논문 간단 소개
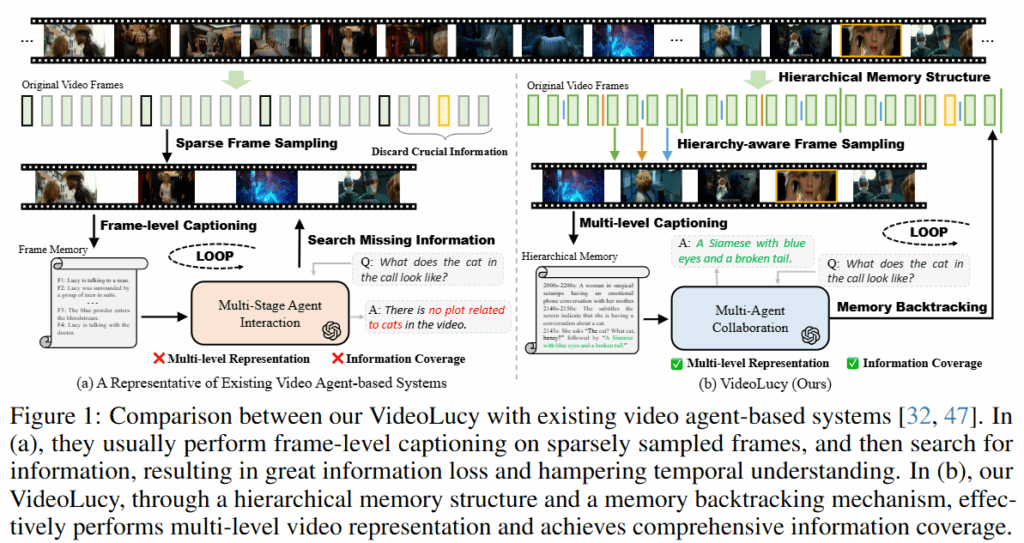
본 논문은 Long video Understanding을 위한 agent 기반 프레임워크를 제시합니다. LLM을 활용하여 비디오에서 중요 정보를 찾아내거나 정보를 통합해 답변을 생성하는 agent를 설계하는 연구는 물론 기존에도 있었습니다. 그러나 기존 연구는 비디오를 활용할 때 프레임 단위로 검색 등을 수행하도록 설계되어 시간적 맥락을 놓치기 쉬우며 프레임 단위로 비디오 데이터를 다루기때문에 연산량을 줄이기 위한 프레임 샘플링이 전처리로 활용되게 되고, 이로인한 정보 손실 위험을 내제하고 있습니다. 본 연구는 비디오 데이터를 프레임으로 나누어 바로 사용하는것이 아니라, 계층적 메모리 구조로 설계하고 역추적(Backtraking)방식으로 데이터를 탐색하는 프레임워크를 제안합니다. 이 뿐만 아니라 논문에서는 long video understanding에서 전역적으로 전개되는 사건에서부터 세부적인 내용까지 이해하는지를 평가할 수 있는 새로운 데이터셋인 EgoMem를 제안하여 VideoLucy가 해결한 기존 프레임워크의 문제(시간적 맥락의 이해/프레임 정보 손실)의 중요성을 다시한번 강조했습니다.
VideoLucy
“Mom, I can feel my brain, the deepest parts of my memory. I can remember the feeling of your hand on my forehead when I ran a fever. I remember stroking the cat, it was so soft, a Siamese with blue eyes and a broken tail.” -Lucy
위는 영화 Lucy의 한 대사로 논문의 첫 장을 장식하고있는 글입니다. 글에서 보면 아이가 “고양이를 쓰다듬은 행위 -> 고양이의 감촉 -> 고양이의 모습”순으로 고양이에 대한 기억을 계층적으로 전개하고 있습니다. 논문에서 제안한 프레임워크인 VideoLucy 또한 시간적 연관성이 있는 사건에 대해 추상적 사건에서 디테일한 요소로 기억해내는 역추적 방식으로 설계되었습니다.
Method
다른 agent 기반의 프레임워크 대비 VideoLucy의 특징은 비디오 참조에 있어 프레임단위의 접근이 아닌 역추적 방식으로 탐색하는 것 입니다. 이를 위해서는 계층적 메모리 구조로 비디오를 가공하는 단계가 필요합니다. 메모리를 구축하고 나서는 agent를 구현하고 agent가 역추적 방식으로 탐색하도록 파이프라인을 설계해야합니다. 메모리 구축 방법은 간단합니다. 파라미터 K를 통해 비디오 세분화 단계를 조절하여 메모리를 생성합니다. 즉, 비디오는 K개의 클립(v_1, v_2, … v_k)으로 나누어진 후 프롬프트 p_i와 함께 캡셔닝 모델에 입력되어 메모리 정보를(m_1, m_2… m_k)를 생성하게 됩니다. 이때 k=1이면 전역적 정보를 포괄하는 메모리, k가 클수록 세부적인 정보를 포함하는 메모리가 구축되며 k는 에이전트가 프로세스를 진행하며 지정하게 됩니다.
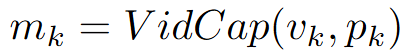
다음으로 에이전트의 종류입니다. 논문에서는 4가지 에이전트를 도입했으며 아래와 같습니다.
- Captioning Agent
- 메모리 구축을 위해 비디오 clip과 instruction(p_k)을 입력받아 텍스트 기억으로 변환하는 에이전트
(위 수식에서 호출되는 VideoCap 모델과 동일)
- 메모리 구축을 위해 비디오 clip과 instruction(p_k)을 입력받아 텍스트 기억으로 변환하는 에이전트
- Localization Agent
- 구축된 메모리(m_1, m_2 … m_k)와 질의를 입력받아 어떤 시간(t)의 메모리(m_t)가 가장 유의미한지 찾아내어 응답(t)하는 에이전트
- Instruction Agent
- 비디오의 현재 메모리와 Logcalization Agent의 검색결과, 질의를 입력받아 다음 실행에 대한 instruction(p_k+1)을 생성하는 에이전트
- Answering Agent
- 현재 비디오 메모리와 질의를 입력받아 질의에 대한 응답을 생성하는 에이전트
논문은 위와같은 다양한 에이전트를 통해 역추적 탐색 방식을 설계했으며 그 알고리즘은 아래와 같습니다.

앞서서 설명한 바와 같이 4개의 에이전트로 메커니즘이 구서오디어있습니다. 먼저 초기 메모리 CM을 구축하는데, 데이터셋마다 다르게 초기 세팅한 T_c를 K 파라미터로 하여 Coarse하게 구축합니다. 이후 Localization 에이전트를 통해 관심 시간을 찾고 이를 활용하여 다음 instruction을 생성합니다 (line 7) 쿼리와 유사한 비디오 클립을 기반으로 다음 메모리를 추가적으로 구축하고(line10) 이를 메모리 CM에 포함하며 Answer agent로 답변을 생성합니다. 이때 생성된 답변을 확신할 수 있다고 판단될 경우 반복을 중지하며, 그렇지 않으면 위의 과정을 반복해 점점 더 세부적인 메모리를 구축하게 됩니다. 실험에서는 무한 반복을 방지하기 위해 최대 반복 횟수를 지정했다고 합니다.
EgoMem Benchmark

논문에서는 Long video에 대한 이해를 평가하는 벤치마크 중 시간적 맥락에 대한 이해 능력에 초점을 맞추어 평가하기 위해 EgoLife 비디오 리소스를 기반으로 서로 떨어진 시간대에 발생한 사건들에 대한 이해와 순간적 사건의 세부사항을 이해할 수 있는지를 중점으로 가공한 EgoMem을 제안합니다. Figure 3에서와 같이 시간적 정보에 대한 이해를 요구하는 6개의 질문 유형(Event order, Temporal Judge, Temporal Align, Event Context, Event Rectification, Event Reconstruction)을 설계하고 세부사항에 대한 정보 누락이 없음을 확인하기 위해 Detail Perception을 추가하여 벤치마크를 구성했으며 총 42개의 평균 6.33시간 비디오와 504개의 질문으로 이루어져 있습니다.
Experiments
VideoLucy는 open source인 Qwen2.5-VL-7B와 DeepSeek-R1을 LLM 모델로 사용하였습니다. 또한 평가를 위해서는 Long video understanding 분야에서 주로 사용되는 MLVU, Video-MME, LVBench와 EgoMem을 활용했습니다. 먼저 Video-MME 벤치마크에서 실험 결과는 오픈소스 모델을 활용한 다른 방법론 대비 가장 높은 성능을 보였으며 상업 모델인 Gemini 1.5 Pro와 동등한 수준이라고 주장합니다.
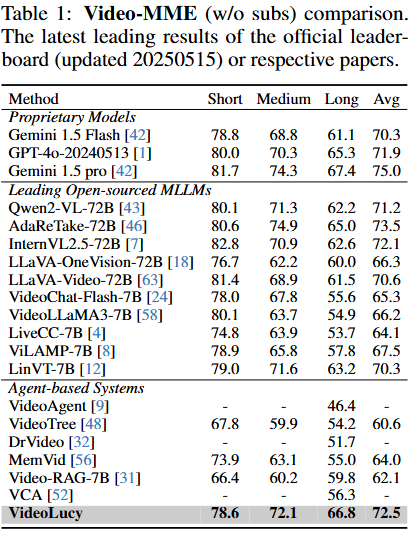
이어서 LVBench와 MLVU에 대한 성능도 리포팅하였습니다. LVBench에서는 이전의 모든 상업/오픈소스 모델을 능가하는 성능을 보이고있으며 MLVU에서도 가장 우수합니다. 이를 통해 VideoLucy가 다양한 지속시간을 갖는 비디오에 대해 효과적으로 성능을 개선하였음을 보였습니다.
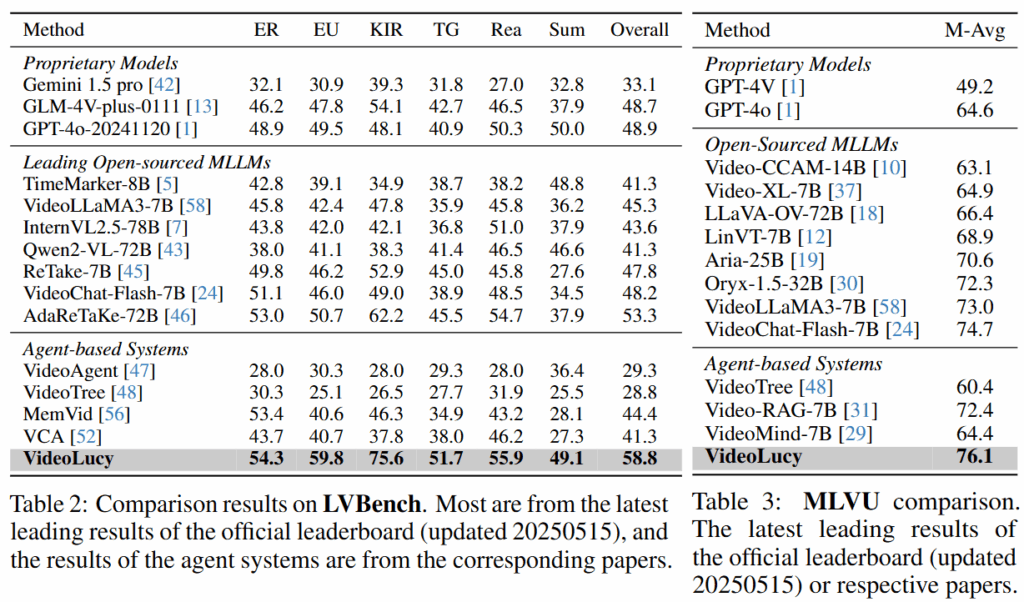
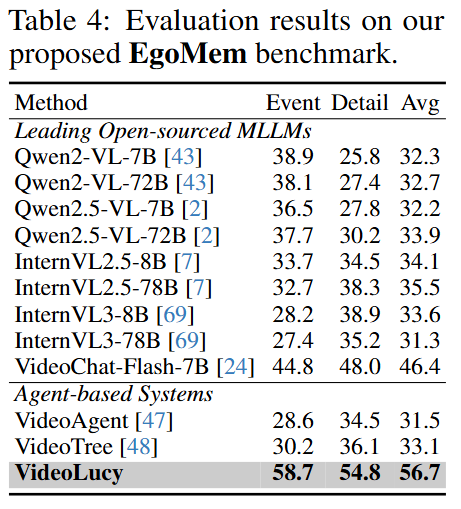
다음으로 제시한 벤치마크는 EgoMem에 대한 벤치마크입니다, 위의 실험된 데이터셋의 비디오는 대부분 2시간 이내의 데이터셋입니다. 그러나 EgoMem은 평균 6시간의 데이터셋으로 극도로 긴 영상에 대한 이해능력을 평가할 수 있습니다. 아래에서 확인할 수 있듯이 기존 방법론의 경우 성능이 매우 좋지 않으며 극도로 긴 영상에 대해서는 정상적으로 동작하지 않을 수 있음을 확인할 수 있습니다. 그러나 제안된 방법을 활용했을때는 가장 우수한 성능을 확인할 수 있으며 VideoLucy가 다양한 길이의 영상에 대해 시간적 맥락(Event, 6가지 질문)이나 세부적 정보(Detail, 세부사항 인식)를 모두 잘 탐색하고 대응할 수 있음을 확인할 수 있습니다.
Ablation and Analysis
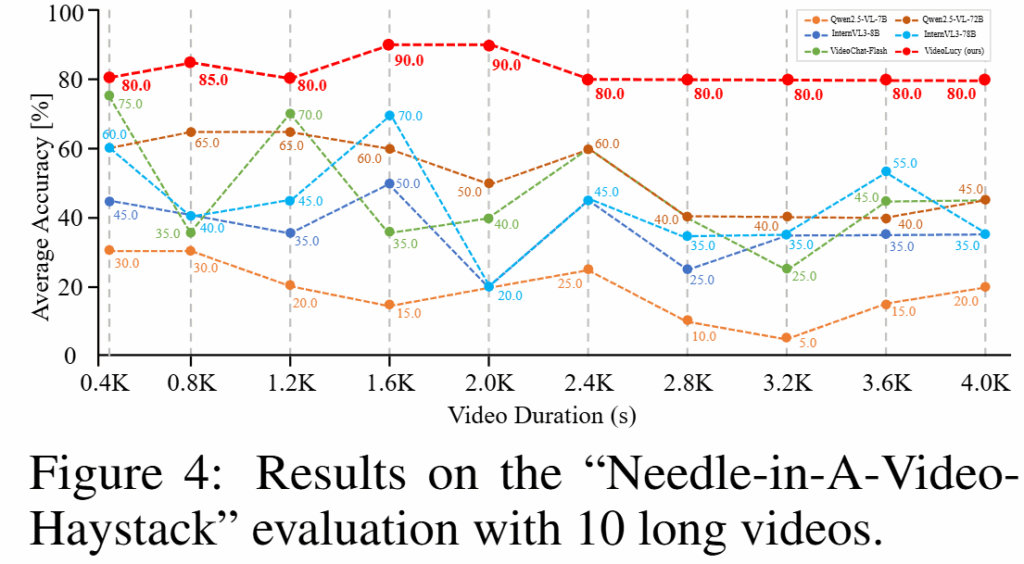
1) 세부사항 이해능력 (Needle in a video haystack)
LVBench와 MLVU에서 추출한 400초~4000초 길이의 10개의 비디오 중간에 10초짜리 비디오를 삽입하고 삽입한 영상에 대한 질의응답을 수행했습니다. 그 결과는 Figure4와 같습니다. 영상의 길이가 길어질수록 일반적으로 성능이 하락하나 VideoLucy(붉은색)의 경우 원본 영상의 길이에 관계없이 높은 정확도를 유지하며 세부 정보에 대한 손실이 없었음을 확인할 수 있습니다.
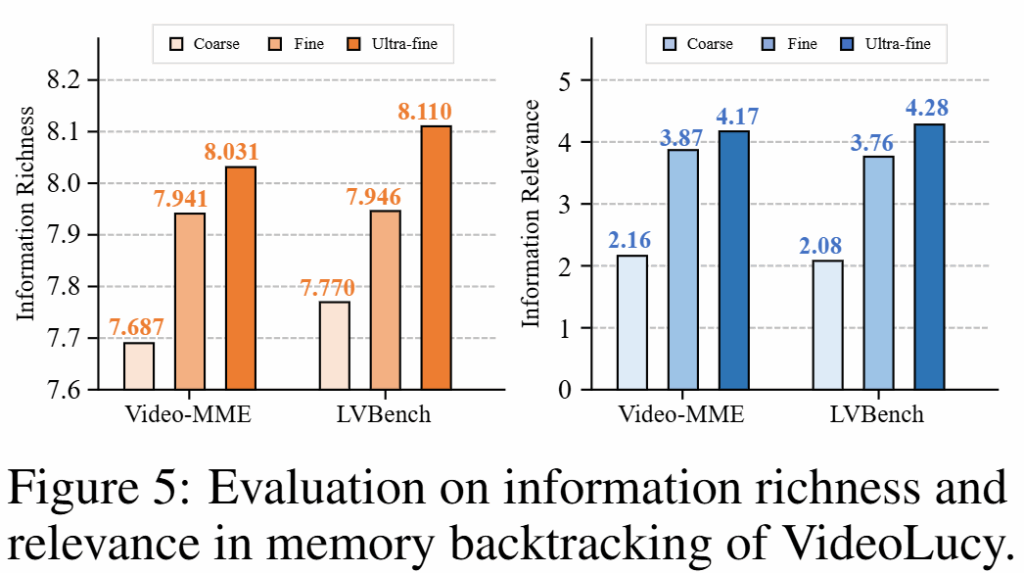
2) 메모리 구축방식의 효율
논문은 제안한 계층적 메모리 설계의 유효성을 검증하기 위해 Video-MME와 LVBench 벤치마크에 대한 추론 수행시 Course(k가 낮음), Fine, Ultra-fine(k가 높음) 역추적의 단계가 깊어질수록(k가 높아질수록) 변화하는 정보량을 Shannon entropy로 측정하여 리포팅했습니다. 그 결과는 Figure5와 같으며 세부 메모리로 전개될 수록 정보량이 증가함을 확인할 수 있습니다.
좋은 리뷰 감사합니다. 결국 핵심은 agent 기반으로 비디오 요약을 수행하되, frame 단위로 너무 local한 답변을 내놓는 기존 프레임워크들과 달리 클립을 나누는 정도를 multi-scale로 다르게 설정해 다양한 수준의 세부 정보를 다룰 수 있게 하였네요. 간단한 질문 남기도록 하겠습니다.
1. 파이프라인에서 instruction agent는 쿼리를 입력 받아 다음 실행에 대한 instruction을 생성하게 되는데, instruction이 정확히 무엇이고 어떤 역할을 하게 되나요? localization 이후 바로 캡셔닝을 수행하면 될 것 같은데 instruction을 생성하는 목적이 궁금합니다.
2. captioning agent는 비디오를 입력받아 텍스트를 출력하게 되는데, 구체적으로 어떻게 동작하는 모델인지 궁금합니다. 비디오 정보를 입력받아 어떻게 처리되어 자연어를 출력하게 되나요?
감사합니다.