1. Introduction
이 연구는 롱컨텍스트 트랜스포머가 실제 서비스에서 점점 더 많이 쓰이면서 긴 컨텍스트를 처리할 때 발생하는 비용(메모리·연산)을 어떻게 줄일지에 초점을 둡니다. 장문 문서 분석이나 개인화 챗봇 같은 응용에서는 컨텍스트가 길수록 도움이 되지만, 그에 따라 KV cache를 저장해야 하는 메모리와 어텐션 계산 비용이 급격히 커집니다. 예를 들어 Qwen2.5-14B에서 120K 토큰을 FP16으로 캐싱하면 약 33GB가 필요해, 모델 파라미터(28GB)보다도 KV 캐시가 더 무거워지는 상황이 생깁니다.
그래서 최근 연구들은 주로 KV cache 메모리를 줄이되 성능은 유지하는 방향으로 발전해 왔습니다. 대표적으로 (1) 어텐션 헤드를 병합하거나, (2) KV를 더 짧은 시퀀스로 압축하거나, (3) 슬라이딩 윈도우로 컨텍스트 창을 제한하는 방식들이 있습니다. 또 다른 흐름은 어텐션의 sparsity를 이용해 디코딩 중이나 KV 캐시를 생성하는 과정(prefill)에서 중요하지 않은 KV를 동적으로 버리는(eviction) 기법들입니다. 이때 핵심은 지금 들어온 쿼리 관점에서 무엇이 중요한가를 점수화해서, 당장 답변에 필요해 보이는 KV만 남기는 방식(그림 1a,b)입니다.
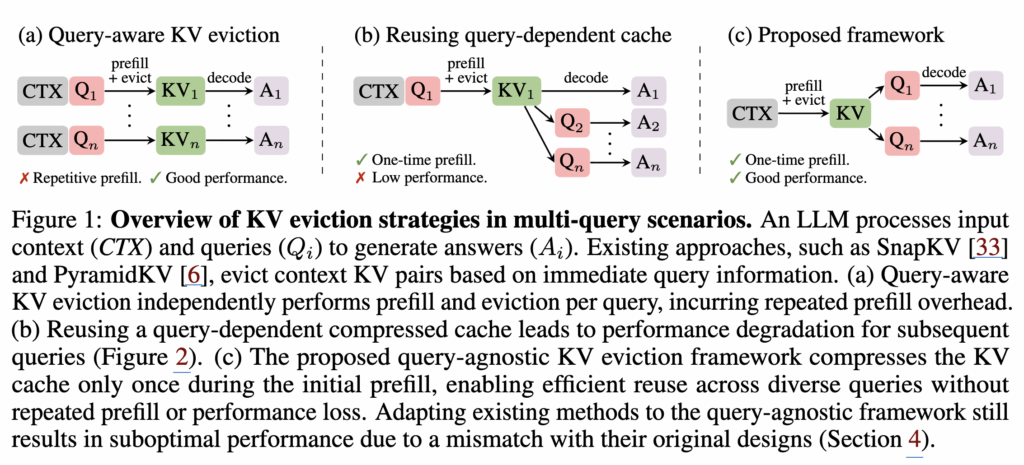
하지만 저자들은 여기서 중요한 약점을 짚습니다. 이런 기존 eviction 방식은 단일 쿼리에는 꽤 잘 맞지만, 실제 챗봇/문서 시스템처럼 여러 개의 서로 다른 질문(multi-query)이 이어지는 환경에서는 문제가 커집니다. 초기에 들어온 질문에 맞춰 KV를 남겨버리면, 뒤이어 등장하는 다른 질문들에 필요한 정보는 이미 버려져서 성능이 크게 떨어진다는 겁니다. 즉 쿼리-인지(query-aware) 방식이 오히려 KV를 초기 질문에 과적합시키는 구조적 한계가 있습니다.
이 문제의식에서 저자들은 KVzip이라는 새 알고리즘을 제안합니다. 핵심은 기존과 반대로, 미래에 어떤 질문이 들어올지 모르는 상황에서도 대응할 수 있도록 쿼리-불가지(query-agnostic)하게 KV 캐시를 압축·정리해 두는 겁니다. 즉 컨텍스트 하나를 기준으로 재사용 가능한 압축 KV 캐시를 만들어 두고(그림 1c), 이후 어떤 질문이 와도 그 캐시로 빠르고 가볍게 추론하게 하자는 접근입니다. 특히 사용자 지시문과 대화 기록을 오프라인으로 준비해 두는 개인화 에이전트나, 기업 문서를 미리 KV 캐시로 만들어 재활용하는 시스템처럼 KV 캐시를 미리 준비(precompute)하는 시나리오에서 큰 이점을 갖습니다.
Query-agnostic eviction을 설계하는 데 있어 가장 큰 어려움은 미래에 어떤 질의가 주어질지 알 수 없다는 점입니다. 이에 대해 저자는 미래 질문을 맞추려 하기보다, 원래 컨텍스트를 잘 ‘복원(reconstruct)’하는 데 필수적인 KV만 남기면, 그게 다양한 다운스트림 질문에도 잘 일반화되는 압축 표현이 될 것이라 가정합니다. 이 관점에서 트랜스포머는 컨텍스트를 KV로 인코딩했다가, 이후 쿼리로 디코딩하는 encoder–decoder처럼 동작한다고 보고, KV를 전통적 압축 기법(Zip[Learned Token Pruning for Transformers])처럼 컨텍스트의 압축된 코드로 해석합니다. 그래서 KVzip은 LLM의 forward pass를 이용해 컨텍스트 복원 과정을 시뮬레이션하고, 그 과정에서 각 KV가 얼마나 참조(어텐션)되는지를 보고 중요도를 매깁니다. 구체적으로는 복원 과정에서 각 KV가 받은 최대 어텐션 값을 기반으로 중요도 점수를 부여해 eviction을 수행합니다.
결과적으로 eviction 이후에는 KV 캐시의 크기가 줄어, 이후 쿼리들이 지연시간과 메모리 사용량에서 큰 이득을 얻습니다. 저자들은 FlashAttention 기준 약 2배 지연시간 감소, 디코딩 KV 캐시 크기에서 394배 감소를 보이면서도, 다양한 질문에 대해 성능 저하가 거의 없다고 리포팅합니다. 또한 KVzip은 (1) 컨텍스트마다 압축을 수행해 더 높은 압축률을 얻는 context-dependent 방식, (2) 배포 후 추가 오버헤드 없이 중간 수준 압축을 제공하는 context-independent 방식을 모두 지원합니다.
실험은 document question-answering, mathematical reasoning, retrieval, code comprehension 등의 여러 태스크와 최대 170K 컨텍스트까지 확장된 셋팅에서 수행되며, SQuAD/GSM8K/SCBench 등 12개 데이터셋과 LLaMA3.1, Qwen2.5, Gemma3(3B~14B) 등 다양한 모델을 포함합니다. 특히 기존 eviction 방법들이 multi-query 환경에서 KV를 조금만(예: 10%) 버려도 성능이 크게 흔들리는 반면, KVzip은 KV를 최대 70%까지 제거해도 정확도를 안정적으로 유지하는 모습을 보입니다.
2 Preliminary
2.1 Notation and Problem Formulation
이 절에서는 KV 캐시 압축(KV eviction) 문제를 수식으로 정의합니다. 텍스트 도메인을 T라고 하고, 오토리그레시브 트랜스포머 LLM fLM:T→T가 greedy decoding으로 토큰을 생성한다고 가정합니다. 모델은 L개의 레이어로 구성되며, 어텐션은 GQA(Grouped-Query Attention)를 사용합니다. 즉 KV head는 H개이고, 각 KV head를 G개의 query head 그룹이 함께 참조하는 구조입니다.
추론 시 효율을 위해, 모델은 입력 컨텍스트 c∈T를 nc개의 토큰으로 토크나이즈한 뒤 prefill 단계에서 모든 중간 표현을 KV pair로 캐싱합니다. 이때 생성되는 캐시는 총 L×H×nc개의 KV pair로 이루어지며 이를 KVc라고 표기합니다. 이후 디코딩은 캐시를 조건으로 한 생성으로 볼 수 있으므로, 저자들은 이를 fLM(⋅∣KVc)로 표기합니다.
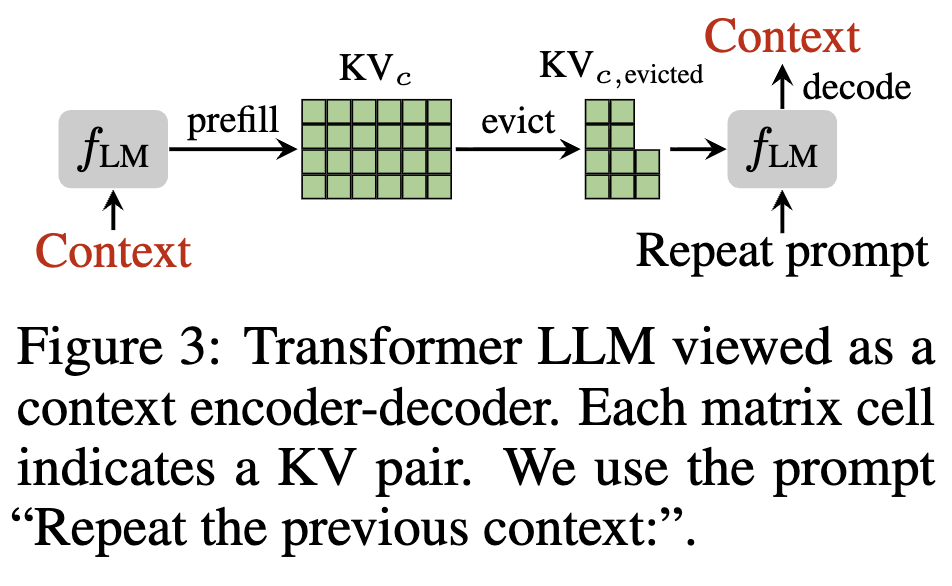
이 논문의 목표는 원래 캐시 KVc에서 일부 KV를 제거해 더 작은 캐시 KVc,evicted⊆KVc 를 만들되, 어떤 질의 q∈T가 오더라도 압축 캐시로 생성한 출력이 원본 캐시 기반 출력과 거의 같게 유지하는 것입니다. 이를 아래처럼 공식화합니다:
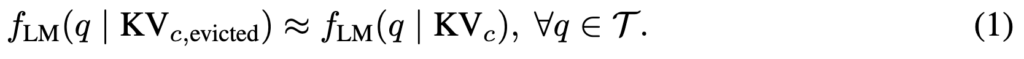
2.2 Analysis of Existing Approaches
이제 저자들은 기존 KV eviction 방식들이 왜 multi-query 환경에서 약한지를 짚습니다. SnapKV나 PyramidKV 같은 방법들은 prefill 시점에 얻는 정보(주로 어텐션)를 이용해 KV 중요도를 계산하고, 그 점수가 높은 KV만 남기는 방식입니다. 구체적으로는 trailing context window 안의 query들을 사용해 지금 이 query들이 어떤 KV를 많이 보나를 기반으로 중요도를 매기고, 그 query에 유용한 KV를 선택적으로 보존합니다.
이 방식은 단일 질문(single-query) 평가에서는 꽤 잘 동작합니다. Needle-in-a-haystack이나 LongBench같은 셋팅에서는 그 질문에 맞춰 KV를 남기면 되기 때문입니다. 대신 이런 방식은 대개 새 질문이 들어올 때마다 prefill+압축을 다시 해야 해서(그림 1a), 질의가 여러 번 들어오는 서비스형 시나리오에서는 반복 비용이 커집니다.
그렇다면 “한 번 압축한 캐시를 재사용하면 되지 않나?”라는 선택지가 있고, 실제로 그림 1b처럼 재사용하면 계산 오버헤드는 줄어듭니다. 문제는 여기서 발생합니다. 기존 방식으로 압축된 캐시는 대체로 첫 번째 질문에 특화된 KV만 남긴 결과라서, 다른 질문이 들어오면 필요한 정보가 이미 날아가 성능이 급격하게 떨어지게 됩니다.
저자들은 이 한계를 SQuAD multi-QA로 보여줍니다(그림 2).
SnapKV는 쿼리마다 prefill+압축을 따로 수행하면 정확도가 높지만, 초기 쿼리로 압축한 캐시를 이후 쿼리에 재사용(reuse)하면 성능이 크게 떨어집니다. 즉, 기존 방식은 query-aware라서 당장은 좋아도, 서로 다른 미래 질문으로 일반화되지 못하는 구조적 한계를 갖는다는 결론입니다.
이 문제를 통해 다음 질문이 무엇일지 모르는 상황에서도 재사용 가능한 압축 캐시가 필요하고, 그래서 저자들은 query-agnostic KV eviction 전략을 제안하게 됩니다.
3 Method
이 알고리즘의 목표는 컨텍스트 c에 대해 만들어진 KV cache KVc 안의 각 KV pair가 얼마나 중요한지를 점수로 매기고, 점수가 낮은 것부터 버려서(evict) 작은 캐시를 만드는 것입니다. 기존 연구들과 마찬가지로, KVzip은 길이 nc의 컨텍스트에 대해 S∈RL×H×nc 형태의 중요도 점수를 만들고, 이 점수를 기준으로 eviction 우선순위를 결정합니다.
3.1 Intuition
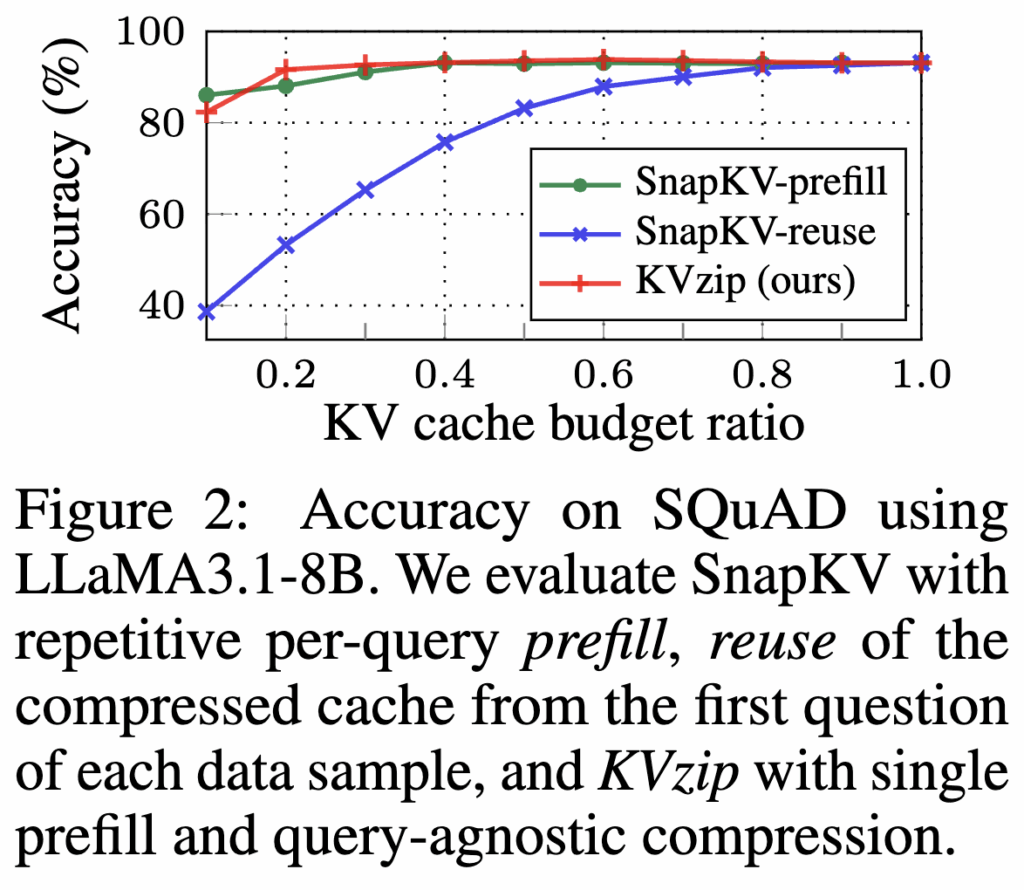
임의의 질문에 잘 답하려면, 압축된 캐시 KVc,evicted가 컨텍스트 정보를 충분히 보존하고 있어야 합니다. 그런데 미래의 질문 q는 알 수 없으니, 질문에 잘 맞는지를 직접 검증할 수가 없습니다. 그 대신, 모델 fLM에게 컨텍스트 c를 다시 써보라(reconstruct)고 시켜서 정보 보존이 충분한지를 확인합니다(Figure 3).
만약 KVc,evicted만으로도 모델이 repeat 프롬프트를 통해 원래 컨텍스트를 정확히 재구성할 수 있다면, 그 캐시는 컨텍스트 정보를 충분히 담고 있다고 볼 수 있습니다. 하지만 여기서 중요한 제약이 있습니다. 매 질문마다 문서를 재생성하고 다시 prefill 하고 다시 KV 만들면 속도·비용 면에서 이점을 잃어버립니다. 그래서 실제 이 방법을 사용하지는 않습니다. 대신 원래 캐시를 재생성하지 않아도 압축된 KV 캐시 자체가 다양한 질문에 잘 일반화됨을 실험적으로 확인합니다. 즉, 실험 결과 이러한 복원 가능성을 기준으로 선택된 KV들은 복원 과정을 거치지 않더라도 다양한 질문에 대해 일반화 성능을 보였고, 이는 self-supervised learning이 다양한 다운스트림으로 일반화되는 원리와 닮아 있다는 식으로 연결합니다.
3.2 KV Importance Scoring
이 직관을 실제 점수로 바꾸는 과정이 3.2의 핵심 방법입니다. KVzip은 각 KV pair의 중요도를 컨텍스트 복원 과정에서 그 KV가 얼마나 많이 참조되었는가로 정량화합니다. 이를 위해 저자들은 teacher-forced decoding을 이용해 복원 과정을 시뮬레이션합니다. 구체적으로는 repeat prompt + 원래 컨텍스트를 하나의 입력 시퀀스로 붙여서(Figure 4), 한 번의 forward pass로 병렬화해 어텐션을 뽑습니다.
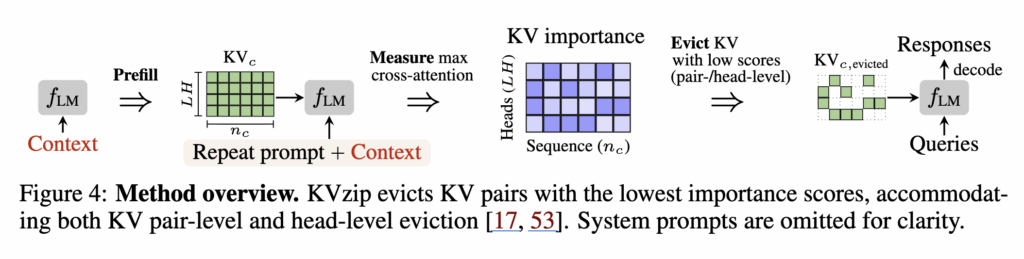
여기서 어떤 KV pair가 복원 과정 중 거의 어텐션을 받지 못했다면, 그 KV는 트랜스포머 계산에 기여하는 정도가 작고, 따라서 버려도 영향이 작을 가능성이 큽니다. 그래서 KVzip은 각 레이어 l, KV head h에 대해, prefilled 컨텍스트 KVc에 해당하는 key들만 골라낸 뒤, 그 key가 teacher-forced 복원 하는동안 받은 어텐션 값의 최댓값을 중요도 점수로 둡니다(식 (2)). 저자들은 이렇게 얻은 전체 점수 S를 maximum cross-attention scores라 정의합니다.
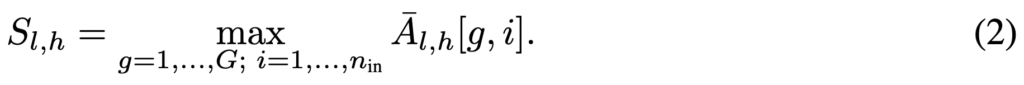
3.3 Observation
이제 이 점수를 통한 분석 결과를 두 가지로 제시합니다.
첫째, 복원(reconstruction)에서의 cross-attention은 매우 희소(sparse)하다는 점입니다(Figure 5).
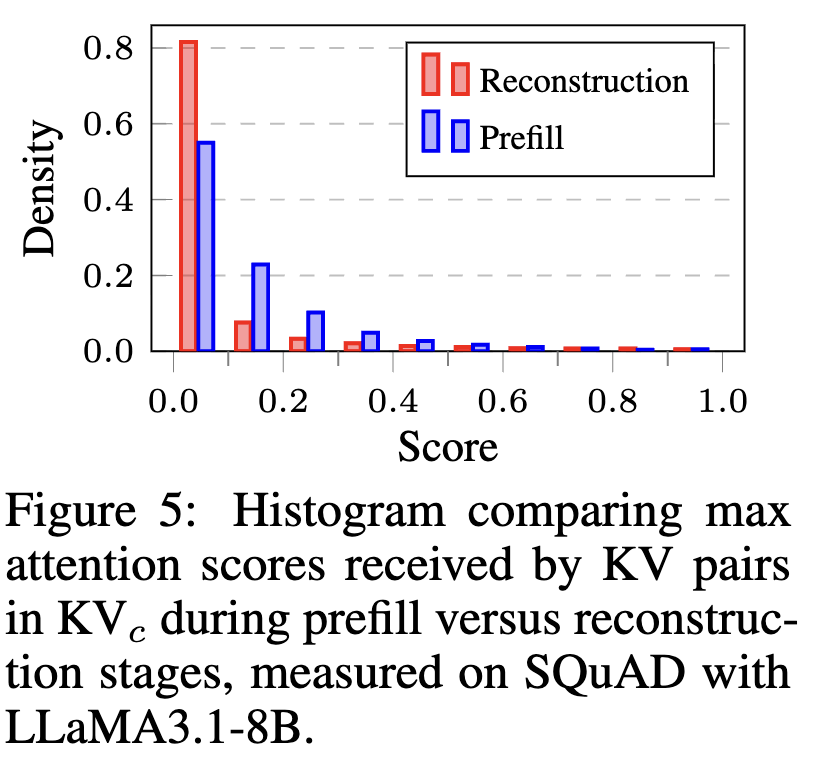
prefill 단계에서는 컨텍스트 토큰들이 서로 상호작용하면서 풍부한 표현을 인코딩해야 하므로 어텐션이 상대적으로 dense하게 나타납니다. 반면 복원 단계에서는 이미 KVc안에 저장된 고수준 표현과 모델 파라미터에 내재된 지식을 함께 활용할 수 있어, 불필요한 attention lookup을 줄이고 정말 필요한 KV만 참조하는 패턴이 나타난다는 겁니다. 이 희소성이 바로 중복 KV를 골라내서 제거할 수 있는 신호가 되고, prefill 어텐션을 그대로 쓰는 기존 H2O 같은 방식보다 더 잘 작동한다고 주장합니다.
둘째, 복원에서 중요했던 KV가 다른 태스크에서도 반복적으로 중요하게 쓰인다 점입니다(Figure 6).
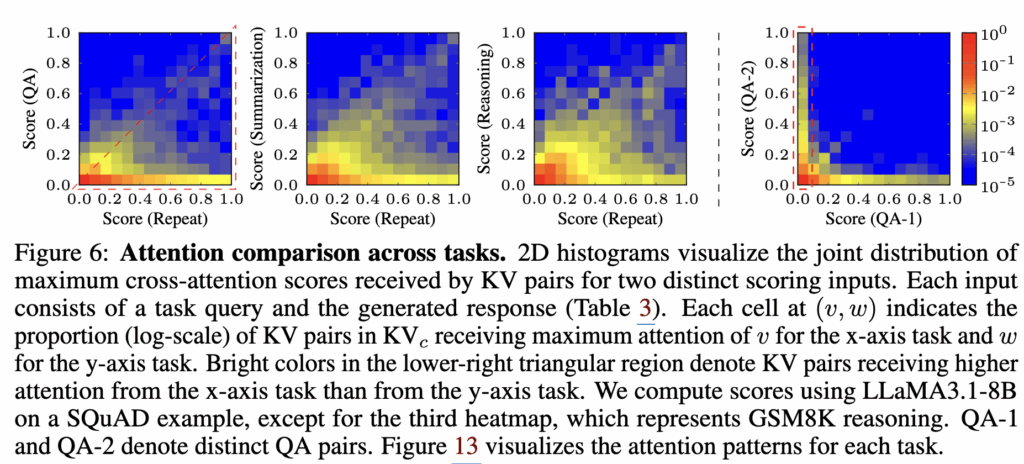
repeat, QA, summarization, reasoning 사이의 max cross-attention score를 비교하면, 앞의 세 태스크는 유사한 영역에 점수가 몰려 복원에 중요했던 KV가 다른 태스크에도 계속 중요하게 쓰인다는 신호를 보입니다. 반대로 서로 다른 QA 태스크끼리 비교하면 분포가 축 쪽으로 퍼지며, query-specific한 변동성이 나타납니다. 즉, 질의에 특화된 KV는 바뀌어도, 복원에 필수적인 KV는 태스크 전반에 공통으로 기여한다는 관찰이 KVzip의 일반화 근거가 됩니다.
3.4 Technical Challenge and Solution
여기까지는 깔끔한데 중요한 문제가 하나 있습니다. 어텐션 행렬은 길이에 대해 O(nc2)로 커져서, 롱컨텍스트에서 그대로 계산,저장하는 건 사실상 불가능합니다. FlashAttention 같은 fused kernel은 블록 단위로 계산해 메모리를 줄일 수 있지만, KVzip은 Softmax로 정규화된 어텐션 값 전체를 보고 나서, 쿼리 방향으로 최댓값(max)을 뽑아야 하는데 FlashAttention은 어텐션 전체를 만들지 않고 블록별 계산해야해서 이 구조와 잘 맞지 않습니다.
그래서 저자들은 해법으로 chunked scoring을 제안합니다. 컨텍스트를 길이 m의 고정 chunk로 쪼개고, 각 chunk에 대해서만 repeat prompt와 붙여서 독립적으로 복원을 시뮬레이션합니다(Figure 7).
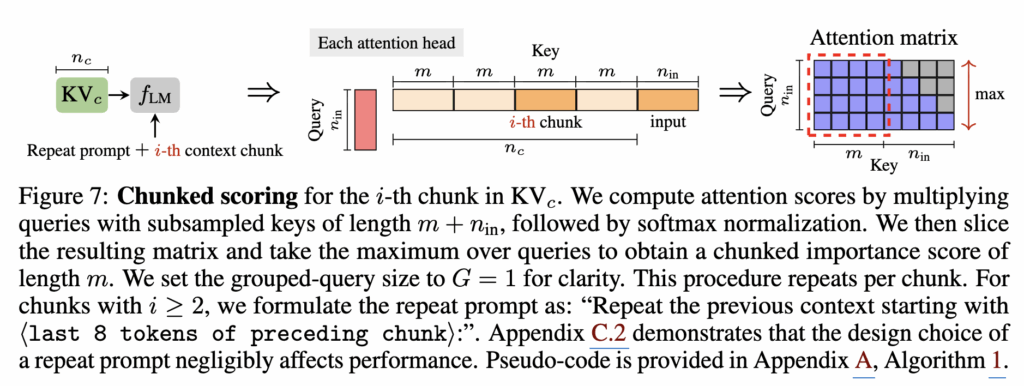
먼저 LLM의 prefill 단계에서 생성된 KV 캐시 KVc는 전체 컨텍스트 길이 nc를 가지는데, KVzip은 이를 한 번에 처리하지 않고 길이 m의 여러 작은 컨텍스트 청크로 분할합니다. 그런 다음 각 청크 i에 대해, 모델이 이전 컨텍스트를 다시 생성하도록 유도하는 repeat prompt와 해당 i-번째 컨텍스트 청크를 결합한 입력을 구성하고, 이 입력을 LLM에 통과시켜 쿼리 벡터를 생성합니다. 어텐션 계산 시에는, 전체 KV 캐시 중에서 현재 청크에 해당하는 키들만 선택하여 쿼리와 결합함으로써, 쿼리 길이와 키 길이에 대응하는 어텐션 행렬을 얻습니다. 이후 이 어텐션 행렬에서, 쿼리에 대응하는 부분만을 취해 각 키 토큰이 복원 과정 동안 받은 Max 어텐션 값을 계산하는데, 에게 해당 청크의 KV 중요도 점수가 됩니다. 이 과정을 모든 청크에 대해 반복하고 점수를 합치면 전체 KVc에 대한 중요도 분포를 얻을 수 있습니다. 결과적으로 이러한 청크화된 점수 계산 방식은, 컨텍스트 전체를 한 번에 처리할 때 발생하는 O(nc2) 어텐션 복잡도를 O(mnc)로 낮추고, 메모리 사용량도 청크 크기 m에 비례하도록 제한함으로써, 매우 긴 컨텍스트에서도 KVzip을 으로 적용할 수 있게 만듭니다.
4. Experiments
다음으로 실험 결과를 살펴보겠습니다.
4.1 Setup
Evaluation. 평가는 압축된 KV cache가 다양한 질문들을 얼마나 잘 처리하는가에 초점을 둡니다. 저자들은 2.2절에서 언급한 query-aware 방식의 한계를 고려해, Figure 1(c)의 query-agnostic 프레임워크를 선택합니다. 즉, task query 없이 컨텍스트만 먼저 prefill한 뒤 KV를 압축하고, 이렇게 만든 compressed KV cache를 가지고 단일/다중 질의에서의 평균 성능을 측정합니다. 평가는 SQuAD, GSM8K, Needle-in-a-Haystack(NIAH), SCBench의 9개 태스크로 구성됩니다.
4.2 Benchmarking
Task Generalization. Figure 9는 Qwen2.5-7B-1M에서 12개 벤치마크를 3개 카테고리로 묶어 multi-query 결과를 제시합니다.
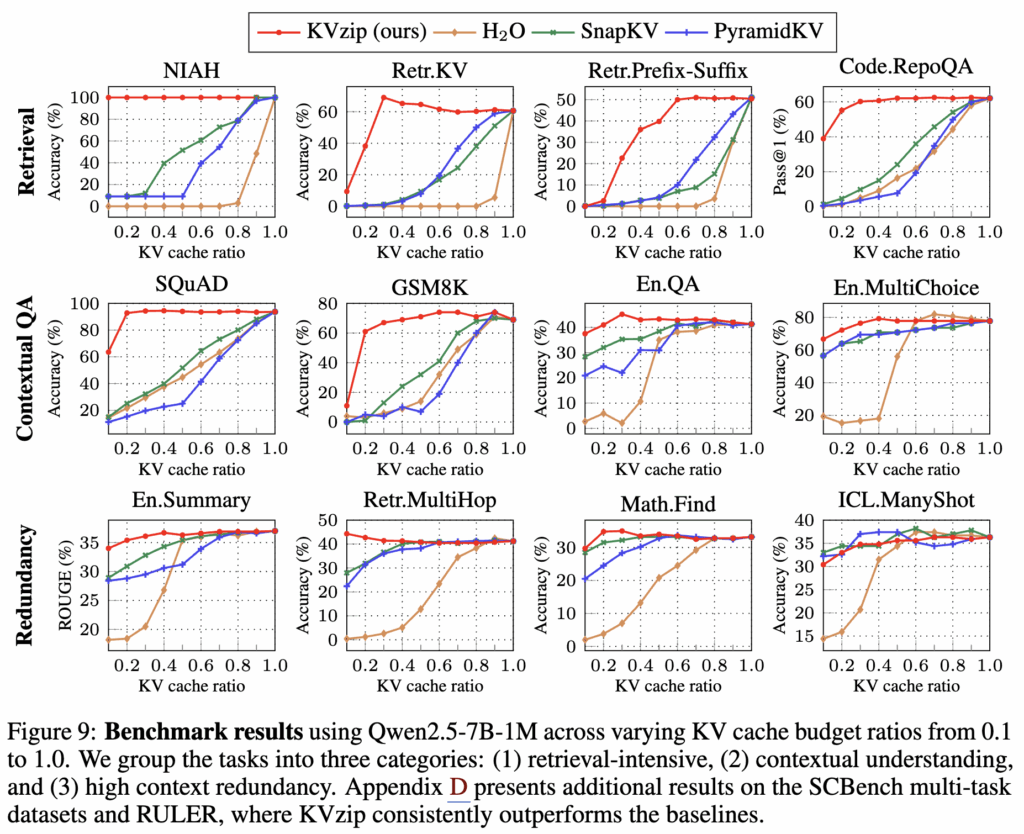
첫 번째 행은 문장/키/코드 함수 등 retrieval 중심 태스크로, KVzip은 cache ratio 30% 수준까지도 성능을 잘 유지하는 반면, baseline 방법들은 90% retention에서도 성능 저하가 크게 나타납니다. 두 번째 행은 문맥 이해/추론으로, KVzip은 더 많은 압축에서도 거의 손실 없이 유지되며 baseline 대비 일관되게 좋은 성능을 보여줍니다. 마지막 행에서 En.Summary는 고수준 문맥이 필요해 다른 태스크들과는 달리, 단순히 반복되는 정보를 찾는 것이 아니라 전반적인 내용을 파악해야 합니다. 이러한 특성 때문에 KV 캐시를 90%까지 압축해도 성능 저하가 거의 없습니다. 그리고 특정 경우에는 성능이 향상되기도 하는데, 이는 KV 캐시 제거로 인해 불필요한 어텐션의 방해가 줄어들었기 때문이라고 저자는 설명하고 있습니다.
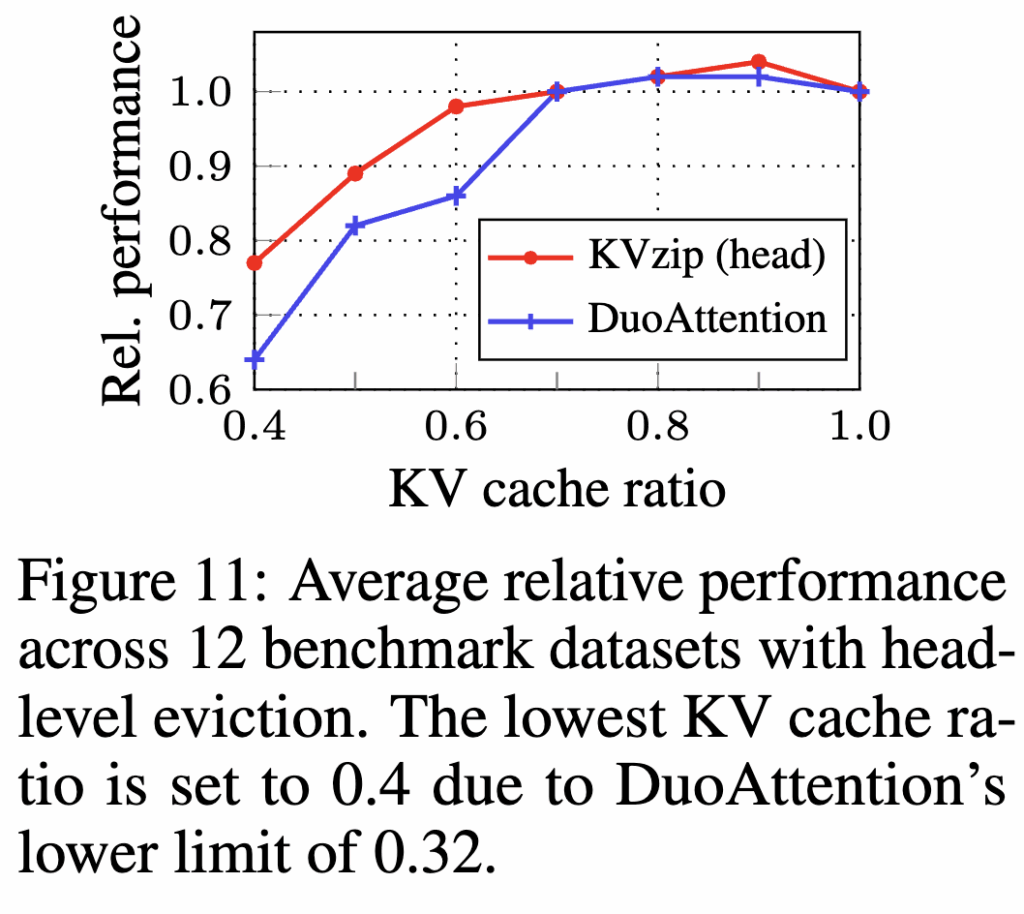
Context-Independent Eviction. KVzip은 배포 이후 오버헤드가 없는 context-independent eviction도 제안합니다. KVzip은 이를 위해 먼저 KV pair-level 점수를 계산한 뒤, 시퀀스 차원에서 최댓값으로 각 어텐션 헤드마다 고정된(head-level) 중요도 점수를 부여합니다. 저자들은 SCBench의 En.QA에서 가져온 88K 토큰짜리 영어 책 텍스트 샘플 하나로 이 head score를 한 번 산출하고, DuoAttention이 제안한 head-level KV eviction 방법을 적용합니다. 그 결과를 Figure 11에서 DuoAttention과 직접 비교하는데, DuoAttention은 합성(passkey) 정보를 잘 찾아내도록 head score를 최적화하는 방식이라 몇 시간의 계산이 필요하지만, KVzip은 자연어 텍스트에서 컨텍스트 복원(reconstruction)을 수행하면서 head score를 뽑기 때문에, 1분 내 몇 번의 forward pass만으로 점수 산출을 끝내면서도 평균 성능이 더 좋게 나옵니다. 즉, KVzip은 head-level로 캐시를 줄이며 성능이 안정적이고, 점수 산출 비용이 낮아 다양한 eviction 방법 중에서 효율성과 실용성을 보여주고 있습니다.
4.3 Analysis
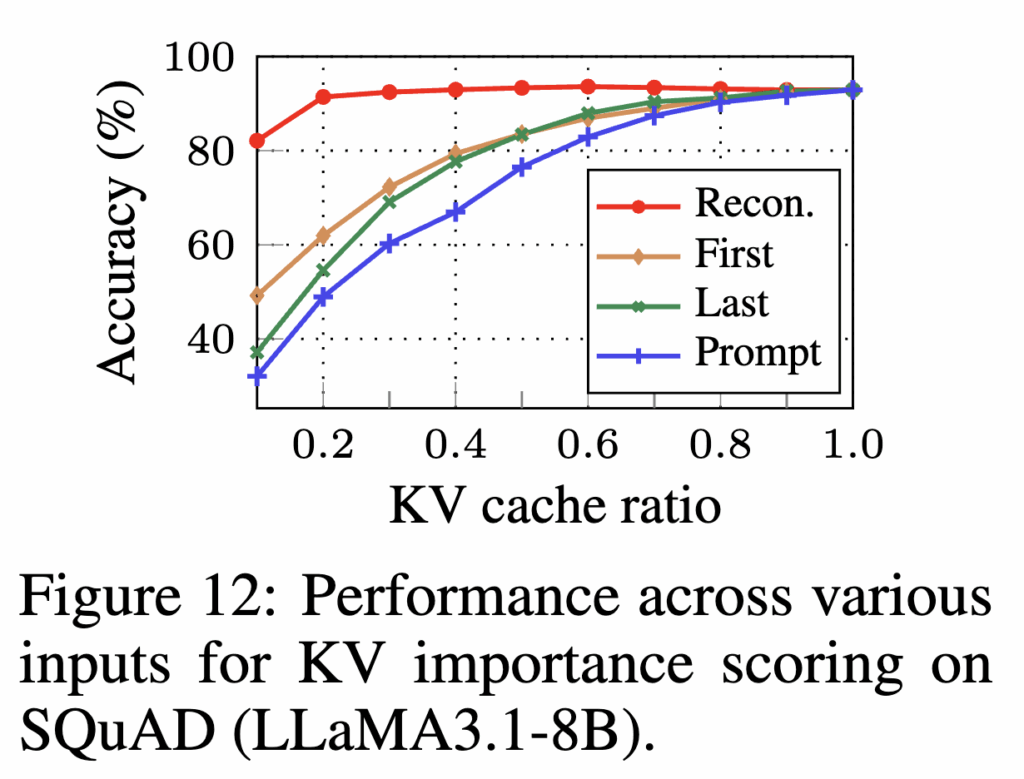
Necessity of Context Reconstruction. KVzip은 importance scoring 입력으로 repeat prompt + 전체 컨텍스트를 결합하는데(Figure 4), Figure 12는 이 full context reconstruction이 필수임을 보여줍니다. repeat prompt에 컨텍스트의 앞 10%(First)만 붙이거나, 뒤 10%(Last)만 붙이거나, prompt만 쓰는 경우(Prompt)와 비교했을 때, 전체 컨텍스트를 복원하도록 하는 입력(Recon) 이 KV eviction 후 성능 저하를 막는 데 가장 중요하다는 것을 보여줍니다.
Behavior Analysis Beyond Task Solving. 추가 분석으로, KV eviction이 프라이버시/얼라인먼트 측면에서 모델의 행동 변화를 만들 수 있음을 보여줍니다. Table 1에 따르면 LLaMA3.1-8B 인스트럭션 모델은 full KV cache를 사용할 때는 사적 정보 관련 질의에 거절(refusal) 하다가, KVzip으로 압축한 캐시를 쓰면 응답하는 사례가 나타납니다. 이는 KVzip이 “컨텍스트 복원에 필요한 KV”를 우선 보존하고 나머지를 버리는 과정에서 거절에 필요했던 신호가 압축 과정에서 같이 날아갈 수 있어서 모델이 원래는 거절했을 질문을, 압축 후엔 답변해버리는 행동 변화가 일어날 수 있다고 설명합니다. 따라서 저자는 KV eviction과 프라이버시, 안정성 등을 향후 연구 과제로 제안하며, 압축률,성능뿐 아니라 거절,안전 행동까지 함께 고려하는 평가와 기법 설계가 필요하다는 문제의식으로 마무리하고 있습니다.
