안녕하세요. 오늘의 X-Review에서 소개해드릴 논문은 24년도 WACV에 게재된 <Tackling Data Bias in MUSIC-AVQA: Crafting a Balanced Dataset for Unbiased Question-Answering> 입니다. 현재 개인적으로 Audio-Visual Question Answering (AVQA) task를 연구중인데, 본 연구에서 가장 널리 활용되는 벤치마크인 MUSIC-AVQA의 편향을 지적하며 개선한 MUSIC-AVQA-v2.0 논문이 있어 정리해보고자 합니다.
그럼 바로 리뷰 시작하겠습니다.
1. Introduction
Audio-Visual Question Answering (AVQA) task는 기존에 이미지와 텍스트만을 다루던 Visual Question Answering과 다르게, 오디오와 비디오 그리고 텍스트 질문이라는 3가지 모달리티 간 상관관계를 잡아낼 수 있어야 합니다. 이러한 AVQA task의 벤치마킹에 가장 많이 활용되는 데이터셋이 바로 MUSIC-AVQA입니다. MUSIC-AVQA는 유튜브에서 플룻, 피아노, 바이올린, 비파 등 악기가 1개 이상 연주되는 비디오들을 모아 악기 소리에 관한 QA 셋으로 구축해둔 것입니다. 더 자세한 설명은 차차 드려보겠습니다.
여기서 개인적 의견으로는, 본래의 ‘진짜’ Audio-Visual QA라면 일상 장면을 담은 비디오에 등장하는 다양한 소리(사람들의 대화, 사람-물건 간 상호작용에서 발생하는 소리, 동물 소리 등)를 바탕으로 QA가 이루어지면 정말 이상적일 것이라 생각이 듭니다. 실제로 이러한 open-world 도메인에서 다양한 QA를 담고있는 ‘AVQA'(AVQA: A Dataset for Audio-Visual Question Answering on Videos, ACM MM, 2024)라는 데이터셋이 있습니다. 물론 이 ‘AVQA’ 데이터셋으로 학습하고 평가하는 AVQA 방법론도 일부 있긴 하지만, 거의 체감상 80% 이상의 방법론들은 MUSIC-AVQA 데이터셋을 학습과 평가에 사용합니다.
좀 더 찾아보니 AVQA 데이터셋은 오디오를 다루는 멀티모달 LLM의 학습이나 평가용 데이터셋으로 많이 편입된 것 같습니다. 정확한 이유는 모르겠지만, 아무래도 downstream task로 풀어나가기엔 어렵거나 규모가 커 대부분 방법론에선 MUSIC-AVQA와 그 변형 데이터셋(MUSIC-AVQA-R, MUSIC-AVQA-v2.0)들을 많이 활용하는 것 같습니다.
다시 돌아와서, original MUSIC-AVQA 데이터셋이 어떻게 구성되어있는지 설명드리겠습니다. 데이터셋의 QA는 모달리티에 따라 “Audio”, “Visual”, “Audio-Visual” 3종류로 나뉩니다. 각각은 해당 모달리티를 봐야 답변할 수 있는 질문들이라고 보시면 될 것 같습니다. 다시 이 3개 모달리티 질문들은 5개 카테고리로 나눌 수 있고, 예시는 아래와 같습니다.
- Existential
- “Is there a voiceover?” — 비디오에 나레이션이 존재하는가?
- Temporal
- “Which violin makes the sound first?”
- Counting
- “How many sounding violins in the video?”
- Location
- “Where is the performance?”
- Comparative
- “Which object makes the sound first?”
MUSIC-AVQA는 이와 같은 형태로 구성되어있으며, 총 33개의 템플릿을 가지고 있습니다. 예를 들어 Counting 질문 예시에서는 템플릿에서 ‘violin’만 다른 악기로 갈아끼우거나, Comparative 질문 예시에서는 템플릿에서 ‘first’만 ‘second’, ‘third’ 등으로 갈아 끼우는 방식을 활용해 총 45,867개의 질문을 구성한 것입니다. 각 템플릿은 사전 정의된 답변 셋을 가지고 있어, 최종적으로는 {“yes”, “no”, “0”, “1”, “2”, “3”, …, “violin”, “piano”, “flute”, …} 이렇게 총 42개의 답변 중 하나로 분류하는 task라고 보시면 됩니다. MUSIC-AVQA는 9,290개 비디오, 45,867개 질문을 가지고 있습니다.
MUSIC-AVQA-v2.0 데이터셋은 MUSIC-AVQA 데이터셋에 존재하는 강력한 편향을 개선한 데이터셋입니다. 여기서 저자가 이야기하는 편향은, 예를 들면 이 비디오에 특정 악기가 등장하냐는 질문의 답변 90%가 “yes”로 구성되어있거나, 어떤 악기가 먼저 소리를 내느냐는 질문에는 “simultaneously”가 전체 답변의 80% 가까이를 차지한다고 합니다. 또한 등장하는 악기의 개수를 세는 질문의 답변으로 0개, 1개, 2개 …, 9개, 10개 이상까지 선택할 수 있는데 실제 정답은 1개, 2개가 50% 이상이라고 합니다. 이렇게 질문과 답변 분포의 편향이 있다면, 모델 학습에 악영향을 줄 수 있고, 심지어는 오디오와 비디오를 볼 필요 없이 질문만 보고 편향된 답을 내어 맞출 수도 있게 되는 것입니다.
저자는 위와 같은 분포의 편향을 제거한 MUSIC-AVQA-v2.0 데이터를 제안하며, 어떠한 단계를 거쳤는지 간단히 설명드리겠습니다. 먼저 각 질문 템플릿에 따른 답변 분포에 편향이 있는지 확인합니다. 모든 템플릿이 편향적인 것은 아니기 때문에, 여기서 몇 개의 왜곡된 분포를 가지는 템플릿을 선택합니다. 이후엔 답변의 균형을 맞출 수 있도록, 선택된 템플릿에 대해 적은 답변을 GT로 갖는 비디오를 추가로 샘플링하는 방식을 선택합니다. 이 과정을 거쳐 기존 MUSIC-AVQA 데이터셋에 비디오는 1,230개 추가, QA 쌍은 약 8,100개를 추가한 v2.0을 만들게 됩니다.
편향이 있는 MUSIC-AVQA로 학습한 기존 방법론 모델들을 새롭게 구성한 데이터셋 MUSIC-AVQA-v2.0으로 평가할 경우 성능이 떨어짐을 보이며, MUSIC-AVQA-v2.0 데이터셋에 대한 베이스라인 방법론도 같이 제안을 합니다. 방법론에 대해서는 뒤에서 간단하게만 알아보겠습니다.
2. Dataset balancing
본 장에서는 데이터셋 편향 제거를 위해 거친 아래 두 단계를 설명합니다.
- Pinpointing biased questions
- Achieving balance
먼저 편향된 질문을 찾아내기 위해, 전체 9개 종류의 type 질문에 대한 답변 분포를 확인합니다. 여기서 9개 종류란 Audio 질문의 2개 타입, Visual 질문의 2개 타입, Audio-Visual 질문의 5개 타입(Existential, Temporal 등)을 의미합니다. 각 종류에 전체 33개 템플릿 중 일부가 조금씩 포함되어있는 것입니다. 질문은 “yes”, “no”와 같이 이진 분류일 수도 있고, “0”, “1”, “2”, … 처럼 다중 분류일 수도 있습니다. 전자의 경우 답변의 60% 이상이 하나로 몰려있을 때, 후자의 경우 답변의 50% 이상이 하나로 몰려있을때를 “bias”라고 정의하였다고 합니다.

확인 결과 original MUSIC-AVQA 데이터셋의 9 종류 질문 중 7 종류의 질문에서 최소 하나 이상의 템플릿이 편향을 보였다고 합니다. 조사한 분포는 위 그림 1 왼쪽에 나타나있습니다. 구체적으로 편향을 보이는 7개 종류는 아래와 같았습니다. 실제로 편향 제거도 아래 7개 템플릿 질문들에 대해서만 진행하였습니다.
- Audio-Visual
- Existential
- Counting
- Temporal
- Visual
- Location
- Counting
- Audio
- Counting
- Comparative
템플릿 단위로 보면 전체 33개 템플릿 중 위 종류에 속하는 총 15개 템플릿이 답변에 대한 편향을 가지고 있었다고 합니다. 그림 1의 오른쪽은 균형을 맞춘 후의 분포인데, 그럼 이제부터는 각 질문 종류별로 편향을 어떻게 해결하였는지 알아보겠습니다.
2.1 Audio-Visual Existential Questions
존재 여부를 묻는 질문이다보니 이 종류의 질문 대부분은 답변이 “yes”, “no”로 구성되어있습니다. 이 경우엔 더 자주 등장하는 답변을 찾고 반대되는 답변에 대한 QA 쌍을 만들어줌으로써 편향을 제거하였습니다. 에를 들어 “Is this sound from the instrument in the video?”라는 질문의 답변은 90%가 “yes”로 구성되어있습니다. 그럼 이 질문에 대한 답변이 “no”인 쌍을 만들어주기 위해 현재 비디오 샘플의 오디오를 다른 악기가 연주되고있는 비디오의 오디오로 대체하는 것입니다.
이 때 문제가 너무 쉬워지는 것을 막기 위해 오디오를 대체할 때 현악기, 금관악기와 같은 악기의 대분류를 고려해주었다고 합니다. 그렇다고 모두 대분류가 같은 악기 소리로 대체한 것은 아니고, 50%는 같은 대분류, 나머지 50%는 다른 대분류에 속하는 악기 오디오로 대체했다고 합니다. 이 방식을 통해 794개의 매칭되지 않는 비디오-오디오 세그먼트를 만들어 추가해주었다고 합니다.
다음으로 “Is there a voiceover?”라는 질문은 답변의 79.6%가 “no”라고 합니다. 마찬가지로 편향이 심한 축에 속하는데요. 저자들이 이 질문을 갖는 비디오 1,278개를 직접 확인한 결과 원본 데이터셋의 annotator들이 voiceover에 대한 서로 다른 기준을 가지고있음을 알게 되었습니다. 실제 사람의 나레이션만을 “voiceover”로 삼아 라벨링된 샘플들도 있었고, 사람의 나레이션은 아니지만 화면 밖에서 나는 소리가 있다면 모두 “voiceover”로 삼아 라벨링된 샘플들도 있었다는 것입니다.
저자들은 후자의 경우를 “voiceover”로 정의하고 결국 13%에 해당하는 mislabeled 샘플을 재라벨링했다고 합니다. 그럼에도 아직 68%의 답변이 “no”였고, 결국 voiceover가 존재하는 별도의 456개 QA pair를 추가하여 no 51.7%, yes 48.3%로 균형을 맞추었다고 합니다.
2.2 Audio-Visual Counting Questions
이 종류의 질문은 비디오 내 악기 개수를 세야하고, 답변은 “0-10″과 “10개 이상” 중 하나입니다. 질문은 아래와 같이 4개 종류로 구성되어있습니다.
- T1: the total number of sounding instruments
- T2: the number of instrument types which are sounding
- T3: the number of a specific sounding instrument type
- T4: the number of instruments that did not sound from the beginning to the end
확인 결과 “0”, “1”, “2”가 답변의 거의 대부분을 차지하고있었으며, 위 4개 템플릿 모두에서 가장 많이 나온 답변이 50% 이상을 차지한다고 합니다. 이 종류의 질문에 대한 균형을 맞추기 위해, 저자들은 YouTube8M 데이터셋에서 최소 2개 이상의 악기가 연주되는 비디오를 찾아나서게 됩니다. YouTube8M 데이터셋은 비디오마다의 태그를 가지고 있는데, 여기서 “musical ensemble”, “string quartet” 등 특정 악기 이름들을 검색해가며 여러 악기가 등장하는 비디오를 찾았다고 합니다.
물론 이 과정에서 너무 품질이 낮거나 앨범 커버만을 보여주는 비디오 등등은 필터링하였고, 살아 남은 비디오들에 대해서는 악기의 총 개수, 서로 다른 악기 종류 개수, 대분류 관점에서의 악기 개수, 소리내는 악기 개수, 소리를 내면서 가장 자주 등장하는 악기의 등장 횟수, 처음부터 끝까지 소리를 내지 않는 악기의 개수를 라벨링하였다고 합니다. 최종적으로 총 591개의 비디오를 추가하였고, T1부터 T4까지 각각 572, 502, 815, 413개의 QA 쌍을 추가했다고 합니다. 당연히 이 쌍들은 기존에 개수가 적었던 답변들에 해당하며, 분포 균형을 맞출 수 있었다고 합니다.
2.3 Audio-Visual Temporal Questions
이 질문은 비디오에서 연주되는 악기의 순서를 묻습니다. 총 22개 악기 중 하나 또는 “left”, “middle”, “right” 같은 위치 중 하나를 답변하면 됩니다. 이 종류의 질문에서는 특히 “Which <Object> makes the sound first/last?” 질문이 74% 비율로 “simultaneously”라는 답변을 가지며 편향이 심한 상황입니다. 동시에 연주된다는 답변의 비율을 줄이기 위해, “left”, “right”, “middle”이 답변이 되는 질문을 늘리고자 합니다.
예를 들어, 비디오에 3개의 바이올린이 등장할 때, 왼쪽 바이올린이 가장 먼저 연주를 시작하는 비디오를 추가한다면 “Which violin starts playing first?”라는 질문에 기존에 “동시에”로 편향되어있던 셋에 “left”라는 답변을 추가할 수 있게 되는 것입니다. 추가로, 비디오 좌우를 flip하여 원래 “left”였던 정답을 “right”으로 만들어 쓸 수 있게 하였습니다.
총 203개의 비디오를 유튜브로부터 샘플링하여 QA 쌍을 만들고, 앞서 말씀드린 augment까지 적용하여 “동시” 이외에 713개의 추가적인 쌍을 만들어주어 결국 74%였던 “동시” 쌍을 41%로 낮추었다고 합니다.
2.4 Visual Counting Questions
앞선 절에서 소개드렸던 질문과 다르게 이 종류의 질문은 “visual” 정보에만 의존해도 해결할 수 있습니다. 대표적으로 “Is there <Object> in the entire video?” 또는 “Are there <Object> and <Object> instruments in the videoi?”와 같은 질문이 있고, 모두 특정 악기가 존재하는지 묻는 것입니다. 이 질문들에 대해 답변 “yes”가 각각 78.4%, 62.7%에 해당하여 편향이 심했고, 마찬가지로 저자들이 직접 비디오를 샘플링하여 “no” 쌍을 각각 794, 423개씩 추가해주었습니다.
다음으로 비디오에 등장하는 악기 종류를 묻는 질문들도 있습니다. 여기서도 특이한 편향이 있는데, 모든 답변 중 “1”, “2”가 무려 91%를 차지한다고 합니다. 앞서 샘플링한 Audio-Visual 비디오 중 2개 이상의 악기가 존재하는 204개 비디오를 가져와 91%의 편향을 80%로 그나마 낮추었다고 합니다.
2.5 Visual Location Questions
이 질문은 여러 템플릿을 가지고 있지만, 그 중에서도 “Where is the performance?”라는 질문은 “indoor”, “outdoor” 중 하나로 답변을 해야합니다. 확인 결과 “indoor”라는 답변의 비율이 72.6%였고 이를 완화하기 위해 외부에서 연주가 이루어지는 456개의 QA 쌍을 가져와 이 편향을 54.7%까지 낮추었다고 합니다.
2.6 Audio Counting Questions
이 종류의 질문은 오디오 상에서 악기가 등장하는지에 대해 묻습니다. 예를 들어 “Is there a <Object> sound?”라는 질문이나 “Are there <Object1> and <Object2> sounds?”라는 질문이 있습니다. 각 질문에 대한 답변 중 “yes”가 차지하는 비율은 76.0%, 78.8%로 편향이 심한 상황입니다. 저자는 비디오에서 어떤 악기의 소리가 나는지 모두 확인한 뒤 답변이 “no”로 나오는 QA 쌍을 각각 794, 423개 만들어 기존의 편향을 각각 52.5%, 61.5%로 낮추었습니다.
다음으로 비디오 전반에 걸쳐 들리는 모든 종류의 악기 개수는 몇개인지 묻는 질문도 있습니다. 이 개수를 세는 질문 또한 마찬가지로 “1”, “2”가 89%의 답변을 차지하며, 비율이 낮은 답변을 포함하는 572개의 QA 쌍을 추가해서 61%로 “1”과 “2” 답변의 비율을 낮추었다고 합니다.
2.7 Audio Comparative Questions
드디어 마지막 카테고리입니다. 이 카테고리는 비디오에 등장하는 악기들을 악기 소리, 연주 길이, 리듬 관점에서 비교합니다. 3개의 템플릿에 대해서, 특히 연주 길이를 비교하는 질문에 편향이 있다고 합니다. A, B 둘 중 A 악기가 더 오래 연주하냐는 질문에 대해 대부분 비디오가 편집에 의해 동시에 끝나다보니 “no”라는 답변의 비율이 68%를 차지한다고 합니다. 이 또한 마찬가지로 추가 샘플링을 통해 “no” 답변의 비율을 53.9%로 낮추었습니다.
3. Approach
본 논문은 편향을 제거한 데이터셋 이외에 베이스라인 방법론도 같이 제안합니다. 다만 방법론 측면에서 contribution이 크진 않고, 기존에 제안되었던 LAVISH라는 방법론과 AVST라는 방법론을 합쳐 새로운 베이스라인을 만들어냈다고 합니다. 전체 파이프라인은 아래 그림 2와 같습니다.
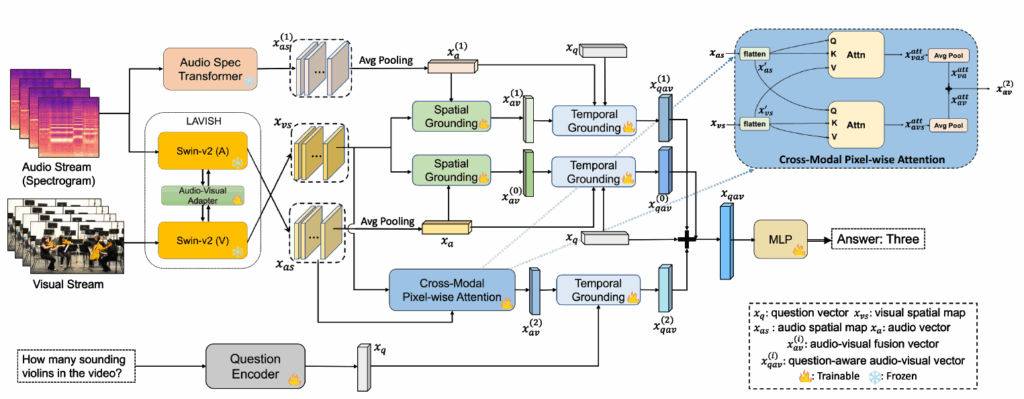
먼저 LAVISH는 2-tower의 사전학습된 Swin Transformer v2 + audio-visual adapter로 구성된 기존 방법론(feature notation 상 (0))입니다. 다음으로 AVST는 spatial & temporal grounding을 수행하는 방법론으로, MUSIC-AVQA 데이터셋과 함께 제안된 방법론입니다.
이 둘을 합친 뒤 저자가 추가한 것은 두가지인데요, 첫 번째는 그림 2 좌상단의 AST branch (feature notation 상 (1))로 Audio-Spectrogram-Transformer와 Swin-v2의 visual backbone를 합친 것입니다. 이 AST branch로부터 audio-visual 기반의 spatial, temporal grounding을 수행합니다. 두 번째는 그림 2 우측 파란색으로 표시된 cross-modal pixel-wise attention 모듈(feature notation 상 (2))입니다. 이 모듈은 granular level에 따라 audio-visual fusion을 refine하는 역할입니다.
3.1 AST branch
사전학습된 AST 모델을 가져와 기존 VGGish 등의 약한 모델을 썼을 때보다 더욱 풍부한 audio feature를 뽑아낼 수 있게 됩니다. AST 모델의 최종 출력인 spatial map x_{as}^{(1)}을 가져와 AVST 방법론에서 제안한 spatial, temporal grounding을 그대로 수행합니다. 이 grounding은 대부분 단순 평균 및 모달 간 cross attention으로만 이루어져있어 추가적인 설명은 생략하겠습니다. 자세한 내용은 AVST 논문 (Learning to answer questions in dynamic audio-visual scenarios)을 참고해주시면 감사드리겠습니다.
3.2 Cross-modal pixel-wise attention module
기존 방법론에선 1차원 벡터 형태의 오디오 feature를 쓰다보니 이를 단순히 평균내어 다른 모달리티와의 cross-attention을 수행했습니다. 그러나 여기선 spatial 축을 갖는 오디오 feature를 사용하기 때문에 visual-audio간 더욱 refine된 pixel-wise cross-attention을 제안합니다.
LAVISH 모델로부터 얻는 frame-level visual map x_{vs} \in{} \mathbb{R}^{H \times{} W \times{} C}와 audio map x_{as} \in{} \mathbb{R}^{H \times{} W \times{} C}가 존재할 때, 두 feature map 모두 공간 축으로 flatten하여 (HW) \times{} C 형태의 특징 x'_{vs}, x'_{as}를 얻습니다.
이렇게 얻은 두 feature map 간 cross-attention을 아래 수식 (1), (2)와 같이 수행합니다.

이후 두 feature는 정규화 후 평균내어져 최종 답변 생성에 관여하게 됩니다.
4. Experiments
4.1 Models Evaluation on Bias and Balanced Dataset
본 절에서는 편향이 심한 기존 MUSIC-AVQA가 실제 모델 학습에 방해를 주는지 확인하는 실험을 진행합니다. 즉 기존 MUSIC-AVQA처럼 정답 분포가 편향되어있는 것이 문장과 비디오, 오디오를 보고 답하는게 아니라, 질문 형태에 따라 편향된 답을 내는지 확인하는 것입니다. 이를 확인하기 위해 Train / Test를 Bias / Balance 각각으로 구성하여 총 4가지 경우의 수에 대한 기존 모델 (AVST, LAVISH)의 성능을 측정합니다.
Balanced Test Set
이미 MUSIC-AVQA-v2.0에는 균형을 맞춰줄 수 있는 샘플들이 많이 있기 때문에, 정답 분포 균형을 맞춘 채로 전체의 20%를 샘플링합니다. 결국 10,819개의 균형잡힌 테스트 스플릿을 구축합니다. 이후 이 스플릿은 모든 실험에서 공정한 테스트셋으로 씁니다.
Balanced Training Set
이미 MUSIC-AVQA-v2.0이 균형 잡혀있기 때문에, 앞서 균형잡힌 테스트 스플릿을 제외한 나머지도 균형이 맞춰져있다고 볼 수 있습니다. 따라서 남은 샘플들을 모두 balanced training set으로 두고, 샘플의 양은 원본 MUSIC-AVQA와 맞춰 대략 31,000개로 둡니다.
Bias Training Set
여기선 원본 MUSIC-AVQA의 심각한 편향 분포를 그대로 구현하기 위해, 앞서 언급했던 “1”, “2”, “simultaneously”, “yes”와 같이 이미 비율이 높은 답변을 포함하는 QA 쌍은 MUSIC-AVQA-v2.0에서 모두 그대로 가져옵니다. 그리고 나머지 minor 답변 QA 쌍은 원본 데이터셋에 비율 높은 답변이 존재하던 비율을 맞춰주는만큼 가져오게 됩니다. 예를 들어 원래 특정 질문의 “yes” 답변 비율이 90%였고 900개의 “yes” 쌍을 가져왔다면, 100개로 조절된 “no” 쌍을 가져와서 원본의 비율 분포를 맞춰주었다는 것입니다. 여기에서도 대략 학습 셋 개수는 31,000개로 맞춰줍니다.
Bias Test Set
여기선 앞서 만들어둔 Balanced Test Set의 10,819개 QA 쌍에서 편향이 심했던 “yes”, “1”과 같은 답변들은 모두 유지하고, “no”, “6”과 같은 minor 답변들의 개수를 조절하여 원본 MUSIC-AVQA 데이터셋의 편향 비율을 맞춰 구축하였습니다.
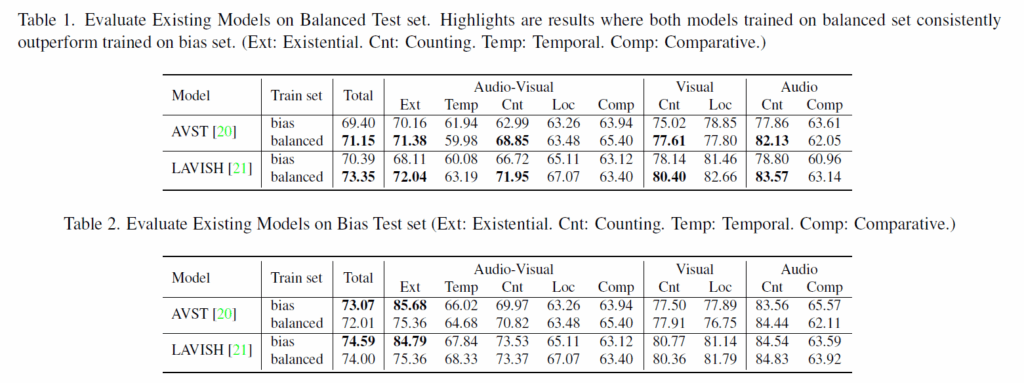
위 표 1, 2는 각각 balanced test, bias test set에 평가했을 때의 성능을 보여줍니다. 각 표에는 balanced, bias로 학습했을 경우의 성능이 나타나있습니다. 표 1에서 balance test인 경우, 두 모델 모두에서 balance train일 때의 성능이 항상 높음을 볼 수 있습니다.
전체 평균으로 보면 AVST와 LAVISH 각각 bias에 비해 balanced로 학습하면 1.75%, 2.96% 향상하는 것을 볼 수 있으며, 이는 곧 편향 없는 데이터로 학습하면 실제 reasoning이 필요한, 즉 편향만으로는 답할 수 없는 상황에서 다양한 경우에 대한 학습이 진행하기 때문에 편향없는 데이터에 높은 성능을 낸다는 결론을 얻을 수 있게 해줍니다.
특히 bias가 심했던 AV Existential, AV Counting에서 굉장히 많이 오르는데, balance train 셋에서 진짜 grounding을 학습하다보니 질문만 보고 답을 외워 답하는 대신 실제 능력을 잘 획득했다는 증거가 되는 부분이라고 볼 수 있습니다.
다음으로 bias test에서의 성능은 표 2에 나타나있습니다. 이 때는 반대로 bias train에 대해 더욱 높은 성능이 나온 것을 볼 수 있는데요. bias train의 결과 모델은 문장만 보고 답변의 분포를 맞추니 그 분포와 동일한 bias test에서는 좋은 성능을 보여주고 있습니다. 반대로 balanced train 모델은 오히려 성능이 bias train 모델보다 떨어지는 상황입니다.
사실 처음에는 진짜 balanced set으로 학습했으면 테스트의 분포가 어떠하든 더욱 잘해야 하는 것 아닌가? 생각이 들 수 있지만 bias train 모델보다 낮은 것이라는 점에 집중해보았을 때 상대적으로 질문과 답변 분포 편향에만 의존하기에 bias train의 성능이 너무 잘 나와버린 상황이라고 이해해볼 수 있습니다.
4.2 New Baseline Evaluation
앞선 절에서의 실험은 일부러 bias/balance를 조정한 데이터였고, 실제 저자가 구축한 MUSIC-AVQA-v2.0은 QA 쌍 학습 36.7K개, val 5k개, 평가 10,819개로 구성되어있습니다. 앞서 설명드린 방법론 중 LAVISH와 AST 모듈만 조합하면 ‘LAST’, LAVISH + AST + Attention까지 모두 사용하면 ‘LAST-Att’이라 부르고 MUSIC-AVQA-v2.0에서 학습한 후 각각의 성능을 측정합니다.
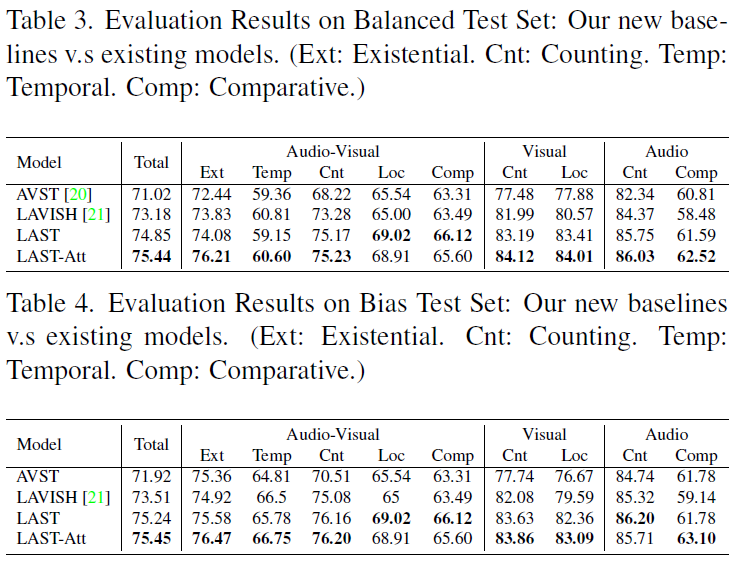
표 3, 4에서 저자가 제안한 방법론 LAST, LAST-Att이 가장 높은 성능을 달성하는 것을 볼 수 있으며 저자도 spatial 축에서 모델 능력이 개선되었다는 정도로만 언급하고 있습니다.
방법론보다는 기존 데이터셋의 답변 관점에서 존재하는 편향을 확인하고, 이를 직접 균형 맞춰주는 방식에 contribution이 큰 논문이라는 점을 알 수 있었습니다. 마침 질문의 일부 변화에 대해 모델들이 잘 대응하는지를 중점으로 문제 정의를 진행하고 있었는데 많은 도움이 된 논문이었습니다.
이상으로 리뷰 마치겠습니다.
좋은 리뷰 잘 읽었습니다.
Audio-Visual Existential 질문에서, 오디오를 다른 비디오의 세그먼트로 교체하여 “no” 샘플을 만드는 방식이 제법 인상적이네요. 다만 이런 방식이 배경 소음, 잔향, 마이크 품질 등 도메인 차이가 섞이면서, 모델 입장에선 “악기가 다르다”기보다 “녹음 환경이 다르다”로 구별할 수도 있을 것 같다는 생각이 드는데요. 저자들이 이런 영향을 줄이기 위한 추가적인 처리가 있는지, 아니면 단순히 대분류(현악기/관악기 등) 정도만 고려한 수준인지 궁금하네요
안녕하세요 좋은 질문 감사합니다.
직접 이 합성 비디오 샘플의 소리를 들어봐야겠지만, 다른 비디오의 음성을 중간에 삽입하는 방식이라면 말씀해주신대로 모델 입장에서는 혼란을 겪을 수 있다 생각합니다. 아무래도 원본 데이터 개수가 워낙 많고 또 비디오/오디오이다보니 데이터를 추가 수집할때마다 따로 처리해준 부분은 없었습니다. 다만 평균 성능대(70 초반)는 또 비슷하다보니 오디오의 도메인 차이에 따른 방해는 그렇게 크지 않다고 볼 수 있을 것 같습니다.