
가능하다면 금주부터는 6-DOF Object Pose Estimation과 관련된 논문들을 읽어보고 리뷰를 진행하고자 합니다. 오늘은 첫 리뷰이기 때문에 6-DOF는 무엇인지에 대한 내용과 2017년 나온 ‘PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes’ 논문을 리뷰하겠습니다.
설명하기에 앞서 먼저 영상하나를 보시죠.
뭔가 로봇이 물체를 인식하고 물체를 잡고 있습니다. 여기서 사용되는 기술이 6-DOF Object Pose Estimation 입니다. 좀 더 설명하자면 위에서 설명한 영상의 로봇은 ‘HSR-ROBOT’이라고 합니다. 해당 로봇은 어떻게 구성됐을까요?

크게 나누면 다음과 같이 구성됐다고 합니다. 그 중 저희가 관심갖는 부분은 gripper,arm,그리고 RGBD 센서입니다. 정확히는 저희는 RGBD 센서에 관심을 갖으며, 이를 이용해 유의미한 정보를 만들고 해당 정보를 이용해 물건을 잡겠죠..? (물건을 잡기위한 제어파트는 최근 시뮬레이션이 너무많이 좋아져 제어도 모델링하기 쉽고 강화학습 기반으로 학습도 많이 이뤄지고 있습니다. 하지만 해당 모델을 실제 환경에서 잘 작동시키려면 시뮬레이션의 환경에서의 인지성능이 기반이 되어야 합니다. 따라서 정확한 환경인지 기술은 해당 로봇의 핵심입니다. )
좀더 이해를 쉽게하기 위해서 가정을 시나리오를 만들어 봅시다. 저는 제가 좋아하는 백산수를 HSR-ROBOT에게 잡으라고 시켰습니다.
HSR-ROBOT은 백산수를 인지하고, 성공적으로 잡았습니다.!! 근데 한가지 의문인건 어떻게 인식하고 잡았을까요…?

HSR-ROBOT에 담긴 RGBD 센서로 실제 백산수 물병의 정보를 얻게 됩니다. 여기서 로봇에게 물병의 X,Y,Z 좌표값만 알려주면 알아서 잡을 수 있을까요?
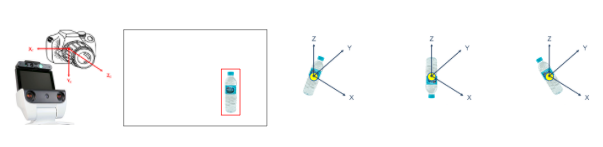
아닙니다. 물병이 정상적으로 위치한 경우에는 Rotation을 무시해도 된다고 하지만, 실제 리얼환경에서는 어떤 상태로 있는지 모르기 때문에 물병에 Rotation 정보도 함께 제공해야 정확하게 물병을 잡을 수 있습니다.
즉 정확히 물체를 잡기위해서 해당 물체의 위치(X,Y,Z) 뿐만아니라 Rotation(Roll,Pitch,Yaw) 정보도 줘야하고, 이러한 이유로 총 6개의 자유도를 갖는다는 의미로 물체의 6 DoF(Degree of Freedom)을 제어부에 제공해야 필요합니다.
그래서 앞서 RGBD 센서를 통해서 물체의 6-DOF 계산이 필요하며, 많은 연구자들이 이를 얻기위한 연구가 이뤄지고 있습니다. 그리고 그 연구에서 많이 인용된 논문이 ‘PoseCNN’ 입니다.
Pose CNN : A Convolutional Neural Network for 6D Object Pose Estimation in Clustered Scenes
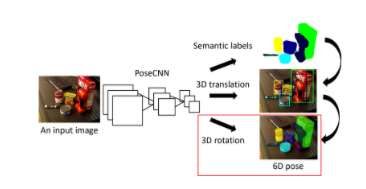
본 연구에서는 2D 이미지를 통해서 Object 의 6D Object Pose를 예측합니다. (나중에 Depth도 사용한 결과를 나타내는데 뒤에서 설명하겠습니다.) 해당 논문에서 제안하는 전체 구상도는 다음과 같습니다.

이미지가 들어오면, CNN을 통해서, Semantic Labels을 구하고, 3D translation을 구하고, 3D Rotation을 구한다. 해당 논문에서 6-DOF를 얻어내기 위한 방법입니다. 각각 방법에 대한 디테일을 확인해보겠습니다.
1. Semantic Labels
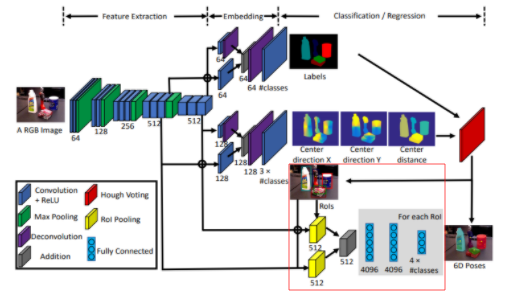
이 부분에 대해서는 조금 할말이 없는데.. 그 이유는 그냥 Semantic Segmentation을 수행하기 때문입니다. 해당 논문에서는 저자가 이전에 제안했던 Segmentation 모델을 사용해 Semantic Label을 얻습니다. 이 모델의 이름은 DA-RNN 으로 RGB 영상으로도 Semantic Label을 얻었고, Depth를 함께 사용해 Semantic Label을 얻었다고 합니다. 해당 논문에서 제안했던 아키텍처는 다음과 같습니다.

자 그럼 다시.. 6 DoF로 돌아와서 저자가 과거에 제안했던 모델을 이용해 Semantic Label을 얻습니다. 그리고 PoseCNN 논문에서 나타낸 전체 아키텍처의 가장 산단을 보면 위에서 볼수있는 DA-RNN 과 구조가 동일합니다. (제 생각에는 DA-RNN을 베이스로 몇개의 브랜치를 따서 6DoF 문제를 해결한 논문이라고 생각됩니다.)
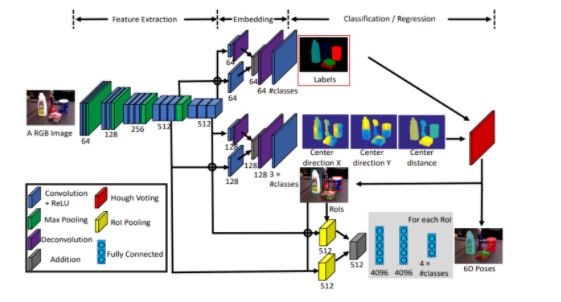
자 그럼 일단 Semantic Label에 대해서는 제껴두고…. 이제 6DOF Object Pose Estimation을 위한 핵심적으로 제안한 Contribution에 대해서 설명하겠습니다.
2. 3D translation
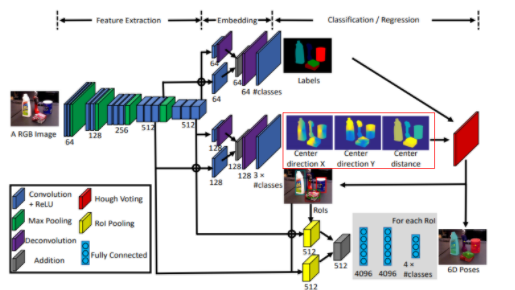
위에 그림에서 빨간색으로 표시된 부분이 3D translation을 CNN 모델을 통해 예측하는 부분입니다. CNN을 사용하기 때문에 ‘아 난 아무것도 모르겠고 걍 3D translation 결과 바로 내놔’ 할수도 있지만 저자도 그렇고 저희도 ‘영상이해’를 배운사람들이기 때문에…. 바로 모델에게 3D translation 결과값을 추론시키기 보다 아래와 같은 이론을 근거로 좀 더 학습이 용이하도록 모델을 설계합니다.
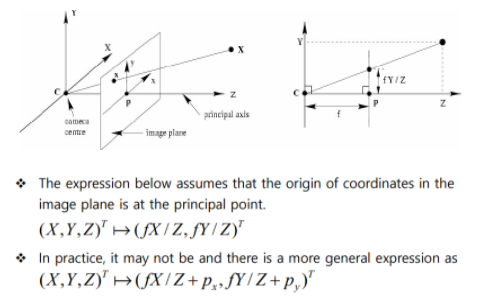
위에 잘 기억은 안나시겠지만 ‘영상이해’ 수업자료 입니다. 카메라센터, 이미지 평면 등등 아직 잘 이해가 안되시는 분들은 ‘영상이해’ 3주차 수업이나 @jwon @jmshin 님의 과거 발표자료를 확인하시면 됩니다..
아무튼 우리가 영상이해에서 배운 위의 관계를 통해 3D translation을 추론하도록 저자는 모델을 설계합니다.
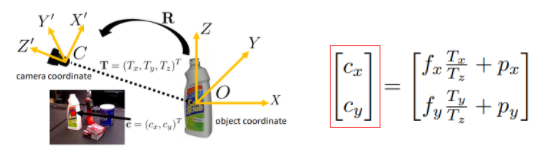
위에서 나타난 수식과 같이 어떤 Object의 센터값과 Tz(카메라와 object의 거리)를 예측하도록 모델을 설계하면 자동으로 Tx, Ty를 구할수 있으며 그러면 3D Translation을 예측할 수 있다는게 저자의 설명입니다. 그러면 여기서 cx, cy에 해당하는 Object의 센터는 어떻게 구할 수 있을까요? 저자는 Implicit Shape Model(ISM) 방법에서 영감을 얻어 해당 방법을 모델에 적용하였다고 합니다.
ISM을 처음접하는 분들을 위해서 ISM에 대해서 설명하고 있는 Fei-Fei Li 교수님의 자료를 첨부해드리겠습니다.



이러한 ISM 의 방법에서 영감을 얻어서 각 픽셀단위로 해당 픽셀의 벡터 방향을 예측하도록 모델을 설계하면 모든 픽셀의 벡터 방향의 교점을 구하면 센터가 될 수 있다고 저자는 이야기합니다. 아래 그림과 같이 말이죠.
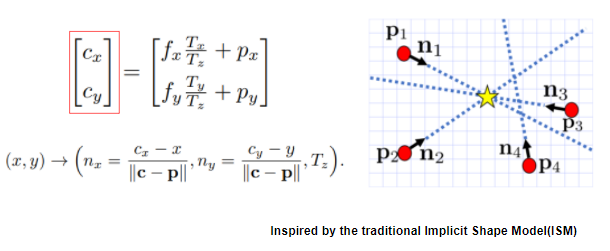
이러한 방법을 사용한다면, 앞서 이야기했던 cx, cy도 CNN을 통해서 예측이 가능합니다. 다시 전체 아키텍처를 확인하면
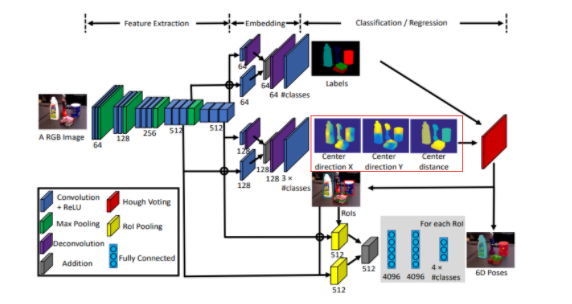
실제 CNN 모델을 이용해 Center direction X, Center direction Y, Center distance를 구하도록 모델이 설계된것을 확인할 수 있습니다. 여기서 Center direction X,Center direction Y는 cx, cy를 구하기 위한 각 픽셀마다의 방향벡터이고, Center distance는 Tz 입니다.
3. 3D rotation
자 앞에서 6DoF를 설명했고, 6DoF는 X,Y,Z 와 Roll,Pitch,Yaw로 구성됐습니다. 카메라의 좌표는 알고있기 때문에 카메라의 좌표를 3D translation 수행하면 Object의 X,Y,Z를 구할 수 있습니다. 이제는 Roll,Pitch,Yaw만 계산하면 6DoF를 얻을 수 있으며 이를 계산하기위한 3D rotation에 대해서 알아봅시다.
자세히 알아보려고 했으나…. Rotation은 앞서 Translation과 다르게 직관적으로 모델을 설계합니다. Semantic Label을 통해서 ROI를 계산하고 ROI를 Crop한 이후에 해당 Crop된 이미지를 통해서 그냥 모델에 태워서 쿼터니언 값을 다이렉트로 예측하게 됩니다. (음… 그냥 그렇다고 합니다.) 여기서 Eulerian Angle을 사용하지 않는 이유는 카메라도 짐벌락 현상이 발생하기 때문에 대부분 쿼터니언을 사용해서인데, 짐벌락이 무엇인지 쿼터니언이 무엇인지는 저보다 아래 영상이 잘 설명하고 있습니다.
자 그럼 생각보다 3D Rotation을 예측하는데 있어서는 새로운 방법이 적용되지 않았는데요.. 그래도 CNN 모델로 예측하도록 하였으니 이에 알맞은 Loss 설계가 필요하겠죠? 본 논문에서 이를위해 설계한 Loss는 다음과 같습니다.
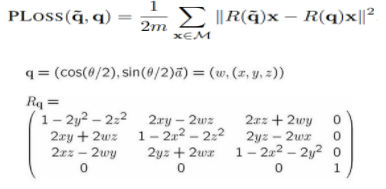
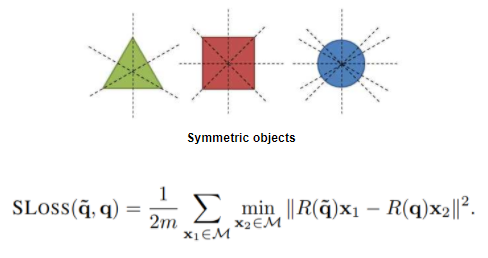
PLoss로 쿼터니언을 예측하기위한 Loss인데 R()을 사용하는 이유는 이를 Rotaition matrix로 변환해 Loss를 계산한다고 합니다. 근데 PLoss는 한계점이 존재하는데 바로 대칭인 Object에 대해서는 제대로 작동하지 않는다는 사실입니다. 그래서 대칭인 Object의 Rotation도 계산할 수 있도록 SPLoss를 추가로 제안합니다.
이러한 Loss를 통해서 최종적으로 3D Rotation을 예측하는 CNN 모델을 학습한다고 저자는 이야기하고 있습니다.
자! 그럼 6 DOF Object Pose를 계산하기위해 논문에서 제안하는 모든 방법에 대한 설명은 끝났습니다. 다시 처음 사용했던 그림을 통해서 정리해봅시다.
이제 이러한 방법으로 어떤 성능을 냈는지, 그리고 어떤 데이터셋을 사용했는지도 함께 확인해봅시다.

본 논문에서는 YCB-VIDEO 데이터셋을 사용했습니다. 해당 데이터셋에 설명은 위에 그림과 같습니다.
자 그러면 이러한 데이터셋을 이용해 6DOF를 예측하면 실제 이를 어떻게 평가하는지 6DOF에서 사용하는 평가방법에 대해서 설명드리겠습니다.
평가방법 (ADD, ADD-S)
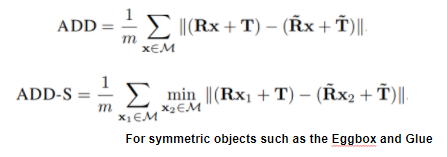
본 논문에서 사용하는 평가방법은 ADD와 ADD-S 입니다. 위에 수식을 보면 알 수 있듯이 모델이 예측한 Rotation, Translation 과 실제 Ground Truth에 해당하는 Rotation, Translation의 값을 통해서 평가를 수행하게 됩니다. 이때도 앞에 Loss 설계에서 언급했듯 대칭 Object에 대해서는 다른 방법의 다른 방법의 평가방법을 사용하고 있으며, 논문에서 이야기하는 대칭 Object는 Eggbox와 Glue를 이야기한다고 합니다.
자 그럼 이러한 평가 방법을 통해 해당 논문이 제안하는 네트워크의 성능은 어떻게 될까요? 논문에서 제안한 방법론의 성능평가는 다음과 같습니다.
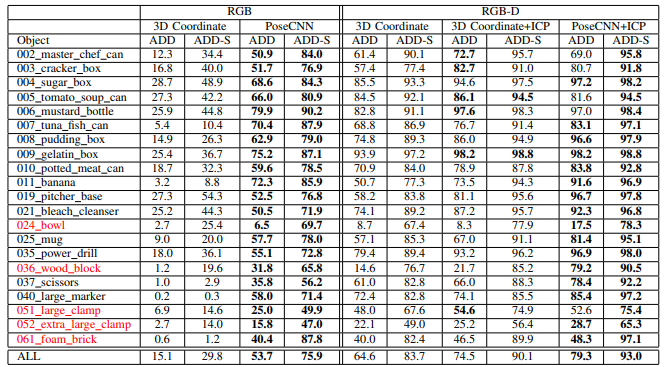
여기서 특정인 RGB와 RGB-D에 대한 평가를 제시하고 있는데 이러한 이유는 앞에서 설명했지만 Semantic Label을 얻는 모델도 기존에 2개의 센서를 가지고 구했던 논문이기 때문에 쉽게 확장이 가능했습니다.
그리고 한가지 특이한점은 기존 방법에 ICP가 추가돼 성능향상을 이뤘는데 여기서 ICP는 무엇일까요? ICP는 Iterative Closest Point의 약자로 모델이 구한 Translation과 Rotation을 실제 정답이 되는 값과 반복적으로 오차를 계산해 업데이트하는 네트워크(?)를 추가해 보정한 결과라고 합니다. (단, ICP 사용으로 인해 정확도는 높일 수있지만 추론속도는 엄청 느려지는게 한계입니다. 그리고 이러한 한계를 해결한 논문을 다음주에 리뷰하도록 하겠습니다.)
더 빠른 이해를 위해 ICP 과정이 담긴 영상을 함께 공유하겠습니다.
자 이러한 ICP방법까지 적용하면 6 DOF Object Pose Estimation을 성공적으로 수행할 수 있었습니다.!! 해당 논문에서 공개한 데모영상을 확인하는 것으로 이번 리뷰를 마치겠습니다.
예고편
해당 논문에서는 ICP 과정을 후처리로 수행해야 정확도가 확실히 높아집니다. 하지만 ICP과정으로 인해서 추론속도가 느리다는 치명적인 한계가 존재합니다. 이러한 한계를 극복하고 Depth 센서도 Fusion하여 성능과 속도를 모두 Boosting한 논문이 있습니다. 다음주에는 가능하다면 해당 논문을 리뷰하도록 하겠습니다.
흥미로운 주제 감사합니다. 해당부분이 관심이있는 분야라 논문을 한번 훑어 읽어보았는데요 ICP를 optimizing하는 과정에서 local mimina에 수렴할 수 있어서 어떠한 조치를 취했는지 부분이 이해가 잘 안가네요 혹시 이부분 이해하셨나요?
컴퓨터 비전이 적용되는 새로운 분야(저에게) 같습니다. 신기하다는 생각이 듭니다. 리뷰 감사합니다
이진수 연구원님, 질문에 가까운 댓글 부탁합니다. 해당 리뷰를 읽고 질문이 이렇게 없을 수 있나요?
단순 XYZ가 아닌 rotation을 고려하는 것이 물체의 형상을 더 잘 고려할 수 있어서 (예를들어 직사각형인 책을 학습할 때 rotation을 고려하면 평행사변형이나 다른 형태로 변형에도 불변하는 특징이 아닌 rotation과 직사각형의 책을 고려할 수 있어서) rotation이 있으면 더 학습을 단순화 할 수 있을 것 같네요
기존에는 한번에 3D 좌표로 해결하려는 시도가 있었는지 궁금합니다! 한번에 해결하려다 문제가 우선 나누어서 생각하는 방향으로 발전한 것이 맞을까요?
만약 맞다면 언젠가 앞으로는 한번에 해결하는 방향으로 바뀔까요? 재미있네요
ISM 방법으로 물체의 중심을 찾는다 하였는데 그럼 feature의 방향 중심을 이용하는 건가요? feature의 중심점이라면 원본 이미지와 사이즈가 달라져 정확하지 않을 것 같은데 혹시 제가 잘못 이해하는 걸까요?