안녕하세요 !
오늘도 video summarization관련 논문에 대해 리뷰해보겠습니다
특히 이번에 다룰 논문은 LLM이 텍스트만 요약하는 게 아니라 비디오 요약도 도와줄 수 있다!!는 아이디어에서 출발한 재밌는 연구입니다
그럼 리뷰 시작하겠습니다 !
Intro
[video summarization]
비디오 요약은 긴 입력 비디오로부터 핵심 정보를 담아 압축하여 짧은 요약 영상을 자동으로 생성하는 task입니다. 하지만 어떤 장면이 요약에 적합한지는 컨텐츠의 종류나 관점에 따라 달라지기 때문에 이 task는 본질적으로 ill-posed하고 주관적인 문제로 여겨져 왔습니다.
따라서 견고한 요약모델을 만들기 위한 가장 직관적인 방법은 모델을 대규모 비디오-요약쌍에 많이 노출시키는 것인데 현실적으로 사람이 요약 영상(pGT)을 직접 만드는 데 비용·시간이 너무 크고 기존 데이터셋(TVSum, SumMe)은 너무 적고 도메인 편중되어 결과적으로 모델이 쉽게 과적합되고 일반화 능력이 제한된다는 문제가 있습니다.
[기존 방법]
기존 연구들은 크게 두가지로 나뉘는데 1) 각 순간을 요약/비요약으로 분류하는 이진분류문제, 2) 각 프레임의 중요도 점수를 예측하는 것 입니다. 하지만 두 방식 모두 본질적인 한계를 가지는데 요약구간이 전체 대비 매우 적어 long-tail의 문제가 심각하다는 것과 모든 프레임을 병렬로 처리하기 때문에 이전 프레임을 요약으로 골랐는지와 같은 정보를 사용하지 못합니다.
따라서 동일한 순간이 반복적으로 선택되는 redundant summary가 발생하게 되고 요약의 흐름이나 맥락적인 구조를 반영하지 못함으로 스토리 구조를 포착하지 못하는 한계가 있습니다.
[Ours]
저자들은 이 논문을 통해 (1) LLM기반 자동 추출요약으로 대규모 데이터셋 생성하고 (2)Autoregressive Summarization Model 제안합니다.
Whisper로 장편 영상의 음성을 텍스트로 전사하여 문장 + 타임스탬프의 형태로 정리한 해당 스크립트를 LLM(GPT 등)에 입력으로 넣어줍니다. LLM은 원문 문장과 타임스탬프 유지한 채 중요한 문장만을 선택하는 추출적 요약을 수행하고, 이렇게 선택된 문장의 타임스탬프로 해당 비디오 구간을 잘라 자동으로 대규모의 pGT 요약 영상을 생성합니다.
또한 요약을 단순한 선택이 아닌 순차적인 생성과정으로, 이전에 생성된 요약 프레임의 feature와 인풋비디오 feature를 조건으로 다음 요약 순간의 feature자체를 autoregressive하게 생성합니다. 이로써 모델은 요약 구간들간의 문맥적인 의존성을 자연스럽게 학습하게되고 중복 요약 문제와 흐름 반영에 대한 문제를 해결하게 됩니다.
또한 멀티모달의 구조이지만 텍스트가 없는 영상도 처리할수 있도록 일부 배치에서 텍스트를 mask토큰으로 대체에 텍스트 유무와 관계 없이 작동하는 범용적인 모델을 제시하였습니다.
Dataset
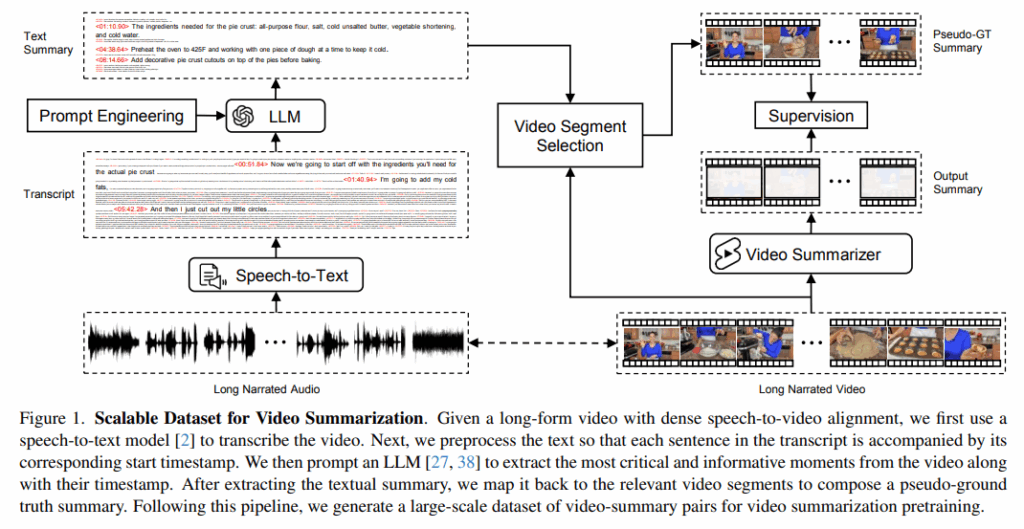
[Source Data]
음성과 영상간의 alignment가 잘 맞는 데이터가 필요하기 때문에 튜브형 How-to 영상으로 구성된 HowTo100M을 사용합니다.
Whisper를 이용해 음성을 텍스트로 변환한 뒤, 변환된 문장과 실제 영상 프레임이 서로 대응하는지 확인하기 위해 CLIP 기반 텍스트–프레임 유사도를 계산합니다. 이때 나레이션이 화면 내용과 전혀 맞지 않는 경우(noise)가 존재할수 있기 때문에 유사도가 낮은 영상은 제거함으로 이후 단계에서 변환된 텍스트(이하 스크립트)와 비디오가 정확히 매핑될수 있도록 말과 화면이 자연스럽게 맞는 영상만 최종 데이터로 남깁니다.
[Prompting LLMs]

이전 단계에서 변환한 비디오 스크립트와 temporal context를 함께 LLM(예. GPT,Llama)에 입력으로 넣어 텍스트 요약을 수행합니다. 이때 요약은 입력 텍스트에서 가장 핵심이 되는 순간들만 선택하는 추출적 요약을 생성하라고 지시하고 해당 문장의 타임스탬프도 함께 유지되도록 명시적으로 지시합니다.
[Pseudo-Ground Truth Video Summary]
추출된 각 문장과 해당 문장의 타임스탬프를 사용하여 비디오에 매칭되는 구간을 찾는데, 이때 타임스탬프의 불일치 문제를 완화하기 위해 해당 구간 내에 CLIP 임베딩 기반의 최근접 이웃 검색(nearest neighborhood search) 을 사용하여 인접한 프레임들을 찾습니다.
이렇게 찾은 프레임들을 시간 순서대로 모아 pseudo-ground truth (pGT)요약 영상을 만듭니다. 저자들은 이 과정을 통해 LfVS-P(250k)라는 데이터셋을 구축했고 비디오 요약 사전학습을 위해 사용됩니다.
기존의 데이터셋과 비교되는 점은 기존 데이터셋 보다 훨씬 크고 평균 영상길이도 길고 다양성 측면에서도 두드러진다고 합니다.
[LfVS-T Benchmark]
모델 성능 평가를 위한 벤치마크(Long-form Video Summarization Testing (LfVS-T))로 사람(전문가)가 수기로 작성한 GT요약과 함께 제공됩니다. 데이터는 유튜브 컨텐츠에서 가져왔고, 나레이션 있는 것 없는 것, 다양한장면 모두 포함됩니다.
Video Summarization Network
- 목적 : 요약으로 예측된 출력v가 요약비디오 pGT와 가깝도록 네트워크를 학습시키는 것
- 입력 : {V,T}
V={X1~Xn} : 영상을 t초마다 균일하게 샘플링한 프레임들의 시퀀스
T={S1~Sk} : 해당 비디오와 연관된 문장(스크립트)의 시퀀스
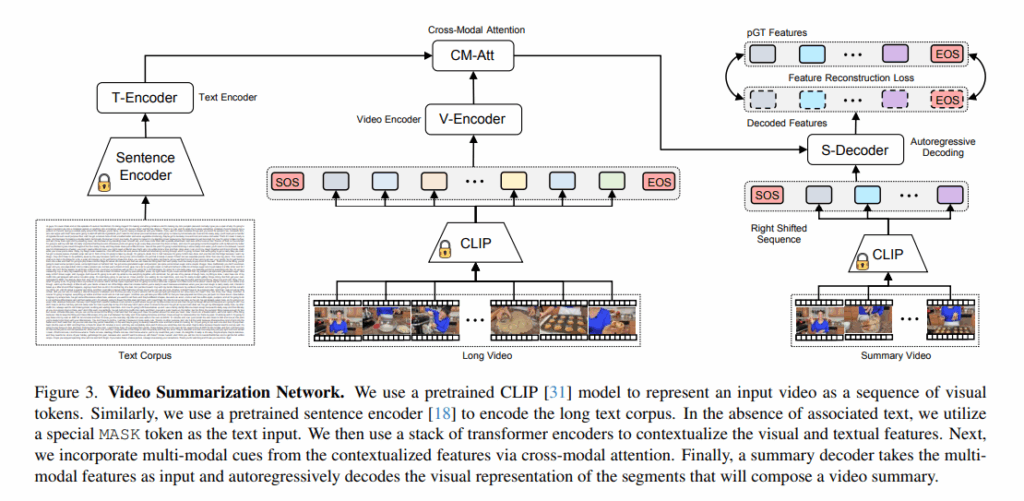
[1. Long Video Encoding (fig3중간)]
- {x1~xn} = CLIP(V)
V={X1~Xn}의 프레임 시퀀스가 입력으로 주어졌을때 사전학습된 CLIP인코더를 사용하여 각 비디오 프레임에 대한 시각 임베딩을 얻습니다. 이 단계를 visual tokenization라고 하고 입력 프레임 시퀀스를 벡터형태의 featrue로 표현된 시각 시퀀스 토큰{x1~xn}를 얻고, 이 시각 토큰을 시퀀스 앞뒤에 각각 [SOS],[EOS]를 붙이고 positional encoding으로 위치정보도 인코딩합니다. - {x̂_i} = V-Encoder({SOS, x1~xn, EOS})
시각 시퀀스 토큰들은 비디오 인코더를 거치는데 이 V-Encoder는 여러 층의 transformer encoder layer로 구성되어 있습니다. 비디오 인코더의 목적은 입력 비디오 시퀀스에 대해 temporal 추론을 수행하는 것입니다. 각 시각 토큰으로 표현된 비디오 모먼트들은 Transformer encoder(=V-Encoder)의 self-attention을 통해 이 프레임들 간의 관계를 학습함으로 문맥화된 비디오 특징 시퀀스를 출력{x̂_i}합니다.
[2. Long Text Encoding (fig3왼쪽)]
- {s1~sk} = SRoBERTa(T)
T={S1~Sk}의 스크립트가 입력으로 주어졌을 때 사전학습 된 LM모델인 SRoBERTa(Sentence Encoder) 사용하여 원본 텍스트를 인코딩된 표현으로 변환하여 문장 임베딩 시퀀스를 출력합니다. - {ŝ1~ŝk} = T-Encoder({s1~sk})
문장 임베딩 시퀀스를 여러 층의 transformer encoder layer로 구성된 text encoder(T-Encoder)에 넣어 문맥적 텍스트 표현을 얻습니다. 이를 통해 텍스트 인코더를 통해 문맥화된 텍스트 표현을 가지게 됩니다. - 저자들은 텍스트가 없어도 되는 프레임워크를 설계하기 위해 학습 과정에서 입력 텍스트를 특정 MASK토큰으로 무작위(0~100%)로 마스킹합니다.
즉, inference시에 텍스트가 없는 비디오가 들어오면 단순히 마스크 토큰을 텍스트의 입력으로 사용하면 됩니다.
[3. Cross-Modal Attention (fig3위쪽)]
- {x̂_ŝ_i} = CM-Att({x̂_i}, {ŝ_j})
비디오-텍스트 입력간의 모달 관계를 포착해서 비디오를 요약하기 위해 Cross-Modal Attention모듈을 사용합니다. 구체적으로는 멀티헤드 어텐션을 변형해서 사용하며 시각 특징을 query(Q)로, 텍스트 특징을 key(K) 및 value(V)로 사용합니다.
즉, 비디오 토큰들이 텍스트 토큰들을 보면서 필요한 context를 가져오는 구조로 이 모듈을 통과하면 텍스트로 조건화된 시각특징이 출력됩니다.
[4. Summary Video Decoding (fig3오른쪽)]
- ŷ_t = S-Decoder({x̂_ŝ_i}, {SOS, y1, …, y_{t–1}})
크로스-모달 어텐션의 출력 features({x̂_ŝ_i})와 t–1까지의 pGT 요약 비디오 시퀀스 입력으로 받아 autoregressive방식으로 비디오 요약을 구성하는 시각 임베딩들을 생성합니다. 여러 층의 transformer decoder layer로 이루어진 S-Decoder를 통과하는데 NLP에서 다음 단어를 에측하는 방식과 비슷하게 다음 요약 순간(next-summary moment) 예측 방식(y1→y2→y3→…→EOS)을 사용합니다.
[Training and Inference]
- L = Σ_{i=1..m+1} |ŷ_i – y_i|²
예측 요약(ŷ1~ŷm)과 pGT 요약(y1~ym) 사이의 feature reconstruction loss를 최소화 하는 방향으로 네트워크를 학습합니다. - Inference시에는 생성된 요약 임베딩들을 입력비디오의 CLIP 임베딩과 최근접 이웃(Nearest Neighbor)방식의 매칭을 통해 생성된 해당 요약 순간에 가장 가까운 실제 비디오 프레임들을 선택하고 이것들을 시간 순서로 이어 붙여 최종 요약 비디오를 생성합니다.
즉, 모델은 비디오를 직접 잘라서 만드는게 아니라 요약으로 뽑을 특징을 생성하고 그 특징에 가까운 원본 비디오 프레임들 중 가장 유사한 CLIP 임베딩을 선택하는 것입니다
Experiment
- 평가 데이터셋 : TVSum, SumMe, LfVS-T(제안한 벤치마크)
- 평가 메트릭 : F1-score, Kendall τ(프레임 쌍 단위의 순서가 얼마나 같은), Spearman ρ(전체적인 중요도 순위가 얼마나 비슷한지,랭킹기반)
[Comparison with State-of-the-Art]
- 제안한 기법과 기존 영상 요약 기법들을 LfVS-P 데이터셋에서 학습시키고 LfVS-T 벤치마크에서 이들의 성능을 평가했으며 아래의 table2와 같이 모든 평가지표에서 기존 최신 기법들에 비해 확실하게 더 나은 성능을 보여줍니다.
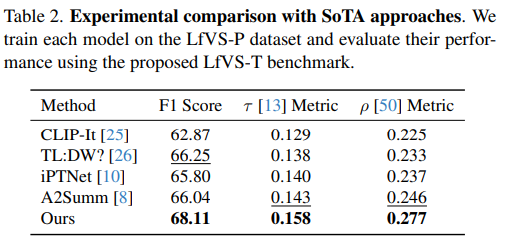
- 제안한 기법과 기존 영상 요약 기법들을 기존의 벤치마크에서 학습하고 평가했고 아래의 table3과 같이 기존의 데이터셋에서도 우수한 성능을 보입니다. 특히 LfVS-P에서 학습한 모델의 제로샷 성능도 기존의 방법급으로 경쟁력 있는 성능을 확인할 수 있습니다. 또한 Kendall τ, Spearman ρ의 지표는 순위기반 지표로 요약의 순서흐름을 잘 만들었는지에 대한 평가인데 저자들의 모델이 해당 지표에서 특히 강하다는 것을 통해 autoregressive 요약 생성 구조가 잘 작동한다는 증거가 됩니다.
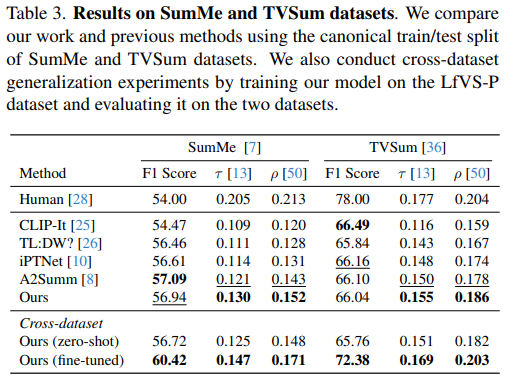
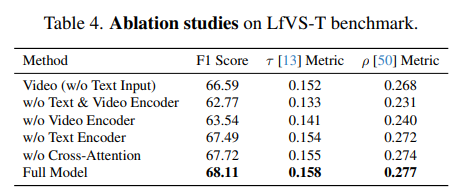
[Ablation Studies]
- Video Summarization Network의 핵심 구성요소들에 대해 ablation 실험을 수행한 결과입니다.
아래의 Table4에서 확인할 수 있듯이 텍스트 입력 없는 모델도 어느정도 성능을 나오는 것을 확인할 수 있으며 Video Encoder와 Text Encoder, Cross-Modal Attention의 모든 구성요소를 가지는 경우 가장 좋은 성능을 보입니다.
특히! 비디오 인코더가 없는 경우에 전체 모델 대비 크게 성능이 떨어지는데 이 비디오 인코더를 거치지 않고는 토큰 간의 시간적,문맥적 관계를 학습하지 못하여 디코더의 요약 생성시 이용하는 context의 질이 낮아지고 이로 인해 요약 성능이 떨어지게 된다고 합니다.
[Experimental Analyses]
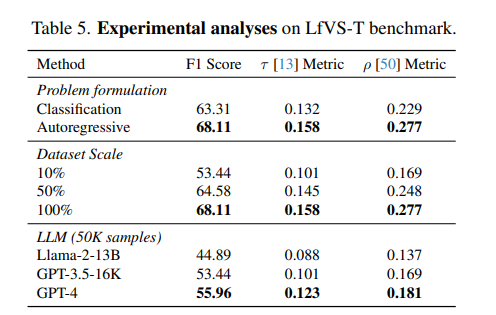
- autoregressive vs Classification
초반에 언급한 요약/비요약으로 분류하는 방법은 해당 분류를 병렬적으로 예측하기 때문에 앞에서 무슨 내용이 요약됐는지를 고려하지 못하고 결국 중복된 순간을 여러번 선택할 수 있거나 영상의 흐름을 다루지 못한다는 단점이 있습니다.
반면에 autoregressive하게 요약을 생성하는 방법은 요약의 흐름(순서)를 직접 모델링 하기 때문에 중복 요약도 방지되고 전체적인 맥락에 맞는 자연스러운 요약을 생성할 수 있습니다. - Dataset Scale
데이터셋 규모와 관련된 지표로 그냥 결국 LfVS-P가 클수록 성능이 계속 좋아지는 것을 확인할 수 있습니다. - LLM
어떤 LLM을 스크립트 요약자로 쓸 것인가와 관련된 지표로 GPT-4 기반 pGT 생성이 가장 좋은 성능을 보이는 것을 볼 수 있습니다.
비디오 요약 관련 task에서 데이터 셋의 양에 대한 문제가 항상 걸림돌처럼 느껴지는데 이 논문은 대규모의 데이터셋을 LLM을 통해 자동으로 추출적 요약을 통해 라벨링 하는것으로 근본적인 데이터 양의 한계를 해결한 것이 굉장히 흥미로웠습니다. 향후 이것보다 더 대용량 데이터셋이 등장할텐데.. 그때 등장할 더 똑똑한 방법은 뭘까요?!!
또한 맥락없이 단순히 중요한 프레임만 몇 개 골라내서 요약으로 합치는게 아닌 autoregressive구도로 이전 요약 순간을 반영하면서 다음 요약을 생성한다는 접근이 멋있는 아이디어라고 느껴졌습니다 !!
리뷰 마치겠습니다 ! 읽어주셔서 감사합니다 🤩
안녕하세요 찬미님 좋은 리뷰감사합니다.
요약 대상 비디오가 입력으로 주어졌을 때, 실제 요약을 생성하는 데 사용되는 모듈이 그림 3의 S-Decoder가 맞는지 궁금합니다.
만약 그렇다면, S-Decoder에서 생성된 요약 임베딩을 사전에 CLIP으로 추출해 둔 비디오 프레임 피처들과 비교하여, 유사도가 가장 높은 프레임들을 선택한 뒤, 이를 시간 순서대로 정렬하여 최종 요약 비디오를 구성하는 것이 맞을까요?
감사합니다.