안녕하세요! 어쩌다 보니 첫 x-review를 쓰게 된 이재윤입니다. 제 첫 x-review는 ResNet이나 Transformer가 될 줄 알았는데, 이번에 근택님 논문 작업에 참여하게 되어 Long video understanding task에 팔로우업 할 겸, 제 역할에 대해 더 깊이 이해할 겸 이번 논문을 읽고 리뷰를 작성하게 되었습니다. 이 논문은 다른 일반적인 논문들과 달리, Toward Spatial Supersensing in Video 논문에 대한 반박 논문입니다. 그래서 반박의 대상이 되는 위 논문은 어떤 내용인지 최대한 간단하게 다루고, 본 내용으로 넘어가겠습니다.
Cambrian-S : Towards Spatial Supersensing in Video
멀티모달 LLM(Multimodal LLM)이 강력한 visual encoder와 언어 모델을 결합하며 빠르게 발전해 왔지만 대부분의 비디오 확장 모델들은 여전히 video stream에서 프레임을 sparse하게 샘플링하여 처리하고 그 안의 spatial 공간 정보를 제대로 표현하지 못하며 지식 회상recall에 의존합니다. 단순히 비디오 한 장면을 기억해서 이건 어떤 영상이네~ 하는 정도에 머물고 있다는 것이죠. 추가로 기존에는 수많은 맥락 토큰을 모델에 그대로 때려넣는 long-context brute force 방식을 사용했으나 비디오 길이duration가 길어질수록 recall 성능이 하락하고 메모리 문제도 생긴다는 이슈가 있습니다. 따라서 저자들은 multimodal intelligence가 지향해야 하는 바를 spatial supersensing이라고 제안합니다.
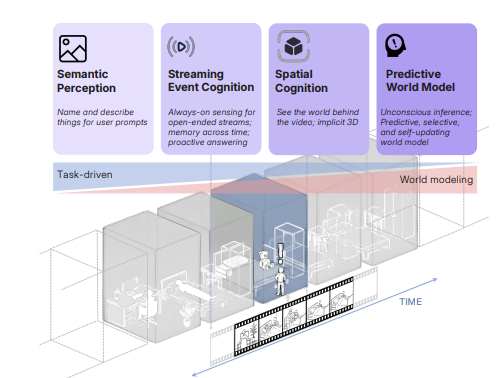
video understanding model이 어떤 과정을 거쳐 발전해야 하는 지를 설명하는 그림입니다. 하나씩 보겠습니다.
- Sematic Perception : 픽셀을 객체, 속성, 관계로 파싱 -> 현재 MLLM들의 강력한 멀티모달 이해 능력
- Streaming Event Cognition : 길이 제한 없는 비디오를 보며 사건을 파악하고 실시간으로 능동적인 지원을 해주는 “같이 보기” 비서 역할을 수행하는 단계
- Implicit 3D spatial cognition : 프레임을 3차원 세계의 2차원 투영으로 취급하고 사물이 어디에 있고 서로 어떻게 연관되며 시간에 따라 구성이 어떻게 변하는지 파악하는 단계 – 여기부터 현재 모델들이 약함
- Predictive World Modeling : 내부 모델이 비디오의 미래 상태(프레임)을 예측하다가, “예상 밖의 일(Surprise)”을 메모리와 의사 결정을 위한 지각 조직화의 기준으로 활용
논문의 제목으로도 등장하고, 앞으로도 자주 등장할 단어인 spatial supersensing은 공간 인지 능력을 바탕으로 predictive world modeling까지 가겠다는 의미로 받아들이시면 되겠습니다. 각설하고, 논문에서는 크게 세 가지 주제를 잡았는데,
- Supersensing 계층 구조의 관점에서 현존 벤치마크들을 비판적으로 조사
- spatial supersensing이 단순히 데이터의 양만 늘린다고 해결되나?
- 새 학습 목표 패러다임인 Predictive Sensing을 위한 맞춤형 추론 파이프라인 제안
이중 1번 주제를 좀 더 중요하게 다루고 나머지 2,3번은 간략하게 짚고만 넘어가겠습니다.
Benchmarking spatial supersensing
저자들은 자신들이 추구하는 spatial supersensing 능력을 평가하기 위해서 현존 Video MLLLM 벤치마크들을 분석하고 시간, 공간 정보에 대한 reasoning 평가를 위해 VSI-SUPER라는 벤치마크를 소개합니다.
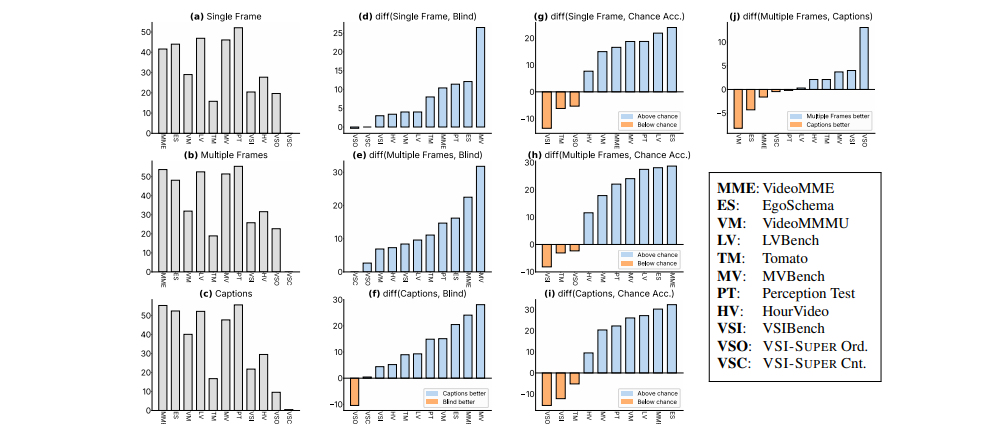
현존 벤치마크들이 정말로 visual sensing을 평가하는 지 아니면 다른 사전 지식에 의존하는 지 평가하기 위해 진단 테스트를 구성했고, 위 figure는 테스트 결과로 보시면 되겠습니다. 베이스 MLLM 모델인 Cambrian-1을 사용해서 다양한 입력 조건 아래 대표적인 비디오 벤치마크를 조사하였습니다. 입력 조건은 Single frame(사진 한 장만 봐도 풀 수 있는 문제인가), Multiple frames(여러 장 보고 temporal 정보 고려하는가), frame captions(텍스트만 봐도 풀 수 있는가), blind test(비디오 없이 쿼리만 보고 맞출 수 있는가), chance acc(무작위 추측) 입니다. 결과만 말씀드리면 많은 벤치마크가 visual input을 거의 사용하지 않아도 문제를 해결할 수 있었고, 일부 vision sensing에 더 의존했고 벤치마크도 있었습니다(VSI-Bench, Tomato). 결론적으로 기존 벤치마크들은 공통적으로 텍스트 또는 프레임 한 장만 보고도 문제를 해결했다는 점에서 perception에 너무 치중되었다는 것인데, 예를 들어 영화를 보고 특정 프레임에 등장한 사람이 몇 명이냐는 질문을 맞추는 것이 과연 모델이 비디오의 맥락을 잘 파악했는지는 미지수이기 때문입니다. 그래서 저자들은 supersensing을 평가할 수 있는 벤치마크인 VSI-SUPER를 제안합니다.
VSI-SUPER
VSI-SUPER는 두 가지 파트로 분리되는 데, VSO(추후 VSR로 불림)와 VSC로 나뉩니다. VSO는 “Long horizion spatial observation and recall” task로 MLLM이 긴 영상을 관찰하고, 관심 물체가 나타난 순서에 맞춰 그 물체가 있었던 구체적 위치나 함께 있던 물건을 회상할 것을 요구합니다. 비디오 데이터는 이미지 편집 모델을 사용해서, 긴 비디오의 서로 다른 4개의 프레임에 테디베어 같이 “관심 객체”를 삽입하고, 이후 곰돌이가 나타난 프레임과 어느 공간에서 나타났는지도 기억해야 합니다. 아래 예시처럼, 객관식 Question과 등장 순서를 의미하는 보기들로 이루어져 있습니다.
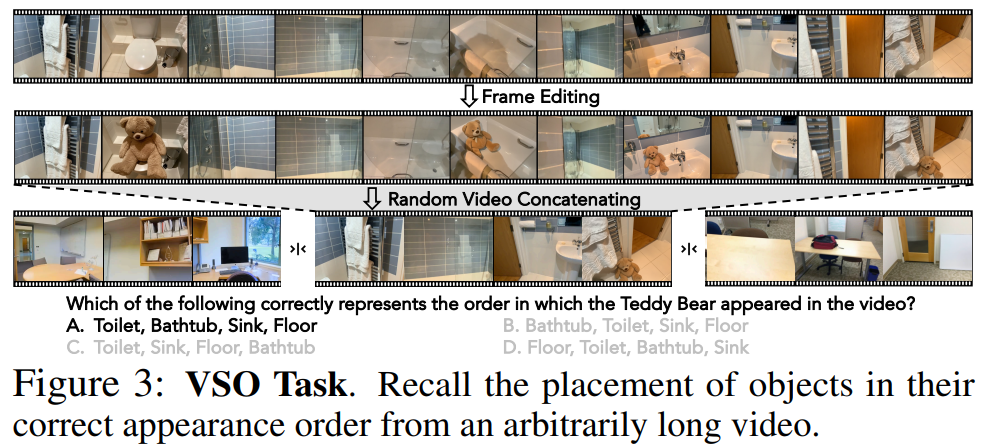
VSC는 긴 비디오에서 지속적으로 특정 물체의 등장 횟수를 카운팅하는 테스크입니다. VSI-Bench에서 여러 개의 공간 스캔 클립을 이어붙여 만들었고, ‘개수’라는 숫자형 QA format이라 MRA(Mean Relative Accuracy)를 평가 메트릭으로 사용합니다.
우선적으로 VSI-SUPER가 최신 MLLM으로 잘 해결되는지 확인하기 위해 Gemini 2.5 Flash을 사용해서 실험을 했는데, 백만 개의 token context length를 가졌음에도 2시간 짜리 비디오를 다루지 못하는 모습을 보여 입력할 context length를 조절하는 것만으로는 VSI-SUPER를 해결할 수 없음을 강조했습니다.
Is supersensing a data problem?
2번째 주제는 spatial supersensing이 단순히 데이터의 양만 늘린다고 해결되나? 라는 내용인데, 최대한 간단하게 설명해보겠습니다.
먼저 spatial 정보를 학습하는 것을 목표하는 데이터셋 VSI-590K를 구성하고, Cambrian-S라는 모델에 비디오 내 공간 정보를 학습시켰습니다. 이 모델은 현존 spatial task(VSI-Bench)에서는 SOTA를 달성했지만, VSI-SUPER가 요구하는 continual sensing에는 실패했습니다. 이를 통해 온전히 data만 건드리는 접근은 한계가 있다는 것을 증명했습니다. 아래 Table2를 보시면, CambrianS 모델이 VSO에서는 비디오 길이가 길어질수록 메모리 부족으로 망가졌고, VSC는 제대로 된 예측조차 수행하지 못하는 모습을 보입니다.

Predictive Sensing for Unbounded Streams
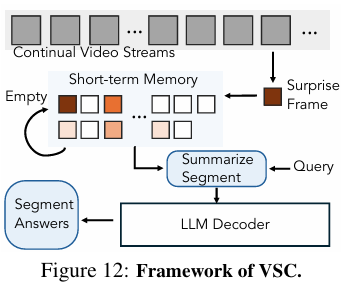
그래서 어떻게 하면 spatial supersensing을 학습해서 저자들이 제안한 VSI-SUPER 벤치마크를 해결할 수 있을까?에 대해 직접 벤치마크 맞춤형 추론 방법론을 설명하는 파트입니다. 여기도 간단하게만 짚고 넘어가겠습니다. 추론 파이프라인의 경우, surprise-based event segmentation 접근을 사용합니다. 여기서 말하는 “surprise”는, 제가 이해하기론 ‘event가 바뀌는 순간’입니다. 예를 들면, ‘진격의 거인’에서 조사병단이 거인이랑 싸우는 장면을 보여주다가, 주인공의 기억 회상으로 넘어가는 그런 “전환”의 순간을 surprise로 이해했습니다. 이 “surprise” 신호를 계산하기 위해 다음 프레임을 예측하는 모델을 사용합니다. 비디오가 재생되며 모델은 frame feature를 buffer에 임시로 저장하며 축적하다가, 예측했던 프레임과 실제 프레임 간 오차(prediction error)가 클 때를 surprise로 판단 후, 한 이벤트 segment 단위의 count 추정치를 만들기 위해 버퍼에 모아두었던 피처들을 요약합니다. 이후 buffer는 초기화시키고, 다음 장면들을 받게 됩니다. 비디오가 끝날 때까지 이런 작업이 반복되고, 이 segment level count estimates를 종합해서 최종 count prediction을 생성합니다. 이것으로 서론을 끝내겠습니다^^,,
Solving Spatial Supersensing Without Spatial Supersensing
Introduction
Video Understanding의 벤치마크는 모델이 긴 비디오 스트림에서 모델이 일관성있고 predictive한 world model을 구축할 수 있는 지 테스트할 수 있어야 합니다. 따라서 시각적 증거, 상태 저장 및 기억, 원하는 객체 또는 사건이 있는 클립/프레임을 쫓아가는 능력 등이 필요하나, 현재 모델들은 이런 능력이 부족하다고 합니다. 많은 벤치마크들 역시 이런 능력을 평가하지 못하는데, 앞선 논문에서 설명했듯이 모델이 시간적 구조temporal structure를 대부분 무시하고 하나의 frame이나 text 입력에만 의존했음에도 SOTA에 버금가거나 능가하는 경향을 보였기 때문입니다.
이렇게 의도된 능력이 아니라 편법을 써서 목표를 달성한 현상을 shortcut learning이라 합니다. 벤치마크가 shortcut으로 풀릴 수 있게 설계되면, 연구자들은 진정한 능력을 개발하기보다 모델에 그런 shortcut을 심는 방향으로 유도되기 때문에 Cambrian-S 논문은 바로 이런 문제를 다루었습니다.
Cambrian-S는 token context의 개수를 조절해서 입력으로 넣는 brute-force 방식이 아니라, 진정한 spatial reasoning 평가를 위해 VSI-SUPER 벤치마크를 도입했습니다. 따라서 진정한 공간 인지 능력과 기억력을 가진 모델은 위 벤치마크에서 강력한 성능을 낼 것이라는 전망이 있지만, 여기서 반박 논문의 저자들은 두 가지 문제를 제기합니다.
- VSI-SUPER 중 VSR(=VSO)이 과연 CLIP,SigLIP 같은 시간적 구조를 무시한 단순 VLM모델로도 해결할 수 있을까? supersensing이나 공간 인지 능력 없이?
- Cambrian-S의 추론 방법이 과연 의도된 이벤트 단위 reasoning과 spatial supersensing을 수행하는가? VSC 벤치마크의 shortcut에 의존하지는 않는가?
Spatial Supersensing Benchmarks Don’t need Spatial Supersensing
제목처럼 “과연 벤치마크(VSI-SUPER)가 실제로 모델의 spatial supersensing 능력을 요구하는 지” 확인하는 파트입니다. 이를 위해 저자들은 VSR 벤치마크 해결을 위해 Nosense라는 단순한 baseline을 설계했고, Gemini, Cambrian-S 등의 다른 MLLM 모델과 성능을 비교했습니다.
VSR task?
VSR(반박 대상 논문은 VSO로 표현)은 모델이 관심 객체의 등장 순서를 떠올려 맞추는 테스트입니다. 데이터셋의 경우, 각 비디오의 4개의 프레임에 관심 객체(ex. teddy bear)를 삽입하고 관심 객체가 있는 환경과 관련된 4개의 auxiliary objects(ex. bed, bathtub, sink, floor)와 함께 위치시킵니다.
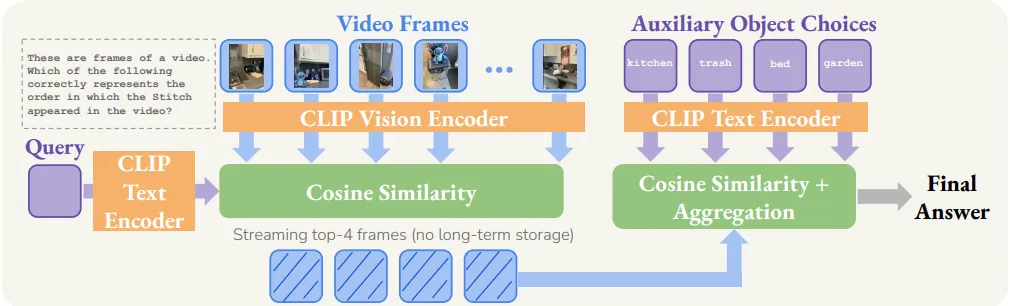

설계는 굉장히 간단한 편입니다. 먼저 비디오 입력의 경우, 비디오를 1초에 하나씩 뽑은 (1FPS로 샘플링) N개의 프레임들로 취급합니다. 각 프레임들을 vision encoder로 인코딩하고, 질문도 text encoder로 인코딩합니다. 이후 각 프레임 피처들과 텍스트 피처 간 코사인 유사도를 구해서 질문과 가장 관련 있는 프레임 4개를 선택합니다. (참고로 4개를 뽑는 이유는 VSR이 4가지 다른 환경에 관심 객체를 삽입하며 데이터셋을 구성했기 때문입니다. 서론의 VSO 예시 참조)그 다음 관심 객체와 각 auxiliary들을 함께 text encoding 해주고, 이전에 뽑앗던 4개의 프레임 피처와 유사도 행렬을 만들어줍니다. 마지막으로 객관식 문항은 auxiliary들의 permutation(1. kitchen→trash→bed→garden, 2. trash→garden→bed→kitchen, …)으로 4개의 보기가 있는데, 각 케이스에 따른 유사도 점수를 종합해서 가장 높은 점수가 나온 문항을 정답으로 선정합니다. 이 Nonsense의 특징은 프레임들을 독립적으로 다뤘기 때문에 비디오의 시간 정보를 무시했고, 네 개의 관련 높은 프레임만 추출하여 장기 기억 능력도 없으며, 코사인 유사도 기반 점수를 사용해서 LLM도 사용하지 않았다는 것입니다. 결국 Cambrian-S 논문에서 지향했던 spatial supersensing이나 공간 인지, world modeling 능력이 Nonsense는 전혀 없음에도 불구하고, 이 Nonsense가 VSR 벤치마크에서 gemini, Cambrian-S 같은 MLLM들을 압도하며 거의 완벽하게 문제를 해결했습니다.
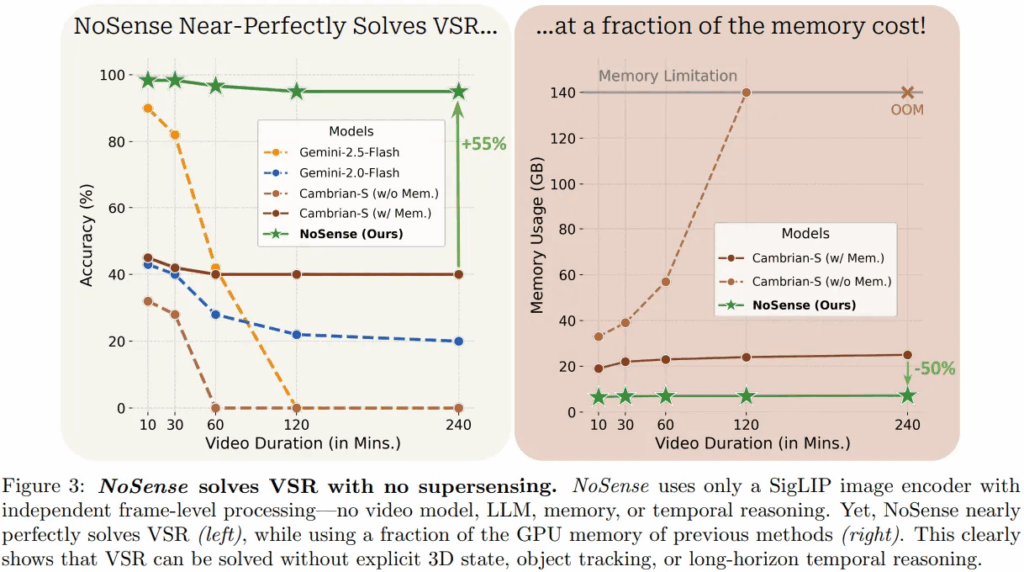
10분 길이의 비디오부터 4시간 길이까지, Nosense 모델이 거의 100%에 달하는 성능을 보여주었고, Cambrian-S와 비교했을 때는 무려 55% 차이가 났다고 합니다. 시간 정보나 공간 정보를 배제하고 관련 높은 프레임만 가지고 answering에 사용했던 Nosense가 완벽에 근접한 성능을 보였다는 것은, VSR이 몇 가지 프레임만 보고도 정답을 맞출 수 있는 semantic perception에 집중하고, 정작 목표였던 world modeling이나 long horizion reasoning을 평가하지 못한다는 것입니다. VSR이 추가적인 inductive bias(여기서는 장기 기억을 통한 spatial supersensing) 없이도 문제 해결이 가능함을 밝혔기 때문에, 저자들은 비전 인코더를 가지고 있고, 통합적인 메모리를 가지며, 쿼리 기반 검색 메커니즘이라는 비슷한 구조를 가진 Cambrian-S 역시 이러한 retrieval style shortcut에 의존할 가능성이 높다고 주장합니다. Spatial supersensing으로 문제를 풀었다고 생각했겠지만, 사실 nosense처럼 일부 프레임 정보만 가지고 관심 객체를 식별했을 거라는 것이죠.
Spatial Supersensing Methods Don’t do Spatial Supersensing
지금까지 VSI-SUPER 중 VSR이 (CLIP같은) 프레임 레벨의 baseline으로 거의 완벽히 풀렸기 때문에, 벤치마크에 맞춘 Cambrian-S의 추론 방법론 역시 벤치마크의 shortcut을 추출해서 성능을 높였을 가능성이 높음을 보였습니다. 이번 파트는 VSC 벤치마크 역시 spatial supersensing을 평가하지 않았음을 분석합니다.
VSC Task?
VSC는 한 비디오의 전체 stream에서 찾고자 하는 unique한 객체의 개수를 세는 task입니다. 예를 들면, 해당 비디오에서 등장한 (unique한) 의자의 개수를 총 몇 개인가? 를 해결하는 task라 보시면 되겠습니다. 문제를 풀기 위해서는 프레임 별로 object를 감지하고, 시간을 가로질러 추론함으로써 중복된 객체를 확인해야 하며, 동일한 객체를 여러 번 세는 것을 피해야 합니다. GT 라벨은 한 unique object의 카운트 개수이며 성능은 MRA(Mean Relative Accuracy)로 측정했습니다.
Sanity Check
VSC에 맞춘 Cambrian-S의 추론 메커니즘은 위에서 설명했기에 생략하겠습니다. 이러한 추론 방법론 설계는 내재적으로 각 segment(event)가 단 한 번만 방문되는 서로 다른 환경이라고 가정하고 있습니다. 집을 돌아다니는 영상이 있다면, 갔던 방은 절대 되돌아가지 않는다는 암묵적인 규칙을 정했다는 것이죠 (하나의 event가 끝나면 buffer를 아예 초기화시키며 이전 프레임 피처 정보를 없애기 때문). 저자들은 이 점을 매커니즘의 허점으로 생각하고 분석 실험을 진행했습니다. Sanity check는 이번에 처음 본 단어인데, “논리적으로 타당한지 확인하는” 일종의 검증 과정으로 보시면 되겠습니다. 위에서 “재방문은 배제한다”라는 식의 가정이 있었기 때문에, sanity check를 위해 저자들은 VSC 내 같은 비디오를 1~5번 이어붙여서 VSC-Repeat이라는 데이터셋으로 검증을 실시합니다. 만약 모델이 spatial supersensing 능력을 가지고 있다면, 반복되는 장면을 인지하고 자신이 셌던 물체의 개수에 변화를 주지 않아야 합니다.

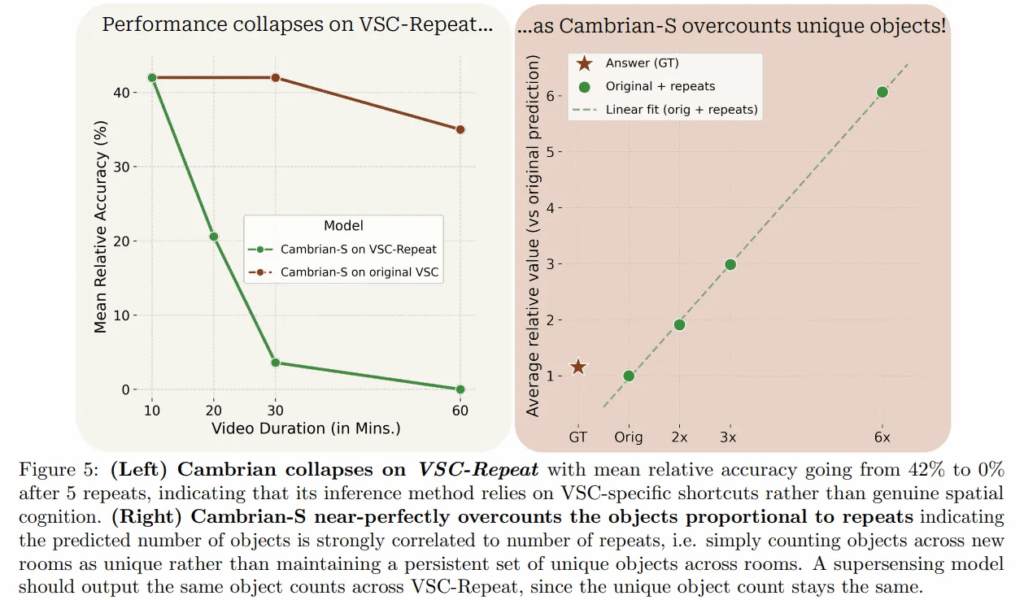
결과부터 말씀드리면, 같은 동영상이 반복되는 비디오를 넣었을 때, count의 GT가 바뀌지 않았음에도 모델은 객체 개수를 제대로 세지 못하고 반복 횟수에 따라 prediction count가 비례해서 증가하는 경향을 보여주었습니다.
왼쪽 그림은 비디오 길이에 따른 MRA의 변화 추이를 보여주는데, 10분 짜리 영상은 2번 더 이어붙여 30분 길이의 비디오를 입력했더니, Cambrian-S의 inference pipeline의 MRA가 42%에서 3.6%로 하락했습니다. 5번 이어붙인 60분 길이의 비디오는 MRA가 0%에 가까운 모습도 볼 수 있죠. 결국 이런 성능 하락은 비디오의 길이를 늘렸기 때문이 아니라, 저자들이 “재방문” 개념을 넣었기 때문입니다. 오른쪽 그림처럼 재방문 횟수에 따라 모델의 예측값 count 횟수도 늘었음을 보았을 때, Cambrian-S에서 제시했던 추론 방법론은 spatial sensing 능력을 본 것이 아니라 데이터셋의 생성 방식에서 기인한 shortcut heuristic에 의존했음을 밝혀냈습니다. 결국 supersensing system을 구현하기 위해서는, 비디오가 진행됨에 따른 world map을 만들고 기억해서, 이렇게 방을 재방문하는 것처럼 반복되는 경험을 감지하고, 같은 물체를 새로운 것이 아니라고 판단할 줄 알아야 합니다.
Discussions
지금까지의 저자들의 주장을 정리하면 다음과 같습니다.
- 현재의 spatial supersensing 벤치마크들은 spatial supersensing 능력을 제대로 평가하지 못한다.
- 현 방법론들은 벤치마크의 shortcut을 학습하게 설계되었다.
저자들은 이 문제를 부분적으로 고치고 진정한 spatial supersensing을 향한 진보를 위해 4가지 모델/벤치마크 설계 원칙을 제안합니다.
- Invariance Check 불변성 검증법이 만들어져야 한다.
- VSC 분석 실험에서 VSC-repeat이라는 같은 영상이 반복되는 비디오를 만든 것처럼, 벤치마크를 만들 때 이런 Invariance check를 함께 설계하고 변형된 조건에서의 성능도 함께 보고하게 만들어 모델이 벤치마크 특유의 특성에 의존하기 어렵게 만들어야 합니다. 변형의 예시로는 repeating scenes, inserting revisits after long delays, shuffling segments with the same layout, or changing playback speed 등등이 있습니다..
- 더 많은 natural한 long form video 사용
- VSC는 구조적으로 반복되지 않는 환경의 event들을 짜집기해서 만들어져 “surprise” 경계에 의존하게 됩니다. 이 방법은 결국 ‘이벤트 경계’를 ‘환경 변화’와 동일시하게 하는 shortcut을 조장하게 됩니다. 같은 방 안에서만 진행되는 비디오가 있을 때, 비디오 중간에 ‘접시가 깨짐’이라는 사건이 발생하는 경우 위의 shortcut으로는 해결되지 않겠죠? 그래서 surprise의 등장이 환경의 변화임을 의미하지 않는 길고 연속적인 비디오를 사용해야 하고 그 예로는 1인칭 시점 이동 영상(egocentric traversals), 재방문 케이스 (revisits and loops) 가 있습니다.
- 개방성 Open-Endedness 강조 및 모달리티 간 독립성 확보
- 벤치마크는 현실의 사용 사례와 일치하는 방향을 유지해야 하는데, 풍부하고 개방적인 task를 좁은 범위의 객관식 문제로 축소하는 벤치마크들은 모델의 실제 역량을 과대평가하고 한계를 가려버릴 위험이 있습니다. 또한 멀티모달 이해 연구에서는 각 모달리티를 어떻게 공동으로 연관시킬 수 있을 지에만 집중했는데, 단일 모달리티에서만 얻을 수 있는 정보가 결정적일 때도 있다고 주장합니다. 예를 들어, 자율주행 자동차가 보행자를 감지할 때 비디오와 오디오 데이터 중 비디오만 보행자를 감지했다고 차를 멈추는 상황은 원하는 상황이 아니기 때문입니다.
- Meta-evaluation의 루틴화
- VSR을 Nosense로, VSC를 VSC-Repeat으로 stress test 한 것처럼 문제를 해결하기 위해 벤치마크나 모델이 실제로 요구하는 것이 무엇인지 확인해야 합니다. 이러한 메타 평가를 Ablation studies와 비슷한 것으로 간주하고 벤치마크 평가의 표준이 되어야 한다고 주장합니다. spatial supersensing task에 대해서는 “명백한 일반성을 가지는 가장 심플한 baseline은 무엇인가?”,”어떤 불변성이 가져야 하는가”,”구조적인 가정을 break했을 때 어떻게 성능 차이가 발생하는가?” 등이 있겠고, 저자들은 이러한 물음에 답하는 것이 진정한 world modeling으로의 발전에 도움이 될 것이라고 합니다.
Conclusion
저자들은 현재의 spatial supersensing 벤치마크와 방법론이 과연 실제로 spatial supersensing을 요구하는 지 분석했고, 벤치마크와 모델이 서로에게 맞춰졌음을 확인했습니다. VSR은 Nosense, VSC는 VSC-Repeat 데이터를 통해 모델은 “object를 삽입한 부분이 네 곳 있다”, “방은 재방문하지 않는다” 와 같은 구조적인 규칙을 학습했을 때 성능이 가장 좋았기 때문에 데이터셋 구조가 가진 허점을 활용했음을 밝혀냈습니다. 또한 Nosense의 성공은 Contrastive VLM의 강력한 perception 능력을 보여주며 문제를 거의 완벽하게 해결했습니다. 결국 VSI-SUPER는 모델의 spatial supersensing 능력을 제대로 평가할 수 없다는 것이 결론이며, 단순한 검색 기반 알고리즘으로는 절대 풀 수 없는 과제를 제시하고 이를 해결해낼 때, 진정한 spatial supersensing으로의 첫걸음을 뗐다고 할 수 있을 것입니다. 또한 저자들은 world modeling 자체와, 이 world modeling을 평가하는 것이 중요하다고 언급하며, 이를 위해서는 단순 비디오 변형에 강건한 벤치마크와 루틴화된 stress test가 필요하다고 주장했습니다.
이번에 LVU task에 새롭게 입문하게 되었는데, 문제점을 벤치마크와 모델 평가의 측면에서 접근했다는 점이 굉장히 인상적이었습니다. 그래서 나중의 연구 활동에서 무언가 문제점을 발견했을 때, 생각보다 더 다양한 접근을 필요로 할 수 있겠다는 생각이 들었습니다. (나쁘게 말하면 문제 발생 시 좀 많이 어지러워질 수 있겠다..?) 앞으로 진행할 논문 작업에서는, 본 논문의 Nosense가 perception 능력이 뛰어나다는 점을 가지고 벤치마크들의 Question들로부터 perception 관련 question들을 걸러내는 데 활용할 예정입니다. 첫 번째 x-review이고, 사실상 논문 2편 분량을 다루느라 정리하기 어려웠는데 잘 마무리한(?) 것 같습니다.. 긴 글 읽어주신 분들 너무 감사드리고 글 구조적인 피드백 주신다면 적극적으로 반영하겠습니다