Guiding Audio-Visual Question Answering with Collective Question Reasoning
안녕하세요 이번에도 AVQA 관련된 논문을 들고왔습니다. 방법론적으로 현재 연구중인 상황에서 각 모달리티별 아웃풋들을 어떻게 잘 Fusion 해서 학습시킬지를 고민하고 있는 단계라 읽어보았습니다. 그럼 리뷰 시작하겠습니다.
Abstract
AVQA는 이제는 대부분 아시겠지만, 복잡한 동적 오디오-비주얼 정보를 토대로 질문에 답변을 해야하는 태스크입니다. 기존 AVQA 연구들은 주로 학습 과정에서 단일 질문-정답 쌍 만을 이용해왔습니다. 저자는 이로 인해 질문들 간에 존재하는 풍부한 의미적 여관성을 충분히 활용하지 못했다고 주장합니다.
저자의 방법론은 CoQo 라는 새로운 프레임워크를 제안하며 이는 여러 개의 질문-정답 쌍을 동시에 입력으로 받아, 이들 질문 간의 추론을 활용함으로써 모델 학습과정을 보조했다고 합니다. 여기까지만 들어보면 사실 inference 과정에서는 여러 개의 질문-정답 쌍을 활용하지 못하지 않나? 라고 생각할 수 있기에 저자는 제안한 방법론 중 QGT ( Question Gudied Transformer) 를 이용해서 학습 단계에서 여러 질문으로부터 집합적인 정보를 하긋ㅂ하는 learnable Token 집합을 도입했고, 추론 단계에서는 비록 하나의 질문이 주어지지만 이 learnable token들이 추가적인 추론 정보를 제공한다고 합니다.
위에 언급한 QGT는 spatial, temporal 차원 모두에 적용되었고, 질문과 관련된 특징을 효율적이면서도 효과적으로 추출할 수 있도록 설계되었다고 합니다. 그러면서 동시에 꽤 높은 성능을 달성했다고는 하는데, backbone 에 따른 성능차이가 좀 있어서, 저희가 연구하고 있는 백본과 비슷한 설정으로 두면 이미 따라잡은 성능이기는 합니다.
Introduction
앞서 언급했듯이 AVQA는 복잡한 동적 오디오 비주얼 정보를 바탕으로 질문에 답해야 하는 태스크로, 최근 지능형 어시스턴트의 확산과 함께 그 중요성이 커지고 있습니다. 인간이 시작과 청각을 동시에 활용해 주변 환경을 이해하고 질문-응답을 통해 상호작용한다는 점에서 AVQA는 실제 환경 이해를 위한 핵심 문제로 간주됩니다. 기존 VQA 보다 Audio 모달리티를 하나 더 이용하는 차이점정도라 생각들 수 있지만 새로운 모달리티를 시간적,공간적인 관계를 동시에 이해하며 매핑해야한다는 점이 난이도를 높이는 것 같습니다.
저자는 기존의 AVQa 방법들은 주로 비주얼과 오디오 특징을 먼저 결합한 뒤, 해당 joint feature를 질문과 상호작용시키는 방식을 사용해 왔다고 합니다. 그러나 비디오는 시간에 따라 다양한 요소를 포함하고 있기 때문에 이러한 방식으로 생성된 오디오-비주얼 특징에는 질문과 무관한 정보가 과도하게 포함되는 문제가 발생한다고 언급합니다. 그 결과, 세밀한 오디오-비주얼 관계를 묻는 질문에 대해서는 정확한 답변을 하지 못하는 한계가 있었다고 합니다.
이를 개선하기 위해 최근 연구들은 질문을 활용해 오디오-비주얼 feature extraction 자체를 가이드하는 question-guided 방식들을 제안했지만, 저자는 이러한 방법들 역시 두 가지 중요한 한계를 가진다고 지적합니다. 첫째, 대부분의 방법이 단일 비디오–단일 질문 쌍만을 기준으로 학습하기 때문에, 서로 다른 질문들 사이에 존재하는 의미적 연관성을 전혀 활용하지 못한다는 점입니다. 예를 들어, 하나의 질문에서 제공되는 단서(악기의 위치, 소리 특성 등)는 다른 질문을 푸는 데 직접적인 힌트가 될 수 있음에도 불구하고, 기존 방식에서는 이러한 정보 공유가 불가능합니다. 둘째, 오디오-비주얼 alignment를 위해 사용하는 contrastive learning이 서로 다른 비디오 간의 랜덤 오디오-비디오 쌍을 negative로 설정하는 방식에 머물러 있어, 구분이 쉬운 샘플들만 학습하게 되고, 결과적으로 질문과 관련된 fine-grained 오디오-비주얼 연관성 학습에는 한계가 있다는 점입니다. (연구를 진행하면서 이런식의 해석은 못해본 것 같은데 좋은 인사이트인 것 같습니다.)
Abstract에서도 말했듯이 저자는 이를 해결하기 위해 QGT 라는 새로운 모듈을 설계했고, 여러 질문간의 집합적 추론을 수행하여 그 결과를 바탕으로 질문에 의해 유도된 오디오-비주얼 특징을 추출할 수 있었다고 합니다.
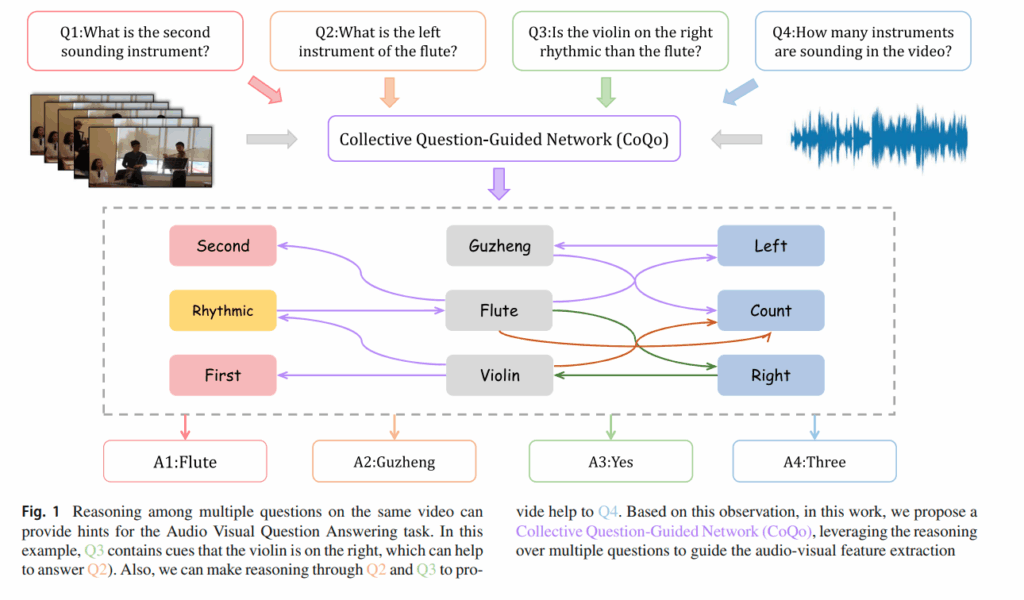
그림을 보면 저자는 질문을 하나만 봤을때보다, Q3을 보면 Q2의 질문에 해답이 될 정보도 들어있고, 이런식으로 여러 질문 set을 보면서 질문 분포의 구조를 학습하는 것을 의도한 것 같습니다. 사실 우려할 수 있는 점은 inference 때 갑자기 보던 질문의 개수보다 적어지니 추론 난이도의 변화를 우려할 수 있을 것 같습니다만, 저자는 동일한 비디오 내에서의 질문들을 모두 모아 학습하기 때문에 모델이 저자가 원하는대로 잘 동작했다면 질문 분포의 구조를 학습하여 전체 질문 유형들 중에서 이러한 부분들에 집중하면 좋겠다. 라는걸 스스로 배우길 기대한 것 같습니다.
Multimodal Learning with Audio
AVQA는 시각, 청각, 언어를 동시에 다루는 태스크이다 보니 넓은 의미에서 멀티모달 태스크에 속합니다. 비디오는 풍부한 오디오-비주얼 정보를 포함하고 있어 단일 모달리티보다 두 모달리티를 함께 활용할 때 더 많은 정보를 얻을 수 있다는 점에서 다양한 오디오-비주얼 태스크들이 연구되어 왔습니다.
기존의 Audio-visual localization, segmentation, sound source localization 등은 오디오와 비주얼 표현 간의 정렬을 학습하는 데 초점을 둡니다. 그러나 기존 방식들은 inter-video 정렬에 집중하고 동일한 비디오 내에서 질문에 따라 달라지는 미세한 오디오 비주얼 관계를 충분히 학습하기에는 한계가 있다고 합니다.
Method
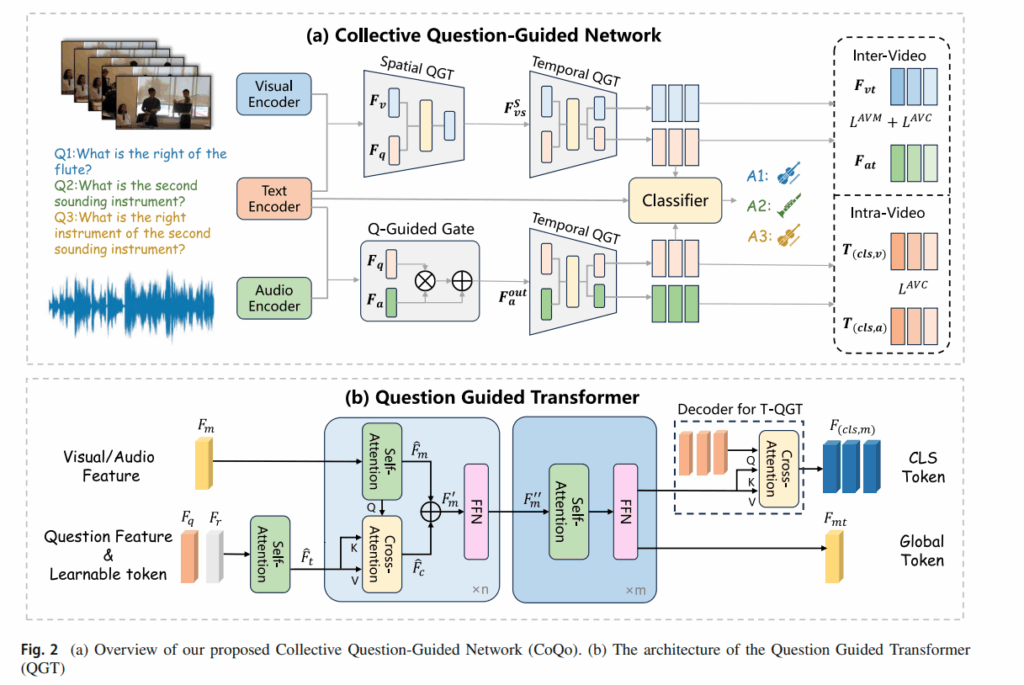
Input Representation
Audio 는 VGGISH 백본을 사용하여 비디오를 T개의 segement로 표현했습니다. 영상이 각 1분이라 60개의 segment T X d 로 이루어진다고 생각하면 됩니다.
Visual 은 Swin Transformer를 백본으로 사용하여 frame X spatial grid 형태로 표현됩니다. T X H X W Xd 형태라고 생각하면 될 것 같습니다.
Question 은 하나의 비디오에 연결된 N개의 질문을 LSTM 으로 인코딩하여 NXd 형태로 얻습니다.
Collective Question-Answering Training
기존 AVQA는 학습데이터가 페어로 주어지니 보통 한번의 forward에서 question이 한번만 사용됩니다.
저자는 2개의 단점을 앞서 언급했는데요
- 같은 비디오의 다른 질문이 제공하는 단서를 버림 (semnatic association 미활용)
- contrastive negative를 다른 비디오에서 랜덤 샘플링하면 너무 쉬움 → fine-grained cue 학습이 약함
그래서 학습 때는 같은 비디오에서 N개의 질문을 한번에 넣어 reasoning 시키고 inference 때는 실용성 때문에 질문을 1개만 넣는 방식으로 구현했습니다. 이때 inference mismatch를 메꾸는 장치가 learnble tokens 입니다.
Question Guided Transformer
$F_m$ : modality Feature (visual or audio)
visual 이면 T-H-W 개의 토큰으로 펼칠수도 있고 단계에 따라 T 일수도 있습니다. audio면 T개의 토큰입니다. 해당 단계는 질문 집합의 reasoning 단계와 질문으로 모달리티를 조건부화하는 (self attn + cross attn) 단계입니다.
저자는 질문 토큰 뒤에 learnable tokens 를 붙입니다. $F_r , R={(r1,…,r_m)}$
$F_t = concat[F_q,F_r]$ 이렇게 concat 한 질문 표현을 초반에 self-attention 을 거친 후 사용합니다. 여기서 저자가 노리고자 하는 점은 질문들끼리 서로 attention 하며 영상내의 단서나 공통 개념등을 공유하고 learnable token 들로 하여금 질문 집합에서 반복적으로 유용한 정보를 저장하는 메모리 슬롯처럼 업데이트하기를 기대합니다. 아직 문장들만 봤으므로 질문 분포에서 공통 구조나 힌트를 attention으로 엮는 과정쯤으로 이해하면 됩니다.
- modality sefl-attention 으로 모달리티 내부 구조를 먼저 정돈합니다. $F^{hat}m=θ{sa}(F_m,F_m,F_m)$
- modality가 질문(+learnable token)에서 필요한 정보를 조회하는 cross attention $F^{hat}c=θ{ca}(F^{hat}_m,F^{hat}_t,F^{hat}_t)$
- 둘을 섞고(residual) FFN 으로 정제합니다. $F’m=(F^{hat}_m+λF^{hat}_c)+F_m,F”m=FFN(F’_m)+F’_m$
Divide Spatial-Temporal QGTs for Video
video는 spatial QGT + Temporal QGT로 나눕니다. 우선 비주얼 feature 자체가 T X H X W 라 토큰수가 너무 많아 분리하는 것이 제일 크며 각 frame의 spatial attention 을 진행하고 pooling 과정으로 frame-level로 압축합니다.
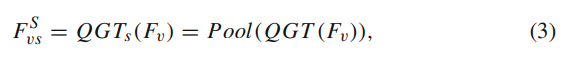
Temporal 축은 temporal attention을 수행하고 decoder를 붙여 답변용 CLS 토큰을 뽑습니다.
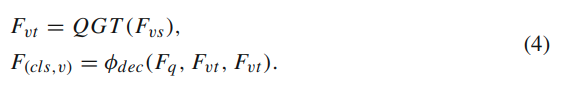
수식을 좀더 생각해보면 질문과 각 시간 segment간 내적 연산으로 cross modal attention map을 만들고 그 가중치를 audio feature에 곱해서 강조해주는 방식입니다. residual 로 원본 입력도 보존하는 형태로 해석하면 됩니다.
Audio-Visual Alignment
왜 inter + intra 를 같이 쓰나? 에 대한 답으로는 기존 inter-video 방식으로 대조학습을 진행하는게 너무 쉽고 같은 비디오 안에서 질문에 따라 달라지는 미세한 AV 연관을 학습하기 위함이라고 합니다.
Inter-video alignment
- Matching loss (이진 분류) positive : 같은 비디오에서 나온 visual,audio negative : 다른 비디오에서 랜덤으로 가져온 visual (또는 audio) $L_{AVM}=CE(1,y_{pos})+CE(0,y_{neg})$
- Bi-directional contrastive loss (CLIP 스타일) $L_{AVC}=InfoNCE(audio↔visual)$ $L_{inter} = L_{AVM} + L_{AVC}$
Intra-video alignment
여기서의 포인트는 같은 비디오 내에서 N개의 질문을 모으고 질문 i로 guided 된 audio CLS 와 visual CLS를 뽑고 사용합니다.
여기서 positive는 같은 질문 i 에 의해 guided 된 오디오 및 비디오 정보입니다.
여기서 negative는 같은 비디오지만 질문이 다른 j 에 의해 guided 된 오디오 및 비디오 정보입니다.
이렇게 설정하여 같은 영상이어도 질문이 다르면 모델이 집중해야 하는 AV cue 가 달라야 한다는 점을 학습합니다.
Modality Fusion and Answer Prediction
alignment로 각 비디오 오디오 정보를 뽑고 나서 concat 후 tanh + FC 로 AV joint를 생성합니다.
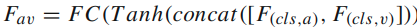
질문 feature와 element-wise 연산 두 가지를 섞습니다.
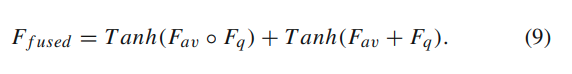
마지막으로는 classifier + softmax로 정답 class 42개를 예측합니다.
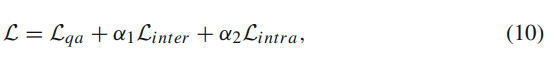
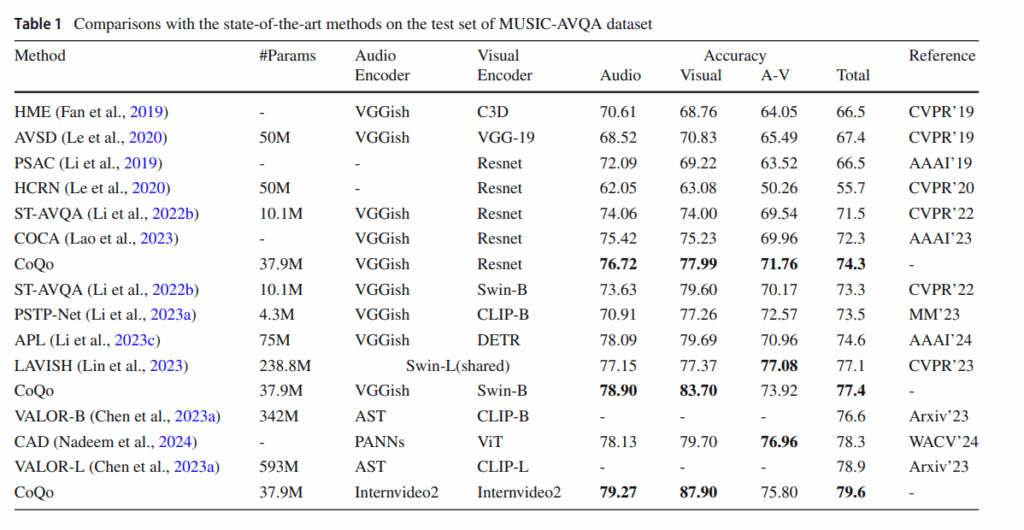
결과를 보면 CoQo 방식이 여러 백본들로 실험이 되었고 internvideo2로 뽑았을때 성능이 SOTA를 달성했습니다. 기존 방법론들이 VGGISH 와 CLIP 을 보통 사용하므로 77.4 성능을 내는것이 기존 방법론과 좀 공평하게 비교할 수 있는 수치로 보입니다.

해당 표는 기존방식인 HCRN 방식에서 저자가 제안한 QGT를 붙였을때 각 질문 유형당 정답 성능이 얼마나 변했는지를 보여주는 표입니다. 단일 질문 inference에서 질문 유형별로 성능이 올랐다로 이해하면 될 것 같습니다.
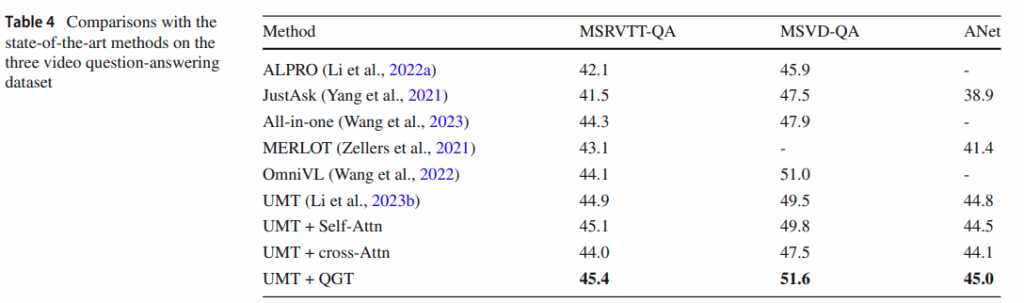
해당 Table은 CoQo 의 QGT가 AVQA뿐만 아니라 기존의 VQA dataset에서도 유용한지 평가한 표입니다. generalization 성능을 평가했다고 생각하면 될 것 같습니다.
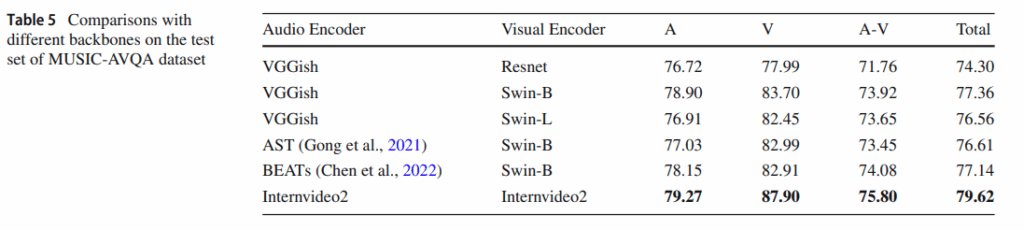
backbone을 바꿔가며 성능을 리포팅했는데, 좀 신기한점은 visual backbone을 swin_L 에서 swin_B 로 했을때 성능이 더 나아지는 부분도 존재합니다. CLIP 의 visual backbone에 비해 Swin 같은게 훨씬 좋으니 더 큰 모델을 쓰면 당연히 성능이 좋아질 줄 알았지만 representation 이 너무 차이나면 오히려 성능이 떨어질 수도 있는 것 같습니다.
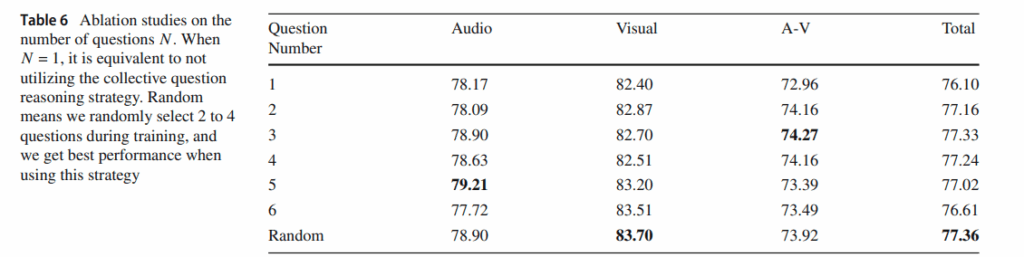
해당 표는 질문의 개수에 따른 ablation 표 입니다. 각 모달리티마다 봐야하는 질문의 개수가 조금씩 다른것을 알 수 있고, 생각보다 질문 개수에 따라 선형적으로 증가하지는 않는 것 같습니다.
이러한 실험들 이외에도 굉장히 많은 실험들을 했지만, 하이퍼파라미터 ablation 등이나 각 layert 수에따른 ablation 혹은 기존 AVQA 논문들이 다루는 정성적 시각화라 크게 신기한 실험은 없었던 것 같습니다.

Conclusion
저자는 AVQA task를 위해 CoQo 라는 네트워크를 제안했습니다. 뭐 큰 제안은 여러 입력 질문들에 대해 집합적으로 추론을 진행한 점이라고 생각하면 될 것같고 해당 질문들으 사용해서 시공간적으로 오디오와 비디오에 대한 특징을 추출하는 과정을 거칩니다. 또한 VQA 데이터셋으로도 제안한 방법의 견고성을 입증한 부분이 실험적으로 유의미하다고 생각합니다. 감사합니다.