오늘은 DeepSeek AI 연구팀이 최근 공개한 LLM 논문을 리뷰해보겠습니다.
DeepSeek 팀은 작년 이맘때 MoE 기반 모델로 큰 주목을 받았던 만큼, 1/12에 공개한 이번 논문도 많은 주목을 받고 있었습니다. 완전 따끈따끈하죠? 해당 페이퍼를 한 단어로 요약하면, 다다익램이라고 하는데요, 왜 그런것인지 한 번 알아보겠습니다.

- Conference: Arxiv 2026
- Authors: Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Yu, Zhewen Hao, Yukun Li, Han Zhang, Huishuai Zhang, Dongyan Zhao, Wenfeng Liang
- Affiliation: Peking University (베이징 대학교), DeepSeek-AI (딥시크 AI)
- Title: Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Model
- Code: GitHub
1. Introduction
요즘 LLM은 대부분 MoE 구조를 사용합니다. 필요한 순간에 일부 파라미터만 활성화해서 계산량 대비 모델 용량을 키우는 방식이죠. 이 접근은 “복잡한 추론”에는 굉장히 잘 맞다고 할 수 있죠
그러나 언어의 상당 부분은 새롭게 추론할 필요가 없는 정보라고 합니다. 예를 들어, 사람 이름, 지명, 관용 표현, 자주 반복되는 문구처럼 그냥 알고 있으면 되는 것들이 굉장히 많습니다. 문제는 Transformer가 이런 정보를 검색(retrieval) 하는 기능을 직접 갖고 있지 않다는 점입니다. 그래서 모델은 이미 알고 있는 정보조차 매번 attention과 FFN을 여러 층 거치며 다시 계산해서 떠올리는 방식으로 처리합니다.
이게 무슨 뜻이냐? Alexander the Great 이라는 ‘알렉산드로스 대왕’ 이라는 하나의 단어로 기능하는 문구가 그 대표인데요. LLM은 저 단어를 한 번에 인식하기는 커녕, 각각의 토큰으로 아래와 같이 받아들입니다. 마치 아래와 같이요
– Alexander → 그냥 단어
– the → 관사
– Great → 형용사
즉, 이 셋이 합쳐진 ‘하나의 엔티티’라는 건 초반엔 모르고, 아래와 같은 여러 layer의 FFN과 attention을 조합한 이후에서야 이 내용을 조합해서 복원하죠
– layer 1–2: Alexander = 사람 이름일 수도?
– layer 3–4: the Great → 칭호?
– layer 5–6: Alexander the Great = 고유명사 하나구나
이런 과정에 대해 의문을 가지고 논문이 시작됩니다, 굳이 이걸 계산으로 해야 할까?
즉, 이런 하나의 엔티티들은 계산하지 않고, 추론이 필요한 부분은 MoE처럼 계산으로 처리하되, 이미 굳어진 언어 패턴은 메모리에서 바로 꺼내 쓰자는 겁니다. 이걸 저자들은 conditional memory라는 새로운 sparsity 축으로 정의하였습니다. 마치 룩업테이블처럼 굳어진 언어패턴의 집합을 Engram이라고 정의한 것이죠. 다시말해, MoE가 “어떤 계산을 할지”를 조건부로 고르는 구조라면, Engram은 “어떤 기억을 불러올지”를 조건부로 고르는 구조입니다.
Engram은 transformer가 등장하기 전, NLP 분야를 지배했던 N-gram에서 가져온 개념입니다. N-gram처럼 바로 앞의 토큰 조합을 키로 삼아, 거대한 임베딩 테이블에서 해당 표현을 즉시 조회하는 것이죠. 중요한 건 이 lookup이 거의 O(1)에 가깝다는 점입니다. 그리고 이 메모리는 그대로 쓰이지 않고, 현재 문맥과 맞는지 한 번 더 확인하는 gating을 거쳐 Transformer 내부에 섞입니다. 즉, “외워둔 정보지만 지금 상황에 맞을 때만 쓰겠다”는 구조입니다.
결과적으로 이런 메모리 구조만 추가했음에도, 추론, 수학, 코드 문제까지 성능이 같이 올라갔다고 합니다. 이정도면 해당 논문이 어떤 컨셉이고, 어떤 점을 문제삼았는지 이해하셨을 것 같습니다. 지금부터 본격적인 내용 설명해보겠습니다
2. Architecture
Engram의 구조는 생각보다 단순합니다. 저자들은 Transformer에 새로운 계산 블록을 얹기보다는, 기억을 꺼내오는 전용 모듈 (Engram) 을 하나 추가하는 방식을 사용했습니다. 핵심은 기존 계산 흐름을 최대한 건드리지 않으면서, 정적인 언어 패턴만 따로 처리하겠다는 점이죠
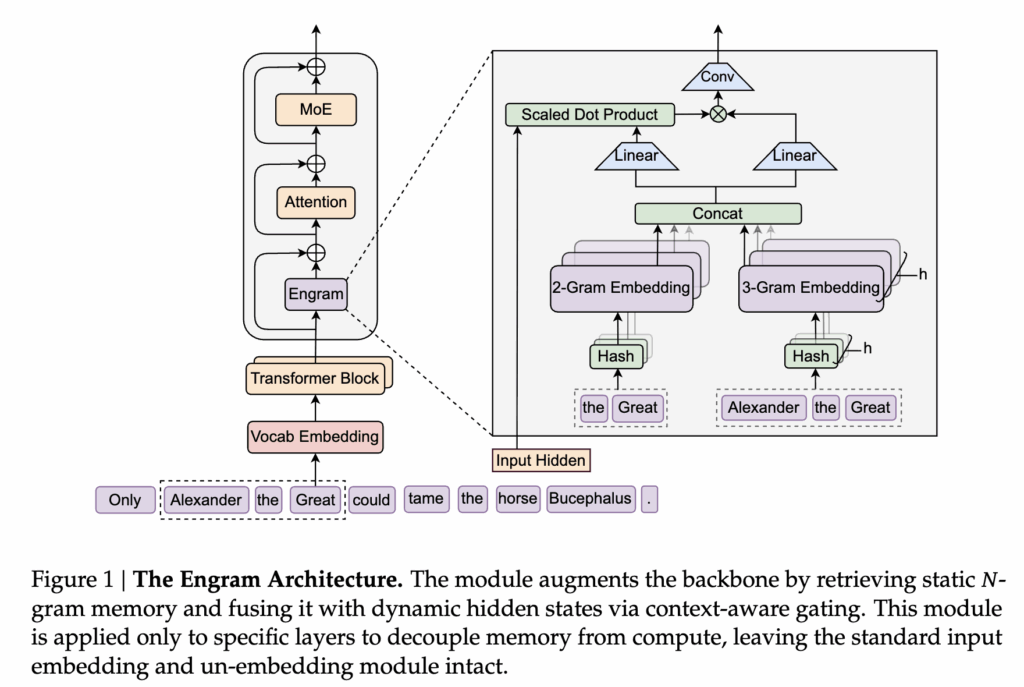
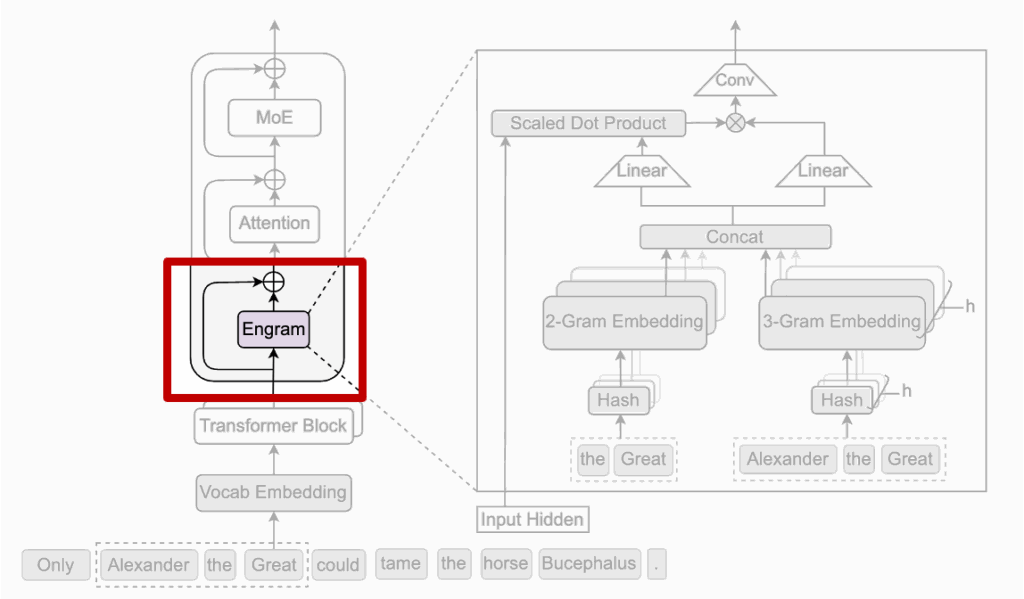
기억을 꺼내오는 전용 모듈이 상단 Figure 1에서 보라색으로 표시된 Engram 블록 입니다. 그림을 보면 Engram은 Transformer 블록 전체를 대체하는 구조가 아니라, 기존 블록 사이에 하나의 블록이 추가되어 있는 것을 볼 수 있습니다. 그 외 나머지 부분은 동일하죠. 그래서 Engram이 들어가더라도 기본적인 token embedding이나 attention 구조는 전혀 바뀌지 않습니다. 이게 저자들이 계산 흐름을 건드리지 않는다고 하는 이유죠
그리고, 특정 layer에 도달했을 때만 Engram이 개입합니다. 실제로 Engram은 Attention이나 MoE 앞에 항상 있는 게 아니라, 일부 layer에만 선택적으로 삽입되어 있습니다. 이는 모든 단계에서 기억을 쓰기보다는, 초반 혹은 중간 단계에서 정적인 패턴만 한 번 정리해두자는 설계에 가깝다고 합니다.
본격적인 설명에 앞서… N-gram에 대해 모르시는 분이 있을 것 같아 설명을 추가해보겠습니다.
(참고자료 https://wikidocs.net/21692)
N-gram 은 통계 기반의 언어 모델로, 이전에 등장하는 일부 단어만을 고려해서 그 다음에 들어갈 단어를 예측하는 방식입니다. 그럼 여기서 N 은 몇 개의 단어를 고려할 지를 결정하는 숫자겠죠? 예를 들어 ‘An adorable little boy is spreading‘ 라는 문장 다음에 등장할 말을 맞춰야 되는 상황이라고 가정해봅시다.
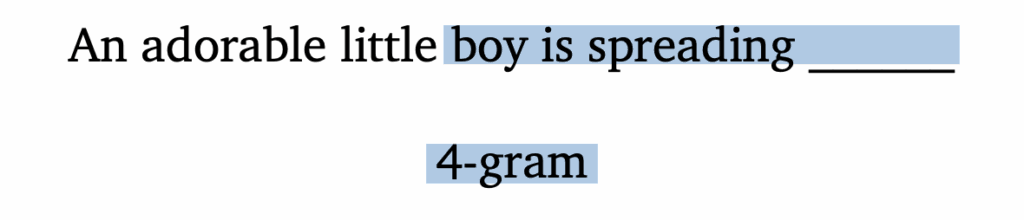
4-gram이라면 예측해야하는 단어를 포함하여 앞에 있는 3개의 단어를 고려합니다. 이때, 다음에 등장할 단어의 확률은 다음과 같이 계산하죠.
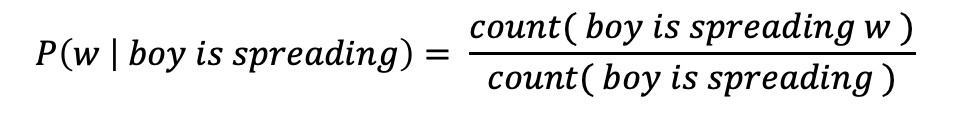
만일 가지고 있는 데이터셋에서 boy is spreading가 1,000번 등장하고, boy is spreading insults가 500번 등장했으며, boy is spreading smiles가 200번 등장했다면… boy is spreading 다음에 insults가 등장할 확률은 50%이며, smiles가 등장할 확률은 20%입니다. 확률적 선택에 따라 insults가 더 맞다고 판단하게 됩니다.
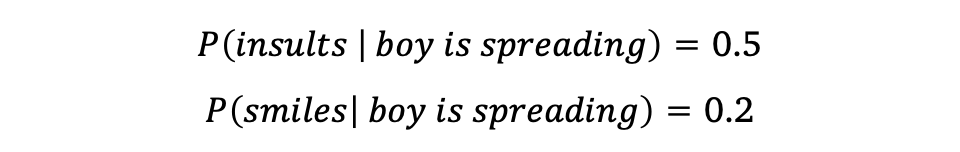
흠 근데 이상하죠? 전체 문장을 고려한다면 분명 사랑스러운 작은 소년인데, 모욕을 퍼뜨리다니… 이렇게 N-gram은 N을 어떻게 설정하는지에 따라서, 그리고 가지고있는 데이터셋에 따라서 성능이 천차만별이 되기도 합니다. 다만 해당 논문에서는 이미 고정되어 사용되는 관용어를 찾기 위한 것으로 N이 그렇게 클 필요는 없겠죠?
2.1. Sparse Retrieval via Hashed 𝑁-grams
이제 Engram 내부를 설명하겠습니다.
가장 먼저 수행되는 것은 Tokenizer Compression입니다. 기존 토크나이저는 ‘Apple’과 ‘apple’ 같이 같은 표현임에도 서로 다른 ID로 처리하여 메모리를 낭비하는 문제가 있습니다. 그러나 Engram은 의미가 같은 표현을 하나로 묶는 것이 목적이기에, 대소문자 통일/유니코드 정규화를 통해 의미적으로 동일한 토큰들을 하나의 ID(Canonical ID)로 매핑하는 Tokenizer Compression 를 적용하였습니다. 그 결과, 128k 크기의 어휘 집합에서 약 23%이나 되는 절감 효과를 얻었다고 합니다.
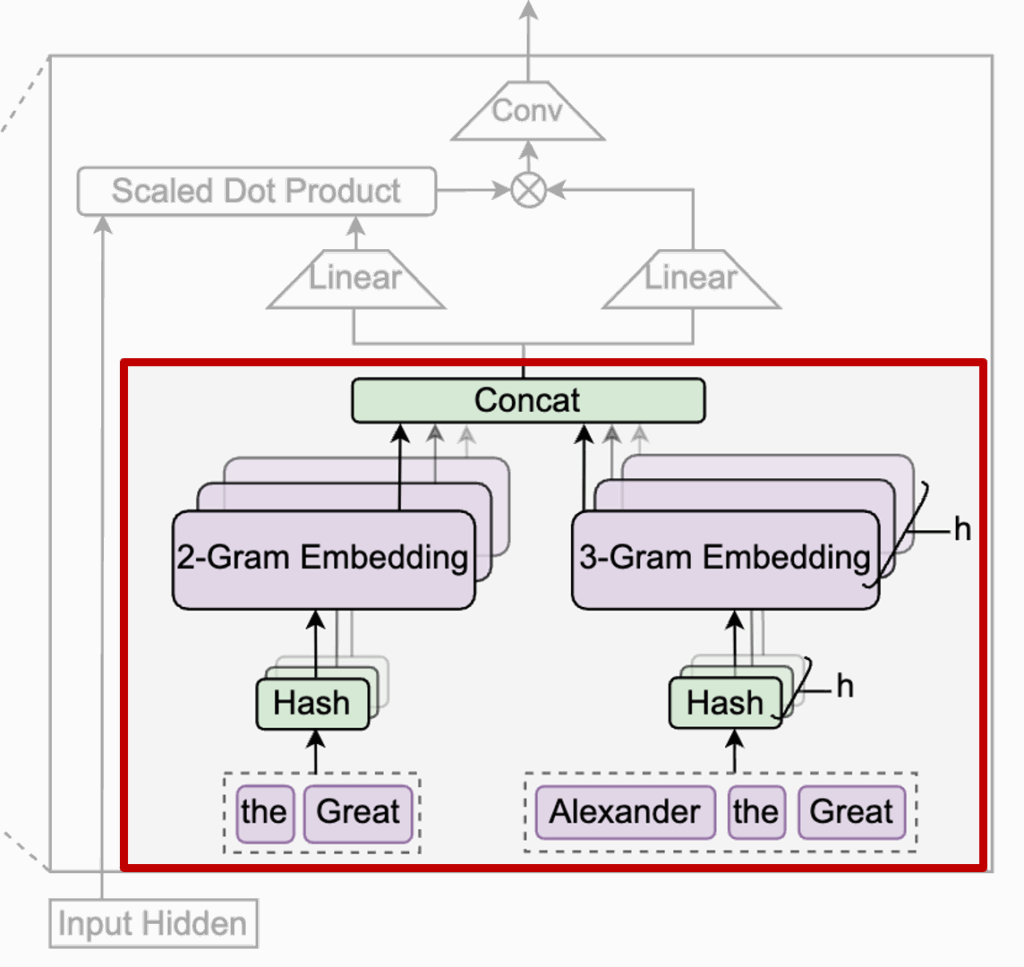
이렇게 압축된 토큰을 기준으로 N-gram을 추출합니다. 상단 그림예시 문장인 “Alexander the Great”가 들어오면, Engram은 현재 토큰 기준으로 바로 앞의 토큰들을 묶어 2-gram, 3-gram을 추출합니다. 그림 아래쪽에 보이는 the Great 그리고 Alexander the Great가 각각 2-gram, 3-gram 이겠죠?
이 N-gram들은 바로 위에 있는 Hash 블록을 통해 메모리 인덱스로 바뀝니다. 중요한 건 이 과정이 attention처럼 연산을 많이 하는 방식이 아니라, 정해진 규칙으로 바로 메모리에서 꺼내오는 lookup이라는 점입니다. 그래서 저자들이 이걸 retrieval이라고 부르죠 (그와 동시에 계산복잡도가 O(1)인 이유)
이렇게 불러온 2-gram, 3-gram 임베딩들은 그대로 쓰이지 않고, Concat을 통해 하나의 메모리 벡터로 합쳐집니다. 여기까지가 retrieval 단계입니다. 즉, “이 위치에서 떠올릴 수 있는 모든 고정된 언어 기억을 모아놓는 과정”이라고 보면 될 것 같네요
2.2 Context-aware Gating
앞에서 Engram은 현재 토큰 주변의 N-gram을 추출해두었습니다. 하지만 여기에는 한 가지 문제가 있습니다. 이렇게 불러온 기억은 문맥을 고려하지 않은 정적인 정보라는 점입니다. 즉, 상황에 따라 맞을 수도 있고, 틀릴 수도 있습니다.
예를 들어, 같은 단어라도 문맥에 따라 의미가 달라지는 경우가 있고, 해시 기반 lookup 특성상 완전히 관련 없는 정보가 섞여 들어올 가능성도 있습니다. 그래서 Engram은 꺼내온 기억을 그대로 믿지 않고, 한 번 더 검증하는 과정을 거칩니다. 이게 바로 context-aware gating입니다.
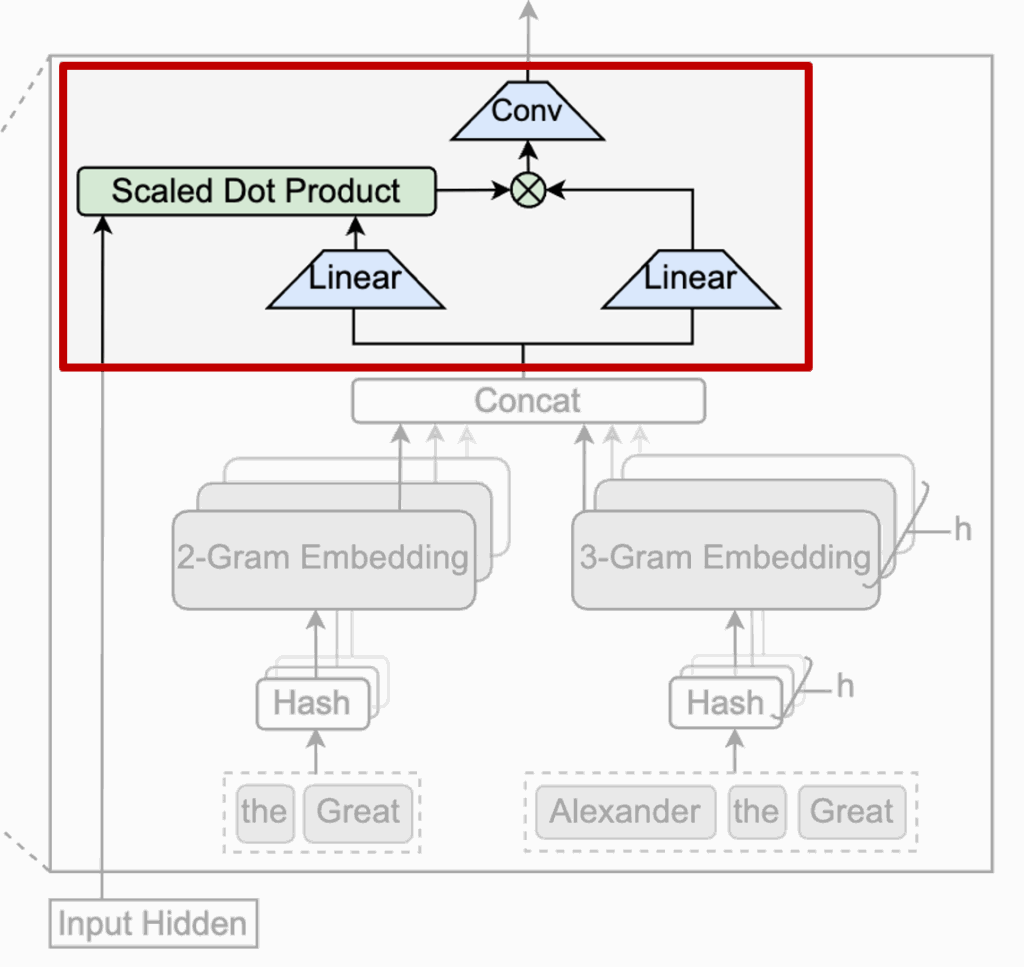
이 단계에서 핵심 역할을 하는 것은 현재 Transformer의 hidden state입니다. 이 hidden state는 이미 앞선 attention layer들을 거치며 문장 전체의 전역 문맥을 요약한 정보라고 볼 수 있습니다. Engram은 이 정보를 기준으로, “지금 문맥에서 이 기억이 정말 어울리는가?”를 판단하는 거죠. 저자는 이를 Fusion 단계라고 하고, 상단 그림 부분에 해당합니다.
구조적으로 보면, 현재 hidden state는 질문(Query) 역할을 하고, 메모리에서 꺼내온 Engram 벡터는 비교 대상(Key/Value) 역할을 합니다. 둘 사이의 유사도를 계산해 하나의 스칼라 값, 즉 gate를 만들고, 이 값으로 메모리 정보를 얼마나 반영할지를 조절합니다. 만약 기억이 현재 문맥과 잘 맞으면 gate가 커지고, 반대로 어색하거나 모순되면 거의 0에 가까워집니다. 결과적으로 쓸모없는 기억은 자연스럽게 걸러진다고 할 수 있겠네요
이렇게 gate를 거친 메모리 정보는 한 번 더 가볍게 다듬어집니다. 저자들은 짧은 1D convolution을 사용해, 단일 토큰이 아니라 근처 토큰까지 함께 고려한 로컬 패턴으로 메모리를 한번 더 정제하였다고 합니다.
마지막으로 이 결과는 residual 방식으로 기존 hidden state에 더해집니다. 즉, Engram은 Transformer의 출력을 덮어쓰지 않고, 필요할 때만 살짝 보조 정보를 얹어주는 구조입니다. 그리고 이 작업은 모든 layer에서 수행되지 않고, 시스템 지연을 고려해 일부 layer에만 선택적으로 적용됩니다.
2.3 Integration with Multi-branch Architecture
이제 다음으로, 이 Engram을 Transformer 안의 어디에, 어떻게 붙이는 게 가장 자연스러운가에 대해 고민을 담은 파트인데요
저자들은 이 문제를 단순히 하나의 경로에 Engram을 추가하는 방식으로 풀지 않습니다. 대신, 최근 LLM에서 널리 사용되는 multi-branch 구조를 기본 전제로 두었습니다. 이 구조에서는 하나의 residual stream이 여러 개의 병렬 branch로 나뉘고, 각 branch가 서로 다른 역할을 수행하게 됩니다.
Engram은 이 multi-branch 구조와 잘 맞도록 설계되었습니다. 바로, 기억 자체는 모든 branch가 공유하되, 그 기억을 얼마나 믿을지는 branch마다 다르게 판단하자는 것이라고 하네요.
구체적으로, Engram이 사용하는 메모리 테이블은 모든 branch에서 공통으로 사용됩니다. 즉, Alexander the Great 같은 고정된 언어 패턴은 하나의 기억으로만 저장됩니다. 대신, 각 branch는 현재 자신이 보고 있는 hidden state를 기준으로, 이 기억이 얼마나 중요한지를 각자 다른 gate로 평가하죠. 어떤 branch에서는 이 기억이 강하게 반영되고, 다른 branch에서는 거의 무시될 수도 있습니다.
이 설계 방식은, 메모리를 branch마다 따로 두지 않기 때문에 파라미터 수는 크게 늘어나지 않으면서도, branch별로 서로 다른 해석과 역할 분담이 가능해집니다. 즉, 어떤 branch는 로컬한 언어 패턴에 더 민감하게 반응하고, 다른 branch는 전역적인 문맥이나 추론에 집중할 수 있다는 장점이 있죠
또 하나 중요한 점은 구현 측면입니다. 저자들은 이 구조가 실제 GPU 환경에서도 효율적으로 동작하도록, 계산을 하나의 큰 연산으로 묶을 수 있게 설계했다고 설명합니다. 덕분에 Engram이 추가되더라도 연산 효율이 크게 떨어지지 않고, 기존 multi-branch Transformer와 자연스럽게 결합됩니다.
2.4 System Efficiency: Decoupling Compute and Memory
이제 논문의 핵심 중 하나인 시스템 설계 이야기입니다. 저자들이 강조하는 Engram의 가장 큰 장점은, 계산과 메모리를 분리(decoupling)할 수 있다는 점입니다.
Engram의 retrieval은 hidden state가 아니라 입력 토큰에만 의존합니다. 즉, Attention / MoE처럼 지금 계산 결과에 따라 접근 위치가 바뀌지 않고 어떤 메모리를 쓸지 미리 정확히 예측 가능 이라는 이 특성이 시스템 설계를 완전히 다르게 만드는 것이죠

학습 시 (Training)
– N-gram embedding 테이블은 매우 크기 때문에
– 여러 GPU에 나누어 저장(sharding)
– 필요한 부분만 All-to-All 통신으로 가져옴
추론 시 (Inference):
– Engram 메모리를 GPU 밖(Host memory)에 둠 입력 토큰을 보고,
– 필요한 메모리 인덱스를 미리 계산
– Transformer의 앞단 계산이 진행되는 동안, 메모리를 비동기로 미리 가져옴(prefetch)
그래서 상단 그림에서 알 수 있듯, GPU는 계산을 멈추지 않고 메모리 통신은 뒤에서 조용히 겹쳐서 수행될 수 있다고 합니다. Engram을 모든 layer에 넣지 않고 일부 layer에만 선택적으로 배치한 이유도 여기 있습니다. 너무 뒤에 두면 모델 성능이 떨어지고, 너무 앞에 두면 통신을 숨길 시간이 부족해지기 때문이죠.
Zipf 분포
자연어의 N-gram은 대부분 Zipf 분포를 따른다고 합니다.
– 자주 쓰이는 패턴은 극소수
– 나머지는 long tail
이 특성 덕분에 Engram은 자주 쓰이는 기억은 빠른 메모리에, 드문 기억은 느리지만 큰 저장소에 이런 계층적 캐시 구조를 자연스럽게 적용할 수 있습니다. 결과적으로 Engram은 모델 크기를 키우지 않고도 사실상 “외장 메모리”를 붙인 것처럼 확장 가능한 구조가 되는 것이죠
3. Scaling Laws and Sparsity Allocation
부수적인 내용까지 다루다 보니, 설명이 좀 길어졌네요.
이제 저자들이 앞에서 제안한 Engram이 정말로 의미 있는 선택인지를 실험적으로 검증하는 파트입니다. 바로 다음의 질문을 해결하기 위한 파트인데요.
같은 계산량(FLOPs)을 쓸 수 있다면, 그 여분의 용량을 계산(MoE)에 쓸 것인가, 아니면 기억(Engram)에 쓸 것인가?
저자들은 이를 sparsity allocation 문제로 정리합니다. Transformer 전체 파라미터 중, 실제로 토큰 하나를 처리할 때 활성화되는 파라미터 수는 제한되어 있습니다. MoE에서는 선택된 expert만 활성화되고, Engram 역시 토큰마다 조회하는 메모리 슬롯 수가 고정되어 있기 때문에, 두 구조 모두 계산량을 늘리지 않고 용량만 늘릴 수 있는 상황인 것이죠
그래서 저자들은 전체 sparse 용량을
– MoE expert 용량으로 쓸지,
– Engram 메모리 테이블로 쓸지
그 비율을 조절하며 성능 변화를 측정하였습니다
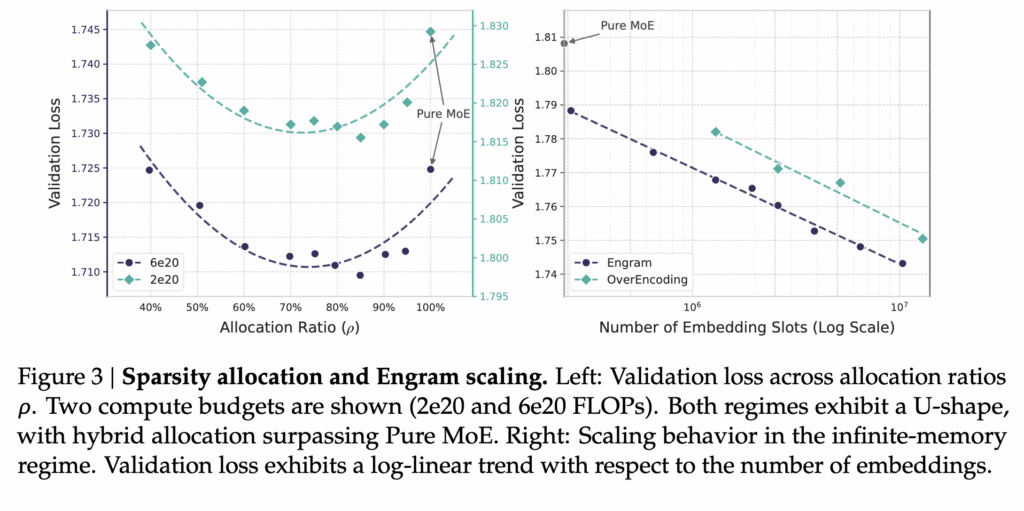
3.1 Sparsity Allocation 결과: U-shape (MoE와 Engram 적절하게 사용!!!)
상단 그림 이 그 실험 결과 입니다. MoE에 모든 sparse 용량을 몰아준 경우(순수 MoE)는, 이미 알고 있는 언어 패턴까지도 매번 계산으로 복원해야 하므로 비효율적입니다. 반대로 Engram에만 용량을 몰아준 경우에는, 추론이나 조합이 필요한 부분을 처리할 계산 능력이 부족해집니다.
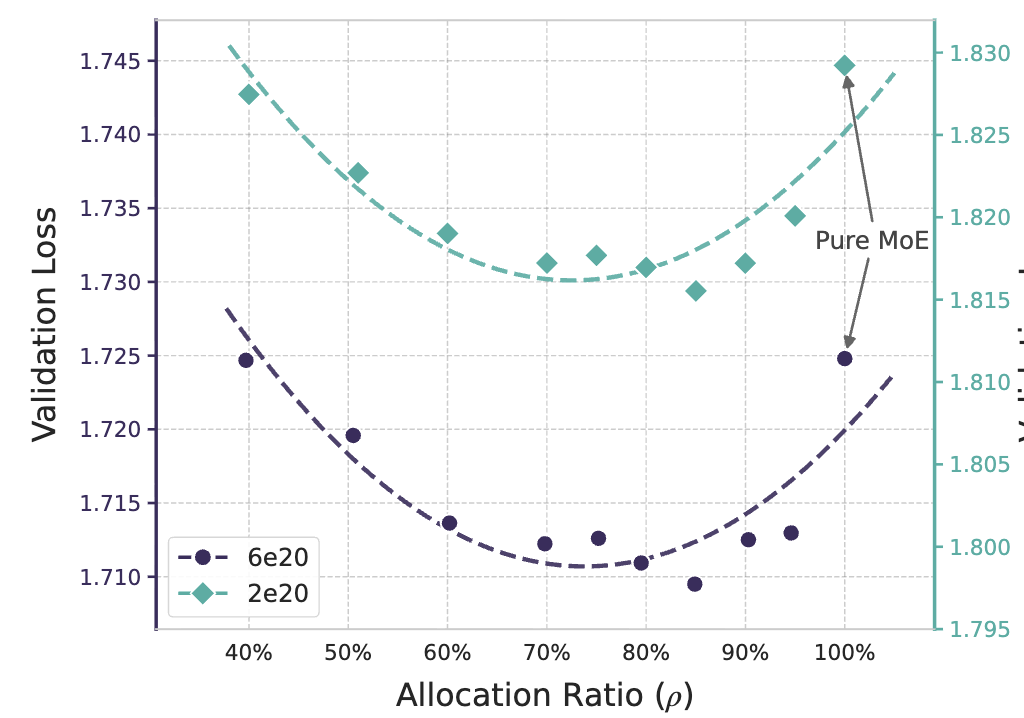
결과적으로 성능은 이 두 극단 사이에서 U자 형태를 보이며, 가장 좋은 성능은 MoE와 Engram을 함께 사용하는 중간 지점에서 나타납니다. 실험에서는 전체 sparse 용량의 약 20~25%를 Engram에 할당했을 때 가장 낮은 validation loss를 기록합니다.
중요한 점은, 이 최적 비율이 모델 크기나 계산 조건이 달라져도 크게 변하지 않는다는 것입니다. 즉, Engram은 특정 세팅에서만 먹히는 트릭이 아니라, 계산 예산이 고정된 상황에서 일관되게 유효한 설계 선택임을 보였다고 합니다.
또 하나 눈여겨볼 결과는, MoE 용량을 꽤 줄이더라도 Engram을 함께 쓰면 순수 MoE와 비슷한 성능을 유지할 수 있다는 점입니다. 이는 일부 계산을 “기억 기반 조회”로 대체할 수 있다는 저자들의 주장을 뒷받침합니다.
3.2 Infinite Memory Regime: 메모리는 계속 늘려도 됨!!!
다음 실험에서는 MoE 백본을 고정한 상태에서 Engram 메모리 크기만 계속 늘려보았다고 합니다. 즉, 계산량은 그대로 두고 기억 용량만 키웠을 때 어떤 일이 벌어지는지를 보는 실험입니다.
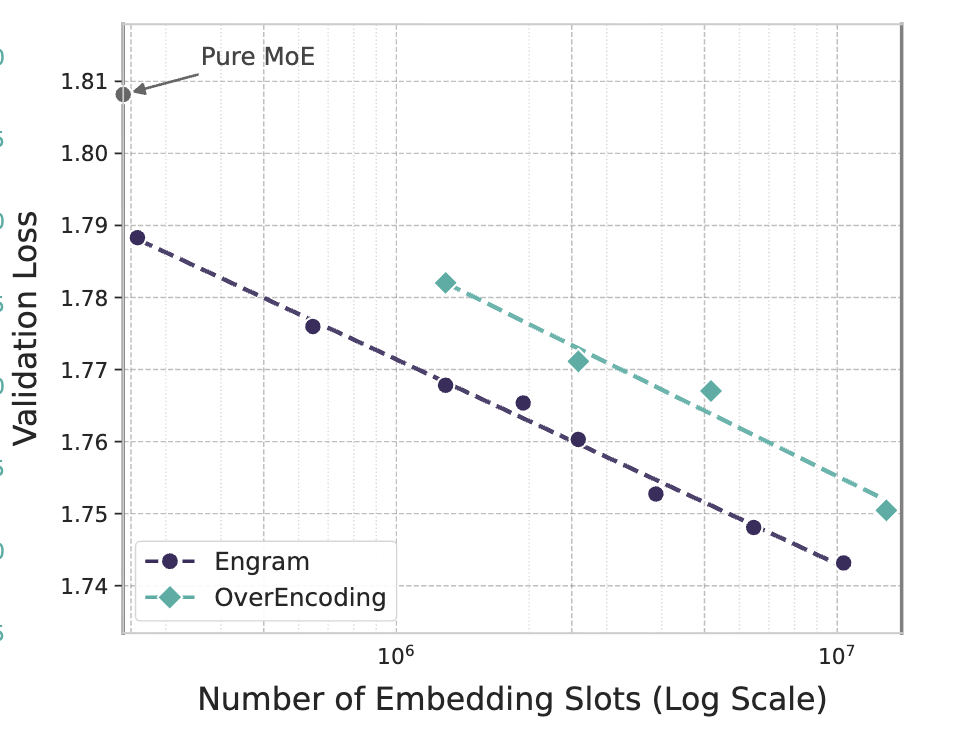
실험 결과 제법 재밌는데요. Engram의 테이블 슬롯 수를 늘릴수록 validation loss가 지속적으로 감소하며, 로그 스케일에서 거의 직선에 가까운 감소 추세를 보였습니다. 이는 Engram이 단순히 도와주는 모듈이 아니라, 메모리 용량 증가에 따라 예측 가능한 스케일링 이득을 제공한다는 것을 의미합니다.
따라서 저자들은 MoE는 계산량과 함께 커져야 하지만, Engram은 계산 비용을 거의 늘리지 않고도 용량을 확장할 수 있습니다.
정리하면 LLM에서 모든 것을 계산으로 처리할 필요는 없고, 계산이 필요한 부분과 외워두면 되는 부분을 분리하는 것이 더 효율적이라는 것입니다. MoE는 생각을 담당하고, Engram은 암기를 담당하여, 두 구조는 경쟁 관계가 아니라 상호 보완 관계에 있다고 정리할 수 있을 것 같습니다.
특히, Scaling Laws 관점에서 보면, Engram은 FLOPs 예산이 제한된 상황에서도 모델 용량을 확장할 수 있는 실질적인 대안을 제시하고 있다고 할 수 있겠네요!
4. Experiment
이제 실험 결과 확인해보겠습니다. 이 장의 핵심은 단순한 SOTA 경쟁이 아니라, “Engram이 어떤 상황에서, 어떤 역할을 하며, 왜 도움이 되는가”를 보여주는 것 같습니다.
4.1 Pre-training Performance Comparison
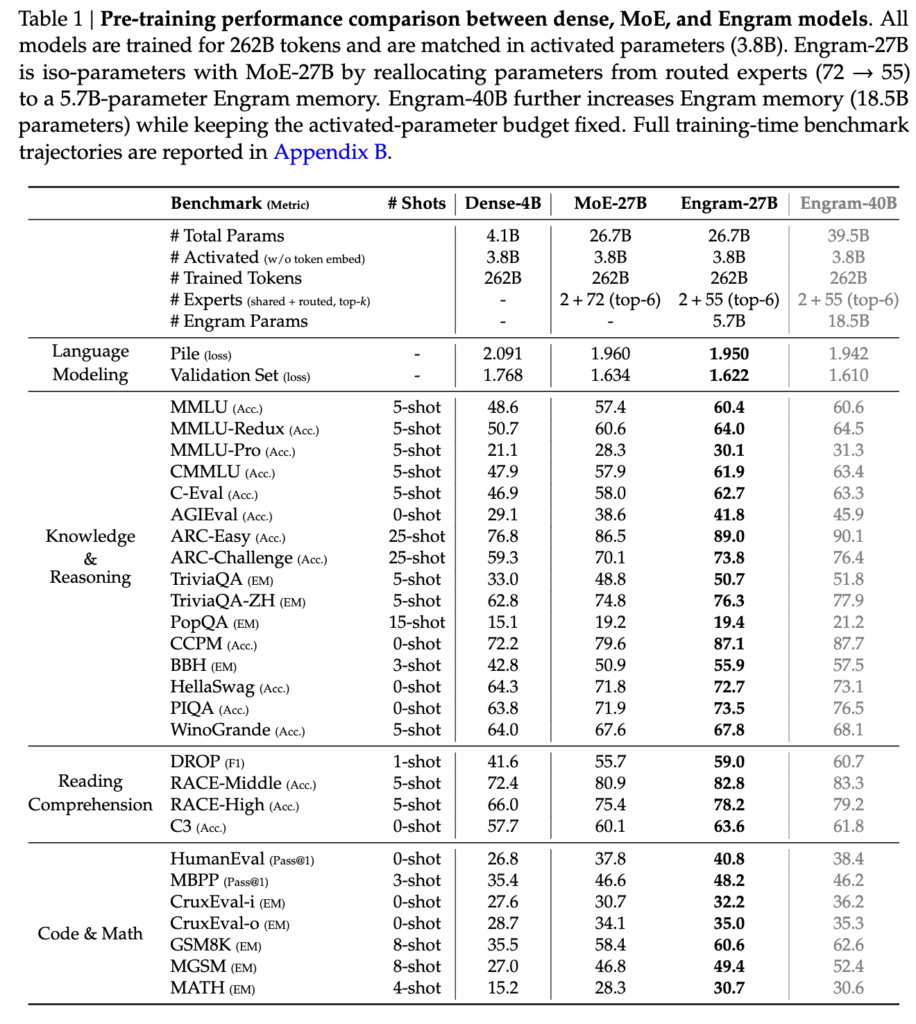
이 테이블은 Engram이 같은 계산량으로도 성능을 올릴 수 있는지를 확인하는 실험입니다. 모든 모델은 활성 파라미터 수(3.8B)와 학습 토큰 수(262B)를 동일하게 맞췄고, 차이는 MoE의 일부 용량을 Engram 메모리로 바꿨느냐입니다. 결과를 보면 Engram-27B는 거의 모든 벤치마크에서 MoE-27B보다 성능이 더 좋고, 특히 MMLU, ARC, GSM8K 같은 지식·추론 태스크에서 개선 폭이 컸습니다. 활성 파라미터는 그대로인데 메모리만 늘린 Engram-40B는 여기서 성능이 더 올라가죠.
Engram이 추가되었음에도 불구하고 활성화되는 파라미터 수는 거의 증가하지 않는다는 것은, 성능 향상은 계산량 증가가 아니라, “이미 알고 있는 언어 패턴을 계산 대신 기억으로 처리한 효과”에서 나온다는 해석이 가능한 것이죠
4.2 Long-context Performance Comparison
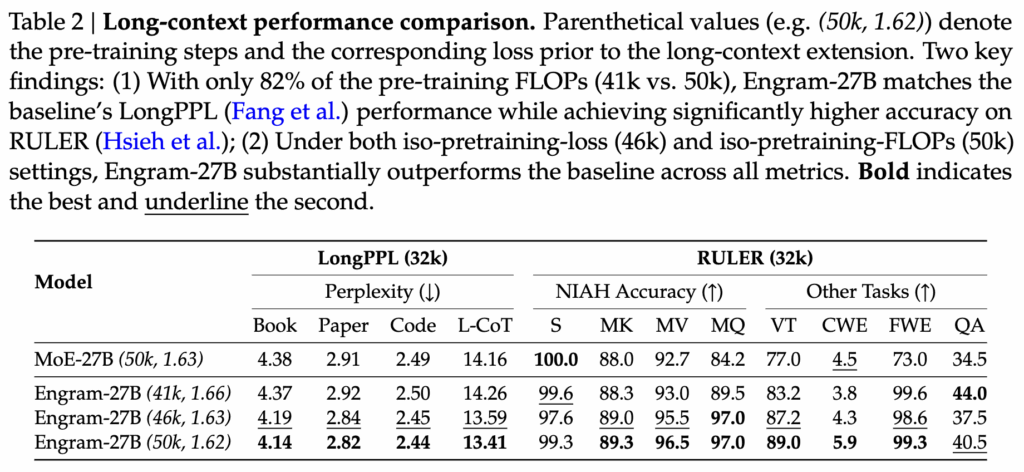
Engram이 긴 문맥(long-context) 환경에서 얼마나 효율적인지를 보여주는 실험입니다. 핵심은 같은 성능을 내기 위해 얼마나 적은 학습 비용(FLOPs)이 드는가를 확인해본 실험입니다. 결과를 보면 Engram-27B는 MoE-27B보다 훨씬 적은 pre-training FLOPs(41k vs 50k)만 사용하고도 LongPPL 성능은 거의 동일하게 유지합니다. 반면 RULER 벤치마크에서는 오히려 정확도가 크게 상승합니다.
또한 동일한 pre-training loss나 동일한 FLOPs 조건으로 비교했을 때도, Engram은 모든 long-context 지표에서 일관되게 MoE를 상회하였습니다. 특히 NIAH, Multi-Query, QA 같은 문맥을 길게 유지하며 정보를 추적해야 하는 태스크에서 차이가 두드러졌습니다.
저자는 Engram은 긴 문맥에서도 불필요한 계산을 반복하지 않고, 고정된 패턴을 메모리로 처리하기 때문에 더 적은 학습 비용으로도 long-context 이해 능력을 확보할 수 있음을 보여주는 것이라고 했습니다.
4.3 Representation Analysis (LogitLens & CKA)
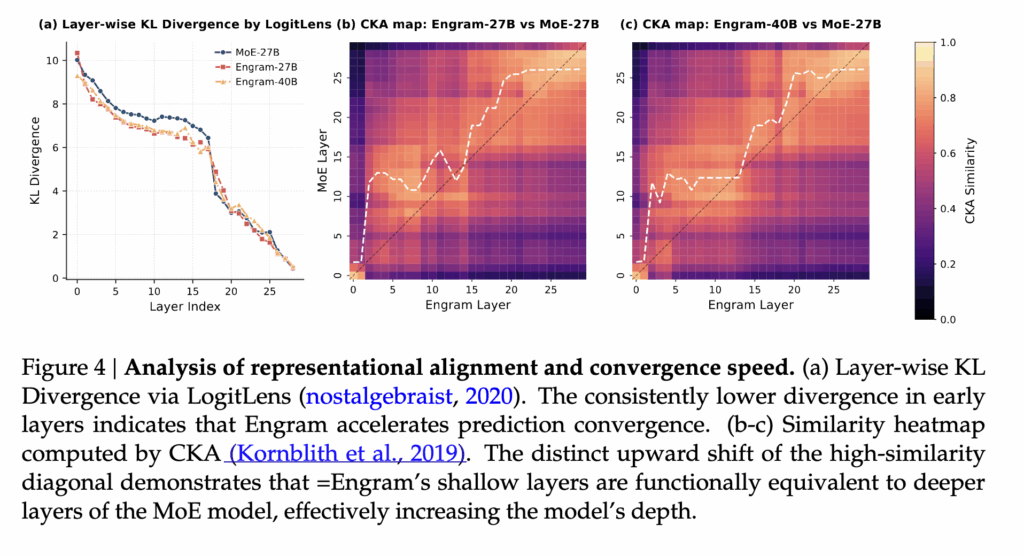
이 그림은 Engram이 모델 내부 표현을 어떻게 바꿔놓는지를 분석한 결과인데요. 왼쪽 그래프(a)는 LogitLens를 이용해, 각 layer에서 예측 분포가 얼마나 빨리 안정되는지를 보여줍니다. 결과를 보면 Engram 모델은 초기 layer부터 KL divergence가 더 낮게 떨어집니다. 즉, Engram은 모델이 정답에 가까운 예측을 더 이른 layer에서 만들기 시작합니다.
오른쪽의 CKA 히트맵(b, c)은 Engram과 MoE의 layer 표현이 서로 얼마나 비슷한지를 비교한 것입니다. 여기서 중요한 포인트는, Engram의 얕은 layer가 MoE의 더 깊은 layer와 높은 유사도를 보인다는 점입니다. 대각선이 위로 밀려 올라간 형태가 바로 그 증거입니다.
정리하자면, Engram은 초반 layer에서 이미 알고 있는 언어 패턴을 메모리로 빠르게 처리해주기 때문에, 모델이 더 일찍 “정리된 표현”을 만들 수 있습니다. 즉, 모델이 초반 레이어에서 사소한 패턴을 처리하느라 힘을 빼지 않아도 되니, 깊은 레이어를 진짜 추론에 쓸 수 있게 되기 때문이죠
4.4 Architecture Ablation Results

이 그림은 Engram의 성능이 우연이 아니라 설계 선택의 결과임을 보여주는 ablation 입니다. 특히, 검정 그래프는 Engram을 어느 layer에 넣느냐에 따른 성능 변화를 나타냅니다. 결과를 보면 Engram을 초기 layer(특히 Layer 2)에 삽입했을 때 validation loss가 가장 낮고, 뒤쪽 layer로 갈수록 효과가 줄어듭니다. 즉, Engram은 후반 추론을 돕는 모듈이라기보다, 초반에 고정된 언어 패턴을 정리해주는 역할에 가깝다는 걸 보여주는 것이라고 합니다
그리고 오른쪽의 자주색 처럼 표시된 결과는 Engram 내부 구성 요소를 하나씩 제거한 실험입니다. multi-branch 구조, token compression, context-aware gating을 제거하면 모두 성능이 악화되며, 특히 gating 제거 시 성능 저하가 가장 컸다고 합니다. 이는 Engram이 단순한 메모리 lookup이 아니라, 문맥에 맞는 기억만 선택하는 구조임을 보여주는 것이라고 하네요
4.5 Visualization of the Engram Gating Mechanism

그림 7은 Engram의 gating scalar \alpha_t가 토큰 단위로 어떻게 활성화되는지를 시각화한 결과다. 색이 진할수록 해당 토큰에서 Engram 메모리의 기여도가 크다는 것을 의미합니다.
관찰하면, Engram의 활성화는 문장 내 모든 토큰에 균일하게 나타나지 않고, Alexander the Great Milky Way Princess of Wales 중국의 4대 발명, 역사적 인물 이름 등 과 같이 고정된 의미를 갖는 명사구, 고유명사, 역사·사실성 표현의 끝 토큰에서 집중적으로 발생하였습니다.
이는 Engram이 N-gram (여기서는 N=3) 기반으로 동작하기 때문이라고 하는데요. 즉, 특정 토큰 x_t 에서 높은 \alpha_t가 관측된다는 것은, 그 토큰으로 끝나는 직전 N-gram 패턴 전체가 “정적인 언어 패턴”으로 인식되어 메모리에서 성공적으로 검색되었음을 의미한다고 합니다. 그리고 Engram이 문법 토큰이나 일반 서술어에는 거의 반응하지 않고, 오직 기억 기반 회상이 필요한 위치에서만 선택적으로 활성화되는 것을 볼 수 있었습니다.
5. Conclusion
본 논문은 기존 MoE 계열 모델이 계산 효율을 위해 동적 라우팅에 집중해왔던 흐름과 달리, 언어 내에 반복적으로 등장하는 정적인 패턴 자체를 별도의 메모리로 분리하는 Engram이라는 새로운 방법을 제안한 연구였습니다.
Engram은 N-gram 기반의 결정론적 retrieval과 context-aware gating을 통해, Transformer의 기본 계산 흐름을 거의 건드리지 않으면서도 지식 집약적 추론과 장문 문맥 이해 성능을 안정적으로 향상시켰습니다. 실험 결과는 Engram이 동일한 활성 파라미터 예산 하에서 MoE 대비 더 빠른 수렴과 높은 성능을 달성함을 보여주었습니다.
특히 시스템 관점에서 계산과 메모리를 분리 가능한 구조로 설계했다는 점은, 대규모 언어 모델 확장에 있어 여러 가능성을 열어준 것은 아닌가 라는 생각이 드네요. 종합하면, Engram은 향후 메모리 증강 언어 모델 설계에 중요한 방향성을 제시한 연구라고도 볼 수 있을 것 같고, 그래서 최근에 많은 주목을 받은 것이 아닌가 하는 생각이 듭니다
안녕하세요 주영님 좋은 글 감사합니다.
엄청 구체적으로 LLM의 동작 과정을 알기 쉽게 정리해주신 것 같습니다.
읽으면서 드는 궁금증이 하나 있는데, Engram이 결국 MoE가 초기 layer 에서 주어진 문맥 정보가 너무 없어 헤매는 경우를 보완하는 것처럼 느껴졌습니다. 혹시 MoE가 초기 layer에서는 역할 분담을 제대로 못한다거나 Engram 처럼 MoE도 전체 layer에서 일부분(뒷부분)에만 넣는다거나 하는 기존의 연구들이 있나요?
감사합니다.