제가 이번에 리뷰할 논문은 11월 24일 공개된 따끈따끈한 논문입니다. 어디에 제출한 지 아직 정보를 확인할 수 없지만, Voxposer, Rekep, OmniManip 등 관심을 가지고 있는 연구들과 비교를 하고있어 리뷰하게 되었습니다.
Abstract
VLMs는 강인한 로봇 조작에 중요한 역할을 하지만, 사람의 지시를 행동으로 변환하는 중간 representation으로 사용하는 데 있어 VLM의 이해 능력과 일반화 능력은 trade-off 관계가 있습니다. 저자들은 context-free grammar(Context-Free Grammar, CFG는 컴퓨터 과학과 언어학에서 널리 사용되며, 특히 컴파일러 설계와 프로그래밍 언어의 문법 정의에 중요한 역할을 합니다.)에 영감을 받아 중간 표현(intermediate representation)을 어휘(vocaburary)와 문법(grammar)으로 분해하는 Semantic Assembly representation(SEAM)을 설계하였습니다. 이를 통해 풍부한 의미적으로 풍부하면서도 간결한 연산 어휘와, 다양한 unseen 작업을 처리할 수 있는 VLM 친화적인 문법을 구축할 수 있었다고 합니다. 또한, 새로운 segmentation 패러다임을 제안하여 검색 기반의 few-shot 학습 방식을 통해 물체의 조작 영역을 짧은 inference 시간으로도 효과적으로 찾을 수 있게 되었다고 합니다. 저자들은 새로운 metrics를 정의하여 action 일반화와 VLM 이해 능력을 정량적으로 평가하고자 하였으며, SEAM이 이러한 두 측면에 있어서 기존 방식보다 뛰어난 성능을 보였음을 입증하였습니다. 마지막으로 다양한 real-world 실험을 통해 다양한 세팅의 task에서 SOTA 성능을 보이는 것을 확인하였습니다.
Introduction
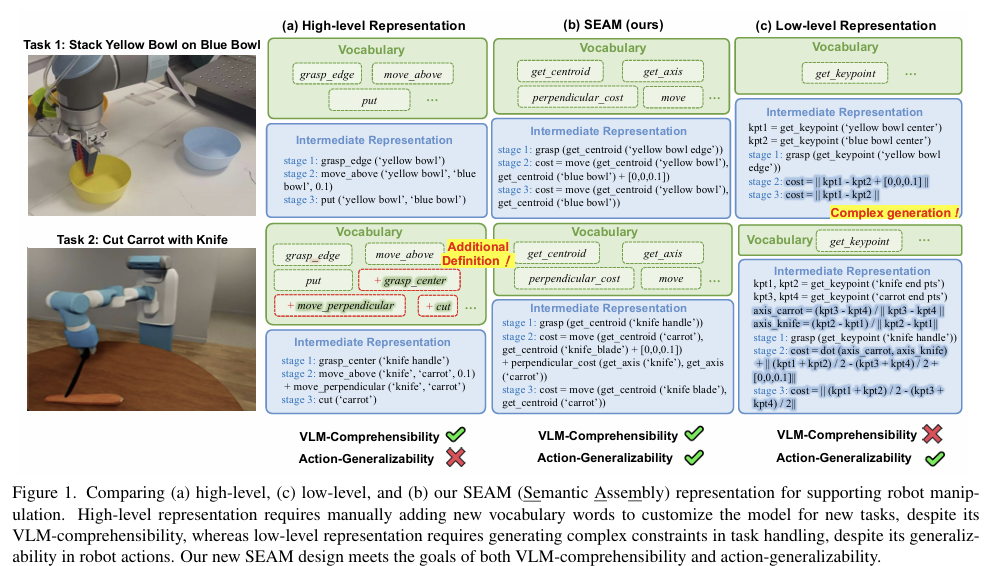
VLMs의 방대한 지식을 활용하는 것은 general robot manipulation 분야의 새로운 가능성을 제시하였으며, 일반적으로 VLM은 인간의 지시를 사전에 정의된 action words와 공간적 제약으로 구성된 intermediate representation으로 변환하는 데 사용됩니다. 기존 연구는 위의 Figure 1(a)와 같이 high-level의 사전 정의된 skill-words를 설계해야 하였으며, 이는 스킬마다 수작업으로 설계해야 하여 번거로우며, 새로운 스킬에 대해서는 추가 작업을 하는 등 확장성이 떨어진다는 문제가 있습니다. 이러한 이유로 최근 Figure 2(c)와 같이 keypoint나 축과 같이 기하학적인 primitives를 사용하는 low-level의 표현 방식이 등장하였습니다. 이러한 방식은 보다 유연하고 일반화 가능성을 보였으나, 중간 표현 자체가 너무 복잡하여 VLM이 이를 이해하고 작업을 생성하는 데 어려움을 겪는다고 합니다. ReKep과 같은 방식이 이에 해당하며, 저자들은 이러한 기존 방식에 한계를 문제삼으며, (1) 다양한 작업에 일반화 가능한 동시에 (2) VLM이 충분히 이해하고 추론할 수 있을 만큼 직관적인 intermediate representation을 설계하고자 하였습니다.
저자들은 SEAM(Semantic Assembly Representation)이라는 새로운 representation을 제안하였습니다. SEAM은 intermediate represesntation을 의미론적 어휘와 구조적 문법으로 분해함으로써 VLM이 이해하기 쉬우면서도 다양한 unseen 작업으로 확장 가능한 표현이 가능하도록 합니다. 이후 VLM이 어휘 단어를 의미론적으로 풍부하고 논리적으로 일관된 방식으로 조합하도록 제약을 주어 코드 생성 과정을 의미론적 정보를 기반으로 조립하는 과정으로 변환하였습니다. 아래의 예시는 VLM 친화적으로 변환하는 과정을 보여주며,

아래의 예시는 다양한 행동으로의 확장 능력에 대한 측면으로, 여러 표현을 블록처럼 조합하여 다양한 행동을 표현할 수 있도록 하였음을 보여줍니다.

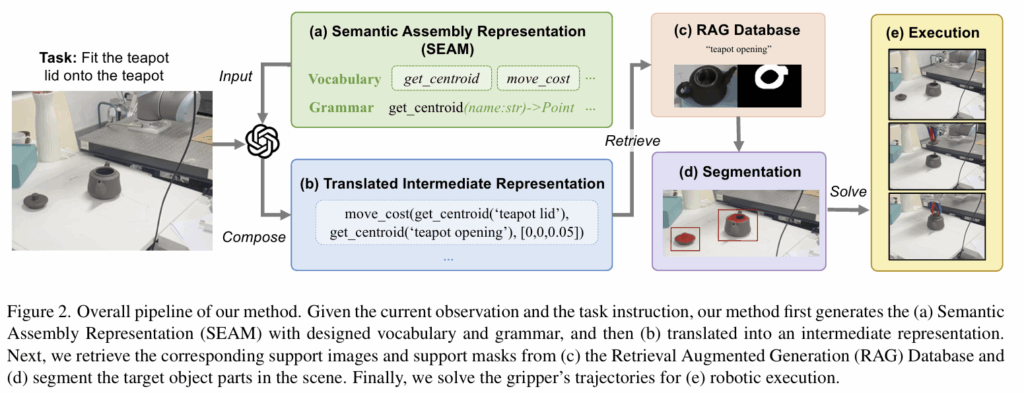
또한, 저자들은 teapot handle이나 bottle cap과 같이 특정 객체 부위와의 정밀한 상호작용이 가능하도록 하기 위해, RGB 이미지와 segmentation mask 쌍으로 구성된 open-vocabulary 이미지 데이터 베이스를 구축하여 fine-grained object part segmentation을 수행합니다. 나아가, RAG(Retrieval-augmented generation) 파이프라인에서 few-shot 학습 기반의 방식을 통해 지시문에 명시된 객체 부위를 정확하게 찾을 수 있도록 하였습니다.
SEAM을 정량적으로 평가하기 위해 저자들은 행동 일반화 능력과 VLM의 이해 능력이라는 2가지 지표를 새롭게 정의하였으며, 실험을 통해 SEAM이 두 지표에서 모두 강력한 성능을 보였으며, 기존 SOTA 방법론 대비 real-world 로봇 조작 성능을 약 15% 향상시켜 실제 세계에서도 강인하게 작동함을 보였습니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- VLM 기반의 로봇 조작을 위해 새로운 Semantic Assembly representation (SEAM)을 제안하여, VLM의 추론과 로봇 행동 사이의 간극을 효과적으로 연결
- RAG 기반의 few-shot learning segmentation 파이프라인을 제안하여, 효율적이고도 세밀한 object-part 수준의 open-vocabulary segmentation이 가능하도록 함
- (저자들이 알기로는) VLM 기반의 로봇 조작을 위한 intermediate representation을 체계적으로 분석하고 VLM의 이해 능력과 행동 일반화 능력이라는 새로운 지표를 제안한 최초의 연구로, 다양한 실험을 통해 SEAM이 기존 방식 대비 15%의 성능 개선을 보임을 입증함
Methods
Problem Forumlation
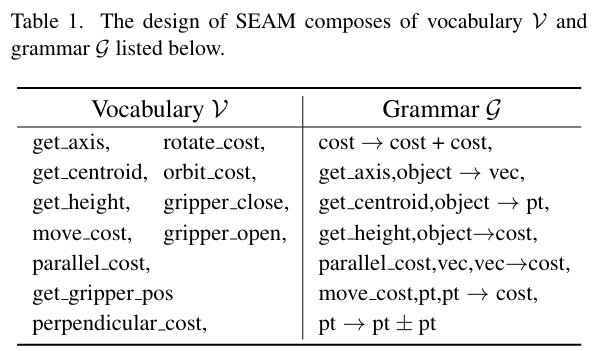
사람의 지시 L와 visual input L가 주어졌을 때, VLM 기반의 로봇 조작은 intermediate representation \mathcal{R}를 구하는 것을 목표로 하며, 이는 이후 solver를 통해 로봇의 액션을 생성하는 데 사용됩니다. 언어적 representation을 \tilde{\mathcal{R}}=(\mathcal{V},\mathcal{G})라 정의하며, 여기서 \mathcal{V}는 skill words를 구성하는 vocabulary, \mathcal{G}는 유효한 구성 규칙인 grammar를 의미합니다.
Context-Free Grammar and SEAM
Context-Free Grammar(CFG)는 유한한 기호(words)와 유한한 재귀적 생성 규칙으로 구성되며, 이 둘을 하나의 언어 를 모델링하고 해당 언어 공간 내의 문자열 패턴을 생성하도록 합니다. CFG는 4개의 튜플(V,\Sigma, R,S)로 정의되며, V는 non-terminal 기호, \Sigma는 terminal 기호, R은 생성 규칙, S는 시작 기호를 의미합니다.
해당 연구는 이러한 CFG를 차용하여 SEAM을 설계하고, VLM을 위해 보다 직관적이고 의미론적인 인터페이스를 제공합니다. CFG의 V,\Sigma, S는 SEAM의 \mathcal{V}에 대응되며, 생성 규칙 R은 SEAM의 \mathcal{G}에 대응됩니다. 아래의 Table 1은 이에 대한 예시입니다.
SEAM Representation Design
저자들의 목표는 VLM의 이해 능력과 행동에 대한 일반화 능력 사이의 균형을 잡는 것으로, 이를 위해 아래의 원칙을 설계하였습니다.
- VLM-Readability: \mathcal{V}에 포함된 단어는 정확한 의미 이해가 가능하도록 VLM의 의미 공간에 맞도록 설계한다.
- Proper Abstraction: representation은 작업 계획과 일반화에 필수적인 파라미터만 보이도록 한다.
- Conciseness: 의미는 최소한의 기호로 전달되며, 정보를 밀도있게 전달하기 위해 high-level 단어들을 사용한다.
- Reliability: \mathcal{G} 내부 시스템은 \mathcal{V} 조합을 제한하여 VLM이 생성하는 출력이 타당하도록 보장한다.
- Proper Minimalism: 핵심 단어 집합을 작고 직관적으로 유지하여 VLM의 학습 부담을 줄이고, 예상치 못한 행동을 방지한다.
- Composability: 표현 방식이 본질적으로 모듈 구조로 이루어져, 새로운 primitive와 규칙을 자연스럽게 통합하여 확장 가능성을 높인다.
이러한 설계 원칙을 기반으로, vocabulary에 포함된 단어들은 의미론적으로 풍부하면서 인간의 자연어와 비슷하여 VLM의 가독성을 확보하였으며, 모든 단어들을 반복적인 하위 구현 세부 사항을 추상화하여, 필요한 최소한의 파라미터만 보이도록 합니다. 예를 들어, “get_axis”의 경우, PCA를 통해 축을 계산하는 내부 구현을 숨기고 입력으로 사용되는 point만을 노출하여 간결하게 표현하는 것 입니다. 이러한 방식을 통해 요소 간 중복을 최소화하여 간결성을 확보하고자 하였습니다.
grammar \mathcal{G}는 어휘 조합을 위한 규칙으로, VLM이 해당 규칙에 따라 어휘를 조립하도록 제약함으로써 구문적으로 타당하고 의미적으로도 신뢰성 있는 output을 생성하도록 합니다. 또한, vocabulary와 grammar 규칙을 최소화하여 VLM이 단어 간 구분에 집중하도록 하였으며, grammar 규칙을 통해 광범위한 행동 조합을 생성할 수 있도록 하여 확장성을 확보하였습니다.
RAG-based Few-shot Open-vocabulary Segmentation

“get_axis”와 같은 \mathcal{V} 내의 단어에 대해 대상 물체 영역을 찾기 위해, 정밀하고 세밀한 open-vocabulary 방식의 segmentation이 필요합니다. 그러나 기존 연구는 정밀한 세부 부위 분할에 어려움이 있었고, 이는 위의 Figure 3에서 확인할 수 있습니다. OV-Seg와 Grounded SAM2와 같은 기존 연구는 물체 영역이 아니라 전체 영역에 집중하였으며, LISA는 hinge와 opening과 같이 세부 부위를 분할하는 데 실패하는 것을 확인하실 수 있습니다.

이러한 문제를 해결하기 위해 저자들은 데이터 베이스 \mathcal{D} = \{(\mathcal{K}_i, \mathcal{P}_i)\}^N_{i=1}를 구축하였으며(위의 그림이 예시), 여기서 \mathcal{K}_i는 특정 객체 부위를 설명하는 핵심 키워드 집합이며, 예를들면 cup opening이라는 객체 부위에 대해서는 {cup opening, cup rim, cup edge} 집합이 핵심 키워드 집합이 될 수 있습니다. \mathcal{P}_i=\{(I^S_j, M^S_j)\}^n_{j=1}로 정의되는 support 쌍으로, I^S_j는 물체 부분이 포함된 j번째 support 이미지, M^S_j는 물체 영역에 대한 마스크를 의미합니다. query 이미지 I_Q와 자연어 지시어 desc가 주어졌을 때, \mathcal{K}_i의 각 키워드와 desc 사이의 Levenshtein distance를 계산하여 가장 가까운 키워드를 포함하는 \mathcal{P}_i를 검색 대상으로 선택한 뒤, 이를 바탕으로 query mask M_Q를 생성합니다. query mask 생성에는 few-shot segmentation 네트워크인 Mapper를 사용하며, 이는 support feature와 query feature사이의 유사도를 attention score로 계산하여 support mask M_S를 query mask M_Q로 매핑합니다.
Trajectory Generation
intermediate representation을 로봇의 실제 행동으로 변환하기 위해 저자들은 전체 cost를 최소화 하도록 end-effector의 pose를 최적화합니다. 구체적으로 SEAM은 python실행이 가능하며, 실행 결과 point cloud P가 SEASM 표현과 얼마나 일치하는 지 수치적으로 계산합니다. 그 다음, 그리퍼와 함께 이동하는 객체 부위를 판별하기 위해 해당 부위가 grasped object에 속하는 지 확인하며, 함께 이동하는 point cloud는 P^m, 정지되어있는 point cloud는 P^s로 표현합니다.
그리퍼와 함께 움직이는 P^m는 동일한 변환 관계를 가지므로, 그리퍼의 target rotation 과 translation을 구하는 문제는 아래의 식을 최적화 하는 문제로 변환할 수 있습니다.
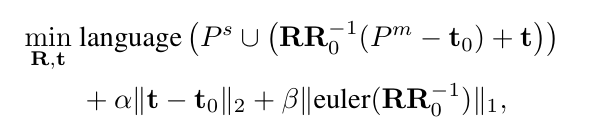
여기서 \mathbf{R}_0과 \mathbf{t}_0은 그리퍼의초기 자세를 의미하며, euler( )는 회전 행렬에서 오일러 각을 추출하는 연산자입니다. 즉, 첫번째 항은 언어 비용이 최소가 되도록 하는 것으로, 정지되어있는 P^s와 그리퍼를 따라 이동한 P^m를 모두 합쳐 cost를 계산하는 것 이며, 마지막 두 항은 정규화 항으로, 그리퍼의 이동량과 회전량이 최소가 되도록 하는 항입니다.
Experiments
Experimental Setup
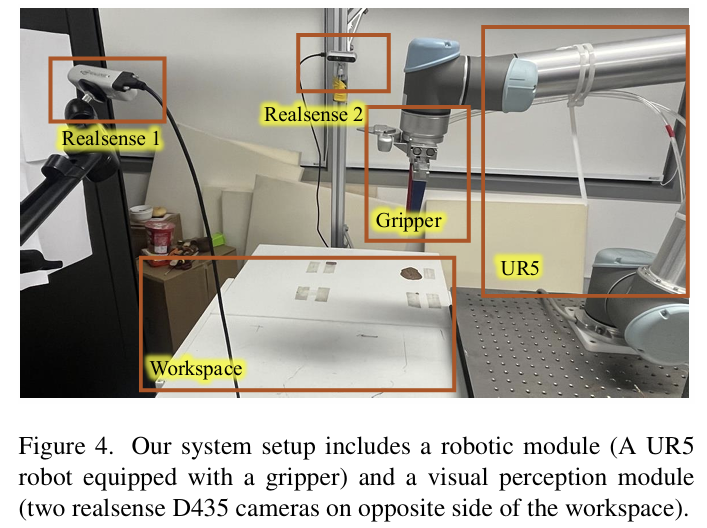
하드웨어 세팅은 위의 Figure 4에서 확인하실 수 있습니다. UR5 로봇을 이용하였으며, 서로 반대편에 2대의 Realsense D435를 배치하여 workspace 전반에 대하여 촬용할 수 있도록 하였습니다.
real-world에서 평가를 위해 8개의 서로 다른 task로 구성된 test set을 구축하였으며, 해당 벤치마크는 음료 따르기와 같은 rigid object 상호작용이 필요한 6가지 작업과 서랍 열기와 같이 관절 구조를 다뤄야하는 6가지 작업으로 구성됩니다. 각 작업은 10번 반복하였을 때 성공률을 지표로 사용하며, 편향을 막기 위해 object의 위치는 매번 무작위로 초기화하였다고 합니다.
함께 비교한 실험들은 VoxPoser, CoPa, ReKep, OmniManip로 모두 x-reivew로 리뷰가 된 적이 있으니 궁금하신 분들은 자세히 읽어보시면 좋을 것 같습니다. 간단하게 정리하면, Voxpser는 3D value map을 구성하여 로봇의 행동을 구하는 방식, CoPa는 시각-언어 이해와 공간적 제약 조건을 통합하여 어휘 제한 없이 조작이 가능하도록 한 연구, ReKep은 keypoint 제약 조건을 구성한 뒤 multi-level 최적화를 통해 자연어 명령을 행동 시퀀스로 변환하는 연구, OmniManip는 조작에 대한 primitive를 사용하여 작업을 수행하기 위한 공간적 제약 조건을 만드는 연구입니다.
Main Results
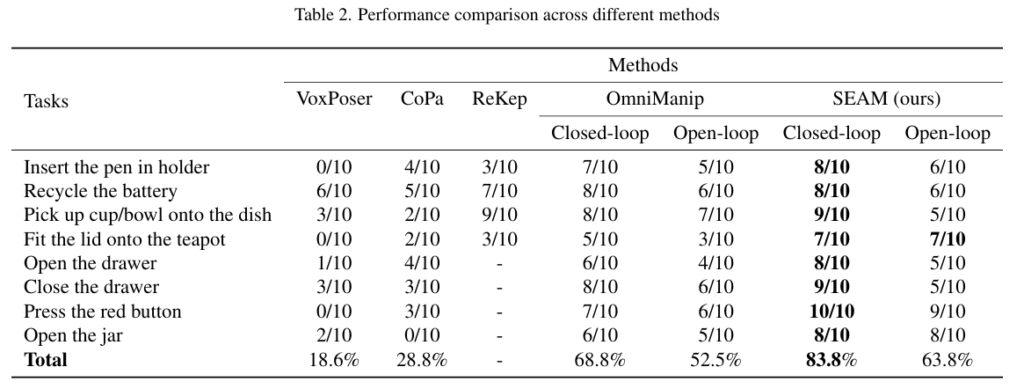
총 8개 작업에 대하여 평가를 수행하였으며, 이에 대한 성공률은 위의 Table 2에서 확인할 수 있습니다. 객체의 위치와 자세는 매번 랜덤하게 초기화되며, 실험 결과 저자들이 제안한 SEAM 방식이 전반적으로 가장 좋은 성능을 달성하였으며, Omnimanip 대비 15% 정도의 성능 향상이 이루어졌음을 확인할 수 있습니다. 여기에 closed-loop 방식과 open-loop 방식이 있는데 이는 한번 결과를 내고 수행하면 open-loop, 반복적으로 업데이트 하면 closed-loop라고 생각하시면 될 것 같습니다. 또한, 아래의 그림들은 작업의 실행 과정을 시각화 한 것 입니다.

1) Semantic Assembly Representation

SEAM은 VLM이 이해하기 쉽고 조합 가능하도록 설계된 방식으로, Figure 6은 펜을 펜 꽂이에 넣는 작업 중 펜을 펜꽂이 위로 이동하는 단계에 대한 각 방법론들의 표현을 확인할 수 있습니다. ReKep은 이미지에서 keypiont를 선택하고 이를 기반으로 축을 계산하도록 하여 팬의 축과 펜꽂이의 축 정렬에 어려움을 겪는 것을 확인할 수 있습니다. OmniManip의 경우도 이미지에서 올바른 축을 선택하고 적절한 표현을 생성해야하므로 축 정렬에 어려움을 겪습니다. 그러나 저자들이 제안한 SEAM 방식은 어휘와 문법을 통해 방향 정렬 문제의 복잡성을 추상화하여 펜과 펜꽂이를 정렬하기 위해 쉽게 표현을 생성하도록 합니다.
2) RAG-based Open-Vocabulary Segmentation

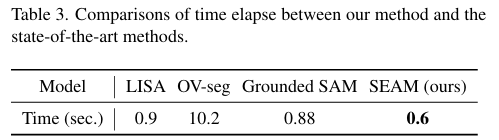
위의 Figure 3이 기존 SOTA 연구들과 해당 방법론의 RAG 기반 segmentation 방식에 대하여 정성적으로 비교한 결과입니다. 보시면 다른 방법론과 비교했을 때, 특정 세밀한 부분에 대하여 잘 찾는 것을 확인할 수 있습니다. 이러한 결과는 실제 로봇 작업에서 정밀한 정렬이 요구되는 작업의 성공률을 크게 개선하는 데 기여하였습니다. 아래의 Figure 7이 이에 대한 예시로, 기존 방식은 내부 점이나 전체 축만을 탐지하여 정확한 위치에 뚜껑을 올리지 못한 것에 반해, Ours는 뚜껑이 있어야 하는 테두리를 정확히 인지하여 작업 성공률을 높일 수 있었다고 합니다. 추가로 Table 3은 추론 시간에 대한 리포팅 결과로, 기존 방법론들에 비해 시간 효율성 측면에서도 좋다는 것을 보였습니다.
Quantitative Study on Action-Generalizability and VLM-Comprehensibility
해당 파트는 VLM 기반의 로봇 조작 방식의 intermediate representation에 대해 2가지 측면에서 비교한 것으로, 저자들이 2가지 지표를 제안하여 평가를 수행하였습니다.
(1) Action-Generalization
Action-Generalization(AG)은 중간 표현이 보지 못한 작업에 일반화 가능한 지를 의미하며, 아래와 같이 정의됩니다.
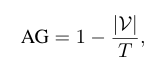
|\mathcal{V}|는 모든 인간 지시문을 변환하는데 필요한 고유 어휘 수이며, T는 전체 task의 수를 의미합니다. AG가 높을수록 작업 표현에 필요한 어휘 연산 수가 적다는 것을 의미하며 이는 강한 일반화 능력을 시사합니다.
(2) VLM-Comprehensibility
VLM-Comprehensibility(VC)는 주어진 행동 지시에 대하여 중간 표현이 올바르게 생성될 수 있는 지를 의미합니다.
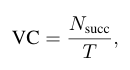
N_{succ}는 VLM이 중간 표현을 성공적으로 생성하여 실제로 수행 완료한 작업의 수를 의미하며, VC는 VLM이 이가나 지시를 기반으로 실제로 성공적으로 행동을 생성하여 조작을 수행하는 비율을 나타냅니다.
Task
단일 로봇 팔, non-tactile, non-force-feedback 조건에서 랜덤하게 33개의 작업을 무작위로 생성하였다고 합니다. 동일한 VLM 모델인 Qwen3-VL에 해당 방법론의 프롬프트들을 제공하여 intermediate representation을 생성하도록 하였으며, 모든 작업에 대하여 실제로 검증하는 것이 노동집약적이고 사실상 불가능하므로 DeepSeek를 활용하여 실제 작업 수행에 합리적인 행동을 생성하였는 지 평가하였다고 합니다. 사실 이 부분이 받아들여질 지 모르겠습니다.. 제 생각에는 받아들여지지 않을 것 같은데요.. 개수를 줄이더라도 실제 가상환경이나 real-world로 평가를 했어야 인정이 될 것 같습니다. 많이 아쉽네요..
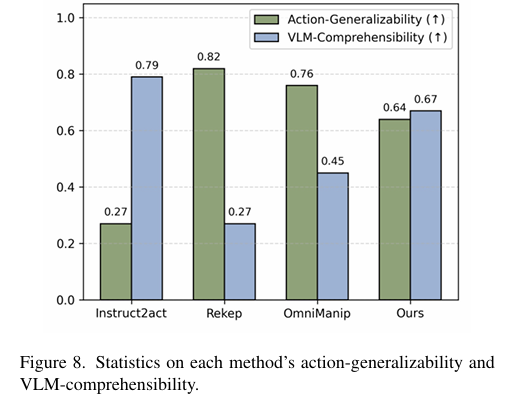
위의 Figure 8은 AG와 VC를 나타낸 결과로, 이러한 실험을 통해 VLM의 이해 능력과 Action 일반화 능력이 trade-off 관계임을 명확이 확인할 수 있으며, SEAM 방식이 그 중 균형을 가장 잘 맞춘 결과라는 것을 저자들은 어필합니다. (그러나 실험이 Deepseek의 평가 결과라면 인정을 받기 어려울 것 같습니다.)