오늘은 Deformable Attention Transformer 를 주제로 리뷰를 작성하고자 합니다. 현재 진행중인 실험에서 deformable attention 컨셉을 사용중이기에, 해당 논문을 읽어보게 되었습니다.
바로 리뷰 시작하겠습니다.
1. Introduction
널리 사용되고 있는 ViT 기반의 모델들은 CNN 기반 모델에 비해 더 큰 receptive fields 와 long-range dependencies 를 모델링 하는 데에 효과적이며, 큰 규모의 학습데이터와 함께 성능적으로도 강점을 가집니다. 하지만 visual recognition 관점에서 봤을 때 과도한 attention 은 양날의 검과 같습니다. 구체적으로 보자면, query patch 당 과도한 수의 key 가 선정되게 된다면 높은 계산 비용과 느린 수렴, 그리고 과적합 문제가 발생합니다.
과도한 attention 연산량을 줄이기 위해 앞선 연구들에서 여러 효율적인 attention 기법들을 제안했습니다. 아래 그림처럼 말이죠.
대표적으로 swin-transformer 에서는 전체 이미지(feature) 를 window 공간으로 나눈 후, 해당 window 공간 내에서 self-attention 연산을 수행합니다 (fig 1-b). 반면 Pyramid Vision Transformer (PVT) 의 경우 ViT의 연산량 자체를 줄이기 위해 key feature와 value feature 를 down-sampling 하는 방식을 사용합니다.
저자는 위와 같은 기본적인 방식들이 효과적이기는 하지만, 입력 데이터에 유동적이지 않은, hand-crafted attention 이기 때문에 optimal 하지 않을 수 있다고 주장합니다. 예를들어 중요한 key/values 가 소실된다거나, 중요하지 않은 key/values 가 가중되는 등의 문제도 발생합니다.
(이런 key/value 의 중요도 문제가 결국 self-attention 을 통해 해결되지않나? 싶기는 하지만,, 저자가 본 문장을 통해 주장하고자 한 부분은 아마 “입력데이터에 유동적이지 않다” 부분인 것 같네요.)
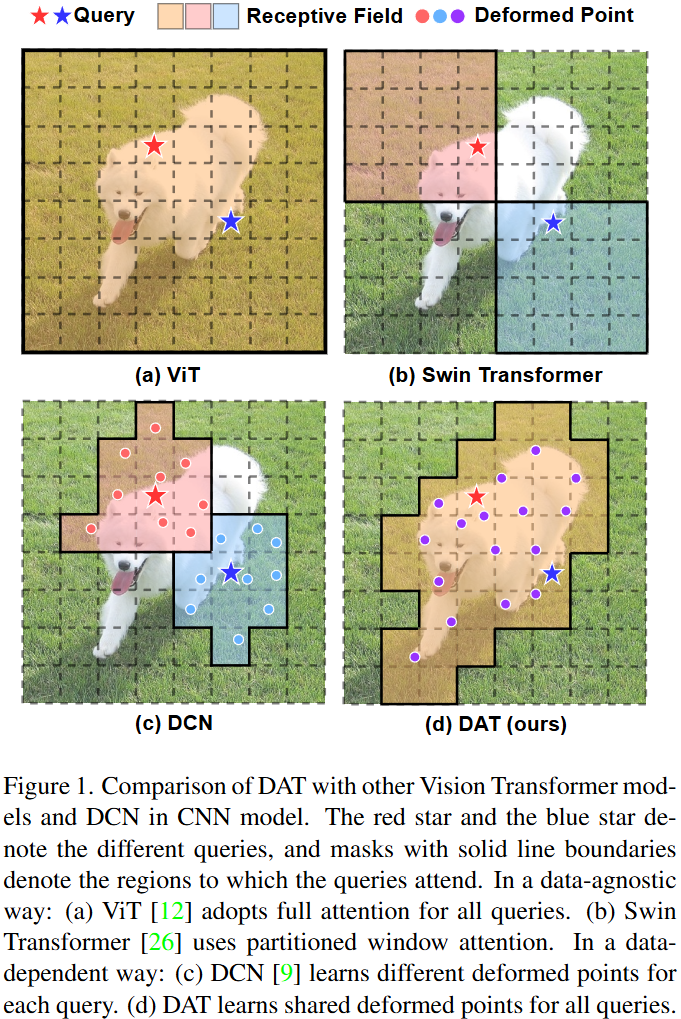
이에 이상적으로 대응하기 위해선, 입력 query 에 대한 후보 key/value 집합이 유동적이고, 각 개별 입력에 대해 적절하게 적응하는 능력을 가져야합니다. 위 fig 1.-(c) 의 deformable convolution network (DCN) 에서는 convolution filter의 receptive field를 고정하지 않고 유동적으로 학습하는 것이 데이터에서 더 중요한 영역에 집중하고 잘 학습할 수 있습니다.
그리고 이 연구를 기반으로 하여 transformer 구조에도 deformable 한 이런 컨셉을 적용하고자 하는 노력들이 있었지만, 단순히 적용하게 될 경우 메모리/계산 복잡도가 폭증하게 됩니다. 그렇기 때문에 transformer 백본 자체에 deformable 메커니즘을 직접적으로 적용한 연구는 없었고, Deformable detr 처럼 detection head 에만 적용하거나, 전처리 layer 정도에만 사용하는 등의 시도만 존재했습니다.
그리하여 본 논문에서는 transformer 백본에 deformable attention 모듈을 엮은 Deformable Attention Transformer (DAT) 를 설계하였습니다. 이전 DCN 과 다른 점은 위 fig. 1의 (c)와 (d)를 비교해보시면 됩니다. 전체 feature map 에서 각 (query) pixels 별로 서로 다른 offset을 학습하는 DCN 과 달리, 본 논문에서 제안하는 DAT 에서는 전체 feature map 에 대해 하나의 공통된 offset을 학습하게 됩니다. 여기서 학습된 offset 을 통해 key와 value 가 중요한 영역으로 이동할 수 있게 됩니다.
동작 방식에 대해선 methods에서 더 설명드리도록 하겠습니다.
2. Method
본 논문은 기존 ViT 모델들이 가지는, 고정적인 attention pattern 의 한계를 극복하고자 각 입력 데이터에 따라 유동적으로/동적으로 attention 영역을 조절하는 Deformable Attention Transformer (DAT) 를 제안합니다.
2.1. Problem Definition
기존 ViT 모델들은 attention 연산을 하는데에 있어 크게 두 가지 한계점을 가집니다.
- Standard ViT: 이미지 전체에 대해 full-attention 을 수행합니다. 이는 모델이 foreground 객체와 관련없는 모든 배경 영역까지 계산에 포함시키게되고, 과도한 computational cost 가 발생합니다.
- PVT, Swin Transformer: 위의 문제를 해결하기위해 attention 영역을 제한하는 ‘Sparse Attention’ 을 사용합니다. 하지만 이 방식은 입력 데이터와 상관없이 (data-agnostic) 고정된 local window 방식을 사용하게 됩니다. 이 때문에 정작 중요한 key-value 쌍을 놓치게 되거나 낮은 가중치를 부여하게 될 수도 있고, 불필요한 영역을 계속해서 계산에 포함시킬 수 있습니다.
저자들은 특히 PVT 에서 수행하는 key/value feature downsampling 이 큰 정보손실을 유발하고, Swin Transformer 의 window 방식은 receptive field 확장이 느려서 큰 객체 모델링에 한계가 있다고 주장합니다.
2.2. Deformable Attention Module
위의 문제를 해결하기 위해, 본 논문에서는 CNN 분야의 Deformable Convolution Network (DCN) 에서 영감을 받아서, 각 입력 데이터에 따라 attention 영역을 유연하게 변화시키는 Deformable Attention 기법을 설계합니다. 아래 그림과 같습니다.
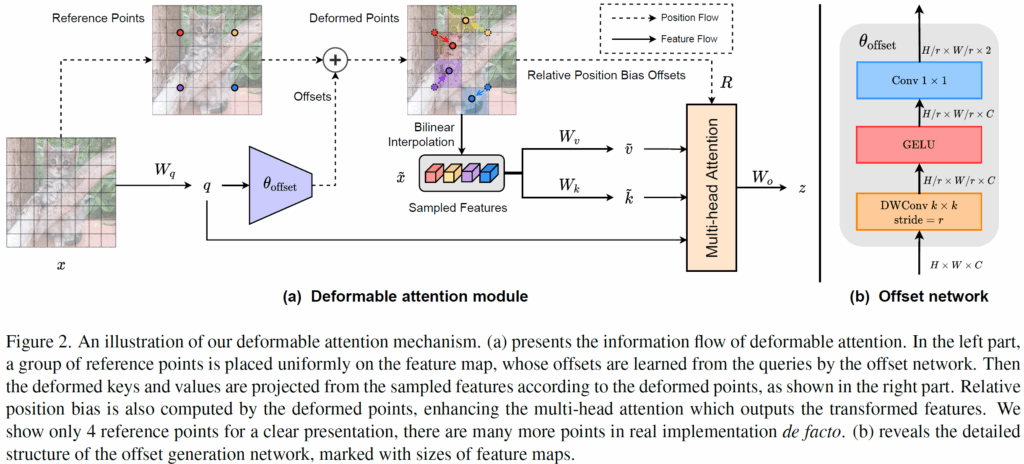
위 그림은 전체 Deformable Attention Module 의 구조에 해당합니다. 해당 모듈의 핵심 컨셉은, attention 연산에서 모든 key-value 를 사용하는 것이 아니라 “중요할 것 같은 위치의 feature들만 샘플링하여 key-value 로 사용하는것“입니다. 전체 대략적인 동작 방식은 아래와 같습니다.
- 입력 feature map x 에 대해 일정한 간격의 Reference Points p 그리드를 생성합니다. 그리드는 마치 바둑판 격자무늬처럼 균등한 간격으로 생성되는것이며, 위 그림에서는 깔끔한 표현을 위해 4개의 reference points 만을 임의로 그렸다고 합니다.
- 입력 feature x 를 임베딩하여 Query q를 생성하고, 해당 q를 shallow한 Offset Network \theta_{offset} 에 통과시켜서 각 reference points 가 이동하게 될 offset \Delta p를 예측합니다.
- 기존 reference points p에 offset \Delta p 를 더해서 변형된 deformed points p + \Delta p 를 계산합니다.
- Interpolatoin 을 사용해서 원본 feature map x 에서 해당 deformed points 위치에 대한 feature \tilde{x} 를 샘플링합니다.
- 샘플링된 feature \tilde{x} 를 임베딩하여 Deformed key \tilde{k} 와 Deformed Value \tilde{v}
- 최종적으로, 원본 Query q와 Deformed key \tilde{k}, Deformed Value \tilde{v} 를 사용해서 multi-head attention 을 수행하게 됩니다.
여기서 중요한 점은, CNN의 DCN처럼 모든 픽셀마다 개별 offset을 학습하면 N_q*N_k*C 라는 어마어마한 계산량이 발생한다는 것입니다. 저자들은 이 문제를 “서로 다른 query라도 비슷한 attention map을 갖는다” 는 관찰에 기반해, 모든 query가 shared deformed key/value를 사용하도록 설계하여 계산량을 선형 복잡도로 낮췄습니다. 이에 대한 직관적인 이해는 intro figure 의 (c) 와 (d) 를 비교해서 살펴보시면 좋으실 듯 합니다.
2.3. Deformable Relative Position Bias
Swin Transformer와 같은 기존 모델들은 query-key 간의 상대적 위치 정보를 인코딩하기 위해 Relative Position Bias Table \hat{B}을 사용합니다. 하지만 이 방식은 key의 위치가 격자(grid)에 고정되어 있어 이산적인(discrete) 상대 거리만 표현할 수 있습니다.
반면 DAT 의 key 는 offset 으로 인해 연속적인 (continuous) 좌표를 가지게 됩니다. 따라서 저자들은 연속적인 상대 위치 좌표를 이용해서 기존의 이산적인 Bias Table \hat{B} 에서 값을 interpolation 해서 bia 를 계산하는 Deformable Relative Position Bias 방식을 설계합니다.
2.4. Model Architecture
DAT 의 전체 구조는 Swin Transformer 와 유사하게 4단계의 계층적 (pyramid) 구조를 가집니다. 아래 그림처럼 말이죠.
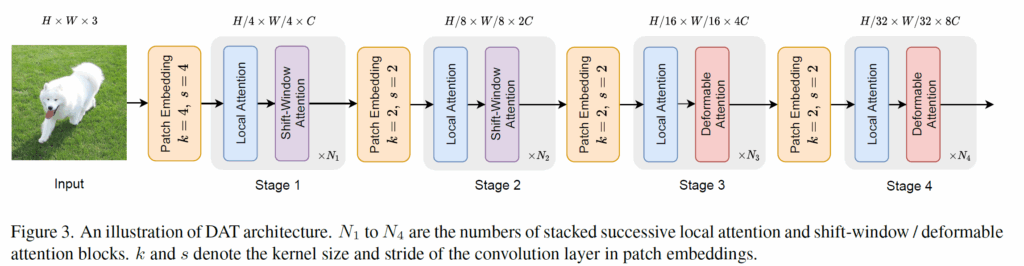
눈여겨 볼 점은 Deformable Attention 이 모든 stage 에 적용되지 않는다는 것입니다.
전체 stage 1~4중에서 stage 1,2 에서는 Swin-transformer 와 동일하게 표준 shift-window atttention 을 사용하고, stage 3,4 에서 Local Attention block 과 Deformable Attention Block 을 순차적으로 쌓아서 사용한다고 합니다.
이에 대해 저자들은 초기 stage 1,2 에서는 주로 local feature 를 학습하고, Deformable Attention 은 feature map 이 큰 초기단계에서 계산 부담이 크기 때문에, global 관계성 모델링이 더 중요한 뒤쪽 stage 3,4 에서만 적용하는 것이 효율/성능의 trade-off 관점에서 좋다고 주장합니다.
3. Experiments
3.1. ImageNet-1K Classification
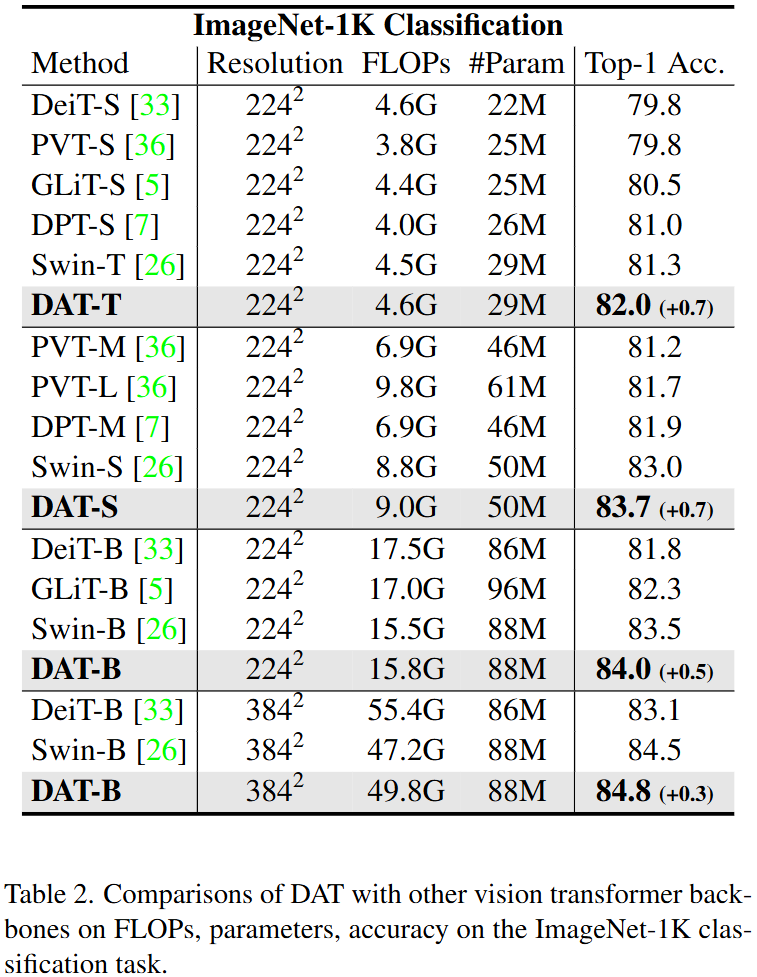
첫번째로는 ImageNet-1K 데이터셋에서 Image Classification 실험입니다.
여러 모델 size에 대해서 DAT 모델이 이전 방법론 대비 꽤나 큰 폭의 성능 향상을 보이고 있습니다. 이와 동시에 연산량과 Parameter 수도 거의 변함이 없네요.
3.2. COCO Object Detection
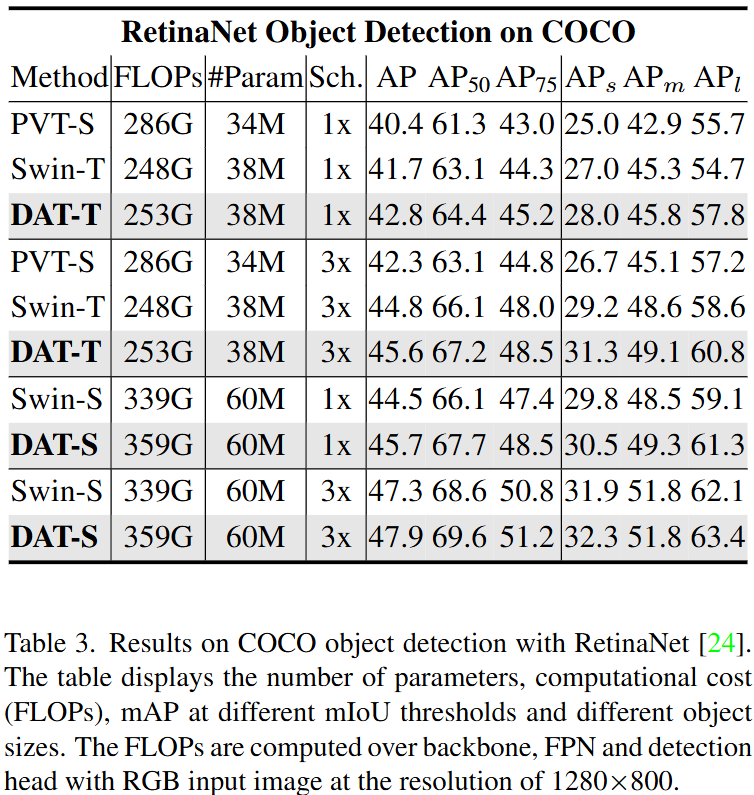
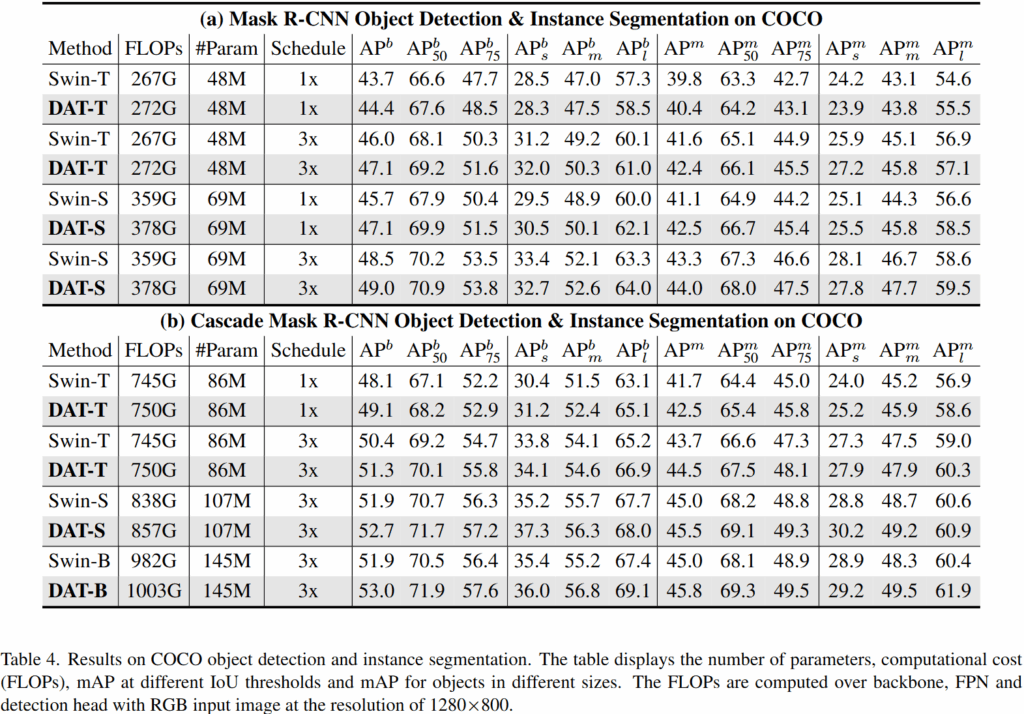
다음으로는 COCO 데이터셋에서 RetinaNet, Mask R-CNN, Cascade Mask R-CNN의 백본으로 DAT를 사용했을때의 실험 결과입니다. 위 결과에서 DAT 는 Swin Transformer 대비 일관되는 성능 향상을 보여주고 있습니다.
특히 다른 수치 대비 큰 객체 (large object) 에 대한 성능인 AP_l 의 향상폭이 꽤나 큰 점이 눈여겨볼만한데요, 저자들은 이에 대해 Deformable Attention 이 유연하게 long-range dependency 를 모델링 할 수 있기 때문이라고 주장합니다. Swin-Transformer 와 같은 고정된 Window 로는 한번에 커버하기 힘든 큰 객체를 ,DAT 에서는 효과적으로 다룰 수 있다고 합니다.
3.3. ADE20K Semantic Segmentation
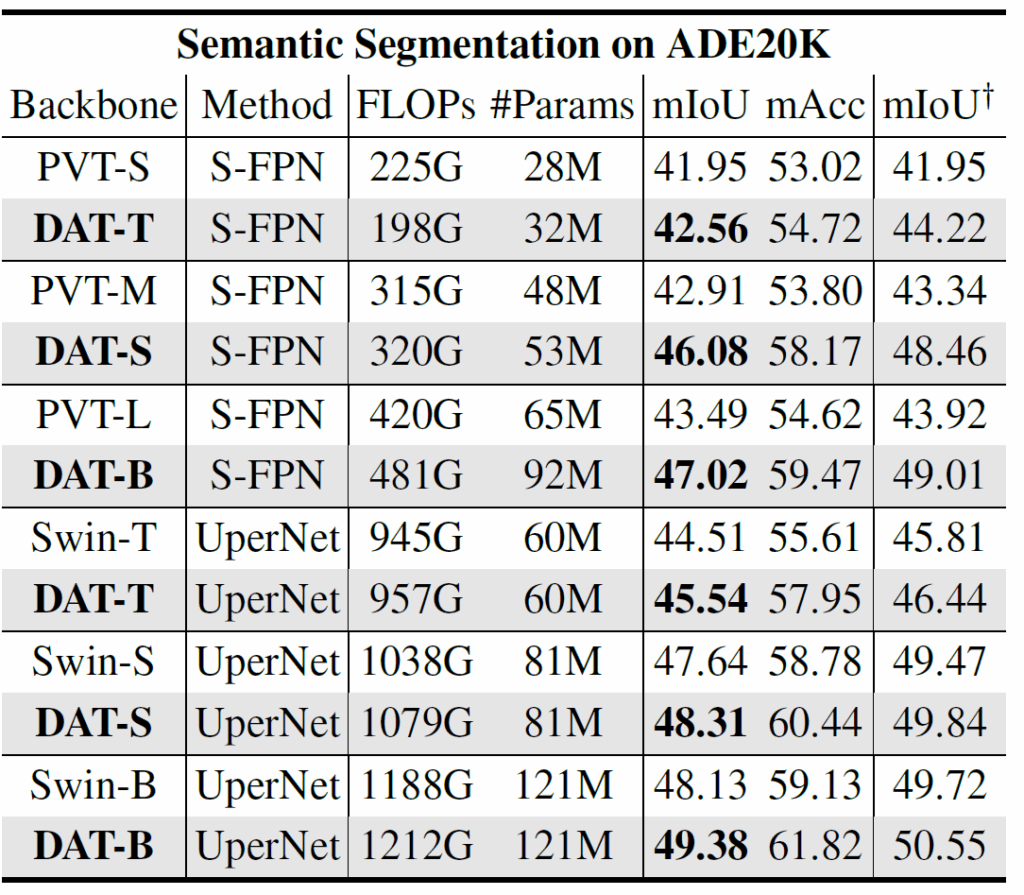
네, 그리고 Dense prediction task 인 semantic segmention 에서도 잘 동작한다~ 라고 주장합니다~~.
3.4. Ablation Study
실험은 DAT-T 구조를 사용하며, ImageNet-1K 의 Accuracy 를 측정합니다,.
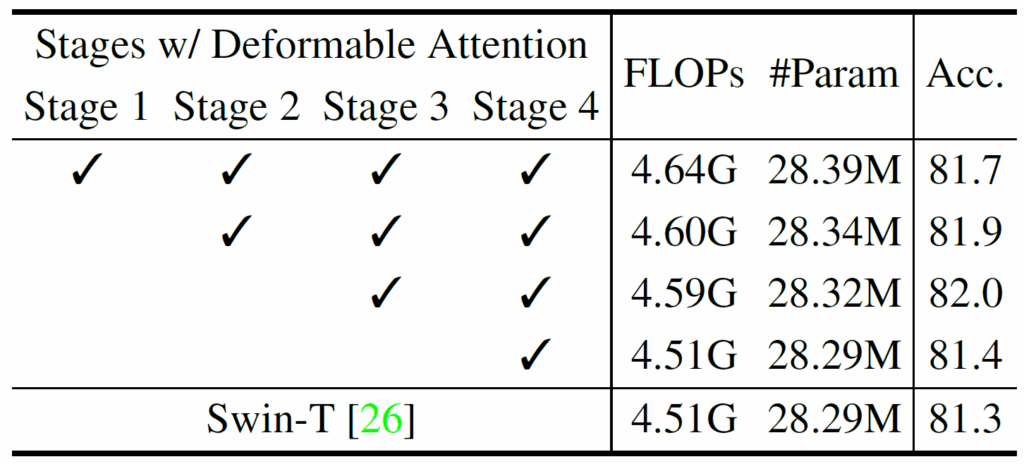
stage 1~4 중 어디에 Deformable Attention 을 적용하는것이 가장 좋은지에 대한 ablation 결과입니다.
결과적으로 stage 3,4 에 적용했을 때 82.0 으로 가장 좋은 성능을 보입니다. 반면 모든 stage 에서 사용하는 경우 81.7 로 미세하게 성능 하락이 발생하는데요, 이에 대해서는 method 에서 저자가 언급한 “초기 stage 에서는 local feature 학습이 중요하고, 후반부에 global 관계 모델링이 중요하기 때문에 후반부에 deformable 을 넣어서 receptive field 를 늘려야 한다~” 라고 말한 것과 일맥상통하는 결과입니다.
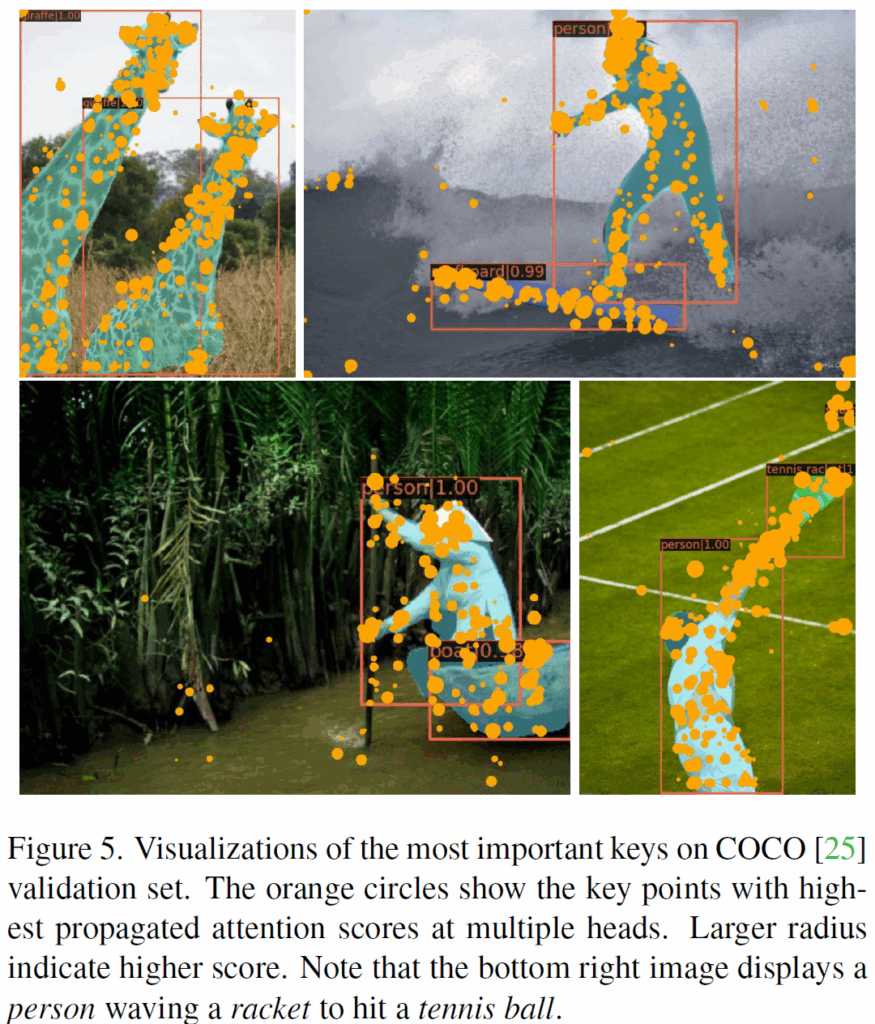
위 figure 는 저자들이 제안하는 Deformable Attention 이 실제로 객체의 중요한 영역을 집중하는 지를 보여주는 시각화 자료입니다. 여러 deformed key 에 대해 attention score 가 높은 부분을 표현했다고 합니다. 배경 영역보다는 객체 영역에 집중하는 모습을 확인할 수 있습니다.

그리고 위 figure 는 전체 deformed key 를 모두 시각화 한 자료입니다. 전체 이미지 영역에 대해 균등하게 생성된 reference points 에 예측된 offsets 이 더해진 결과 (= deformed points) 라고 보시면 됩니다. 첫 줄은 stage3을, 두번째 줄은 stage 4 를 나타냅니다.
저자들이 주장하길, stage 3->4로 갈수록 deformed points 들이 배경 영역이 아니라 정확하게 target obejct 의 경계 내부로 잘 deformed 된다~ 라고 하는데 음.. 저는 잘 모르겠습니다 ㅎ. 100% 납득하기는 어렵네요, 생각보다 deformed 가 많이는 안되는 것 같습니다.

다음은 attention map 을 직접 표현한 시각화 결과입니다. 첫번째 세번째 row 는 DAT의 결과, 두번째 네번째 row 는 Swin Transformer 의 결과입니다.
각 그림을 자세히 보시면 특정 query point (빨간색 별) 과 deformed key (주황색 점) 이 보이실겁니다. 이는 특정 query point 에 대해 높은 attention 값이 계산되는 key 를 시각화 한 결과입니다.
Swin Transformer 의 결과 (2,4 rows) 의 경우 확실히 선별된 key 들이 local window 안에 갇혀있네요. (뭐 어쩌면 당연한 결과일 수 있습니다.)
반면 DAT 의 경우 선별된 deformed key 들이 꽤나 globally 하게 중요한 영역들에 퍼져있는것을 볼 수 있습니다, 유동적으로 말이죠.
네 오늘은 Deformable Attention Transformer 논문을 리뷰하였습니다.
시각화 결과를 보니 Deformed Key 라고 해서 막 완전 많이 deformed 되지는 않더군요, 하지만 실제 attention score 가 높은 key 를 선별해서 시각화 했을 때에는 꽤나 효과적으로 잘 동작하는 결과를 보이는걸로 봐서 효과가 꽤나 있는 방법론이라는 것을 알게 되었습니다.
리뷰 마치겠습니다 감사합니다.
안녕하세요, 석준님 좋은 논문 리뷰 잘 읽었습니다
Deformable Attention이 입력마다 중요한 영역만 선택적으로 참조한다는 점이 매우 흥미로웠습니다.
한 가지 이해가 안되는 점으로는 DAT이 전체 이미지에서 일부 위치만 샘플링해 key/value를 구성하는 방식이라면, 기존 ViT의 장점인 전역적인 관계 모델링 능력이 제한되는 것 아닌가? 하는 의문이 들었습니다.
논문 사용되는 방법으로도 전역성이 유지가 되는지 아니면 이러한 전역성 감소 문제나 trade-off에 대해 별도로 논의한 부분이 있는지 궁금합니다.
좋은 리뷰 공유해주셔서 감사합니다!🎯
안녕하세요 석준님 리뷰 감사합니다 ~!
한가지 궁금한게 있는데요!
“서로 다른 query라도 비슷한 attention map을 갖는다”라는 관찰이 결국 이미지에서 비슷한 부분이나 같은 객체에 포함된 픽셀들이 피처도 비슷하고 그래서 key나 value의 위치도 비슷하기 때문에 attention map이 큰 차이를 보이지 않는 거고, 따라서 offset을 쿼리마다 따로 만들 필요가 없다는 의미로 이해하면 될까요??
제가 맞게 이해한건지 확인차 질문 드립니다!