안녕하세요, 허재연입니다. 오늘도 Video Scene Graph Generation 논문을 가져 왔습니다. 포멧과 공개 시기를 미루어 보아 CVPR2026에 제출된 논문이 아닐까 하네요. 지금까지의 방법론들과는 다르게 VLM의 정보를 활용합니다. LLM을 적용하려는 시도는 이전에도 있었는데 VLM(Qwen2.5-VL-7B-Instruct 사용)을 적극적으로 도입한 논문은 많지 않았기에 재밌게 읽었습니다. 그럼 리뷰 시작하겠습니다.

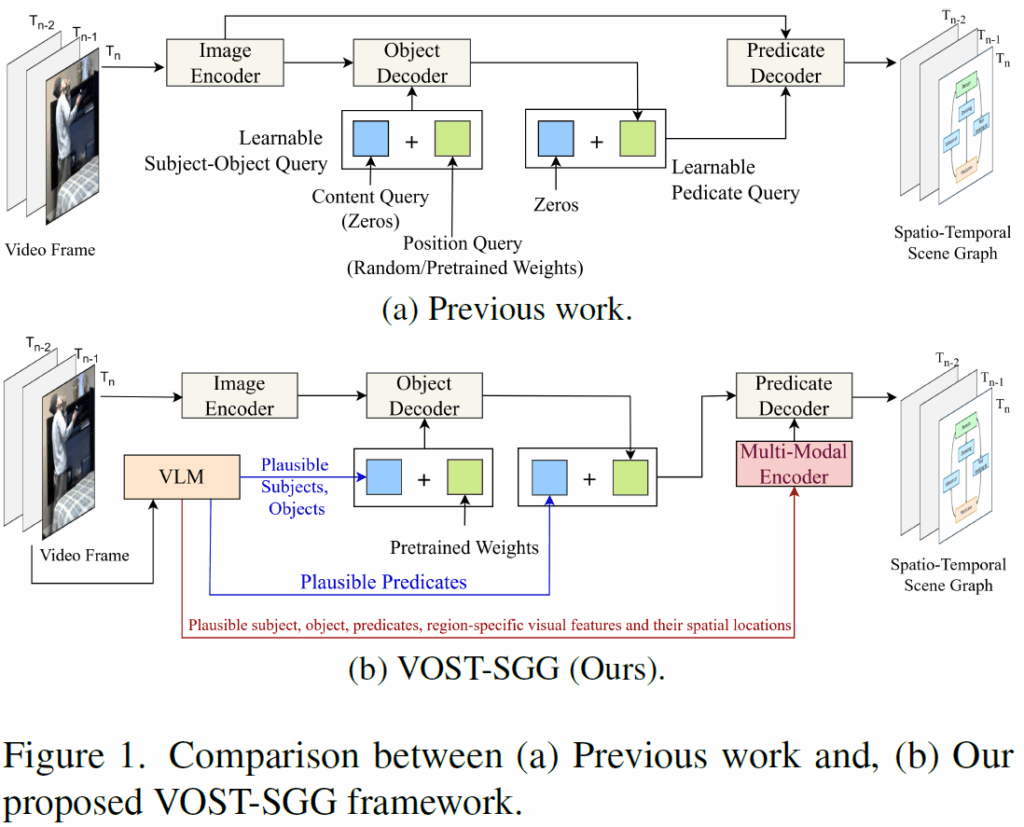
이제 점점 Video SGG 논문들은 기존에는 1.Faster RCNN으로 물체들을 검출하고 이후 2. 검출 결과들을 temporal 축으로 묶어 후처리하여 이들 간 relation을 예측하는 2단계 구조로 많이 수행되었습니다. 최근에는 DETR 구조를 기반으로 1-stage 예측을 하는 흐름으로 거의 넘어오고 있습니다.
DETR 구조는 기본적으로 트랜스포머 디코더에서 learnable queries와 visual feature가 Cross-Attention을 하며 예측을 하게 됩니다. 이 때 learnable query는 1.모델이 무엇에 집중해야 하는지를 지정하는 content query와, 2.모델이 어디에 주목해야 하는지를 나타내는 position query로 이루어지는데, 디코더에서 Cross-Attention weight는 쿼리를 content part(모델 앞부분에서 인코딩된 visual feature)와 position part(positional embeding)으로 구성된 키 집합과 비교해서 계산됩니다. 이 과정에서 디코더가 쿼리와 특징 간 유사도 기반으로 feature map에서 feature를 풀링하게 됩니다. 하지만 저자들은 최근 제안되고 있는 DETR 기반 방법론들에서 2가지 한계점을 지적합니다.
첫 번째 한계점은 쿼리 형성 과정에서 의미론적인 구체성이 부족하다는 것입니다. 컨텐츠 쿼리는 기본적으로 visual feature에서 무엇을 찾을지 인코딩하도록 설계되었는데, 기존 방법론들은 보통 이를 0으로 초기화하기에 object나 relation에 대한 의미론적 사전 정보를 제공하지 못하고, 학습 시간도 오래 걸렸습니다.
두 번째 한계점은 쿼리가 instance-agnostic하게 구성된다는 것입니다. 쿼리는 일반적으로 비디오 프레임의 특정한 시각적.의미론적 문맥을 고려하지 않고 형성되기에 frame-specific한 관계에 집중하는 데 한계가 있었습니다. 결국 첫번째, 두번째 한계는 쿼리의 초기화에서 비롯된 문제들입니다.
마지막 세번째 한계점은 모델들이 시각적 특징에만 의존하기에 시각적으로는 유사해 보이지만 기능적 의미는 다른, (예를 들면 문을 여는 사람과 문을 닫는 사람은 시각적으로는 유사해 보이지만 그 의미가 다르죠)의미론적으로 풍부한 관계들을 명확히 구분하는 데 어려움을 겪는다는 것입니다.
이를 해결하기 위해 저자들은 VLM을 활용한 VOST-SGG(VLM-aided One-stage ST-SGG) 프레임워크를 제안합니다. 개선점은 크게 2가지입니다.
(1) Dual-source query initialization
DETR의 쿼리는 보통 content query와 position query로 나눠집니다. content query는 모델이 무엇에 집중할지(semantic intent)를 담당하고, position query는 어디에 집중할지(spatial guidance)를 담당합니다.
위의 첫번째, 두번째 한계를 완화하기 위해서, VLM에서 얻은 인스턴스에 대한 common sense knowledge를 content query에 주입하여 디코더가 아래 Fkgure 1(b)처럼 영벡터 대신 유의미한 물체와 관계를 찾을 수 있도록 하였습니다. 또한 position query는 MS-COCO에서 사전학습된 instance-agnostic spatial anchors를 사용해 초기화하여 다양한 장면에 걸쳐 잘 동작할 수 있도록 하였습니다.
(2) Multi-modal feature bank for predicate decoding
세 번째 한계를 완화하기 위해서는 시각, 텍스트, 공간적 feature를 사용하는 multi-modal feature bank를 도입하였습니다. 이 feature들은 VLM이 생성한 subject, object, relation에 대한 textual cue와 이들의 region-level visual embedding 및 공간 정보를 사용해 생성합니다. 이를 통해 learnable query들은 디코딩 과정에서 visual feature에만 의존하지 않고 multi-modal feature space에서 CA를 수행해서 문맥을 더 잘 반영한 relation 예측이 가능하다고 합니다.
저자들이 주장하는 contribution을 요약하면 다음과 같습니다.
- DETR 기반 ST-SGG 방법론들의 learnable query의 형성에 집중해서, 주목할 대상(content query 활용)과 위치(position query 활용)를 분리해 디코더에서 ‘무엇을, 어디에’ 집중할지 가이드해줄 수 있도록 하는 ‘dual-source query initialization’ 전략을 제안하였다.
- VLM의 지식에서 추출한 시각, 텍스트, 공간적 단서를 융합해 multi-modal feature bank를 도입하여, 기존보다 풍부한 문맥 정보를 바탕으로 relation classification 능력을 개선하였다.
- Action Genome 데이터셋에서의 실험에서 SOTA를 달성해 제안 방법론이 효과적임을 확인하였다.
Methodology
제안하는 VOST-SGG의 핵심은 1. 쿼리의 재설계와(그림 3), 2. relation 분류를 위한 multi-modal feature bank의 도입(그림 4)에 있습니다. 전반적인 파이프라인 개요는 아래 Figure 2.에 나와 있습니다. 기본적으로 CVPR 2024에서 제안된 OED 모델을 기반으로 합니다.
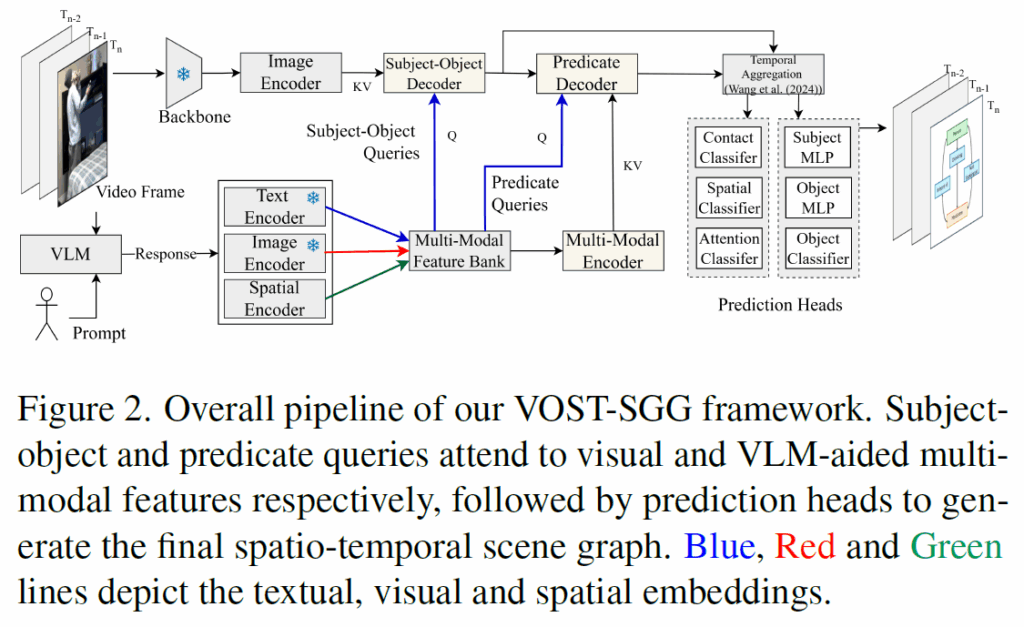
일단 비디오 프레임이 주어지면, 먼저 이미지 백본으로 visual feature 추출하고 인코더를 통과시킵니다. 이와 동시에 VLM에 프롬프트를 입력해 해당 프레임에 대해 적절한 subject, object, relation 후보를 생성하고 전용 멀티모달 인코더를 통해 정제합니다. 이렇게 임베딩 된 feature들은 multi-modal feature bank를 구축합니다. 이후 <subject-object> 쿼리는 subject-object decoder 내에서 visual feature와 cross-attention을 통해 주어와 목적어에 대한 특징을 포착합니다. 이후 predicate query는 predicate decoder 내에서 멀티모달 feature와 cross-attention을 수행해 관계에 대한 특징을 뽑아냅니다. 이렇게 만들어진 subject-object 쿼리 및 relation 쿼리는 이후 temporal aggregation 단계에서 reference frame들의 쿼리들과 Cross-Attention을 통해 시간적 정보를 추가적으로 주입받고, 각자의 prediction head를 거쳐 최종 예측을 수행합니다.
Re-visiting query design: A dual-source approach for “what-where” reasoning
앞에서 설명했듯, DETR기반 방법론들의 learnable query는 (1) 모델이 무엇에 주목해야 하는지 가이드하는 content query와 (2) 이미지의 어느 부분에 모델이 집중해야 하는지 가이드하는 position query로 구성됩니다. 하지만 기존에는 content query가 0으로 초기화돼서 별다른 의미론적 guide를 주지 못했습니다. (position query는 random init되거나 사전학습 가중치로 초기화됩니다). 이렇게 되면 (1)쿼리가 검색하려는 object나 predicate 특징에 대한 정보를 제공하지 못해 의미론적 구체성이 부족해지고, (2) 초기화 과정에서 개별 비디오 프레임의 instance별 정보가 무시되어 Figure 1(a)처럼 식별력이 약해지는 instance-agnostic 초기화 문제가 생기게 됩니다(여기서 instance는 단일 비디오 프레임을 의미합니다)
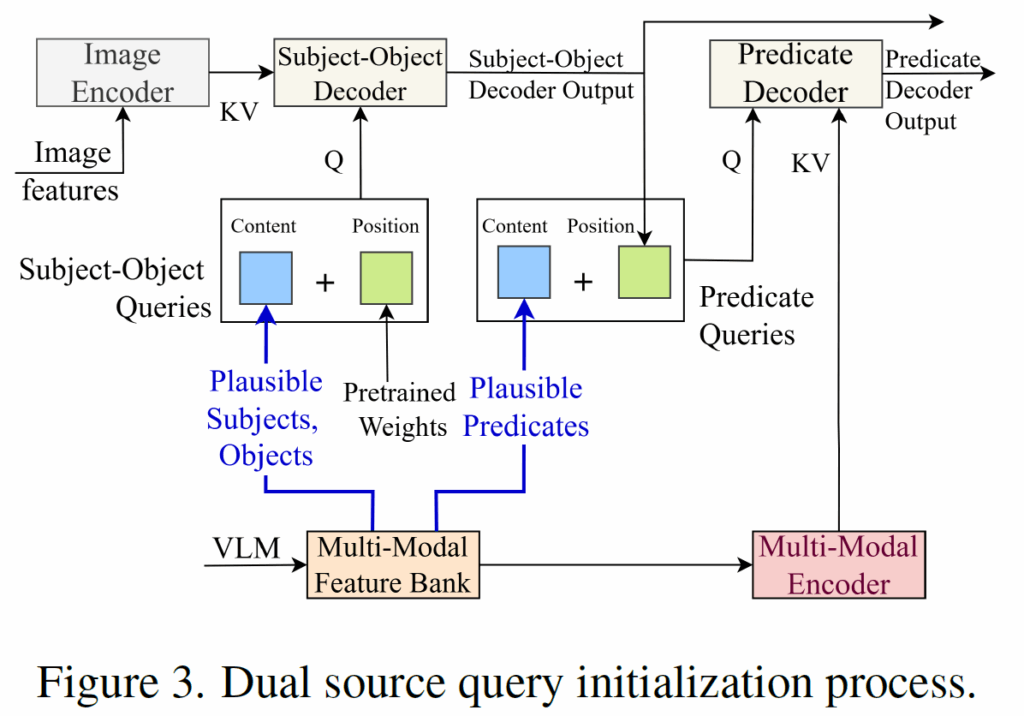
Shifting from ”where” to ”what-where” with dual source query initialization
저자들은 순수한 공간적 추론(‘어디’)을 ‘무엇’과 ‘어디’를 결합한 의미론적 근거를 제공하는 공간 추론으로 발전시키기 위해 dual source query initialization을 사용해 위의 두 문제를 완화합니다(추가적인 inductive bias를 제공하는 것이죠). position query가 계속 어디를 볼지 가이드하는 동안, VLM에서 추출한 상식 정보로 개연성 있는 object 및 predicate를 만들어 ‘무엇을’ 찾을지 정의하는 semantic cue로 사용하여 content query에 보다 풍부한 정보를 제공합니다. 이런 고수준 개념어(person, hold, cup 등)은 각 쿼리에 검색할 relational triplet 유형에 대해 명확한 시작점을 제공해서 검색 공간을 효율적으로 좁히고, 추가적인 정보 정제의 품질을 높이는 사전 정보 역할을 하게 됩니다.
position query는 딱히 복잡한 초기화 과정은 없고 MS-COCO에서 사전학습된 가중치를 사용해 이후 AG dataset에서 파인튜닝을 진행합니다.
subject-object detection에서, 아래 식(6)처럼 Q에 있는 N개의 content query 중 x개에 {sub}_{t}와 {obj}_{t} 임베딩을 concat하여 할당합니다. x는 주어진 프레임을 VLM에 프롬프트 넣은 개연성 있는(plausible) <subject-object> 쌍의 개수입니다.
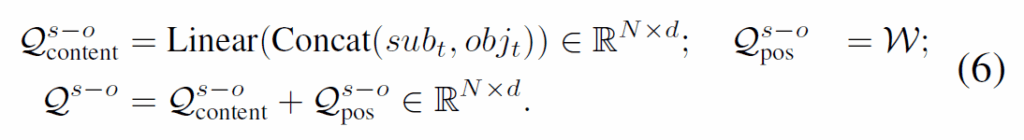
predicate decoder에서, 관련 predicate embedding {pred}_{t} 을 content query에 할당하고, 학습된 <subject-object> 쿼리 출력 {Q}^{s-o'} 가 position query 역할을 하도록 하여 수식 (7)과 같이 predicate query {Q}^{p}를 생성합니다.
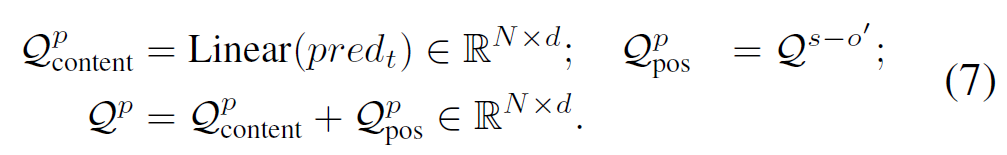
Multi-modal feature bank
기존 Spatio-Temporal SGG 방법론들은 비디오 프레임만을 사용해 예측을 수행하는데, 본 논문의 저자들은 이렇게 단일 이미지 모달리티만 사용하면 복잡한 상호작용을 추론해야 하는 상황에서 예측력이 저하될 수 있다고 주장합니다. (예를 들어 ‘사람이 문을 여는 것’과 ‘사람이 문을 닫는 것’ 처럼 외형적으로는 유사해 보이지만 기능적 맥락이 다른 상황 등) 이를 위해 추가적인 문맥적 지식을 활용하고자 하였고, 아래 그림 4와 같이 Multi-modal feature bank를 도입하였습니다.
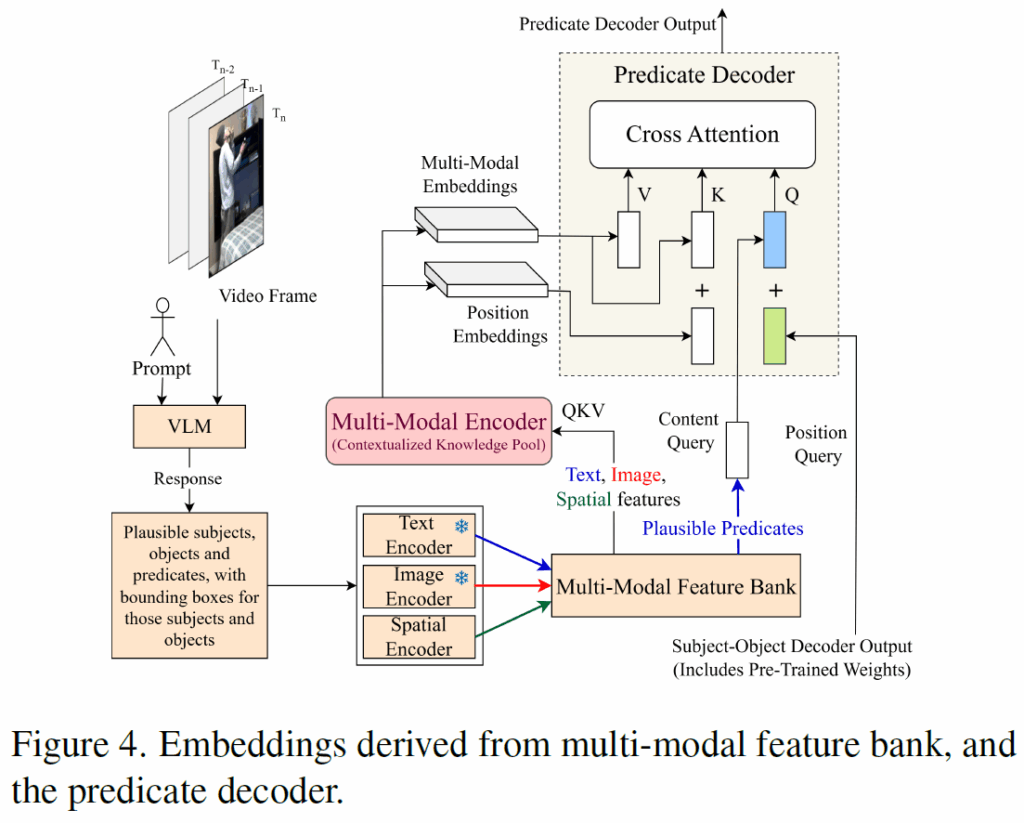
프레임에서 개연성 있는 <subject-object> pair 및 이들 간 관예뿐만 아니라, 프롬프트로 VLM에 subject와 object의 bounding box를 요청합니다. 응답 받은 bbox를 기반으로 visual encoder를 사용해 subject, object, relation에 대한 visual embedding {sub}_{v}, {obj}_{v}, {pred}_{v}을 각각 추출합니다. 그리고 VLM이 예측한 bbox를 single spatial feature로 변환하고 visual, textual feature와 동일한 공간으로 투영시켜 다음 수식(8)과 같이 관계 영역 i에 대한 통합 공간 임베딩을 만듭니다.
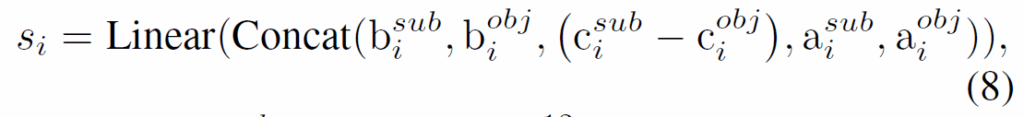
위 수식에서 b,c,a는 각각 bounding box 좌표, 센터 좌표, subject 및 object bounding box의 면적을 나타냅니다.
그리고 아래 식(9)와 같이 시각, 텍스트, 공간적 특징을 사용하여 multimodal feature bank {F}^{MMBank}를 형성하고, 이후 멀티모달 인코더에서 MHSA을 거쳐 멀티모달 임베딩을 형성합니다.
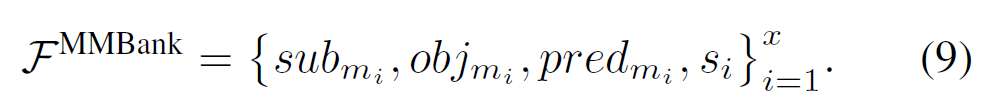
여기서 {m}_{i} ∈ { {v}_{i}, {t}_{i}}는 i 번째 region에 대한 시각/텍스트 모달리티입니다.
제안된 멀티모달 인코더는 텍스트, 시각, 공간적 상식 근거에 기반한 frame-specific한 문맥 표현을 생성하여 강력한 predicate 분류를 가능하게 합니다. content 쿼리에 VLM에서 뽑은 물체에 대한 의미를 전달하여 각 쿼리에 의미론적으로 ‘사람 앞의 소파’와 같은 시작점을 제공해 예측을 돕는 것이죠. (VLM 출력은 초기화 역할만 하게 됩니다)
학습시에는 DETR과 동일하게 헝가리안 알고리즘을 사용합니다. 해당 매칭 수식은 모두 잘 아실테니 자세한 설명은 생략하겠습니다.
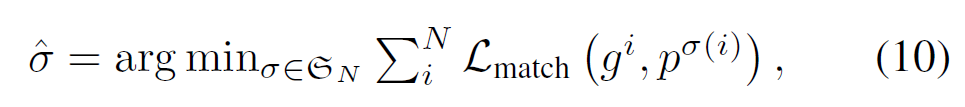
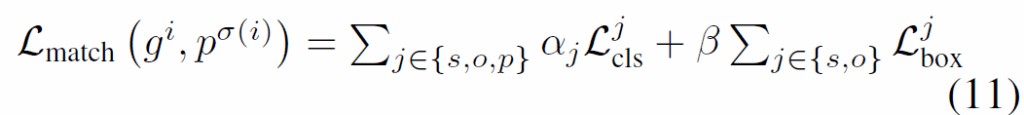
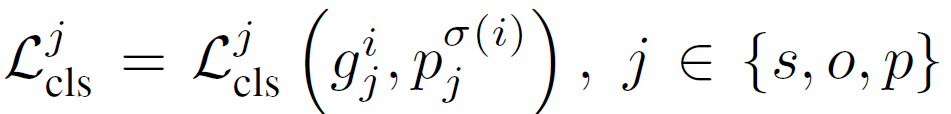
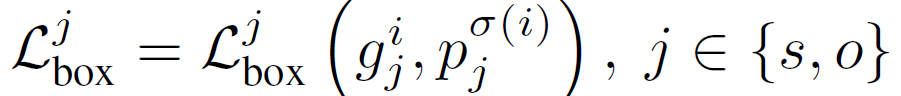
Experiment
기존 논문들과 동일하게 AG 데이터셋에서 Recall@K 및 mean Recall@K로 성능을 리포팅합니다. 구현 디테일을 좀 보자면, VLM으로는 Qwen2.5-VL-7BInstruct을 사용했고, 이미지 백본은 ResNet50을 사용하였고 textual/visual embedding을 추출할 때 CLIP ViT-B32를 사용했다고 합니다.
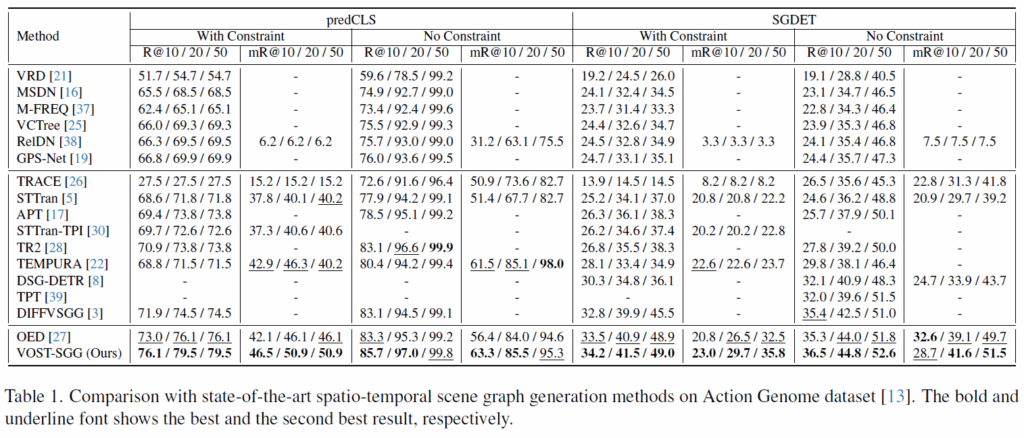
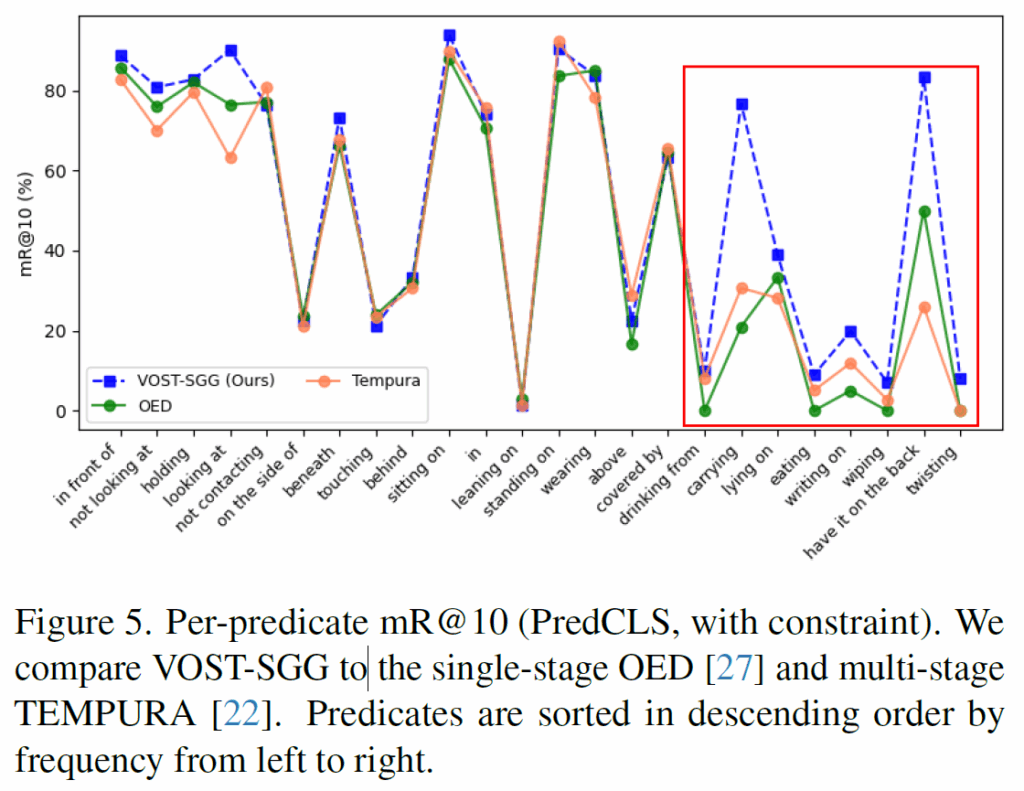
방법론이 3가지로 섹터로 나뉘어져 있는데, 맨 윗칸 방법론들은 이미지 기반 SGG 방법론들을, 가운데 칸 방법론들은 2-stage Spatio-Temporal SGG 방법론들을, 맨 아래 OED, VOST-SGG는 1-stage 방법론들입니다. 기본적으로 1-stage 방법론들이 성능이 좋고, 제안하는 VOST-SGG가 Recall 및 Mean Recall에서 모두 가장 좋은 성능을 달성하였습니다. 특히 그림 5에 나타난 것처럼, head class의 성능을 희생시키지 않고 ‘닦기(wiping)’, ‘위에 쓰기(writing on)’, ‘등에 지기(have it on the back)’, ‘비틀기(twisting)’같은 tail쪽에 분포된 predicate의 성능이 개선됨을 확인했습니다(가장 오른쪽에 있는 8개의 predicate는 데이터셋에서 희소한 클래스들입니다). 제안 방법론이 롱테일 분포의 한계를 기존 방법론들보다 강건하게 대응할 수 있음을 보여준다고 합니다.
마지막으로 Ablation 보고 마무리하겠습니다.

IAQI는 기존의 쿼리 초기화 방식, DSQI는 제안하는 쿼리 초기화 방식, MMFB는 Multi-Modal Feature bank를 의미합니다. 제안하는 DSQI 및 MMFB를 조합했을 때 가장 좋은 결과를 보여줍니다.
쿼리 초기화를 개선하고 문맥 정보를 추가하기 위해 VLM을 도입한 방법론이었습니다. 지금 실험에서도 text 정보를 활용할 수 없을까 고민중에 있고, 이전에는 쿼리 초기화를 잘 해볼 수 없을까 실험을 이리저리 해봤었는데 이렇게 둘을 결합한 방법을 사용해서 신기하네요.. 좋은 인사이트를 얻었습니다.
이만 리뷰 마무리하도록 하겠습니다. 감사합니다.