안녕하세요. 이번에 리뷰로 들고온 논문은 2024 CoRL에 게재된 LeLaN: Learning A Language-Conditioned Navigation Policy from In-the-Wild Videos 이라는 논문입니다. 이 논문의 간단한 컨셉은 언어 조건 내비게이션에서 언어 라벨,액션 라벨이 없는(in-the-wild) 1인칭 영상이 있으면 이걸 파운데이션 모델(SAM,VLM,LLM,Depth,RFM) 조합으로 언어 지시 + 목표(객체) 포즈 + 그 포즈로 가는 로봇 행동(궤적)을 자동 생성한 데이터로 언어 조건 내비게이션 정책을 학습하겠다라는 것입니다. 다만 문제 설정은 일반적인 탐색까지 포함하는 형태가 아니라 목표가 현재 시점에 시야 안에 존재하는 last mile 상황으로 범위를 좁혀서 문제를 풀고자 한다라고 보시면 좋을 것 같습니다. 바로 리뷰시작하도록 하겠습니다.
Introduction
저자가 말하길 로봇 분야는 언어로 주석된 로봇 데이터가 부족하기 떄문에 기존 연구들은 이 부족함을 우회하기 위해, 이미 인터넷 규모로 학습된 VLM/LLM을 제로샷으로 로봇에 갖다 붙이는 방향으로 많이 진행되었다고 합니다. 예를 들면 LLM이 상위 수준에서 계획을 세워준다든지(high-level planning), 로봇 API를 호출하는 코드를 생성한다든지(code-generated policies), 아예 모델이 관측을 보고 제로샷으로 제어를 뽑는다든지(zero-shot control) 같은 흐름들로 학습 데이터 부족하니 이미 똑똑한 모델을 그대로 쓰자라는 식으로 연구가 진행되어왔습니다.
그런데 저자들은 이런 접근이 결국 근본 한계를 가진다고 지적합니다. 핵심은 두 가지인데 먼저 데이터 분포 차이입니다. 파운데이션 모델이 학습된 데이터 분포(웹 이미지/텍스트)와 로봇이 실제로 몸을 갖고 움직이면서 마주치는 데이터 분포는 애초에 많이 다르다는데 모델은 말은 잘하지만 로봇이 동작하면서 현실에서 마주하는 경험과 맞물릴 때는 엉뚱하게 동작할 수 있다라는 점을 지적합니다. 그리고 두번째는 비용/배포 문제를 언급합니다. 당연히 VLM/LLM은 계산량이 크다 보니 모바일 로봇에서 중요한 엣지 환경에서는 그대로 올려서 쓰기가 어렵습니다.
저자들은 이러한 문제를 해결하기 위해서 대규모 데이터 증강을 활용합니다. 저자들 주장을 그대로 옮기면, “파운데이션 모델의 능력을 로봇의 embodied experience에 효과적으로 grounding 하려면, 결국 로봇이 실제로 겪는 형태에 가까운 supervision을 큰 규모로 만들어줘야 한다” 라는 것입니다. 즉, 첫번재 한계에 대해서는 실제 로봇이 마주할 환경에 대한 데이터 셋을 대규모로 구축하여 파운데이션 모델의 능력을 실제 로봇 환경에서의 상황에서도 잘 동작할 수 있도록 하는 것입니다.
그래서 저자들은 egocentric 내비게이션 영상(로봇이 직접 찍은 1인칭 데이터뿐 아니라 유튜브 FPV 투어 영상, 사람이 걸으며 찍은 FPV 등) 같은 행동 라벨이 없는(action-free) 데이터에 대해서도, 파운데이션 모델들을 조합해 언어 라벨 + 행동 라벨을 자동으로 만들어내는 파이프라인을 제안합니다.
파이프라인에 대해서 간단히 언급하고 넘어가자면(추후에 자세히 다루겠습니다.) 먼저 각 이미지에서 세그멘테이션 모델로 물체들을 분할해서, 언어 지시문이 참조할 수 있는 관심 객체(object of interest)를 뽑습니다. 그 다음 VLM으로 그 객체에 대한 description(캡션과 비슷한 느낌입니다.) 만들고, LLM으로 저 물체로 가라와 같은 스타일의 다양한 언어 지시문을 생성합니다. 그리고 여기서 끝이 아니라, 로봇이 실제로 어떻게 움직여야 하는지까지 만들기 위해 단안 depth 모델로부터 3D 포인트 클라우드 정보를 얻고 로봇 파운데이션 모델(RFM)을 이용해 그 객체로 위치로 이동할 수 있도록 하는 counterfactual action label(합성 행동 라벨) 을 생성합니다.
결국 사람이 일일이 로봇 데이터를 라벨링하지 않아도 파운데이션 모델들을 이용해 대규모로 supervision을 만들 수 있다 라는 점을 어필 하는 것 같습니다.
마지막으로 저자들이 주장하는 기여는 4개로 정리하면 아래와 같습니다.
- 행동 정보가 없는 영상(action-free video) 에도 적용 가능한, 파운데이션 모델 기반 일반적 라벨링 기법을 제안한다.
- 이렇게 만든 라벨로 학습한 정책이 노이즈가 섞인 언어 지시, 동적 객체, 장애물 회피 같은 현실적 상황에서 더 강인하고 SOTA 성능을 보인다는 걸 실험으로 보여준다.
- 데이터 ablation을 통해, 정책을 안정적으로 grounding하려면 in-domain 로봇 데이터가 중요하다는 점과, 본 논문의 증강 방식이 실제로 효과가 있음을 검증한다.
- 언어+행동 라벨이 붙은 120시간+ egocentric 데이터를 공개하고, 그 중에는 여러 국가/도시에서 수집된 인간 보행 FPV 데이터도 포함된다.
Methods
해당 논문은 로봇이 이미 관측가능한 객체의 위치까지 정밀하게 이동해야하는 내비게이션 문제를 푸는 관점에서 fine-grained semantic understanding과 목표 객체에 대한 정밀한 내비게이션에 초점을 두는 방법론이다 라고 이해하시면 좋을 것 같습니다.
일단 전체적인 파이프라인은 아래와 같습니다. 각각에 대한 내용은 차근 차근 다뤄보도록 하겠습니다.
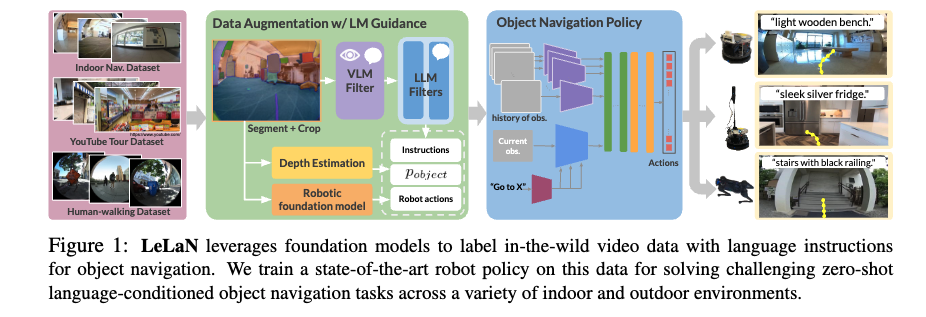
파운데이션 모델을 활용한 Labeling
먼저 논문에서는 Data Augmentation w/LM Guidance를 가장 중요하게 다루고 있고 Objec Navigation Policy 부분 같은 경우는 파운데이션 모델을 활용하여 적용만 하는 부분이다 보니 저자들은 관련 내용을 appendix로 넘겼는데 해당 내용에 대해서도 메서드 마지막 파트에서 잠깐 언급하고 넘어가도록 하겠습니다.일단 해당 파트에서는 데이터 증강위주로 설명을 드리도록 하겠습니다.
Language annotation
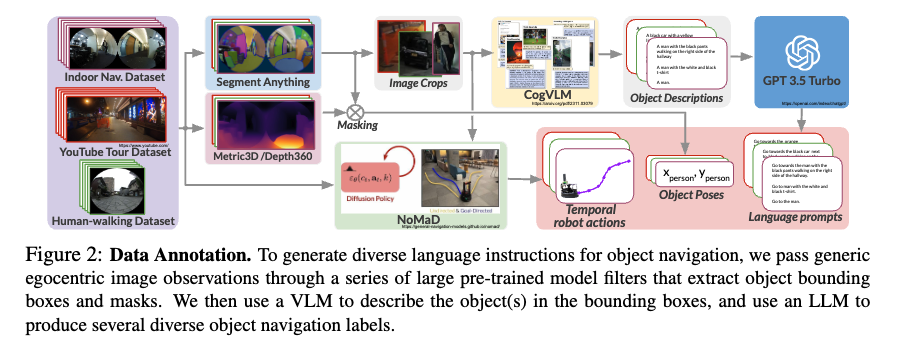
먼저 language annotation을 어떻게 하는지에 대해서 자세하게 설명드리도자면 먼저 데이터의 각 프레임을 SAM(segment Anything)에 입력해서 장면 내의 객체를 masking하고 바운딩 박스를 생성합니다. 그리고 이 바운딩 박스를 이용해서 이미지를 트롭하고 이 크롭 영역(관심 객체)를 VLM(CogVLM)에 입력해서 크롭에 포함된 객체에 대한 language description을 생성하게됩니다. 그리고 이 description은 다시 LLM(GPT-3.5-turbo)에 전달이되고 LLM은 VLM이 생성한 description을 바탕으로 이미지 크롭 속 객체를 지칭하는 다양한 표현을 사용하여 “Go to X” 형태의 언어 지시문을 생성하게 됩니다.
이제 여기서 드실 수 있는 의문점을 조금 해소하고자 부연설명을 드리자면 사실상 VLM만을 가지고 이미지 크롭으로부터 description 없이 그냥 바로 여러개의 언어 지시문을 VLM이 생성하게끔 할 수 있습니다. 근데 그 당시 논문 제출 시점 기준으로 오픈 소스가 아닌 VLM은 비용이 너무 비싸고 추론시간도 매우 길었다고 합니다. 그래서 오픈 소스 VLM을 채택하여 사용하였지만 이 오픈소스 모델이 생성되는 프롬프트의 품질이 좋지는 않았다고 합니다. 그래서 저자들은 일단은 오픈 소스 VLM을 사용해서 바로 지시문이 아닌 이미지 설명을 생성하고 빠르고 가성비가 좋은 GPT-3.5-turbo(LLM)를 활용해서 해당 설명을 바탕으로 언어 지시문을 생성하는 방식을 채택했다고 합니다.
Pose estimation and action generation
결국 로봇이 보는 관측은 결국 2D 이미지이기 때문에 저 물체로 가라를 실행하려면 이를 실제 3D 공간 좌표로 grounding 해줘야 합니다. 그래서 앞서 구한 관심 객체(크롭 영역)에 해당하는 Pose 정보를 goal pose로 추정하고 해당 목표를 향해 충돌 없이 이동하도록 하는 로봇 action 값을 생성해야합니다.
저자들은 객체의 pose를 추정하기 위해서 CoW와 유사하게 Depth 추정 모델을 활용하여(Metric3D, Depth360)을 사용해서 장면에 대한 depth를 추정한뒤 이를 바탕으로 PointCloud를 생성합니다. 그리고 SAM을 통해 얻은 마스크를 이용해서 포인트 클라우들르 필터링하고 해당 영역의 median 값으로, 언어지시문에 매칭된 객체에 대응하는 3D Pose(=goal Pose)를 얻게 됩니다.
그리고 충돌 회피 행동을 학습하기 위해서 저자들은 내비게이션을 위한 파운데이션 모델을 활용해서 충돌을 회피하는 행동을 생성하고 이 행동을 supervision으로 사용하게됩니다.
그래서 결과적으로 데이터 내 i번째 이미지 o_i에 해당 방식을 적용하면 m개의 객체에 대해 각각 대응하는 추정된 pose
{p_i^j}_{j=1 \dots m}와, 각 객체에 대해 생성된 로봇 행동 시퀀스
{\bar{p}i^j[h]}_{h=0 \dots M-1}를 얻게 됩니다. 여기서 M은 RFM의 control horizon입니다.(모델이 예측하는 액션 시퀀스 수) 객체의 개수 m은 SAM에서 탐지된 객체 중 LLM을 통과한 탐지 결과의 수에 의해 결정되게 됩니다. 또 각 객체는 {l_{ig}^j}_{g=1 \dots n}과 같이 n개의 언어 지시문을 가지고 여기서 n은 생성된 프롬프트의 개수에 따라 달라진다고 보시면 됩니다.
appendix의 내용을 조금 가져와 자세히 설명드리자면 파운데이션 모델을 활용해 수도라벨을 생성하기 이전에 기존에 파운데이션 모델로서 사용되는 NoMaD라는 모델은 input으로 observation와 goal image가 input으로 들어가게 됩니다. 하지만 현재 상황(object reaching setting)으로는 goal image가 존재하지 않습니다. 따라서 수도라벨을 생성하기 이전에 NoMaD의 goal image input으로 크롭된 이미지 영역이 들어가도록하게끔 파인튜닝을 먼저 진행을 해야합니다. 이를 위해 기존 NoMaD데이터셋에 있는 목표 지점의 로봇 2D pose(NoMaD는 2D pose 정보가 있음)를 카메라에 투영하여 이미지 좌표 [u,v]를 얻고, 그 주변을 랜덤 박스로 잘라 goal image를 구성하게되고. 이 입력 형태에 적응시키기 위해 배치의 절반은 crop goal, 절반은 원래 goal image를 주는 방식으로 NoMaD를 추가 파인튜닝을 진행하고 그 후에 이를 바탕으로 수도라벨을 생성하게 됩니다.
Architecture
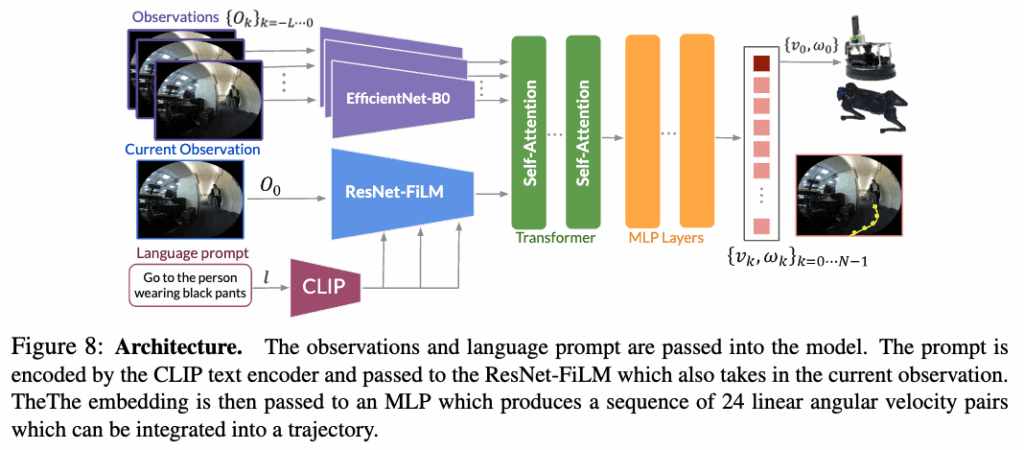
그림 8은 해당 논문에서 제안하는 네트워크 아키텍처 \pi_\theta의 전체 구조입니다. 입력된 언어 지시문 l을 고정된(frozen) CLIP 텍스트 인코더를 사용하여 임베딩을 한 후에ResNet-FiLM 기반의 비주얼 인코더를 통해, 언어 지시문 l에 맞는 시각적 특징을 추출하게 됩니다.
그리고 관측 이미지 시퀀스 {o_k}_{k=-L \dots 0} 에 대해서는 EfficientNet-B0를 사용하여 시각적 특징을 추출하고, 이렇게 얻은 특징들을 Transformer를 거쳐 MLP로 전달하여, 선속도와 각속도 {v_k, \omega_k}_{k=1 \dots N}로 이루어진 속도 명령 시퀀스를 출력하게 됩니다.
Loss function
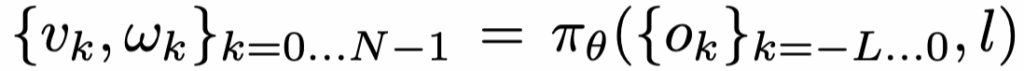
먼저 정책 \pi_\theta는 입력으로 현재 프레임 + 과거 L장의 관측 이미지 {o_k}_{k=-L\cdots 0}와, 목표 객체에 대응하는 언어 지시문 l 을 받아서, 출력으로는 앞으로 N스텝 동안의 선속도/각속도 명령 시퀀스 {(v_k,\omega_k)}_{k=0\cdots N-1} 를 예측합니다. 즉 한 번에 한 스텝 액션만 내는 게 아니라, 일정 horizon만큼의 선속도 각속도 명령을 통째로 뽑는 형태라고 보시면 될 것 같습니다.
학습 샘플을 만들 때는 증강 데이터셋에서 현재 상태 인덱스 i, 목표 객체 인덱스 j, 그리고 그 객체에 대해 생성된 프롬프트 인덱스 g 를 랜덤으로 선택합니다. 그러면 해당 샘플에 대해 목표 객체의 3D pose p_o와(실제로는 이동 로봇이므로 수평면으로 투영한 2D 목표 \tilde p_o를 사용), 그리고 teacher가 생성한 참조 궤적 {\bar p[k]}_{k=0\cdots M-1}가 함께 주어진다고 보시면 됩니다. 여기서 {\bar p[k]}는 충돌 회피 능력을 가진 로봇 파운데이션 모델(RFM)이고 구체적으로는 NoMaD로부터 만들어진 참고 경로라고 이해하시면 좋을 것 같습니다.
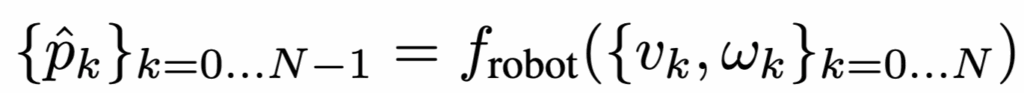
여기서 loss를 바로 cmd_vel 공간에서 계산하는 게 아니라, 정책이 예측한 {(v_k,\omega_k)}를 미분가능한 운동학 모델 f_{\text{robot}} 로 rollout해서, 가상 2D 로봇 포즈 시퀀스 {\hat p_k}{p^k}로 변환한다고 하는데 이부분에 대해서는 자세히 다루지 않아 상세한 내용은 잘 모르겠습니다.. 무튼 이를 통해서 Pose를 구한 뒤 이 포즈 시퀀스에 대해 목적함수를 계산하게 됩니다.. 전체 objective는 크게 세 가지로 구성됩니다.
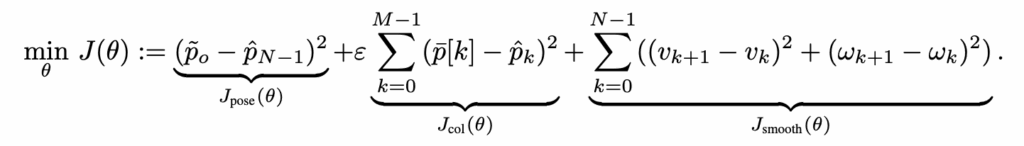
- 목표 도달 J_{\text{pose}}: rollout한 마지막 포즈 \hat p_{N-1}가 목표 객체의 2D 위치 \tilde p_o에 가까워지도록 하는 항입니다. 결국 목표 객체 근처에 도착해라에 해당하는 가장 기본적인 object-reaching supervision이라고 보시면 됩니다.
- 충돌 회피 항 J_{\text{col}}: 학생 정책의 rollout 포즈 \hat p_k가 NoMaD가 생성한 참조 궤적 \bar p[k]를 따라가도록 MSE로 맞추는 항입니다. 충돌 회피 행동을 이미 학습한 teacher(NoMaD)의 경로를 모사하도록 하는 distillation 형태라고 보시면 좋을 것 같습니다. 저자들은 기본 정책만 학습하면 목표를 향해 직선으로 움직이는 경향이 있어, 시작 지점 근처의 장애물과 충돌할 수 있다고 보고 이 항을 추가합니다.
- 부드러운 이동을 위한 항 smoothJ_{\text{smooth}}: 연속 스텝에서 속도 변화 (v_{k+1}-v_k),(\omega_{k+1}-\omega_k)가 작도록 하는 정규화 항입니다. 실제 로봇 구동에서 cmd_vel이 급격히 튀는 것을 막고 보다 안정적인 궤적을 만들기 위한 장치라고 보시면 좋을 것 같습니다.
마지막으로 저자들은 J_{\text{col}}이 목표 근처에서도 계속 회피를 강제하면 오히려 마지막 접근(last-mile reaching)을 방해할 수 있다는 점을 고려해서, 목표가 1m 이내로 가까운 경우에는 \epsilon으로 J_{\text{col}}을 마스킹하여 끄는 전략을 사용합니다. 정리하면, 이 정책 학습은 첫째 손실항은 목표 객체까지 도달하는 것, 두번째 손실항은 teacher로부터 충돌 회피 습관을 distilation 하는 것, 세번째 항은 속도 명령을 부드럽게 만드는 것 이 3가지를 동시에 만족하도록 설계되어 있다고 보시면 될 것 같습니다.
Dataset
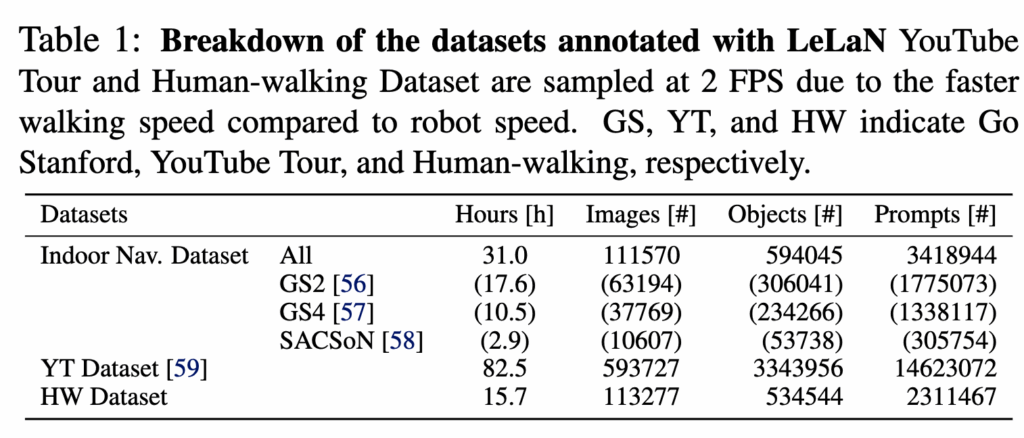
학습에 사용한 데이터셋 같은 경우는 다양한 egocentric 데이터셋을 사용하여 학습했다고 합니다.
- 실내 내비게이션 데이터셋 :사무실 건물 환경에서 모바일 로봇이 주행한 궤적(trajectory)에서 얻은 이미지 관측
- 유튜브 투어 데이터셋: 여러 국가의 투어 영상으로 구성된 유튜브 비디오 데이터
- 인간 보행 데이터셋 : 실내 환경 및 야외 도심 환경에서 카메라를 들고 걸으며 수집한 데이터
Experiments
실험은 real world에서 실제 로봇으로 평가하며 저자들이 던진 네 가지 질문(Q1–Q4)에 맞춰 실험을 구성하여 평가를 진행합니다.
Q1. 다양한 언어 지시문(단순/복잡/노이즈)에서 목표 객체까지 도달할 수 있는가?
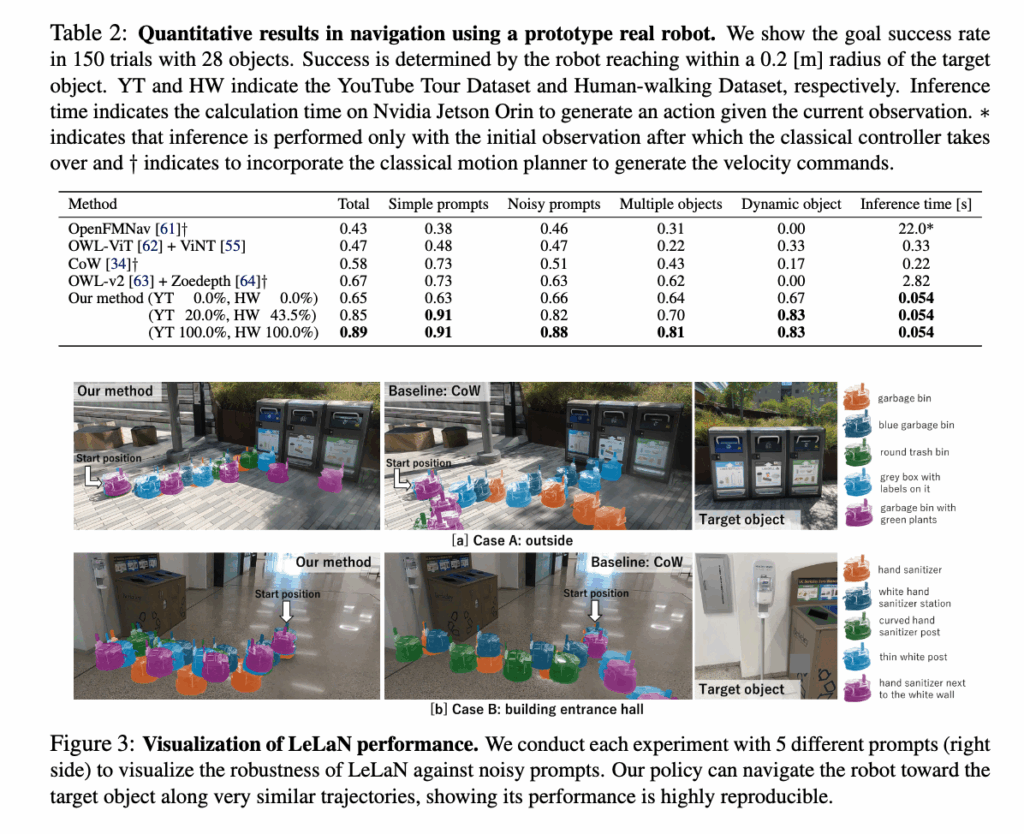

저자들은 단순히 “Go to chair” 같은 깨끗한 지시뿐 아니라,수식어가 과하게 붙거나 틀린 표현이 섞인 noisy prompt, 혹은 객체를 직접적으로 묘사하는게 아니라 간접적으로 묘사하는 지시까지 포함해 모델의 강건성을 평가합니다. FIg3 맨 오른쪽에 평가에 사용한 지시표현이 나와있고 아래 동그란 소파예시를 보시면 실제로 빨간 표시는 잘못된 지시어로 노이즈를 추가하거나, 직접적으로 객체를 언급하지 않은 표현을 사용하여 평가하였다고합니다.
결과적으로 LeLaN이 가장 강한 베이스라인 대비 높은 성공률을 보이고, 특히 노이즈가 섞인 지시에서 성능 격차가 더 크게 벌어지는 점을 강조합니다. 그리고 표 2는 총 1050회 이상의 평가에서 얻은 정량 분석 결과라고 합니다.
Q2. 장애물이 있을 때 충돌 회피까지 가능한가?
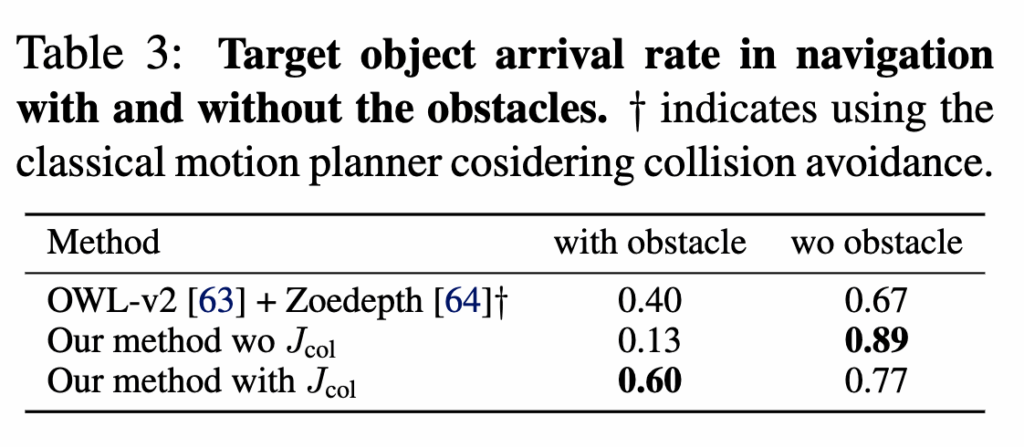
해당 실험 같은 경우 목표로 직진(beeline)하는 경향 때문에 생길 수 있는 충돌 문제를 다루는 실험이라고 보시면 될 것 같습니다. 이라고 보는 저자들은 이를 해결하기 위해 RFM(NoMaD)에서 충돌 회피 행동을 증류(distill)하는 목적함수 J_{\text{col}} 을 추가했고, 실제로 장애물을 배치한 환경에서 J_{\text{col}}유무에 따른 성능 차이를 비교합니다.
J_{\text{col}} 항이 없으면 장애물에 자주 충돌하고, J_{\text{col}}을 넣으면 장애물 환경에서 목표 도달률이 개선되는 결과를 확인할 수 있습니다. 또 저자들은 고전적 모션 플래너를 결합한 베이스라인도 비교하긴하지만 속도,전환 측면에서 한계가 있음을 언급하며 LeLaN(+J_{\text{col}})의 이점을 강조합니다.
Q3. 로봇 형태(embodiment)와 카메라가 바뀌어도 일반화되는가?

저자들은 LeLaN이 in-the-wild비디오(다양한 카메라/높이/포즈)를 학습에 포함한다는 점을 근거로,새로운 로봇/카메라로도 전이가 되는지를 확인하는 실험도 진행을 합니다. 저자들은 서로 다른 4가지 로봇 세팅(예: 4족 로봇, 다른 fisheye, narrow FOV, 높이가 다른 카메라 등)에서 정책을 테스트하고, 형태와 카메라가 바뀌어도 목표 객체로의 내비게이션이 가능함을 정성적으로 보여줍니다. 특정 센서/세팅에만 과적합된 정책이 아니라는 주장을 정성적인 결과로 보여줍니다.
Q4. in-the-wild 비디오(YouTube/Human-walking)가 성능에 실제로 기여하는가?
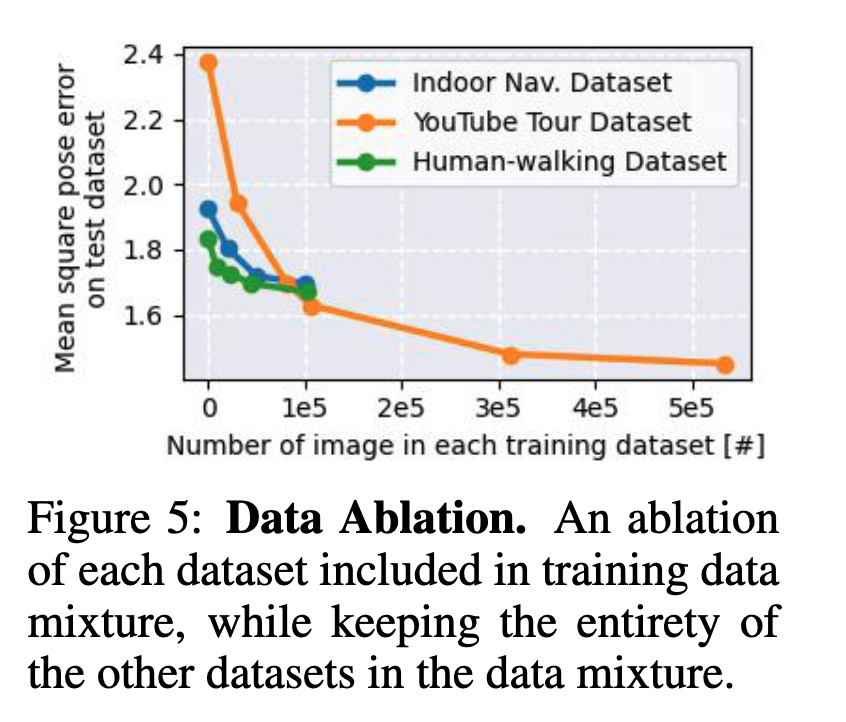
위는 데이터 규모 관점에서 어블레이션 실험입니다. 저자들은 Indoor 로봇 데이터만으로도 학습이 되지만, 성능이 어느 지점에서 saturation되고, 반면 YouTube Tour 같은 대규모 in-the-wild 데이터는 100K 프레임 이후에도 성능을 계속 끌어올려 500K 프레임 규모의 최종 정책까지 학습 가능하게 만든다고 주장합니다. 이런 파운데이션 모델 기반 라벨링 파이프라인이 스케일업 가능한 데이터 확장을 제공한다는 점을 어블레이션 실험으로 보여주는 것 같습니다. 또 실제 로봇 평가에서도 in-the-wild 데이터 비중을 늘릴수록 성능이 좋아지는 결과 또한 Table 2에서 확인하실 수 있습니다.
Conclusion
일단 NoMaD 파인튜닝 과정이 이해하기가 좀 어려웠습니다..아직도 잘 이해했는지는 모르겠지만, 결국 해당 방법론은 깊이 추정 모델, VLM, LLM 과 같은 파운데이션 모델이 가진 지식을 활용해서 행동 정보가 없는 egocentric 데이터에 언어 라벨 이랑 행동라벨을 자동으로 부여해서 데이터를 증강시킴으로써 로봇 분야에서 항상 걸리는 언어/행동 라벨 부족 문제를 해결하고자했다라는 것을 보여주는 것 같습니다. 그리고 실험파트에서는 언급하지는 않았지만 한계도 물론 존재합니다. 예를 들어 동일 객체가 여러 개 있을 때 공간적 구분이 필요한 상황(“왼쪽 오른쪽 중간 등등”)에서 혼동하는 문제 그리고 충돌 회피가 여전히 어렵다고는 합니다. 현재 방법론은 객체가 보이는 위치에서 객체까지 다가가는 문제를 다룬다는 점에서도 그렇고 결국 텍스트로 목표를 지정하고 로봇이 실제 3D 환경에서 계획/회피까지 안정적으로 수행하기에는 아직 한계가 있는 것 같습니다. 그리고 중요한 건 아니지만 마지막으로 읽으면서 개인적으로 가장 궁금했던 부분은 이 논문이 큰 틀에서는 NoMaD류와 다르게 waypoint(상대 좌표 시퀀스) 를 출력하지 않고, 선속도,각속도(v,ω) 로 바로 출력된다는 점입니다. 근데 크게 보면 NoMaD에서 입력이 goal Image 에서 language만 바뀌고 텍스트 인코더만 추가된 것 같은데 왜 이전과는 다른 출력 공간을 택했는지 의문점이 들었지만 이에 대한 저자의 언급은 따로 없었던점이 아쉬운 것 같습니다. 사실 지금까지 제가 읽었던 논문들의 방법론들은 직접적인 로봇의 속도 값이 아닌 좌표값을 액션의 형태로 출력을 했기 때문에 기존 다양한 네비게이션 방법론들은 찾아보면서 상황에 따라 어떤 방식을 주로 채택해서 사용하는지에 대해서 조금 더 알아봐야할 것 같습니다. 갈길이 먼 것 같네요 열심히 가야겠습니다.
이만 리뷰 마무리하도록 하겠습니다. 감사합니다.