소개글
안녕하세요. 이번 주 3D Object detection(OD) 관련 논문을 가지고 왔습니다. 복잡한 내용이었지만, 논문이 짜임새있고 자세하게 서술되어있어서 이해하는데 많은 도움이 되었습니다. 코드또한 해당깃허브에 친절히 공개 해두어서 기회가 되면 실습을 해보고 싶습니다.
해당 논문은 제목에서 알 수 있듯이, weekly supervise 3D OD에 관한 내용입니다. 3D OD는 내용도 어렵고 공개된 코드등, 학습자료도 2D에 비해 많이 없습니다. 그런 의미에서 해당논문과 코드는 상당히 학습 할만한 가치가 있습니다.
배경
먼저 weekly supervised라는 의미를 생각해봅시다. Weekly supervised가 supervised에 비해 좋은점들은 무엇일까요? Supervised 방법을 택하는 순간 GT label이 필요합니다. 항상 데이터셋과 그에 해당하는 GT값들이 주어지면 참 좋겠지만, 새로운 데이터셋을 구축해야하는 상황에서 GT 값을 만들기위해 annotation을 하는 과정은 labour-intensive and time-consuming 합니다. 특히나 3D OD에서는 그 기회비용이 2D에 비해 비교안될 정도로 큽니다. 그렇기 때문에 해당 논문에서는 GT bounding box가 필요없는 Weekly supervised 방법을 제안합니다.
논문에 의하면 GT bounding box없이 3D OD를 하기 위해서는 어려운점이 크게 2가지 존재합니다.
- Unstructured 포인트클라우드로 부터 3D object proposal를 생성하는 방법
- 3D bounding box를 예측하기위해 3D object proposal을 classify & refine하는 방법
우선, 첫번째 문제를 해결하기위해 저자는 unsupervised 3D object proposal modul(UPM)을 정의합니다. UPM에서는 Point cloud density를 기반으로 물체가 있는지 없는지 우선 판단합니다. 그런데 여기서 문제가 있습니다. Point cloud density는 scanner의 distance에 영향을 많이 받습니다. 따라서 해당 논문에서는 normalized point cloud density를 object가 있는지 없는지에 대한 판단지표로 사용합니다. (Density를 계산하는 방법에대해서는 아래에서 다시 다루겠습니다. 우선은 이해위주로 전체적인 맥락을 먼저 설명하겠습니다.)
두번째 문제를 해결하기 위해 저자는 cross-modal transfer learning 방법을 사용합니다. 해당 방법에서는 포인트클라우드기반 detection network는 student가 되고 image recognition task를 위해 pre-trained된 network가 teacher이 됩니다. 아래 그림과 함께 설명을 이어가겠습니다.
파이프라인
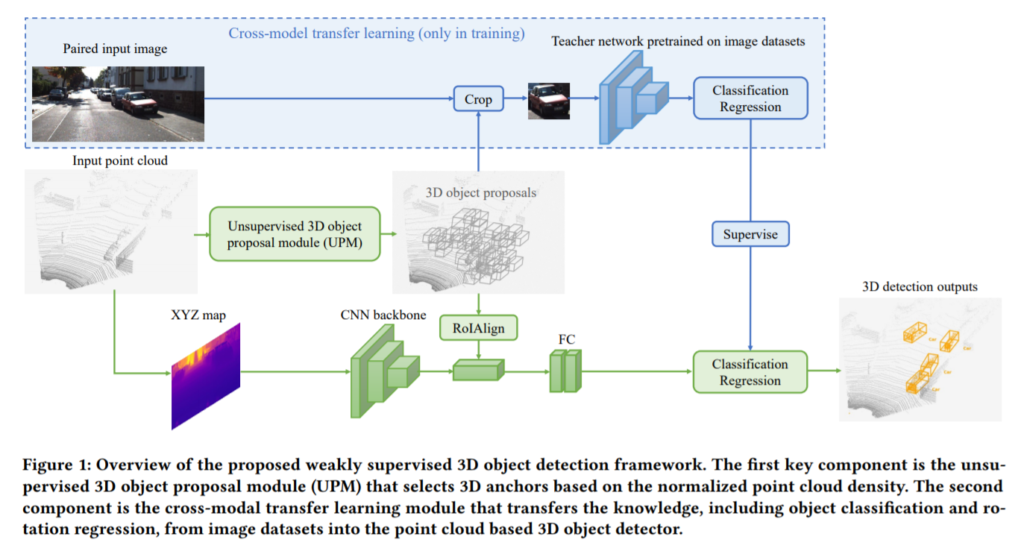
전체적인 파이프라인입니다. 위에 파란영역이 cross-model transfer learning 부분입니다. 해당 부분은 training을 할때만 사용됩니다. input image를 보시면 training할 때는 paired input image이고, test을 할때는 point cloud만을 사용하는 것을 볼 수 있습니다. 여기서 paired input image란 point cloud와 RGB이미지의 pair을 의미합니다. 즉, 라이다 센서로 측정된 point cloud와 카메라로 측정된 RGB데이터를 동시에 사용하겠단 의미입니다.
Teacher network를 매개체로 사용함으로써, RGB 도메인을 포인트클라우드 도메인으로 바꿉니다. 이를통해 annotation없이 3D OD를 수행하게됩니다. 그러나 항상 teacher network가 student를 잘 학습시키는 것은 아닙니다. 해당 이유에 대해서는 아래에서 다시 다루겠습니다.
위와같은 파이프라인을 이용하여 KITTI 데이터셋에 대해 실험을 진행하였으며, 논문의 주 contribution은 다음과 같습니다.
- 제안된 방법인 UPM을 활용하여 anchor를 할당한다. 이때, 물체와 라이다센서의 distance에 강인하기 위해 제안된 normalized point cloud density를 사용
- 2D를 3D 도메인으로 효과적으로 바꿈으로써, GT bounding box없이 3D object detector을 학습 (아래 cross modal transfer learning method에서 다시설명)
- 포인트클라우드 데이터를 이용한 weekly supervised learning의 OD를 처음으로 가능하게 함. 또한, 다양한 실험을 통해 해당 방법론의 효용성을 입증
Normalize & Density
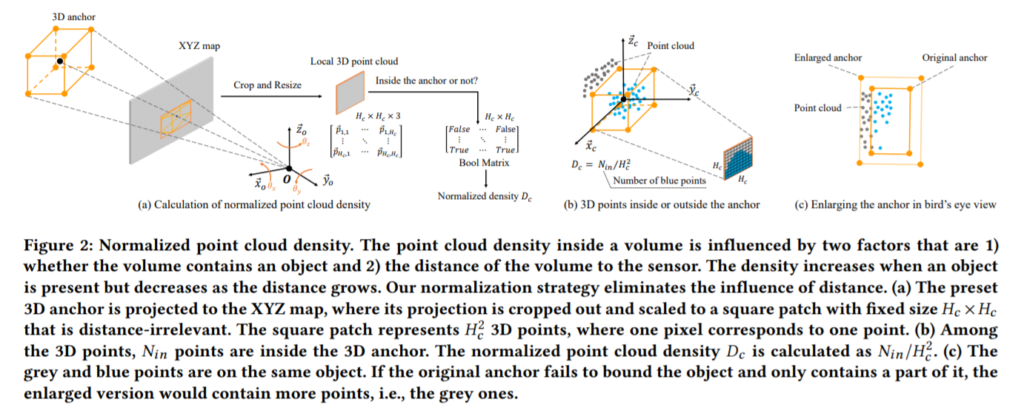
위에서 언급했듯이 해당 논문에서는 sensor와 object사이의 distance에 강인한 density를 얻기위해 normalized point cloud density를 사용하였습니다. Point cloud를 normalize하는 전략에 대한 설명을 해보겠습니다. 위의 그림을 보시면 맨 왼쪽에 3D anchor로부터의 point cloud가 있습니다. 이를 front-view XYZ 평면에 mapping시킵니다. 이때 매핑된 한개한개의 픽셀은 x,y,z 정보를 담고있습니다. 이렇게 매핑을 시키면 3D box는 2D box로 변하게 됩니다. (b)그림처럼 해당부분을 crop하고 H_c*H_c 크기로 resize해주게되면 interpolation에 의해 모두 같은 크기로 resize되었기 때문에 distance에 강인해집니다. 이때의 density D_c = N_in/(H_C)^2 (N_in은 앵커박스안의 포인트클라우드 갯수) 로 정의되며 해당 density가 일정 threshold 이상이면 boolean 형태로 object가 있다고 판단합니다. 이때 주의해야할점은 N_in은 지면과 맞닿고 있는 points는 포함하지 않는다는점 입니다. 해당부분은 RANSAC방법을 사용하여 outlier로 취급하여 제거합니다.
앵커박스내의 Point cloud density가 일정 threshold 이상이면 positive, 이하이면 negative로 분류합니다. 앵커박스가 negative가 되면 romoved되고 positive인 앵커박스중에서 또 다시 선별과정을 거칩니다. Figure2 (c) 그림에 나와있듯 앵커박스를 입실론배만큼 확대한다음 확대된 앵커박스와 기존앵커박스 사이에 있는 points를 셉니다. 만약 해당영역에 points들이 많이들어가면 앵커박스의 alignment가 정확하게 맞지 않음을 뜻합니다. alignment를 맞추기위해 x, y, z 축으로 조금씩 이동해가며 해당과정을 반복합니다. 이때, 만약 입실론이 너무 크면 다른 오브젝트의 points를 포함할 가능성이 있기 때문에 적절한값을 정해주어야합니다.
Cross modal transfer learning method
다음으로 이야기해볼 주제는 cross modal transfer learning method입니다. 먼저 이 논문의 contribution을 생각해보면 2D이미지에 대한 정보를 3D 도메인으로 전달한다. 라는 내용이 있었습니다. 이를 좀 더 자세히 설명하자면, training할때 RGB영역에서 2D bounding box로 label되어있는 GT이미지를 point cloud영역의 3D bounding box로 바꾸어주는 것입니다. 해당 과정을 거치면 test할때는 point cloud정보만 입력하면 되게 됩니다. 이를 통해 3D bounding box를 일일히 다 annotation하는 수고를 덜 수 있습니다.
Teacher network는 PASCAL VOC, ImageNet에서 pre-trained된 VGG16기반의 모델을 사용하였습니다. 해당 모델은 image recognition하고 view point regression에 사용됩니다. 1개의 image를 input으로 받고, 해당 이미지를 사전에 정의한 label혹은 background로 labeling하게 됩니다. 그리고 그와 동시에 물체의 view point를 regression하게 되는데 이때 rotation을 사용합니다. 16개의 bins를 만들고 rotation에 따라서 해당 bins로 classification하는 multi-bin classification으로 view point를 정하게됩니다.

위에서 density는 연속적인 실수임에 비해 물체는 boolean타입으로 검출이 되므로 문제가 생길 수 있다고 했습니다. Teacher network가 confident 할때는 주로 별 문제가 되지 않지만, (a) 그래프에서 confusion zone에 해당하면 문제가 발생할 수 있습니다. 쉽게 말해서, teacher가 student한테 잘못된 지식을 학습시키게 되는셈 입니다. 그래서 해당논문에서는 confusion zone에 해당될 때에는 0과 1로 구분되는 boolean type의 label이 아닌 soft label을 정의하여 사용합니다. 그리고 이를 최적화 하기 위해 rectified cross entropy loss를 사용합니다.
평가
Implementation을 하는 과정에서의 frameworks는 tensorflow를 사용하였으며 해당 링크에 공개되어있습니다.
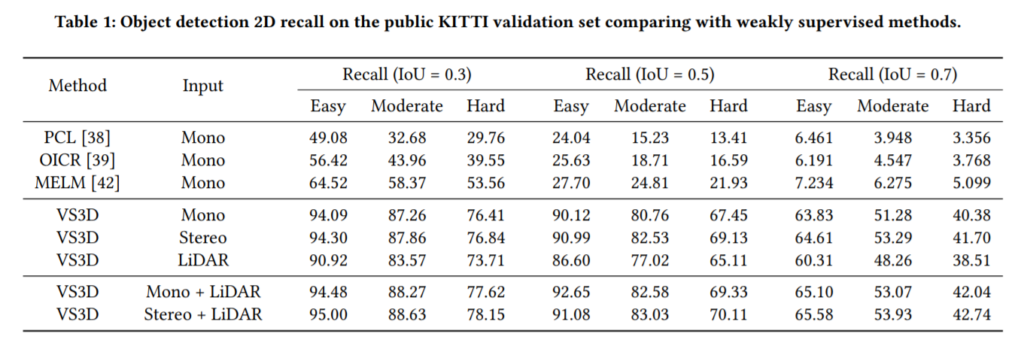
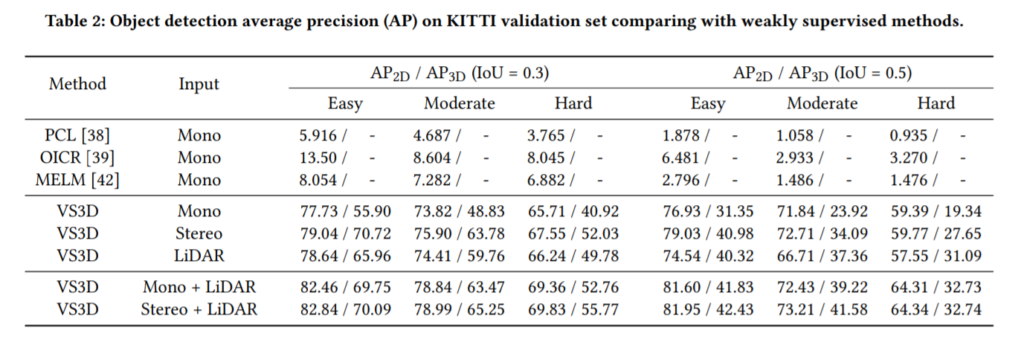
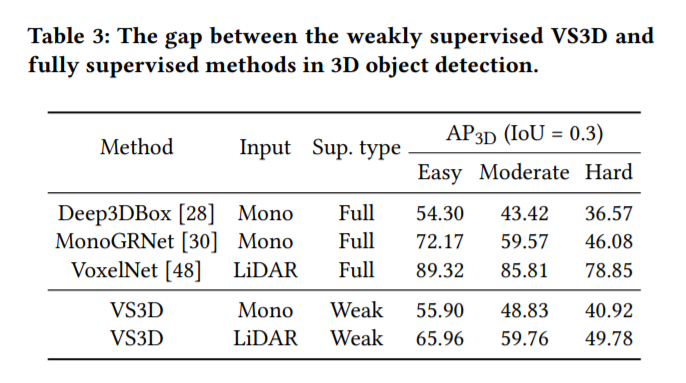
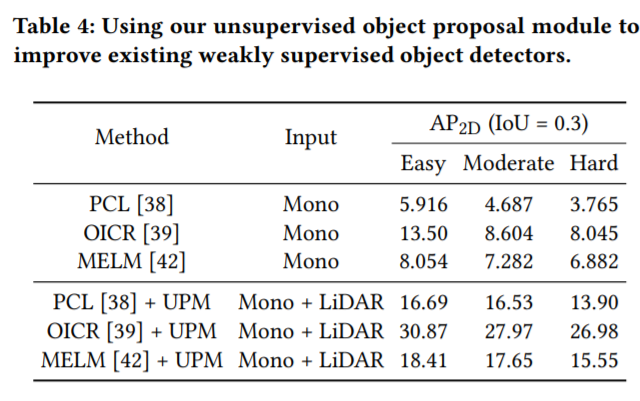
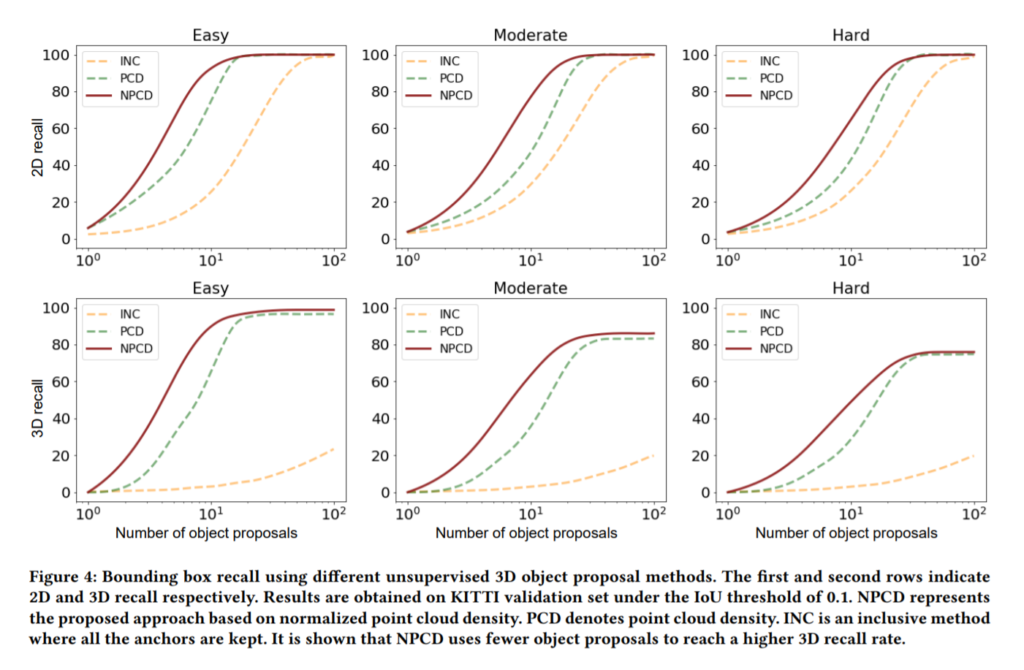
실험은 KITTI 데이터셋에 대한 결과입니다. 가벼운 마음으로 읽어보시면 좋을거같습니다.

이제 리뷰를 마치기 전에 해당내용들을 잘 이해했는지 자기점검용으로 간단한 퀴즈를 내보겠습니다. 댓글로 퀴즈에대한 답을 달아도되고 내용에 대한 질문을 하셔도 됩니다. (딱히 질문이 없는 분들과 제대로 이해했는지 확인해보고 싶으신 분들을위해 준비했습니다.)
- 해당 논문에서 제안하는 weekly supervision 방법이 supervision에 비해 가지는 이점은? (Hint: annotation)
- 해당 논문에서의 contribution중 한개는 2D 정보를 3D 도메인으로 전달하는 것이다. 원문을 살펴보면 “An effective approach to transferring knowledge from 2D images to 3D domain, which makes it possible to train 3D object detectors on unlabeled point clouds. ” 라고 언급되어 있는데 해당 내용이 의미하는바는? (Hint: bounding box)
- 파이프라인을 보면 RoI align 모듈이 있다. RoI align을 하기위해 논문에서 사용한 방법론을 설명하시오. (Hint: enlarge, 입실론)
- Teacher network는 classification과 viewpoint regression을 해준다. 이 때, view point regression은rotation에 대하여 “multi-ㅁ” 에 대한 classification으로 해결한다. ㅁ안에 들어갈 말은? (Hint: unit circle )
- Teacher network가 object가 있는지 여부를 판단할때 confusion zone이 생성되는 이유는? (Hint: boolean)
- 5번 문제에서 생성된 confusion zone을 student에게 그대로 학습시키면 성능저하를 초래할 수 있다. 따라서 논문저자가 제안한 confusion zone에 대한 처리방법을 서술하시오? (Hint: soft label)
논문리뷰 감사합니다. 해당 방법론의 한계로는 density기반으로 proposal을 얻다보니 3D박스를 잘 표현하지 못할것 같습니다. 그래서 실제 해당 논문의 지표도 iou가 0.3을 기준으로 나타내고 있지 않을까하는 생각이 듭니다. 따로 정확한 3D박스를 예측하기 내용이 있나요..?
density기반으로 proposal을 얻은다음 align을 진행하여 세부 수정하는 과정을 거치게됩니다. IoU가 높은건지 낮은건지는 OD 논문 리뷰가 처음이라 감이 잘 안잡히는데요. 일반적으로 3D OD에서 IoU가 더 낮은거 같습니다. 또한 IoU를 높게 설정하고 실험을 하면 라이다 센서기반이 더 성능이 잘 나온다고는 논문에 명시되어있습니다. 정확한 3D 박스 예측이란 표현이 너무 모호하네요. 충분한 답변이 되었는지 모르겠습니다.
좋은 글 감사합니다.
제가 알던 Teacher와 student model은 두 모델이 동일한 output을 내어 GT뿐만 아니라 teacher output과 student output의 차이를 loss로 추가하여 학습하는 것만을 알고 있었는데, 해당 방법론과 같이 label 형식으로 제공하여 학습에 사용할 수도 있겠군요.
지식이 +1 늘었습니다. 감사합니다.
도움이 되셨다면 다행입니다!
리뷰 감사합니다! Cross modal transfer learning method의 figure 3 (a) 에서 x축이 물체의 유무를 판단하는 score, y축이 density 정도라면 c와 같은 경향을 가져야 할 것 같은데, Probabilistic density는 다른 의미를 갖나요?
1. 비용이 비싼 3D annotation을 진행하지 않아도 됨
2. cross model transfer learning을 통해 2D bounding box로 3D model을 학습한다
3. mapping 후, 해당하는 point 수가 threshold 이상이면 positive 이하면 negative 판별, 이 후 positive를 입실론 배 확대하여 해당하는 point 수를 이용하여 ROI 수정
4. bin
5. 물체가 있고 없음은 이산적인 label이나 이를 평가할 때 사용되는 데이터는 연속적인 값인 density 이기 때문
6. soft label을 정의하여 사용 (이 때 soft label이 figure c의 (c)와 같은 label인가요? )
먼저 figure 3 (a) 에서 confusion zone이 발생하는 이유는 일정 threshold 기준으로 1 혹은 0으로 라벨링 하기 때문입니다. x축이 0과 가까우면 물체가없다. 1에 가까우면 물체가 있다 이구요. density가 높은 구간은 1로 라벨링하고 낮은구간은 0으로 라벨링하게 됩니다. 그러나 density가 애매모호한 구간에서는 probability 값이 낮기 때문에 그래프내의 confusion zone이 생깁니다. 따라서 그래프개형이 (a)처럼 나옵니다. (c)는 (b)처럼 라벨링을 1과 0으로 하는것이 아닌 soft label을 사용하여 라벨링하는것입니다.
먼저 퀴즈는 전부 다 정답입니다.(짝짝) 6번 퀴즈 질문에 대한 답을 드리자면, 네 맞습니다. soft label이 (c) 상의 s^입니다. s는 hard label(0과 1)이 되구요.