1. Introduction
최근 대규모 텍스트 코퍼스와 멀티모달 데이터를 바탕으로 학습된 LLM과 이를 시각 모달리티로 확장한 LVLM은 다양한 태스크를 해결하기 위한 표준 모델로 사용되고 있습니다. 이들 모델은 많은 양의 텍스트, 멀티모달 데이터로 사전 학습되면서, 거대한 파라미터 안에 많은 지식을 내재하고 있다는 강점을 갖습니다. 그럼에도 불구하고 이러한 지식은 부정확할 수 있고, 기존 지식이 업데이트 되었을때 사실과 다른 답변을 생성하는 문제가 존재합니다. 이 한계 때문에 external knowledge sources(외부 데이터 소스) 의 필요성이 커졌고, 이를 보완하는 방법론으로 Retrieval-Augmented Generation(RAG)가 소개되었습니다. RAG 프레임워크는 질의와 관련된 정보를 외부 데이터 소스 에서 검색한 뒤, 그 내용을 바탕으로 답변을 생성하는 방식으로 동작합니다.
하지만 지금까지의 RAG 연수는 대부분 텍스트 기반 정보 검색과 텍스트-이미지 쌍을 외부 데이터 소스로 활용하는 것에 초점을 맞춰왔습니다. 최근에는 이 프레임워크에 비디오까지 추가하여 더 넓은 범위의 외부 데이터 소스를 활용하는 연구가 진행되고 있습니다. 하지만 이 연구도 초기 연구이다 보니 몇 가지 한계점이 존재합니다. 구체적으로 2024년에 발표된 ‘Video-rag: Visually aligned retrieval-augmented long video comprehension’, ‘. Drvideo: Document retrieval based long video understanding.’모델은 질의와 관련된 비디오를 먼저 주고 그 비디오 안에서 프레임을 골라 LLM에 입력하는 방식으로 동작합니다. 하지만 일반적인 애플리케이션 상황에서는 어떤 비디오가 질의와 관련되어 있는지가 미리 주어지지 않기 때문에, 이러한 가정은 현실적인 시나리오에서는 한계가 있습니다. 그리고 또 다른 연구들에서는 비디오를 텍스트 형식으로 변환한 뒤에 이를 LLM에 입력합니다. 이러한 텍스트 중심의 접근 방식은 구현이 간편하다는 장점이 있지만 비디오를 텍스트로 변환하는 과정에서 비디오가 가지고 있는 시간적 문맥 정보를 소실한가는 한계가 있습니다.
따라서 본 논문에서는 이러한 한계점을 보완하기 위해, 질의가 주어졌을 때 먼저 질의와 관련된 비디오를 Retrieval한 뒤, 해당 비디오의 시각 정보까지 함께 활용하여 답변을 생성하는 VideoRAG 프레임워크를 제안합니다.
다만 비디오의 시각 정보를 활용할때 몇 가지 어려움이 있습니다. 첫 번째는 비디오는 본질적으로 길고 중복 정보가 많기 때문에, LVLM의 한정된 컨텍스트 길이로 모든 프레임을 처리하는 것은 불가능합니다. 또한 모든 프레임이 검색과 답변 생성에 유용한 것이 아니기 때문에, 불필요한 프레임까지 처리하는 것은 비효율적입니다. 이를 해결하기 위해 저자는 정보량 높은 프레임들만 선택하는 frame selection 모델을 도입하여 비디오 내에서 핵심적인 프레임 서브셋을 추출하도록 해주었습니다.
두 번째 어려움은 비디오를 활용할때 시각 정보 뿐만 아니라 자막과 같은 텍스트 정보를 함께 활용하면 더 높은 정확성을 기대할 수 있습니다. 하지만 실제 환경에서는 이러한 자막이 항상 제공되지 않는다는 문제가 있습니다. 따라서 저자는 이를 해결하기 위해 Automatic Speech Recognition(ASR)을 활용하여 비디오에서 음성을 추출하고 이를 텍스트로 변환해 모든 비디오에 대해 시각,텍스트 정보를 모두 활용할 수 있도록 모듈을 제안합니다.
2. Method
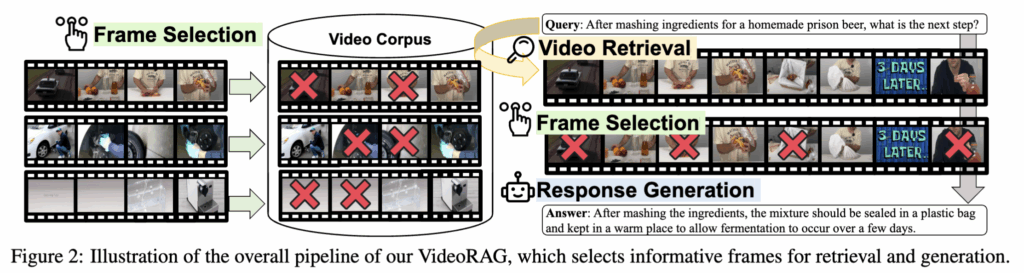
Retrieval-Augmented Generation(RAG)
그럼 먼저 Retrieval-Augmented Generation(RAG)의 일반적인 파이프라인에 대해 말씀드리겠습니다. RAG는 위키피디아(Wikipedia)와 같은 외부 지식 소스에서 관련 정보를 가져와, 검색된 지식을 바탕으로 답변을 생성합니다.
수식으로 살펴보면 질의 q가 주어졌을 때 retrieval 모듈을 사용하여 외부 코퍼스 C로부터 질의와 관련된 문서(또는 지식 단위) 집합 K={k1,k2,…,kk}(이는 문서단위라고 이해하시면 됩니다.) 를 검색합니다.
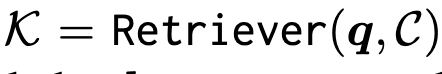
이때 질의 q와 각 지식 k는 각각 토큰 시퀀스 q=[q1,q2,…,qi], k=[k1,k2,…,kj](이는 문서 안에있는 토큰을 의미합니다.) 로 표현됩니다. Retrieval 단계에서는 지식 k와 질의 q 를 하나의 벡터로 인코딩한 후에 유사도를 계산하여 관련성이 높은 몇 개의 문서만 가져옵니다.
이후 generation 단계에서는 이렇게 검색된 지식 집합 K를 질의와 함께 LLM에 입력하여, 최종 답변 y를 생성합니다.

전통적인 RAG는 위와 같이 대부분 텍스트 정보를 기반으로 답변을 생성해왔습니다.
Large Video Language Models
다음으로 비디오가 주어졌을떄 이를 어떻게 처리하는지 설명 드리겠습니다.
비디오 V는 시각 프레임 시퀀스 V=[v1,v2,…,vn], 그리고 자막과 같이 해당 비디오와 연관된 텍스트 정보는 토큰 시퀀스 t=[t1,t2,…,tm] 로 표현할 수 있습니다.
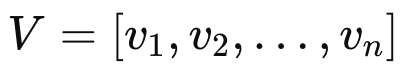
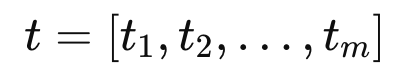
그리고 LVLM은 vision encoder와 text encoder로 구성되어 있어 각각의 모달리티에 대해 임베딩을 생성한 뒤에 이를 입력으로 넣습니다.

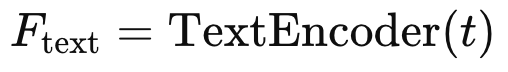
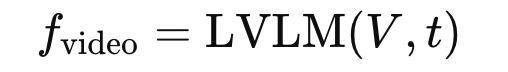
2.2 VideoRAG
그럼 이제 이 논문에서 제안하는 VideoRAG에 대해 알아보겠습니다.
Video Retrieval
이전에 말한 것 처럼 VideoRAG는 질의가 주어졌을 때 비디오 코퍼스를 대상으로 video retrieval을 진행합니다.
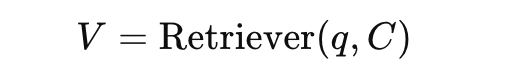
Video-Augmented Response Generation
질의와 관련된 비디오들이 검색된 이후에는, 이 비디오들을 답변 생성 과정에 통합하여, 검색된 비디오에 기반한 답변을 생성하는 단계가 이어집니다. 이를 위해 먼저, 각 비디오에 대해 프레임 시퀀스와 그에 대응하는 텍스트 정보(자막)를 하나의 멀티모달 쌍으로 구성합니다. 그런 다음, 이렇게 얻은 멀티모달 쌍들을 모든 검색된 비디오에 대해 이어 붙이고, 마지막에 사용자 질의 q를 덧붙여 다음과 같은 입력 시퀀스를 만듭니다.
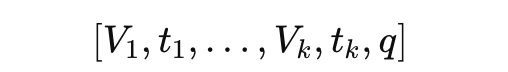
이후에 이 전체 시퀀스를 LVLM에 입력하여 답변을 생성하게 됩니다.
2.3 Frame Selection for VideoRAG
하지만 위 파이프라인을 그대로 사용하기에는 이전에 언급한 것처럼 “비디오의 길고 중복되는 프레임”, “불필요한 프레임” 등의 어려움이 있습니다. 이를 해결하기 위해 저자는 Adaptive Frame Selection과 Frame Space Reduction with Clustering을 도입합니다.
Adaptive Frame Selection
먼저 비디오에 총 n개의 프레임이 있다고 할 때, Comb(⋅)는 전체 n개 프레임 중에서 m개의 조합 서브셋을 선택하는 샘플링하는 함수이고, f(⋅)는 선택된 프레임 서브셋의 유사도를 평가하는 스코어 함수라고 정의합니다. 그러면 retrieval 단계에서의 frame selection은 아래와 같이 표현할 수 있습니다.
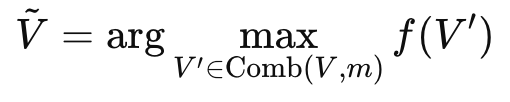
즉, 가능한 여러 프레임 조합들 중에서 f 점수가 가장 높은 서브셋을 선택하는 방식입니다.
Frame Space Reduction with Clustering
하지만 비디오가 많은 프레임을 가지고 있을때 Comb를 활용하여 가능한 모든 조합을 계산하면 계산량이 너무 증가하게 됩니다. 이를 해결하기 위해 저자는 먼저 k-means++ 클러스터링을 사용해 프레임 공간을 reduction하는 전략을 사용합니다. 구체적으로는 비디오의 모든 프레임을 임베딩 공간에서 클러스터링하여 k개의 군집으로 묶고, 각 군집마다 클러스터 중심(centroid)에 가장 가까운 프레임 하나를 대표 프레임으로 선택합니다. 이 과정을 거치면, 원래 n개의 프레임을 가지고 있던 비디오가 이제 대표 프레임 k개로 요약됩니다. 이후 frame selection은 이 축소된 k개에 대해서만 수행하므로 계산량을 훨씬 줄일 수 있습니다.
2.4 Auxiliary Text Generation
그리고 앞서 비디오를 활용할때 시각 정보 뿐만 아니라 자막과 같은 텍스트 정보를 함께 활용한다고 설명드렸습니다. 이를 해결하기 위해 Automatic Speech Recognition(ASR)을 활용하는데 수식은 아래와 같습니다.

여기서 Audio(V)는 비디오 V로부터 오디오를 추출하는 연산이고, AudioToTex는 추출된 오디오를 텍스트로 변환하는 ASR 모듈을 의미합니다. 그리고 원래 비디오에 자막 t가 존재하지 않는 비디오의 경우 오디오로 생성하는게 아니라 원래 자막을 보조 텍스트로 활용합니다.
3. Experiment
이제 실험 파트로 넘어가겠습니다.
Datasets
본 논문에서는 question answering 태스크를 대상으로 VideoRAG를 평가합니다.
먼저, WikiHowQA 데이터셋은 WikiHow 웹페이지에서 수집한 절차(순서나 단계를 물어보는 질문), 방법(어떤 방식으로 하는지) 질문과 이에 대한 답변을 사람이 annotaion하여 제공됩니다.
추가적으로 보다 포괄적인 평가를 위해 HowTo100M 데이터셋에서 LLM을 활용해 질의–응답 쌍을 자동 생성한 synthetic QA 데이터셋을 사용합니다.
그리고 비디오 코퍼스로는 HowTo100M를 사용합니다.
Implementation Details
생성 단계에서 사용하는 LVLM으로는 다음과 같이 3가지 모델을 사용합니다.
- LLaVA-Video (7B)
- InternVL 2.5 (8B)
- Qwen-2.5-VL (3B)
그리고 retrieval 단계에는 InternVideo2를 사용합니다.
retrieval 단계에서는 비디오당 4 프레임만 사용하고, generation 단계에서는 비디오당 최대 32 프레임을 사용합니다. 마지막으로 Auxiliary text generation을 위해서는 Whisper를 사용하여, 비디오 오디오로부터 자막을 생성합니다
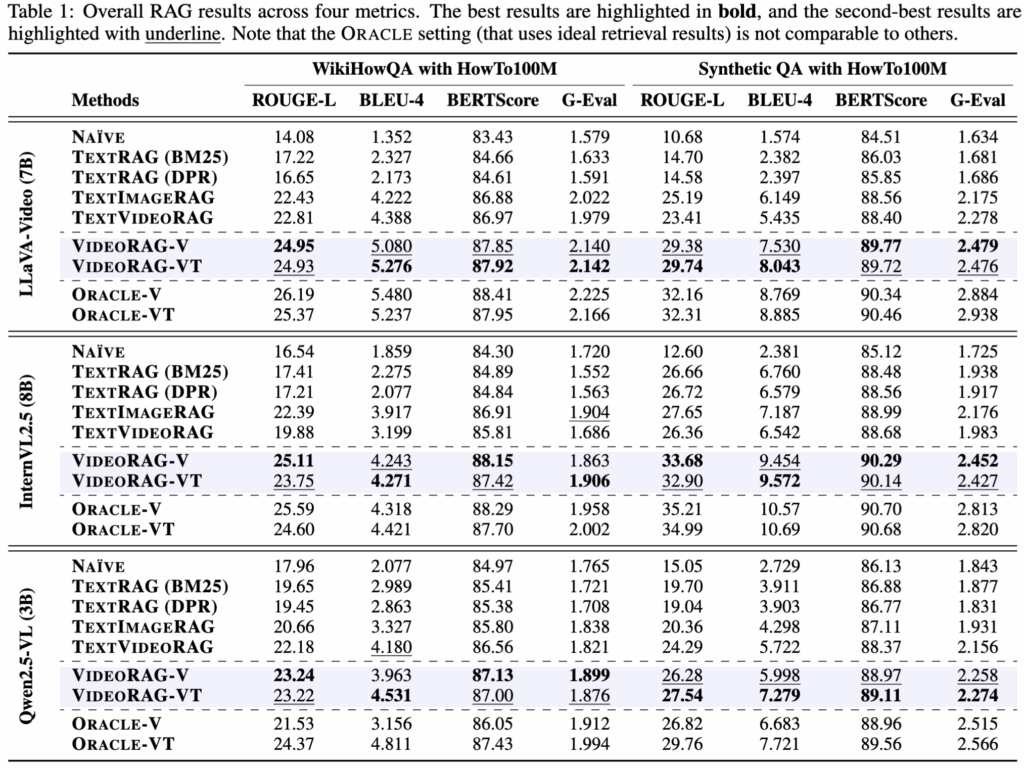
먼저 Table 1의 결과를 살펴보면 모든 RAG 모델이 NAÏVE 베이스라인보다 높은 성능을 보이며 답변을 생성할떄 외부 지식을 활용하는 것이 정확도를 높일 수 있다는 것을 확인할 수 있습니다. 그리고 저자가 제안하는 VIDEORAG는 기존의 텍스트 기반, 텍스트-이미지 기반, 텍스트-비디오 기반 RAG 베이스라인들을 높은 성능을 보이고 있습니다. 저자는 추가적으로 RAG에서 비디오만 사용하는 VIDEORAG-V와 비디오와,텍스트를 모두 활용하는 VIDEORAG-VT 의 성능도 리포팅하는데 답변을 생성할때 비디오의 시각적 특징만으로도 정확도 향상에 도움이 되는 것을 확인할 수 있습니다.
추가적으로 저자는 Retrieval된 비디오의 정확도가 이후 답변 생성에 영향을 줄 수 있다 가정하고 이를 위해 retrival Oracle을 설정하여 리포팅합니다. Table 1에서 Oracle 설정이 가장 높은 성능을 보였고 이를 통해 비디오 retrieval이 더 정교해 질 수록 성능 향상의 여지가 크다는 것을 확인할 수 있습니다.
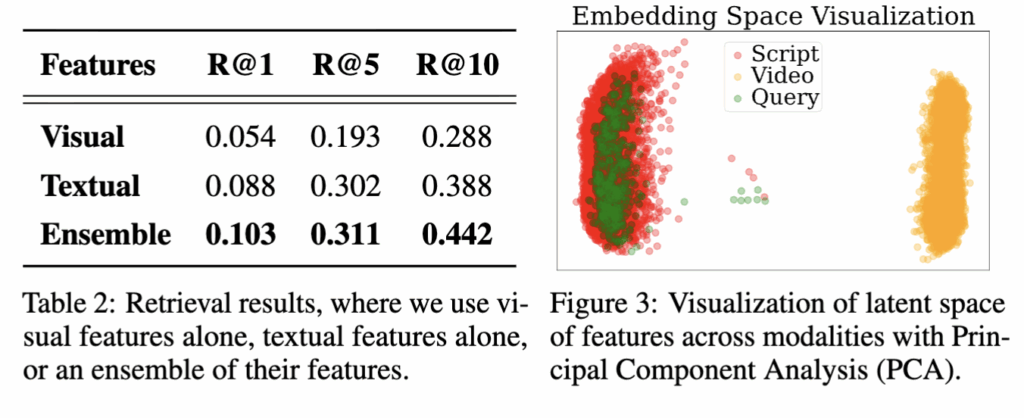
위 테이블 2에서는 비디오 검색을 할 때 텍스트, 시각, 이 둘의 결합하여 retrieval 결과를 비교합니다. 실험 결과, 텍스트 특징이 시각 특징보다 더 좋은 성능을 보이는데, 이는 사용자 질의와 더 강한 semantic aligㅁnment을 이루기 때문인 것 같다고 저자는 분석하고 있습니다. 그리고 Figure 3에서 비디오,자막,쿼리를 임베딩 상에 시각화하였습니다. 보는 것처럼 비디오 특징보다 비디오의 텍스트(자막)이 임베딩 상에 쿼리와 더 근접하고 비디오 특징은 쿼리와 모달리티 갭이 있어 검색 성능이 최적에 미치지 못하는 것을 알 수 있습니다.

위 테이블 4는 Ablation study에 대한 결과입니다. 이를 통해, 텍스트 기반이든 비디오 코퍼스이든 외부 지식을 도입하는 것 자체가 NAIVE 베이스라인 대비 성능 향상을 가져온다는 점을 확인할 수 있습니다. 하지만 일반적인 텍스트 문서(TextRAG)와 비디오를 함께 사용하는 접근법은 오히려 성능이 하락하는 모습을 보였습니다. 이는 텍스트 지식 베이스에서 검색된 텍스트 콘텐츠가 비디오가 제공하는 정보와 중복되거나 상충되는 불필요한 세부 정보 때문일 수 있고 그 결과 이러한 중복·모순 정보가 비디오 정보를 희석시키며, VideoRAG의 효과를 오히려 떨어뜨릴 수 있다고 저자는 분석하고 있습니다.
안녕하세요, 의철님. 좋은 논문 리뷰 감사합니다.
리뷰를 보던 중 의문이 드는 점이 생겼습니다.
프레임을 추려서 LVLM에 넣는 방식이라고 이해했는데, 그렇다면 시간적으로 이어진 영상에서 겉보기에는 중요하지 않아 보이지만 사실은 힌트가 되는 부분을 놓칠 가능성도 있는지 궁금합니다. 또한 이렇게 프레임을 줄이면 영상의 시간적 흐름이나 연관성도 일부 사라질 수 있는지도 알고 싶습니다.
다시 한번 좋은 논문 리뷰 감사합니다.📼