
안녕하세요 이번에는 새롭게 video understanding, question answering, explanation tasks를 수행하는 Video large language model 논문에 대해 소개하고자 합니다.
Video-LLM 모델을 이해하기 위해서는 먼저 Image-LLM(Image Large Language Model)에 대한 이해가 필요합니다. 최근 GPT-4, Gemini, MM1, Phi-3, LLaVA-NeXT와 같은 Multimodal Large Language Model(MLLM)들은 이미지와 같은 시각적 입력과 텍스트를 함께 처리하여 사용자 질의에 적합한 응답을 생성합니다. 이러한 MLLM들의 기반이 된 선행 연구로는 Flamingo(2022, DeepMind), BLIP-2(2023, Salesforce), LLaVA(2023–2024) 등의 대표적인 Image-LLM 모델들이 있습니다.
Flamingo, BLIP-2, LLaVA는 모두 시각-언어 이해를 위해 LLM을 활용하지만 접근 방식이 다릅니다. Flamingo는 이미지·비디오·텍스트를 한 프롬프트 안에 교차 방식으로 배치해 추가 파인튜닝 없이 텍스트 답변을 생성하는 멀티모달 LLM이고, BLIP-2는 비전 모델과 언어 모델에 대해, 둘 사이의 gap을 잇는 Q-Former를 도입해 이미지 조건부 텍스트 생성을 하는 모델입니다. 마지막으로 LLaVA는 비전 인코더가 추출한 시각 특징을 MLP Projection으로 LLM의 시각 토큰으로 입력하고, GPT로 생성한 이미지-질문-답변 데이터로 Visual Instruction Tuning을 수행한 모델이라고 할 수 있습니다.
이제 이러한 Image-LLM 모델을 바탕으로 최근에는 Video-LLM 연구가 많이 진행되고 있습니다. 대표적인 모델로는 Video-ChatGPT(2024), LLaVA-NeXT-Video(2024), PLLaVA(2024), Video-LLaVA(2023), VideoChat(2023) 등이 있습니다. Video-LLM도 기본적으로 비주얼 특징을 추출해 LLM에 연결한다는 큰 틀은 같지만, 비디오에 포함된 시간 정보나 장면 전환, 동작 등 시공간 정보를 함께 다루어야 합니다. 그렇기 때문에 이를 위한 프레임 샘플링이나, temporal attention, adapter 등의 기법들이 Image-LLM 모델들에 추가로 구성된다고 이해하시면 될 것 같습니다.
Training-Free Video LLMs
그럼 본격적으로 이 논문에 주제라고 할 수 있는 Training-Free Video LLMs에 대해 설명하고, 기존 방식의 한계점과 SlowFast-LLaVA가 이를 어떻게 개선했는지 설명드리겠습니다.
이 모델들은 Image LLMs를 기반으로 하고 비디오 도메인에 적용시키기 위해 추가적인 fine-tuning이 필요 없는 모델들을 말합니다. 대표적인 모델로는 FreeVA,IG-VLM 등이 있습니다. FreeVA는 프레임별 특징을 뽑은 뒤 temporal aggregation 으로 요약해서 LLM에 입력하고, IG-VLM은 여러 프레임을 이미지 그리드 한 장으로 배치해 Image-LLM을 그대로 사용하는 방식입니다. 하지만 이들 방법에는 두 가지 한계점이 있습니다. 첫번째는 처리 가능한 프레임 수가 적다는 문제입니다. FreeVA 4장, IG-VLM 6장의 이미지만 처리하기 때문에 주로 짧고 단순한 영상에만 적합합니다. 두번째로 이 모델들은 비디오의 특징을 단순히 LLM에 입력하기 때문에 temporal dependency가 전적으로 LLM 추론 능력에 의존한다는 문제가 있습니다. 그렇기 때문에 비디오의 정보를 모델링하기 위한 temporal modeling 이 부족하다는 한계가 있습니다.
본 논문에서는 이러한 한계점을 극복하기 위해 SlowFast 디자인을 제안합니다. 이 방법론은 더 많은 프레임(50개)을 처리하기 위해 spatial(공간적), temporal(시간적) 단서를 모두 포함할 수 있도록 Slow path와 Fast path를 설계한 모델입니다. 그렇다면 SlowFast 모델은 어떻게 이러한 디자인을 설계했는지 설명드리도록 하겠습니다.
1. INTRODUCTION
Video-LLM은 비디오 입력을 처리하고 사전 훈련된 LLM을 사용하여 질의에 맞는 답변을 생성하는 모델입니다. Video-LLM이 좋은 성능을 보이고 있지만 대부분의 기존 방법론들은 대규모 라벨링된 비디오 데이터 셋에서 fine-tuning되므로 cost가 높다는 단점이 있습니다. 최근에는 이러한 cost를 줄이기 위해 fine-tuning이 필요없는 training-free 방법들이 제안되고 있습니다. 그렇지만 이 모델들에도 한계점이 있는데 앞서 설명드린 것처럼 1. 적은 수의 프레임만 처리하고 2. 적절한 temporal 모델링 없이 비디오의 특징을 그대로 LLM에 입력하기 때문에 video motion patterns을 전적으로 LLM에 의존한다는 한계가 있습니다.
본 논문에서는 추가적인 fine-tuning 없이 LLaVA-NeXT를 기반으로 하여 raining-free Video LLM 모델인 SlowFast-LLaVA (or SF-LLaVA for short)를 제안합니다. 이 모델은 visual encoder를 통해 뽑은 특징에 대해 Slow pathway와 Fast pathway로 처리하여 LLM에 입력합니다. Slow pathway는 낮은 프레임 속도로 특징을 추출하면서 더 높은 해상도로 공간 정보를 유지하고, Fast pathway는 높은 프레임 속도로 추출하지만 모션 큐에 집중하기 위해 aggressive spatial pooling stride를 사용합니다.
이러한 설계를 통해 비디오 내에서 천천히 변화하는 시각적 의미를 반영하여 시간이 지나도 크게 변하지 않는 공간 정보와, 빠르게 변화하는 움직임 등의 시간적 맥락을 통합하여 특징을 얻을 수 있습니다.
SlowFast-LLaVA는 Open-Ended VideoQA, Multiple Choice, VideoQA, Text Generation task에서 8개 벤치마크로 평가되었고 데이터는 1인칭·3인칭 영상과 짧은·긴 영상 등을 포함하고 있습니다. 실험 결과 모든 벤치마크에서 기존 training-free 보다 앞선 결과를 보였고 데이터로 파인튜닝한 모델과 비교해도 비슷하거나 더 높은 성능을 보였습니다.
2. Method
저자가 제안하는 방법론의 아키텍쳐는 다음과 같습니다.
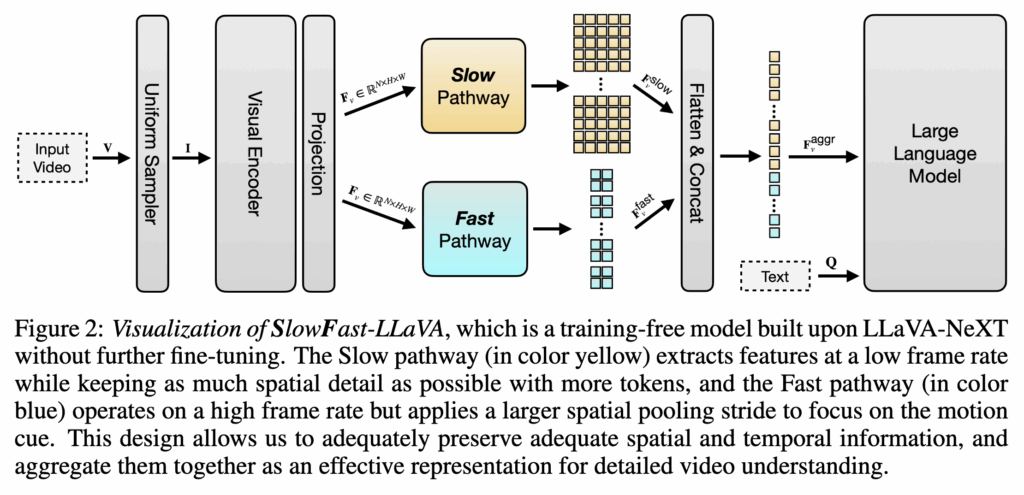
먼저 LLaVA-NeXT 모델에 입력이 주어졌을때 이를 어떻게 처리하는지 설명드리겠습니다. 비디오 V가 주어지면 프레임 샘플러는 먼저 N개의 키 프레임(I로 표시)을 선택합니다. 샘플링된 프레임은 CLIP-L의 visual 인코더로 추출되며 수식은 아래와 같습니다.

비디오 특징 Fv는 LLM에 입력하기 전에 feature aggregator를 통해 프레임 특징들을 요약합니다. 수식은 아래와 같습니다.

이를 통해 많은 양의 토큰 들을 몇 개의 토큰으로 압축해 제한된 LLM 입력에 맞출 수 있고 프레임의 순서와 변화를 반영해 더 나은 비디오 특징을 얻을 수 있습니다. 그리고 이렇게 추출된 비디오 특징을 프롬프트와 함께 사전학습된 LLM에 넣어 답변 A를 생성하게 됩니다.
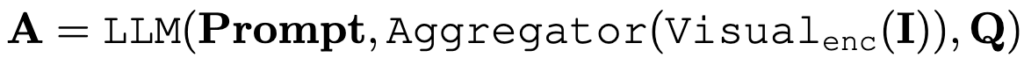
SLOWFAST ARCHITECTURE
저자의 모델 또한 위에서 설명드린 파이프라인을 그대로 따르지만 N개(50개)의 비디오 프레임을 처리할때 두가지 pathway로 처리하는 방식에 차이가 있습니다.
The Slow pathway
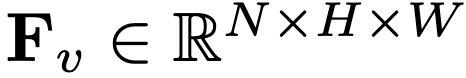
H,W 크기를 가지는 N개의 프레임이 주어졌을때, Slow pathway에서는 Nslow(10개) 의 프레임을 샘플링하고 이에 PLLaVA의 풀링방식을 적용하여 1×2 풀링을 적용합니다. PLLaVA에 따르면 적절한 풀링은 효율성과 강인성이 좋아지기 때문에 저자 또한 이를 적용했다고 합니다.

The Fast pathway
Fast pathway는 비디오의 포함된 많은 시간적 맥락을 포함하기 위해 Fv의 모든 프레임(50개) 특징을 사용합니다. 비디오 에서 샘플링된 모든 프레임(N)을 그대로 사용하고, 대신 aggressive spatial pooling stride를 크게하여 공간 해상도를 낮춥니다. 이를 수식으로 표현하면 다음과 같습니다.

이제 이렇게 Slow pathway와 Fast pathway를 통해 추출된 특징에 대해 flatten 시켜 concat 한 후에 프롬프트,질문과 함께 LLM에 입력합니다.
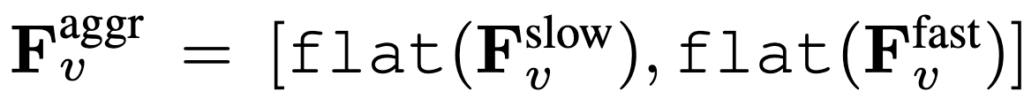
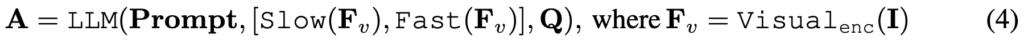
추가적으로 50개의 키 프레임은 336 × 336 크기로 리사이즈되고 visual encoder를 타고 나오면 24 × 24 크기의 토큰을 출력합니다. 따라서 slow path에서 pooling을 거쳐 10*12*24= 2,880의 토큰을 가지고 Fast path는 50 × 4 × 4 = 800개의 토큰을 가집니다.
3. EXPERIMENTS
저자는 Open-Ended VideoQA, Multiple Choice VideoQA, Text Generation 벤치마크에서 모델을 평가합니다. Open-Ended VideoQA는 비디오와 질문을 주고 자유롭게 답변을 생성합니다. 평가를 위해서 MSVD-QA, MSRVTT-QA, TGIF-QA, ActivityNet-QA (ANet-QA) 데이터셋을 사용하고 평가 지표는 Accuracy, Quality로 평가하는데 모델이 출력한 답변은 GPT-3.5-Turbo-0125를 채점자로 하여 모델의 Accuracy, Quality를 평가합니다.
Multiple Choice VideoQA는 객관식의 답을 고르는 테스크이고 NExT-QA, EgoSchema, IntentQA 데이터셋을 사용합니다.
Text Generation는 비디오 내용을 바탕으로 문장을 얼마나 잘 만들어내는지 평가하고 평가 기준은 다음과 같습니다.
- CI (Correctness of Information) — 내용이 사실과 일치하는가
- DO (Detail Orientation) — 세부 묘사가 충분한가
- CU (Contextual Understanding) — 맥락을 잘 이해했는가
- TU (Temporal Understanding) — 시간 순서(이전/이후 사건)를 잘 이해했는가
- CO (Consistency) — 답변이 일관되고 논리적인가
이는 VCGBench 데이터셋을 활용하였으며 마찬가지로 GPT-3.5-Turbo-0125로 평가를 진행합니다.
Open-Ended VideoQA

Open-Ended VideoQA의 성능은 위 표 1에 나타나있습니다. 저자의 모델은 모든 Open-Ended VideoQA 벤치마크에서 기존의 training-free 방식들보다 더 나은 성능을 보여주었고, Supervised Fine-Tuning된 Video LLM과 비교를 해도 동등하거나 더 나은 성능을 보여주었습니다.
Multiple Choice VideoQA
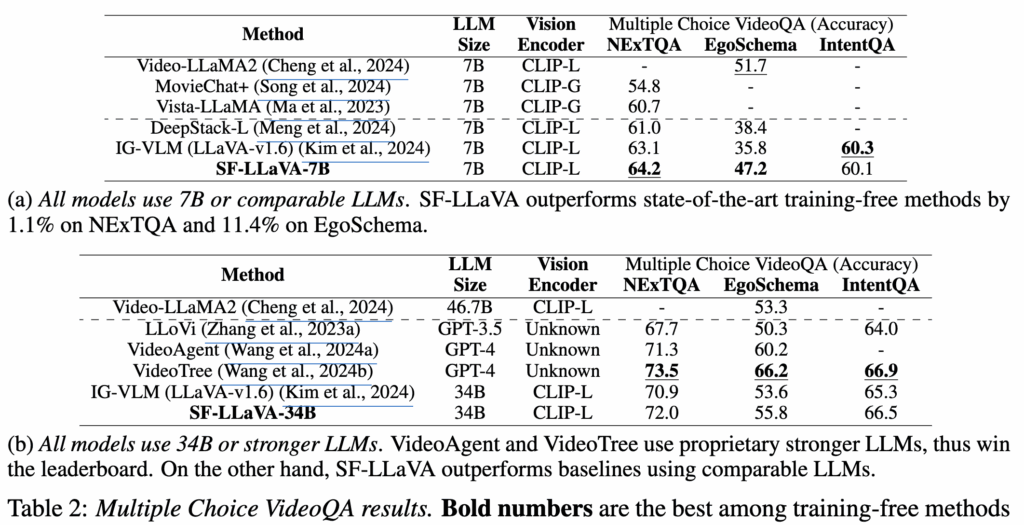
Multiple Choice VideoQA에서도 높은 성능을 보여주었습니다. 표2(b)에서는 training-free 방식을 사용한 VideoTree 모델이 높은 성능을 보여주었는데 이는 GPT-4 LLM을 기반으로 하여 오픈소스 LLM보다 훨씬 좋은 성능을 보이기 때문이라고 언급하고 있습니다.
Text Generation
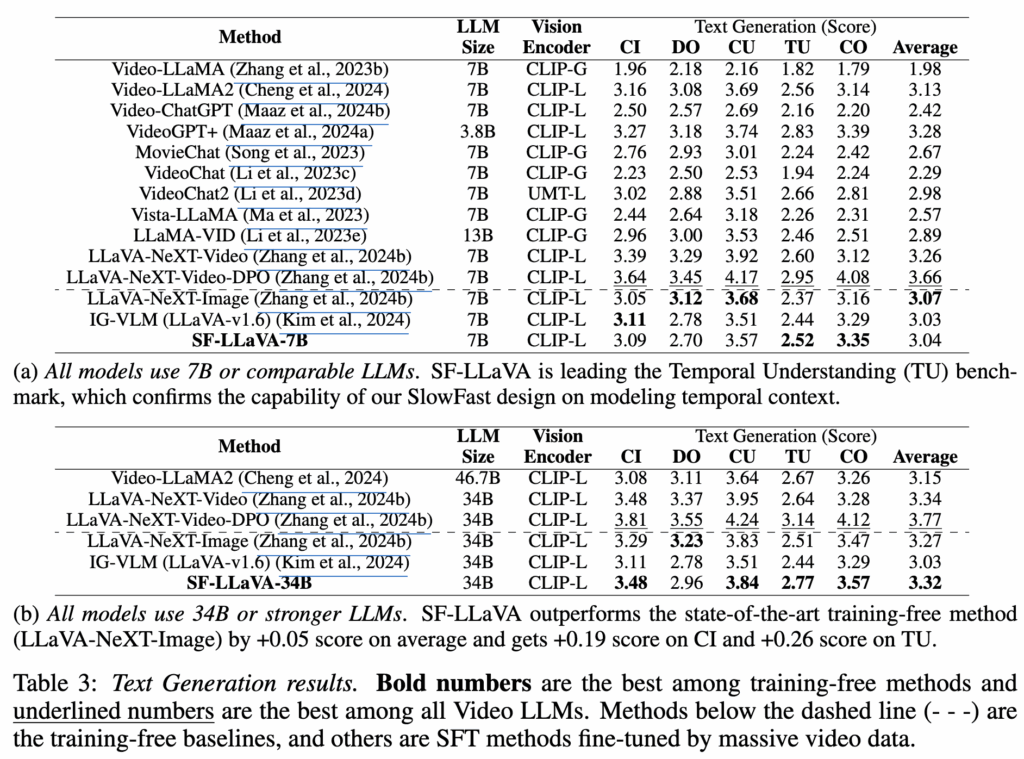
Text Generation에서는 평균적으로 training-free 모델들보다 좋은 성능을 보이고 있습니다. Detail Orientation(DO)에서는 LLaVA-NeXT-Image에 점수가 낮았는데, 이는 LLaVA-NeXT-Image가 SF-LLaVA보다 더 많은 입력 프레임을 사용하기 때문이라고 언급하고 있습니다(LLaVA-NeXT-Image는 32개의 프레임을 12×12 토큰으로 처리, SF-LLaVA는 10개의 프레임을 12×24 토큰으로 처리)
DESIGN CHOICES OF PROMPT
SF-LLaVA는 추가적인 파인튜닝 없이 사전 학습된 Image-LLM을 기반으로 VideoQA를 수행합니다. 저자는 SF-LLaVA가 비디오 태스크를 더 잘 이해할 수 있도록 새로운 프롬프트 설계가 필요한지 평가하며, 프롬프트를 세 가지 구성 요소로 나누어 실험을 진행합니다.
- Task instruction prompt
먼저 모델이 수행해야 할 태스크를 더 명확하게 알려주는 지시문을 사용하여 프롬프트를 재구성하였습니다.
Open-Ended VideoQA에서는 “Answer the question precisely based on the input.” ,
Multiple-Choice QA에서는 “Select the best option to answer the question.”로 프롬프트로 재구성 하였습니다.
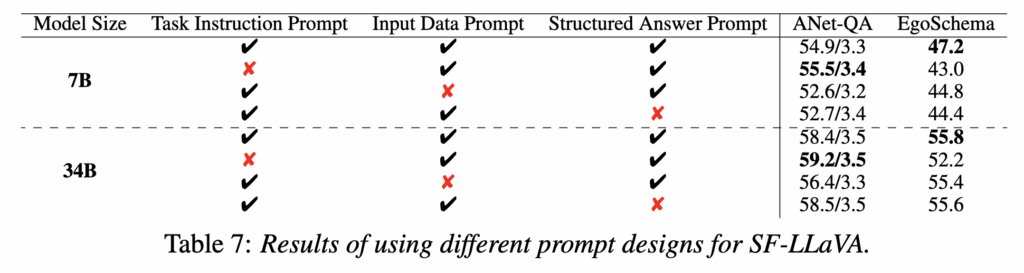
표7의 1행, 2행을 비교했을때 task instruction prompt를 사용하면 EgoSchema에서 성능을 향상시킬 수 있음을 보여주었습니다. 하지만 ActivityNet-QA에는 도움이 되지 않아 Multiple Choice VideoQA에만 task instruction prompt를 사용했다고 합니다.
- Input data prompt
이는 LLM에 입력되는 visual 데이터(비디오 프레임)의 구조를 설명하는 텍스트 지시문입니다.
예를 들어, IG-VLM 에서는 이미지를 그리드 형태로 배열하는 방식을, PLLaVA에서는 이미지 시퀀스를 사용하는 방식을 설명합니다. 이 프롬프트는 다음과 같이 사용됩니다. “The input consists of a sequence of key frames from a video”.
표 7의 결과(행 1과 3)에 따르면, 입력 데이터 프롬프트를 사용했을 때 ActivityNet-QA와 EgoSchema 벤치마크 모두에서 더 나은 성능을 보였습니다. 이는 비주얼 토큰의 구조에 대한 세부 정보를 제공하는 것이 모델이 입력을 더 잘 이해하는 데 중요함을 보여줍니다.
- Structured answer prompt
이는 모델이 미리 정해진 형식으로 답변을 생성하도록 유도하는 명령어입니다. 이러한 프롬프트는 모델이 더 정확한 결과를 얻는데 기여한다고 합니다. Multiple Choice VideoQA에서는 “Best Option:(” 프롬프트를, Multiple Choice VideoQA에서는 “In this video,” 프롬프트를 사용했습니다. 표 7 (1행과 4행)에서는 structured answer prompt를 사용하면 7B LLM으로 ActivityNet-QA에서 2.2%, EgoSchema에서 2.8%만큼 향상된 결과를 보여줍니다.
리뷰 잘 읽었습니다 몇 가지 궁금한 점이 있어 댓글 남깁니다
1. Multiple Choice VideoQA에서 VideoTree가 높은 성능을 보이지만, 이는 GPT-4 기반 LLM을 사용하기 때문이라고 말씀해주셨는데요. 혹시 논문에서 동일한 LLM(예: 같은 규모의 open-source LLM)을 사용할 때의 비교 혹은 SF-LLaVA + 더 강한 LLM 과 같은 다른 조합에 대한 실험 있었는지 궁금합니다. 만약 없다면, 저자들이 성능 영향을 LLM 능력 vs 비디오 인코딩/aggregation 설계 중 어디가 더 큰 것인지 대한 언급이 있었는지도 궁금하네요
2. Text Generation 실험에서 Detail Orientation(DO) 지표는 LLaVA-NeXT-Image가 더 높고, 이는 더 많은 입력 프레임을 사용하기 때문이라고 하셨는데요. 이 부분은 프레임 수와 공간 해상도가 함께 엮여 있어, 단순히 프레임 개수 때문인지, 아니면 이미지 토큰 분포의 차이 때문인지를 구분하기 어려워 보이기도 하네요. 따라서 혹시 논문에서 프레임 수만 바꾸거나, 동일 토큰 내에서 해상도/프레임 수를 조정하는 ablation이 있었나요?
안녕하세요 주영님 좋은 질문 감사합니다.
SF-LLaVA의 주요 목표는 training-free 방식으로 기존 Image LLM을 사용하여 비디오 태스크를 수행하기 때문에 비교 대상은 주로 동일하거나 유사한 규모의 오픈소스 LLM을 사용합니다. 저자들은 LLM의 능력과 비디오 인코딩 설계 중 어느 쪽이 성능에 더 큰 영향을 미치는지에 대해 언급하지는 않았습니다. 하지만 논문의 전체적인 초점은 “SlowFast”라는 새로운 비디오 인코딩을 통해 기존 Image LLM의 비디오 이해 능력을 훈련 없이 높였기 때문에 이는 좋은 비디오 표현 설계가 LLM의 능력을 활용하는 데 영향을 줄 수 있다 생각합니다
2. 프레임 수를 1,2,4,8,10,12 으로 바꾸어가며 albation 성능을 측정했고 프레임수 10에서 가장 좋은 성능을 보여습니다. 하지만 이는 전반적인 성능 측정이고 Text generation (DO) 만을 위한 실험은 진행하지 않았습니다.
감사합니다.
안녕하세요 정의철 연구원님 좋은 리뷰 감사합니다.
요즘 SlowFast의 아이디어를 적용한 점이 흥미롭네요. SlowFast는 CNN기반의 네트워크로 Layer마다 SLow Path와 Fast Path의 Fusion을 통해 비디오를 이해하는데, SLOWFAST-LLAVA는 SLow Path와 Fast Path의 concat을 마지막에 한번만 하는 이유가 궁금합니다. 사실 SlowFast 이후 2 pathway를 활용하여 비디오를 모델링하는 연구들이 꽤 존재했던 걸로 기억하는데 완전 새로운 방법론이라는 생각이 들지는 않습니다. SlowFast의 방법을 적용했다는 것 외에 다른 Contribution이 있는지도 궁금합니다. 마지막으로 주영님의 질문과 비슷한데 오픈소스 기반의 다른 방법론과의 성능 차이도 궁금합니다.
감사합니다.
안녕하세요 성준님 좋은 질문 감사합니다.
SlowFast가 기존에 있던 방법론이라는 사실은 몰랐는데 덕분에 알게되었습니다. 제가 SlowFast의 구조는 잘 몰라서 성준님이 설명해주신 것을 바탕으로 답변을 드리면 SlowFast는 Layer마다 Fusion을 하기 때문에 아키텍쳐 구조를 변경해야 하고 추가적인 학습이 필요하다는 생각이 듭니다. 하지만 이 논문의 컨셉은 기존에 잘 훈련된 Image LLM의 구조를 그대로 활용하며 추가적인 fine-tuning을 수행하지 않는 것에 초점을 맞추기 때문에 단순히 두 경로의 특징을 마지막에 한번만 concat하여 단순함을 유지하지 않았나 싶습니다.
감사합니다.
의철님 안녕하세요. 좋은 리뷰 감사합니다.
소개해주신 방법론이 이미지만 다루는 VLM을, 비디오까지 다룰 수 있도록 확장하는 가장 쉽고 간단한 방식인 것 같습니다.
결국 본 방법론은 training-free로, 비디오를 마치 연속된 이미지처럼 다루되 기존 방법론들과의 차이를 두기 위해 SlowFast 기반의 샘플링을 하여 모델에 넣어준 것으로 이해하였습니다. 그렇다면 위 SlowFast 방식으로 샘플링된 형태의 비디오를 가지고 fine-tuning도 할 수 있을텐데, 이렇게 할 경우 논문에서 제안한 training-free 또는 기존 단일 샘플링 방식의 방법론들과의 성능은 어떻게 차이가 날지 의철님의 의견이 궁금합니다.
안녕하세요 현우님 좋은 질문 감사합니다.
일단 본 논문에서 제안한 방법이 기존 training-free 방식보다 좋은 성능을 보였기 때문에 slow-fast path의 방식이 성능 향상에 도움이 된다는 것을 알 수 있습니다. 하지만 fine-tuning을 적용하게 되면 기존에 학습된 가중치가 변하게 되기 때문에, 이것이 실제로 성능 향상으로 이어질지 혹은 성능 저하로 이어질지는 실험적으로 확인해봐야 알 수 있을 것 같습니다. 제 생각에는 slow-fast path를 통해 성능 향상을 시킬 수는 있지만 지금 구조는 너무 단순하기 때문에 추가적인 구조 설계가 필요할 것 같네요.
감사합니다.
리뷰 감사합니다.
이미지만 다루는 llm 모델을 비디오 llm 으로 확장하는 과정에서 결국 핵심이 되어야할 부분은 temporal 축에서의 고려일것 같은데, 이와 관련해선 단순히 flatten 해서 concat 한 후 llm 에 넣는것으로 이해했습니다. 명시적인 temporal modeling 기법이 상대적으로 단순한데도 높은 성능을 달성하는 핵심 key 가 뭐라고 생각하시는지 궁금합니다.
안녕하세요 석준님 좋은 질문 감사합니다.
겉보기에는 단순히 flatten하여 concatenate하는 것처럼 보일 수 있지만, SlowFast 디자인 자체가 이미 시간적 정보를 사전 처리하여 LLM에 전달하고 있습니다. Fast Pathway는 ‘빠른 변화’와 ‘움직임’에 초점을 맞추고, Slow Pathway는 ‘느린 변화’와 ‘장면의 의미’에 초점을 맞추고 있습니다. 이러한 설계가 기존 training-free 모델들보다 높은 성능을 달성할 수 있는 핵심 요인이라고 생각합니다.
감사합니다.
안녕하세요 의철님 리뷰 감사합니다!
궁금한 점이 있어 질문남깁니다~!
Slow path는 10*12*24= 2,880개의 고해상도 토큰을, Fast path의 50 × 4 × 4 = 800개의 저해상도 토큰을 단순 concat한다고 알려주셨는데 이렇게 토큰수가 크게 다른 두 시퀀스를 단순히 concat해서 LLM입력으로 사용해도 어텐션 측면에서 비율 불균형의 영향이 없는지 궁금합니다! 혹시 해당 부분에 대한 ablation이나 추가 분석이 있었을까여?