NAVER Europe에서 공개한 AP loss 코드를 살펴보니, feature를 추출하는 모델이 R-MAC 인것을 확인할 수 있었습니다. 처음보는 이름의 모델이라 해당 모델의 논문을 찾아 읽어보았습니다.
R-MAC을 설명하기 위해서는 우선 MAC에 대한 설명이 필요합니다.
MAC
MAC은 Maximum Activations of Convolutions의 약자입니다.
이름에서 유추할 수 있습니다. convolution layer를 통과한 feature의 가장 activation한 부분을 descriptor로 사용하는 방법입니다. 정말 간단한 방법으로
feature를 추출하는 방법은 다음과 같습니다.
1. 일반적인 pretrianed CNN 모델 ( VGG-16, ResNET 등)의 FC layer를 제거하고, freeze 시킵니다.
2. 그러면 (Batch가 있다면 B x) W x H x K 형태의 feature가 만들어 질텐데요,
3. 이 feature에서, W x H 의 값들중, max의 값으로 pooling합니다.
4. 그러면 1 x 1 x K 의 feature가 만들어집니다.
5. L2 normalization을 적용합니다.
6. 이것이 descriptor가 됩니다.
feature에서 값이 크다는것은 그만큼 활성화가 많이 되었음을 의미하기도 하니까, 이름이 왜 MAC 인지 알 수 있습니다.
R-MAC
MAC은, W x H 전체의 가장 큰 값을 취하기 때문에, 과정에서 알 수 있듯, 위치정보가 손실됩니다. R-MAC은 MAC의 이러한 단점을 보완한 방법입니다. R은 region의 약자입니다.
R-MAC의 추출방법은 MAC과 거의 동일합니다. 다만 설명했듯, 지역(위치)정보를 최대한 유지 할 수 있도록 합니다.
MAC이 W x H feature의 전체중의 max를 취했다면, 이와 달리 R-MAC은 W x H 의 feature를 정사각형으로 구역을 나누어 max pooling 합니다. 이때 정사각형의 영역은, W와 H중 짧은 쪽의 길이를 한 변의 길이로 취합니다.
region을 나누어 max를 구하면, 정사각형의 크기에 따라 n개의 K차원 vector가 만들어 집니다. 이를 모두 더하고 l2 norm을 취하고, PCA를 거치고 다시 l2 norm을 적용하여 1개의 K차원 vector를 만듭니다.
이 pooling은 1번만이 아니라 정사각형의 크기를 uniform하게 줄여가며 몇차례 더 진행합니다. 마치 sliding window 처럼 pooling을 진행하는데요, 정사각형의 구역은 40%정도 겹치도록 sliding window처럼 pooling합니다. 또한 몇 번 더 진행할지는, 경험적으로 택한다고 합니다. 아래의 그림을 참고하면 이해가 빠를 것 같습니다.
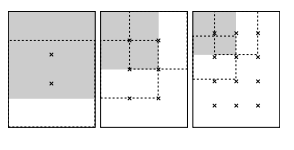
그렇게 l2 pca l2 를 취한 vector가 몇 번 더 진행할지에 따라 m개가 만들어 지는데요, 이를 다시 더하고 l2 norm을 취한 K 차원 vector를 descriptor로 사용하는 것이 R-MAC 입니다.
Ranking
간단합니다. R-MAC과 MAC 모두 Ranking은 cosine similarity 가 높은 순서로 ranking합니다. 모든 이미지에 대해 MAC 혹은 R-MAC 방법으로 feature를 뽑고, query image의 feature도 추출하여, 그들간의 코사인 유사도가 높은 순서로 k개를 Ranking합니다.
Re-ranking
ranking에서는 R-MAC의 feature를 만든것 처럼 region의 feature들을 합치지 않은 정보들을 이용합니다. ranking에서 선정한 feature들과 query의 feature의 cosine similarity를 구하는데요, 말한것 처럼 합치지 않은 region의 feature에서 코사인 유사도가 높은 n개의 영역들을 찾아냅니다. 그러면 각 후보 feature마다 n개의 region feature들이 추출됩니다. 이를 합치고 l2 norm을 적용한, K차원의 vector가 후보의 수 만큼 생기게 됩니다.
이를 query image의 MAC feature와의 cosine similarity를 구하고, 높은 순서로 re-ranking합니다.

위 이미지의 5개의 box가 cosine similarity 가 높은 5개의 region이고, 이 region의 max를 합치고, l2 pca l2한 K차원 vector와, query image의 MAC (K차원 vector)의 cosine similarity 가 높은 순서로 re-ranking 합니다.
QE( Query expansion )
re-ranking 을 하고나면, top은 query와 유사할 확률이 높습니다. 마지막으로 QE라는 과정을 진행합니다. re-ranking된 top 5개의 image를 query vector와 merge하고, mean을 구하여 이 값과 cosine similarity 가 가장높은 이미지를 최종 적으로 채택한다고 하는데, merge하는 것이 MAC인지, R-MAC인지, 이미지 자체인지는 QE에 관한 논문을 좀 더 찾아봐야 할 것 같습니다. 이는 지금 진행중인 retrieval에 적용할 수 있을 것 같습니다.
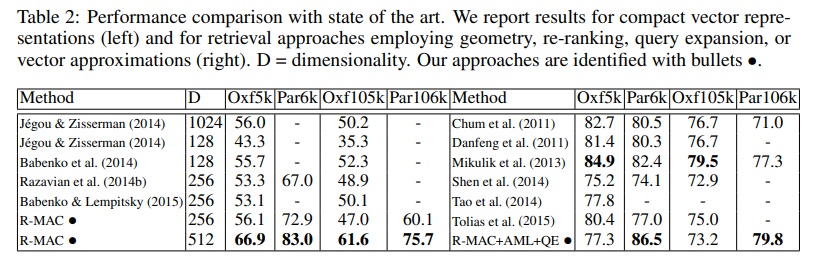
R-MAC이 현재 SOTA 포함된 방법론인가요?