이번 리뷰는 논문 작업이 끝난 후 다음 연구 주제인 Long-horizon Task와 Failure Detection 분야를 서칭하던 중, 자극적인 제목에 끌려 보게되었습니다. Latent Action, World Model 을 unified 라니. 코드와 모델 weight 및 컴퓨팅 리소스까지 꽤나 자세하게 나와있기도 했는데요. 저는 한편으로 Long-horizon Task에서의 Failure Detection을 위해선 World Model급의 Latent Action feature 정도는 되어야 유의미한 uncertainty 정보의 froxy로써 활용해먹어 failure detection을 개선할 수 있지 않을까란 막연한 생각이 있었기에 해당 논문 리뷰가 제게 괜찮은 인사이트를 주기를 바라며 리뷰 시작하겠습니다.
Introduction
“Embodied Agent”가 제대로 기능하려면, 장면과 instruction을 이해하고, 가능한 미래를 상상하며, 그 결과를 예측하고, 실제 action을 생성하는 일련의 인지 기능들이 하나의 통합된 모델 안에서 함께 작동해야 합니다. 하지만 기존 방법들을 보면, 이러한 능력들이 대부분 서로 분리된 형태로 모델링되어 있죠. 저자들은 embodied agent를 위해선 모델링 자체도 여러가지 인지 기능들을 하나로 통합할 수 있는 통짜 모델이 필요하다는 주장을 첫 문단부터 은근히 비추며 운을 뗍니다. 그러면서 기존의 Embodied Agent를 위한 모델 구성이 각각 어떤 차이가 있는 지를 나열하며 설명합니다.
요즈음 로봇러닝의 메인스트림은 2가지 연구 스콥이 있는 것 같습니다. 일부 연구 스콥은 vision과 language로부터 정적인 policy를 학습하는 VLA를 메인으로 두고 초점을 맞추고, 또 다른 연구 스콥에선 미래 상태를 예측하는 world model이나 generative model을 중심으로 구성되는 연구들이 많은 것 같습니다. 실제로 본 논문에서 상당히 많은 수의 방법론을 해당 설명을 할 때 reference로 삼았는데요. (해당 reference들을 빠른 시일 내에 제가 follow up 할 수 있었으면 좋겠습니다..)
반면 F1(25.09)이라는 이전의 통합관점의 시도를 했던 연구는 VLA와 inverse dynamics model(IDM)을 결합해 미래의 visual observation을 명시적으로 imagination하는 구조를 취하지만, World Model이나 Video Generation Model(VGM)은 포함하지 않아 여전히 완전한 통합에는 이르지 못했었다고 주장합니다.
그러면서 기존의 연구들이 본래 하나의 시스템으로 구성되어야 할 문제를 다음의 5개의 독립적인 modeling task로 쪼개고 있다고 저자들이 입력 condition에 대한 출력 수식으로 먼저 교통정리를 하기 시작합니다.
VLA: p(a_{t+1:t+k} \mid o_t, \ell)
World Model (WM): p(o_{t+1:t+k} \mid o_t, a_{t+1:t+k})
Inverse Dynamics Model (IDM): p(a_{t+1:t+k} \mid o_{t:t+k})
Video Generation Model (VGM): p(o_{t+1:t+k} \mid o_t, \ell)
Video–Action Joint Prediction Model: p(o_{t+1:t+k}, a_{t+1:t+k} \mid o_t, \ell)
이러한 능력들을 하나의 프레임워크로 통합하는 데에는 두 가지 근본적인 어려움이 존재한다고 합니다.(Section 3에서 자세히 다룸). 첫 번째는, 이처럼 다양한 multimodal generative capability를 단일 모델 안에서 동시에 다루는 것 자체가 쉽지 않다는 점입니다. Unified World Model(UWM, RSS25’)은 이론적인 prototype을 제시하긴 했지만, 대부분 scratch부터 학습되거나 제한적인 prior(기존 pretrained 모델의 사전지식)만을 활용하기 때문에, VLM이 가진 강한 vision-language understanding이나 VGM이 보유한 풍부한 physical interaction knowledge를 충분히 활용하지 못합니다.
두 번째 문제는 데이터 측면입니다. embodied intelligence는 인터넷스케일 비디오, egocentric human demonstration, multi-robot trajectory와 같이 모두 다른 대규모의 heterogeneous data로부터 학습할 수 있어야 하지만, embodiment마다 action space가 크게 다르고, 대부분의 비디오 데이터에는 action label이 존재하지 않습니다. 이로 인해 일반적인 motion과 interaction prior를 담은 action expert를 사전학습하는 것이 매우 어렵다는 한계가 남아 있습니다.
이러한 문제들을 해결하기 위해, 저자들은 pretrained expert들을 Mixture-of-Transformers(MoT) 아키텍처 안에서 통합한 Unified Latent Action World Model인 Motus를 제안합니다. Motus는 video generator(generative expert), action expert, 그리고 vision-language understanding expert를 shared multi-head self-attention layer로 연결함으로써, 위에서 언급한 5가지 모델 구분을 하나의 모델 안에서 통합하는 구조를 제시합니다. 저자들은 이 설계를 Tri-model Joint Attention이라고 부르며, 각 expert의 특화된 기능은 유지하면서도 cross-modal knowledge fusion이 가능하도록 했다고 설명합니다.
기타 자세한 방법론은 아래에서 다루도록 하고, Contribution 남기겠습니다.
- world model, inverse dynamics model, VLA, VGM, video–action joint prediction model이라는 다섯 가지 주요 패러다임을 general multimodal prior의 손실 없이 통합한 unified embodied foundation model을 제안합니다.
- optical flow 기반 latent action을 활용해 cross-embodiment transferable motion knowledge를 학습할 수 있는, 세 단계 학습 파이프라인과 six-layer data pyramid로 구성된 scalable robotic recipe를 제시합니다.
- 시뮬레이션과 실제 환경 모두에서 extensive experiment를 통해 기존 state-of-the-art 대비 우수한 성능을 보였으며, simulation에서는 X-VLA 대비 15%, π0.5 대비 45% 향상을, real-world에서는 11~48%의 성능 개선을 달성함으로써, 대규모 general prior와 domain-specific prior를 효과적으로 결합하는 것이 policy generalization에 중요함을 입증합니다.
Problem Formulation
Embodied Policies
notation정리가 들어가는 Problem Formulation입니다. language-conditioned robotic manipulation 으로 문제를 설정합니다. 각 embodiment에 대해, 이 문제는 action a \in \mathcal{A}, observation o \in \mathcal{O} (visual input), language instruction \ell \in \mathcal{L}, 그리고 로봇의 proprioception p로 정의됩니다. 여기서 \mathcal{A}, \mathcal{O}, \mathcal{L}은 각각 action space, observation space, language instruction space를 의미합니다.
일반적으로 이 문제는 expert가 수집한 데이터셋
D_{\text{expert}} = {{\ell, p_1, o_1, a_1, \dots, p_N, o_N, a_N}}을 제공합니다. 이 데이터셋에는 N timestep 동안 expert가 수행한 robot proprioception, visual observation, action이 포함되며, 각 trajectory마다 대응되는 language annotation이 함께 주어집니다.
이 데이터셋을 기반으로, 파라미터 \theta로 parameterize된 policy를 학습합니다. 각 timestep t에서 policy는 현재 observation과 proprioception을 조건으로 다음 k개의 action을 예측하며(action chunking), 이는 다음과 같은 분포로 모델링됩니다.
p_\theta(a_{t+1:t+k} \mid o_t, p_t, \ell)또는
p_\theta(a_{t+1:t+k} \mid o_t, \ell)policy p_\theta는 다음 log-likelihood objective를 최대화하도록 학습됩니다.
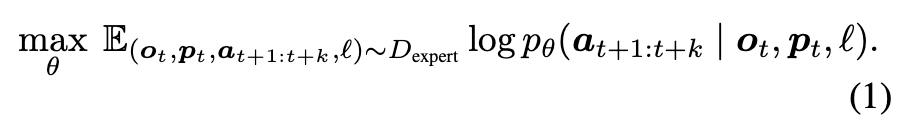
또한 위의 기호적 정의를 바탕으로, embodied intelligence를 구성하는 다섯 가지 modeling type에 대한 확률 분포를 도출할 수 있으며, 이들은 하나의 모델 안에서 통합적으로 학습될 수 있다고 설명합니다.
VLA: p(a_{t+1:t+k} \mid o_t, \ell)
World Model (WM): p(o_{t+1:t+k} \mid o_t, a_{t+1:t+k})
Inverse Dynamics Model (IDM): p(a_{t+1:t+k} \mid o_{t:t+k})
Video Generation Model (VGM): p(o_{t+1:t+k} \mid o_t, \ell)
Video–Action Joint Prediction Model: p(o_{t+1:t+k}, a_{t+1:t+k} \mid o_t, \ell)
이 다섯 가지 분포가 이후 본 논문에서 하나의 unified framework 안에서 함께 모델링하고자 하는 embodied intelligence의 핵심 구성 요소임을 명시합니다.
4.1. Motus
Model Architecture
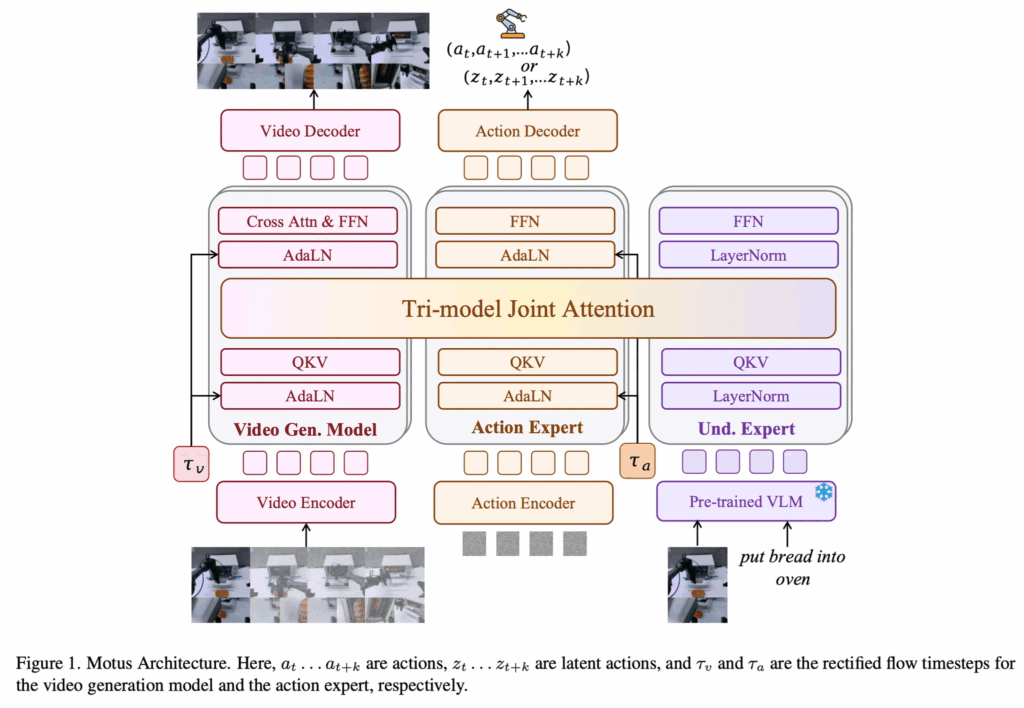
인트로에서 언급한 multimodal generative capability 통합 문제를 해결하기 위해, 저자들은 unified latent action world model인 Motus를 제안합니다. Motus는 우선 heterogeneous한 multimodal data에 대해 joint learning이 가능한 general generative model로 설계되었으며, 이를 통해 하나의 네트워크 안에서 다섯 가지 분포를 모두 모델링하는 general-purpose system을 지향합니다.
또한 현실적으로 정렬된 대규모 multimodal data를 요구하지 않기 위해, Motus는 기존 foundation model들이 이미 학습해둔 rich pretrained prior를 적극적으로 활용합니다. Fig. 1 을 보면 구체적으로는 pretrained VGM(generative expert), pretrained VLM을 기반으로 한 understanding expert, 그리고 action expert를 Mixture-of-Transformers(MoT) 아키텍처 안에서 통합합니다. 이 구조를 통해 scene understanding, instruction interpretation, consequence prediction, future video imagination, action planning이라는 상보적인 능력을 하나의 모델 안에서 결합하되, end-to-end로 처음부터 학습할 필요는 없도록 설계되었습니다.
Unified World Model(UWM)이 observation token과 action token을 단순히 concatenate한 뒤, self-attention과 FFN으로 구성된 동일한 UWM block을 연속적으로 통과시키는 방식이라면, Motus는 pretrained VLM과 VGM의 구조적 특성을 유지하기 위해 MoT 구조를 채택합니다. Motus에서는 각 expert가 독립적인 Transformer module을 유지하면서, multi-head self-attention layer만을 concat하는 방식, 즉 Tri-model Joint Attention을 사용합니다. 이 설계는 expert 간 역할 혼선을 줄이면서도 cross-modal feature fusion을 가능하게 하며, 서로 다른 pretrained knowledge가 상호 보완적으로 작동하도록 유도합니다.
Tri-model Joint Attention
학습 시 Motus는 rectified flow 기반 objective를 사용해 video와 action chunk를 동시에 예측합니다. 구체적인 loss는 다음과 같이 정의됩니다.
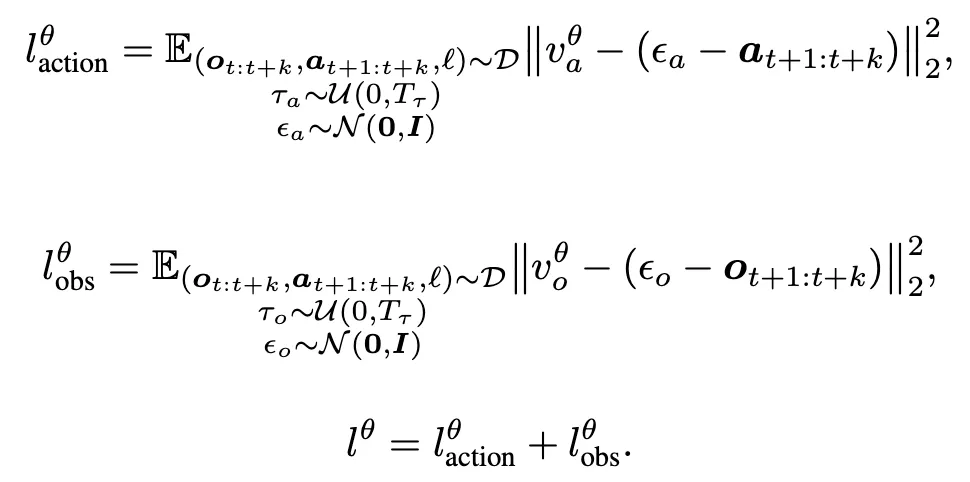
여기서 o_t는 condition frame이며, o_{t+1:t+k}와 a_{t+1:t+k}는 이후의 observation과 action sequence를 의미합니다. \tau_a, \tau_o는 각각 action과 observation에 할당된 timestep이고, \epsilon_a, \epsilon_o는 Gaussian noise이며, v^\theta_a, v^\theta_o는 unified model이 예측한 velocity field입니다. \ell^\theta_{\text{action}}과 \ell^\theta_{\text{obs}}는 각각 action과 observation에 대한 loss입니다.
Motus는 video와 action에 서로 다른 timestep과 noise scale을 할당함으로써 UniDiffuser-like scheduler를 구성합니다. 이를 통해 heterogeneous한 data distribution을 효과적으로 포착할 수 있으며, inference 시에는 VLA, World Model, IDM, VGM, Video–Action Joint Prediction Model 등 다양한 embodied foundation model 모드로 adaptive switching이 가능해집니다.
결과적으로 Motus는 scene을 이해하고, instruction을 따르며, outcome을 예측하고, 미래를 imagination하고, action을 출력하는 전 과정을 하나의 unified multimodal architecture 안에서 수행할 수 있는 모델로 정리됩니다.
Action-Dense Video-Sparse Prediction

Motus는 널리 사용되는 action-chunking 기법을 기반으로 하기 때문에, 미래의 video와 action sequence를 함께 예측해야 합니다. 즉, o_{t+1:t+k}, ; a_{t+1:t+k} 를 동시에 예측하는 구조를 취합니다. 이로 인해 몇 가지 문제가 발생합니다. 첫째, 학습과 inference의 효율이 떨어진다는 점입니다. 둘째, video frame 예측에서 중복이 많이 발생합니다. 셋째, Tri-modal Joint Attention 구조에서 video token의 수가 action token보다 훨씬 많아지는 불균형이 생깁니다.
이러한 token 불균형은 모델이 video prediction에 과도하게 맞춰 학습되도록 만들고, 결과적으로 action prediction 성능을 약화시키는 원인이 됩니다. 이를 해결하기 위해 저자들은 Fig. 2 와 같은 Action-Dense Video-Sparse Prediction 전략을 제안합니다. 학습과 inference 과정 모두에서 video frame을 downsampling하여 video token과 action token의 개수가 균형을 이루도록 하는데, 예를 들어, action frame rate 대비 video frame rate를 1/6 수준으로 설정하는 방식입니다. 이를 통해 video 예측의 중복을 줄이면서도 action prediction에 필요한 정보는 유지하도록 설계했다고 합니다.
Experts Details.
저자들은 generative expert로는 접근성과 사용 편의성을 고려해 Wan 2.2 5B를 video foundation model로 사용합니다. 이 모델의 self-attention context를 확장해, cross-modal Tri-model Joint Attention 메커니즘을 구성합니다.
action expert는 Wan과 동일한 depth를 갖는 Transformer block으로 구성되는데, 각 block은 rectified flow timestep을 주입하기 위한 AdaLN, Feed-Forward Network(FFN), 그리고 expert 간 상호작용을 위한 Tri-model Joint Attention으로 이루어져 있습니다.
저자들은 understanding expert로 Qwen3-VL-2B를 채택하는데, 이는 robotic manipulation에 중요한 3D grounding, spatial understanding, 정확한 object localization 능력을 본래 갖추고 있기 때문이라고 합니다. 해당 expert 입력은 VLM의 마지막 layer에서 대응되는 token을 사용합니다. understanding expert 자체는 여러 개의 Transformer block으로 구성되며, 각 block은 Layer Normalization, FFN, 그리고 Tri-model Joint Attention을 포함하는 구조입니다.
4.2. Latent Actions
저자들은 인트로에서 언급한 데이터 측면의 문제(Utilization of Heterogeneous Data)를 해결하기 위해, 대규모 heterogeneous data를 활용할 수 있도록 visual dynamics로부터 직접 generalizable action pattern을 학습하는 방식을 제안합니다. 구체적으로는 pixel 단위의 motion을 인코딩하는 latent action을 도입합니다. 이 latent action은 internet video, egocentric human demonstration, multi-robot trajectory 등 다양한 소스로부터 motion knowledge를 흡수할 수 있게 해주며, explicit action label이 없는 데이터에 대해서도 action expert를 효과적으로 pretraining할 수 있도록 했습니다.
Optical Flow Based Representation
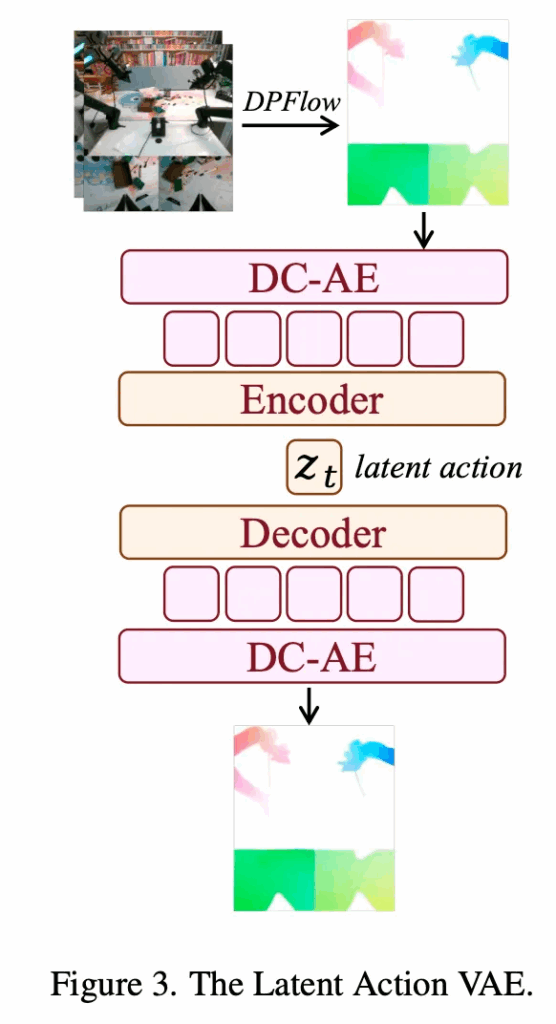
motion을 표현하기 위한 자연스러운 표현으로 요즈음의 방법론들이 그렇듯 optical flow를 채택했습니다. 전체 구조는 Figure 3을 보시면 됩니다. optical flow는 연속된 frame 사이의 pixel-level displacement를 포착하는 representation으로 쓰이는데, 본 논문에서는 DPFlow라는 기법을 사용해 optical flow를 계산한 뒤, 이를 RGB 이미지 형태로 변환합니다. 특히 고차원인 flow representation을 control-level space로 압축하기 위해, deep convolutional variational autoencoder(DC-AE)를 사용합니다. DC-AE는 optical flow를 재구성하면서 동시에 이를 512차원의 token 4개로 인코딩합니다. 이후 lightweight encoder를 통해 이 4 × 512 feature를 하나의 14차원 vector로 projection하는데, 이는 일반적인 robot action space의 규모와 유사하게 맞춘 것입니다. 이러한 차원 정합성 덕분에 latent representation은 실제 robotic control과 자연스럽게 alignment될 수 있으며, perception과 action을 연결하는 bridge 역할을 수행할 수 있다고 합니다.
Training and Distribution Alignment
latent space가 실제 action space와 잘 정렬되도록 하기 위해, 저자들은 AnyPos를 따라 task-agnostic data를 함께 사용합니다. 구체적으로는 Curobo를 활용해 target robot의 action space를 무작위로 샘플링하면서 image–action pair를 수집합니다. 이 데이터는 task와 무관한 실제 action supervision을 제공하며, VAE가 실행 가능한 motor behavior를 반영하는 embedding을 학습하도록 돕고, latent action을 실제 control distribution에 anchoring하는 역할을 합니다.
학습 과정에서는 전체 데이터 중 90%를 unlabeled data로 사용해 self-supervised reconstruction을 수행하고, 나머지 10%는 labeled trajectory를 사용해 weak action supervision을 제공합니다. 이 labeled 데이터에는 task-agnostic data와 일반적인 robot demonstration이 모두 포함됩니다. 차원 정합성과 weak action supervision이 함께 작용하면서, latent-action distribution은 실제 action distribution과 alignment되며, video로부터 학습된 motion prior가 자연스럽게 실행 가능한 control로 매핑될 수 있도록 유도됩니다.
전체 loss는 reconstruction, alignment, KL regularization을 결합한 형태인데,
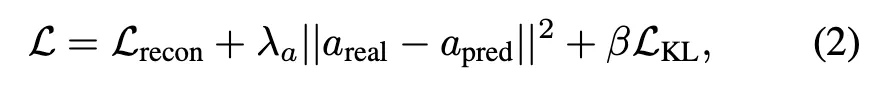
여기서 L_{\text{recon}}은 flow reconstruction error를 최소화하는 항이고, 두 번째 항은 latent action과 real action을 정렬하기 위한 항이며, L_{\text{KL}}은 latent space에 대한 regularization 역할을 합니다. \lambda_a, \beta는 하이퍼파라미터입니다.
4.3. Model Training and Data
Motus Training
Motus는 서로 다른 데이터셋에 포함된 physical interaction prior를 점진적으로 통합해, target robot으로 transfer 가능한 policy를 학습하기 위해 Tab. 1 에서처럼 세 단계로 구성된 구조적인 학습 절차를 따릅니다. 각 단계는 하나의 핵심적인 문제를 해결하는 데 초점을 둡니다.
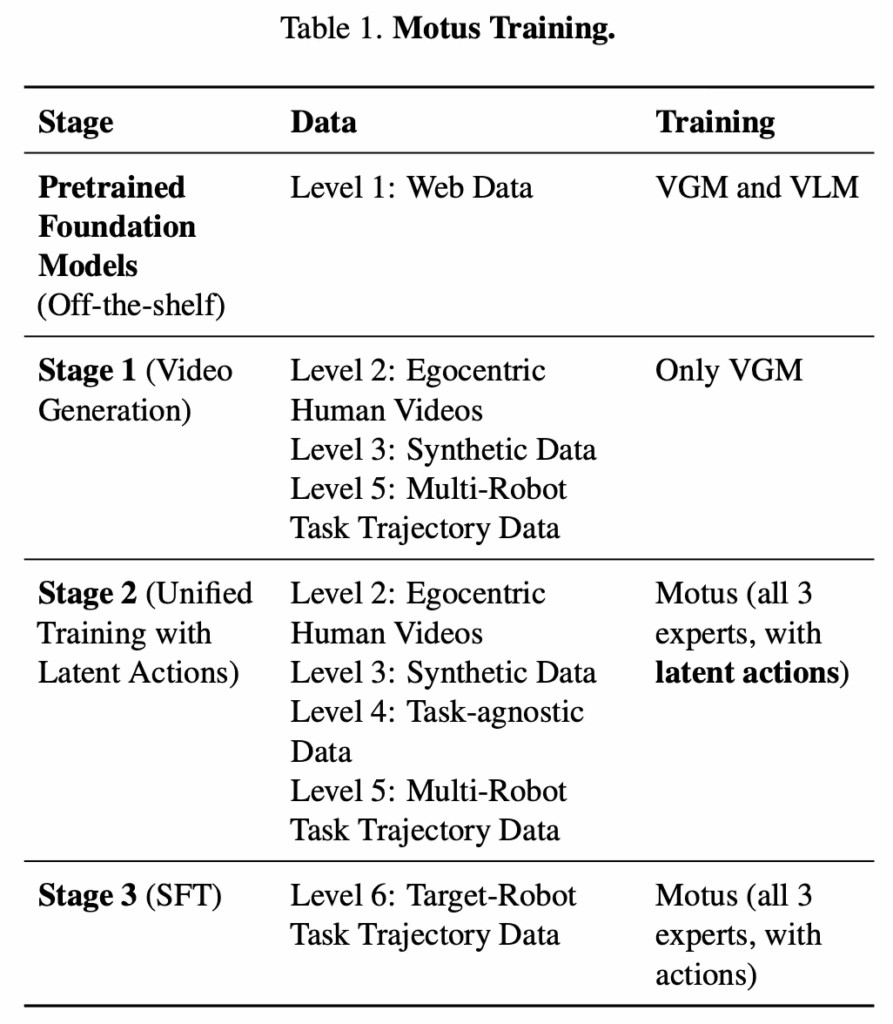
- Stage 1: Learning Visual Dynamics 첫 단계에서는 realistic한 physical interaction을 모델에 주입하기 위해, multi-robot trajectory와 human video를 사용해 Video Generation Model(VGM)을 먼저 적응시킵니다. 이를 통해 VGM은 language instruction과 초기 이미지가 주어졌을 때, task 수행 과정에 대해 그럴듯한 미래 video sequence를 생성할 수 있게 됩니다.
- Stage 2: Learning Action Representations 두 번째 단계에서는 visual forecast와 control 사이를 연결하기 위해, 전체 Motus 모델을 videos, language, latent action을 사용해 pretraining합니다. 이때 VLM은 frozen 상태로 유지됩니다. 이 단계의 목적은 motion과 interaction에 대한 지식을 latent action space에 내재화함으로써, action expert를 초기화하는 데 있습니다.
- Stage 3: Specializing for the Target Robot 마지막 단계에서는 target robot 데이터로 fine-tuning을 수행해, 앞선 단계에서 학습한 prior들이 특정 embodiment의 dynamics와 kinematics에 맞게 완전히 적응되도록 합니다. 이를 통해 Motus는 target robot 환경에서 실행 가능한 policy로 마무리됩니다.
Data
저자들은 robot에게 generalizable manipulation skill을 부여하기 위해, semantic understanding, physical reasoning, spatiotemporal dynamics, decision-making에 이르는 풍부한 prior knowledge를 담은 대규모 multimodal data를 활용합니다. embodied data는 저희가 알다시피 language ℓ, image o, action a라는 여러 modality로 구성됩니다. 그래서 각 modality의 존재 여부를 기준으로, 저자들은 의미 있는 모든 데이터 유형을 아래처럼 착착 정리했는데요.
- Language + Image + Action VLA에서 주로 사용되는 robot trajectory 데이터로, {ℓ, o₁, a₁, …, o_N, a_N} 형태를 가집니다.
- Language + Image {ℓ, o₁, …, o_N} 형태의 video sequence이거나, {(o, ℓ)} 형태의 image–text pair입니다.
- Image + Action task-agnostic interaction data로, {(o₁, a₁, …, o_i, a_i)} 형태를 가집니다.
- Language-only {textual corpus} 형태의 {ℓ} 데이터입니다.
visual modality가 포함되지 않은 데이터 유형(예: language + action)은 visuomotor policy learning에 적합하지 않다고 보고 제외했다고 합니다. 그리고 나머지 데이터 유형들은 embodied policy 학습에 활용 가능한 전체 스펙트럼을 구성했다고 하는데,, 이러한 데이터의 다양성을 구조화하기 위해, 저자들은 아래 fig. 4. 와 같은 embodied data pyramid를 도입하였습니다.

이 피라미드는 데이터의 정보 밀도와 policy relevance를 기준으로 각 데이터 유형을 계층적으로 정리한 구조입니다. Motus는 web-scale의 간접적인 데이터부터 target robot demonstration까지, 총 여섯 단계로 구성된 데이터 레벨(Tab. 1. 다시 참고.)을 학습 단계별로 효과적으로 통합하고 정렬하는 걸 목표로했는데, 이를 통해 서로 이질적인 여러 데이터셋을 하나의 일관된 모델 아키텍처 안에서 통합할 수 있다고 설명합니다.
5. Experiments
저자들은 simulation 환경과 real-world 환경 모두에서 Motus의 효과를 평가하기 위해 extensive experiment를 수행합니다.
5.1. Baselines
Motus는 π0.5와 X-VLA를 포함한 SoTA 방법들과 비교됩니다. 모든 모델은 simulation 환경에서 평가되며, baseline 중 π0.5에 대해서는 real-world task에서도 추가로 성능을 측정합니다. 또한 from-scratch로 학습한 모델과 Stage 1까지만 학습한 모델을 Motus와 비교해, 단계별 학습 전략의 효과도 함께 분석합니다.
5.2. Evaluation in Simulation Environment
simulation 환경에서는 RoboTwin 2.0 benchmark에 포함된 50개의 representative manipulation task를 대상으로 single-task 성능을 평가합니다. 방법의 일반적인 능력을 검증하기 위해 multi-task training도 수행하는데, Motus와 모든 baseline은 clean scene에서 수집된 2500개의 demonstration(각 task당 50개)과, 강하게 randomization된 scene에서 수집된 25000개의 demonstration(각 task당 500개)으로 학습됩니다.
randomization에는 random background, cluttered table, table height perturbation, randomized lighting이 포함됩니다. 모든 모델은 pretrained checkpoint에서 시작해 RoboTwin 데이터셋으로 40k step 동안 fine-tuning되며, 각 task에 대해 100회 실행을 수행해 success rate를 측정합니다.
이 RoboTwin 2.0 benchmark는 다양한 task scene과 randomized instruction을 포함하고 있어서, 다양한 manipulation setting을 처리하는 능력을 평가하는 데 특히 까다롭고 의미 있는 평가 환경이라고 하네요. 또한 강한 배경 변화와 환경 변화는 distribution shift 하에서의 generalization 성능을 평가하는 역할을 합니다. 모든 모델이 동일하게 40k step의 fine-tuning만 허용되기 때문에, 서로 다른 pretraining 전략의 효과를 비교하는 데 있어 공정하게 비교할 수 있는 것 같습니다.
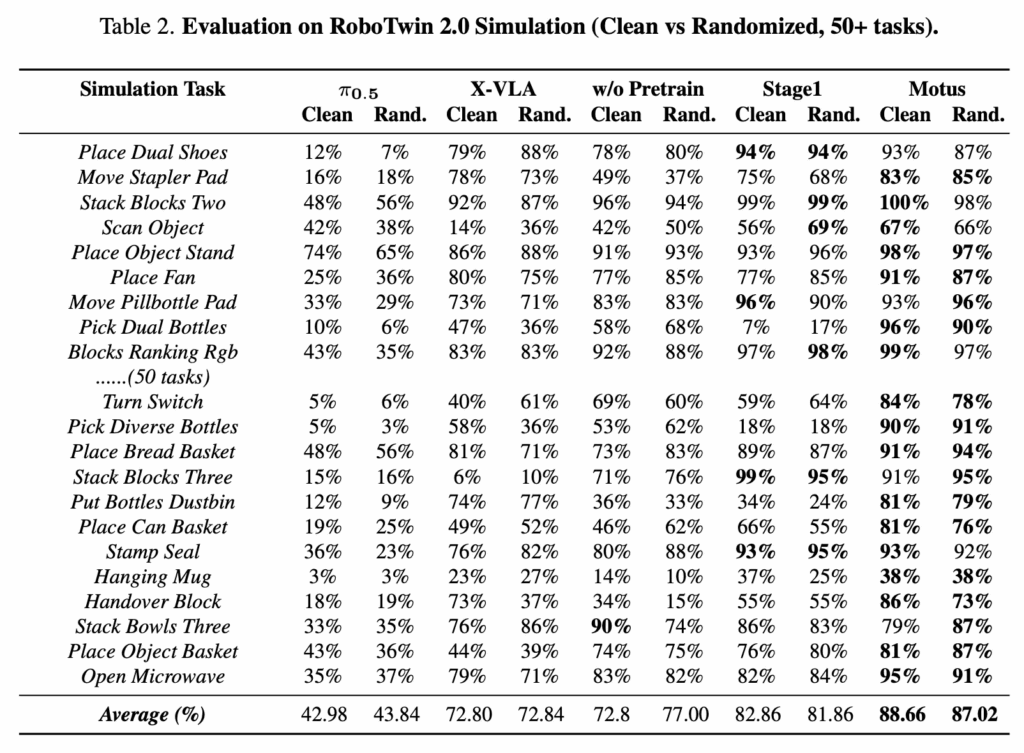
Table 2가 전반적인 Simulation에서의 성능입니다. Motus는 해당 RoboTwin 2.0 randomized multi-task setting에서 SoTA 성능을 달성하며, π0.5 대비 45% 이상의 절대적인 향상을 보이는데요. 이를 통해 저자들은 unified MoT 모델로 구성된 Motus가 vision, language, action generation을 효과적으로 통합함으로써 multimodal generative capability 통합 문제를 해결한 것이라고 주장합니다. 또한 latent action 도입을 통해 labeled data와 대규모 unlabeled data를 모두 활용할 수 있어, embodiment 간 generalization과 풍부한 motion prior 학습 측면에서 Utilization of Heterogeneous Data 문제 역시 해결했다고 설명합니다. 이러한 요소들의 결합이 결국에 기존 접근의 한계를 넘어서는 성능 향상으로 이어졌다고 주장하네요.
5.3. Real-World Experiments
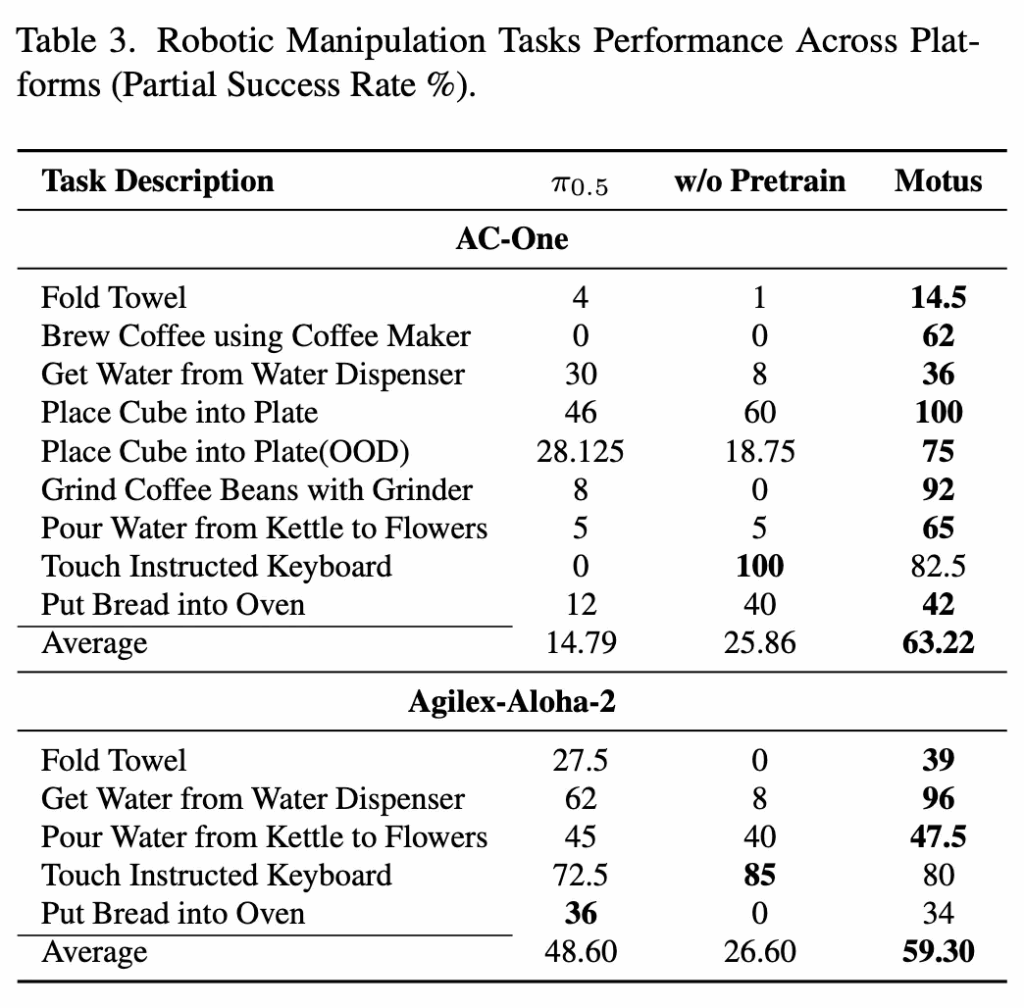
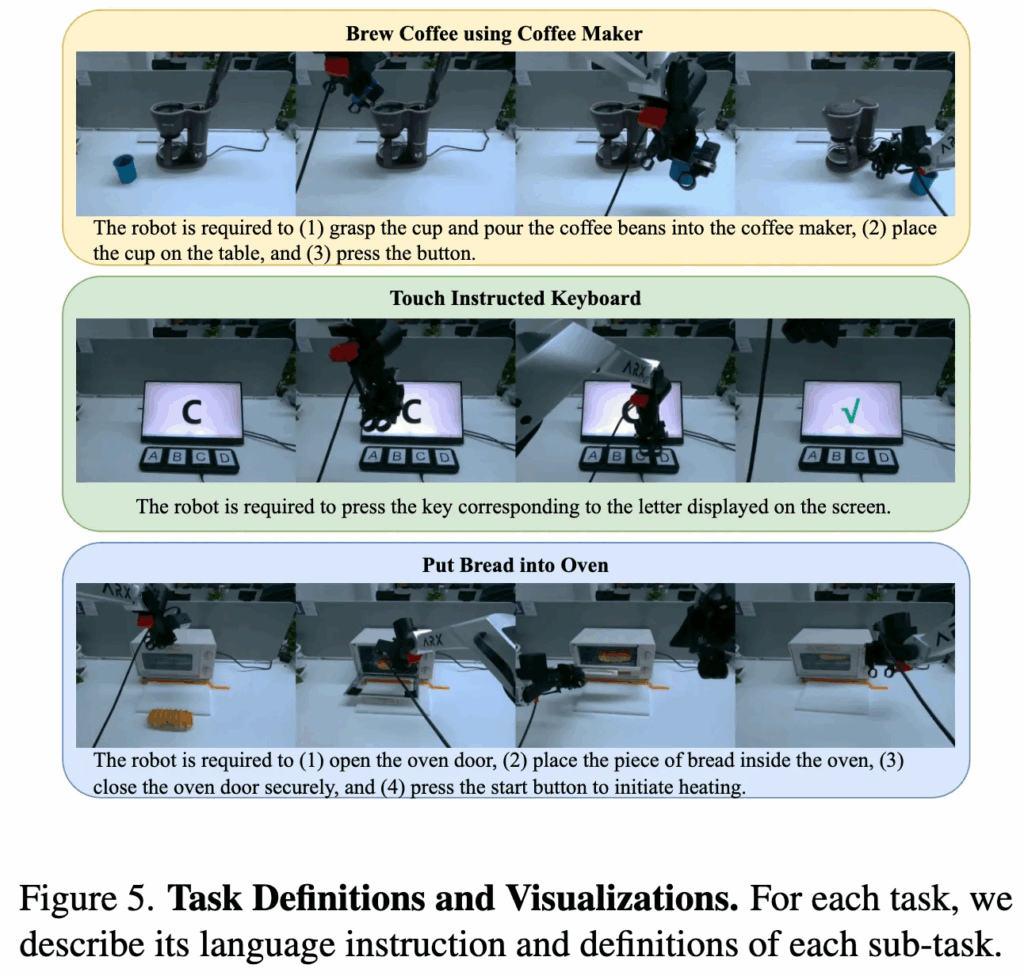
real-world 실험은 두 가지 dual-arm robotic platform인 AC-One과 Agilex-Aloha-2에서 수행됩니다. 실험 task는 Spatial Understanding, Deformable Object Manipulation, Precision Fluid Control, Visual Understanding, Long-Horizon Planning 등 다양한 policy capability를 포괄하며, 구체적인 예로는 수건 접기, 드립 커피 머신을 이용한 커피 추출, 그라인더로 원두 갈기 등이 포함됩니다.
각 task마다 100개의 trajectory를 사용해 학습하며, simulation 환경과 마찬가지로 multi-task joint training 방식을 사용합니다. 즉, 각 로봇 플랫폼별로 모든 task를 하나의 모델로 함께 학습한 뒤, 개별 task에 대해 평가를 수행합니다. 이건 모델의 robustness와 generalization 능력을 보다 종합적으로 평가하기 위한 세팅이라고 하네요.
baseline으로는 π0.5를 사용합니다. 대부분의 task가 long-horizon reasoning을 요구하고 subtask로 분해 가능하다는 점을 고려해, evaluation metric으로 partial success rate를 사용합니다. 이 metric은 task를 여러 subtask로 나누고, 각 subgoal 달성 여부에 따라 부분 점수를 부여하며, 전체 task를 성공적으로 완료했을 때만 full score를 부여해서 모델 능력을 나눠서 평가합니다.
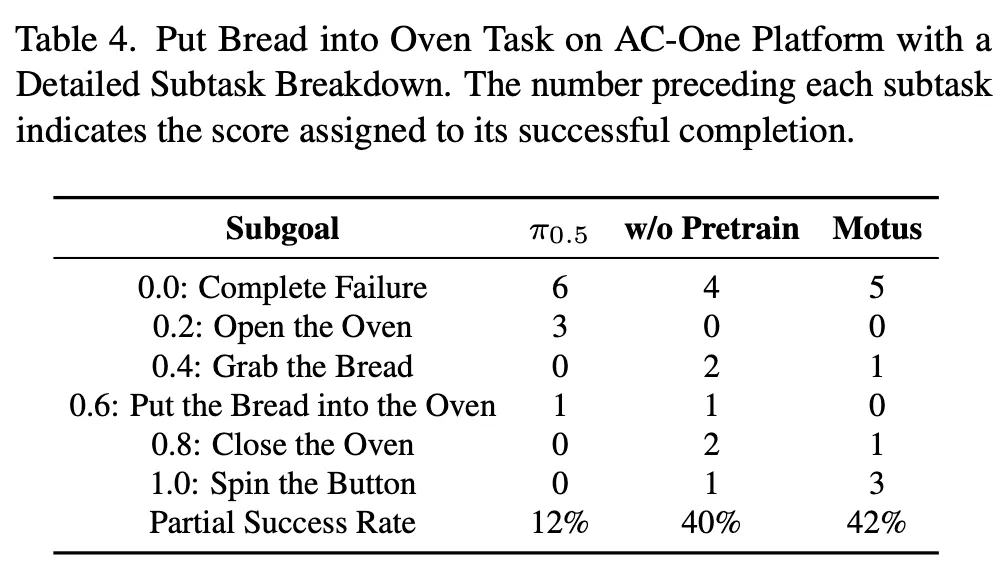
아래의 Table 4, 5를 보면 real환경 subtask 실험에서, Motus가 높은 성능을 보이는데, 특이한점은, w/o pretrain일 때 태스크에 따라서 다소 미비한 성능을 보인다는 점입니다. 그래도 시사점은 1.0에 대핟ㅇ하는 최종 성공까지가는 경우가 많은 것이 Motus인 점을 보면 여러 sub-task로 쪼개어져 태스크를 수행해야되는 Long-horizon 세팅에서도 Unified model이 강력한 성능으로 이끌 수 있음을 보였음이라고 보면 되겠습니다. 사실 이 분야에 follow up이 매우 잘 되어있지 않아 깊은 고찰은 아직까지는 쉽진 않네요.. 노력하겠습니다.
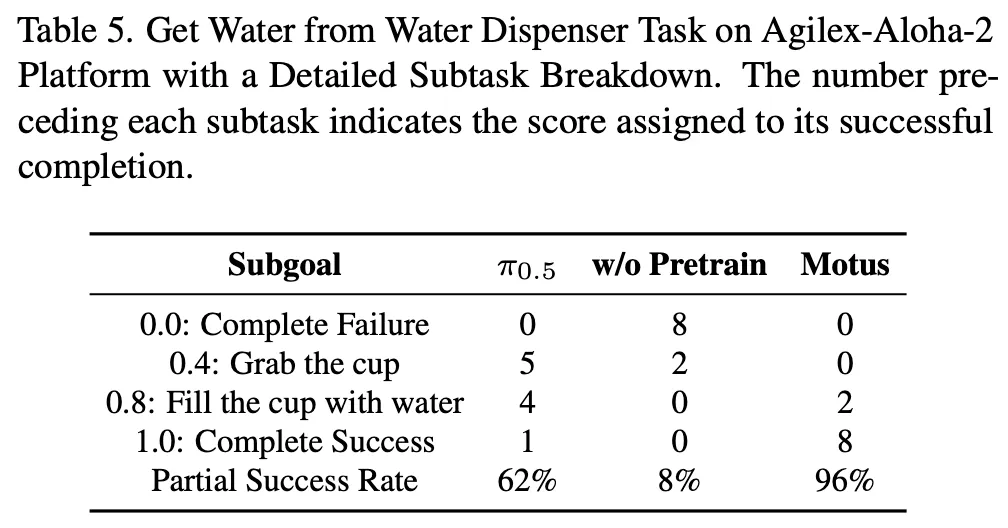
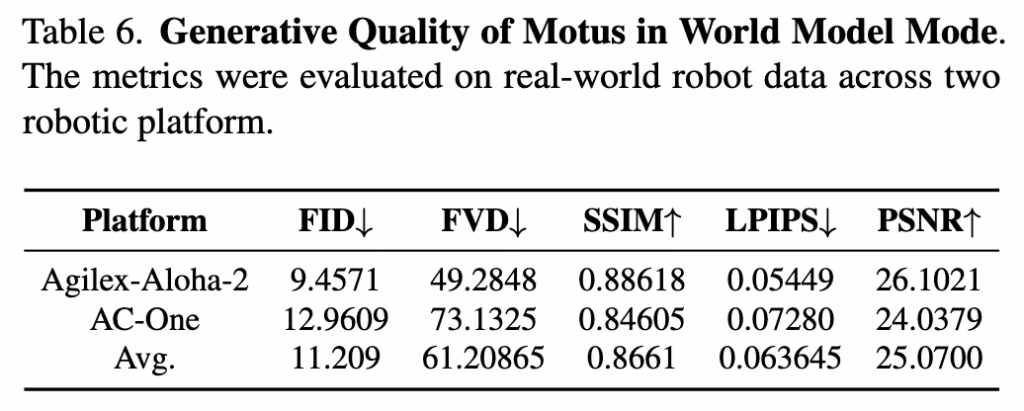
아래는 Table 6입니다. Motus의 World Model 모드에서의 생성퀄리티에 대한 평가인데요. 기존의 다른 방법론과 따로 비교를 한 건 아니고 self-evaluation이라 사실 어느정도의 수준인지는 파악이 안되는 상황입니다. 논문에서도 추가적인 설명이 없어서 아쉽네요.
리얼 환경에서 task description 별로 더 구체적인 결과는 아래 Table 3에 정리되어 있는데요. Motus는 두 종류의 robotic arm 모두에서 모든 task에 대해 baseline인 π0.5를 일관되게 상회하는 성능을 보입니다.
아래 Figure 5는 task에 따른 실험의 시각자료인데요. 저희 로보틱스팀이 생각했을 때 꽤나 복잡하고 긴 작업이라고 생각되는 작업들을 잘 수행해내는 결과를 보입니다. 이는 프로젝트 페이지 내에서도 확인해 볼 수 있었습니다.
5.4. Ablation Study
저자들은 각 학습 단계의 기여도를 분석하기 위해 ablation study를 수행합니다. 구체적으로는 pretraining 없이 학습한 모델과 Stage 1까지만 pretraining한 모델을 비교 대상으로 설정합니다.
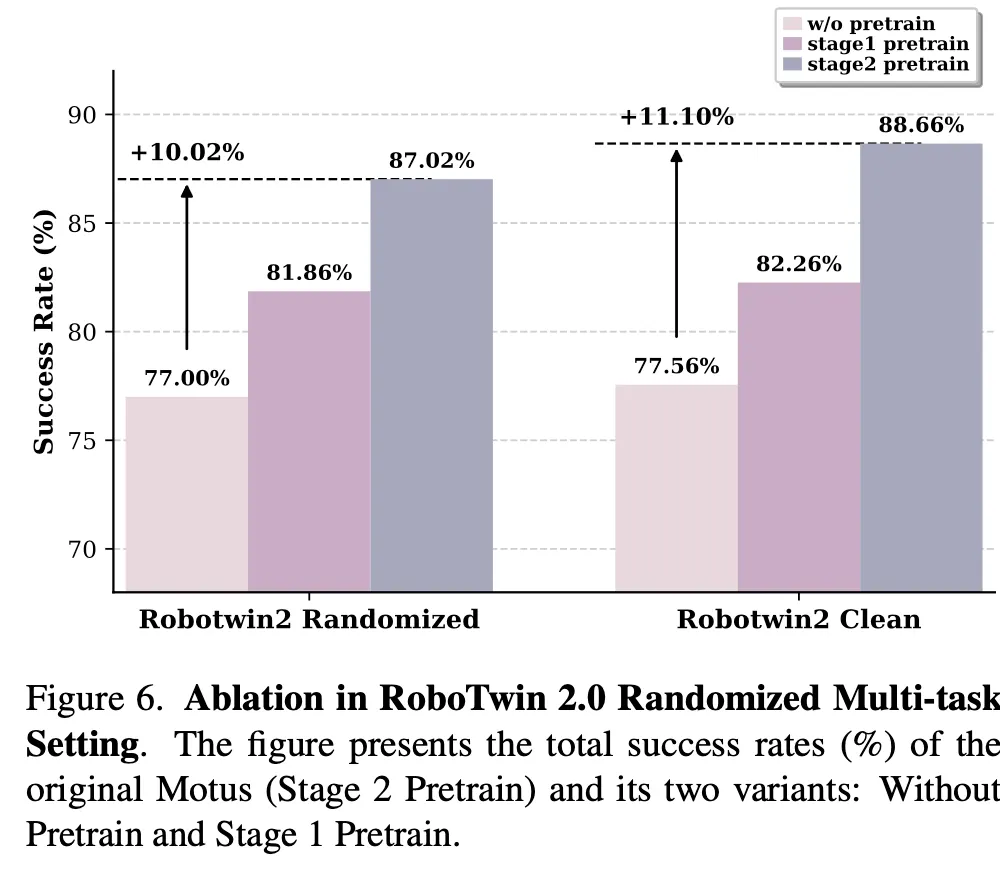
simulation 환경에서는 RoboTwin 2.0 simulator에서 accuracy를 측정했고, simulation 에 대한 실험 결과는 아래 Figure 6에서 보여줍니다. Stage1 pretrain은 VGM(비디오 생성 모델)만 사전학습(visual dynamics 적응)하는 단계이고, Stage2 pretrain 은 Motus의 핵심 단계로써 VGM + latent-action을 포함한 통합(pretraining with latent actions) 방식으로, VLM만 frozen하는 방식입니다.
최종적으로 Motus의 ablation 실험에서는 generalize한 VL 사전지식 + 영상 기반 물리적 사전지식(비디오 생성) 이 optical-flow 기반 latent-action으로 행동 표현을 학습하여 통합한 상태로 pretrain한다면, 실제 로봇 제어 성능과 도메인 강건성이 단계적으로 개선된다는 저자의 메인 철학을 실험적으로 확인한 결과론적인 해석이라고 볼 수 있겠습니다.
아직 arxiv 논문인지라, 논문 내의 실험에 대한 설명과 주장이 꽤나 빈약했습니다. accept을 위해선 아직 분석적으로 보완할 점이 많은 논문임에는 분명합니다. 그럼에도 불구하고 성능면에서는 놀랄만한 성능을 보였고, 특히 저의 경우는 Long-horizon Task에서의 성능이 높다는 점과 코드레벨에서의 모델 통합 및 학습 구현에서 인상깊게 보았습니다. 실험결과에 대한 설명은 저자들이 추후 차차 업데이트할 것으로 예상되고, 해당 논문이 코드공개와 weight공개가 잘 되어있다는 점에서 미루어볼 때 accept된다면 생각보다 활용도가 높을 수 있는 방법론으로 생각됩니다만, 일단은 그 전까지는 흐린 눈을 해야겠네요.
참고로 모델 파라미터는 다음과 같았습니다. 8B 인데, 꽤나 작은 파라미터에 흥미가 생기네요.

World Model 내의 Latent Action feature를 Long-horizon task에서의 failure detection을 위한 uncertainty score로써 활용해먹으려면 다른 방면의 논문 서치가 필요할 것 같습니다. 해당 논문만으로는 분석에 대한 고찰이 쉽지 않아 적절한 인사이트를 아직까진 얻지 못했네요.