RAG 과정에서 텍스트와 이미지의 연관성을 어떻게 다루고 있는지 얘기하던 중, 졸업생 이광진 연구원이 DeepSeek-OCR이라는 텍스트를 비전으로 압축(?)한다는 개념을 소개해줘서 DeepSeek-OCR 논문을 읽게 되었습니다
- Conference: Arxiv 2025
- Authors: Haoran Wei, Yaofeng Sun, Yukun Li
- Affiliation: DeepSeek-AI
- Title: DeepSeek-OCR: Contexts Optical Compression
1. Background & Motivation
최근 LLM은 입력 토큰 길이가 길어질수록 연산량이 기하급수적으로 증가하기 때문에, PDF나 논문처럼 수천 개의 토큰을 포함한 문서를 처리하는 데 한계가 있습니다. 반면 동일한 문서라도 텍스트 대신 이미지를 입력하면 훨씬 적은 수의 시각 토큰만으로 동일한 정보를 압축해 표현할 수 있기 때문에, Vision을 텍스트 압축의 매개체(?)로 활용할 가능성이 주목받고 있습니다. 즉, 이미지는 장문 입력을 줄인 LLM의 long-context 문제를 완화할 수 있는 대안으로 사용하려는 시도가 생긴 것이죠
하지만 기존 OCR 및 VLM 연구들은 주로 문자, 표, 수식 등을 얼마나 정확하게 인식할 수 있는지에 초점을 맞춰왔지, 문서 한 장을 복원하는 데 실제로 몇 개의 비전 토큰이 필요한가? 와 같은 근본적인 질문을 다루지 않았습니다. 긴 텍스트를 효과적으로 처리하기 위해 중요한 것은 단순히 인식 정확도가 아니라, 정보를 얼마나 적은 토큰으로 전달하면서도 원문의 의미를 손실 없이 재구성할 수 있는가라는 점입니다. 따라서 이러한 관점에서 OCR은 단순한 텍스트 인식이 아니라, 시각 기반 텍스트 압축의 상한과 가능성까지 검증할 수 있는 분야라고 할 수 있는 거죠
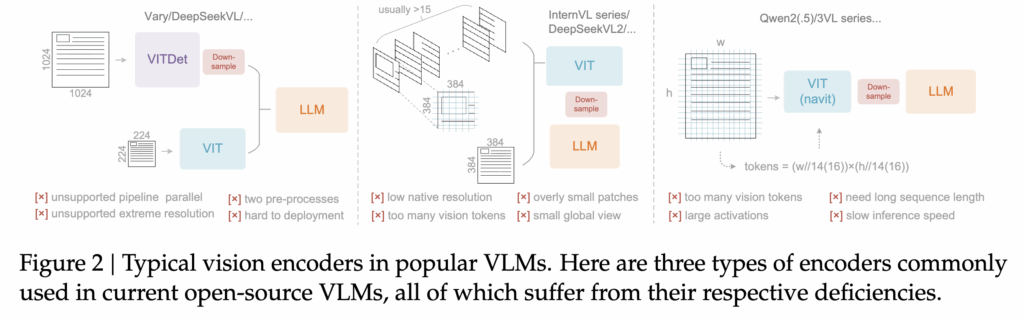
기존 VLM에서 사용되는 비전 인코더들은 이 목적을 달성하기에 적합하지 않다는 점도 저자들이 제시했는데요. 상단 그림 2에서 확인할 수 있듯이, Vary·DeepSeekVL 계열 모델은 극단적 고해상도를 지원하지 못해 문서 입력에 한계가 있고, InternVL 계열 모델은 작은 패치를 지나치게 많이 생성해 비전 토큰 수가 과도하게 증가하며, Qwen 계열 모델은 긴 시퀀스를 요구해 추론 속도가 크게 저하됩니다. 즉 현재 널리 사용되는 비전 인코더들은 모두 장문 문서를 적은 토큰으로 표현한다는 목표와 정합성이 부족하기 때문에, 구조적으로 새로운 방법론이 필요한 상황이죠 .
2. Contribution
이러한 문제를 해결하기 위해 저자들은 고해상도 입력에서도 활성 메모리를 낮게 유지하면서 비전 토큰 수를 강하게 압축할 수 있는 DeepEncoder를 설계했습니다. DeepEncoder는 Local Perception Module (LPM)과 Global Perception Module (GPM)을 직렬로 연결하고, 그 사이에 16× Token Compression Module을 배치하여 고해상도 문서를 처리하더라도 최종적으로 매우 적은 수의 비전 토큰만 생성되도록 구성한 점이 핵심입니다. 또한 생성된 압축 시각 표현을 MoE-based LLM Decoder가 텍스트로 복원하도록 학습함으로써, 단순 OCR 성능이 아니라 시각 압축과 텍스트 복원 간의 비선형 매핑을 모델 자체가 습득하도록 유도했다고 하네요.
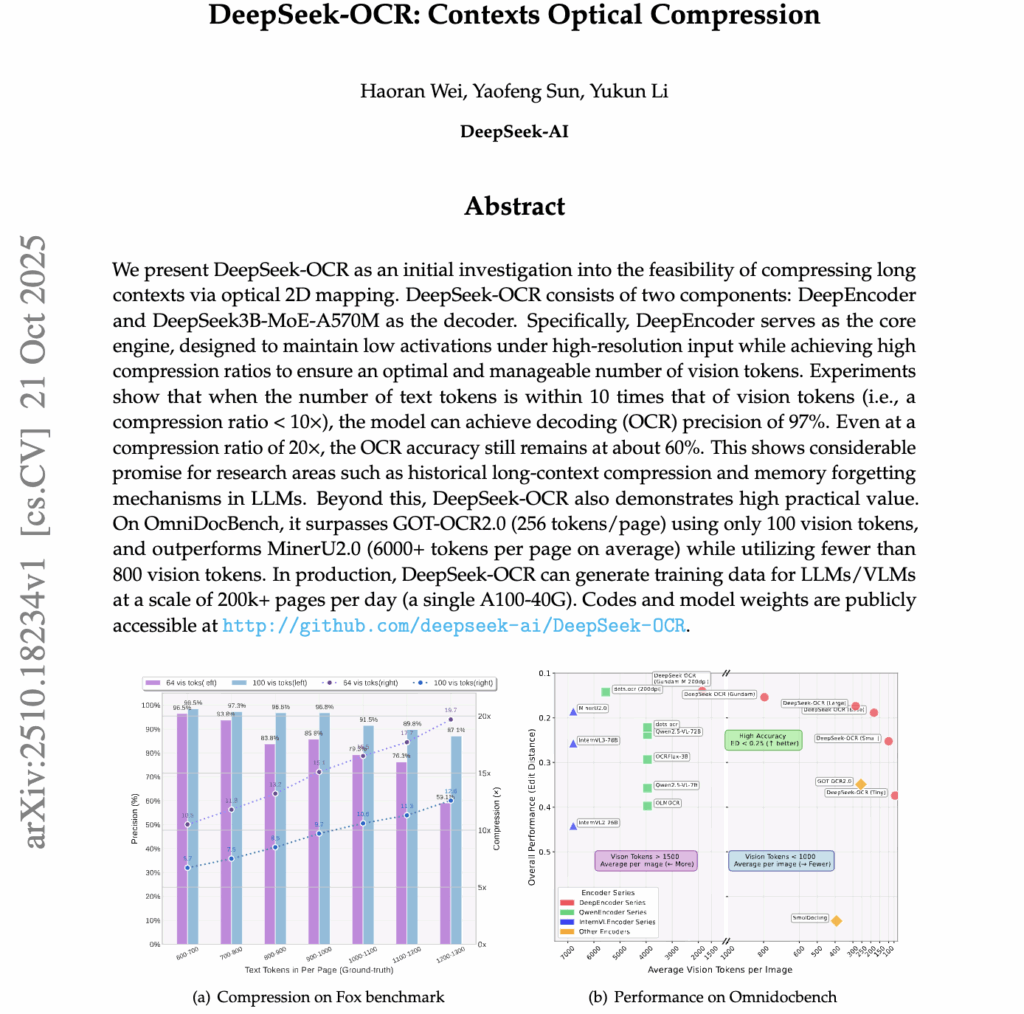
그 결과 DeepSeek-OCR은 OCR 정확도 향상뿐 아니라 압축 비율과 복원 가능성의 관계를 정량적으로 제시했다는 점이 인상깊네요. 예를 들어 Fox 벤치마크에서 텍스트 토큰 대비 9–10배 적은 비전 토큰으로도 약 96%의 정확도를 유지하며, 20배 이상 압축했을 때도 약 60% 수준의 복원이 가능함을 보여주었습니다. 본격적인 설명 시작하겠습니다.
3. Method
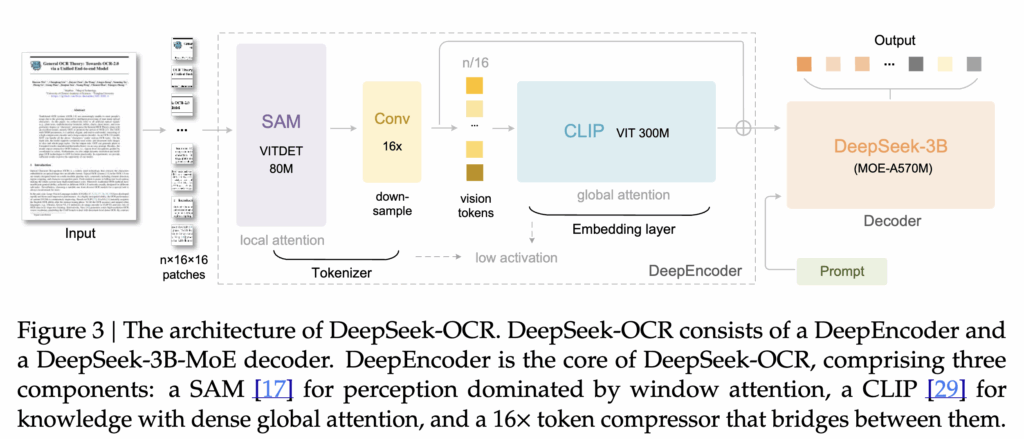
DeepSeek-OCR의 전체 구조는 문서를 비전 토큰으로 강하게 압축하고, 이를 다시 텍스트로 복원하는 과정 으로 구성되어 있습니다. 상단 그림 3에서도 확인할 수 있듯이, 모델은 먼저 입력 문서를 DeepEncoder에 투입해 고해상도 이미지를 매우 적은 수의 비전 토큰으로 변환합니다. 이후 생성된 압축 토큰들이 MoE-based LLM Decoder에 전달되며 텍스트 형태로 복원되는 방식으로 End-to-End 학습이 이뤄집니다. 이제 각 파트별로 자세하게 설명해보겠습니다.
3.1 DeepEncoder
DeepEncoder는 고해상도 문서를 처리할 수 있으면서도 적은 수의 비전 토큰을 유지한다는 목표로 설계된 비전 인코더입니다. 저자들은 기존 공개 모델들이 고해상도 입력, 활성 메모리, 토큰 수, 다양한 해상도 지원을 동시에 충족하지 못한다는 점을 보완하기 위해, 새로운 인코더 구조를 직접 설계했다고 합니다.
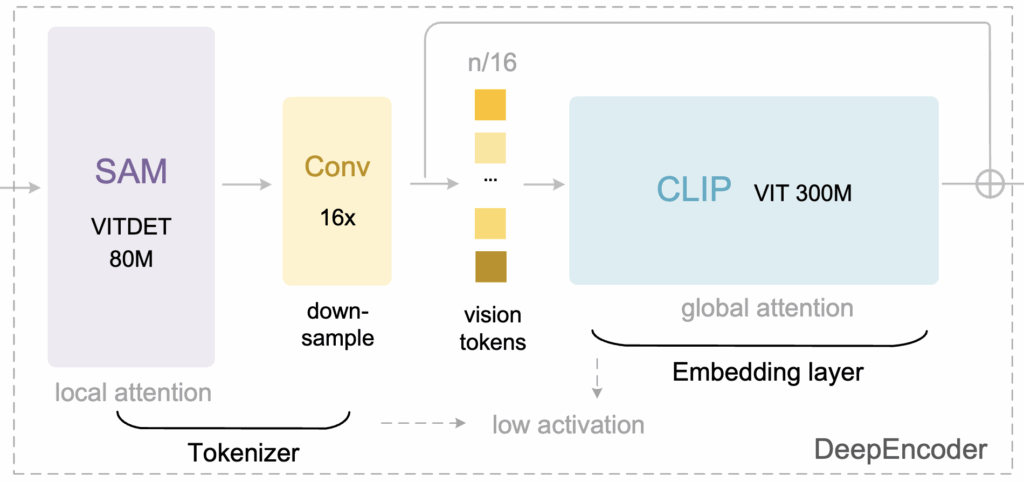
DeepEncoder는 크게 두 개의 컴포넌트로 구성되는데, 하나는 Local Perception Module (LPM)로 문서의 지역적 시각 특징을 추출하는 역할을 하고, 다른 하나는 Global Perception Module (GPM)로 문단 구조나 레이아웃 같은 문서 전역 정보를 해석하는 역할을 합니다. 이 두 모듈을 직렬로 연결하여 로컬 세부 정보 → 전역 맥락 순으로 처리하도록 설계된 것이 특징입니다.
두 모듈 사이에 존재하는 16× Token Compression Module이 DeepEncoder의 핵심 부분으로, 1024×1024 입력을 처리하더라도 생성되는 비전 토큰이 4096개로 폭증하지 않고 256개 정도로 줄어들도록 합니다. 즉, 문서 전체를 보면서도 토큰 수는 일정 수치 이하로 제한되어야 한다는 목표를 충족시키는 모듈이라고 볼 수 있습니다. 이러한 구조 덕분에 고해상도 입력을 사용해도 활성 메모리가 과도하게 증가하지 않아 실용적인 추론 비용을 유지할 수 있었다고 합니다
3.2 Multiple Resolution Support
DeepEncoder는 하나의 특정 입력 해상도만 처리하는 것이 아니라, 다양한 크기의 문서를 효율적으로 처리할 수 있도록 다중 해상도 입력을 지원합니다. 저자들은 특히 단일 모델이 토큰 수가 서로 다른 입력을 모두 다룰 수 있어야, 비전 기반 컨텍스트 압축의 한계를 실험적으로 분석할 수 있다고 강조했죠.

그림 4를 보면 DeepEncoder가 지원하는 입력 모드들이 시각적으로 정리되어 있는데, 크게 Native Resolution Mode와 Dynamic Resolution Mode의 두 가지 계열로 구성됩니다. Native Mode는 Tiny, Small, Base, Large로 구분되며 각각 64, 100, 256, 400개의 비전 토큰을 생성하도록 설계되어 있어 입력 크기에 비례해 토큰 수가 증가하도록 조정됩니다.
Dynamic Resolution Mode는 초고해상도 문서(예: 신문, 스캔본, 도해가 많은 보고서)를 처리하기 위한 방식으로 설계되었습니다. 이 모드에서는 이미지가 여러 타일(local views)과 global view로 분할되어 입력되며, tile 수에 따라 최종 토큰 수가 조절됩니다. Dynamic Resolution Mode는 초고해상도 문서에서도 활성 메모리를 억제하면서 필요한 정보만 유지할 수 있는 장점이 있어 실용적 평가에 적합하다고 하네요.
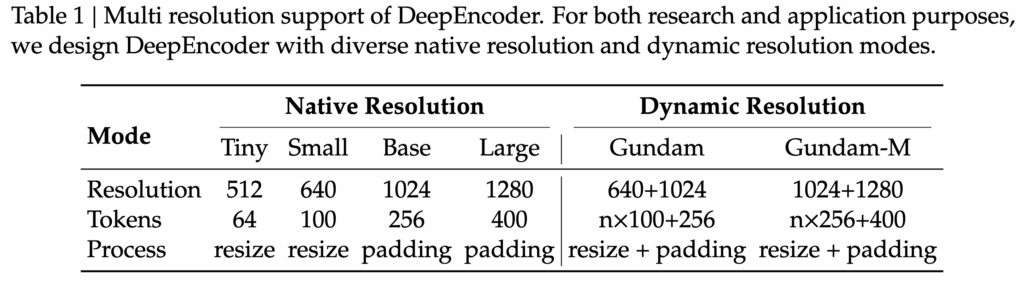
테이블 1에서 각 모드와 설정에 따른 토큰 수가 실제 수치 즉, 입력 해상도·타일 개수·토큰 수 사이의 관계를 확인할 수 있습니다. 예를 들어 Native Base 모드는 1024×1024 입력에서 256개의 토큰을 생성하며, Dynamic Gundam 모드는 타일 수(n)에 따라 n×100+256 형태로 토큰 수가 선형 증가하는 구조를 가집니다. 이러한 설계 덕분에 모델은 다양한 문서 형식과 정보 밀도를 하나의 단일 모델로 처리할 수 있게 됩니다.
3.3. The MoE Decoder
압축된 비전 토큰을 텍스트로 복원하는 단계에서는 DeepSeek-3B-MoE 기반의 디코더가 사용됩니다. 이 디코더는 64개의 전문가(Experts) 중 6개를 선택적으로 활성화하는 Sparse MoE 구조를 따르며, 표현력은 30억(3B) 파라미터 모델 수준이지만 실제 추론 시 활성 파라미터는 약 5억 수준으로 유지된다는 점이 특징이죠.
모델은 DeepEncoder가 생성한 압축 토큰을 입력받아 원래 문서를 구성했던 텍스트 표현을 복원하는 역할을 수행합니다. 여기서 디코더는 단순한 linear decoding이 아니라, 시각적 latent와 언어적 맥락 사이의 비선형 매핑을 학습하도록 설계되어 있어 시각 기반 압축 → 자연어 복원의 연결성을 모델 자체가 습득하게 됩니다. 즉, 유실된 정보 없이 문장을 되살리는 능력을 LLM이 OCR 학습 과정 속에서 자연스럽게 흡수하는 셈이죠.
결과적으로 저자들은 이러한 MoE 기반 LLM이 일반적인 언어 모델보다 OCR에 특화된 사전학습을 수행할 경우, 비전 토큰을 언어적 구조로 재해석하는 데 더욱 자연스러운 통합 능력을 보인다고 합니다.
3.4 Data Engine
DeepSeek-OCR의 성능은 모델 구조뿐 아니라 학습 데이터에도 영향을 받았다고 하는데요. 저자들은 단순 문자 인식만을 위한 데이터가 아니라, 문서·도표·수식·도형·자연 이미지·텍스트만 데이터까지 포괄한 복합적인 학습 세트를 구축해 모델이 다양한 입력 형태를 다룰 수 있도록 했습니다. 전체 데이터 구성 비율은 OCR 70%, 일반 비전 20%, 텍스트만 10%입니다.

먼저 OCR 1.0 데이터는 PDF 문서 중심의 대규모 데이터로 약 30M 페이지가 사용되었습니다. 이때 라벨 품질을 두 단계로 나누어 학습한 것이 특징인데, 그림 5에서도 볼 수 있듯이 Coarse label로 전체 구조를 파악하고 Fine label로 문장 단위 인식을 개선하는 방식이었습니다. 특히 소수 언어 데이터의 부족 문제는 모델이 생성한 라벨을 다시 활용해 추가 학습 데이터를 생산하는 방식으로 해결했습니다.
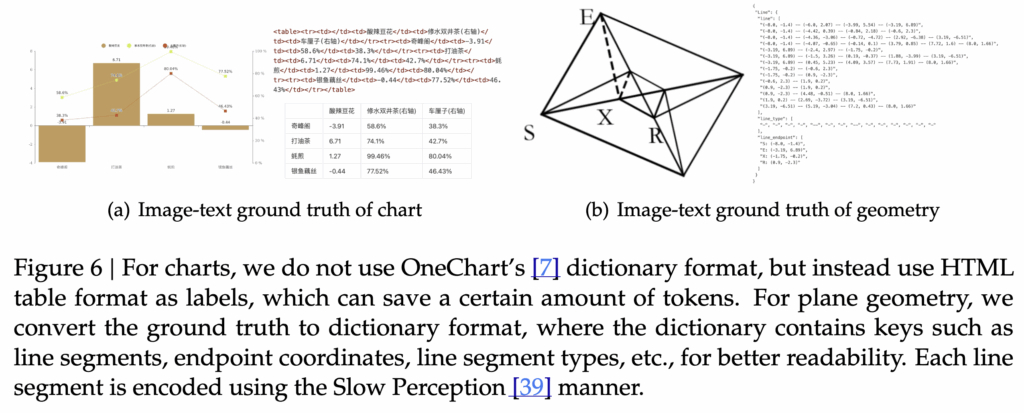
다음으로 OCR 2.0 데이터는 단순 텍스트가 아닌 표, 화학식, 기하 도형 등 구조적·규칙성을 가진 시각 패턴을 포함합니다. 표 데이터는 차트를 HTML-table 형식으로 변환하는 방식으로 구성되며, 그림 6(a)에서 예시를 확인할 수 있습니다. 화학식은 SMILES 문자열을 이미지화해 학습하고, 기하 도형 데이터는 그림 6(b)에서 보이듯이 같은 도형을 다른 좌표 위치에 매핑하는 방식으로 다양하게 확장하였다고 하네요 이를 통해 모델은 문자 인식뿐만 아니라 구조와 규칙을 지닌 시각적 표현도 텍스트로 변환할 수 있게 됩니다.
또한 General Vision Data도 일부 포함되는데, DeepEncoder가 OCR에만 과도하게 특화되어 기본적인 시각 이해 능력을 잃지 않도록 유지하기 위해서라고 합니다. 따라서 저자들은 DeepSeek-VL2의 구성 방식을 참고해 caption, detection, grounding과 같은 일반 비전 태스크 데이터를 함께 학습시켜, 문서 이미지가 아닌 일상 사진·사물·장면 입력에서도 의미 있는 시각 표현을 생성할 수 있도록 했습니다.
요약하면, Data Engine은 단순 OCR 데이터 확장이 아니라 시각 기반 텍스트 표현을 복원하기 위한 데이터를 구축하는 데 초점을 두고 있습니다.
3.5 Training Pipelines
DeepSeek-OCR의 학습 과정은 두 단계로 진행됩니다. 먼저 DeepEncoder를 단독으로 학습해 고해상도 이미지를 적은 수의 비전 토큰으로 압축하는 능력을 확립하고, 이후 해당 인코더를 기반으로 MoE Decoder와 함께 End-to-End 방식으로 전체 DeepSeek-OCR을 학습시키는 구조입니다. 즉, 인코더가 시각 압축을 배우고 난 뒤 디코더가 압축된 시각 표현 → 텍스트 복원을 학습하는 순차적 학습 프로세스라고 이해하면 되겠네요
DeepEncoder 학습 단계
이 단계에서는 OCR 1.0/2.0 데이터와 일반 비전 데이터를 모두 사용하며, Next Token Prediction 방식으로 학습됩니다. 전체 데이터는 2 Epoch 동안 학습되며, 배치 사이즈 1280과 AdamW 기반 스케줄링을 적용했다고 합니다. 고해상도 문서를 토큰 4096 길이 안에 표현하도록 설계된 것도 이 시점에서 최적화된 것이빈다.
완성된 DeepEncoder를 토대로 전체 DeepSeek-OCR을 학습 단계
이때 DeepEncoder는 Vision Tokenizer로 취급되며, 일부 모듈(SAM·압축기)은 freeze하고 CLIP 파트는 다시 학습하는 방식으로 조정됩니다. 언어 모델 부분은 DeepSeek-3B-MoE가 사용되며 파이프라인 병렬화로 4개의 파트로 나누어 학습을 수행했다고 하네요. 데이터 병렬화 40, 글로벌 배치 640, 20개의 A100×40GB 노드를 기반으로 학습 속도는 텍스트 전용 데이터에서 하루 90B tokens, 멀티모달 데이터에서 70B tokens라고 합니다.
4. Evaluation
4.1 Vision-text Compression Study
이 실험은 DeepSeek-OCR이 문서의 텍스트 정보를 얼마나 적은 비전 토큰으로 압축한 뒤 다시 복원할 수 있는지를 확인할 수 있습니다. 저자들은 Fox 벤치마크 중 영어 문서를 사용해, 원본 텍스트를 DeepSeek-OCR 토크나이저로 토큰화한 뒤 문서 길이에 따라 600–1300 토큰 구간의 100개 문서를 선정하고 평가를 진행했다고 합니다. 압축 토큰의 개수는 입력 해상도에 따라 결정되며, Tiny 모드(64 vision tokens)와 Small 모드(100 vision tokens)가 비교 대상으로 사용되었습니다.
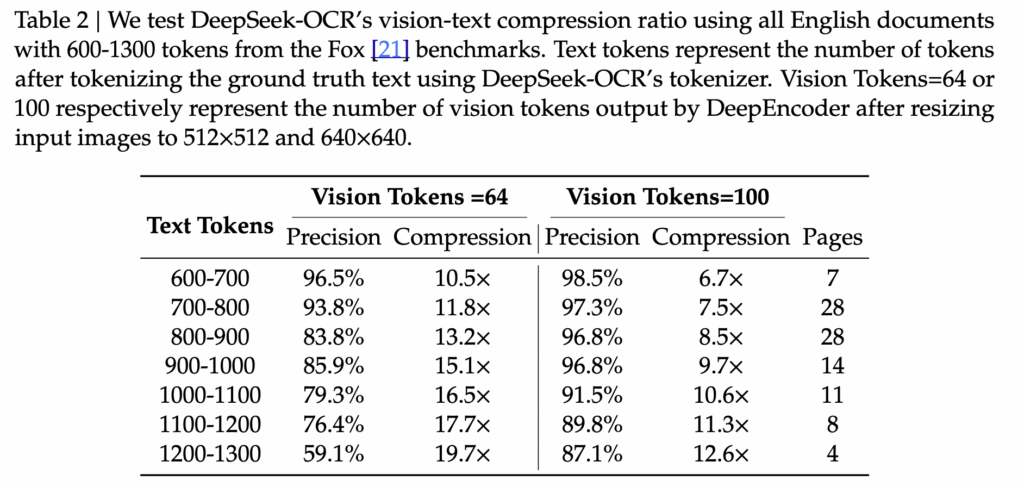
Table 2에 따르면, 텍스트 토큰 대비 약 10배 수준의 압축(64 vision tokens)에서도 약 97% 정확도가 유지된다는 점이 가장 인상적인데요. 압축률이 커질수록 정밀도가 일정 수준 감소하기는 하지만, 20배 가까운 극한 압축 상황에서도 정확도가 약 60% 수준으로 유지된다는 점은 시각 기반 압축이 충분히 실용적일 수 있음을 보여줍니다. 또한 실험 환경이 Fox 벤치마크의 레이아웃 형식을 완전히 반영하지 못했기 때문에, 실제 성능은 표기된 수치보다 소폭 높을 것이라는 언급도 포함되어 있습니다.
저자들은 성능 감소의 원인에 대해 두 가지 가설을 제시하였습니다. 첫째, 문서 레이아웃이 복잡해질수록 페이지 단위 표현이 더 어려워지는 문제, 둘째, 텍스트가 작은 해상도로 렌더링될 때 장문 영역이 흐려지는 문제입니다. 논문에서는 첫 번째는 단일 레이아웃 페이지 렌더링으로 개선 가능하며, 두 번째는 LLM의 장기 맥락 유지 능력과 연계된 구조적 개선이 필요할 것이라고 하네요.
4.2. OCR Practical Performance
DeepSeek-OCR은 단순히 연구용이 아니라 실제 문서 인식 환경에서도 높은 실용성을 보이는 모델이라고 합니다. 이를 검증하기 위해 저자들은 OmniDocBench에서 DeepSeek-OCR의 OCR 성능을 평가했으며, 결과는 Table 3에 정리되어 있습니다. 재밌는 점은 DeepSeek-OCR이 경쟁 모델 대비 훨씬 적은 수의 vision token을 사용하면서도 동일하거나 더 높은 성능을 달성했다는 점입니다.
예를 들어, 100개의 vision tokens (640×640) 만 사용해도 DeepSeek-OCR은 GOT-OCR2.0(256 tokens) 을 능가하며, 400 tokens (1280×1280) 환경에서는 현 SOTA 모델들과 동등한 성능을 달성했습니다. 더 나아가 800 tokens 이하의 “Gundam mode” 설정에서도 DeepSeek-OCR은 약 7,000 vision tokens이 필요한 MinerU2.0 보다 더 우수한 성능을 보였습니다.
즉, 동일한 문서에서 필요한 vision token 수가 압도적으로 적기 때문에, DeepSeek-OCR은 속도·메모리 효율성 측면에서 현실적인 활용 여지가 높다고 볼 수 있는 것이죠. 이는 아래 Table 4에서도 다시 한번 확인할 수 있는데, 문서 유형별로 필요한 vision token이 다름을 보여줍니다.
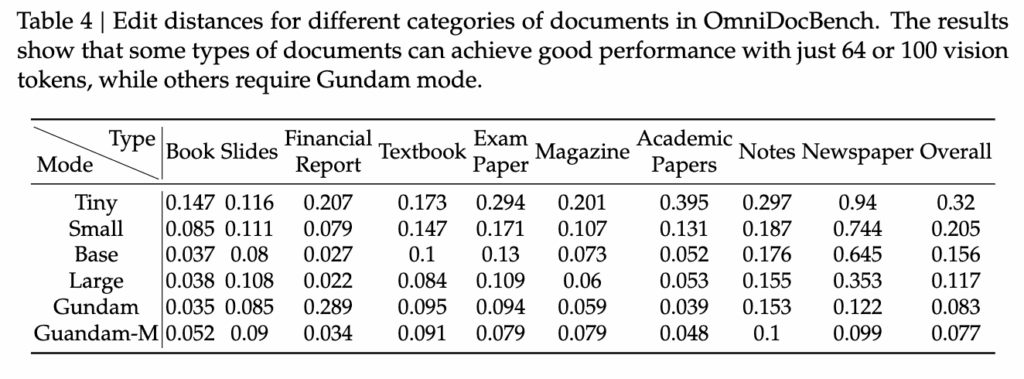
- 슬라이드형 문서 → 64 tokens만으로도 충분
- 보고서/책 형태 문서 → 100 tokens으로 안정적인 성능
- 신문·만화 등 텍스트가 수천 토큰에 달하는 경우 → 10× 이상의 압축이 어렵기 때문에 Dynamic Resolution Mode가 요구
특히 앞선 Section 4.1 Vision-text Compression Study와 연결해서 보면, 대부분의 실무 문서(보고서/슬라이드/자료집 등)는 보통 텍스트 토큰 수가 1,000 이하이기 때문에 약 10× 시각 압축에서 성능 저하 없이 사용 가능하다는 해석으로 이어집니다. 즉 DeepSeek-OCR은 단순 OCR 정확도 향상을 넘어서 문서 종류별 vision token 최적치를 제시하고, 시각 기반 압축의 한계가 어디인지까지 실험적으로 확인했다는 점에서도 의미가 큽니다.
4.3 Qualitative Study
4.3.1 Deep Parsing
저자들은 DeepSeek-OCR이 단순히 문자를 감지·인식(OCR)하는 수준을 넘어, 문서 내부의 이미지 자체를 2차적으로 분석하여 구조화된 정보를 추출하는 기능을 수행할 수 있다고 설명합니다. 이를 deep parsing이라 부르고, 하나의 통합 프롬프트만으로 문서 안에 존재하는 다양한 종류의 이미지를 추가 모델 호출 없이 다룰 수 있다는 점을 주요 특징이라고 하네요. 몇 가지 예시만 한번 살펴보겠습니다
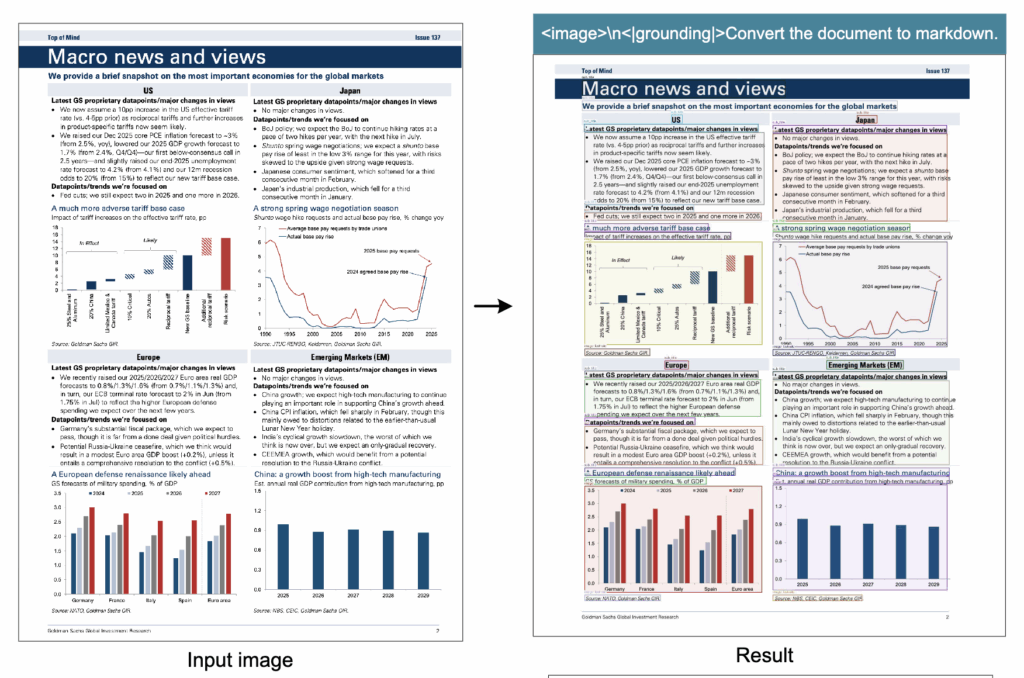
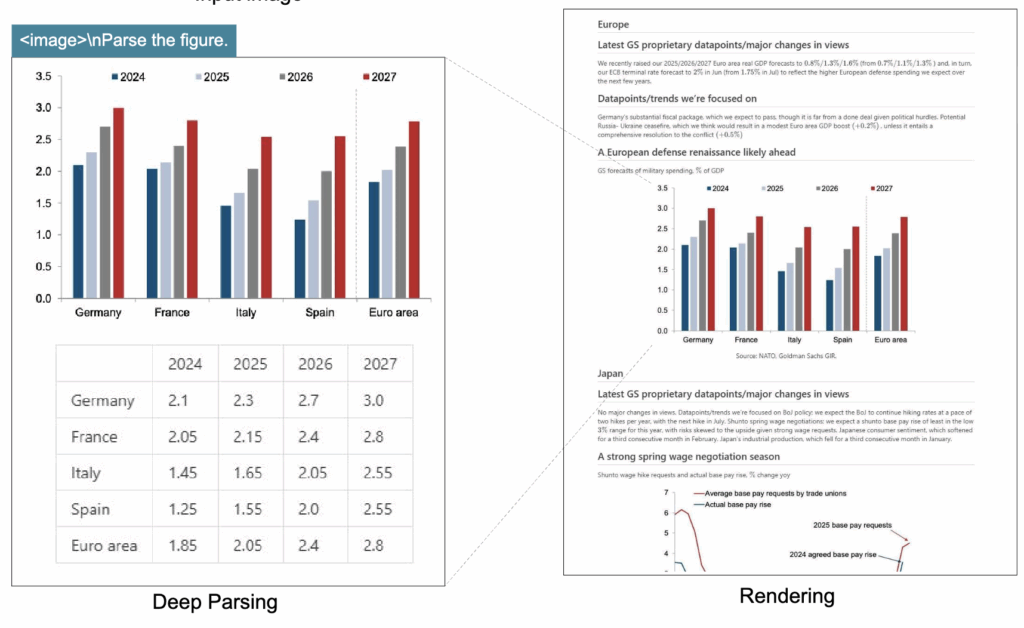
상단 그림은 금융 보고서의 차트 분석이 가능함을 정성적으로 보이는 그림입니다. DeepSeek-OCR은 문서 내 삽입된 분석 차트를 감지한 뒤, 그래프의 데이터 포맷과 축 정보를 구조화된 형태로 추출합니다. 금융·과학 분야 문서에서 그래프 정보는 핵심 해석 요소이기 때문에, 차트 구조화 기능은 향후 OCR 모델의 필수 요소가 될 가능성이 높다고 저자들은 주장합니다.


상단 그림은 자연 이미지 캡셔닝을 보이는 그림입니다. 책이나 기사처럼 텍스트와 사진이 혼재된 문서의 경우, DeepSeek-OCR은 별도의 vision captioning 모델 없이도 이미지 종류를 인식하고 세부 묘사(dense caption)를 생성할 수 있습니다. 즉, deep parsing은 단순 분류가 아니라 이미지의 의미적 내용까지 추출하는 기능을 포함합니다.
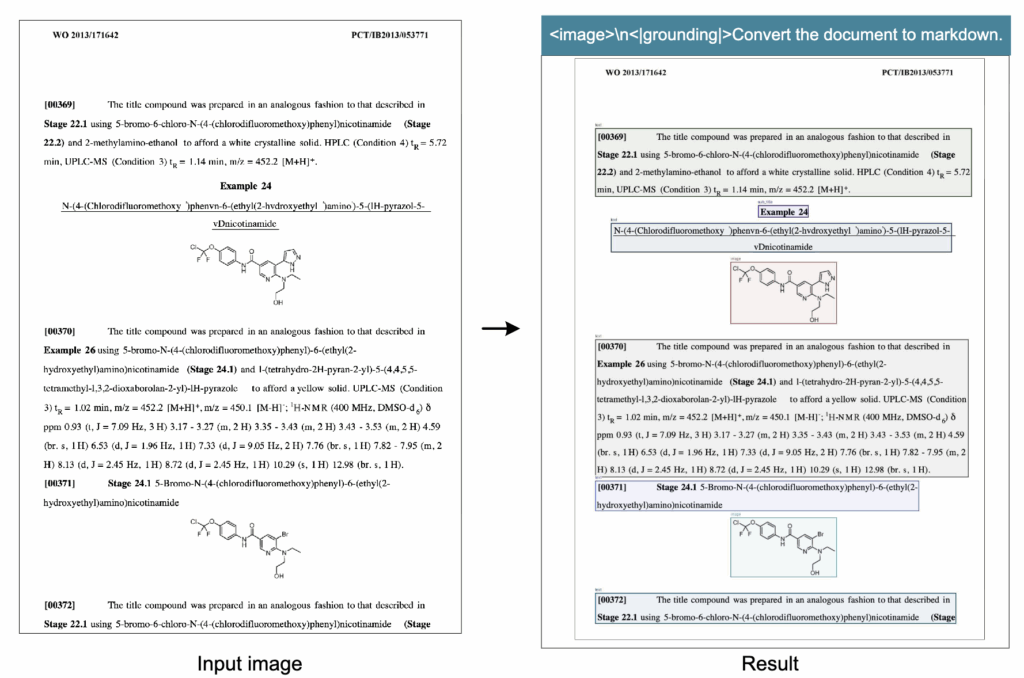
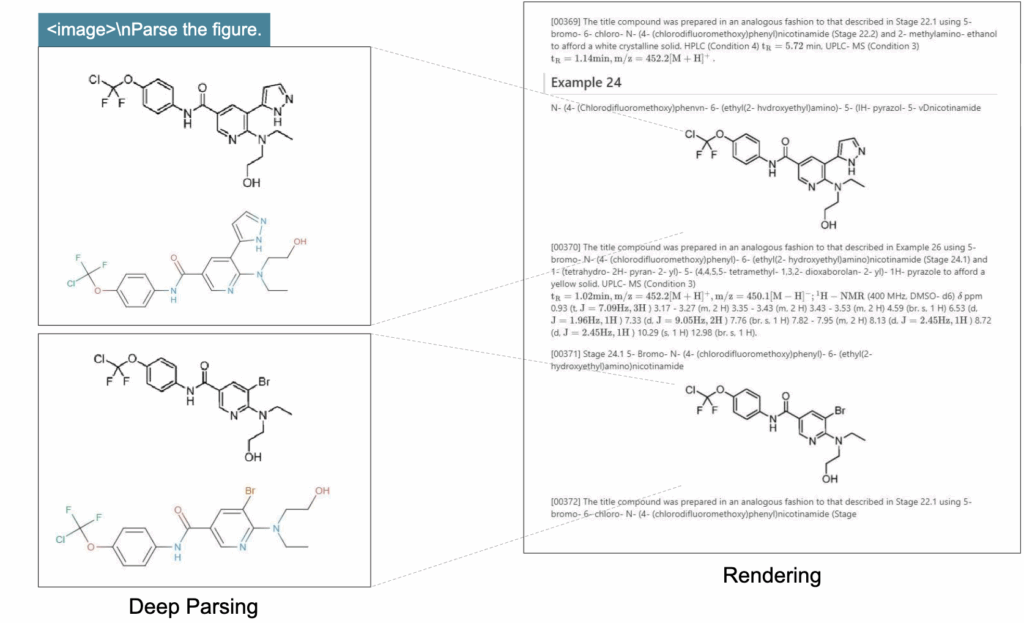
화학식 및 과학 문서 추출도 가능한데요. 화학 문헌에서는 구조식·분자식 등 특수 형식의 기호가 등장하는데, DeepSeek-OCR은 이를 구조적으로 인식하여 SMILES 포맷으로 변환할 수 있음을 보여줍니다. 저자들은 이러한 능력이 향후 STEM 분야에서 LLM·VLM 기반 연구 자동화에 기여할 가능성이 있다고 언급하였습니다
4.3.2 Multilingual Recognition
저자들은 DeepSeek-OCR이 중국어·영어뿐 아니라 인터넷 PDF에서 자주 등장하는 다국어 문서를 처리할 수 있는 범용성을 갖추고 있다는 것도 언급하였습니다. 특히, 해당 모델은 약 100개 언어에 대해 OCR 기능을 지원하며, 이는 대규모 LLM·VLM 학습 데이터 구축에도 필수적인 요소라고 합니다.

DeepSeek-OCR은 다국어 문서에서도 layout OCR(원본 형식 유지)과 non-layout OCR(순수 텍스트 추출)을 모두 지원한다는 점이 특징입니다. 즉, 단순히 언어 확장만 한 것이 아니라, 문서 구조를 보존할지 제거할지 사용자가 프롬프트로 선택할 수 있도록 설계되어 있다고 하네요. Figure 11에서는 아랍어와 싱할라어 같은 소수 언어 문서를 대상으로도 이러한 기능이 제대로 작동함을 보여줍니다.
4.3.3. General vision understanding
마지막으로 일정 수준의 범용 이미지 이해 능력도 갖추고 있는 것도 보였습니다. 이는 CLIP 기반의 DeepEncoder 구조와 일반 비전 데이터(Section 3.4.3)가 학습 과정에 포함되었기 때문이라고 합니다.

Figure 12에서는 이미지 캡션 생성, 객체 검출, 비주얼 그라운딩 등 기본적인 비전-언어 작업이 가능함을 확인할 수 있습니다. 또한 학습 데이터 중 텍스트-only 데이터가 포함되어 있어, 모델은 OCR 성능 외에도 언어 이해 능력을 유지하고 있습니다. 다만 저자들은 본 모델이 SFT(Supervised Fine-Tuning)를 포함하지 않았기 때문에 대화형 챗봇처럼 동작하는 모델이 아니며, 특정 기능을 활성화하려면 별도의 프롬프트가 필요할 수 있다고 언급하였습니다.