안녕하세요 이번에 들고온 논문은 최신 MLLM 들의 시각적 능력이 언어적 priors에 크게 의존하고 있고 실제 모델의 근본적인 시각적 능력을 평가하기 위한 벤치마크를 제공한 논문입니다. 1/13일에 아카이브에 올라온 따끈따끈한 논문입니다.
Abstract
멀티모달 LLM들은 최근 굉장히 많은 태스크에서 좋은 성능을 보이고 있지만, 저자들은 이 모델들의 시각 이해 능력 자체에는 여전히 근본적인 한계가 있다고 주장합니다. 인간은 언어를 배우기 훨씬 이전부터 물체 인식, 공간 관계 파악 같은 핵심적인 시각 능력을 자연스럽게 습득하는 반면, 현재의 MLLM들은 이런 능력이 부족한 대신 언어적 priors에 크게 의존해 시각 문제를 해결하고 있다는 것입니다.
저자들이 흥미롭게 지적하는 부분은, 최신 MLLM들이 3세 아이도 별다른 고민 없이 해결할 수 있는 아주 기초적인 시각 문제에서조차 실패한다는 점입니다. 다만 기존 벤치마크들은 대부분 언어 이해나 지식 추론이 강하게 섞여 있어, 모델의 “순수한 시각 능력”을 정확히 평가하기 어렵다는 한계가 있었습니다.
이 문제를 분석하기 위해 저자들은 BABYVISION이라는 새로운 벤치마크를 제안합니다. BABYVISION은 언어 지식의 개입을 최대한 배제하고, MLLM이 실제로 기본적인 시각적 개념을 이해하고 있는지를 평가하는 데 초점을 맞추고 있습니다. 총 388개의 문항으로 구성되어 있으며, 4개의 큰 범주와 22개의 세부 시각 task를 포함하고 있습니다.
실험 결과를 보면, 최신 모델들조차 인간 기준선에 크게 못 미치는 성능을 보입니다. 예를 들어 Gemini3-Pro-Preview는 49.7점을 기록하는데, 이는 6세 아동보다도 낮은 수준이며 성인 평균 점수인 94.1점과는 상당한 차이가 납니다. 이는 현재 MLLM들이 지식 중심의 평가에서는 높은 성능을 보이지만, 물체의 지속성이나 형태 인식과 같은 근본적인 시각적 primitive는 제대로 학습하지 못하고 있음을 나타냅니다.
저자는 BABYVISION에서의 성능 향상이 인간 수준의 시각 인지와 시각적 추론 능력으로 나아가기 위한 중요한 단계가 될 것이라고 주장합니다. 또한 단순 선택형 응답을 넘어 생성 기반 모델로 시각 추론을 평가하기 위해 BABYVISIONGEN과 자동 평가 툴킷을 같이 제안했다고 합니다.
Introduction
저자는 먼저 인간의 시각 능력이 언어 습득보다 훨씬 이른 시점에서 형성된다는 점에서 이야기를 시작합니다. 실제로 영아는 생후 몇 개월만 지나도 형태나 질감을 구분하고 움직이는 물체를 추적하며 occlusion 이나 depth 정보를 추론하고 간단한 물리적 사건에 대해 이해할 수 있다고 합니다. 이러한 능력은 언어적 능력이 추론에 개입되기 이전에 자연스럽게 발달하고 이후 언어 이해나 추상적 사고, 운동 계획과 같은 고차원 인지 기능의 토대가 된다고 합니다.
그러나 현재의 MLLM 들은 정반대의 능력 분포를 보인다고 저자들은 지적합니다. 이 모델들은 고차원 지식이나 교육을 요구하는 고수준 벤치마크, 예를 들어 복잡한 수학, 기하 추론이나 대규모 인물 및 장소 인식 심지어 의료 스타일의 질의응답과 같은 태스크에서는 매우 강력한 성능을 보입니다. 하지만 아이러니하게도 언어적 중재 없이도 어린 아이들이 쉽게 해결할 수 있는 기본적인 시각 과제에서는 일관되게 약점을 드러낸다는 것을 지적합니다.
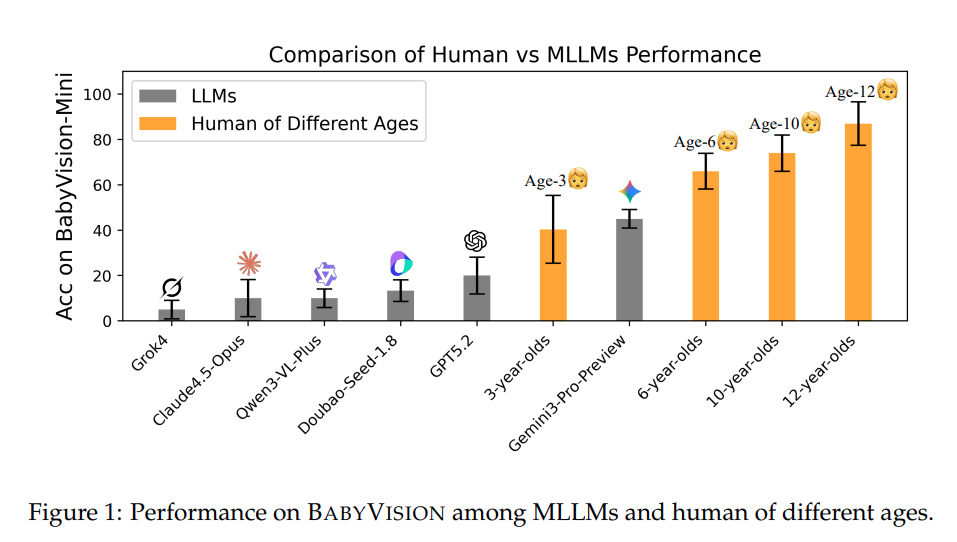
구체적으로 시각적으로 구분(discrimination) 및 시각적 추적(tracking), 공간 관계 이해, 단순한 시각 패턴 인식과 같은 과제에서 MLLM 들의 수준은 3~12세 수준의 인간이 거의 언어를 사용하지 않고 해결하는 수준보다도 못하다고 하며 위의 Figure1을 보여줍니다. 그러면서 기존의 멀티모달 평가 벤치마크들은 이러한 언어를 넘어선 시각 이해 능력을 체계적으로 측정하지 못하고 있었다는 것이 저자들의 문제정의라고 생각하시면 됩니다. 많은 벤치마크들이 시각 입력을 사용하지만 실제로는 텍스트 이해나 지식 추론이 강하게 개입되어 있어 모델이 순수한 시각적 인지 능력을 갖추고 있는지를 분리해서 평가하기 어렵다는 한계가 있었습니다.
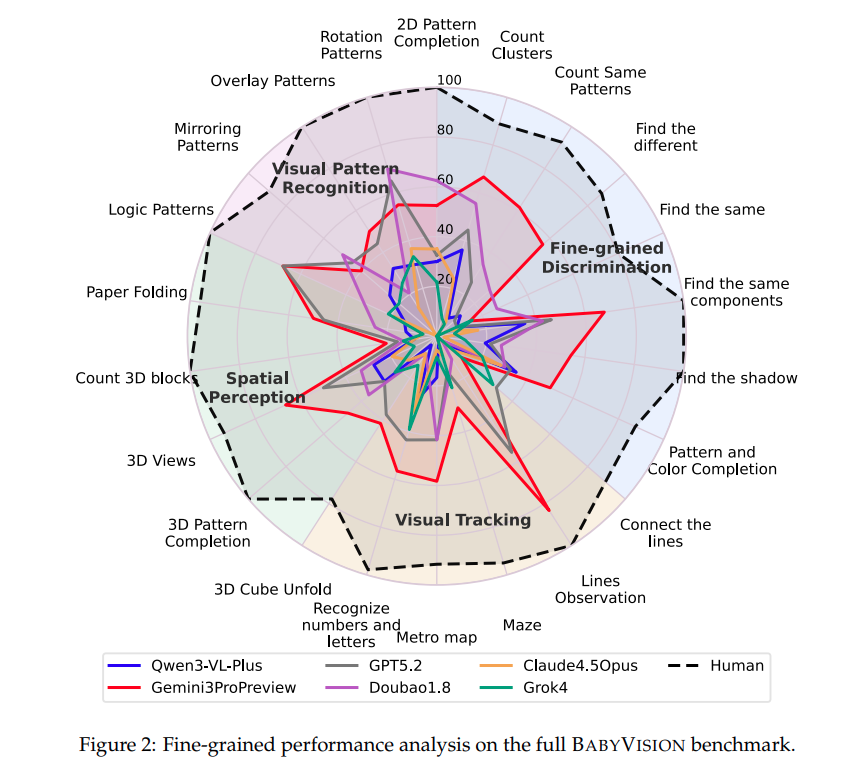
저자의 벤치마크 기준 Human 의 성능보다 대부분의 최신 MLLM 들의 성능이 현저히 낮음을 확인할 수 있습니다. 인간 평가자는 평균 94.1%의 정확도를 기록하는 문제들을 약 44프로 해결하는 모습을 보였고, 이러한 격차는 저자가 구분한 4가지 도메인에서 모두 일관적으로 나타납니다. 특히 visual tracking 이나 spatial perception 에서 가장 큰 실패가 있었고, 교차하는 선을 따라가며 동일한 객체를 감지하거나 3차원 구조를 머릿속으로 변환하는 문제에서 반복적으로 오류가 있었다고 합니다.
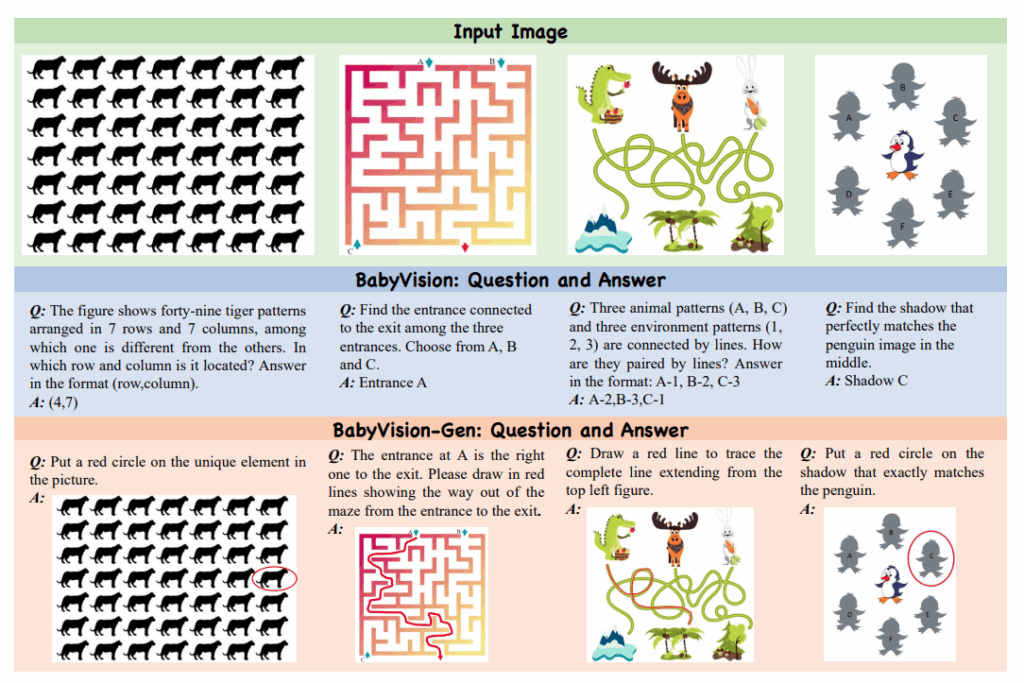
실제 문제들의 예시입니다. 틀린그림 찾기, 미로 탈출할 수 있는 입구 찾기, 라인 따라가기, 그림자 찾기등 시각적 이해도를 평가하는 문제들로 이루어져 있는 것을 알 수 있습니다.
저자들은 이 논문의 기여를 3가지로 정리합니다.
- 언어를 넘어선 기초 시각 추론 능력을 평가하기 위한 정제된 벤치마크 BABYVISION 제안
- 시각적 생성 과정을 통해 추론 능력을 평가하는 BABYVISION-GEN 과 신뢰도 높은 자동 평가 툴킷을 제안
- 최신 MLLM과 생성 모델들을 폭넓게 평가하여 인간과 모델 간의 큰 성능 격차와 모델 간 편차를 체계적으로 분석하고 RLVR 학습이나 생성 기반 접근이 시각 추론에 어떤 영향을 미치는지 탐구
BabyVision
벤치마크 논문인 만큼 저자들이 제안한 벤치마크의 구성과 설계 철학을 설명합니다. 앞서 언급했지만 저자의 벤치마크는 기존 멀티모달 벤치마크처럼 고수준 의미 추론이나 도메인 지식을 묻는 것이 아니라, 인간이 언어를 배우기 이전 혹은 언어와 함께 매우 이른 시기에 습득하는 기초적인 시각 능력 자체를 평가하는 것이 목적입니다.
저자는 총 4가지의 시각 중심 범주로 나누는데 각각
- Fine-grained Discrimination, 미묘한 시각적 차이를 구분하는 능력 총 8개 세부 유형
- Visual Tracking, 선이나 경로, ㅇ무직임을 따라가며 객체의 정체성 유지 5개의 세부 유형
- Spatial Perception, 3차원 구조나 공간적 관계를 이해하는 능력을 평가 5개의 세부 유형
- Visual Pattern Recognition, 논리적 기하학적 패턴을 인식하는 능력을 평가 4개의 세부 유형
이러한 분류를 토대로 388개의 질문을 포함하는 벤치마크를 구축했고 문제 수를 단순히 늘리는 것보다 시각적 조건과 문제 구조 측면에서 최대한 다양한 유형의 시각 추론을 포괄하도록 설계했다고 합니다.
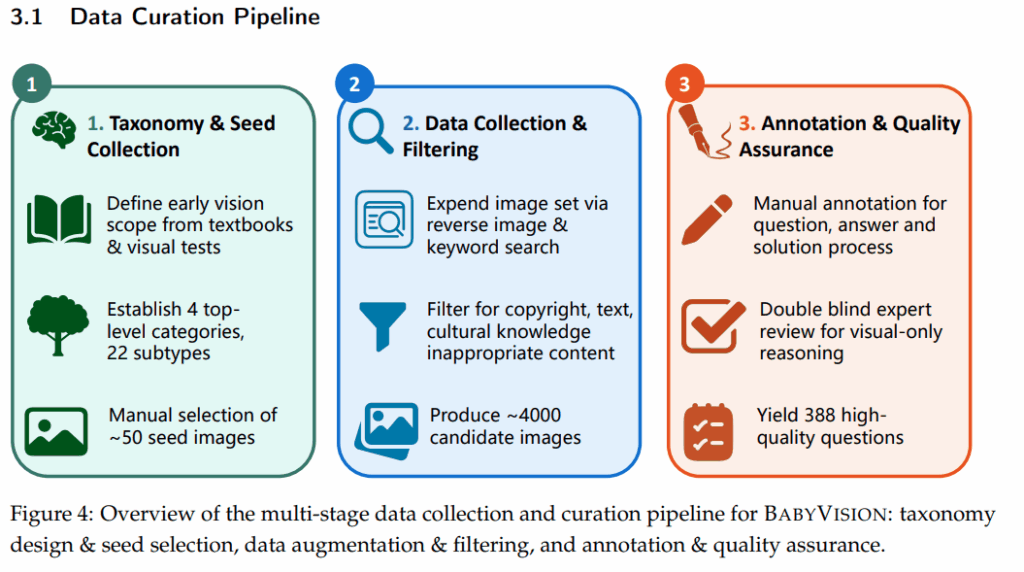
저자는 데이터셋의 신뢰성과 타당성을 확보하기 위해, 상당히 엄격한 다단계 데이터 수집 및 정제 과정을 거쳤다고 합니다. 이 전체 파이프라인은 3가지 단계로 위의 Figure로 구성되어 있습니다.
첫째는 Taxonomy & Seed Collection 으로 발달심리학을 기반으로 early vision의 범위를 정의합니다. 12세 이하 아동의 교과서나 표준화된 시각 발달 테스트를 참고해서 어떤 시각 능력이 인간에게 근본적인지를 정리하고 이를 바탕으로 앞서 언급한 4개의 상위 범주와 22개의 세부 유형을 확정합니다. 이후 각 세부 유형마다 4~5개의 대표적인 시각 과제를 잘 나타내는 seed image 를 잘 수집해서 선정했고 약 100개의 고품질 시드 이미지를 확보합니다.
둘째는 Data Collection and Filtering 으로 저자들이 수집한 seed Image를 바탕으로 역이미지 검색과 키워드 기반 검색을 통해서 유사한 이미지를 인터넷에서 대규모로 수집하는 것입니다. 이 과정에서 저작권이 없는 이미지만 엄격히 선별했고 텍스트가 과도하게 포함되어있거나 문화적 배경 지식이 필요한 경우는 제거했다고 합니다. 이 단계를 거치면 약 4천개의 후보 이미지가 생성됩니다.
셋째는 Annotation and Quality Assurance로 모든 후보 이미지는 annotator에 의해 수작업으로 검수되었다고 합니다. 먼저 이미지가 정의된taxonomy에 부합하는지 검증하고 텍스트 읽기나 문화 지식에 의존하는경우 제외 그리고 각 이미지들에 대해서는 질문과 정답뿐만 아니라 왜 그 정답이 맞는지에 대한 설명을 상세한 solution process를 함께 작성합니다.
최종적으로 모든 annotation은 전문가가 해당 문제가 언어가 아닌 시각적 분석만으로 해결이 가능한건, 그리고 정답과 추론이 명확한지를 검증했고 두명의 전문가가 동의한 경우에만 최종 문제로 포함되었다고 합니다.
설계에서 돋보이는 점은 위치의 편향을 줄이기 위해서 정답 분포의 위치도 균형 있게 설정하였고, 질문 길이를 26단어 정도로 설정해서 불필요한 설명을 최소화해서 언어적 추론이나 텍스트 기반의 꼼수를 못사용하게 구성하였습니다. 또한 평가 데이터셋 외에도 동일 파이프라인을 거친 학습용 예제를 1400개 구성하여 학습이 모델 성능에 영향을 미치는지 분석했습니다.
최근 언어 모델들의 RLVR 즉 강화학습 기법을 통해 추론 성능을 크게 향상 시키는 기법이 주목받고 있어서 이 접근이 시각 추론에도 동일하게 효과가 있는지를 확인하기 위해 실험을 진행했다고 하며 이를 위해 Qwen3-VL-8B-Thinking을 베이스로 RLVR 기반 파인튜닝을 진행해보았다고 합니다.
다만 저자가 추가로 구성한 1400개의 구성이 4개의 큰 주요 태스크 범주는 일치하지만 난이도 분포가 달라 초기 성능은 학습 데이터셋은 34.2, BABTVISION set은 13.1% 로 매우 낮았습니다.
학습 과정에서 사용할 보상 신호는 모델이 생성한 답변과 정답 간의 일치 여부를 LLM judge로 판단해서 모델이 점점 더 일관된 추론을 할 수 있게 했습니다.

해당 Figure 를 통해 학습에 사용하지 않은 테스트 데이터에서도 성능이 올라 RLVR 방식이 단순한 과적합이 아닌 일정 수준의 일반화 효과가 있음을 보여줍니다.
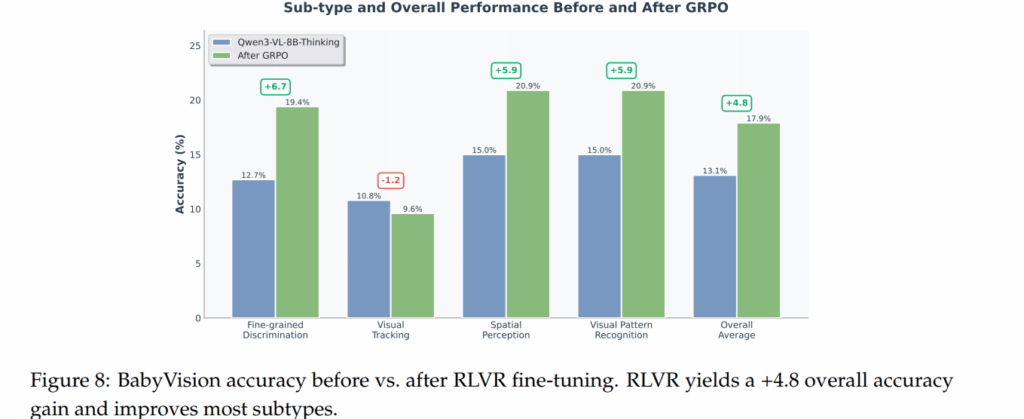
Visual Tracking을 제외하면 전체 정확도 기준 4.8%의 성능 향상이 있었다고 합니다. 저자의 분석으로는 이러한 tracking에 관련된 문제는 객체의 정체성을 유지해야 하는 연속지각 문제로 언어로 생각을 길게 풀어내는 방식이랑은 잘 맞지 않아 이러한 결과가 나왔다고 분석합니다. 다시 말해 RLVR은 시각 문제 중에서도 언어적 추론으로 재구성이 가능한 유형에는 효과가 있지만 인간의 저수준 시각 처리에 가까운 능력까지 대체하지는 못합니다.
Evaluation
평가 단계에서는 모든 모델에 대해 동일한 프롬프트 템플릿을 사용합니다. 모델에게는 문제를 충분히 생각한 뒤 지정된 형식으로 최종 답변을 제시하도록 유도하고 가능할 경우 각 모델에서 가장 높은 reasoning effort 설정을 사용했다고 합니다.
모델 출력의 평가는 LLM as judge 방식으로 Qwen3-Max 를 사용해서 두 답변이 의미적으로 동일한지를 판단했고 그 근거는 저자들이 해당 평가 방식이 인간 평가자와 100% 일치하는 결과를 보였다고 합니다. 사용된 judge 프롬프트는 appednix에 존재합니다.
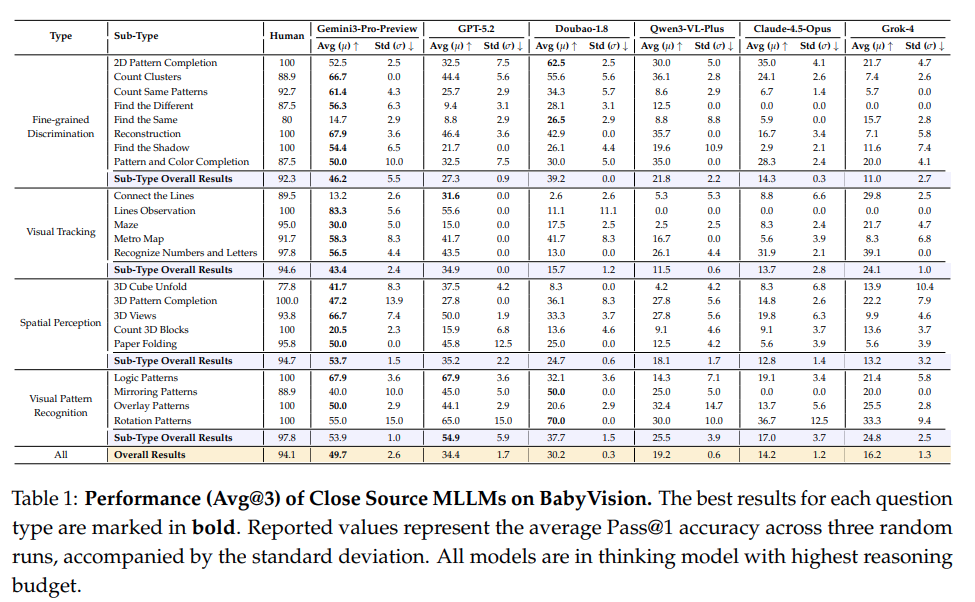
저자의 평가 방식은 3회를 시행했을떄를 평가하며 평균과 표준편차를 같이 보여줍니다. 인간 대비 절반의 능력과 네 도메인 모두에서 낮은 성능을 보이는 것을 토대로 기초 시각 능력 자체가 전반적으로 부족하다는 한계로 언급합니다.
BABYVBISION-GEN
저자는 실험을 진행하면서 한가지 중요한 관찰을 합니다. 많은 문제들이 사실 언어로 답을 설명하는 것보다 시각적으로 표현하는 편이 훨씬 자연스럽다는 점입니다. 예를 들어 미로를 푸는 문제나 패턴을 완성하는 문제를 이간이 해결할 때 보통은 경로를 따라 선을 그리거나 도형을 직접 완성하지 머릿속 과정을 문장으로 풀어 설명하지는 않습니다. 다른 부분 찾기 (find the diffrence) 문제 역시, 차이점을 말로 설명하기보다는 해당 영역을 직접 동그라미로 표시하는 방식이 훨씬 직관적입니다. 저자는 이러한 관점에서 현재의 MLLM 평가 방식이 시각 추론을 언어 출력으로 강제하고 있는 구조적 한계를 가지고 있다고 봅니다. 모델이 실제로는 시각적으로 문제를 어느정도 이해하고 있음에도 불구하고 이를 언어로 변환해 설명하지 못해서 성능이 낮게 측정될 수 있다는 것입니다. 이러한 문제의식을 통해 저자들은 언어 출력을 우회하고 이미지 생성 자체를 통해 시각 추론 능력을 평가하는 BABYVISION-GEN 을 제안합니다.
Test Reasoning in Generation Models
GEN 버전은 BABYVISION 문제 중 일부를 선택해서 정답을 이미지 생성으로 표현하도록 재구성한 버전입니다. 기존의 질문-응답 형식 대신, 모델에게 해당 과정을 보여주는 이미지를 생성하라는 generation prompt를 제공합니다. 예를 들어서 미로 문제에서는 출구까지의 경로를 선으로 표시, 패턴 문제에서는 누락된 부분을 완성하거나 올바른 영역을 직접 표시하도록 합니다. 다시 말해서 말로는 설명을 못해도? 그림으로는 풀 수 있는가 를 묻는 실험이라고 생각하면 됩니다.
Evaluation
BABYVISION-GEN의 평가는 단순 텍스트 비교보다 훨씬 까다롭습니다. 모델이 생성한 이미지가 정답을 시각적으로 제대로 표현했는지를 판단해야 하기 때문입니다. 이를 위해 저자들은 모든 모델에게 원본 이미지를 유지한 채, 최소한의 시각적 오버레이(선, 원, 화살표, 간단한 텍스트 등)만 추가하도록 지시합니다. 이렇게 하면 모델의 예측을 명확하게 표현하면서도 원본 시각 정보를 훼손하지 않고 비교할 수 있습니다.
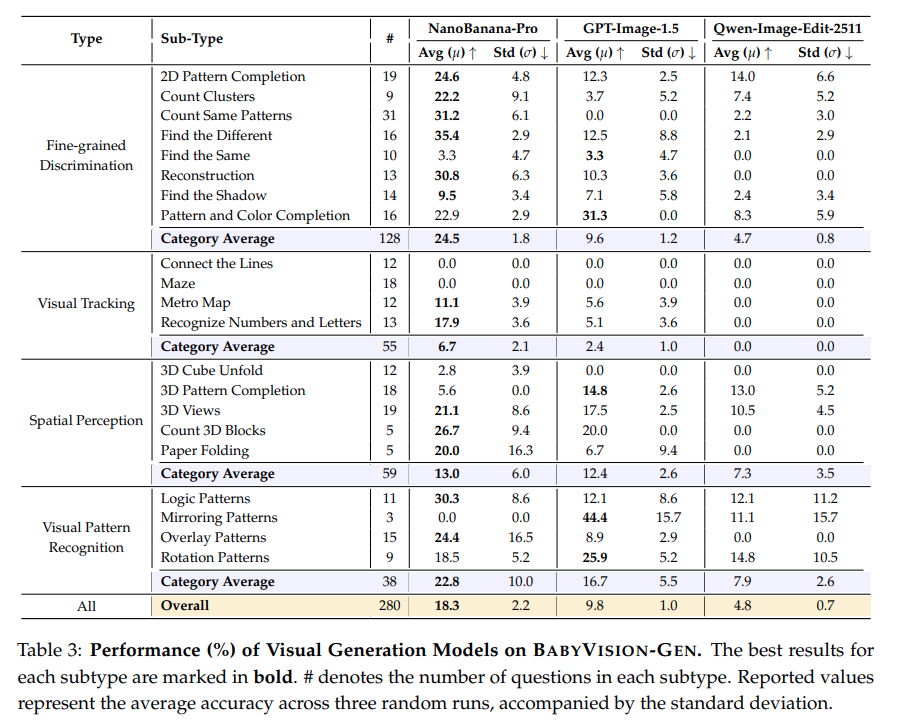
자동 평가를 위해 저자들은 Gemini-3-Flash를 judge로 사용합니다. 평가 시 judge는 세 가지 이미지를 입력으로 받습니다. 첫째는 원본 이미지, 둘째는 인간이 만든 정답 solution image, 셋째는 모델이 생성한 결과 이미지입니다. judge는 문제 subtype별로 정의된 기준에 따라, 모델의 출력이 정답과 일치하는지를 이진 판단합니다. 예를 들어, 미로 문제에서는 동일한 경로를 따라갔는지, 선택 문제에서는 같은 옵션을 표시했는지 등을 기준으로 평가합니다. 자동 평가의 신뢰성을 검증하기 위해, 저자들은 NanoBanana-Pro 모델의 모든 출력 결과에 대해서 박사급 어노테이터가 평가했다고 합니다.. 그 결과 자동 평가와 인간 평가 간의 일치율은 96.1% 정도로 높았고, F1 점수는 0.924로 높아 이를 judge를 대규모 평가에 활용해도 무리가 없을 정도의 신뢰도를 가진다는 것으로 해석합니다.
Discussion
왜 최신 MLLM 은 쉬워보이는 시각 문제를 틀리는지에 대한 분석입니다.
- Fine grained detail 손실, 너무 말로 설명하려다 디테일을 잃는다고 주장하는 케이스입니다. 첫번 째 유형은 아주 미세한 시각적 차이는 말로 설명하기 애매하고 이러한 문제를 풀때 인간은 굳이 말로 설명하지 않습니다. 이 모양이 저모양과 비슷한가 겹치나? 이러한 것을 병렬적인 기하학적 비교로 바로 판단한다고 합니다. 반면 MLLM 은 언어적 개념으로 압축하는 과정에서 미세한 형태 정보가 사라지고 결정적 차이를 최종적으로 잡아내지 못한다고 주장합니다. Figure6 a 에서도 모델이 그럴듯한 언어적 추론을 길게 하지만, 정작 문제의 핵심인 외곽선 일치여부를 놓칩니다.

Manifold identitiy 유지 실패, 선을 따라가다 길을 바꿔버린다. 두번째 실패 유형은 연속적인 구조의 정체성을 끝까지 유지하지 못하는 문제라고 합니다. 즉 앞서 언급한 tracking 문제입니다. 사람은 미로 문제나 선 연결 문제에서 특정 선 하나를 시각적으로 고정하고 교차점이 나와도 그 선을 계속 따라갑니다. 이는 언어 이전 단계의 원초적인 시각 능력이라고 언급합니다. 다만 MLLM은 이를 단계별 텍스트 지시로 바꿔 처리하고 이는 왼쪽으로 간다 → 아래로 간다 → 오른쪽으로 간다와 같은 표현이 되어 경우의 수가 생기고 특정 선에 대한 지속적인 정체성 표현이 사라진다고 합니다.

3D spatial imagination 문제로 3차원 공간 상상의 실패입니다. 인간은 2D를 보고도 3D 구조를 구성한 뒤 회전하거나 다른 시점에서 바라보는 걸 비교적 자연스럽게 하는데 이 과정도 거의 비언어적인 정신적 시뮬레이션이라고 합니다. MLLM 은 이를 이해할 수 없기에 높이가 몇이다. 뒤에 더 높은 것이 없다 와 같이 언어적 논리적 규칙으로 3D구조를 근사하고 이는 3D 공간의 좌표계나 가림 관계를 설명하기에 어렵습니다.

Visual pattern induction 실패, 구조보다는 겉모습에 더 집착한다는 내용으로 시각적 패턴에서 추상 규칙을 유도하는 능력의 부족입니다. 사람은 회전한다, 이동한다 대칭된다 같은 관계쩍 변환 규칙을 먼저 추출하고 객체를 변수처럼 다룬다고 합니다. 하지만 MLLM 은 속성 으로 나열하려는 경향이 있다고 합니다. 즉 갈색이 여기있고 이 위치에는 주황색이고 이렇게 표면적 특징에 집중하여 실제로 중요한 구조적 변환 규칙을 모른다고 합니다.

Beyond Language : Visual Externalization
저자는 앞선 분석들을 토대로 MLLM 들의 시각 정보를 언어로 압축하는 과정에서 병목이 되므로 우회하는 방식을 제안하는데, 인간이 BABYVISION 들의 문제를 말로 생각하며 풀지 않는다는 점에서 굳이 MLLM 로 하여금 언어 공간에서 reasoning 을 한 뒤 텍스트로 답을 내놓아야할 필요가 있냐는 질문을 합니다. 대신 시각 공간에서 생각하고 시각적인 결과물로 답을 내는 방식을 언급하고 이를 BABYVISION-GEN의 실험을 통해 그 가능성을 보였습니다.
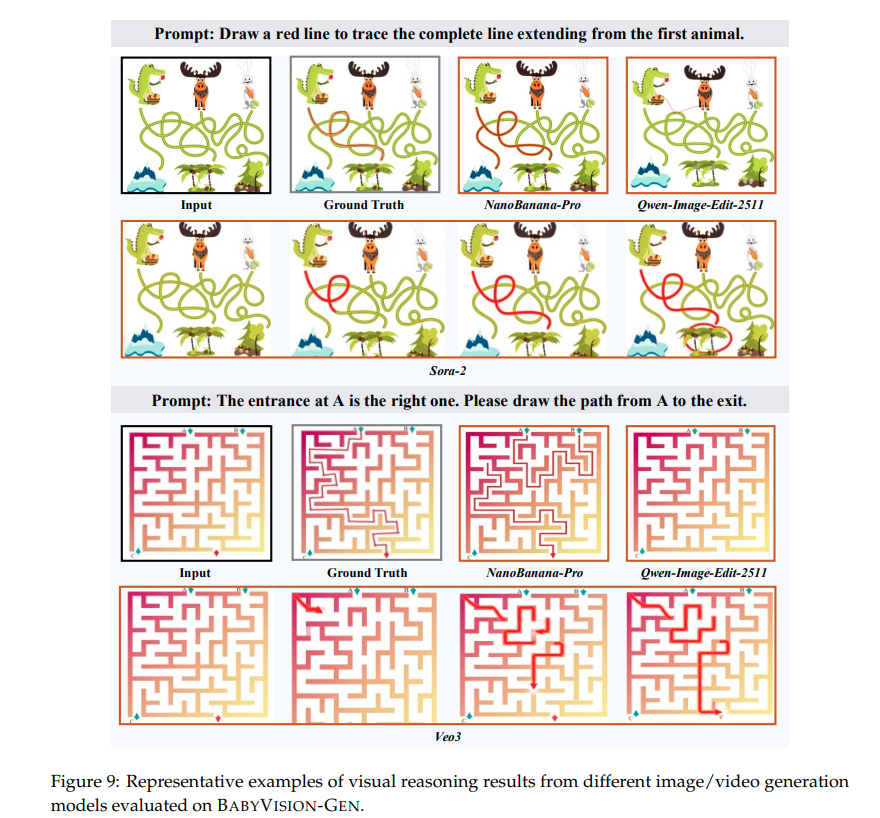
저자들은 이미지 비디오 생성 모델을 GEN 데이터로 평가하며 그 결과로 일부 모델이 실제로 인간처럼 직접 경로는 그리거나 패턴을 완성하는 방식으로 문제를 해결하려고 하는 점을 언급합니다.
특히 sora2 나 Nanobanana-Pro 같은 모델은 미로 문제에서 실제로 빨간 선을 따라 경로를 그려 나가며 해답을 표현하는 모습을 보입니다. 이는 기존 MLLM 에서 보기 힘들었던 인간적인 시각적 사고 과정에 가깝다고 합니다. 그렇지만 해당 문제들을 잘 푸는것은 아니고 생성 결과에 여전히 오류가 많아 시각 생성 자체만으로는 충분하지 않고 시각적 이해 능력이 충분해야 가능해 Future work 로 남겨둡니다.
Conclusion
기존의 MLLM 들의 문제점들을 토대로 언어 습득 이전에 인간이 획득하는 초기 시각 능력을 평가하는 데이터셋을 제안합니다. 기존 MLLM 들의 문제점들의 근본 원인으로 verbalization bottelneck을 지목하고 향후 MLLM 들의 진전은 모델의 스케일업이나 언어 추론 강화가 아닌 시각 정보를 끝까지 보존한 채 reasoning 하는 아키텍처적 변화에서 나올 가능성이 높다고 주장합니다. 또한 BABYVISION-GEN 을 통해 시각 생성 기반 평가라는 대안을 제시합니다.
감사합니다.