안녕하세요, 이번주는 로봇 데이터 증강에 관한 논문입니다. 새로운 데이터 취득 없이 기존의 데이터셋을 효과적으로 증강하면 대규모 데이터셋이 더 의미있어 지지 않을까? 하던 와중에 보게된 논문이고 제목처럼 plug and play 방식으로 로봇 데이터 증강을 제안한 논문입니다. 리뷰 시작해보도록 하겠습니다.
Introduction
로봇 모방학습 데이터의 시각적 증강은 정책의 시각적 안정성을 높이는 방법중 핵심적인 방법인데, 기존의 데이터 증강 방법들은 camera calibration이나 크로마키 같은 제약 조건이 강했습니다. 이로인해 plug and play 식으로 손쉽게 활용되지 못했고, 결과물 자체도 배경 이미지나 텍스쳐를 무작위로 적용하는것과 같은 단순한 치환 식의 증강이라 때로는 실제 환경에서 로봇의 성능을 떨어뜨리는 문제도 있었습니다. 저자들은 이러한 문제를 해결하기 위해 RoboEngine이라는 방법을 제안했습니다. 물리적인 제약과 작업의 맥락을 고려해 로봇 데이터의 배경을 생성하는 방식입니다. 해당 방법론은 사전의 환경 세팅이나 조건을 만족하지 않고 plug and play식으로 작동하는 것이 핵심입니다. 더 나아가 저자들은 unseen 환경에서의 성공률 향상도 확인했다고 합니다. 해당 연구의 핵심 contribution을 정리하자면 다음과 같습니다.
- 3800장의 로봇 데이터셋에서부터 얻은 pixel level segmentation된 데이터셋인 RoboSeg를 공개했고, 이를 기반으로 로봇을 segmentation할 수 있는 모델을 학습했습니다.
- 이러한 segmentation 모델과 더불어 로봇의 작업 조건을 반영하도록 finetuning된 Diffusion 기반 배경 생성 모델을 RoboEngine 툴킷에 통합해서 데이터 증강을 수행했습니다.
- 실제 로봇 실험을 통해 RoboEngine의 효과를 검증했습니다. 단일 환경에서 수집한 데모로 학습한 정책을 RoboEngine으로 증강하여 6개의 새로운 환경에서 기존 방법 대비 큰 폭의 성능 향상을 보였습니다.
Related Work
모방학습은 전문가 시연을 바탕으로 로봇 조작 행동을 학습하는 접근법입니다. 그래서 대부분 시각-액션을 기반으로 훈현하는 만큼 환경의 시각적 변화에 민감하여 훈련에 사용되지 않은 새로운 환경이나 배경 변화에서 성능이 쉽게 저하되는 약점을 갖고 있습니다. 이러한 시각적 일반화 문제를 해결하기 위해 보다 강인한 정책 네트워크 구조 제안, 대규모 pretraining을 통한 표현력 향상, 데이터 수집 범위 확대나 합성 데이터 생성을 통한 학습 데이터 다양화 등 다양한 연구가 진행되어 왔습니다. 이떄
특히 로봇 학습 데이터를 직접 수집하는 일은 막대한 시간과 비용이 들며, 다양한 환경마다 데이터를 확보하는 것은 더욱 비현실적이기 때문에, 이를 보완하기 위한 데이터 증강강 연구가 활발히 이루어져 왔습니다. 간단한 이미지 처리 기반의 전통적 증강(crop이나 color jitter등)은 동일 도메인 내의 시각 변화에 대한 강인성은 높여주지만, 새로운 배경이나 물체와 같은 큰 변화를 다루기에는 한계가 있습니다. 이를 위한 대안으로 생성 모델을 활용한 증강 기법들은 이러한 큰 변화에도 대응할 수 있으나, 플러그 앤 플레이 방식으로 사용하기 어렵다는 단점이 있었습니다. 많은 기법들이 전경에 해당하는 마스크를 얻기 위해 크로마키나 정밀한 calibration과 같은 사전 조건을 요구했다고 합니다.
기존 로봇 데이터 증강 기법들은 이러한 현실성 문제를 만족하지 못해 로봇 학습 커뮤니티에서 자리 잡기 어려웠고, 저자들은 이러한 한계를 해결하기 위해 plug and play 형식으로로 RoboEngine 툴킷을 제안했습니다.
Method

간단하게 설명하자면 RoboEngine은 visual demonstration dataset에 새로운 배경을 합성하여 증강 데이터를 생성하는 파이프라인 입니다. 크게는 전경과 배경을 분할하는 것과 데이터 맥락에 어울리는 배경 생성으로 나눌 수 있을 것 같습니다. 이 때 정확한 로봇 마스크를 얻는 것이 기존 방법의 병목이었고, 이를 해결하기 위한 데이터셋과 모델을 새로 구축한 것이 핵심이라고 할 수 있을 것 같습니다.
Task Definition
RoboEngine이 수행하는 증강 작업은 다음과 같이 정의됩니다. 우선 로봇 조작 시연 데이터셋의 각 프레임에 대해, 로봇 팔 부위, 작업 관련 물체들, 배경 영역을 식별하여 segmentation을 진행합니다. 예를 들어 “Put Mouse on the Pad” 작업이라면 로봇 팔 영역(R), 마우스와 패드 같은 대상 객체 영역(O), 그리고 그 외의 배경 영역(B)으로 분리합니다. 그런 다음 배경 생성 모델을 활용해 기존 배경 대신 새로운 가상 배경 B′을 만들어냅니다. 이때 생성되는 배경은 앞서 분할해둔 로봇과 물체 영역을 그대로 유지한 채 합성되며, 생성 과정에서 물리적 제약과 장면에 대한 맥락이 반영되어 로봇 배치 환경과 어울리는 배경이 생성되도록 합니다. 마지막으로 새 배경 B’에 원본의 로봇 R과 객체 O를 합성하여 증강된 이미지 I′=R+O+B′를 얻습니다. 이러한 과정을 통해 원래 시연 데이터셋 D로부터 증강된 데이터셋 D′를 생성하며, D′의 배경 분포가 실제 로봇을 배치하고자 하는 환경에 가까워질수록 로봇 정책의 성능과 일반화 능력이 향상된다고 생각하시면 될 것 같스빈다.
RoboSeg Dataset and Robot Segmentation Model
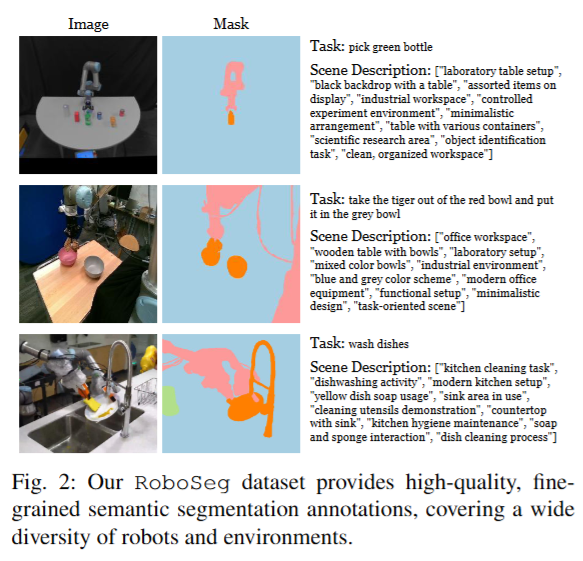
기존의 범용 segmentation 모델들을 바로 활용할 경우 로봇 팔과 주변 물체를 정확히 분리하는 데 어려움이 있었다고 합니다. 실제로 Segment Anything Model (SAM)이나 LISA와 같은 최신 모델조차 로봇 팔을 배경과 혼동하여 잘못 분할하거나, 정확한 마스크를 얻기 위해서는 여전히 녹색 배경이나 카메라 보정 등의 도움을 받아야 했고, 기존의 배경 증강 기법들의 공통된 한계였다고 합니다. 이러한 문제를 해결하고자, 저자들은 RoboSeg라는 새로운 로봇 장면 분할 데이터셋을 구축했습니다. RoboSeg에는 다양한 로봇 데이터 출처 35곳 이상에서 임의로 선정한 3,800장의 이미지가 포함되어 있으며, 로봇 종류(Franka, WidowX, HelloRobot, UR5, Sawyer, xArm 등)와 카메라 뷰, 배경 환경의 다양성을 극대화 해서 만들었다고 합니다.
각 이미지는 픽셀 단위로 세 가지 유형의 마스크로 나누었습니다. (1) 로봇 그리퍼와 연결된 링크인 robot-main, (2) 로봇 베이스 등 그 외 로봇의 나머지 부분인 robot-auxiliary, (3) 작업과 관계된 모든 물체(object)로 라벨링했습니다다. 심지어 로봇의 전선까지 식별될 정도로 세밀한 라벨링을 제공한다고 합니다. 저자들이 extremely fine-grained mask라고 강조했습니다 허허.. 이렇게 로봇 팔과 작업 물체를 완벽히 분리된 형태로 얻은 데이터로 구성했다고 하빈다. 추가로 GPT-4o를 통해 scene에대한 간단한 설명도 추가했다고 합니다. 이렇게 얻은 데이터로 EVF-SAM (Language conditioned Segmentation의 SOTA 모델이라고 생각해주시면 될 것 같습니다.. 아마(?))을 finetuning했습니다. 이렇게 얻은 Robo-SAM 모델은 기존의 로봇 데이터 배경 증강 기법들의 한계인 unseen 상황에서의 전경 분리 작업을 수행할 수 있는 방법을 최초로 제시했다는 점에서 의미가 큰 것 같습니다.
Plug-and-Play RoboEngine Augmentation
RoboEngine의 증강 파이프라인은 전경-배경 분리와 배경 생성 두 단계의 모델을 완전하게 통합하여 하나의 툴킷으로 제공하는 데 중점을 두었습니다. 저자들도 통합된 파이프라인이 코드 몇줄로 그대로 적용할 수 있다는 점을 강조합니다. 먼저 임의의 로봇 학습 데이터의 한 프레임이주어지면, 앞서 학습된 Robo-SAM 모델을 이용해 로봇의 마스크를 추출하고, 동시에 EVF-SAM을 사용해 작업 관련 물체들의 마스크를 얻어줍니다. 전경 영역이 식별되고 나면 이를 제외한 영역에 대해 Diffusion을 사용해 새로운 배경을 만듭니다. 이 때 저자들은 BackGround-Diffusion이라는 text to image 생성 모델을 활용했는데, 이 모델은 전경 마스크를 인식하여 그 주변에 물리적으로 그럴듯한 배경을 생성하는 모델이라고 합니다. BackGround-Diffusion 모델 또한 RoboSeg 데이터로 finetuning 하여 로봇 데이터의 배경에 더 어울리게 했다고 합니다. (대규모 데이터셋에서 3800장을 구해왔음에도 3800장은 모든 장면을 커버하기는 좀 힘든(?) 정도인 것 같습니다. 아니면 tabletop 스러운 장면을 만들게 하는건지,, 요건 좀 더 알아봐야 할 것 같습니다. 이 때 배경 생성 시 참고할 텍스트 설명은 앞서 RoboSeg에 준비된 gpt-4o를 활용한 프롬프트를 사용하고, 이 중 무작위로 하나를 선택해 다양한 장면이 만들어지도록 했다고 합니다. 이와 같이 segmentation 모델과 배경 생성 모델을 결합한 파이프라인을 RoboEngine으로 구현하여, 추가 장비나 복잡한 환경 설정 없이 곧바로 쓸 수 있는 플러그 앤 플레이 툴킷으로 배포했습니다. 아래 예시와 같이 기존의 이미지 증강 라이브러리처럼 정말 간편하게 쓸 수 있음을 재차 강조했습니다. 데이터 증강 파이프라인의 fundamental중 하나라고 말하고있습니다.
기존 데이터셋으로부터 segmentation모델과 diffusion model을 finetuning할 데이터를 만들고, 추가로 학습한 모델들을 하나로 잘 포장해서 배포했다. 라고 이해하시면 될 것 같습니다.
Experiments
저자들은 RoboEngine의 segmentation 모델의 성능부터 전체 증강 효과까지 실험을 진행했습니다. 또한 기존 증강 기법들과의 비교 및 데이터 증강량 변화에 따른 성능 추이 등 다양한 분석을 수행했습니다. (하나의 파이프라인에 대해 여러 실험을 해야 하는 것을 또 느낍니다..)
Segmentation Result
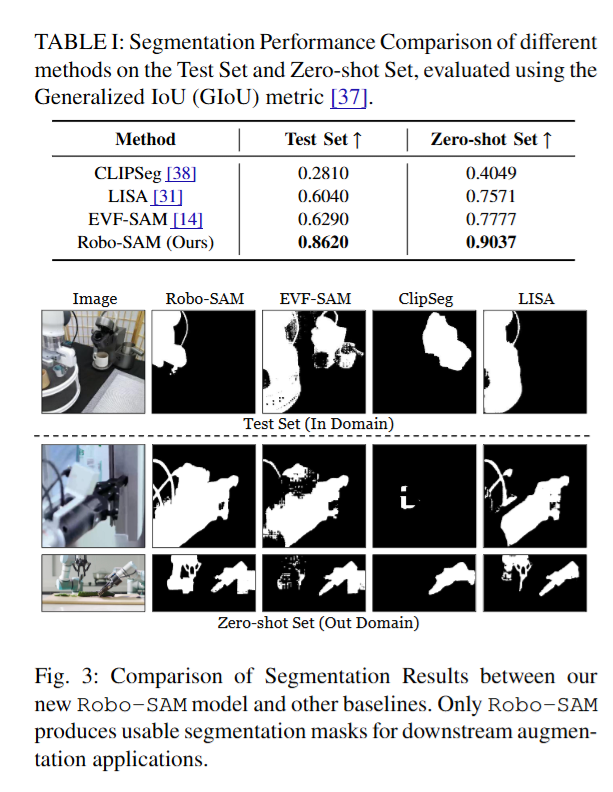
Robo-SAM의 성능을 검증하기 위해 RoboSeg 데이터셋을 구성한 이미지들 중 RoboSeg 학습에 사용되지 않은 새로운 장면 97장을 모은 것과 Zero-shot Set으로, 인터넷에서 임의로 수집한 로봇 조작 장면 이미지 45장으로 구성했습니다. 두 데이터셋에 대해 CLIPSeg, LISA, EVF-SAM 에게 모두 robot이라는 프롬프트를 전달했다고 합니다. 정량적 평가지표로는 예측 마스크와 정답 마스크 간의 GIoU를 사용했습니다.
아래 table1의 결과를 보면 Test Set과 Zero-shot Set 모두에서 GIoU가 상승했습니다. EVF-SAM 뿐만 아니라 기존 segmentation 모델들은 사실상 증강에 활용하기 어려운 수준의 마스크를 내놓았다고 합니다. 이는 이전 연구에서도 지적된 바와 같이, 범용 segmentation 모델로는 로봇 팔 같이 복잡한 구조를 제대로 인식하기 어렵다는 문제를 Robo-SAM이 해결했음을 강조했습니다. 이 때 calibration 없이 높은 로봇 세그멘테이션 능력을 얻어서 다양한 환경에서 플러그 앤 플레이 증강을 가능케 한 토대가 되었다고 합니다.
Augmentation Baselines and Results
저자들은 다양한 이미지 증강 파이프라인에 RoboSeg를 통한 마스크를 전달해 segmentation 이후의 성능 또한 평가를 진행했다고 합니다. Background 방식은 Stable Diffusion v2.1을 사용해 전체 이미지를 새로 생성한 뒤, 생성된 이미지에서 로봇과 물체 영역만 원본으로 교체하는 방식입니다. Inpainting 방식은 SAM-V2로 모든 객체를 세분화 후 그중 작업에 무관한 5개 물체를 선택해 Stable Diffusion 인페인팅 모델로 해당 영역을 배경으로 메우는 방식입니다. ImageNet 방식은 ImageNet 이미지 하나를 무작위 선택해 로봇과 작업 물체를 제외한 모든 픽셀을 치환하는 방식입니다. Texture 방식은 배경을 패턴 기반으로 증강하는 방법입니다. 마지막으로 No aug는 어떠한 증강도 적용하지 않은 원본 데이터로, 다른 증강 방법의 효과를 평가하기 위한 기준(baseline)으로 사용됩니다. 이렇게 보니 최초의 방법론이라 그런지 비교대상들이.. 허허
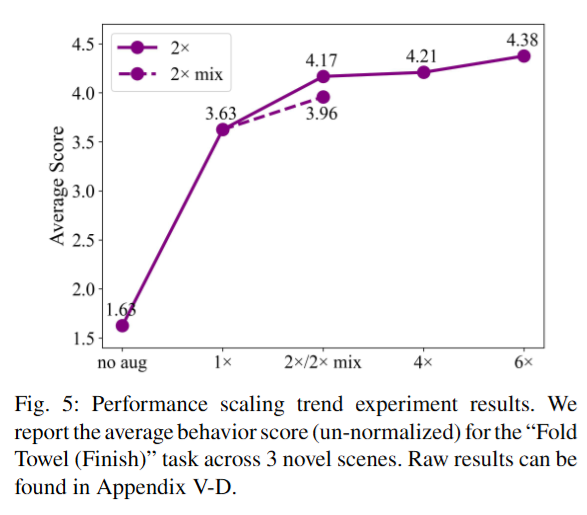
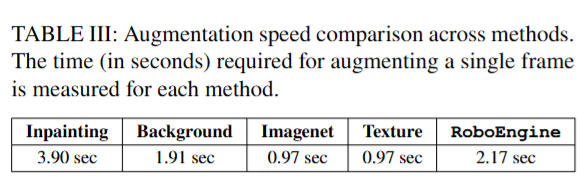
결과를 보면 Inpainting 방식의 경우, 제거할 객체의 선택과 개수 등 하이퍼파라미터에 성능이 크게 좌우되었다고 합니다. 또 프레임당 처리 시간이 가장 오래 걸려 실용성도 떨어졌다고 합니다. 흥미로운 점은 Background, ImageNet, Texture 방식들은 별다른 조건 없이 손쉽게 큰 배경 변화를 줄 수 있지만 위 figure 5를 보면 “No aug” 대비 성능 향상을 보였다고 합니다. (진짜 로봇 데이터 배경은 어떻게 됐던 달라지기만 하면 시각적인 강인함을 갖는것인지..? 아래 figure를 보면 맥락적으론 완전 별로인데도 불구하고 성능이 향상되다니.. Robo Seg 모델의 힘이 느껴지는 부분이었습니다.) 그 중 Texture 증강은 무작위 텍스처로 배경을 바꾸는 간단한 방법임에도 오히려 ImageNet이나 Background 방법보다 효과가 좋았다고 합니다.. 이러한 간단 치환 방식들은 생성 모델을 매번 실행할 필요가 없으므로 증강 처리 속도가 매우 빨라 (0.97초 이내) 대규모 증강이 필요한 경우 유리했다고 합니다. RoboEngine은 물리적 제약을 지키면서도 다양한 새로운 장면을 만들어내기 때문에 최종적인 성능이 가장 높게 나타났습니다. 정성적인 결과를 보면 물론 직접 해봐야 알겠지만 확실히 의미가 있는 것 같습니다.

Table 2의 결과는 다양한 증강 방식으로 학습된 정책을 6개의 새로운 환경에서 평가한 평균 행동 점수와 성공률을 나타냅니다. No aug를 기준으로 각 방법의 성능 향상 폭을 비교할 수 있었습니다. 평가지표중 good grasp의 경우 저자들이 동작을 할 때 최적의 파지점을 정하고 해당 지점을 중심으로 일정 영역을 두고 얼마나 가깝게 파지했나를 기준으로 잡았다고 합니다.
앞서 말했듯 어떤 형태의 증강이라도 적용하면 성능이 크게 향상되었으며, 그중 RoboEngine이 평균 점수 0.62, 성공률 60.9%로 No aug 대비 210% 이상의 개선을 기록하며 가장 우수한 성능을 보였습니다. 또한 Texture 증강 등 기존 최고 기법 대비 약 20% 더 높은 점수를 달성했습니다. 저자들은 이러한 부분이 RoboEngine이 실제 로봇이 마주할 수 있는 다양한 장면 구성을 물리적으로 일관되게 생성하는 부분이라고 언급했습니다.
세부적으로 보면 Inpainting 방식은 장면 변화 폭이 제한적이어서 일부 환경에서는 원본 배경 대부분이 유지되는 등 시각적 변화가 충분하지 않아 상대적으로 작은 성능 향상을 보였다고 합니다. 또한 inpainting 방식은 Table3을 보면 처리 속도가 느려 대규모 데이터에 적용하기 비효율적이라는 한계가 있습니다. 반면 Background, ImageNet, Texture 방식은 모두 기본 환경 대비 뚜렷한 성능 향상을 보였습니다. 이 중 Texture 방식이 약간 더 우수한 성능을 보였는데, 이는 다양한 패턴 기반 배경 노출로 인해 모델이 보다 넓은 시각적 분포를 학습할 수 있었기 때문이라고 주장합니다. ImageNet 배경 치환도 효과적이었지만, 일부 이미지에서 로봇 주변이 부자연스러워지는 등 물리적 일관성이 떨어지는 경우가 있어 Texture보다 다소 뒤처졌습니다. 이 부분에서 패턴은 물리적 일관성을 유지하는건지..?에 대한 의문이 있습니다.) Background 방식은 높은 다양성을 제공하지만, 비현실적 요소가 등장할 때 학습을 방해한다고 합니다. 다만 Diffusion 기반이라 증강 속도가 좀 느린게 흠이지 않나 싶습니다.

안녕하세요 리뷰 잘 보았습니다. 몇가지 궁금한 점이 있는데,
1. 우선 저자들의 Robo-SAM은 기존 SAMv2를 자신들이 제안한 3800장의 데이터셋으로 그냥 fine-tuning한 모델인가요? 아니면 segmentation을 더 잘하기 위한 모듈 부분의 수정도 같이 들어가나요?
2. 저자들이 segmentation 할 때 짚어야할 전경 객체들에 대해서는 Robo-SAM이 아닌 EVF-SAM을 사용한다고 했는데 EVF-SAM은 뭔가요? 그냥 SAM과는 다른 모델인가요?
3. 그림2 제일 위를 보면 짚을 수 있는 bottle이 여러개임에도 불구하고 가장 가운데 bottle에 대해서만 segmentation이 쳐져있는데 이는 Task-goal에 맞는 객체에 대해서만 segmentation을 하는건가요? 그러면 저자들이 3800장 데이터셋 수집을 위해 참고한 35개의 데이터셋들은 manipulator 연구를 위해 영상과 task goal이 매칭된 데이터셋인가요?
안녕하세요 정민님 댓글 감사합니다. 답변이 늦은점 죄송합니다,,
A 1,2 (제가 설명을 깔끔하게 못 한것 같습니다,,)
Robo-SAM이 저자들이 제안한 3800장의 데이터셋으로 EVF-SAM을 finetuning한 모델이고, 전체 파이프라인에서 로봇을 segmentation 하기 위해서 Robo-SAM을 활용했습니다.
EVF-SAM (Early Vision-language Fusion-SAM)은 멀티모달 임베딩을 따로 만들어서 SAM의 prompt encoder에 projection해서 사용하는 기존의 텍스트 기반 segmentation 모델입니다. 이 때 EVF-SAM은 SAM을 기반으로 만들어졌는데, 저자들은 EVF 구조를 SAM2에 붙여서 base로 삼아 finetuning 했습니다. 추가적인 모듈 수정은 없었습니다.
A3. 맞습니다.
여러 bottle 이 있을때, task description이 “green bottle을 집어라” 라면, 초록색 bottle만 object로 annotation 돼있습니다. 저자들이 참고한 데이터셋에는 거의 대부분 매칭이 돼있습니다. 일부 표현되지 않은 데이터셋에 대해서는 논문에서 언급이 없었습니다.
안녕하세요 영규님. 좋은 리뷰 감사합니다!
궁금한 점이 있어 질문드립니다.
로봇 imitation learning은 rollout 단위로 학습하는 것으로 알고 있는데,
위 논문은 개별 이미지를 증강하는 방식으로 보입니다.
그렇다면 한 rollout내에서 연속된 프레임들이 각각 다른 배경으로 증강되는 건가요?
이 경우 오히려 학습에 악영향을 미치는게 아닐까 생각이 들어 질문드립니다.
안녕하세요 정우님 댓글 감사합니다. 답변이 늦어 죄송합니다
음.. 일단 최근 Imitation Learning 모델들은 rollout 단위로 학습하지 않고 video 기준으로 특정 프레임의 이미지와 state로 학습합니다.
그렇다고 해서 한 rollout 내에서 연속된 프레임들이 전부 다른 배경으로 증강되지는 않고, 하나의 비디오의 배경을 여러 버전으로 만든다고 생각하시면 될 것 같습니다.
정우님이 우려한다고 생각하는 trajectory의 맥락(제가 이해한게 맞을까요?)는 temporal consistency인데, 이건 이미지 처리 이후 latent sequence에서 처리되기 때문에 배경이 다르게 증강되는게 악영향을 미치지는 않을 것 같습니다. 실제로 코드에서도 여러 비디오를 합쳐두고 랜덤으로 데이터로더를 통해 불러옵니다.