
- Conference: ICCV 2025
- Authors: Dohwan Ko, Ji Soo Lee, Minhyuk Choi, Zihang Meng, Hyunwoo J. Kim
- Affiliation: Korea University (고려대학교), Meta GenAI, KAIST (카이스트)
- Title: Bidirectional Likelihood Estimation with Multi-Modal Large Language Models for Text-Video Retrieval
- Code: GitHub (BLiM)
1. Introduction
Text-Video Retrieval은 주어진 텍스트에 대응되는 비디오, 혹은 비디오에 대응되는 텍스트를 검색하는 태스크입니다. 기존에는 CLIP이나 BERT 기반의 dual-encoder 구조가 주로 사용되었으며, 계산 효율은 높았지만 쿼리와 후보 간의 세밀한 의미 정렬에는 한계가 있었습니다. 이를 보완하기 위해 최근에는 멀티모달 대규모 언어 모델(MLLM)을 활용한 retrieval 방식이 제안되었습니다. MLLM은 쿼리와 후보를 함께 입력으로 처리하여 토큰 단위의 상호작용이 가능하고, 특히 길고 복잡한 쿼리에서 성능 향상을 보였죠
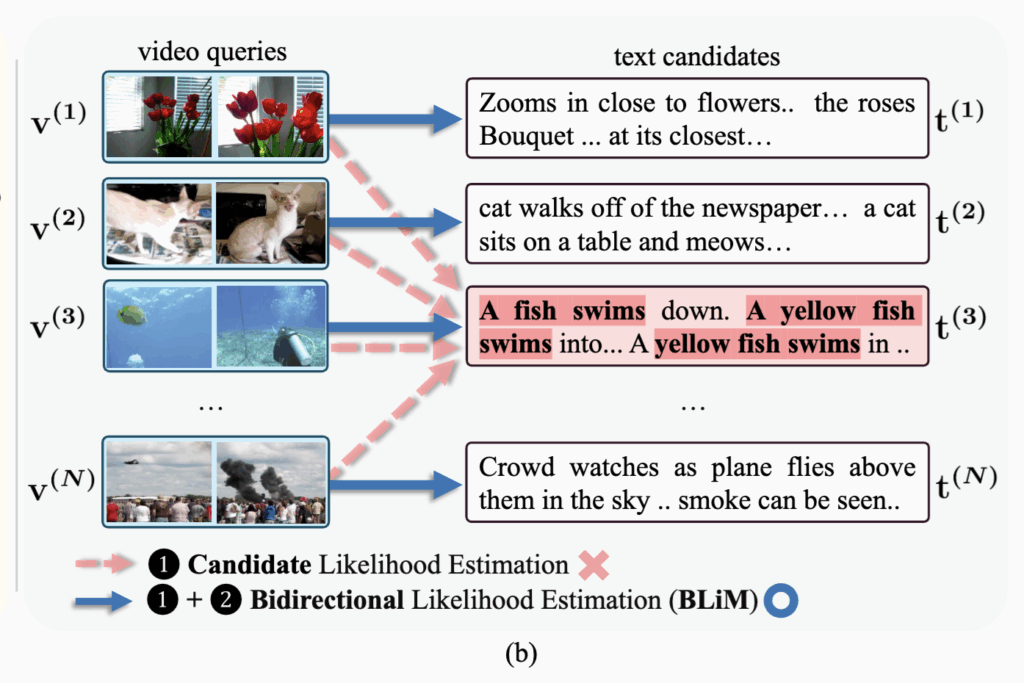
그러나 저자들은 MLLM을 단순히 candidate likelihood P(t|v) 기준으로 사용할 경우, 실제 쿼리와의 관련성보다 후보 자체의 prior에 편향되는 문제가 발생한다고 합니다. Figure 1(b)에 나타난 것처럼, 비디오 내용과 잘 맞지 않더라도 길고 반복적인 텍스트가 더 높은 점수를 받아 선택되는 현상이 나타난 것이었습니다.
이러한 candidate prior bias는 왜 발생하느냐? MLLM의 자기회귀적 특성으로 인해, 텍스트의 빈도나 형식에 과도하게 의존하기 때문이라고 하네요. 이는 비디오 정보를 충분히 활용하지 못하게 만들기도 한다고 합니다.
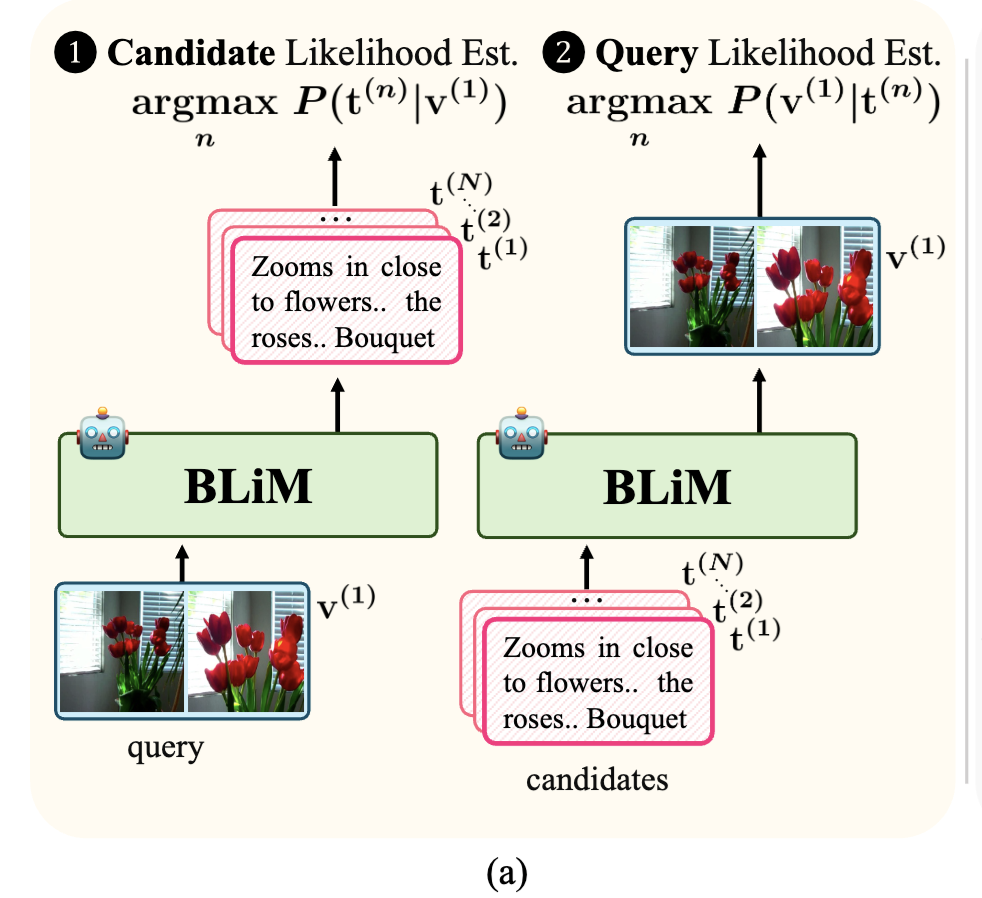
이를 해결하기 위해 본 논문에서는 Bidirectional Likelihood Estimation with MLLM(BLiM)을 제안했습니다. 상단 Figure 1(a)와 같이, BLiM은 비디오로부터 텍스트를 생성하는 likelihood와 텍스트로부터 비디오를 생성하는 likelihood를 함께 고려하여, 쿼리–후보 간의 의미적 정합성에 더 집중하도록 설계하였다고 합니다. 또한 저자들은 candidate likelihood에 포함된 prior 효과를 완화하기 위해, 학습 없이 적용 가능한 Candidate Prior Normalization(CPN) 기법을 함께 제안하였는데, 자세한 내용은 리뷰를 통해 알아보겠습니다.
2. Candidate Prior Bias
본격적인 설명 전에, MLLM 기반 Text-Video Retrieval에서 candidate likelihood를 그대로 사용할 경우 왜 bias가 발생하는지를 수식으로 설명하였습니다. 핵심은 retrieval 과정이 쿼리–후보 간의 실제 관련성보다, 후보 자체가 얼마나 “자주 등장하는지”에 영향을 받는다는 점입니다.
Video-to-text retrieval에서 일반적으로 사용되는 추론 방식은 다음과 같습니다. 주어진 비디오 v에 대해, 텍스트 후보 t^{(n)} 중 가장 높은 candidate likelihood P(t^{(n)} \mid v)를 가지는 후보를 선택.
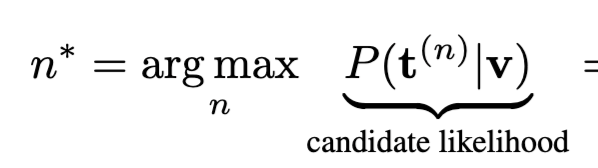
저자들은 이 식을 베이즈 정리로 다시 쓰면 문제가 드러난다고 설명합니다.
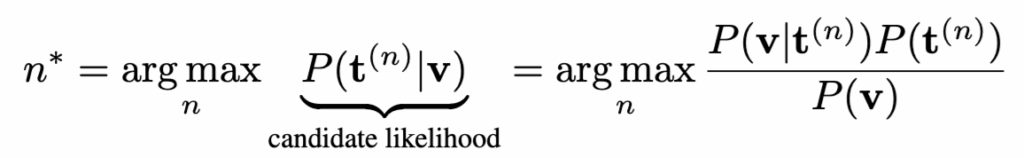
즉, candidate likelihood는 실제 쿼리와의 정합성을 나타내는 query likelihood P(v \mid t)와, 쿼리와 무관한 candidate prior P(t)의 곱으로 결정됩니다. 이상적으로는 query likelihood에 의해 ranking이 결정되어야 하지만, prior가 클 경우 retrieval 결과에 큰 영향을 미치게 되죠

저자들은 Proposition 1을 통해, query likelihood가 정답을 올바르게 구분하더라도 candidate prior가 충분히 크면 ranking이 뒤집힐 수 있음을 보이기도 했는데요. 다시 말해, 의미적으로 더 잘 맞는 후보보다, 자주 등장하는 후보가 선택되는 상황이 이론적으로도 발생 가능하다는 것입니다.
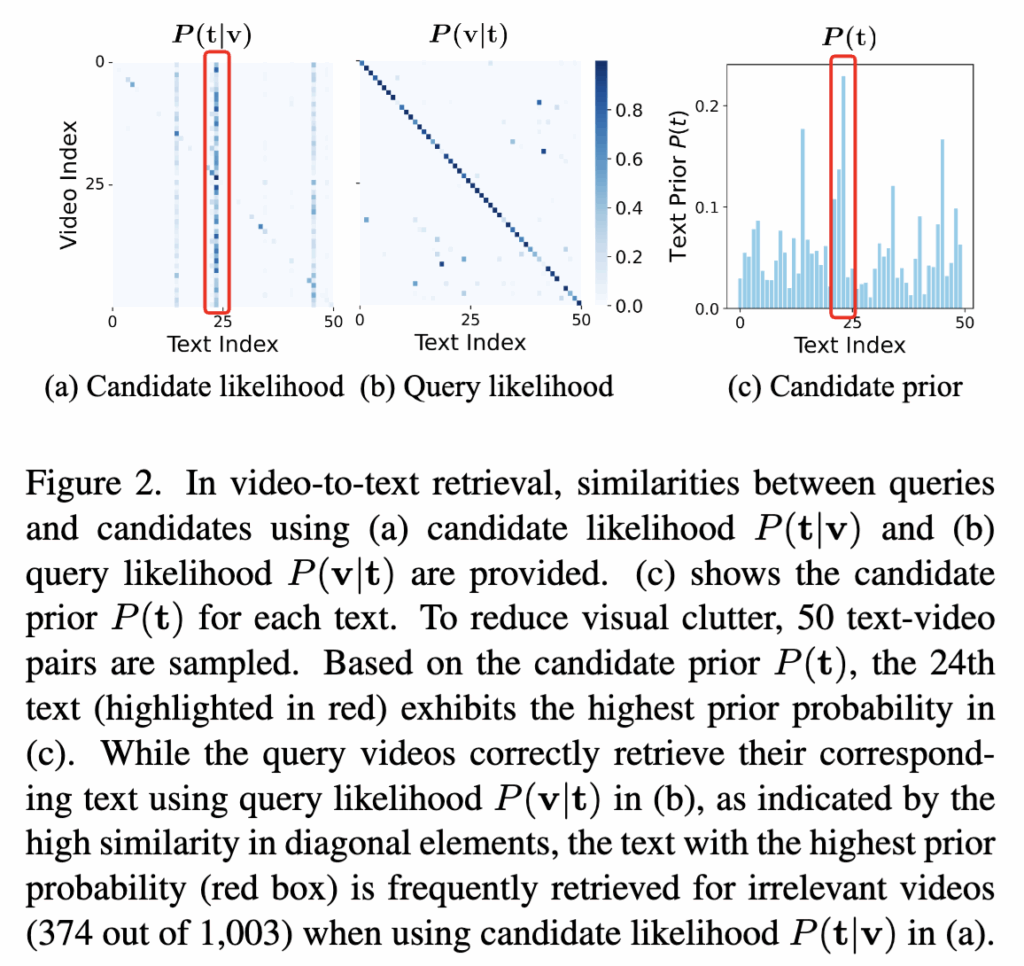
Figure 2에서 이러한 현상을 직관적으로 확인할 수 있는데요. Query likelihood 기준(Fig. 2b)에서는 비디오와 텍스트가 올바르게 대응되지만, candidate likelihood 기준(Fig. 2a)에서는 특정 텍스트 하나가 여러 비디오에 반복적으로 선택됩니다. 이는 Fig. 2c에서 보이듯 해당 텍스트가 가장 높은 candidate prior를 가지기 때문이라고 합니다.
말이 어렵지 이 파트는 MLLM 기반 retrieval은 “비디오를 보고 고르는 것처럼 보이지만, 실제로는 텍스트를 보고 고르는 경우가 많다”는 문제를 수식적으로 보인 것이죠
Text-Video Retrieval에서 MLLM을 쓰면 보통 이렇게 합니다. “이 비디오를 보고, 이 텍스트가 나올 확률이 얼마나 될까?” 이 확률이 높은 텍스트를 정답으로 고르는 방식이죠. 문제는, 이 확률이 비디오 내용만 보고 결정되는 게 아니라는 점입니다.
이 문장이 비디오랑 잘 맞아서가 아니라, 이 문장이 모델이 좋아하는 문장이어서 계속 뽑힌 것이 기존 문제라고 이해하시면 됩니다.
3. Method
3.1 Bidirectional Likelihood Estimation of MLLM
앞선 분석을 바탕으로, 저자들은 기존 MLLM이 주로 비디오→텍스트 likelihood P(t|v)만 최대화하도록 학습된다는 점이 candidate prior bias의 원인이라 하였는데요. 이를 해결하기 위해, 본 논문에서는 비디오와 텍스트 양쪽 방향의 likelihood를 동시에 고려하는 BLiM(Bidirectional Likelihood Estimation with MLLM)을 제안합니다.
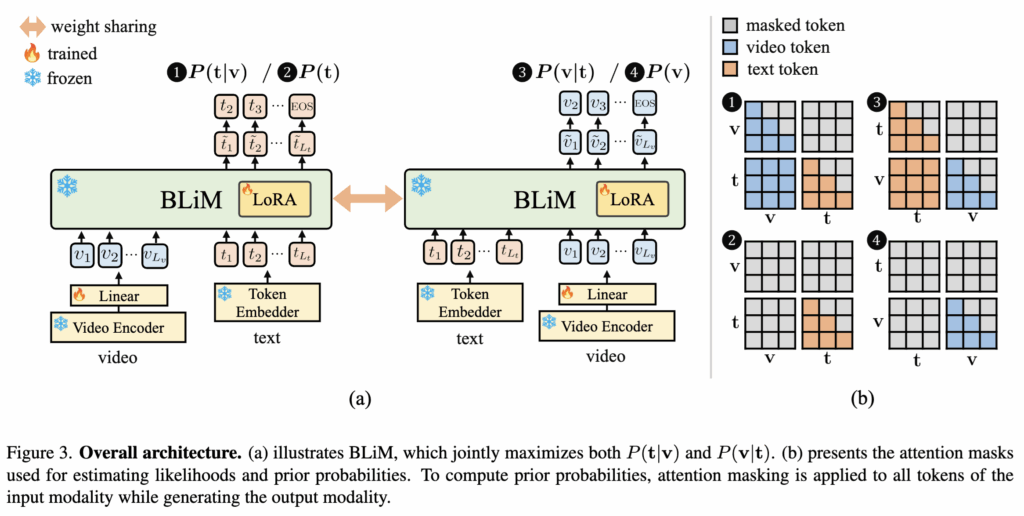
BLiM은 기본적으로 사전 학습된 Video MLLM인 VideoChat-Flash 7B를 기반으로, 입력 비디오는 여러 개의 clip으로 분할된 뒤, 비디오 인코더를 통해 clip 단위의 시각적 특징을 추출합니다. 이후 이 특징들은 선형 projection layer를 거쳐 LLM의 임베딩 공간으로 매핑되며, 텍스트 토큰과 함께 LLM에 입력됩니다. 이 과정에서 학습되는 파라미터는 projection layer와 LoRA 모듈에 한정되어, 비교적 효율적인 fine-tuning을 수행하죠
학습 과정에서 BLiM은 두 가지 likelihood를 동시에 최대화하도록 설계되었습니다. 첫 번째는 기존 MLLM과 동일한 video-grounded text generation, 즉 비디오가 주어졌을 때 텍스트를 생성하는 likelihood P(t|v)입니다. 이는 텍스트를 autoregressive하게 생성하면서, 각 토큰의 확률을 최대화하는 일반적인 언어 모델 학습 방식과 동일합니다.
두 번째는 본 논문의 핵심 차별점인 text-grounded video feature generation, 즉 텍스트가 주어졌을 때 비디오 clip feature를 순차적으로 예측하는 likelihood P(v|t)입니다. 여기서는 이전 clip들과 텍스트를 조건으로 다음 clip feature를 맞히는 방식으로 학습이 진행되며, softmax를 통해 여러 후보 clip 중 올바른 clip을 선택하도록 합니다. 이를 통해 모델은 텍스트와 시간적으로 일관된 비디오 표현을 함께 학습하게 됩니다.
최종적으로 BLiM은 이 두 likelihood를 단순히 합산한 Loss를 통해 학습됩니다.
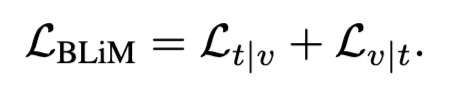
이렇게 학습된 BLiM은 추론 단계에서 두 likelihood를 함께 사용해 최종 retrieval 결과를 결정합니다. Video-to-text retrieval의 경우, 주어진 비디오 쿼리에 대해 텍스트 후보가 비디오로부터 얼마나 잘 생성될 수 있는지에 해당하는 candidate likelihood P(t|v)와, 해당 텍스트가 다시 비디오를 얼마나 잘 설명할 수 있는지를 나타내는 query likelihood P(v|t)를 합산하여 점수를 계산합니다. 즉, “비디오가 이 텍스트를 만들 가능성”과 “이 텍스트가 비디오를 만들 가능성”을 동시에 고려하는 방식이죠
Text-to-video retrieval에서도 동일한 아이디어가 적용되지만, 쿼리와 후보의 역할만 서로 바뀝니다. 이 경우에는 텍스트 쿼리에 대해 비디오가 생성될 가능성과, 해당 비디오로부터 텍스트가 생성될 가능성을 함께 고려하여 최종 후보를 선택합니다. 저자들은 이러한 양방향 likelihood 결합이, 특정 후보가 모델 내부에서 자주 등장한다는 이유만으로 선택되는 현상을 완화하는 데 효과적이라고 설명합니다.
직관적으로 보면, candidate likelihood는 “이 쿼리로부터 이 후보가 나올 법한가”를 평가하는 반면, query likelihood는 “이 후보로부터 이 쿼리가 나올 법한가”를 평가합니다. BLiM은 이 두 관점을 동시에 사용함으로써, 단방향 likelihood에서 발생하던 candidate prior bias를 줄이고, 쿼리와 후보 간의 의미적 정합성에 기반한 retrieval을 수행하고자 한 것이죠
3.2 Candidate Prior Normalization (CPN)
BLiM은 양방향 likelihood를 통해 candidate prior bias를 줄이지만, 저자들은 이를 추론 단계에서 더 직접적으로 완화하는 방법으로 Candidate Prior Normalization(CPN)을 추가로 제안합니다. 핵심 아이디어는 단순합니다. candidate likelihood에 포함된 prior 성분을 점수 계산에서 의도적으로 약화시키는 것입니다.
앞서 보았듯이, video-to-text retrieval에서 사용되는 candidate likelihood P(t \mid v)는 query–candidate 정합성과 무관한 candidate prior P(t)의 영향을 함께 포함하고 있습니다. CPN은 이 중 prior 항의 영향을 제거하거나 줄이기 위해, candidate likelihood를 P(t)^\alpha로 나누어 정규화합니다. (\alpha \in [0,1]는 prior를 얼마나 강하게 억제할지를 조절하는 하이퍼파라미터)
로그 스케일에서 보면, 이는 기존 점수 P(t \mid v)에서 \alpha \log P(t)를 빼주는 형태로 해석할 수 있다고 합니다. 즉, “자주 등장해서 점수가 높은 후보”에 패널티를 주는 방식이라고 이해하면 됩니다. 동일한 정규화는 text-to-video retrieval에서도 비디오 prior P(v)에 대해 대칭적으로 적용됩니다.
재밌는 점은 CPN이 추가 학습 없이 inference 단계에서만 적용되는 training-free 기법이라는 점입니다. 저자들은 이 간단한 정규화만으로도 retrieval 성능이 안정적으로 향상되며, candidate prior bias가 눈에 띄게 완화되었다고 실험을 통해 보이기도 하였습니다.
4. Experiment
4.1 Comparison with state-of-the-art models.
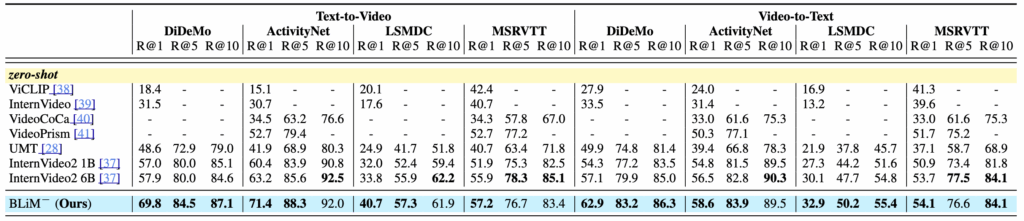
Table 1에서는 BLiM을 기존 모델들과 비교한 결과를 보여줍니다. 먼저 zero-shot 설정에서는, 사전 학습된 MLLM이 P(t \mid v)만 사용할 수 있다는 한계로 인해 query likelihood 없이 CPN만 적용한 BLiM⁻을 사용합니다. 그럼에도 불구하고 BLiM⁻은 기존 SOTA인 InternVideo2 6B 대비 평균 R@1 기준 4.9 향상을 보이며, 단순한 prior 정규화만으로도 의미 있는 성능 개선이 가능함을 보여줍니다.
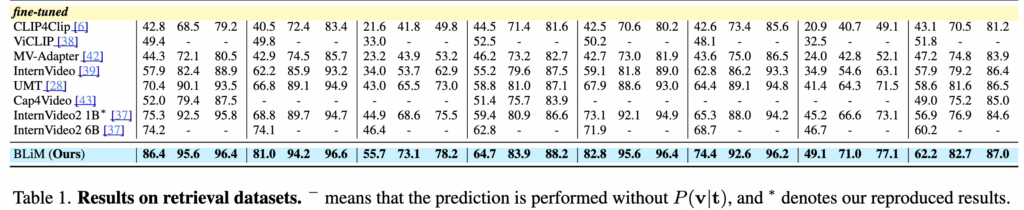
Fine-tuning 설정에서는 양방향 likelihood를 모두 활용한 BLiM이 모든 벤치마크에서 가장 뛰어난 성능을 보였습니다. 특히 DiDeMo의 text-to-video retrieval에서는 InternVideo2 6B 대비 R@1이 12.2 향상되었으며, 전체 데이터셋 평균 기준으로도 6.4의 R@1 차이를 보였습니다.
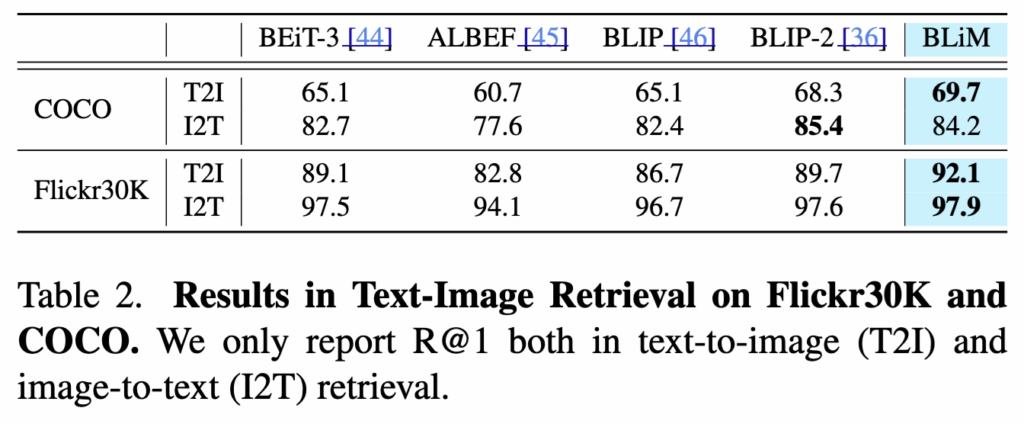
Text-Image Retrieval로의 확장 실험 결과도 보였습니다. 이 경우 P(v \mid t)에서 비디오 clip 시퀀스를 예측하는 대신, 단일 이미지 feature를 직접 예측하도록 구조를 단순화하였고, P(t \mid v)는 기존과 동일하게 유지하였습니다.
Table 2의 결과에 따르면, BLiM은 Flickr30k와 COCO 데이터셋에서 BLIP-2를 포함한 기존 Text-Image Retrieval 모델들을 전반적으로 뛰어넘는 성능을 보였습니다. 특히 Flickr30k의 text-to-image retrieval에서는 R@1 기준으로 BLIP-2 대비 2.4 향상을 기록하며, 양방향 likelihood 추정이 이미지 기반 retrieval에서도 효과적으로 작동함을 보여줍니다.
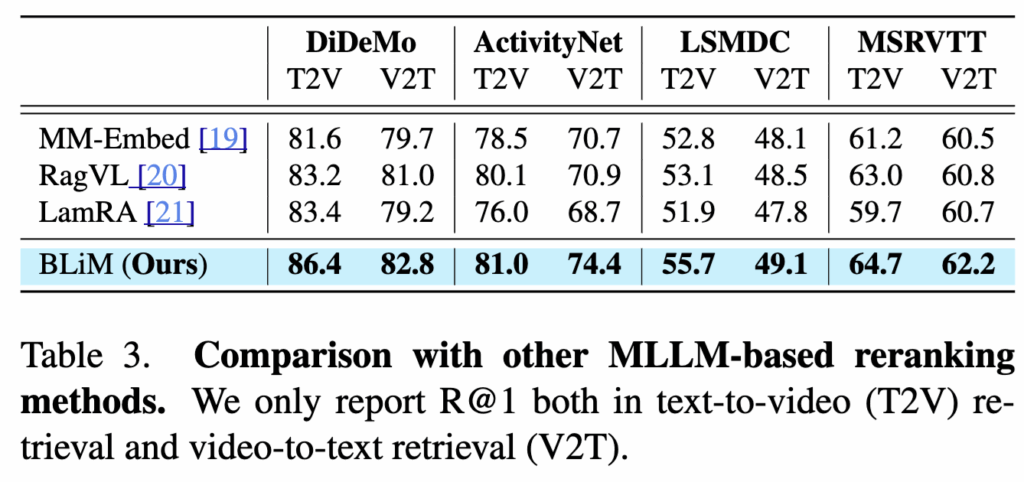
저자들은 BLiM을 기존 MLLM 기반 retrieval 방법들과 비교하여, 단순한 프롬프트 기반 정합성 판단 방식과의 차이도 실험으로 보였는데요. 예를 들어 MM-Embed는 쿼리–후보 쌍이 맞는지를 True/False로 판단해 재랭킹하는 반면, BLiM은 양방향 likelihood 추정을 통해 쿼리와 후보가 서로를 생성할 수 있는지를 직접 평가한다고 합니다.
즉, 동일한 MLLM 백본과 동일한 reranking 조건에서 실험한 결과, BLiM은 모든 데이터셋에서 기존 MLLM 기반 방법들을 일관되게 뛰어 넘고, 이는 양방향 likelihood 추정이 MLLM 기반 retrieval에 효과적인 정합성 신호를 제공함을 보여주는 결과라고 합니다.
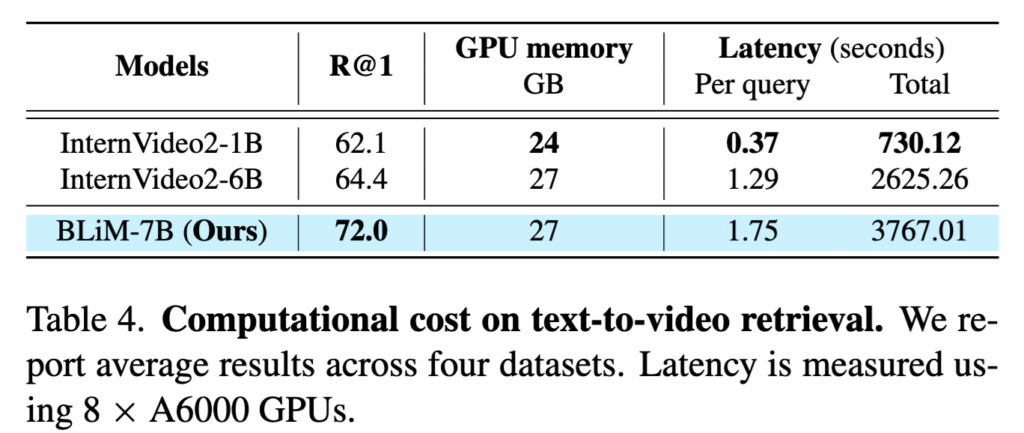
BLiM의 계산 비용 결과도 InternVideo2와 비교하였습니다. BLiM은 1차로 경량 모델을 사용해 후보를 추린 뒤, 양방향 likelihood 기반으로 재랭킹하는 two-stage 구조를 사용하기 때문에 전체 추론 시간에는 1차 retrieval 비용이 포함됩니다. 그럼에도 불구하고, BLiM은 InternVideo2 6B 대비 R@1 성능을 크게 향상시키면서도, 쿼리당 약 0.46초의 latency만 발생시키고 GPU 메모리 사용량도 유사한 수준. 이는 BLiM이 높은 성능 향상을 비교적 작은 계산 비용 증가로 달성했음을 보여주는 결과라고 하네요.
4.2 ABlation Studies
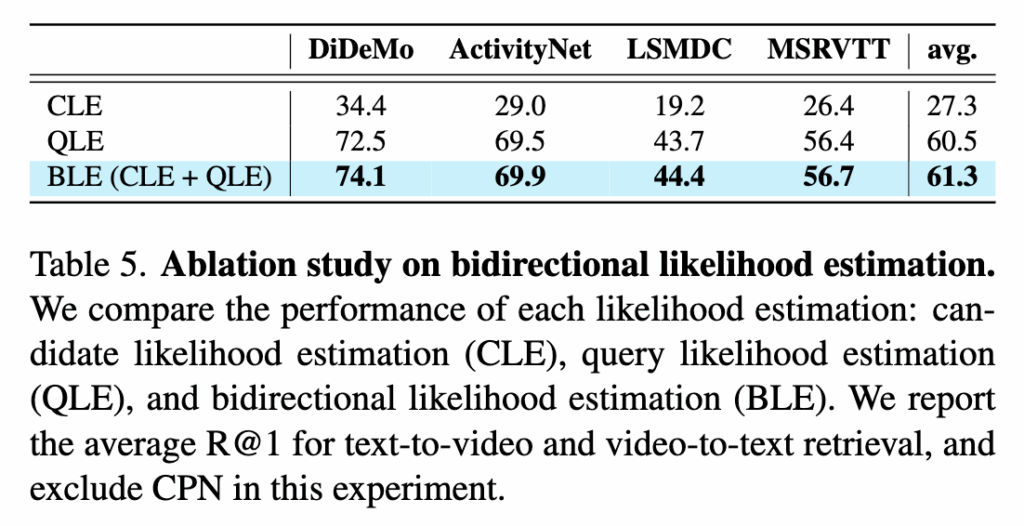
bidirectional likelihood estimation의 효과를 검증하기 위해, CPN을 제외한 상태에서 ablation 실험을 수행했습니다. 실험 결과, candidate likelihood만 사용하는 경우(CLE)는 후보의 prior에 크게 영향을 받아 성능이 저하되는 반면, query likelihood(QLE)를 추가하면 모든 데이터셋에서 R@1 성능이 크게 향상되는 것을 확인했습니다. 또한 query likelihood만 사용하는 경우보다, 두 likelihood를 함께 사용하는 bidirectional 방식(BCE)이 추가적인 성능 향상을 보였습니다.
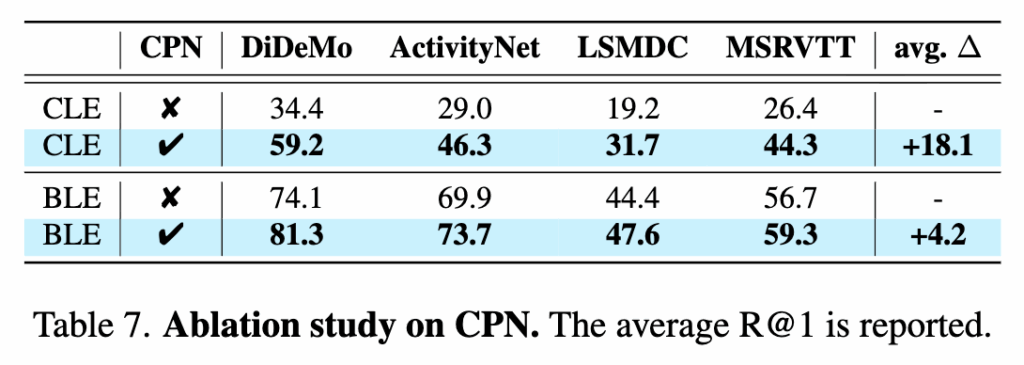
마지막으로 CPN ablation 실험 결과입니다. candidate likelihood에 CPN을 적용했을 때 모든 데이터셋에서 R@1 성능이 크게 향상되는 것을 확인했습니다. 또한 bidirectional likelihood 설정에서도 CPN을 추가하면 평균적으로 추가적인 성능 개선이 나타났습니다.
Conclusion
본 논문은 MLLM 기반 Text-Video Retrieval에서 candidate prior bias가 성능 저하의 주요 원인임을 지적하고, 이를 해결하기 위해 bidirectional likelihood estimation과 CPN을 제안했습니다. 제안한 BLiM은 쿼리–후보 간의 의미적 정합성에 보다 집중하도록 설계되었으며, 다양한 벤치마크에서 일관된 성능 향상을 보였습니다.
이 논문의 가장 큰 장점은 MLLM retrieval에서 막연히 사용되던 likelihood를 ‘왜 틀리는지’의 관점에서 재해석했다는 점 같습니다. 다만 two-stage retrieval에 의존하는 구조이기 때문에, end-to-end retrieval로의 확장이나 대규모 후보 환경에서의 한계는 향후 추가 검증이 필요할 것 같기도 합니다