이번 리뷰는 저가 한번도 다뤄보지 않은 주제인 Human Pose Estimation 관련 논문에 대해서 작성해보고자 합니다.
해당 분야에 대해 다른사람의 리뷰는 종종 보았지만 직접 읽고 리뷰하는 것은 처음이라 제 공부겸 차근차근 정리하고자 합니다.
Human Pose Estimation
먼저 human pose estimation이란 사람의 관절을 찾아 Tracking하는 task를 말합니다. 해당 task 역시 다른 여러 컴퓨터 비전 task처럼 최근에 CNN을 통한 딥러닝 기반으로 수행이 가능합니다.
하지만 해당 분야의 연구는 대부분 성능을 높이기 위한 모델 및 방법론들을 제시하다보니 실용적인 부분은 많이 밀려나있다고 합니다. 우리가 흔히 알고 있는 모델의 정확성과 inference의 속도 간 trade-off 관계를 의미하겠죠.
최근에 모델의 효율성 측면에 대해서 많이 이슈가 되고 있고, 이를 해결하고자 여러 논문 및 방법론들이 제안되고 있는데, 제가 이번에 리뷰할 논문도 이러한 관점에서 나온 논문입니다.
Introduction
이 논문에서 하고자하는 것은 위에서도 설명드렸다시피 inference의 속도를 빠르게 하여 실제 효율성은 높이면서 성능은 유지하거나 더 높이고자 하는 것입니다.
이를 위해 해당 논문에서는 총 세가지로 파트로 나누어 설명합니다.
- Lightweight Hourglass Network
- Pretrained Teacher Network
- Pose Knowledge Distillation
그럼 하나하나 알아보도록 하겠습니다.
Lightweight Hourglass Network
먼저 Hourglass Network란 무엇일까요? 해당 네트워크는 Segmentation, Depth Estimation, Optical Flow 등 주로 pixel level에서의 predict을 목적으로 한 task에서 많이 나오는 네트워크 구조입니다.
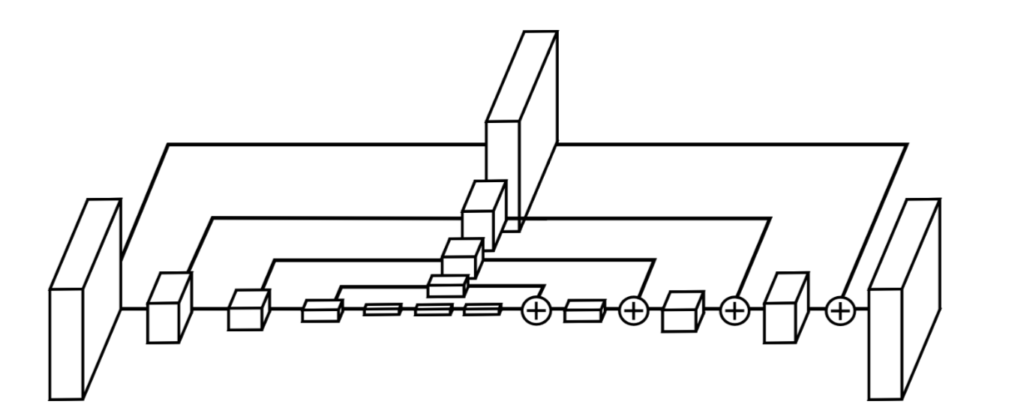
보시다시ㅣ feature map이 점점 줄어들었다가 다시 커지는 모습을 볼 수 있으며 이 모습이 마치 모래시계같다고 해서 hourglass network라고 부릅니다.
feature의 사이즈가 점점 줄어드는 것은 CNN을 통하여 feature가 extract되는 것이며 이러한 feature를 다시 원래의 input size만큼 늘리기 위하여 interpolation을 합니다.
그리고 upsampling할 때 손실된 정보를 보완해주고자 인코더 부분에서의 feature map의 값을가져오는 skip connection도 존재하구요.
기존의 Human Pose Estimation에서는 이러한 hourglass network를 여러개 붙였다고 합니다. 2개를 붙이면 2 hourglass, 4개를 붙이면 4 hourglass라고 하는데 해당 논문에서는 기존에 8 hourglass network 모델을 절반으로 줄여 4 hourglass로 만들었으며 각 layer의 채널이 기존 256인 것을 128로 줄였다고 합니다.
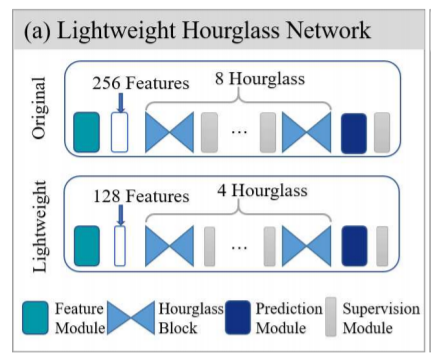
이렇게 모델도 반으로 줄이고, 채널도 절반으로 줄였는데 성능의 하락은 고작 1%밖에 안되었다고 합니다. 어떻게 이런 일이 가능할까요?
이는 바로 다음에 설명할 Knowledge Distillation 기법 덕분입니다.
Knowledge Distillation
Knowledge Distillation이라는 방법은 이 논문을 읽기 전에는 한번도 들어보지 못했던 방법인데, 매우 흥미로웠습니다.
일단 한줄로 말씀드리면 Knowledge Distillation이란 크고 깊은 네트워크를 pre-train한 후 우리가 사용할 작고 가벼운 네트워크를 학습시킬 때 보조로 사용한다는 것입니다.
해당 기법은 딥러닝의 대가 중 한분이신 제프리 힌튼 교수님께서 NIPS 2014에 제출한 “Distilling the Knowledge in a Neural Network” 라는 논문에서 처음 나온 기법입니다.
모델을 크고 깊게 쌓음으로써모델의 성능을 키우는 것도 좋지만 동일한 성능에서 모델이 더 작고 가벼워질 수 있도록 효율적인 측면(Computing Resource, Memory 등)도 고려하자는 것이죠.
그래서 힌튼 교수님께서는 작은 네트워크가 큰 네트워크와 비슷한 성능을 낼 수 있게끔 학습과정에서 큰 네트워크의 지식을 작은 네트워크에게 공유하자는 것이 “Distilling the Knowledge in a Neural Network”의 목적이었습니다.
제가 리뷰하는 논문인 Fast Human Pose Estimation 역시 이러한 Knowledge Distillation을 사용하고자 했습니다. 이를 진행하기 위해서는 학습에 도움을 줄 Teacher Network를 먼저 pretrain 해야겠죠.
Pre-train Teacher Network
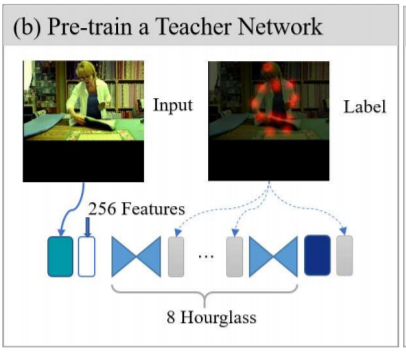
Teacher Network로 사용한 모델은 Pose Estimation에서 SOTA라고 알려진 모델입니다. 8개의 Hourglass Network로 이루어져있으며 각 레이어의 채널이 256 채널로 우리가 학습할 Lightweight Hourglass Network보다 크고 깊은 모습입니다.
이러한 Teacher Network를 먼저 학습시킨 후 나중에 Lightweight Hourglass Network를 학습시킬 때 사용하게 됩니다.
Supervision Enhancement by Pose Distillation
자 그러면 이제 Knowledge Distillation을 어떻게 적용시킬 수 있을까요?
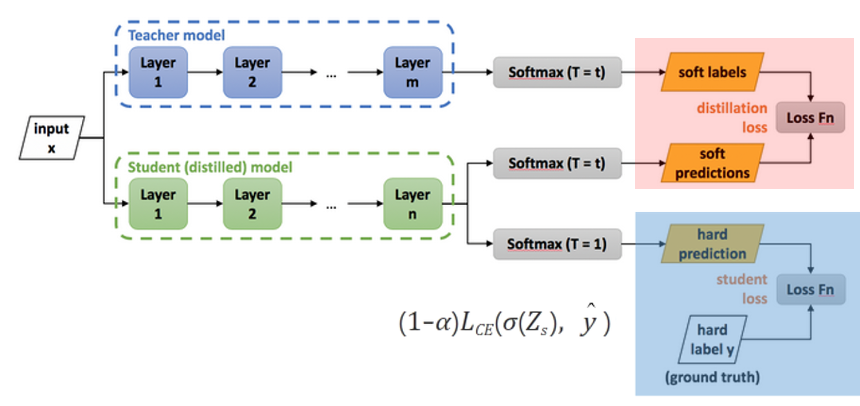
해당 기법에서의 방식을 알아보기 전에 먼저 기존의 Knowledge Distillation 기법이 어떤식으로 작동하는지 알아보겠습니다. 위에 그림은 Image Classification 네트워크를 학습하기 위해 knowledge Distillation을 적용한 파이프라인입니다.
Input은 각각 Teacher model과 Student model을 타게 됩니다. 파란색 영역부터 살펴보면 마지막 단에 SoftMax를 거친 후 hard prediction(argmax를 통한 확률이 가장 높은 label을 1, 나머지는 0으로 예측)을 최종 output으로 내놓습니다.
그렇게 나온 결과와 GT label과 비교한 후 backprop하여 학습을 진행하겠죠. 여기까지는 아주 일반적인 모델 학습 방법입니다. 저희가 중요하게 봐야할 부분은 위에 빨간색 영역입니다.
빨간색 영역을 보시면 똑같은 input에 대하여 Teacher model이 예측한 label 값이 존재하게 됩니다. 이 값과 student model이 예측한 값을 비교하여 loss 계산할 때 사용하게 됩니다.
이때 중요한 점은 hard prediction(label)이 아닌 soft prediction을 가지고 loss 계산을 한다는 점인데요, 이는 단순히 Teacher model의 가장 높은 확률을 가진 class 말고 다른 class에 대해서도 어느정도 확률값을 가지고 있는지를 student model에게 반영해주기 위해서라고 합니다.
예를 들어 Hard label에서는 단순히 [0, 0, 1, 0] 이지만 Soft label을 사용하게 되면 [0.2, 0.1, 0.7, 0]이 될 수 있으며 이러한 자잘한 확률 예측값도 student network에 반영해주고 싶은 것입니다.
자 그럼 다시 Pose Estimation으로 돌아와 봅시다. 해당 논문에서 학습하는 방식도 위에서 설명한 방식과 별 차이 없습니다. Student model이 학습할 때 Loss로 GT뿐만 아니라 Teacher model의 predict 값과도 계산하게 되는 것이죠.
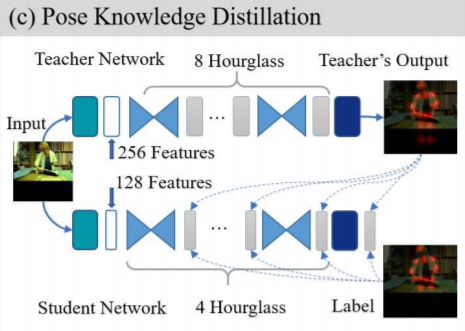
위에 그림은 해당 논문에서 제안하는 학습 방식으로 아까 보셨던 Knowledge Distillation 파이프라인과 큰 차이가 없는 모습입니다. Teacher의 output이 Student Network에 적용되는 모습이죠.
여기서 한가지 중요하게 알아가셔야 할 점은, 기존의 Knowledge Distillation network의 경우 Image Classification에 주로 사용되던 기법입니다.
그래서 아까 설명드렸다시피 Soft-label based Cross Entropy Loss를 사용하는 것이며 이를 human pose 모델에 곧바로 적용하기에는 부적합하다고 합니다.
그래서 이를 해결하고자 논문에서는 다음과 같은 Loss function을 설계하였습니다.
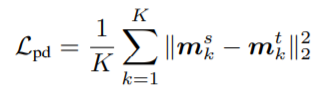
m^{s}_{k}, m^{t}_{k} 는 각각 student model과 teacher model이 predict한 k번째 관절 confidence map입니다.
loss 계산 수식은 teacher와 student model의 pose supervised learning loss를 최대한 유사하게 하기 위하여 MSE를 기반으로 구성하였다고 합니다.
Experiments
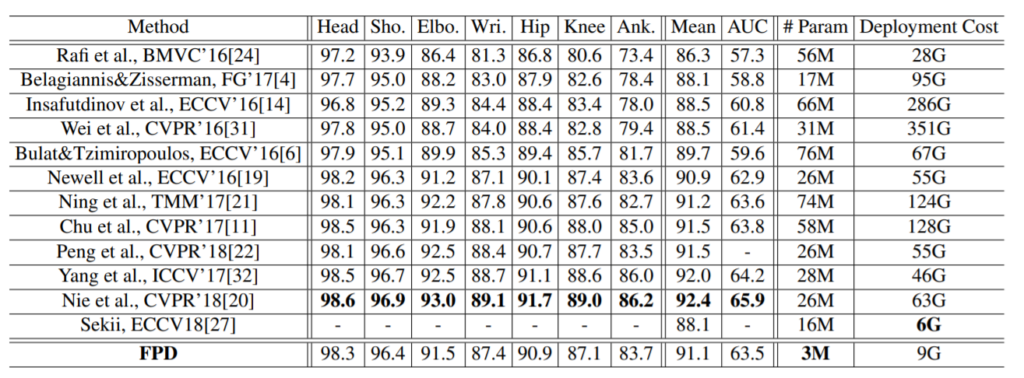
위에 표는 MPII 데이터 셋을 가지고 정성적으로 평가한 테이블입니다. 먼저 MPII 데이터 셋은 간략하게 설명드리자면 주로 Sport와 관련된 데이터 셋으로 동적인 장면들이 많이 존재한다고 보시면 될 것 같습니다.
볼드체로 표기된 Nie et al CVPR’18 방법론이 현재 Pose Estimation에서 SOTA라고 볼 수 있으며 맨 아래 FPD가 해당 논문에서 제안한 방법론입니다.
보시면 Nie et al이 Mean 성능이 92.4로 제일 높은 것을 보실 수 있지만 FPD 역시 91.1로 매우 큰 차이가 나지는 않는 모습입니다.
반면에 FPD 논문에서의 목적인 모델의 경량화는 관점에서 봤을 때, Nie et al은 파라미터 수가 26M인 반면, FPD의 경우 3M로 무려 8.7배만큼 축소시킨 것을 보실 수 있습니다.
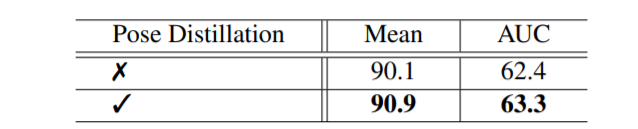
다음은 Knowledge Distillation의 효과를 확인하기 위한 테이블입니다. 보시면 Pose Distillation을 적용했을 경우 안했을 경우보다 0.8 정도의 성능 향상이 있는 모습입니다.
정성적인 결과들을 끝으로 해당 리뷰를 마치도록 하겠습니다.
