안녕하세요. 이번 X-Review에선 20년도 CVPR에 게재된 VQA 논문을 소개해드리고자합니다. 나온지 시간이 꽤 된 논문이지만 지금 개인 연구에 적용한 아이디어와 거의 동일하여 리뷰하게 되었습니다. 간단하게는 Visual Question Answering을 수행하는 과정에서 질문 문장의 사소한 차이에 대응할 수 있도록, 그 디테일함을 모델에게 학습시키는 방법론입니다.
1. Introduction
Visual Question Answering (VQA) task는 이미지에 관련된 자연어 질문이 입력되었을 때, 이에 알맞는 정답을 내뱉어야 합니다. 2020년도에도 그랬지만 이 VQA는 아직까지도 활발히 연구되고 있으며, 요즘은 대부분 VLM들이 여러 도메인의 VQA를 벤치마킹하는 추세입니다.
지금 연구중인 AVQA도 유사한 문제가 있지만, 당시 VQA에서 활발히 벤치마킹되던 VQA v1, VQA v2와 같은 데이터셋은 특히나 linguistic correlation을 학습하기만 하면 좋은 성능을 낼 수 있다는 결과가 있었습니다. 언어와 정답 간 편향이 있다는 의미로, 예를 들어 “이 이미지에 X가 몇개야?”라고 묻는다면, 어떠한 이미지이든 X가 무엇이든 관계 없이 그냥 “2개”라고 답하면 꽤나 높은 성능을 달성했다고 합니다. 이러한 상관관계 편향을 깨기 위해 그 당시 의도적으로 학습 및 평가 셋의 데이터 분포를 다르게 설정한 VQA-CP(VQA under Changing Priors)라는 데이터셋이 등장했다고 합니다.
VQA-CP와 같이 데이터셋 관점에서 편향을 제거하는 갈래가 있었고, 다르게는 방법론 측면에서 편향을 줄이고자하는 ensemble-based 모델들이 등장하고 있던 시기였습니다. Ensemble-based 방식들은 기본적인 VQA 모델과 질문 텍스트만 입력해서 답변을 내뱉는 question-only 모델로 구성됩니다. Ensemble-based 방식의 단순한 아이디어만 전달드리면 기본 VQA 모델은 제대로 정답을 맞추도록, 반대로 question-only 모델은 질문만 입력받았으니 답을 맞추지 못하도록 하는 방향으로 학습합니다.
이러한 ensemble-based 방법론들이 실제로 편향을 많이 제거하면서 VQA-CP 벤치마크에서 높은 성능을 기록하게 됩니다. 그러나 저자는 단순히 성능이 높음에만 주목하지 않고 강인한 VQA란 무엇일지에 대해 다시 고민해보게됩니다. 결국 저자는 ensemble-based 방법론들도 아직 갖추지 못했으나 강인한 VQA를 위해 반드시 갖춰야하는 두 개의 능력을 아래와 같이 정의합니다.
- Visual-explainable
- Question-sensitive
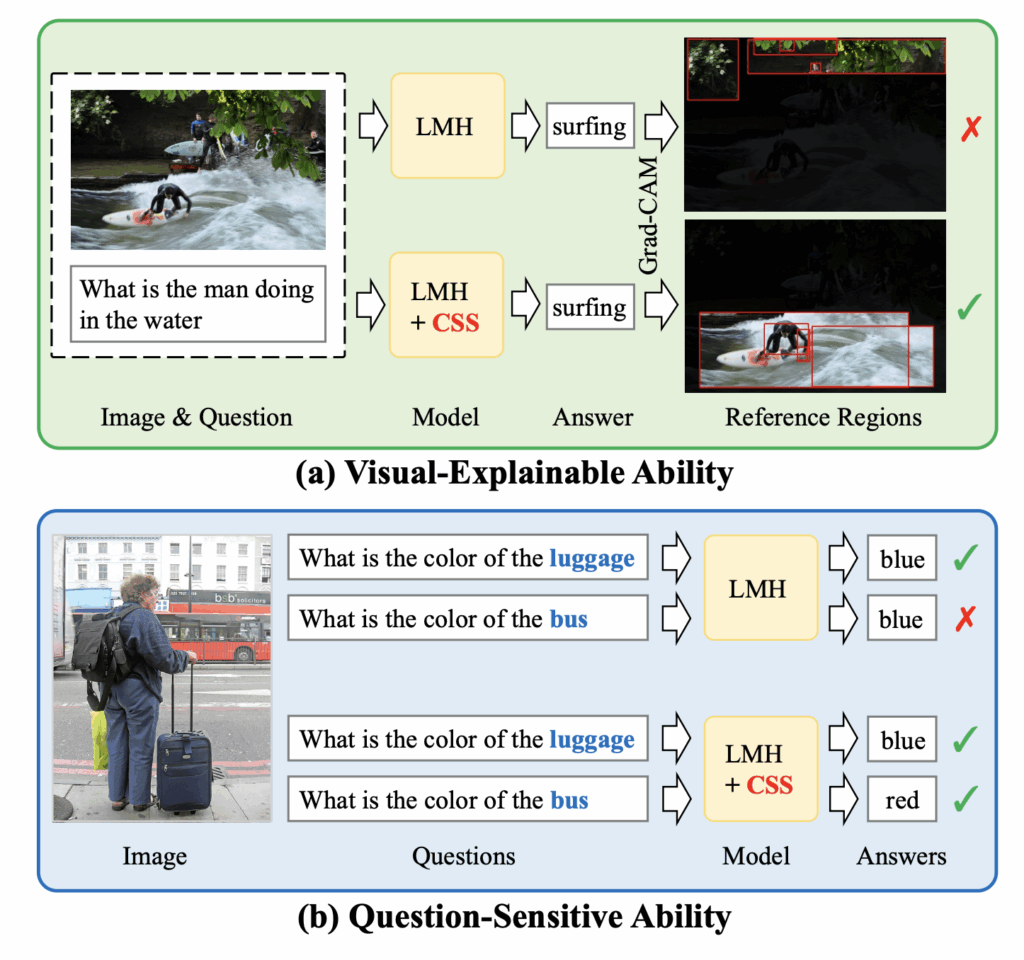
두 특성 중 첫 번째인 visual-explainable은, 모델이 정답을 결정할 때 올바른 근거를 가지고있어야 한다는 것입니다. 그림 1-(a)를 보면 남자가 서핑하고 있는 이미지에서 “남자가 무엇을 하고있는지”에 대한 답을 내기 위해 기존 모델 LMH의 답변과, LMH와 저자가 제안하는 CSS를 함께 붙여썼을 때의 답변을 보여주고 있습니다. 둘 다 “surfing”이라는 결과를 잘 내고 있지만, Grad-CAM을 살펴보면 기존 모델은 실제 서핑과는 관련 없는 이미지 상단의 나무 영역에 집중하는 것을 볼 수가 있습니다. 정답은 어찌저찌 맞았지만 올바른 reasoning 과정을 거쳤다고 보기 어려운 상황입니다.
두 번째 특성은 question-sensitive입니다. 사실 이 부분이 제가 개인 연구에서 보고있는 부분과 완전히 일치하는데, 그림 1-(b)에서 볼 수 있듯, 문장에서 한 단어만 바꿔 물어보았을 때 답변 또한 올바르게 바뀌어야 한다는 것입니다. 이를 통해 모델이 지금까지 단순한 문장 구조와 답변의 correlation이 아닌 개별 문장을 정말로 “잘 이해”하고 있었는지 알아볼 수 있습니다. 마찬가지로 기존 모델은 질문이 바뀌어도 “blue”라고 답하지만 CSS를 붙이면 각 질문에 맞는 답을 잘 출력하는 모습을 볼 수 있습니다.
이러한 상황속에서, 저자는 두 특성을 개선할 수 있는 model-agnostic Counterfactual Samples Synthesizing (CSS) 방법론을 제안합니다. CSS는 구조나 loss가 복잡한 ensemble-based 방법론들보다 훨씬 간단하며, 심지어는 plug-and-play 방식으로 이미 존재하는 방법론의 visual-explainable, question-sensitive 능력을 개선할 수 있게 해줍니다.

CSS는 이름 그대로 편향을 제거해줄 수 있는 counterfactual 샘플을 합성하고 이를 학습하는 방법론으로, 그림 2에서 볼 수 있듯 V-CSS와 Q-CSS 두 가지로 나뉩니다. V-CSS는 질문은 그대로 두고 이미지와 GT 정답을 수정합니다. 질문에서 “tie”가 중요하다면 “tie”를 가린 counterfactual 이미지를 생성하고, GT를 원래 답과 다르게 설정하는 것입니다. 반대로 Q-CSS는 이미지는 그대로 두고 질문과 GT 정답을 수정하는 방식으로 합성 샘플을 구축하여 학습합니다. 질문에서 핵심 단어(명사)를 찾아 “[MASK]” 토큰으로 가리고 정답도 다르게 설정하는 것입니다.
위와 같은 합성 샘플로 학습하며 모델이 핵심이 되는 객체 (visual-explainable) 및 단어(question-sensitive)에 집중하도록 만들어주는 것입니다. 일단 CSS가 일종의 데이터 합성을 통해 모델의 detail한 표현력을 개선하는 방법론이라는 정도만 보고 자세한 내용은 뒤에서 알아보겠습니다.
2. Approach
VQA 수행을 위한 기본 annotation을 정의하면서 시작하겠습니다. 데이터셋 \mathcal{D} = \{I_{i}, Q_{i}, a_{i}\}_{i=1}^{N}는 이미지 I, 질문 Q, 정답 a triplet으로 구성됩니다. 편의상 i는 표기에서 생략하고, VQA task는 mapping 함수 f_{vqa}: \mathcal{I} \times{} \mathcal{Q} \to{} [0, 1]^{|\mathcal{A}|}를 학습하는 것이 목적입니다. 전체 정답 중 현재 이미지와 질문을 가지고 각 정답의 확률 분포를 내뱉는 것입니다.
2.1 Preliminaries
먼저 CSS를 적용할 베이스라인 모델 UpDn과 앞서 언급했던 ensemble-based 모델을 하나씩 정리해보겠습니다.
Bottom-Up Top-Down (UpDn) Model
UpDn 모델은 입력된 각 이미지 I를 이미지 인코더 e_{v}에 태워 object feature V = \{v_{1}, \cdots{}, v_{n_{v}}\}를 추출합니다. 단일 이미지의 특징을 뽑는 것이 아니라 object detection의 결과물처럼 이미지 내 객체의 특징을 추출한다는 것이 특이하네요. 다음으로 입력된 질문 Q 또한 텍스트 인코더 e_{q}에 태워 단어 feature Q = \{w_{1}, \cdots{}, w_{n_{q}}\}를 추출합니다. 최종적으로는 두 feature를 활용해 정답의 확률 분포를 아래 수식 (1)과 같이 출력합니다.

f_{vqa}()는 일반적으로 attention 연산으로 구성되고, 분류이기 때문에 CE Loss로 학습됩니다.
Ensemble-Based Models
앞서 설명드린대로 ensemble-based model은 단어-정답 편향을 제거하기 위해 question-only model을 사용합니다. 이러한 형태의 모델들은 아래와 같은 알고리즘으로 task를 수행합니다.

알고리즘 1의 5번 줄에서 question-only 모델의 예측을 얻고, 6번 줄에서 두 모델의 분포를 merge(M)하여 학습합니다. 추론 시에는 원래의 VQA 모델만 활용합니다.
CSS는 학습에 들어가는 (I, Q, a)를 변경시키기에 모델이 어떠한 구조를 갖든 plug-in 방식으로 적용할 수 있습니다.
2.2 Counterfactual Samples Synthesizing (CSS)
어떠한 VQA 모델이든, CSS는 입력 triplet (I, Q, a)에 대해 아래와 같은 과정을 수행합니다.
- Original 샘플 (I, Q, a)로 모델 학습
- V-CSS 또는 Q-CSS로 각 모달리티의 counterfactual 샘플 (I^{-}, Q, a^{-}) 또는 (I, Q^{-}, a^{-}) 생성
- Counterfactual 샘플로 모델 학습

결국 각 모달리티의 counterfactual 샘플을 어떻게 생성하는지가 핵심이고, 이는 위 알고리즘 2에 나타나있습니다. 3번 줄에서 0~1 사이 값을 uniform sampling한 뒤 \delta{}값에 따라 확률적으로 V-CSS 또는 Q-CSS를 수행하고 있는데, 여기서 \delta{}는 0.5입니다. 즉 랜덤으로 둘 중 하나의 기법이 적용되는 것이고, 각 방식에 대해서는 아래에서 이어 설명드리겠습니다.
2.2.1 V-CSS
V-CSS의 목적은 입력 질문에 대해 counterfactual한 이미지를 만들고, 그에 맞게 답을 수정하여 학습함으로써 진짜 이 질문에 답하기 위해서는 어떤 객체를 봐야하는지 알려주는 것입니다. 그림 2에서 보았듯 이미지에 남자의 넥타이가 없다면 적어도 실제 정답인 “초록색”을 내뱉지 않도록 학습한다는 것입니다.
이 과정은 알고리즘 2의 5-8번 줄에 해당합니다. 입력 샘플의 이미지와 정답을 counterfactual하게 변경해주는 기법입니다. V-CSS는 아래 단계로 구성되고, 각 단계가 5-8번 줄 하나하나에 해당합니다.
- Initial objects selection (IO_Sel)
- Object local contributions calculation
- Critical object selection (CO_Sel)
- Dynamic answer assigning (DA_Ass)
1) Initial Object Selection (IO_Sel)
주어진 정보를 활용해 이미지에 대한 counterfactual 샘플을 만들기 위해서는 먼저 이미지의 어느 객체(영역)이 중요한지 알아야 합니다. VQA 과정 중 주요 객체에 대한 counterfactual 샘플을 만들고 학습해야 효과가 가장 크겠죠. 이를 위해 아래와 같은 과정으로 문장 내 명사와 유사한 객체 영역 특징을 선별합니다.
본 과정의 목적은 정답과 관련있을법한 객체들만 추린 후보 집합 \mathcal{I}를 만드는 것입니다. 이를 위해 먼저 질문 문장 내 단어들에 대한 POS tagging (SpaCy 라이브러리 활용) 후 명사 단어만을 가져옵니다. 그리고 각 object feature에는 그 object의 클래스 이름이 함께 존재하는데, 이 클래스 이름과 질문 문장 내 명사들의 GloVe feature를 뽑고 cosine 유사도를 계산합니다. 이 유사도를 \mathcal{SIM}이라 칭하며, \mathcal{SIM}에서 top-|\mathcal{I}|개의 객체를 후보 집합 \mathcal{I}로 가져갑니다.
2) Object Local Contributions Calculation
본 단계에서는 후보군 Object set \mathcal{I} 중 정말 질문과 관련있을 듯한 객체를 거르기 위해 객체별로 local contribution을 계산합니다. 이 때 Grad-CAM 기법을 차용해 \mathcal{I}에 속한 각 객체의 중요도 score는 아래 수식 (4)와 같이 구해줍니다.
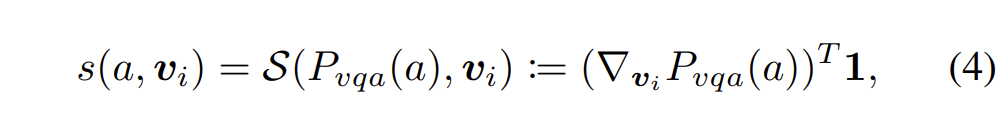
객체가 GT 정답 결정에 많은 기여를 하였을수록 높은 score를 주는 것입니다.
3) Critical Objects Selection (CO_Sel)
수식 (4)에서 뽑은 contribution scores s(a, v_{i})가 가장 큰 Top-K개를 가져와 실제 counterfactual 샘플 생성에 관여할 critical object set I^{+}를 구축합니다.

여기서 critical object의 개수 K는 위 수식 (5)를 만족하는 가장 작은 정수로, 이미지마다 달라집니다. 수식 (5)에서 \eta{}=0.65로, 후보군 \mathcal{I} 내 65% 가량의 객체들을 선택한다고 볼 수 있습니다.

위 그림 3은 V-CSS 과정을 거쳐 얻은 counterfactual 이미지를 보여주고 있습니다. 명사 “kite”와 관련된 영역 집합 (I^{+})가 가운데 그림과 같다면, I^{-}는 정확히 그 반대, 즉 I에서 I^{+}를 제외한 객체들로 구성됩니다.
4) Dynamic Answer Assigning (DA_Ass)
앞서 그림 2에서는 이미지 내 남자의 넥타이를 가린 뒤 정답 또한 “NOT green”으로 바꾸는 것처럼 표현되어있었지만, VQA는 정해진 리스트 내에서 정답을 분류하기 때문에 실제 이렇게 학습시키는 것은 불가능합니다. 그렇다고해서 모델이 만들어낸 counterfactual 이미지를 일일이 보며 확실한 오답을 매핑하는 것도 불가능하겠죠.
결국 DA_Ass 단계에선 모델이 counterfactual 이미지 I^{-}와 원본 질문을 보고 절대 내뱉어서는 안되는 답을 이 셋의 라벨로 지정해주게 됩니다. 이 단계는 아래 알고리즘 3과 같이 동작합니다.

먼저 학습중인 모델을 no_grad()로 돌린 뒤 핵심 object가 포함되어있는 이미지와 원본 질문 셋 (I^{+}, Q)을 입력하여 확률 분포 (P_{vqa}^{+})를 얻습니다. 이상적인 상황이라면 모델은 object-centric한 이미지를 볼테니 실제 정답과 유사한 순서대로 확률 분포를 만들어낼 것입니다. 색깔에 대한 질문이라면 “green”, “blue”, “red”, … 순서대로 확률 분포가 생성되겠죠.
이 P_{vqa}^{+}의 분포 기준 Top-N 객체들은 만약 모델이 counterfactual 샘플 I^{-}, Q를 봤다면 절대로 내뱉어서는 안되는 질문입니다. 여기서 a^{-}, Q의 할당은 알고리즘 3의 5번 줄과 같습니다. 일단 VQA는 질문마다 답이 하나로 정해져있지 않고, 여러 annotator들이 라벨링해둔 답을 집합처럼 사용한다고 합니다. 예를 들어 annotator가 10명이면 한 샘플의 GT도 10개 원소를 갖는 리스트인 것입니다. 여기서 확률분포 top-N개에 포함되는 원소는 전체 GT 리스트에서 제외시킴으로써 a^{-}, Q를 만드는 것입니다.
2.2.2 Q-CSS
Q-CSS의 동작 과정도 알고리즘 2에 모두 나타나있습니다. 목적은 V-CSS와 마찬가지로 답변 결정에 중요한 역할을 하는 단어를 찾아 [MASK] 토큰으로 대체해 counterfactual sample을 만드는 것입니다. 우선 단어는 개수가 그렇게 많지 않으니 11번 줄에서 바로 score 계산 후 12번 줄에서 critical word를 골라내게 되고, 이 단어를 기준으로 질문 Q^{+}, Q^{-}를 만듭니다. 다음으로 13번 줄에서 V-CSS와 유사한 결의 정답 할당 방식을 활용합니다.
1) Word Local Contribution Calculation

본 단계에서도 수식 (4)와 동일하게 Grad-CAM 방식으로 단어별 기여도를 계산합니다.
2) Critical Words Selection (CW_Sel)
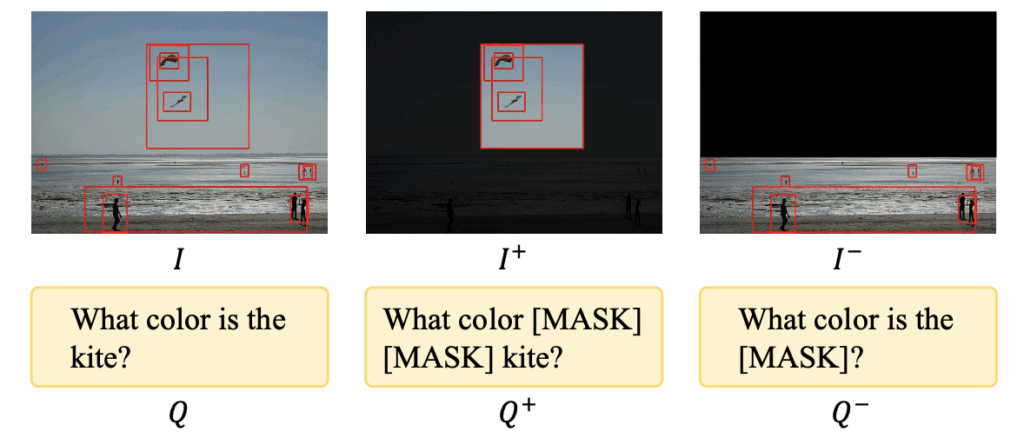
지금 학습 및 평가에 활용중인 VQA-CP 데이터셋에는 문장별 type 정보가 같이 표시되어있습니다. 그림 3을 다시 보시면, 질문이 counting 관련이라면 문장에서 “What color”는 답변 결정에 큰 영향을 미치지 않는다고 판단하여 마스킹할 후보에서 제거합니다. 그럼 남은 단어 요소인 “is the kite”에서, 수식 (6)에서 뽑은 score 기준으로 critical word를 Top-K개 선정합니다. 다시 예를 들어 “kite”가 critical word로 선정되었으면 그림 3 가운데처럼 Q^{+}는 kite만 살린 문장, Q^{-}는 “is the”만 살린 문장으로 만들어주는 것입니다.
3) Dynamic Answer Assigning (DA_Ass)
여기선 앞서 만든 Q^{+}, Q^{-}에 대한 정답을 만들어야하고, 이는 알고리즘 3과 완전히 동일하게 동작하여 설명을 생략하겠습니다.
3. Experiments
3.1 Ablative Studies
3.1.1 Hyperparameters of V-CSS and Q-CSS
V-CSS와 Q-CSS에 들어가있는 하이퍼파라미터에 대한 ablation 실험을 몇가지 진행하였으며, 실험은 기존 ensemble-based 방법론인 LMH에 CSS를 얹는 상황에서 진행되었습니다. 모든 하이퍼파라미터 ablation 성능은 아래 그림 4에 담겨있습니다.
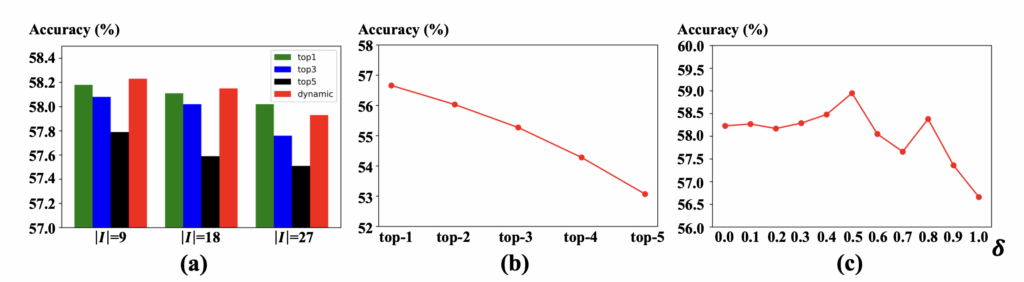
그림 4-(a)는 V-CSS의 Initial Objects Selection 과정에서 추리는 객체의 개수 |\mathcal{I}| 관련 실험 결과입니다. 전체 객체 중에서 더 많은 객체를 inital set에 넣는 경우, 즉 |\mathcal{I}|가 클수록 성능이 점진적으로 떨어지는 모습을 볼 수 있습니다. 실제 가려줄 대상인 critical object도 이 |\mathcal{I}|에 0.65 비율만큼 추리기에 너무 많은 수의 객체를 이 셋에 포함시키면 노이즈 객체들이 많아져 발생하는 현상으로 보입니다. 또한 V-CSS는 0.65 비율만큼의 단어를 critical object로 두게 되는데, 이러한 dynamic 방식이 아닌 고정된 1, 3, 5개의 객체를 critical로 지정하는 경우 제안하는 dynamic에 비해 성능이 떨어지는 것을 볼 수 있습니다.
그림 4-(b)는 Q-CSS에서 [MASK] 토큰으로 대체할 기존 단어의 개수에 따른 ablation 실험 결과입니다. 최종적으로는 문장 내에서 단 한 개의 단어만을 바꾸는 것이 가장 높은 성능을 달성하였고, 아무래도 가리는 단어가 많아질수록 [MASK] 토큰도 어느 방향으로 학습되어야할지 모호해지는 부분이 있어 성능이 점점 크게 떨어지는 것 같습니다.
그림 4-(c)는 \delta{}값에 대한 ablation 실험 결과입니다. \delta{}는 알고리즘 2에서 현재 샘플에 대해 V-CSS를 적용할지, Q-CSS를 적용할지 결정해주는 확률 threshold로, 정확히는 V-CSS가 실행될 확률이라 보시면 됩니다. 결국 둘을 반반으로 사용했을 때가 성능이 가장 높음을 알 수 있습니다.
추가로 신기하게도 \delta{}가 0.0일 때, 1.0일 때보다 훨씬 높은 성능을 보이고 있습니다. 0.0이면 V-CSS만을, 1.0에 가까워질수록 Q-CSS를 섞게되는데, 아무래도 visual 쪽 정보가 조금 더 풍부하다보니 편향 제거 시 visual 정보를 건드리는 것이 더욱 효과적임을 확인할 수 있었습니다.
3.1.2 Architecture Agnostic
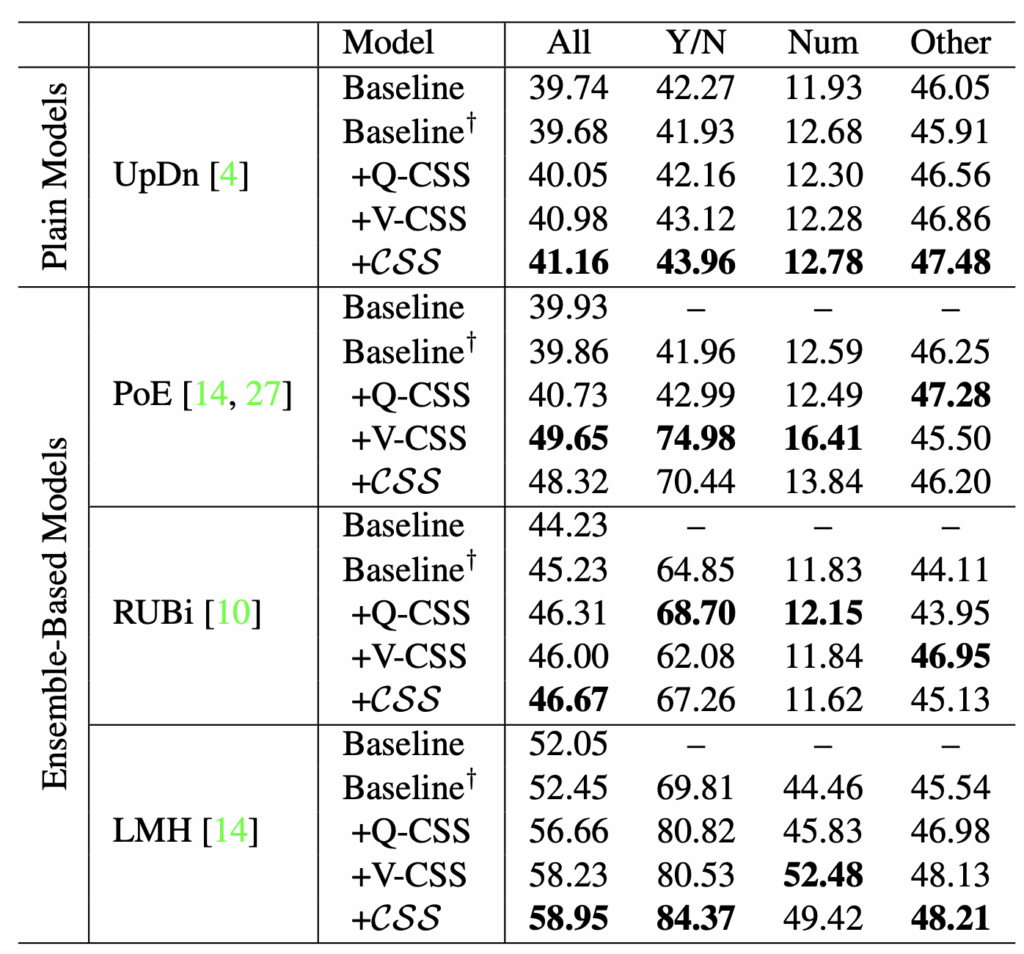
표 1은 VQA-CP v2 데이터셋에 대해, CSS를 어느 방법론에 붙이든 agnostic하게 성능이 오름을 보여줍니다. \dagger{} 표시는 저자의 reimplementation 성능을 의미합니다. Plain model인 UpDn에 적용해도 베이스라인 대비 성능이 상승하나, 질문과 답변의 spurious correlation을 제거하는 목적으로 설계되어있는 Ensemble-based 방법론들에 CSS를 적용했을 때의 성능 향상 폭이 확실히 큰 것을 볼 수 있습니다. 이를 통해 방법론 관점에서 뿐만 아니라 CSS와 같은 데이터 관점에서의 편향 제거를 함께 해주는 것이 유의미함을 알 수 있었습니다.
3.2 Comparisons with State-of-the-Arts
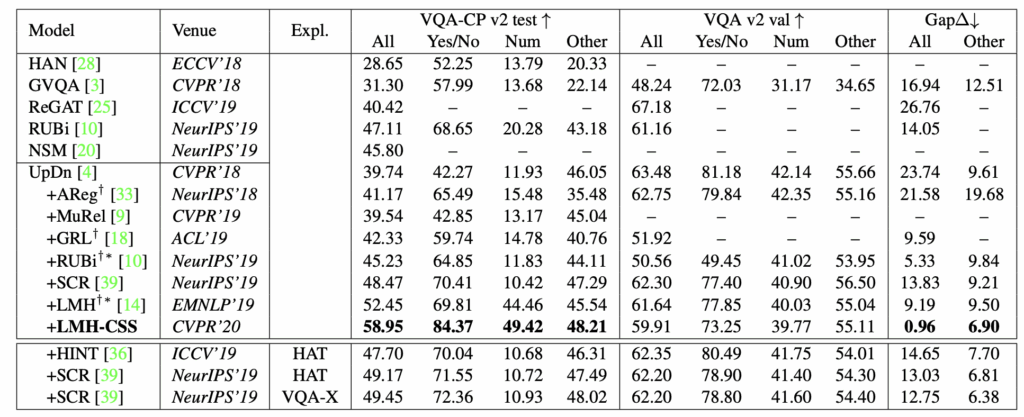
표 3은 VQA-CP v2, VQA v2 데이터셋에서 기존 방법론들과 CSS의 성능 비교를 보여주고 있습니다. UpDn을 베이스라인으로 삼는 모델들과 그 중 LMH에 CSS를 붙인 LMH-CSS 성능이 나타나있습니다. 추가로 ExpL이 표기되어있는 방법론들은 human annotation이나 explanation을 추가로 활용한 것입니다.
VQA-CP v2 데이터셋에서 LMH-CSS는 기존 LMH의 평균 성능을 6% 이상 올리며 압도적인 SOTA 성능을 달성하고 있습니다. 다만 편향이 존재하는 VQA v2에서는 타 방법론들에 비해 상대적으로 낮은 성능을 보이고있는데, 저자는 실질적으로 이 절대적 성능보다는 일반 VQA와 VQA-CP 데이터셋간 성능 차이를 보아야한다고 강조합니다.
즉 VQA v2에선 성능이 잘 나오지만 VQA-CP v2에선 성능이 크게 떨어지는 기존 방법론들은 편향에 의존하였을 뿐 분포가 달라지면 성능이 무너진다는 의미인 것이죠. 가장 오른쪽 열에 표시되어있는 성능 Gap 관점에서 LMH-CSS가 가장 적은 편차를 보이며 일반성을 가진 모델임을 증명하고 있습니다.
3.3 Improving Visual-Explainable Ability
여기서부터는 저자가 맨 처음 VQA 모델이라면 갖춰야한다고 강조한 두 가지 특성 Visual-Explainable과 Question-Sensitive 능력에 대해 살펴봅니다. 먼저 Visual-Explainable 부분입니다. 이 특성을 증명하는 과정에서 먼저 두 가지 질문을 던집니다.
Q1: Can existing visual-explainable models be incorporated into the ensemble-based framework?
Q2: How does CSS improve model’s visual explainable ability?
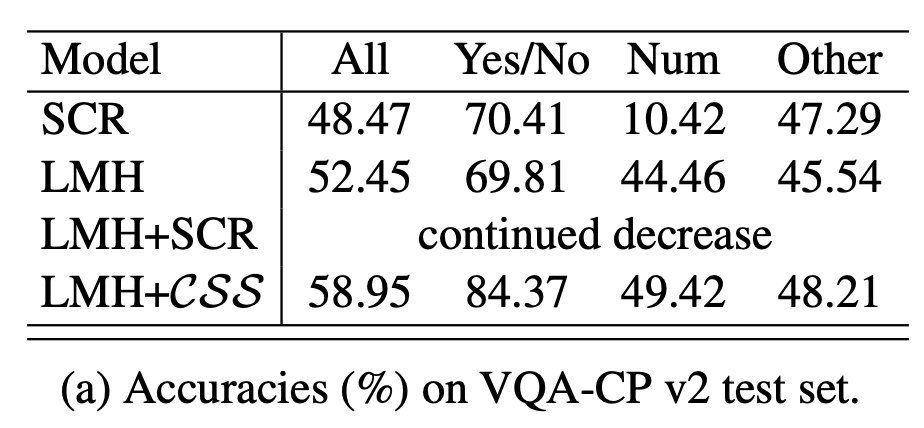
먼저 Q1은 visual-explainable 능력을 강화하는 다른 방법론들 대비 CSS가 왜 그들보다 우수한지 보여주기 위해 나온 질문입니다. 이에 대한 답을 얻기 위해 SOTA visual-explainable 강화 기법인 SCR(Self-critical reasoning for robust visual question answering. NeurIPS, 2019)을 LMH에 붙입니다.
다만 그 당시까지의 visual-explainable 강화 방법론들은 GT object가 필요하고 이를 학습 후에 붙여 쓰기에 end-to-end가 아니었습니다. 그래서 학습을 마친 LMH에 SCR을 붙여 학습을 이어가게 되는데, 위 표 4-(a)에서 볼 수 있듯 LMH+SCR은 학습 직후부터 기존의 성능이 떨어진다고합니다. 그러나 LMH+CSS는 학습이 완료된 모델에 대해 추가 학습을 진행해도 원래의 성능을 향상시키며 더욱 joint한 방법론임을 강조합니다.

다음으로 Q2는, 질문 그대로 CSS가 어떤 관점에서 기존 모델의 visual-explainable 능력을 개선하는지 확인하기 위해 나온 질문입니다. 결국 V-CSS 과정에서 측정되는 객체와 명사의 유사도 \mathcal{SIM}에 대해, 이 유사도가 높은 객체들이 실제로 중요한 객체였는지 판단해본다는 의미입니다.
그러나 어떤 객체가 답변에 중요한 역할을 하는지에 대한 라벨은 없기 때문에, 간접적으로 수식 (4)의 점수를 활용합니다. 이 점수는 V-CSS 과정에서 뽑은 특정 객체가 정답 예측에 관여하는 gradient 점수였습니다. 이 s(a, v)값이 높은 Top-K개 객체를 가져와 그 객체들의 \mathcal{SIM}을 평균내어 Average Importance (\mathcal{AI}) score를 계산해 비교합니다.
위 표 4-(b)에서 LMH-CSS의 \mathcal{AI} score가 가장 높음을 알 수 있고, 이는 곧 CSS 학습을 통해 모델이 올바른 정답 예측에 관여하는 객체에 집중하며 visual-explainable ability를 개선함을 정량적으로 보여주고 있습니다.
3.4 Improving Question-Sensitive Ability
마찬가지로 CSS 방법론을 question-sensitive ability 개선 관점에서 바라보기 위해 두 가지 질문을 던집니다.
Q3: Does CSS helps to improve the robustness to diverse rephrasings of questions?
Q4: How does CSS improve the model’s question-sensitive abilities?
Q3는 질문이 다양하게 변형되었을 때 CSS 학습을 마친 모델이 어떻게 대응하는지 묻는 질문입니다. 이에 대한 성능을 측정하기 위해 문장을 rephrased 해둔 VQA-Rephrasings라는 데이터셋에서 VQA-CP와 동일하게 스플릿을 분리하여 VQA-CP-Rephrasings 데이터셋을 구축합니다.
이렇게 변형된 질문이 들어왔을 때 모델이 어떻게 대응하는지 보기위해 기존에 제안된 Consensus Score CS(k)를 활용합니다. CS(k)는 대략 여러 개의 rephrased 질문 중 k개 이상의 답변이 실제 GT 정답으로 일관되었을 때를 TP로 보고 측정한 정확도 메트릭이라고 보시면 됩니다.
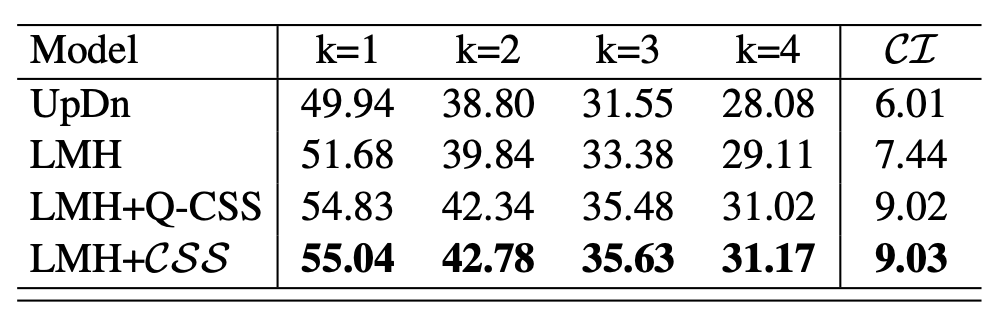
위 표 4-(c)의 좌측에 CS(k)가 나타나있으며 당연히 k가 커질수록 정답 기준이 엄격해지며 성능도 떨어지는 것을 볼 수 있습니다. 이 rephrasing 데이터셋은 하나의 원본 문장에 대해 4개의 rephrased 문장이 있는데, LMH+CSS는 문장이 rephrased 되어도 모두 일관되게 정답을 내뱉은 정확도가 31.17%라는 것입니다. 넷 중 하나만 맞았을 때도 TP라고 하다면 그땐 55.04%의 정확도를 보이는 것이죠. 아무튼 위 표를 통해 CSS가 문장 변형에도 잘 대응하고 의미를 이해하며 가장 높은 성능을 달성하고 있습니다.
마지막으로 Q4는 CSS가 문장의 의미가 바뀌었을 때 민감하게 잘 반응하는지 확인하는 질문입니다. 우선 정량적으로 이 sensitivity에 대한 지표가 없기 때문에, 저자는 아래 수식 (7)과 같이 Confidence Improvement \mathcal{CI} 값을 정의합니다.
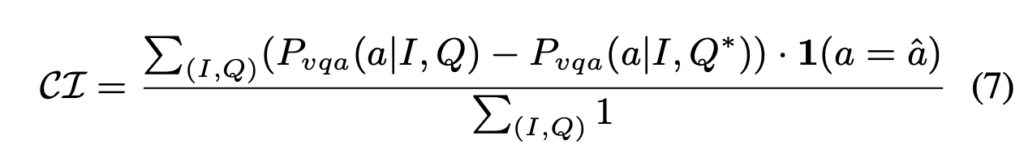
수식 (7)에서 Q^{*}는 문장 Q에서 critical noun을 제거한 문장입니다. 원본 문장 Q와 Q^{*}을 각각 던졌을 때 나오는 GT 클래스의 확률을 빼서 모델이 얼마나 문장 변화에 민감하게 대응하는지 확인하는 지표입니다. \mathcal{CI} 값이 클수록, 즉 모델이 확률을 확 떨어뜨렸을수록 민감하게 반응하는 좋은 현상이라 볼 수 있습니다.
마찬가지로 위 표 4-(c) 오른쪽을 보았을 때 LMH+CSS가 가장 높은 민감도를 보여주며 문장의 사소한 차이에도 명확한 의미 변화를 잘 알아챔을 보여주고 있습니다.
이상으로 리뷰 마치겠습니다.