안녕하세요 최인하입니다. 이번에는 Diffusion Policy에 대해서 리뷰하겠습니다. 항상 해야지 해야지 했었던 논문인데, 이해하는데 background가 필요했던 논문이라 오래걸렸던 것 같습니다. 아직까지 완전히 이해한건 아닌 것 같지만 리뷰하면서 또 공부해보겠습니다.
Abstract
Diffusion Policy를 간략하게 소개한다면 conditional denosing diffusion process를 통해, 로봇의 visuomotor policy를 표현하는 모델입니다. visuomotor policy란 vision 정보를 입력받아 로봇이 어떠한 행동을 해야하는지 출력하는 function, distribution 정도라고 이해하면 될 것 같습니다. DP는 기존의 policy를 표현하는 robot learning method들이 잘 표현하지 못했던 multimodal action distribution을 잘 표현했으며, robot의 높은 자유도도 잘 처리하였고, training stability도 보여줬습니다. 이로인해 압도적인 성능 차이를 보이며 SOTA를 달성했죠. 어떻게 가능했는지 설명해보겠습니다.
Diffusion Policy Formulation
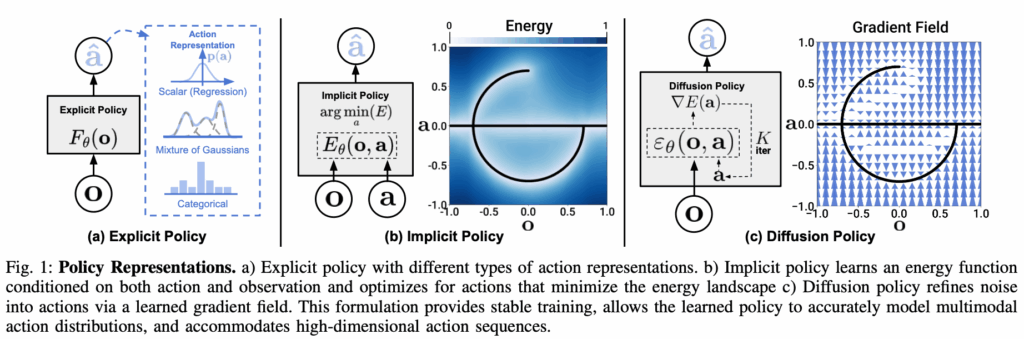
제가 생각하는 DP의 핵심은 robot policy를 Denoising Diffusion Probabilistic Models(DDPM) 방식으로 표현한 것입니다. 기존의 모델들은 Fig1 (a) 에서 보는 것과 같이 visomotor policy를 표현할 때 supervised regression task로 표현해서 action이 하나로 정해지거나 different action을 표현하기 위해 Mixture of Gaussians을 사용하거나, Categorical로 양자화하여 표현했습니다. 하지만 Mixture of Gaussians을 사용해서 multimodal action distribution 을 표현하기에는 가우시안을 혼합하기 복잡하였고, Categorical을 사용할경우 많은 action이 주어졌을 때 bin의 수가 매우 많아질 수 있다는 문제점이 존재하였습니다. 따라서 DP는 visuomotor policy를 DDPM으로 representation 함으로써 위와 같은 문제를 해결하였습니다.
Denoising Diffusion Probabilistic Models(DDPM)
DDPM에 대해서 간략하게 설명하겠습니다. 우선 생성형 모델이란 주어진 데이터를 잘 설명하는 분포를 학습하고, 그 분포를 통해 새로운 데이터를 생성할 수 있는 모델입니다. 하지만 주어진 데이터의 분포를 모르기 때문에 이를 likelihood로 나타내는 것은 너무 어려웠습니다. 따라서 DDPM은 데이터 분포의 likelihood를 직접 학습하는 대신 각 noise level에서 정의 되는 분포의 score 즉 log-likelihood가 증가하는 방향을 학습함으로써 denoising 과정을 통해 데이터를 생성합니다.

DDPM의 학습 과정을 보면 원본 이미지와 Forward process(원본 이미지 x0에서 점진적으로 노이즈를 추가하여 xt 최종적으로 가우시안 노이즈가 된 상태까지 진행)가 진행 된 상태에서 0~t의 sample 중 하나를 random으로 선택하여 모델은 원본 이미지로 부터 얼만큼의 노이즈가 추가 된 것인지 학습합니다. 위에서는 noise level에서의 score를 학습한다고 하였는데 여기서는 noise의 MSE로 loss가 정의 되었는데요. DDPM에서는 계산하기 어려운 분포의 log-likelihood 문제를 ELBO(Evidence Lower Bound)를 사용해서 Forward process와 Reverse process(노이즈를 순차적으로 제거하는 과정)의 KL-divergence 문제로 풀어내어 결과적으로 noise의 MSE로 loss function이 정의 됩니다. 훨씬 간단해졌죠!

Sampling 과정에서는 학습된 noise function을 가지고 가우시안 노이즈가 들어왔을 때 노이즈를 점진적으로 제거하여 데이터를 생성합니다. 좀 더 풀어쓰면 각 noise level에서의 score를 예측하여 데이터 분포를 따르는 샘플을 샘플링 하는 과정이라고 생각하시면 될 것 같습니다. 이 과정을 stochastic langevin dynamics이라고도 합니다. DDPM을 설명해야 뒤에 나올 내용들이 더욱 이해가 잘 될 것 같아서 간략하게 설명해봤습니다.
Multimodal distribution & High dimensional output space
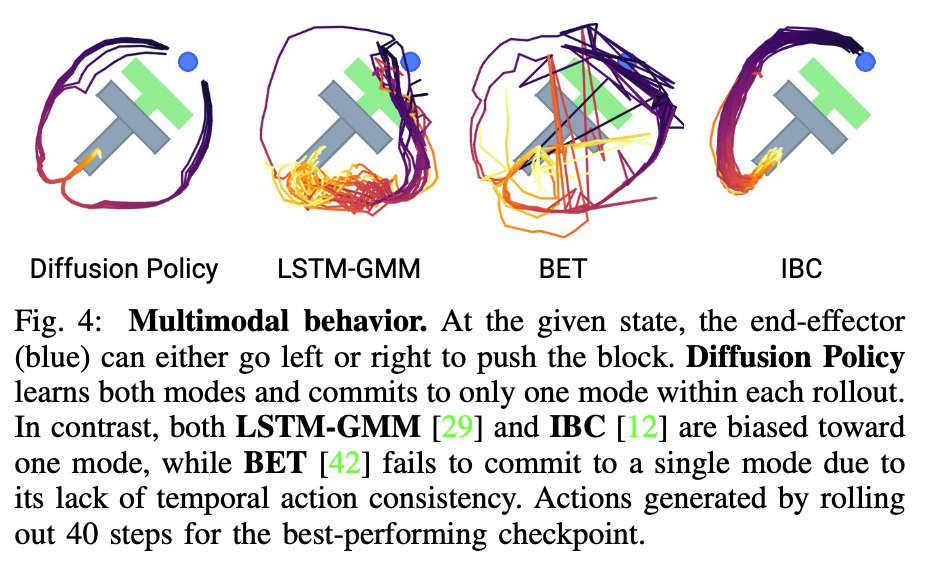
Multimodal distribution이란 task를 수행할 때 여러 타당한 행동들(demonstration 과정에서 수행한 여러 동작들)의 분포입니다. 위에서는 push T task를 예시로 들었습니다. 저는 더욱 이해하기 쉽게 T를 나무로 보고 점을 운전자라고 생각하고 설명하겠습니다. 운전을 하고 가는데 앞에 나무가 있으면 저희는 왼쪽으로 피할 수도 있고 오른쪽으로 피할 수도 있을 것입니다. 여러 취할 수 있는 행동들이 있겠죠. 기존의 모델들은 이러한 여러 행동들을 잘 나타내지 못했습니다. 하나로 정해버리거나, action이 불안정했죠. 하지만 DP는 위에서 설명한 DDPM 방식으로 action distribution의 score를 예측하여 확률적으로 진행하므로(stochastic langevin dynamics) 다양한 Multimodal action을 표현할 수 있게 됩니다. 하지만 확률적으로 action을 하나 표현한다면 진행하는 과정에서 예시를들면 BET 방식처럼 진동할 수 있겠죠. 여기서 High dimensional output space의 장점이 나타납니다. DDPM 방식은 고차원 image를 처리하는 모델이었으므로, 고차원 데이터를 다루기에 충분합니다. 따라서 DP는 각 로봇 조인트의 action을 sequential하게 예측해서 뽑아냅니다. 따라서 DP는 observation을 통해 지나온 과정을 알게되고, action을 sequentail하게 뽑아내므로 부드러운 motion이 가능해집니다.
Training stability
DP는 training 과정에서 안정적입니다. 이로인해 training을 어디서 멈추고 deploy를 해야 될지 알기 쉽습니다. 왜 이런 장점을 가져갈 수 있었을까요? 위에서 언급한 것 처럼 데이터의 분포는 복잡하고 구하기 어렵습니다. 즉 저희가 알 수 없죠. Energy based model들은 확률 분포를 정의하기 위해 다음과 같이 표기하지만 Z를 계산하기가 불가능하다고 합니다. 따라서 Z를 근사하기 위해서 negative sample을 사용하는데 이와 같은 기법들이 training을 불안정하게 만든다고 합니다.
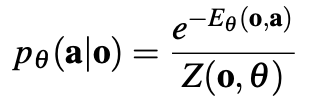
하지만 DDPM을 사용하는 DP는 action distribution의 score gradient를 학습하므로, 미분할 경우 Z는 0으로 사라지게 되는 이점이 있습니다. 따라서 학습이 더욱 안정적이라고 합니다.
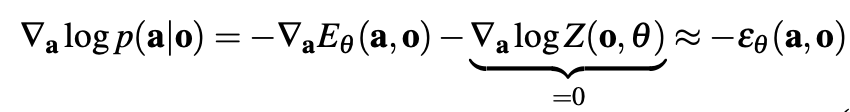
Model architecture
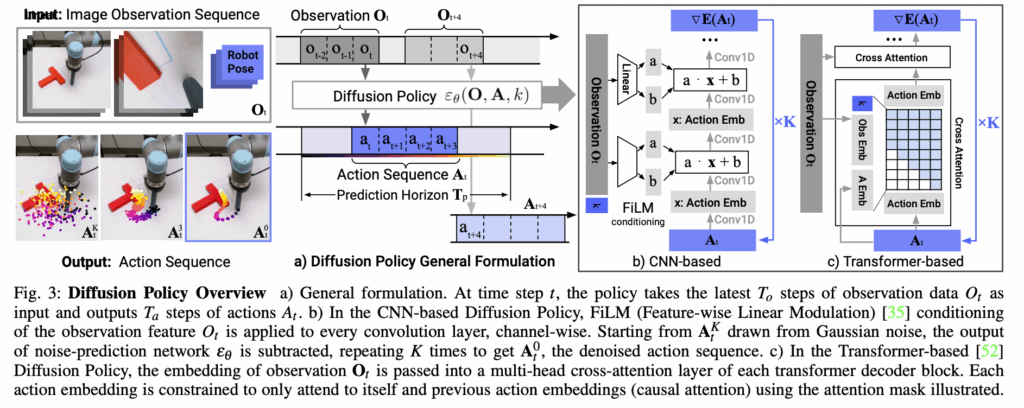
DP의 architecture는 위와 같습니다. 위에서 설명한 것처럼 Input으로 observation 이 들어가고 condition으로 사용됩니다. 그 후 노이즈를 예측하여 action을 sampling하는 과정에서 CNN 또는 Transformer가 사용됩니다. 논문에서는 CNN은 action trajectory의 예측만 수행한다고 하며 observation은 condition으로 주입하기 위해 FiLM구조를 사용한다고 합니다. Transformer는 디코더 구조를 사용했다고 합니다. 논문에서는 CNN 구조가 대부분 task에서 좋은 성능을 보였으나 action sequences 가 빠르게 변화하는 task에서는 Transformer보다 안좋은 성능을 보인다고 합니다. 이를 cnn의 low – frequency signal inductive bias라고 표현하네요.
model은 Tp만큼 sequential하게 action prediction 을 수행합니다. 그리고 실제로 수행되는 action은 At만큼 수행됩니다. 위에서 이 절차 덕분에 부드러운 motion이 가능해진다고 설명했습니다. 또한 closed loop 시스템으로 action을 한번에 수행하는 것이 아니라서(At) observation이 즉 condition이 변화했을 때 그에 맞는 action을 계속 수행하게 됩니다.
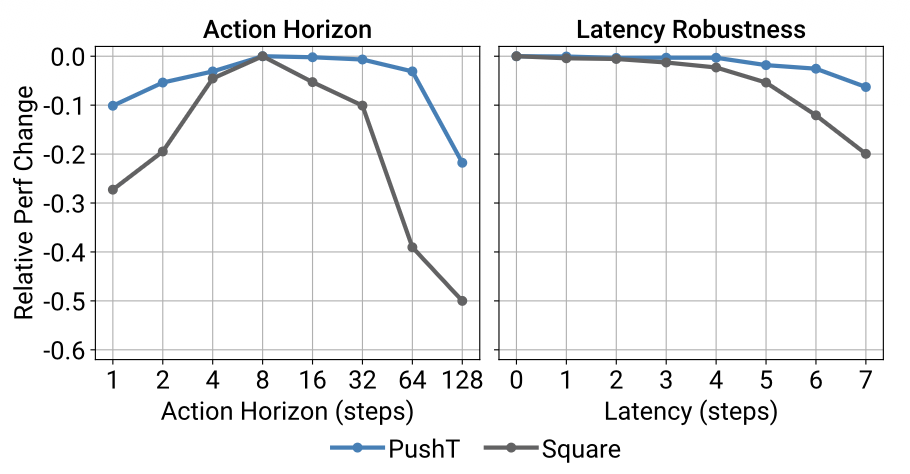
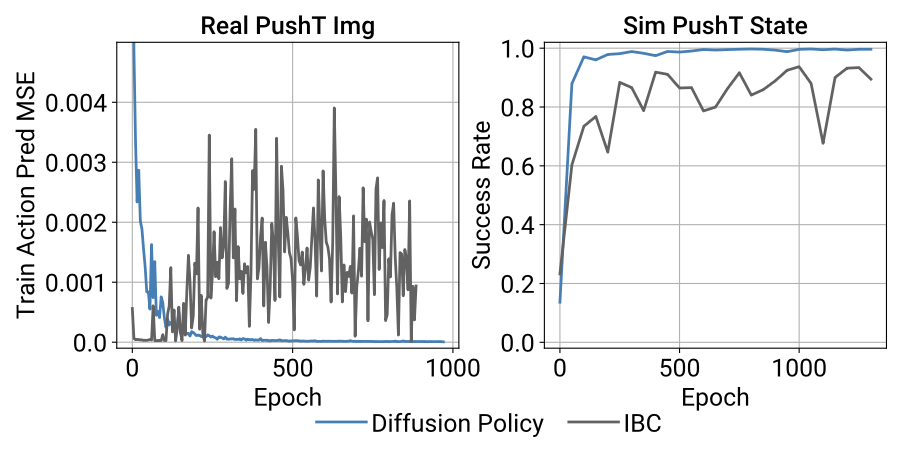
하지만 action horizon을 계속 늘릴 경우 반응 속도가 느려져 성능이 저하 된다고 합니다. 위의 그림에서 왼쪽 그래프가 이를 의미합니다.
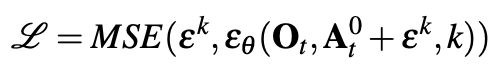
Loss function은 DDPM을 사용하므로 위에서 설명한 것과 같이 noise의 MSE를 사용합니다.
Evaluation
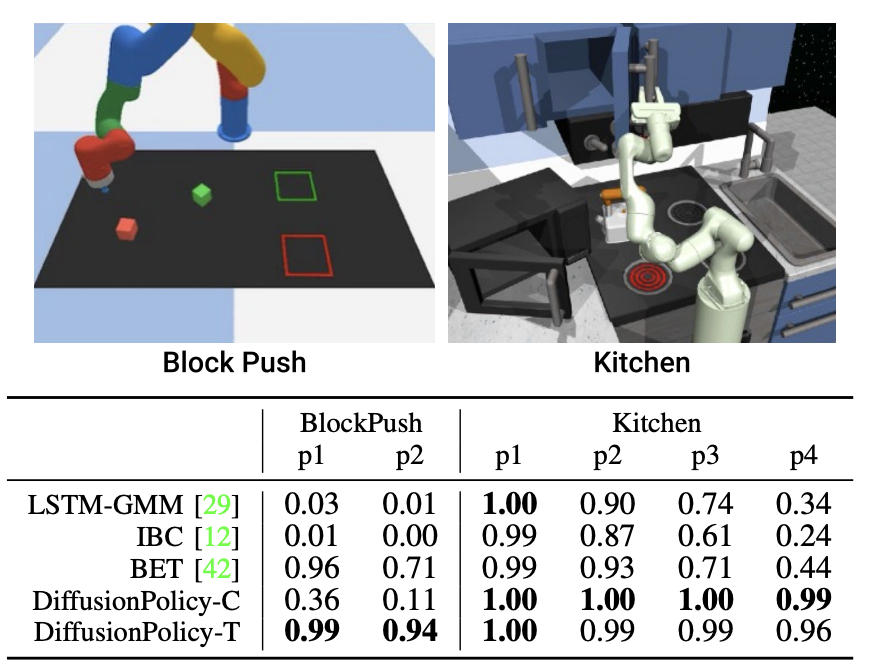
DP는 다른 model에 비해 Task 수행 능력이 뛰어나다고 합니다. 두 task 전부 multimodal action을 나타내며, DP의 성능이 좋은 것을 확인할 수 있습니다. 여기서 CNN 모델이 BlockPush(블럭 하나를 밀어 넣고, 나머지도 밀어 넣는 multimodal Task)에서 좋은 성능을 보여주지 못하는데 이 부분이 잘 이해가 안되는 것 같습니다.. p2는 2개의 블럭을 zone에다가 넣는 경우인데 cnn의 성능은 처참합니다. 근데 kitchen task의 경우에는 p4 즉 4개의 물체와 상호작용하는 경우에서 cnn은 transformer의 성능을 뛰어넘어 버립니다. 논문에서는 CNN의 국소적인 부분을 잘 탐지하는 대신 장기적인 의존성이 약하다고 하는데, kitchen에서는 좋은 성능을 보이는 것을 보아 뭔가 와닿지가 않습니다. 댓글로 의견 주시면 감사하겠습니다.
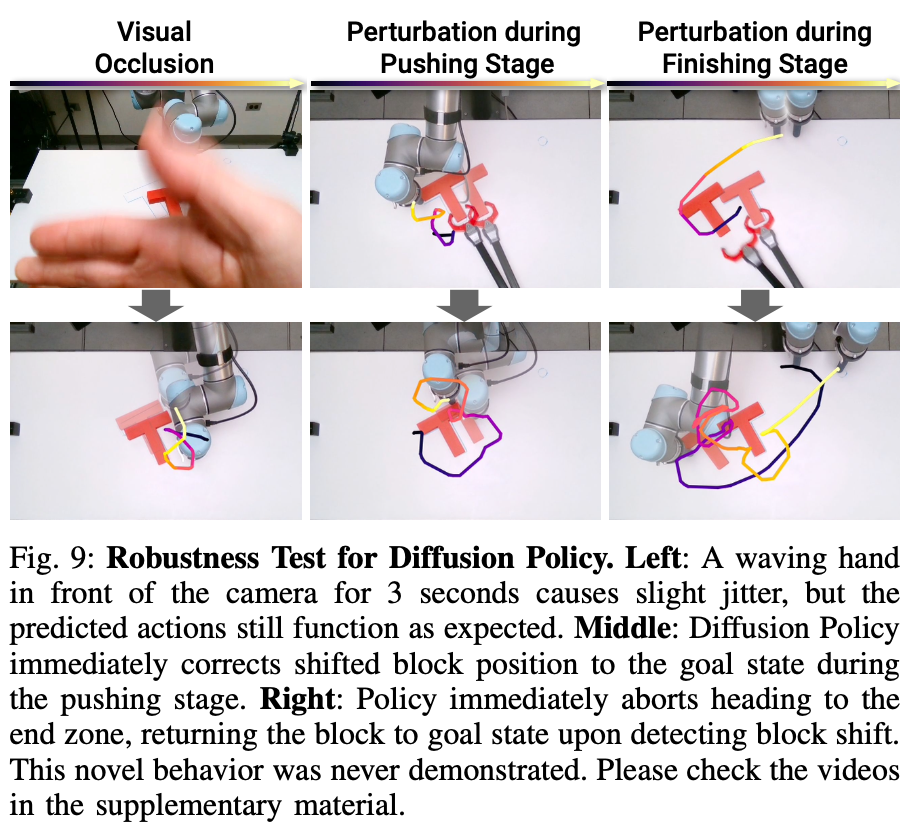
DP는 visual occlusion 이 발생해도 약간의 jitter 현상은 발생되지만 action은 지속적으로 수행된다고 합니다. sequential 한 action 덕분인 것 같습니다. 또한 observation 이 condition으로 사용되므로, T를 의도적으로 움직였을 때에도 적절한 행동을 취하는 것으로 보입니다.
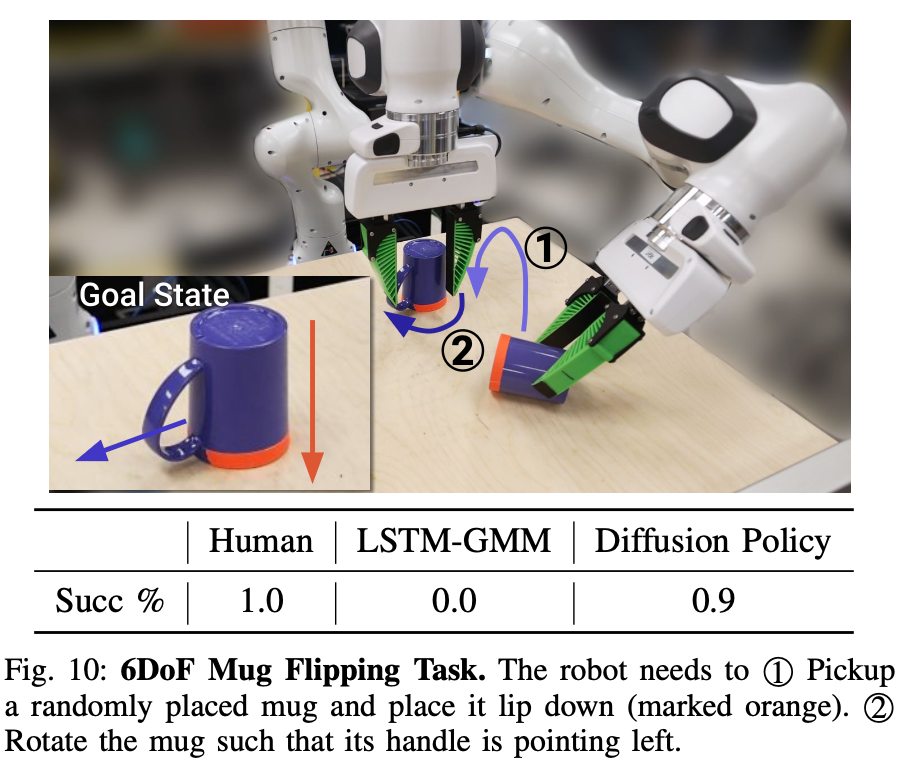
observation 이 조건으로 들어가고, long horizon에 강력하기 때문에 mug cup의 위치가 랜덤이고 놓여지는 것도 랜덤일 경우에도 task를 잘 수행하는 모습을 보입니다. 실제로 영상을 보면 그냥 아무데나 던지는데 잘 수행하는 모습을 보여줍니다.
Diffusion Policy 리뷰였습니다. 앞으로 제가 연구할 방향에서 아직 모르겠지만 Diffusion Policy가 쓰일 수 있을지.. Diffusion model의 multimodal distribution 은 대단한 것 같습니다. 고차원을 커버할 수 있다는 장점이 Hand의 큰 자유도를 커버할 수 있을까요? Flow matching이라는 기법도 들리는데 둘의 차이점도 궁금해서 앞으로 찾아봐야겠습니다. 읽어주셔서 감사합니다.