안녕하세요 황찬미입니다!
오늘도 비디오 요약 관련 최신 논문을 살펴보려고 합니다!!
그럼 바로 리뷰 시작하겠습니다
[Intro]
비디오 요약 연구는 오래됐지만 두가지의 큰 장애물이 있습니다. 먼저 데이터가 너무 적다는 문제로 요약 모델을 제대로 학습하려면 원본 비디오가 많아야 하는데 기존 데이터셋(TVSum, SumMe(~50개 정도))은 비디오 개수가 턱없이 적습니다. 특히나 대형모델(LLM이나 VLM)을 사용하여 학습할때는 대형 모델을 안정적으로 파인튜닝 하기 어렵기 때문에 과적합의 위험이 증가합니다. 두번째로는 대부분의 영상 요약은 비디오 → 비디오의 형태만 있습니다. 즉, 영상 일부를 잘라서 짧게 만드는 형태 중심으로 보다 다양한 형태의 요약을 다루지 못하는 한계가 있습니다.
[제안하는 데이터셋 : Instruct-V2Xum]
YouTube에서 수집한 30,000개의 다양한 비디오로 구성된 크로스모달 비디오 요약 데이터셋이며, 영상 길이는 40초에서 940초까지 다양하게 포함됩니다.
요약본의 길이는 원본 비디오의 평균 16.39%(약 1/6 길이)로 생성됩니다.
각 요약 영상에는 특정 프레임 인덱스를 참조하여 생성된 텍스트 요약이 함께 제공됩니다.
데이터셋의 GT는 프레임 캡션 기반 텍스트 요약이며, 이 텍스트 요약에 포함된 프레임들을 비디오 요약 GT로 사용합니다.
[제안하는 프레임워크 : V2Xum-LLM]
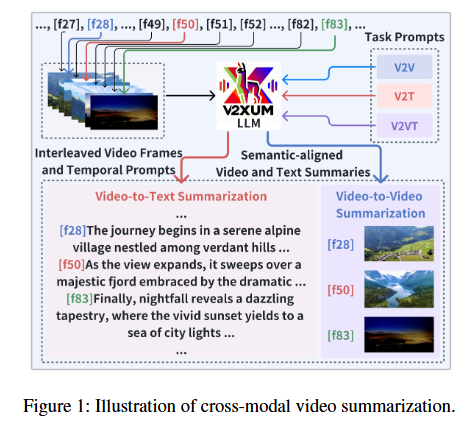
LM의 텍스트 디코더 하나로 서로 다른 요약 task(Video-to-Video, Video-to-Text, Video-and-Text Summarization)를 통합한 최초의 프레임워크로, temporal 프롬프트와 task 지시를 활용하여 요약 방식 자체를 제어합니다.
즉, 하나의 LLM 디코더에서 프롬프트만 바꿔 모든 요약을 수행할 수 있습니다.
학습 과정에서는 텍스트 요약에서 중요하다고 언급된 프레임들이 실제로 어떤 시각적 특징을 가지고 있는지, 그리고 그 특징이 왜 중요한지에 대한 패턴과 연관성을 학습하게 됩니다.
예를 들어 “강아지가 공을 물어오는 장면 [f120]”이라는 텍스트 요약을 학습한다면 모델은 f120 프레임의 시각적 요소들(강아지, 공, 특정 동작 등)이 해당 텍스트와 강하게 연결되어 요약에서 중요한 의미를 갖는다는 점을 이해하게 됩니다.
즉, 모델은 시간 정보와 언어적 의미 사이의 복합적 관계를 학습하여 텍스트가 부여한 중요도를 시각적 특징과 연동해 이해하게 됩니다.
또한 V2V 및 V2VT 요약 task를 위한 새로운 평가지표도 함께 제안합니다.
[The insturct-V2Xum Dataset]
제안하는 데이터셋(train 25,000개, val 1,000개, test 4,000개)
비디오 요약 방식은 추출적 텍스트 요약(extractive summarization)과 유사하게 텍스트 요약이 글에서 핵심 문장을 골라내듯이 비디오에서는 핵심 프레임을 뽑아냅니다.
데이터 큐레이션
- 영상 프레임 1 FPS로 추출하고 → 각 프레임에 대해 LLaVA-1.5-7B를 사용하여 상세한 캡션을 얻습니다 → 전체 프레임 캡션을 하나의 문서로 간주하여 GPT-4로 추출적 문서 요약(초기요약)을 수행하고 → 텍스트 요약과 동시에 추출된 프레임으로 비디오 요약도 함께 얻습니다 → 마지막으로 텍스트 요약은 GPT-4를 사용해서 초기요약을 한번 더 매끄럽게 다듬어줍니다.
최종 텍스트 요약 (Text Summarization Refinement)
- 텍스트 요약의 중복성을 줄이기 위해 BERTScore를 활용해서 서로 유사한 프레임의 텍스트 표현을 기준 임계값으로 걸러냅니다. (필터링된 프레임 캡션의 인덱스가 곧 비디오 요약이 됩니다.)
- 이후 GPT-4를 사용해 이 텍스트 요약을 더 압축하고 문법적으로 매끄럽게 다듬어 줍니다.
사람 검증(Human Verification)
- 위에서 설명한 GPT-4로 생성한 최종 요약 데이터를 사람이 직접 검수했습니다.
최종적으로 3만 개의 데이터셋을 구축했습니다.
[V2Xum-LLaMA]
제안하는 프레임워크(temporal prompt instruction tuning 프레임워크)
이 프레임워크는 서로 다른 형태의 요약(V2V, V2T, V2VT)을 하나의 LLM 디코더에서 통합하여 생성합니다.
기존 VLM 기반 모델들이 필요로 했던 task-specific head를 제거하여 사전에 훈련된 LLM/VLM 파라미터를 재사용할 수 있게 함으로써 데이터가 적은 상황에서도 fine-tuning이 가능해집니다.
또한 프레임을 단순히 이미지처럼 처리하는 것이 아니라 프레임 ID를 토큰화하여 프롬프트에 함께 넣기 때문에 LLM이 temporal 정보를 직접 이해할 수 있으며 어떤 프레임을 선택해야 하는지 등 세밀한 시간적 추론(dense temporal prediction) 이 가능해집니다.
즉 한마디로 말하자면 프레임 + 시간 토큰을 섞어서 LLaMA에 입력하고, 프롬프트로 요약 타입을 제어하면서 V2V / V2T / V2VT를 모두 한 번에 생성할 수 있는 LLM 기반 요약 프레임워크라고 할 수 있습니다.
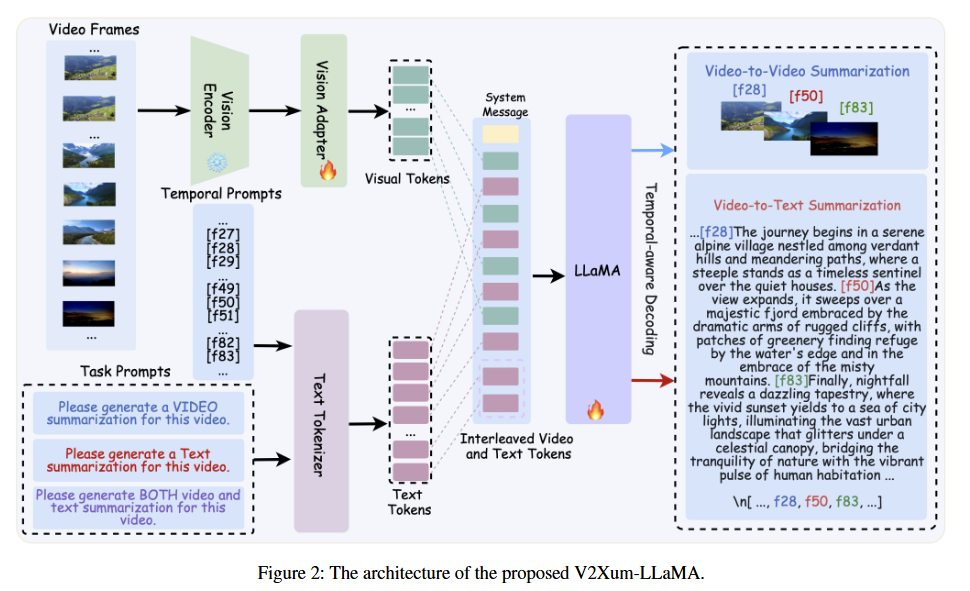
[입력 단계 (Interleaved Video and Temporal Prompt Encoding)]
- 각 비디오 프레임을 사전학습된 CLIP 인코더 EvE_vEv를 사용하여 비주얼 토큰 시퀀스 V={v1,v2,…,vL}를 얻습니다.
이후 각 비주얼 토큰에 대해 temporal prompt T={t1,t2,…,tL}를 결합합니다. 이 프롬프트는 “[f00], [f06], [f12]”와 같은 0으로 패딩된 숫자 형태의 자연어 토큰입니다. - Temporal prompt 토큰들은 비주얼 토큰 시퀀스 V 사이에 삽입되어 교차된(interleaved) 시퀀스 S={t1,v1,t2,v2,…,tL,vL}를 구성합니다. 이를 통해 타임스탬프와 시각적 의미(visual semantics) 간의 관계를 더 정확히 포착할 수 있게 됩니다.
- 이 시퀀스 S는 vision adapter를 거쳐 LLM의 단어 임베딩 공간으로 사영되며 사영된 시퀀스도 S로 표기합니다.
[디코딩 단계 (Temporal-Aware Decoding)]
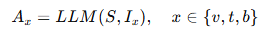
- 여기서 Av는 V2V 요약, At는 V2T 요약, Ab는 V2VT 요약이며
Iv,It,Ib는 각 요약 작업을 수행하기 위한 task instruction입니다. - Temporal prompt가 포함된 시퀀스 S와 task instruction Ix를 LLaMA와 같은 LLM 디코더에 입력하면 출력은 Ax로 정의되며 이를 temporal-aware decoding이라고 부릅니다.
조금 더 구체적으로 살펴보자면 !
- V2V 요약(Av) 은 temporal token([fXX])들로 구성된 프레임 인덱스 시퀀스입니다.
- V2T 요약(At) 은 자연어 문장 안에 temporal token이 함께 포함된 형태입니다.
(At={…,wi−1,tj,wi+1,wi+2,…})
여기서 t_j(시간 토큰)은 시각적 내용을 요약하는 단어나 문장과 연결되어 있으며 생성된 V2T 요약 A_t에서 이 t_j를 추출하면 V2V 요약(A_v) 을 다시 얻을 수 있습니다.
[학습 방식 (Task-Controllable Video Summarization Training)]
- 앞서 언급했듯이 요약의 종류는 task instruction Ix로 제어할 수 있습니다.
즉, “이 비디오에 대해 BOTH/VIDEO/TEXT 요약을 생성하라(Please generate a BOTH/VIDEO/TEXT summarization for this video.)”와 같은 task prompt를 사용해 모델이 그 task에 해당하는 형태로 요약을 생성하도록 지시합니다.
이후 모델은 일반적인 autoregressive LM과 동일하게 negative log-likelihood loss 를 사용하여 end-to-end 방식으로 학습됩니다 - 학습 시 vision encoder(CLIP) 의 파라미터는 freeze 되고 vision adapter + LLaMA 디코더 의 파라미터만 업데이트됩니다
[Experiments]
FCLIP & Cross-FCLIP
- 기존의 V2V평가지표(F1, Kendall, Spearman)는 주로 모델이 모든 비디오 프레임에 대해 importance score를 할당한다는 것을 전제로 하기 때문에 LLM이 출력한 Discrete한 프레임번호 목록이 평가지표들이 요구하는 입력 형태와의 근본적인 불일치가 있습니다.
따라서 Discrete한 LLM의 출력(요약)을 평가하는 새로운 평가방법으로 FCLIP과 Cross-FCLIP을 제안합니다.
FCLIP은 비디오 요약 끼리 semantic similarity 기반으로 시간적으로 조금 어긋나도 의미가 같으면 높은 점수를 주는 평가를 진행하고 Cross-FCLIP은 비디오 요약과 텍스트 요약 간의 semantic matching을 평가합니다.
[FCLIP]
기존의 F1 score의 형식을 그대로 가져와서 R_CLIP와 P_CLIP의 조화평균을 사용하여 semantic version으로 확장합니다.
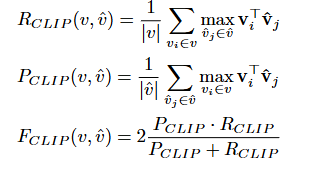
- R_CLIP (Recall) : GT의 각 프레임vi에 대해 예측 요약의 모든 프레임 vj 중 가장 의미가 비슷한 것을 찾는것으로 GT프레임이 예측 요약에서 얼마나 잘 커버되었는 가를 봅니다.
- P_CLIP (Precision) : 예측 요약의 각 프레임 vj에 대해 GT프레임들 중 가장 비슷한 것을 찾는 것으로 예측된 프레임들이 얼마나 GT에 의미적으로 근접한 지를 봅니다.
[Cross-FCLIP]
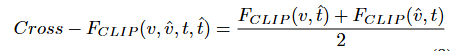
- “텍스트 요약이 비디오를 잘 설명하는가?”의 GT 비디오와 예측 텍스트 간의 FCLIP(v, t̂),
”비디오 요약이 텍스트 요약과 의미적으로 일치하는가?”의 예측 비디오와 GT 텍스트 간의 FCLIP(v̂, t)
이 두가지를 모두 계산해서 평균을 냅니다. 이 방식은 프레임 단위로 텍스트와 의미를 매칭하고 세밀한 구간까지 align을 평가함으로 멀티모달 정보가 서로 잘 맞는지 보다 정밀하게 판정할 수 있습니다.
[Baseline Models]
Baseline Models들을 비교군은 크게 3개의 그룹으로 나누어서 VideoXum 데이터셋으로 훈련과 추론을 진행했습니
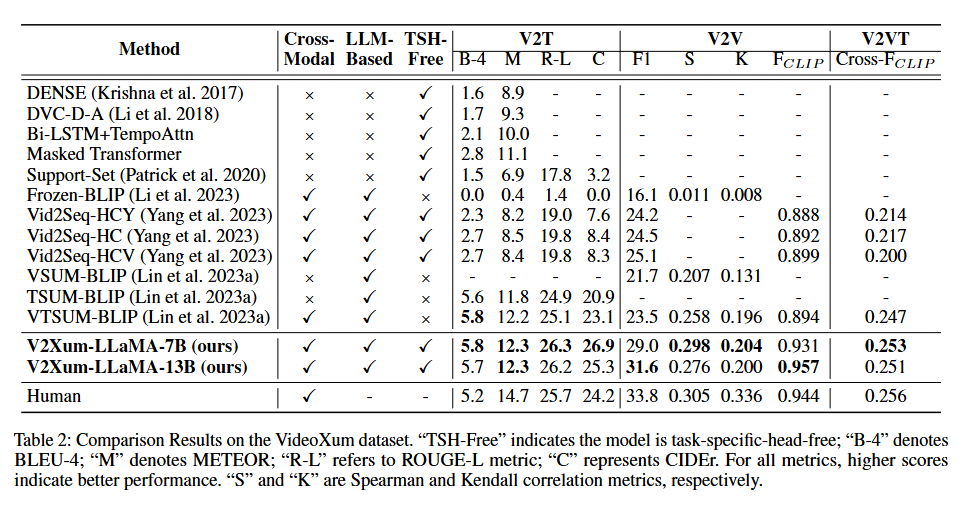
- LLM기반 BLIP계열
FrozenBLIP, VSUM-BLIP, TSUM-BLIP, VTSUM-BLIP으로 LLM 기반 크로스모달 요약에서 가장 강력한 SOTA 계열입니다.
- Task-Specific-Head-Free (TSH-Free)
Dense caption 기반과 Non-regression timestamp 방식으로 V2Xum-LLaMA처럼 head 없이 요약을 수행한다는 공통점을 가지고 있는 모델들입니다.
- 전통적 V2V 요약 모델(dppLSTM, DSN, Sumgraph)로 V2Xum-LLaMA가 비디오만 보는 요약에서도 강한지 평가했습니다.
결과적으로 V2Xum-LLaMA는 V2V, V2T, V2VT 모두 baseline들을 넘어섰고 특히 V2V의 F1 score, Spearman, Kendall 모두 대폭 향상했습니다. 즉, Temporal prompt + interleaving 구조가 정확한 temporal reasoning을 가능하게 했다는 근거가 됩니다.
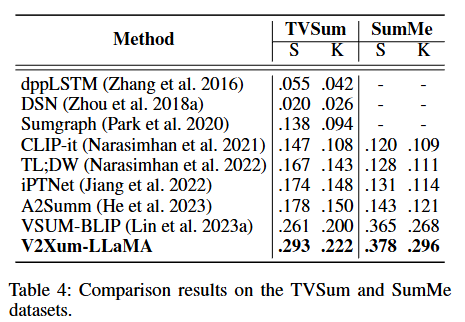
또한 TVSum과 SumMe에서도 최고의 성능을 보였습니다. 이 실험은 조금 흥미로운데, LLM 기반 모델이 전통적인 V2V 모델보다 더 강한 성능을 냈다는 것을 의미합니다. 이로써 LLM기반 요약이 비디오 요약에도 꽤 강력하게 통한다는것을 명확히 보여줍니다.
[Instruct-V2Xum 데이터셋]
저자들이 제안하는 Instruct-V2Xum 데이터셋으로 훈련 및 추론을 진행했습니다.
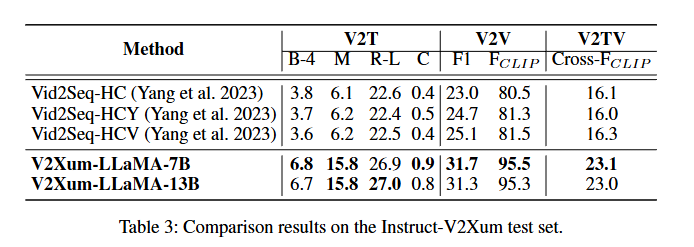
- 표3을 통해 모델들이 해당 데이터셋에 잘 적응되어 꽤 괜찮은 성능이 나타나는 것을 먼저 확인할 수 있고, 저자들이 제안한 모델이 전반적으로 성능이 뛰어난 것을 알수 있습니다.
추가적으로 V2Xum-LLaMA-13B가 V2T에서 성능이 뛰어난 이유는 더 큰 언어모델이기 때문에 증가된 훈련 데이터의 양으로 인한 이점을 얻었기 때문이라고 저자들은 말합니다.
[TVSum과 SumMe 데이터셋(기존 데이터)]
기존의 가장 많이 쓰이는 TVSum과 SumMe 데이터셋으로 훈련 및 추론을 진행했습니다.
[Limitations of Current Video Summarization & Conclusion]
현재의 비디오 요약은 데이터 부족과 옛날(?)방식의 모델 구조와 의미적 유사도를 반영하지 못하는 부정확한 평가지표 때문에 발전에 큰 제약이 있다고 저자들은 지적하며 이 세가지 문제를 근본적으로 해결하는 프레임 워크로 V2Xum-LLaMA + 새로운 평가 지표를 제안했습니다
저도 최근 비디오 요약 연구를 위해 여러 논문들을 읽어보게 됐는데, 대부분의 연구가 새로운 요약모델과 함께 자체 데이터셋을 제안하고 있지만 정작 그 데이터셋의 요약(GT)자체가 매우 주관적이라는 점이 계속 눈에 들어옵니다. 어떤 데이터셋은 텍스트 묘사의 밀도 같은것을 기준으로 삼고, 어떤 데이터셋은 특정 액션 이벤트를 중심으로 요약을 만들고, 또 어떤 데이터셋은 사용자의 선택을 기반으로 합니다. 즉, 무엇을 요약의 정답(GT)로 볼 것인지에 대한 보편적인 기준 자체가 존재하지 않습니다. 요약의 GT가 이렇게 약간 제각각이고 명확한 기준이라고 할만한 게 없다보니 자연스럽게 평가지표 또한 특정 데이터셋의 형테에만 맞춰져 있는게 아닌가.. 실제 좋은 요약을 제대로 평가하는게 맞는건가..? 하는 의문이 들기도 합니다..! 합의된 GT가 없고 그로 인해 객관적인 평가지표가 부재하다는 의문이 결국 이 비디오 요약의 근본적인 문제라고 개인적으로 생각되고 이 문제가 앞으로의 연구에서 어떻게 해결될 지 기대가 됩니다!
리뷰 읽어주셔서 감사합니다 😁😉