의미합니다. 단순 motion 정보를 제거한 Uniform의 결과를 Original video와 비교하였을 때 sub-sampling한 frame의 수가 줄어듬에 따라 성능 하락 폭이 큰 것을 보이며, 이를 통해 motion 정보는 성능에 꽤 큰 영향을 주고 있음을 확인할 수 있습니다. 그러나 Temporal Gen. Only 를 통해 Class-Agnostic Temporal Generator를 활용하여 motion 정보의 보완이 이루어진다면 성능 하락 폭이 각각 UCF101 : 35%->10%, Kinetics : 15%->9% 로 줄일 수 있음을 확인할 수 있습니다. 또한, Class-Agnostic Temporal Generator 을 사용하기 위한 sub-sampling 시, motion-invariant한 frame을 뽑기 위해 Max Response 방법론을 추가하여 사용했을 때, Our Full Analysis에서 확인할 수 있듯이 성능 하락 폭이 좀 더 줄어 motion 정보를 대부분 대체할 수 있음을 알 수 있습니다. 그리고 Temporal Gen.+Oracle의 성능이 Original Video의 성능을 뛰어넘은 것을 통해 이상적인 상황에서 frame selection이 이루어진다면 motion 정보는 대체될 수 있음을 보이며, 앞으로 keyframe selection 연구에 대한 중요성 또한 시사합니다.
4. Reference
[1] http://ai.stanford.edu/~dahuang/papers/cvpr18-fb.pdf