안녕하세요, 최근 비디오 생성모델을 통한 로봇 학습 데이터 증강 파이프라인에 관심을 가지고 있는데, Giga AI에서 며칠전 공개된 embodied AI 데이터용 비디오 생성 모델이 발표와 동시에 주목을 받고있고, 그 결과물이 제가 보기에는 충격적이었습니다. 다만 리소스도 많이 필요하고 정확히 어떻게 발전해서 해당 모델이 등장했는지를 보기 위해 관련 연구들을 분석해볼 예정입니다. 그런 면에서 video generation 모델을 통해 viewpoint augmentation을 시도한 논문을 리뷰해보도록 하겠습니다.
Introduction
모방 학습은 observation으로부터 제어 명령을 예측할 수 있는 visuomotor policy를 가능하게 만들었습니다. 그러나 이러한 정책은 viewpoint shift에 굉장히 민감하여, 하나의 고정된 egocentric viewpoint에서 학습한 경우 새로운 viewpoint에서 성능이 급격히 저하될 수 있습니다. 실제로 최신 VLA를 finetuning 해봤을 때도 해당 문제를 경험할 수 있었습니다. 기존 시점에서 잘 동작하던 정책도 로봇의 카메라가 뒤로 물러나거나 좌우로 회전되면 작업에 실패하는 경우가 대부분입니다. 이는 훈련 데이터의 시점 다양성 부족으로 인한 분포 차이 문제로, 실제 로봇 활용 시 큰 한계점으로 지적됩니다. 현재로써는 이러한 문제를 해결하기 위해 다양한 1인칭 각도의 데모 데이터를 확보하거나 생성해야 합니다.
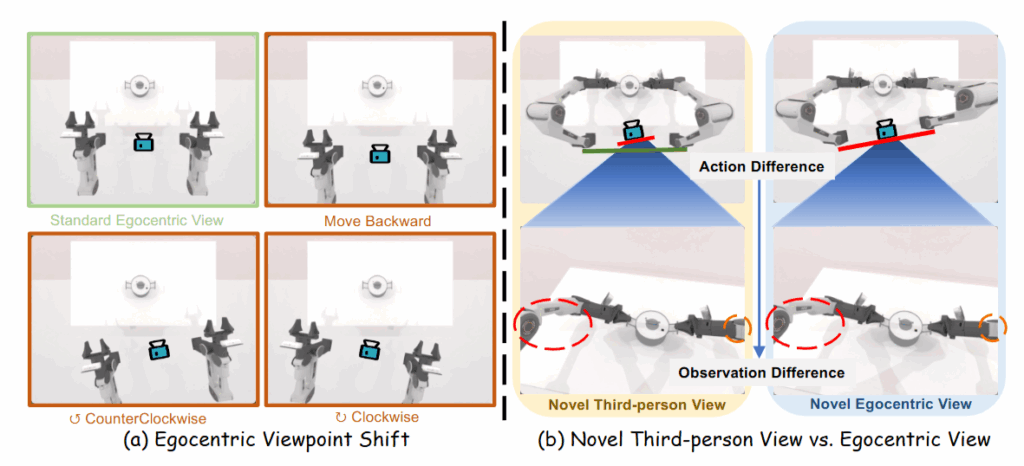
이 문제를 완화하려는 노력은 두 갈래로 진행되어 왔습니다. 우선 시점 변환을 위해 3D pointcloud 렌더링이나 3D reconstruction, 이미지 생성 모델등을 활용하여 새로운 관점의 영상을 합성하는 접근이 있습니다. 하지만 이러한 방법들은 행동에 대한 변화 없이 시각 정보만 변경하기 때문에 큰 시점 변화를 겪을 때 화면에 보이는 영상과 로봇의 행동 간 불일치가 발생합니다. 즉, 로봇 팔의 움직임은 원래 카메라 기준인데 영상은 다른 각도이므로, figure (a)와같이 로봇이 움직이면 (로봇의 1인칭 시점이 움직이면) 다른 view가 나오게 되고, 1인칭 시점 영상에서 확인해보면 figure1의 b와 같이 같은 자세를 했을 때 로봇이 보이는 정도가 다른것을 볼 수 있습니다. (차이가 크진 않지만 저정도의 차이로도 성능 드랍이 생깁니다)
다른 방향으로는 월드 모델이나 비디오 생성 모델을 통해 새로운 데이터 자체를 예측하는 접근도 있었습니다. 그러나 이러한 접근들은 모방학습에 필요한 state-action pair 데이터를 직접 생성하지 않고, 로봇 움직임에 따른 카메라 이동 같은 1인칭 시점 변화의 영향을 명시적으로 다루지 못했습니다. 결국 새로운 시점의 데모를 생성하려면 시각적 관찰과 그에 맞는 로봇 행동을 일치시켜 만들어내는 별도의 방안이 필요합니다. 최근 Inverse Dynamics Model들이 해당 역할을 하려고 연구되고 있으나 최근 CoRL에 갔을때 들은 말에 의하면 아직은 실제 데이터 생성 파이프라인에 적용하기에는 여러 한계들이 있다고 합니다.
따라서 저자들은 새로운 egocentric 데모를 생성하려면 현실감 있는 새로운 시점 영상 합성과 함께, 그 시점에 맞게 action을 retargeting해야 한다는 점을 주요 문제로 삼았습니다. 이를 위해 저자들은 두 가지 핵심 요소를 제안했습니다. 새로운 시점에서 유의미한 로봇 동작 시퀀스를 만드는 것과 그 동작에 일치하는 현실감 있는 영상 시퀀스를 생성하는 것입니다.
저자들은 시뮬레이션 환경을 사용해 위 두가지 핵심 요소를 한 번에 해결하는 EgoDemoGen이라는 프레임워크를 제안했습니다. EgoDemoGen은 원본 데모에서 변화되는 RT를 기준으로 그 관점에서 state-action pair 데이터를 생성합니다. 이를 위해 Action Retargeting 모듈을 통해 새로운 시점에 맞게 kinematically feasible한 trajectory를 얻습니다. 다음으로 저자들이 제안한 EgoViewTransfer라는 video generation 모델을 활용하여 해당 trajectory에 맞는 영상을 생성합니다.
저자들은 EgoDemoGen을 통해 생성된 합성 데이터를 기존의 데이터와 함께 학습시켰을때 새로운 viewpoint에 대한 일반화 성능이 크게 향상 되었다고 합니다. RoboTwin2.0 시뮬레이션 환경에서 한 가지 시점만으로 학습한 policy 대비 원래의 viewpoint에서 성공률은 약 17%, 새로운 viewpoint에서의 성공률은 약 17.7% 향상되었고 , real world에서도 18.3, 25.8%의 향상을 보였다고 합니다. 여러 시점으로 학습 했을 때 한가지 시점으로 학습했을 떄보다 그 시점에서도 성능이 향상된다는것 또한 포인트인것 같습니다. 또한 생성된 다른 시점에서의 데이터를 늘릴수록 성능이 계속 증가하였다고 합니다.
Related Works
기존의 Imitation Learning을 위한 data generation 파이프라인에 대한 간략한 정리만 하고 넘어가도록 하겠습니다. 기존에는 아래와 같이 크게 세가지 접근으로 나뉘어집니다. 먼저 기하학적인 접근입니다. 주로 RGB-D를 통해 3D reconstruction을 진행해 같은 행동을 하는 데이터셋을 다른 시점에서 NVS해가며 변환하는 방식이 있었다고 합니다. 다만 이는 정확하지 않은 복원 때문에 vision-action mismatch가 심했다고 합니다. 다음으로는 생성형 모델 기반으로 영상 자체를 생성하는 것입니다. Video diffusion 모델들을 통해 원본 영상을 condition으로 받는 새로운 데이터를 합성하는 방식입니다. 다만 이는 앞서 말했듯 이에 맞는 action 데이터를 같이 생성하지 못하는 한계가 있습니다. 기존 motion retargeting 기술들로는 고정된 시점에서의 trajectory 변화는 가능하지만, 새로운 시점에서 변화된 trajectory를 다루지 못하는 한계가 있어 여전히 어려움을 겪고 있습니다.
Video diffusion의 로봇 러닝쪽 활용에 대해서 조금 더 이야기를 하자면 비디오 생성 모델 자체를 policy로 사용하는 접근도 있었다고 합니다. 어떠한 장면을 보고 task를 수행할 때 생성된 비디오에 대한 action을 디코딩하는 방식으로 작동합니다. 아니면 action trajectory를 컨디션으로 받아 미래를 예측하는 world model을 사용해서 action을 먼저 변환시키고 그에 해당하는 영상을 취득해 데이터를 만들어 학습시킨 policy를 활용했습니다. 다만 이 두 방법 모두 고정된 viewpoint에 대한 생성만 잘 해냈기 떄문에 근본적으로 view point에 대한 강인성을 향상시키기에는 한계가 있었다고 합니다.
이런 관점에서 저자들의 연구는 새로운 viewpoint에서의 state-action pair 쌍을 직접 예측하도록 구성돼있어 새로운 시점에서의 영상과 해당 영상에 맞게 retargeting된 데이터를 생성할 수 있고, 결과적으로 novel viewpoint에서의 성능 향상을 위한 유의미한 데이터 확장 파이프라인으로 사용할 수 있다고 합니다.
Method
Method
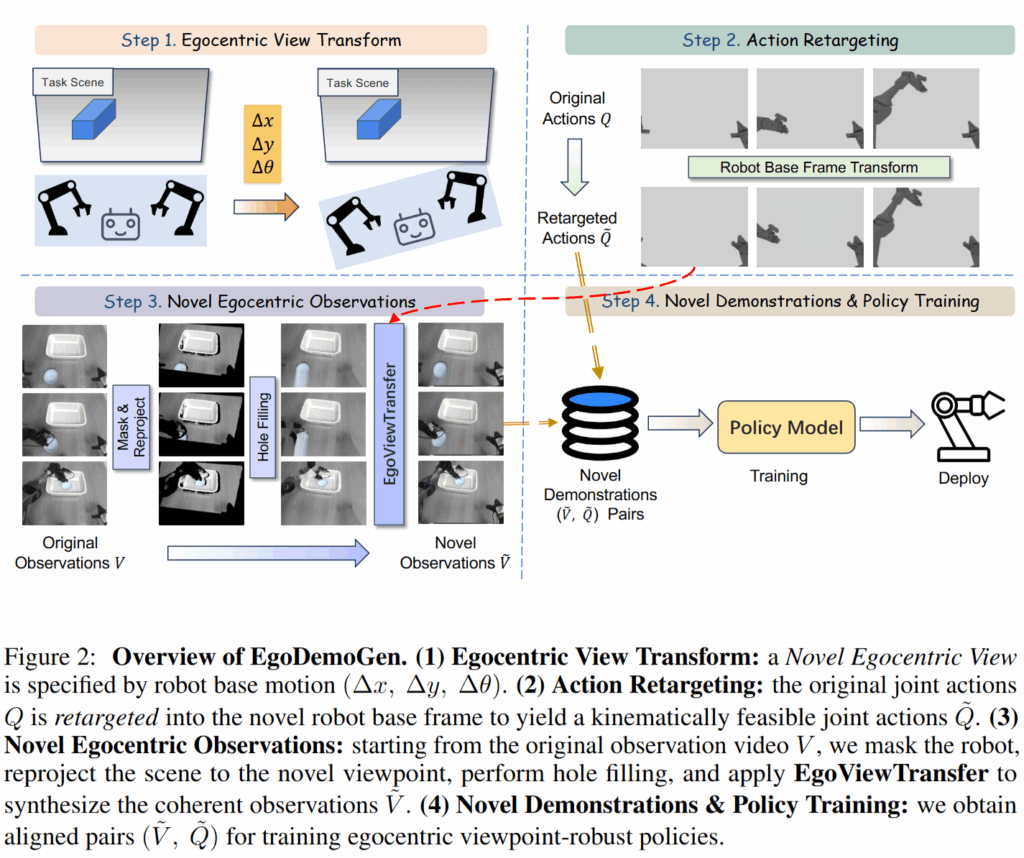
다시 정리를 하자면 EgoDemoGen은 특정 1인칭 시점에서 수집된 로봇 데모를 기준으로 novel egocentric viewpoint에대한 새로운 데모 (state, action)를 생성합니다. 이 때 새로운 시점은 로봇 베이스의 RT로 정의됩니다. 로봇이 다른 위치/방향에 있는 상황을 가정한다고 생각하면 편하게 이해될 것 같습니다.프레임워크는 크게 아래와 같이 진행됩니다
- Egocentric View Transform: 먼저 figure2의 (1)과 같이 새로운 1인칭 시점을 정의하는 로봇 베이스의 변환을 지정합니다.
- Action Retargeting: 이후 (2)와 같이 원본 데모의 동작 시퀀스를 새로운 로봇 베이스 프레임에 맞게 retargeting 하여 새로운 동작 시퀀스를 얻어줍니다. 로봇의 동작 영상은 시뮬레이터에 변환된 action을 rollout 하거나 URDF를 통해 얻어줍니다. 데모에서는 시뮬레이션을 활용했습니다.
- Novel Egocentric Observations: (3)과 같이 기준이 되는 특정 데모의 영상으로부터 로봇을 제외한 novel observation을 구해 (2)의 결과물과 함께 EgoViewTransfer을 통해 새로운 시점의 영상을 합성합니다.
- Novel Demonstration & Policy Training: 최종적으로 (4)와 같이 새로운 viewpoint에 대한 state-action 데이터를 얻습니다. 이를 기존 데이터와 함께 학습해 다양한 시점에 대한 일반화 능력을 갖추게 됩니다
한마디로 배경 영상과 로봇이 움직이는 novel view 영상을 따로따로 생성해서 합치는 식으로 데이터를 생성한다고 보시면 될 것 같습니다. 아래 예시가 직관적이라 가져왔습니다. 각각 시뮬레이션 데이터와 real world데이터를 기준으로 왼쪽부터 원본, novel 배경영상, novel 로봇영상, 합쳐진 새로운 영상이라고 보시면 됩니다.


Action Retargeting
Action Retargeting 과정에서는 원본 데모의 action sequence를 입력받아 지정된 새로운 로봇 베이스 frame에서 동일 작업을 수행할 수 있는 기구학적으로 유효한 새로운 action sequence를 계산하는 것입니다. Retargeting 부분은 기존의 trajectory 기반 augmentation 방법론들과 유사합니다.
먼저 원본 베이스 좌표계에서 주어진 관절 각도로부터 forward kinewatics를 사용해 end effector의 pose를 계산합니다. 이후 기존 로봇 좌표계와 새로운 로봇 좌표계 간의 변환관계를 ee trajectory의 각 pose에 적용해줍니다. 다시말해 ‘로봇이 새로운 view point에서는 어떻게 이 작업을 수행할까?’에 대한 trajectory를 얻는다고 보시면 될 것 같습니다. 다만 이 때 trajectory를 IK를활용해 다시 새롭게 얻은 ee pose를 joint state로 변환해 이후 파이프라인에 활용합니다. 이 과정이 큰 범위의 novel viewpoint에서의 유효한 데이터 생성에 큰 영향을 미친다고 합니다. 이 joint대로 시뮬레이터 상에서 로봇을 움직이며 로봇의 움직임을 취득합니다.
Novel Egocentric Observation Generation
Action Retargeting을 통해 새로운 action sequence를 얻은 후에는 이에 맞는 observation을 생성해야 합니다. 이 때의 observation 영상은 로봇이 새로운 위치에서 동일 작업을 수행할 때 로봇 1인칭 카메라에 보이는 로봇을 제외한 장면을 RGB-D로부터 얻은 pointclould를 활용해 구합니다. 해당 과정은 아래와 같이 이루어집니다.


간단히 설명하자면 우선 위 algorithm 2와 같이 로봇이 masking된 배경만 보이는 영상과 로봇만 움직이는 영상을 취득합니다. 이후 원본의 observation (RGB-D) 에서 로봇을 masking하고 배경만 남긴 영상을 pointcloud를 활용해 새로운 시점으로 Algorithm 3와 같이 투영합니다. 이렇게 얻은 scene에는 문제가 있는데, 원본 시점에서 보이지 않았던 영역이 투영 시 구멍으로 변하게 됩니다. 예를 들어, 원래 로봇의 시야에 가려져 보이지 않았던 물체 뒷면 등이 새로운 각도에서는 드러날 수 있지만, 원본 영상에는 정보가 없으므로 구멍으로 표시됩니다. 이러한 영역에 대해 inpainting모델을 통해 구멍을 채워준다고 합니다. 배경과 로봇의 영상을 따로 얻은 뒤에는 이를 바탕으로 EgoViewTransfer 모델을 통해 두 영상을 input으로 받아 video diffusion을 진행합니다.
EgoViewTransfer

EgoViewTransfer 모델은 앞서 말했듯 scene video와 robot video를 input으로 해서 새로운 영상을 합성하는데, 이는 Trajectory Crafter라는 모델의 double reprojection이라는 방식을 사용해 로봇의 egocentric 데이터셋으로 self supervised 방식의 finetuning을 진행했다고 합니다. CogVideoX-5b-I2V 모델에 finetuning 했습니다.
Experiments
실험은 Mobile Aloha로 real world와 simulation(robotwin 2.0)에서 진행되었습니다. Lift pot, Mic 반대손으로 넘겨주기, 병 흔들기의 task로 진행됐고, 카메라 시점은 로봇 좌표계 중심을 기준으로 가로세로 20cm, 각도 [-10,10] 범위에서 평가했다고 합니다. 어떻게 보면 정말 크지 않은 차이인데, 현재 visuomotor policy가 viewpoint에 얼마나 민감한지와 video generation 모델의 한계를 보여주는 대목이 아닌가 싶습니다. 시뮬레이션에서는 ACT를 학습시키고, real robot에서는 pi zero를 학습시켜서 평가했습니다. Baseline으로는 고정된 기본 시점에서의 데모 50개를 사용한 영상과 100개의 시뮬레이션 데모로 학습한 모델을 사용했다고 합니다.

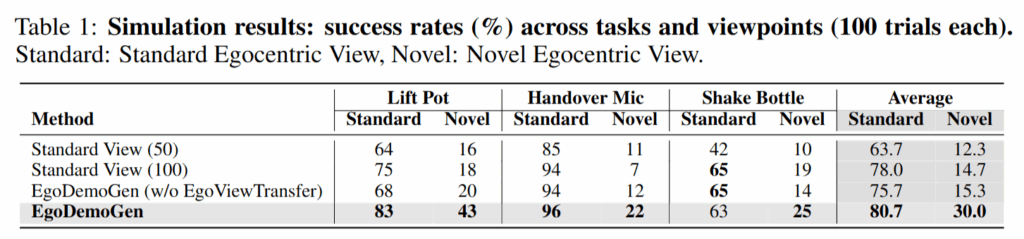
결과는 아래와 같습니다. 시뮬레이션에서의 실험 결과는 아래 Table 1과 같이 Lift Pot, Handover Mic, Shake Bottle에서 novel viewpoint 성능이 향상되었습니다. 표준 데모만으로 학습한 policy대비 15%의 성능 향상이 있었습니다. EgoViewTransfer 없이 장면과 로봇 표현을 단순히 합성한 naive merge 방식에서는 거의 성능 향상을 만들지 못했습니다. 또 흥미로운 점은 Standard View 성능도 감소하지 않고 오히려 소폭 향상된다는 점 입니다. 여러 viewpoint로 다양한 데이터를 구성해 학습하는게 여러모로 좋은 것 같습니다.
Real world에서는 Table 2와 같이 Pick Bowl, Pick-and-Place in Basket, Pick-and-Place on Plate에 대해 세 개의 시점(Standard, CCW, CW)에서 각각 20회를 평가했으며, novel view는 CCW와 CW의 평균으로 계산했습니다. CCW, CW는 반시계방향, 시계방향을 의미합니다. 역시 novel viewpoint 에서의 성능이 증가하였습니다.
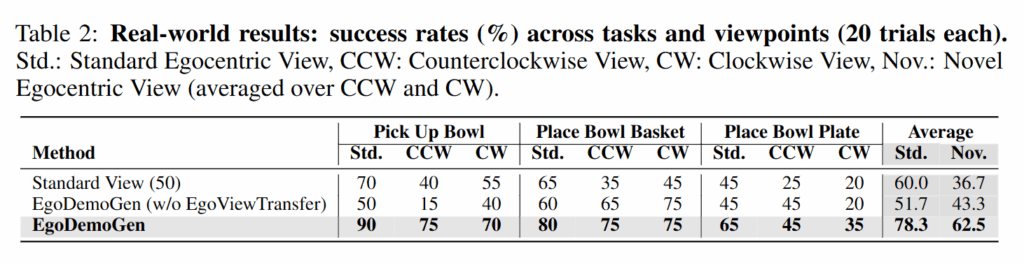
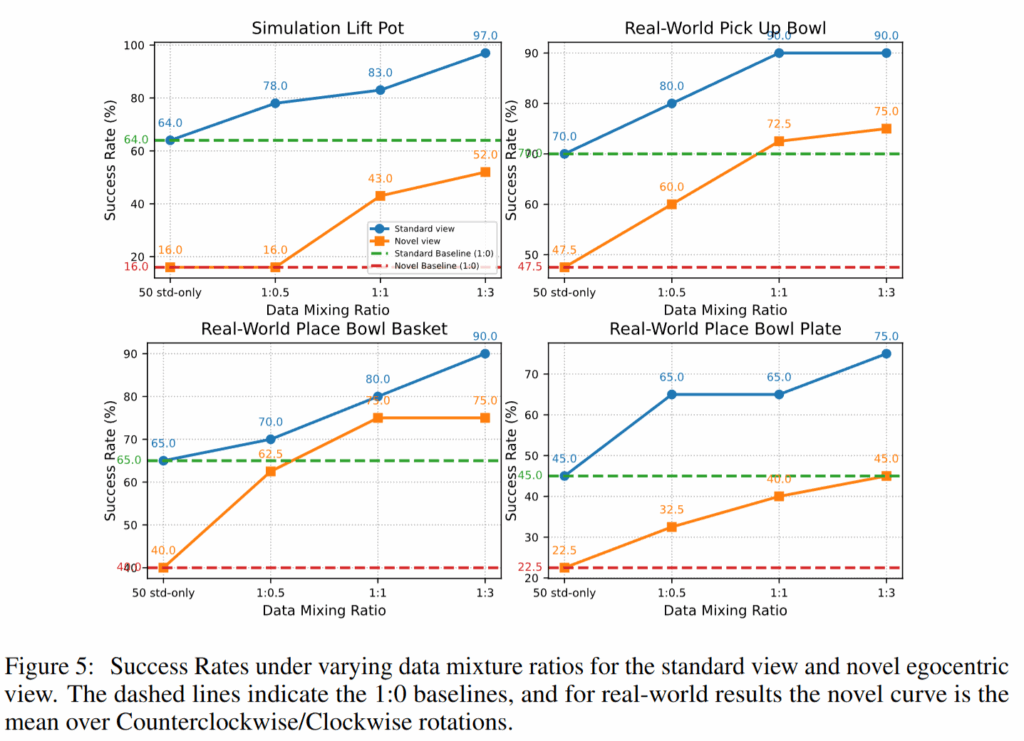
Figure 5는 Standard 데모와 EgoDemoGen으로 생성된 데모를 어떤 비율로 섞어 학습할 때 가장 효율적인지를 보여주는 분석입니다. 표준 데모만 사용하는 설정(1:0)에서 출발해, EgoDemoGen 데이터를 0.5배, 1배, 3배 비율로 바꿔가며 실험한 결과 표준 시점과 새로운 시점 모두에서 성공률이 꾸준히 증가했고 1:1 비율로 섞었을 때 성능이 가장 좋았습니다. 너무 과도하게 많은 시점 증강 데이터가 필요하지는 않을 것 같습니다.
아래는 정성적 결과입니다. 단순하게 얻어진 두 비디오를 합성했을때 보다 현실같은 모습을 보여줍니다. Blur된 부분도 없고, 로봇도 확실히 현실적인 모습입니다. 다만 이 결과를 놓고 봤을때 시뮬레이션에 굳이 배경을 올려야 하나?와 더불어 더 다양한 범위에서 viewpoint증강을 하려면 필요할수도 있나?의 고민이 시작됐습니다.
