안녕하세요 최인하입니다. 이번에 리뷰할 논문은 Dexterous hand manipulation 관련 논문을 서베이 하면서 조사했던 논문을 리뷰해 보려고 합니다. 바로 시작하겠습니다.
Abstract
Human demonstration을 기반으로 한 imitation learning은 로봇에게 manipulation skills를 가르치는 효과적인 방법이라고 합니다. 하지만 이러한 방식에 있어서 human 데이터 수집은 큰 시간적 비용과 인간 작업이 필요 하다는 이유가 큰 걸림돌이 되었죠. 또한 bimanual dexterous robot은 두 팔과 multi fingerd hands를 동시에 제어해야 하는 어려움 때문에 데이터를 모으는 것 또한 더욱 어렵습니다.
Introduction
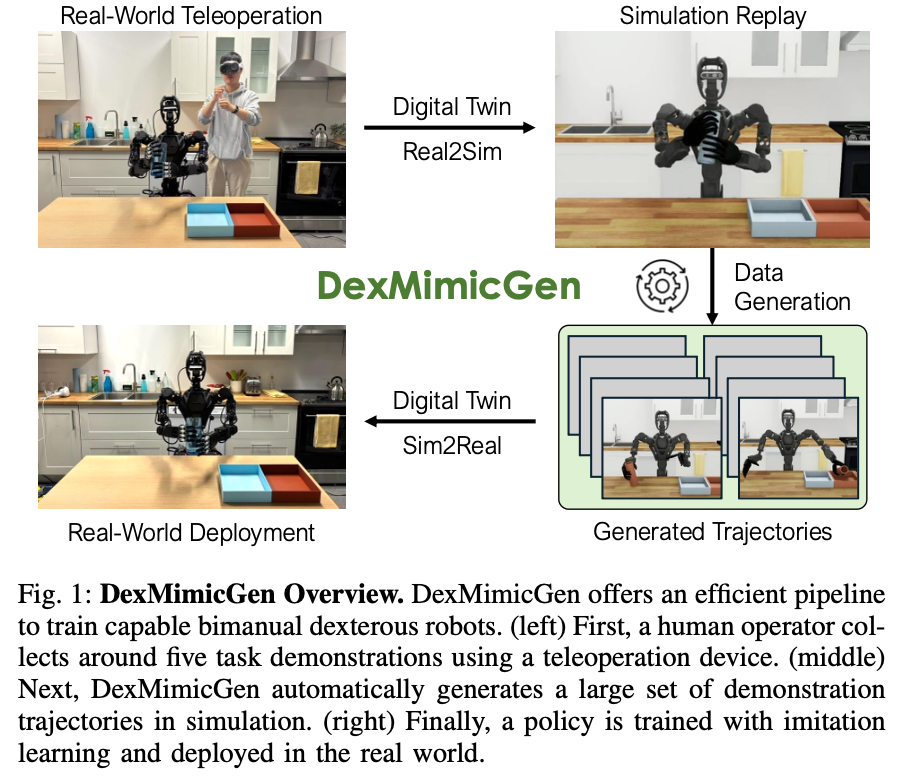
보통 human demonstraion을 수집하는 방법은 teleoperation 방식을 통해 수행됩니다. Teleoperation을 수행할 때는 사람이 직접 로봇을 제어하여 policy를 학습하기 위한 데이터를 수집합니다. 하지만 이러한 방식 때문에 많은 양의 데이터를 필요로 하면 시간적 비용과 다수의 인간 작업이 필요하다는 단점이 생기는거죠. 또한 논문에서는 five – fingers hand와 양 팔을 모두 제어하는 것도 매우 높은 난이도라고 설명합니다. 좋은 데이터를 수집하기도 어렵다는 이야기겠죠. 또한 필연적으로 많은 자유도를 요구하면서 더욱 더 많은 데이터를 요구할 것입니다. 이를 해결하기 위해서 sim 환경에서 데이터를 취득하는 방식들이 등장했고 실제로도 효과가 있었다고 합니다. 이 논문에서도 위와 같은 이유로 DexMimicGen을 제안합니다. 이는 small set of human demonstration을 기반으로 sim 환경에서 demonstration transformation과 replay를 수행하여 대량의 bimanual manipulation에 적합한 imitation learning training data를 자동으로 생성한다고 합니다. DexMimicGen은 single arm을 대상으로 한 MimicGen을 기반으로 만들어졌다고 합니다. 어떻게 DexMimicGen은 single arm 기반인 MimicGen을 bimanual로 확장시켰을까요? 우선 MimicGen은 각 작업을 subtask의 sequence로 분해하고 각각의 subtask trajectory를 생성한 뒤 결합하는 방식이라고 합니다. 하지만 bimanulal 상황에서는 두팔이 독립적으로 움직이는 상황도 있을 수 있고, 협력을 할 수도 있겠죠? 더욱 고려해야 되는 점이 많습니다. 따라서 single subtask segmentation에 의존하는 MimicGen은 bimanual task에 있어서 어려움을 겪을 수밖에 없습니다. 이러한 문제를 해결하기 위해 DexMimicGen은 flexible per-arm subtask segmentation을 사용하여 각 팔이 독립적으로 task를 수행하면서 필요한 협력은 수행하도록 합니다.
MimicGen
들어가기에 앞서 MimicGen을 간단하게 소개하고 넘어가겠습니다. MimicGen 방식은 적은 human demonstration을 사용하여 대규모의 training dataset을 만드는 방법입니다. MimicGen은 task를 object-centric subtasks의 집합으로 구성합니다. 그 후 human demonstration data는 분할된 subtask에 해당하는 구간으로 나눠집니다. 각각의 segment들은 world 좌표계 기준으로 End Effector의 sequential 한 pose로 구성됩니다. 이제 새로운 scene에서 demonstration을 생성하기 위해 새로운 object pose를 측정하고, 원래의 시연에서의 object pose와 SE3 변환을 이용하여 변환 행렬을 구한 후 이를 엔드 이펙터에 적용하고, object centric의 이점을 이용하여 물체와 엔드 이펙터 사이의 상대적인 pose를 일정하게 유지함으로써 원본의 시연 segment가 새로운 scene에서도 동일하게 적용될 수 있도록 합니다.
DexMimicGen Method

자 이제 bimanual manipulation을 생각해보면 single arm manipulation에 비해서 복잡합니다. 우선 양팔을 독립적으로 다른 task를 수행할 수도 있고, 하나의 goal을 위해 서로 coordination을 해야할 수도 있습니다. 또한 한 팔의 subtask가 완료되어야만 다음 팔이 subtask를 시도할 수 있는 상황이 만들어지기도 합니다. 따라서 DexMimicGen은 subtask를 위에서 설명한 세가지 유형으로 분류했습니다. 하나씩 설명해보겠습니다. (또한 MimicGen과 마찬가지로 SE(3) equivariance를 사용한다고 하네요)
Parallel Subtasks
이 부분은 생각보다 간단합니다. 우선 Fig. 2 맨 위의 사진에서 볼 수 있듯이 bimanual manipulation 에서는 각각의 팔이 서로 다른 task를 수행할 수 있습니다. 이때 MimicGen 처럼 하나의 subtask sequence는 적합하지 않겠죠. 이를 해결하기 위해 그냥 subtask sequence를 각각의 팔에게 할당해 주는 방식을 사용했습니다. 그로인해서 각각의 팔은 고유한 segment 집합을 가질 수 있겠죠. 그리고 각 팔은 action 정보를 담고 있는 큐를 이용해서 비동기적으로 task를 수행한다고 합니다. 큐가 비면 다음 subtask의 segment를 변환 후 큐에 삽입한다고 합니다.
Coordination subtasks
bimanual manipulation 작업에서 coordination을 요구하는 경우가 있을 수 있습니다. 이러한 경우에는 두 팔의 엔드 이펙터의 relative pose가 source demonstration과 일치해야 하므로 DexMimicGen에서는 동기화된 방식으로 양 팔의 궤적을 실행하면서 두개의 궤적이 동일한 transformation을 통해서 생성되도록 합니다. 이는 coordination subtasks에 해당되는 부분에서는 양 팔 모두 같은 timestep에서 끝나도록 강제합니다. 따라서 각 팔이 다른 팔을 기다리면서 작업을 수행하게 됩니다. 만약 한 팔이 다른 팔보다 빨리 움직이면 충돌이 발생하거나, 물건을 놓칠 수 있겠죠? Transform 방식에는 논문에서 두가지가 언급되었습니다. 첫번째는 MimicGen과 같이 SE(3)을 이용하는 것입니다. 두번째는 replay 방식으로 souce demonstration trajectory를 그대로 사용하는 방식입니다. 이는 물건을 넘겨주거나 특정 coordination subtasks에서 유용할 수 있다고 합니다. 어려운 작업일 수록 kinematics limits을 잘 지켜서 안정성을 높이고 성공률을 높이는 방향인 것 같습니다. 그냥 그대로 따라하는거네요. 이럴 경우 데이터 증강 효과가 없으니까 특정 환경에 overfitting 되지 않을까 생각이 드네요.
Sequential Subtasks
쉽게 예를 들어 pick and place task인 경우에도 pick이 먼저 수행되어야 되겠죠? 따라서 논문에서는 이러한 sequential한 subtasks를 처리하기 위해 ordering constraint mechanism을 적용했다고 합니다. subtask를 pre-subtask와 post-subtask로 나눈 후 post-subtask를 수행하는 팔이 pre-subtask를 수행하는 팔의 작업이 완료될 때까지 기다린 후 subtask를 진행한다고 합니다.
Data Generation for Bimanual Manipulation
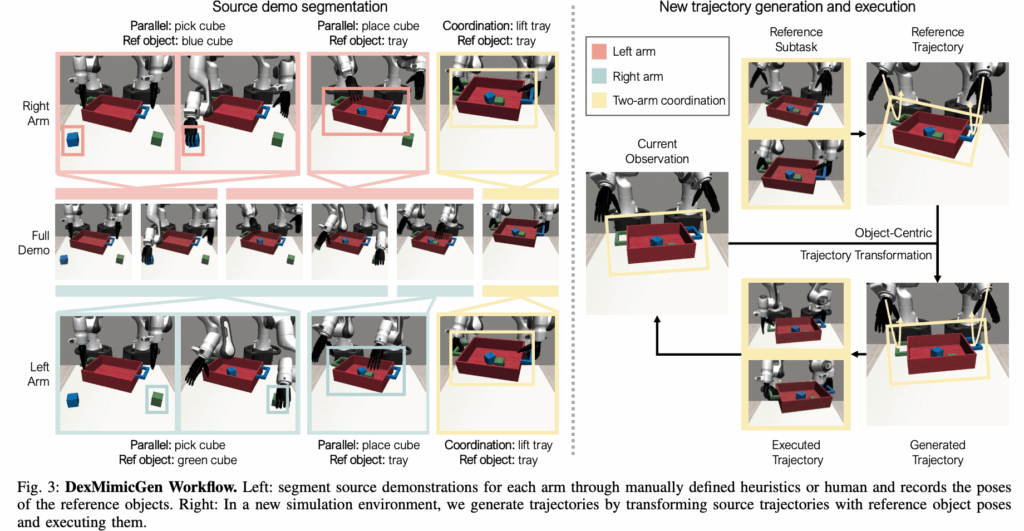
이 부분에서는 위의 그림 Tray Lift task를 예로 들어서 전체적인 data generation 과정을 설명합니다. 위에서 설명한거 총정리라고 생각하시면 될 것 같습니다. 자 처음에는 human demonstration을 이용하여 source demos를 수집합니다. 그 다음 source demos는 human annotation을 통해서 subtasks로 segmentation이 됩니다.(풀어서 설명하면 하나의 task를 subtasks로 나누고 각각의 subtasks를 수행할 때 end effector의 poses들이 sequential한 집합으로 segmentation 된다는 말입니다.) 그리고 위의 그림을 보면 마지막 작업 lift tray를 할 때 coordination이 필요합니다. 이제 data generation이 시작할 때 scene은 randomized됩니다. 이 예제에서는 SE(3) transformation이 사용되는 것 같습니다. 즉 tray의 변환을 통해서 변환 행렬을 구한 후 이 변환 행렬을 가지고 엔드 이펙터의 궤적을 변환 시킵니다. 여기서 five fingers의 궤적은 replay 방식으로 생성한다고 하네요 엔드 이펙터와 상대적인 관계여서 그렇다고 합니다. 그 후 task가 성공하여야 demonstration이 생성된다고 합니다.
System Design
simulation environment

논문에서는 DexMimicGen을 구축하기 위해서 sim과 실제 환경 모두에서 source human demonstration을 수집할 수 있도록 하는 대규모 sim 환경과 teleoperation system을 구축했다고 합니다. 시뮬레이션은 MuJoCo를 사용했다고 하며, Hardware는 2-DOF gripper가 장착된 bimanual panda arms, dexterous hands가 장착된 bimanual panda arms, dexterous hands가 장착된 bimanual panda arms가 사용되었다고 합니다. 각각의 하드웨어마다 다른 controller를 사용한다고 합니다. panda arms에서는 delta end-effector pose를 joint torque commands로 변환하고, humanoid인 경우 mink 기반의 Ik를 사용한다고 합니다. 이는 humanoid kinematic의 복잡성을 처리하기 위해서 라고 합니다. finger 같은 경우 그냥 각도 값을 넣는다고 하네요. 이러한 하드웨어마다 3개의 task를 부여해서 총 9개의 task를 수행한다고 합니다.(Piece Assembly, Box packing, Drawer,… 등등) 또한 MimicGen과 마찬가지로 특정 task들에 대해서 default reset distribution D0를 확장하는 task variant를 도입한다고 합니다. D1은 sim 상황에서 객체들의 초기 위치가 기본 설정보다 더 넓은 범위로 다양하게 주어질 수 있도록 합니다. D2는 객체의 위치가 서로 바뀌어 설정 될 수도 있습니다.
Teleoperation system
각 하드웨어에 맞게 teleoperation 방법도 다르다고 합니다. 2-DOF가 장착된 panda arms의 경우 Iphone 기반 teleoperation을 이용하여 human wrist 및 gripper actions를 캡처한다고 합니다. dexterous hands 경우에는 Apple vision pro 기반 teleoperation 시스템을 구현했다고 합니다. 이를 위해 human to robot calibration process를 설계했다고 하며 human finger pose를 robot finger joint positions로 retarget 하기 위해서 OmniH2O에서 제공하는 retargeting method를 이용했다고 합니다.
Experiments
논문에서는 2-DOF가 사용되는 task에 대해서는 10개의 human demonstration을 수집하지만, dexterous hands가 사용된 task들의 경우에는 높은 자유도에 대한 시간 비용 때문에 5개의 demonstration만 수집한다고 합니다. SE(3) 방식이 아니라 replay 방식을 사용하는데도 시간이 많이드는 것을 보면 retargeting 부분에서 계산이 많이 소요되는 것 같습니다. 그 후 각 task마다 DexMimicGen을 사용하여 1000개의 demonstraiton을 생성한다고 합니다.
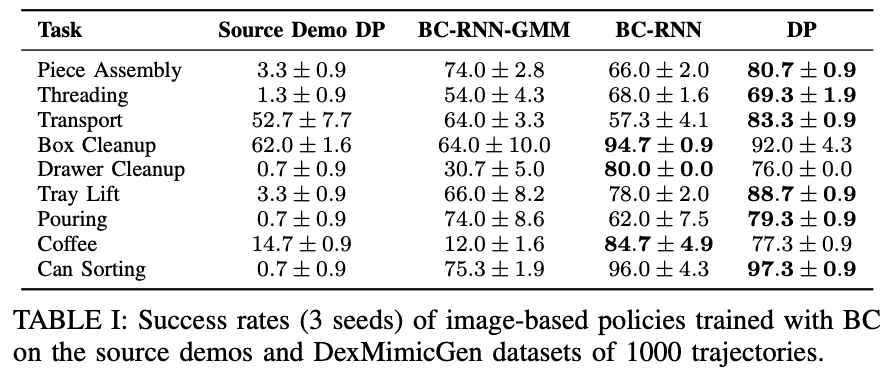
source human demo만 사용해서 학습하는 것 보다 훨씬 높은 성공률을 기록했다고 하네요. 1000개보다 더 사용하면 더 높아질까요?
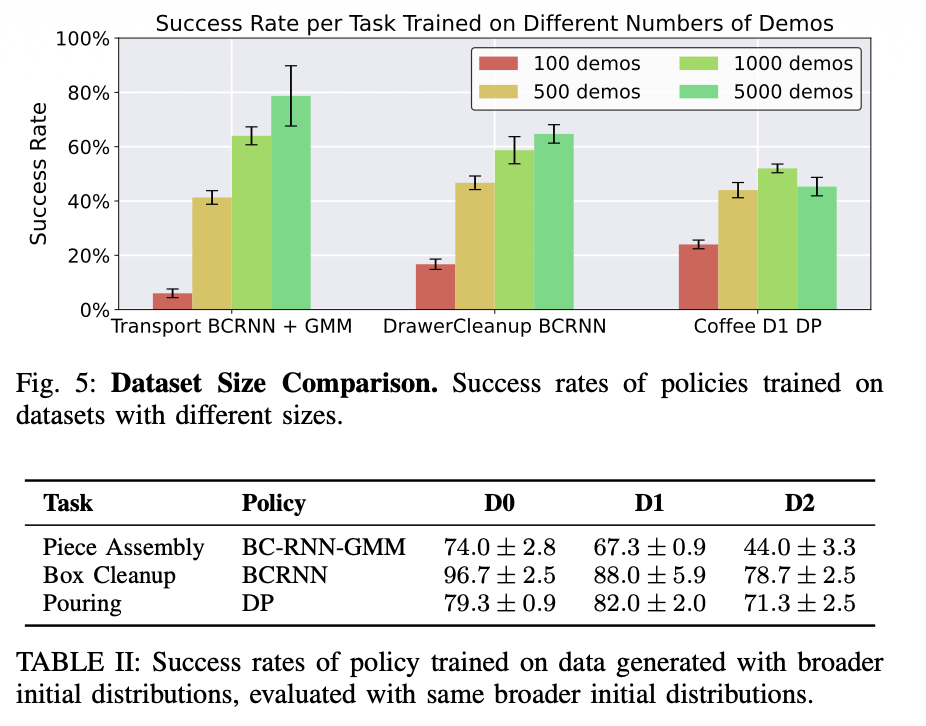
많은 demo를 사용하면 성공률이 올라가는 것도 있지만 떨어지는 것도 존재하는 것 같습니다. 이를 논문에서는 diminishing returns라고 표현 했는데 찾아보니까 경제 용어네요. 간단하게 설명해보면 일정 수준의 고점에 도달하면 더이상 증가하지 않고 오히려 input을 추가하면 떨어진다는 의미 같습니다. 이 부분에서는 정책이 이미 충분한 정보를 학습해서 최선의 결과를 도출했는데 추가된 데이터들이 계속해서 들어오면 오히려 안좋은 방향으로 학습할 수 있다는 것인 것 같습니다.
또한 위에서 설명한 D0,1,2에 따라 성공률의 변화도 나타나는 것을 볼 수 있습니다.

다른 방법과 비교해도 성공률이 월등히 높다고 합니다.
Real-World Evaluation

논문에서는 6-DoF Inspire dexterous hands를 장착한 Fourier GR1 휴머노이드를 사용하여 real world에서도 평가를 진행하였습니다. 카메라는 D435i를 사용하며 head mounted와 로봇 앞에 배치되어 first person view와 third person view를 제공한다고 합니다. 이제 실제 환경과 동일하게 sim환경을 구축합니다. 그 후 객체의 정확한 pose 추정을 위해 pose estimation 과정을 수행합니다. 이는 로봇의 head view camera를 통해 초기 RGB-D를 캡처하고 GroundingDINO를 이용하여 object의 RGB 마스크를 추출합니다. 그 후 RGB 마스크 내의 깊이 값들을 평균하여 실제 object의 중심점을 결정하고, 이를 이용해서 sim 환경에서의 object의 x,y 좌표를 초기화합니다.
이제 먼저 Can Sorting task에 대한 human demonstration 4개를 수집하고 sim 상황에서 replay한다고 합니다. 이때 sim 상황에서 성공했다고 판단하면 바로 real world의 로봇에게 전송되어 실행된다고 하네요. 이를 통해 총 40개의 데이터를 자동으로 수집한다고 합니다.
마지막으로는 이렇게 모은 40개의 데이터를 가지고 Diffusion policy를 사용해 학습한 정책과, 4개의 human demo를 가지고 학습한 정책을 비교하는 과정을 하였는데. DexMimicGen의 경우 90%의 성공률을 보였지만 4개의 human demo를 통해 학습한 정책은 0%의 성공률을 보였다고 합니다.
안녕하세요 인하님 리뷰 잘 읽었습니다
데이터에 존재하는 목표 대상과 각 팔의 궤적을 다른 변화시키고, 이 때 양 팔로 작업을 해야하기 때문에 task 관점에서 각 팔이 취해야 하는 행동을 크게 크게 사람이 segmentation해서 데이터를 증강하는 기법으로 알고있는데요, 기반이 된 MimicGen과 다르게 Dex가 붙은 이유가 무엇인가요?
또 real world evaluation을 진행할 때 human demonstration 4개를 수집하고 replay한다음 성공시 로봇에 전송해서 40개의 데이터를 수집한다고 했는데 이 때 dexmimicgen 파이프라인을 돌려서 나온 궤적을 기준으로 성공을 판단하는건가요? 그렇다면 저희가 시도해봤을 때 real에서는 성공했는데 시뮬레이션에서는 실패했던것 처럼 그 부분에 대한 이야기도 있었나요?
안녕하세요 영규님 좋은 댓글 감사합니다!
바로 답변드리겠습니다.
Q1. 제가 생각하기에는 기존의 MimicGen과 소개한 DexMimicGen의 큰 차이점은 single arm manipulation에서 bimanual manipulation 방식으로의 전환인 것 같습니다. 즉 task를 양팔을 사용해서 해결할 수 있음을 의미합니다. 이러한 점은 single arm이 해결할 수 있는 task를 더 쉽게 해결할 수 있는 가능성을 제공할 수 있을뿐만 아니라, 더욱 고도화된? 어려운 task를 해결할 수 있는 가능성도 제공합니다. 따라서 Dex(Dexterous)(손재주 있는) 기존의 방식보다 손재주 있게 Dexterous하게 task를 수행할 수 있기 때문에 Dex가 붙은 것 같습니다.
Q2. 맞습니다. dexmimicgen 파이프라인을 통해 나온 궤적을 기준으로 성공 여부를 판단합니다. 제가 읽어봤을 때success check는 sim 상황에서만 이루어지는 것 같습니다.
감사합니다.